基于深度學習的維吾爾文掃描體識別
2021-03-27 01:18:44吾守爾斯拉木許苗苗熊黎劍王明輝
東北師大學報(自然科學版) 2021年1期
湯 敬,吾守爾·斯拉木,許苗苗,熊黎劍,王明輝
(1.新疆大學軟件學院,新疆 烏魯木齊 830091;2.新疆大學信息科學與工程學院,新疆 烏魯木齊 830046)
0 引言
中國作為一個多民族的國家,維吾爾文是目前中國使用比較多的少數民族語言之一,尤其是新疆作為維吾爾族的主要聚居地,人們平時的交流、學習等方面都會頻繁地使用維吾爾文,并且有關維吾爾文的文獻資料也相當多,而現有技術在中文的圖像文字識別中已經廣泛應用,相比之下維吾爾文圖像文字識別的研究相對落后了很多,因此研究維吾爾文的圖像文字識別有著重要的意義.
文獻[1-4]針對維吾爾文圖像識別是采用對單詞文字進行先切分,然后再來識別的思想,分析如何切分更好才能使識別結果更優.其中有關將單詞不進行切分,整體直接識別的研究相對來說還是較少.由于維吾爾文文字自身的特點,其是粘連型的文字,所以在進行切分的時候具有很大的難度,是過往切分研究中的難點之一.
隨著深度學習在視覺研究領域所展現出的強大性能,其在英文和中文的圖像文字識別中也表現非凡,從眾多科研人員展示的實驗研究結果中也可以看出深度學習優于傳統方法.所以在維吾爾文圖像文字識別中使用深度學習的方法來整體識別文字就可以避免切分.已有的關于維吾爾文的研究中,賈建忠[5]在研究維吾爾文文字識別時采用的神經網絡研究是對單個字符的識別,在單字符的識別上有著不錯的效果.
本文建立了維吾爾文圖像識別的數據集,提出了TRBGA模型.
1 深度學習
1.1 深度學習概念
深度學習(deep leaning,DL)來源于人工神經網絡,其概念是由G.E.Hinton等[6]在2006年提出,從此開啟了深度學習在學術界和工業界的浪潮.深度學習是目前最成功的表示學習方法,它把表示學習的任務分成幾個小的目標,可以先從原始的數據中學習低級表示,之后從低級表示學習到高級表示.這樣,機器就更容易自主地將這些小目標學好,從而完成最終學習任務,并且省去了人工選取過程[7].目前深度學習在算法、模型、硬件設施與開發社區都取得了重要的突破[8],解決了之前神經網絡難于優化、應用有限等問題.目前深度學習在計算機視覺領域大放異彩,其中卷積神經網絡、循環神經網絡、深度殘差網絡、密集卷積網絡等常被使用.
1.2 深度學習模型介紹
1.2.1 卷積神經網絡
卷積神經網絡(CNN)的英文全稱是“Convolutional Neural Network”.而神經網絡的靈感來自于生物神經網絡的功能和結構,并以此提出一種計算模型.CNN可以從端到端的通過傳統的方法訓練并學習圖像的特征[9].CNN網絡最早可以追溯到1989年[10].近些年它在圖像分類的問題上獲得了成功.目前,CNN在圖像識別領域也有著廣泛的應用.CNN作為一種人工神經網絡,其結構特征主要由輸入層、卷積層、池化層、全連接層組成,其中卷積層主要是提取特征,池化層下采樣,全連接層用來做分類.其結構如圖1所示.得益于現在GPU所提供的強大算力支撐以及網絡中加入激活函數RuLu,原來難于處理的大量數據,現在處理起來變得容易很多,計算時間大幅減少、收斂速度也更快.

圖1 卷積神經網絡結構
1.2.2 循環(遞歸)神經網絡
循環神經網絡(Recurrent Neural Networks,RNN)[11]中神經元的輸出可以在下一個時間戳直接作用到自身,這樣可以在普通的CNN或全連接網絡里解決,由于每層神經元的信號只能向上一層傳播導致樣本的處理在各個時刻是獨立的,以及全連接的DNN會因為時間序列上的變化而無法對其進行建模等問題.RNN被設計出來的目的是用來處理序列相關的數據,其核心思想就是將當前時刻的輸入與上一個時刻的輸入一起作用于當前時刻輸入的計算,這樣隱藏層之間的節點就變得有連接了,而傳統的神經網絡每層之間的節點是無連接的.與CNN網絡通過空間上參數共享從而減少參數的思想不同,RNN的參數共享體現在時間序列上.目前RNN在語言建模、語音識別[12]、機器翻譯[13]、生成圖像描述、視頻標記等領域都有很好的應用.RNN結構示意圖如圖2所示.
