GWR模型下農用地土壤鎳空間分布預測
2021-03-30 08:10:30王春帥姚立偉劉弋琿牛瑞卿任超
遙感信息 2021年1期
王春帥,姚立偉,劉弋琿,牛瑞卿,任超
(1.河南省地質礦產勘察開發局 第一地質礦產調查院,河南 洛陽 471000;2.中國地質大學(武漢) 地球物理與空間信息研究所,武漢 430070)
0 引言
隨著《中華人民共和國土壤污染防治法》的頒布與執行,土壤污染現狀的調查工作變得越來越重要,而農用地土壤是食品安全的第一道關口,因而需要加強對農用地的監管工作。但是傳統的土壤重金屬監測方法需要耗費大量時間、人工成本,具有高成本、低效率、不能大范圍進行快速檢測的特點。利用光譜及各類其他因子進行重金屬濃度快速反演的方法應運而生,這種方法具有高效、快速、無損、無害、可重復、成本低、尺度大的優點。利用光譜特征來擬合區域重金屬污染空間分布的研究已經成為熱點,常用的方法有最小二乘法回歸、偏最小二乘回歸、逐步回歸、支持向量機、隨機森林等,但是對于線性模型的使用主要以全局模型為主,局部模型擬合的研究很少[1-3]。
沈強等[4]通過對光譜曲線進行連續去除和一階微分預處理,選擇合適的高光譜數據進行逐步回歸,建立了對礦業廢棄地土壤重金屬含量進行高光譜反演的模型;張秋霞等[5]利用偏最小二乘模型對高標準基本農田區域重金屬含量進行高光譜反演,其模型決定系數達到了0.70~0.99,獲得了極好的反演效果;陶超等[6]利用支持向量機模型對土壤重金屬鉛、鋅進行高光譜反演,取得了較好的模型精度;徐良驥等[7]采用逐步回歸、偏最小二乘回歸、人工神經網絡的方法分別對煤矸石充填復墾重構土壤中重金屬含量進行高光譜反演,發現人工神經網絡模型取得了最好的建模效果。可見,對重金屬濃度反演所用到的主要為高光譜遙感影像,而Landsat-8因為數據源的開放性,使用更加普遍,利用Landsat-8進行反演重金屬的研究已經取得了一定的研究成果。王海瀟等[8]利用DEM數據對Landsat-8影像進行地形校正,然后利用校正后的反射率變換作為變量,利用PLSR模型進行建模反演重金屬Cu含量,模型決定系數達到0.52,有較好建模效果;方媛[9]利用多時相Landsat-8影像,使用偏最小二乘回歸、人工神經網絡、支持向量機模型進行無偏評價與選擇,發現偏最小二乘模型在土壤重金屬反演中表現最佳,并利用該模型對Cu、As、Cr含量進行反演。
綜上所述,對于土壤中重金屬濃度的反演主要考慮光譜特征,很少考慮樣品采集點的空間位置及地形信息。因此,本研究綜合考慮光譜變換信息、采樣點空間位置信息、地形信息等,選用逐步回歸和地理加權回歸,實現土壤中重金屬鎳含量的快速、精確反演,同時為以后的研究提供新的思路。
1 研究區域概況
研究區石寶溝位于欒川縣石廟鎮,地理范圍為111°31′9.47″E至111°33′6.47″E,33°48′53.76″N至33°51′50.21″N之間,面積為3 km2。農用地污染土壤采樣范圍為0.50 km2,污染地塊主要分布在石寶溝及銀洞溝,呈條帶狀分布于石寶路兩側。調查區北至石寶溝三岔口,南至石寶溝溝口,與伊河河谷相接。研究區交通便利,有S328省道(欒川縣城至石廟鎮),區內主干道路為石寶溝道路。研究區位于北至馬超營斷裂和南達欒川斷裂之間的異常區,該異常區呈現為狹長的帶狀形態,屬于盧氏—欒川鉬、鎢、鉛、鋅、銀金地球化學異常帶,其中廣泛發育的元素有Mo、Ag、Pb、Zn、Au、W、Cu、Mn、Ni等。沿馬超營斷裂帶,形成Au、Ag、Pb、Zn、Mo、Bi多元素的綜合異常帶,Ag、Pb、Zn元素異常套合較好。不同類型的巖體與巖體的不同部位分別形成鉬、鎢、銀、鉛、鋅、鐵、銅、鋅、硫、金礦等,構成一個完整的成礦系列[10-16]。
本研究區成礦地質條件極為優越,存在豐富的礦產資源,但是由于歷史原因,曾經有多達24個采礦權,無序開采嚴重,礦產開采過程中長期存在大礦小開、一礦多家分塊開采現象,資源利用效率低,并且不可避免地對研究區域內農用地產生污染,導致該區域農用地重金屬含量異常。
2 數據來源及研究方法
2.1 數據來源及處理
本研究根據石寶溝和銀洞溝農用地土壤分布特點,以自然分割的地塊劃分調查采樣區[17-18]。采樣田塊共計60個,每個地塊構成一個單獨的采樣區,每個采樣區劃分若干個采樣單元,采用1∶1 000田塊測量成果圖對采樣區進行網格化剖分。在石寶溝主溝、支溝銀洞溝、支溝倒回溝溝口農用地土壤污染區共布設表層土壤樣點277個。將采集的樣品依據土壤環境監測技術規范樣品流轉的要求,運輸至實驗室進行鎳濃度的化驗分析。采用的分析方法為石墨爐原子吸收分光光度法。地塊劃分及檢測結果如圖1所示。