1.2.3 殘差網絡
理論上講,神經網絡層數越多能提取到的特征信息就越豐富,也就越具有語義信息.在計算機視覺領域,兼有分辨率信息和語義信息的網絡才能獲得更好的性能,單靠淺層網絡提取的分辨率信息獲取的效果會降低.采用堆積神經網絡層數來提取特征應該會有好的性能,但實際情況卻與之相反,深層的網絡結構不僅會出現性能退化,而且帶來了梯度消失或爆炸的問題,通過初始化數據和正則化等傳統方法解決了梯度的問題.
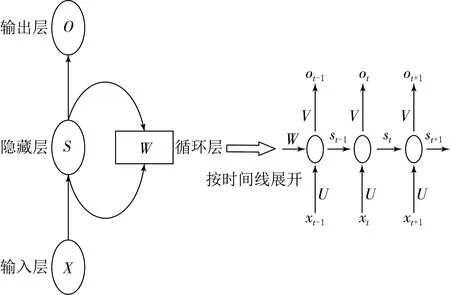
圖2 RNN結構
文獻[14]提出來的殘差網絡(ResNet)在提升性能的同時也很好地解決了加深神經網絡層數帶來的缺陷.ResNet的核心思想是引入了身份近路連接(IdentityShortcut Connention),也就是淺層特征和深層特征的一個簡單相加,將一個跳躍(skip connection)添加到標準前饋卷積網絡來繞過一些中間層,實際效果相當好,在保持原有網絡性能的同時,通過加深網絡層數來提高網絡性能.目前殘差網絡已經在計算機視覺[15]等領域得到了廣泛的使用.其結構如圖3所示.
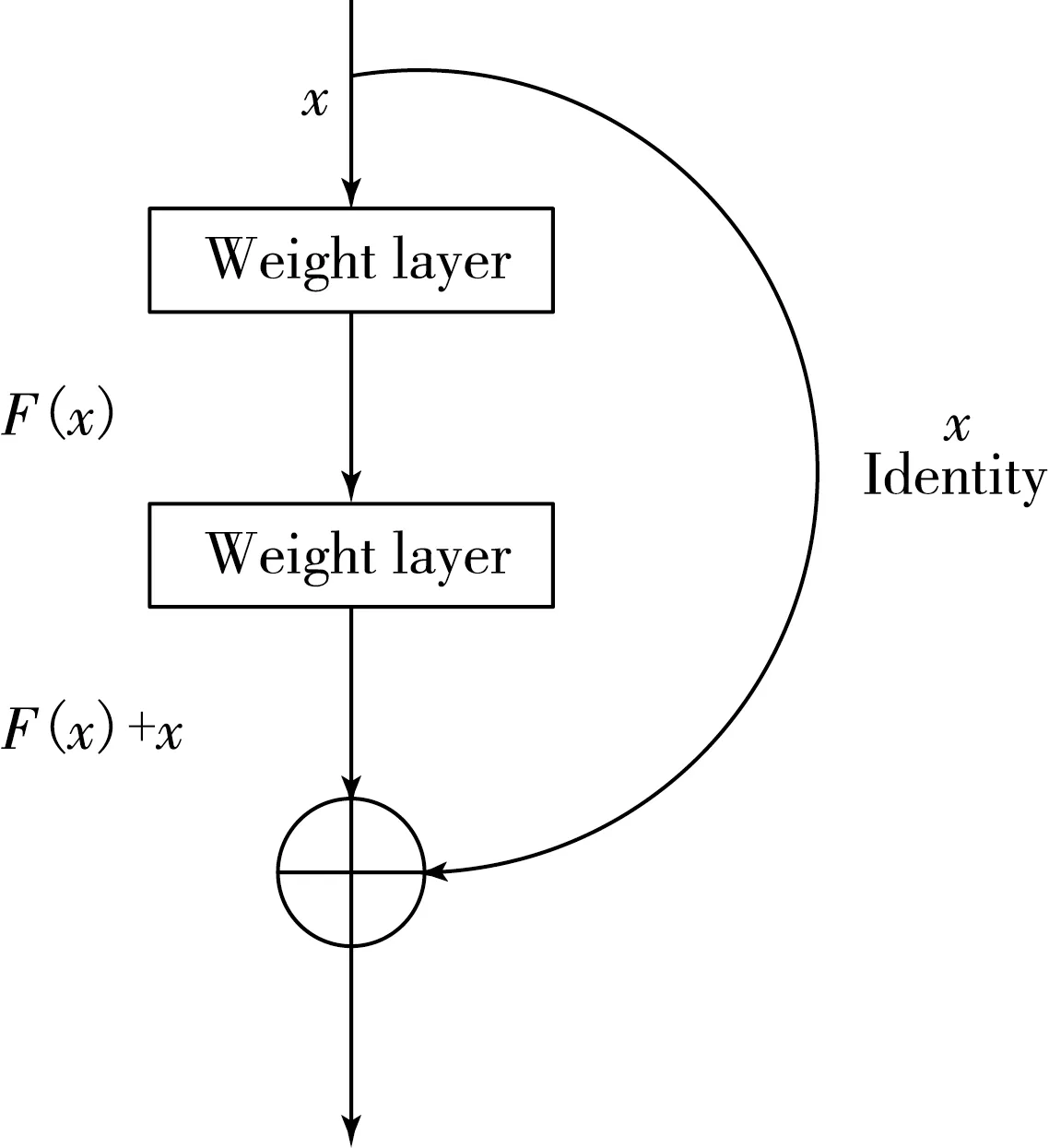
圖3 殘差網絡結構
1.2.4 密集卷積網絡
加深的網絡可以帶來豐富的表達,從AlexNet和VGG等可以看出研究人員在深度問題上一直在研究.但更深的網絡又不可避免帶來梯度消失問題,隨后ResNet、Highway Networks、Stochastic depth[16-18]等網絡都是針對該問題提出的,盡管這些網絡結構不同,但是它們的核心點是相似的,都是構建一個從早期層到后期層的短路徑.
G.Huang等[19]提出的密集卷積網絡(DenseNet)借鑒了ResNet的設計理念,并在此基礎上推陳出新.為了保證網絡之間各層能有最大的信息流動來進行更加有效地訓練,DenseNet采用了一種更為密集的連接方法,通過前向傳播將各層和其他層密集地連接起來.在普通卷積神經網絡里,網絡有多少層就有多少連接,其模式是一對一的,在DesnseNet網絡中就不一樣了,各層會和所有的其他層進行連接,L層的DenseNet網絡將有L(L+1)/2個連接,對于每層來說,在它前面的各層的特征都將作為它的輸入,同時它的特征也將會和它前面的層一起作為其后各層的輸入.DenseNet網絡結構有效地緩解了梯度上的問題,網絡層間特征的傳播得以加強,支持特征重用,同時也在很大程度上減少了參數量,其結構如圖4所示.