圖1 研究區農用地Ni空間分布
本研究采樣時間為2018年7月末至8月中旬,從美國地質調查局網站(www.usgs.gov)下載了研究區2018年8月的Landsat-8影像,并利用ENVI 5.3對圖像進行預處理,包括輻射定標與大氣校正。利用BIGMAP下載了研究區1 m×1 m的DEM數據,該數據精度較高,用于計算坡度、坡向等地形因子。
2.2 研究方法
土壤的反射光譜包含了豐富的土壤信息,是土壤形狀的綜合反映,在近紅外波段范圍(700~1 000 nm)內,土壤光譜的吸收特性主要是由于金屬離子的電子躍遷形成;而在短波紅外區域(1 000~3 000 nm),土壤的吸收主要是由于有機質、碳酸鹽、層狀硅酸鹽等礦物的各類分子團中化學鍵的彎曲、伸展、變形等振動造成。重金屬元素在土壤中通常存在多種化學形態,不同的形態具有不同的敏感光譜特征。通過多波段的組合運算,將不同波段的光譜信息進行相互補充,使得組合后結果與重金屬元素濃度的相關系數顯著高于單一波段[19-23]。
本研究通過提取研究區域農用地的可見光-近紅外-短波紅外的波段信息,并進行一定的波段組合運算,結合地形因子、與污染企業的空間位置距離因子等,選擇不造成明顯多重共線性的解釋因子,使用地理加權回歸的方式進行建模,并對所建模型進行評估,最終對整個研究區域進行重金屬鎳反演,評價其空間分布特征。技術流程見圖2。