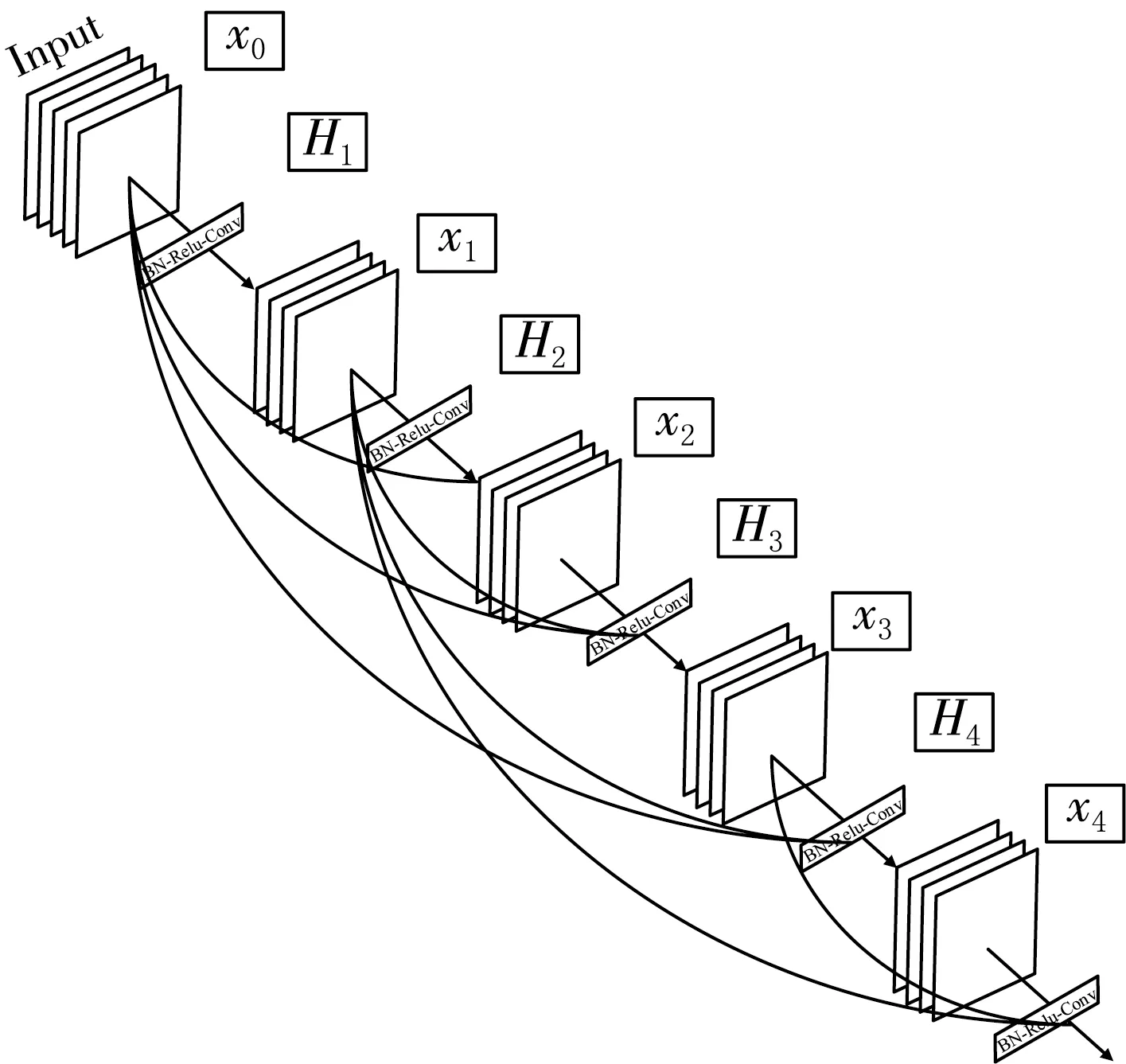
圖4 密集卷積網絡結構
2 基于深度學習的圖像文字識別模型
維吾爾語的圖像文字的識別過程主要步驟是先對輸入進來的圖像進行特征提取,在經過循環層來學習上下文的語義信息,最后通過CTC或者Attention生成最終的標簽.如圖5所示.
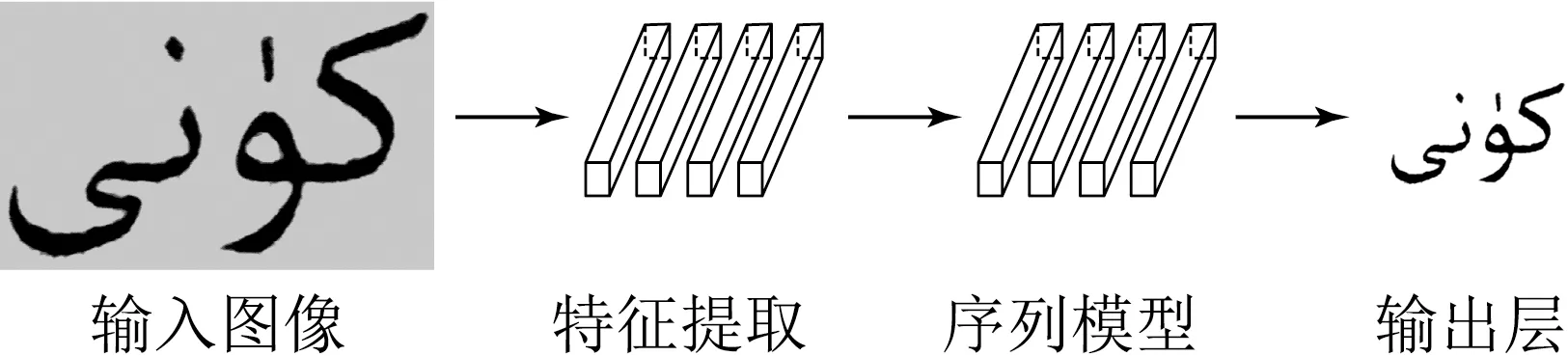
圖5 識別模型結構示意圖
2.1 CRNN模型
CRNN(Convolutional Recurrent Neural Network)[20]是一種端到端的模型,該網絡結合了DCNN和RNN 2個模型,可以用來對長度不固定的圖像進行序列識別.在該模型出來之前傳統的識別方式都是先切分,然后再來識別的,用來識別的算法不僅煩瑣而且可讀性也很差,同時存在著許多的問題無法解決,比如粘連型的文字.CNN在提取圖像表征特征上表現優異,RNN在處理序列相關的問題上具有優勢,這樣將兩者結合起來的神經網絡在需要對有時序的數據建模上表現驚人,因此不僅在音頻、自然語言等領域得到了廣泛應用,在文本序列識別研究的領域也帶來了本質革新.
CRNN模型由3部分網絡結構組成,分別是卷積層、循環層以及轉錄層(CTC)[21].
卷積層部分通過普通神經網絡中的卷積層和最大池化層來提取輸入進來的圖像的序列信息,經過該層后的圖像將被統一到相同的高度,也就是在空間上對圖片進行了保序和壓縮處理,相當于在水平方向上,圖像被切成了若干片,然后從這些切片中提取出相對應的特征向量作為下一步循環層的輸入.雖然卷積學習到的是每一列上的特征,但是這些特征與輸入圖像的一塊區域是相對應的,也就是卷積網絡的感受野之間是重疊的,這樣就有了上下文有關的信息,為后面的RNN學習上下文特性提供了可能.
循環層部分使用一個雙向雙層的LSTM結構,LSTM是RNN的變形,其在學習序列有關的上下文信息上表現出色,因此圖像識別時加入LSTM使得模型變得更穩定和有效.在網絡訓練中,RNN可以將誤差值再反向傳給卷積層,這樣,卷積層和循環層就可以一起訓練.另外RNN可以訓練并學習長度不定的序列.
CTC層的工作是將RNN層每一幀的預測轉成序列標簽,在模擬動態規劃的過程找出最高概率的序列標簽.CTC中加入了空白類,通過一定的映射法則去除重復的序列,得到最終目標.其示意圖如圖6所示.
圖6 CTC轉錄示意圖
本文中測試運行了CRNN網絡,其在維吾爾語識別中也有著不錯的表現.
2.2 基于轉換層(TPS)的深度學習模型
TPS的主要功能是將輸入進來的圖形X轉換成歸一化的圖形X′.傳統的池化方式(Max Pooling/Average Pooling)所帶來卷積網絡的位移不變性和旋轉不變性只是局部的和固定的,而且池化并不擅長處理其他形式的仿射變換.TPS是一種基于樣條的數據插值和平滑技術,是空間變換網絡(STN)[22]的一種變體形式,而TPS非常強大的一點是它可以近似所有和生物有關的變形.因此,使用TPS可以在圖像上找到多個基準點,然后基于這些基準點進行TPS轉換成我們所期望的矩形,從而減輕網絡的學習負擔.
根據實驗的需要選擇適合實驗的網絡,本文選擇了用ResNet來提取特征,并做了層數上的調整,采用了33層的ResNet提升網絡的識別性能.
本文的序列層采用了和CRNN模型一樣的BiLSTM,另外稍微做了調整,將第一層的LSTM換成了GRU層,GRU也是RNN的變體形式.
預測模型部分的主要任務是將輸入H預測出一個字符的序列Y(Y=y,y,…).