圖2 技術流程圖
1)變量選取。首先,利用Landsat-8遙感影像提取研究區農用地的各種植被指數作為因子,包括歸一化植被指數(NDVI)、綠色歸一化植被指數(GNDVI)、比值植被指數(RVI)、增強型植被指數(RVI)等共計9種;其次,對Landsat-8影像的7個波段進行不同方式的波段運算,包括對波段取對數,開根號,任意2個波段之間的加、減、乘、除運算,以及任意3個波段之間的加、乘運算等;然后,考慮到研究區多年礦產背景,農用地中重金屬可能來源于企業排放廢氣的大氣沉降作用、尾礦庫泄露等,利用ArcGIS及DEM數據提取采樣點的高程、坡度、坡向、地面曲率因子、剖面曲率因子、平面曲率因子、坡度變率因子以及坡向變率因子等地形因子;最后,利用ArcGIS的近鄰分析工具,分別計算每一個采樣點與尾礦庫、礦產加工企業以及主干線(石寶路)的最近距離,將結果作為分析因子。
綜上,本研究共獲取的自變量因子有243個,計算每一種因子與鎳濃度的皮爾遜相關性系數,篩選出顯著性水平α=0.01的變量因子33個。
2)OLS模型。OLS模型利用n組觀察值求得p個獨立變量與因變量之間殘差平方和最小的擬合方法是一種利用n組觀測值,使得p個獨立變量與因變量之間的殘差平方和取得最小的擬合方法。計算方法如式(1)所示。
(1)
式中:Y是農用地土壤中重金屬鎳的濃度;βi為未知的模型擬合參數;p是用于建模的變量個數;ε為模型的殘差項,服從正態分布N(0,σ2)。通過矩陣方程的方式進行估計,如式(2)所示。
(2)
逐步回歸是指將所有自變量按其對因變量的影響程度從大到小排序,把通過了偏F統計量檢驗的自變量逐個引入回歸方程;同時,對已引入的變量進行檢驗,若未通過檢驗則剔除,直到既不能引入新變量也不能剔除已有變量為止。
3)空間自相關。空間自相關是進行地理加權回歸分析的前提條件,一般用于描述某一區域的樣本觀測數據與其他區域的樣本觀測數據之間的相互依賴程度,常用來確定數據間是否具有依賴性的指數為全局莫蘭指數(global Moran’S I)。
4)地理加權回歸。地理加權回歸(geographic weighted regression,GWR)模型是對傳統線性回歸模型的擴展,通過把數據的位置信息通過權重的方式嵌入到回歸參數來反映數據在空間上的關系差異,其實質是一種局部加權最小二乘法。基本的GWR模型表達如式(3)所示。
(3)
式中:i=1,2,3,…,n;(μi,υi)為第i個樣本數據的位置;γn(μi,vi)為第i個樣本數據中的第n個估計參數,是能夠反映不同地理位置的函數項;γ0(μi,υi)為估計方程的常數項;δin為第i個樣本數據的第n項解釋變量;δi~N(0,σ2);Cov(εi,εj)=0(i≠j)。選擇一個合適的最優帶寬是構建高質量GWR模型的關鍵。通過對比驗證,本文使用固定距離法構成核函數,并選擇最小信息準則AIC指標來決定最優帶寬(式(4))。
(4)

5)模型擬合度評估。建立模型后,對測試集數據應用模型,計算應用平均誤差(mean error,ME)、平均絕對誤差(mean absolute error,MAE)、均方根誤差(root mean square error,RMSE)和預測精度(accuracy,Acc)對模型進行精度評價。ME衡量模型預測偏移程度,該值越接近于0,偏移程度越小;MAE和RMSE是衡量模型估算精度的指標,該值越小,模型精度越高;Acc是描述模型預測精度更直觀的指標,越接近于1,模型預測能力越好。
3 模型構建與評估
3.1 OLS模型
從所有277個檢測數據中隨機抽取75%(207組)的數據作為建模組,將剩余25%(70組)的數據作為驗證組。
設定自變量進入模型的顯著性水平SLE=0.1,保留在模型中的顯著性水平SLS=0.05,通過逐步回歸的方法最終選出采樣點與廠區的最短距離、ln(band2/band3)、band3-band5為基礎變量的模型。
模型計算的方程分析見表1,回歸模型的系數、顯著性及共線性診斷見表2。可見,農用地土壤中鎳含量與尾礦庫、工礦企業等有關,所建立的模型中所有的變量因子顯著性檢驗均小于0.01,并且VIF值小于10,說明變量因子之間不存在嚴重的多重共線性。此外,模型決定系數(R2)達到0.325,在一定程度上已達到統計模型所需的基本要求,但是仍然偏低。