本文的預測選擇是基于Attention的模型,從文獻[23]所做的大量對比實驗可以看出,在提升識別的性能上面Attention的模型要優于基于CTC[24]的模型,所以在實驗中直接選用了Attention的模型作為該階段的預測模型[25],通過Attention來自動捕獲輸入進來的序列的信息流,并以此來預測出字符的輸出序列.
在該Attention中用了一層基于LSTM的注意力機制的解碼器.在第t步時,LSTM解碼器將預測一個輸出
yt=Softmax(WoSt+bo).
(1)
其中:Wo和bo是訓練參數,St是LSTM解碼器隱藏層在t時刻的狀態.其中
St=LSTM(yt-1,ct,St-1).
(2)
式中ct是權重H(H=h1,…)的和,h來自于前面的網絡.其中
(3)
式中的αti是attention的權重,計算公式為
(4)
eti的計算公式為
eti=vTtanh(Wst-1+Vhi+b).
(5)
式中v,W,V和b都是網絡訓練中的參數,該LSTM隱藏層使用的維數設置為256.
2.3 目標函數
實驗訓練中,訓練數據集用TD= {Xi,Yi}來表示,其中Xi表示用來訓練的圖像,Yi表示訓練的圖像對應的單詞標簽.公式為
(6)
該目標函數通過圖像及其對應標注的單詞標簽來計算成本,從而進行端到端的模型訓練.
3 實驗過程及結果
為了保證實驗各項環境的一致性,本文所有的結果都是在相同的訓練數據集、驗證數據集、測試數據集以及計算性能上完成的.
本文是在CPU Intel Xeon 1.70 GHz、12 GB的GPU內存、Ubuntu18.04系統下搭建Pytorh的環境下進行的.實驗環境以及配置參數如表1所示.

表1 實驗環境配置參數
3.1 數據集
針對目前用于維吾爾文訓練的數據集不足,難以達到深度學習訓練的數據量.首先是收集整理維吾爾文圖像文字的相關數據,為此從兩方面進行了數據集的收集工作.
(1) 真實樣本的采集.在新疆的天山網站上收集了大概50份的維吾爾語的新聞,然后通過腳本去除重復的單詞以及符號寫入word文檔,一共采集了9 379個維吾爾文單詞.然后通過打印機打印出來后用掃描儀掃入電腦,通過工具以單詞為單位裁剪出可用于訓練的圖像.其中訓練集7 397張、驗證集991張、測試集991張.如圖7所示.

圖7 真實掃描體數據
(2) 合成數據集.盡管訓練集采用真實數據集對實驗的提升有著極大的幫助,但考慮到真實數據集的制作需要耗費大量的時間和人力,所以采用真實樣本加合成樣本的方案有其必要性,根維吾爾文由32個字母組成,有的字母的變體形式多達4種,所以形式一共有128種.本文中一個字符的多個變形仍視為該字符本身.因為和代表同一個字母,計算機沒有做區分,所以顯示的是33個字符.之后通過腳本以掃描體圖片為背景,在上面合成隨機的維吾爾文字符生成了10萬張的圖片,并請維吾爾族的同學做了后續的檢查后,將合成數據集與真實樣本的訓練集一起作為本實驗的訓練集,一共是107 395張圖像.合成數據如圖8所示.

圖8 合成數據示意圖
3.2 實驗結果對比分析
在該數據集上分別使用CRNN模型、RBA(ResNet+BiLSTM+attn)、CLOVA-AI v2(TPS+ResNet(29)+BiLSTM+attn)以及TRBGA(TPS+ResNet(33)+BiLSTM+GRU+attn)模型做了對比實驗,實驗結果如表2所示.

表2 實驗結果
從表2中可以看出神經網絡在維吾爾文圖像文字識別中有著優異的表現,其中我們提出的模型TRBGA準確率達到了99.395%,是目前幾個模型中最優的算法.
4 結論
本文對維吾爾文圖像文字識別進行了深入的研究,收集制作維吾爾圖像識別數據集和改進維吾爾圖像文字識別的算法.其中構建的維吾爾文圖像文字數據集對后續的維吾爾文識別研究有積極的促進意義,提出的TRBGA模型與主流的網絡做了對比實驗,實驗結果顯示所提出的識別準確率達到了99.395%,優于傳統模型算法.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