表1 方差分析表

表2 OLS回歸模型系數、顯著性及共線性診斷
3.2 空間自相關分析
利用ArcGIS的空間自相關分析工具,計算研究區用于建模樣本的局部莫蘭指數,計算結果見表3。由莫蘭指數可知,本研究區重金屬鎳濃度呈空間正相關,根據Z得分可認為該區域空間顯著相關。此外,通過顯著性水平α=1的顯著性檢驗得知,本研究區呈現顯著空間自相關,GWR模型適用。

表3 全局空間自相關分析結果表
3.3 GWR模型
采用與礦產加工企業廠區最短距離、ln(band2/band3)、band3-band5作為模型的解釋變量,以高斯函數為核函數,選擇使AIC值取得最小值的帶寬為模型的最終帶寬,帶寬為460.97 m。在這個帶寬范圍內,每個樣點平均有25個相鄰樣點參與建模,模型統計數據如表4所示,模型決定系數達到0.64,取得較好的擬合效果。

表4 GWR模型統計結果
GWR模型獲取了每一個樣品點的回歸模型,其系數的統計結果見表5。根據ArcGIS官方介紹,所計算模型的條件數如果大于30,表示存在多重共線性。由表5可知,本研究建立的模型不存在大于30的條件數,故本模型不存在明顯的多重共線性。

表5 GWR模型條件數及各變量系數的統計特征
3.4 模型評估
將277個樣本點數據中的驗證組數據進行驗證,并計算ME、MAE、RMSE、Acc值,計算結果見表6,2種模型驗證結果的殘差分布見圖3。通過對比可以發現,利用地理加權回歸模型GWR,明顯可以獲得更好的擬合效果,其MAE和RMSE計算結果均較低,而且Acc計算結果顯示模型預測精度達到了96.51%。另一方面,從殘差分布圖(圖4)也可以看出,GWR的殘差分布更加集中,并更接近于0。

表6 模型評估結果

圖3 OLS模型反演效果圖
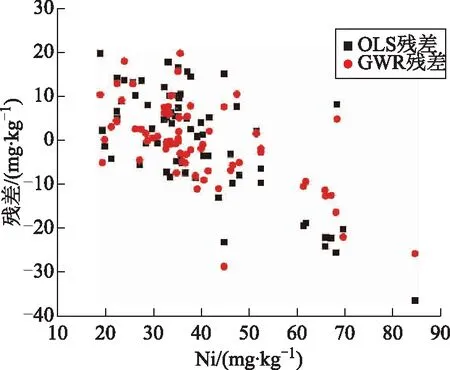
圖4 2種模型擬合研究區驗證樣本鎳濃度的殘差分布
4 反演
利用所建立的模型,對整個研究區農用地進行了反演。利用OLS模型反演的結果見圖3,利用GWR模型反演結果見圖5,2種模型反演結果的統計特征見表7。
由表7可知,利用OLS模型反演的結果,重金屬鎳含量范圍在20.80~62.03 mg/kg,GWR模型反演的結果中金屬鎳含量范圍在19.61~66.99 mg/kg之間。實際采樣檢測數據中,重金屬鎳含量范圍在12.36~124.00 mg/kg之間,范圍大的主要原因在于研究區內所采集樣品中存在少數偏高的離群點。例如研究區偏南側2個地塊,其周圍重金屬鎳含量均屬正常狀態,只有它們的濃度存在異常(其鎳含量分別為124 mg/kg、60.9 mg/kg),原因可能在于這2個地塊位于企業周邊(欒川縣天罡礦業有限公司),受到了該企業的影響,或者是由于該地塊采集樣品的例外性導致了值的異常。而OLS模型和GWR模型均無法對孤立的異常點進行反演。分別比較OLS模型分位數與實測值分位數之間的差異、GWR模型分位數與實測值分位數之間的差異,可見GWR分位數之間的差距更加小,說明了GWR模型的可靠性。

圖5 GWR模型反演效果圖

表7 全局實測值及各模型計算結果統計特征
由圖1、圖3(a)、圖5(a)可見,研究區中部偏北區域重金屬含量均較高。細節見圖3(b)、圖5(b)。該區域重金屬濃度的統計信息見表8。該區域實測值濃度的范圍為12.36~84.47 mg/kg,OLS模型模擬計算的結果范圍為36.52~60.13 mg/kg,而GWR模型模擬計算的結果范圍為39.46~66.99 mg/kg,對于最大值和最小值的模擬效果較差;中間各分位數與平均值相比較而言,GWR取得更好的模擬效果。總之,GWR模型的計算結果可以真實反映該區域重金屬濃度的異常狀況,該區域重金屬濃度異常的原因可能與上游存在的大型礦產加工企業鑫川化工的生產經營活動有關。
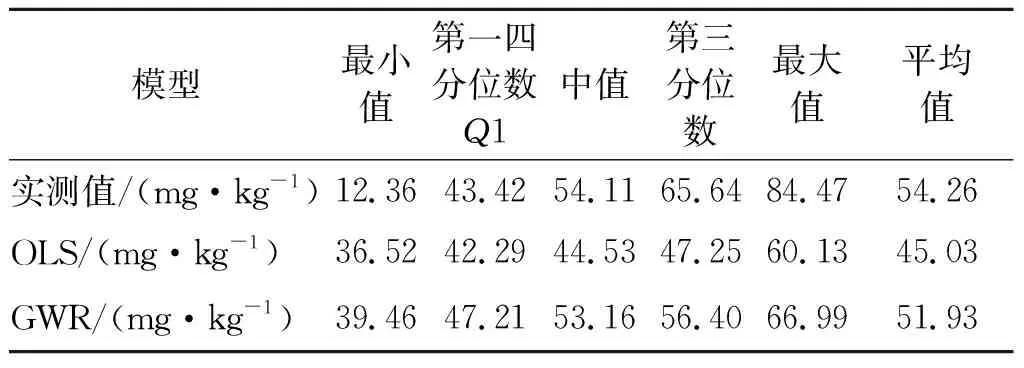
表8 研究區中部偏北區域實測值及各模型計算結果統計特征
綜上,本研究在研究區范圍內選取了一些未進行實際采樣的區域進行2種模型的反演,結果發現倒回溝西側區域重金屬鎳含量較高(圖3(c)、圖5(c))。通過對該區域模型反演結果進行統計特征分析(表9)發現,GWR模型反演濃度范圍為29.73~49.57 mg/kg,該區域平均值為41.66 mg/kg,含量高于整體的平均值,其主要原因與該區域歷史上存在尾礦庫有關。該區域農田為尾礦庫復填重構土壤,土壤中重金屬鎳濃度與其他區域相比存在異常。

表9 倒回溝西側區域各模型反演結果統計特征
5 結束語
本研究通過將采樣點與礦產加工企業的最短距離、ln(band2/band3)、band3-band5作為基礎變量,以欒川縣石寶溝農用地土壤實際檢測重金屬鎳濃度作為目標變量,分別使用逐步回歸與地理加權回歸的方法進行模型擬合(模型決定因子分別達到了0.325和0.64),之后利用建立模型前隨機抽取的驗證樣本對模型進行了驗證。經過計算,Acc值分別為72.88%和96.51%。綜合比較,使用GWR模型獲得了更加優秀的擬合效果。
通過對整個研究區所有農用地鎳含量的空間分布應用2種模型進行反演,并與實測值進行對比,進一步發現GWR模型的有效性較佳,估算結果與實際情況吻合良好。
對于無實測值區域,通過反演發現,倒回溝西側區域重金屬鎳含量異常,其原因和該區域用地歷史有關。該區域曾經存在礦產加工企業,同時部分農用地為尾礦庫復墾重構所得。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
光學精密工程(2016年6期)2016-11-07 09:07:19
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
