遼代歷史文化資源知識圖譜構建研究
2021-04-01 07:04:56譚楠楠
大連民族大學學報 2021年1期
劉 爽,譚楠楠,楊 輝
(大連民族大學 計算機科學與工程學院,遼寧 大連116650)
隨著語義網的發(fā)展,目前互聯(lián)網上發(fā)布越來越多的結構化數(shù)據(jù)、半結構化數(shù)據(jù)、非結構化數(shù)據(jù),并將其作為鏈接數(shù)據(jù)發(fā)布。在此背景下,Google在2012年提出知識圖譜(Knowledge Graph)這一概念,旨在改善搜索引擎效果[1]。知識圖譜以結構化三元組的形式來進行存儲,基本組成單位由頭實體、尾實體以及描述這兩實體之間的關系組成。通用表示方式為G=(E,R,S),其中E={e1,e2,e3…,e|E|}表示實體集合,R={r1,r2,r3…,r|R|}表示關系集合,S?E×R×E表示知識圖譜中的三元組集合。目前對知識圖譜的研究應用主要分為通用領域知識圖譜和垂直領域知識圖譜。典型的中文通用領域知識圖譜有CN-DBpedia[2]、zhishi.me[3]、Ownthink[4]、XLore[5]等。上述通用領域知識圖譜雖收集了大量的領域知識,但無法深入對某一領域內的知識進行詳細描述。垂直領域知識圖譜在這方面的優(yōu)勢大于通用領域知識圖譜,但是該領域知識圖譜構建通常采用手工構建,需要消耗大量的人力財力。
經過調查發(fā)現(xiàn),現(xiàn)有通用領域知識圖譜中含有部分關于遼代歷史文化資源相關的內容,但是現(xiàn)有知識圖譜從規(guī)模化、規(guī)范化、形式化等方面任有很大的提升空間[6]。目前垂直領域中關于遼代歷史文化資源的知識圖譜還沒有,如何基于高效的知識工程方法以及先進的文本數(shù)據(jù)挖掘技術,構建大規(guī)模、高質量的遼代歷史知識圖譜,仍是極具挑戰(zhàn)性的課題。
本文初步探討了遼代歷史領域知識圖譜當前面臨的機遇和挑戰(zhàn),從新的領域知識圖譜角度提出了遼代歷史領域知識圖譜構建技術。針對遼代歷史領域的特點對知識各個環(huán)節(jié)的關鍵技術流程進行專項研究,利用自然語言處理、文本數(shù)據(jù)挖掘技術和知識抽取、知識融合等知識圖譜構建技術,采用人機結合的方式構建了遼代歷史文化資源知識圖譜。
1 相關研究
命名實體識別(Named Entity Recognition,NER),又稱作“專名識別”,是指識別文本中具有特定意義的實體,主要包括人名、地名、機構名、專有名詞等。簡單的講,就是識別自然文本中的實體指稱的邊界和類別[7]。目前命名實體識別的主要技術方法分為:基于規(guī)則和詞典的方法、基于統(tǒng)計的方法、基于神經網絡的方法等。其中基于規(guī)則的方法多采用語言學專家手工構造規(guī)則模板,選用特征包括統(tǒng)計信息、標點符號、關鍵字、指示詞和方向詞、中心詞等方法,以模式和字符串相匹配為主要手段,這類系統(tǒng)大多依賴于知識庫和詞典的建立。基于統(tǒng)計機器學習方法將NER視作序列標注任務,利用大規(guī)模語料來學習出標注模型,從而對句子的各個位置進行標注。常用的方法主要包括:隱馬爾可夫模型[8](HMM)、最大熵[9](ME)、支持向量機[10](SVM)、條件隨機場[11](CRF)。基于神經網絡的方法在硬件能力的發(fā)展以及詞的分布式表示(word embedding)的出現(xiàn),成為可以有效處理許多NLP任務的模型。其中主要模型有CNN-CRF、RNN-CRF、LSTM-CRF等。
隨著互聯(lián)網技術的高速發(fā)展,人們在對通用領域數(shù)據(jù)進行實體抽取的同時開始關注垂直領域的實體抽取,然而垂直領域的數(shù)據(jù)文本有其自身的特點,進行實體抽取時需考慮其自身特點[12]。
在命名實體識別的工作中,主要分為基于規(guī)則的方法、基于統(tǒng)計機器學習的方法和基于神經網絡的方法。其中常見的基于統(tǒng)計機器學習的模型主要有隱馬爾可夫模型、最大熵模型、支持向量機和條件隨機場等。然而,這些方法在進行特征提取時需要人工進行完成。同時在模型訓練方面需要大量的人工標注樣本,并且效果不明顯[13]。
基于神經網絡的方法在命名實體識別任務中通常被當作序列標注任務,通過建立序列標注模型對文本進行實體識別。2011年Collobert[14]等采用卷積神經網絡(CNN)進行特征提取,同時通過融合其他特征效果上取得不錯的識別效果。丁晟春[15]等人針對網絡公開平臺上的多源異構的企業(yè)數(shù)據(jù)的散亂、無序、碎片化問題,提出Bi-LSTM-CRF深度學習模型進行商業(yè)領域中的命名實體識別工作。何春輝[16]等人利用電子文檔在糖尿病領域中取得了較好的應用,實驗結果表明該模型在包含15種實體類別的數(shù)據(jù)集上準確率達到了89.14%。李永苗[17]利用BiLSTM網絡對中文電子病歷中的實體進行提取,構建出了中文電子病歷知識圖譜。Feng[18]等提出了一種基于BiLSTM的神經網絡結構的命名實體識別方法。買買提阿依甫[19]等人根據(jù)維吾爾語的特點,提出了BiLSTM-CNN-CRF模型。李麗雙[20]等人將CNN-BiLSTM-CRF模型應用在生物醫(yī)學語料上,獲得了當時最高F1值。柳潤杰[21]通過使用BiLSTM-CRF模型將《二十四史》中的人名、地名、時間等實體識別后,在此基礎上構建了《二十四史》知識圖譜。
本文在進行遼代歷史文化實體識別中將使用BiLSTM-CRF的深度神經網絡模型。首先將輸入的詞由one-hot向量映射為低維稠密的字向量(character embedding),然后將得到的字向量序列作為輸入傳入到BiLSTM神經網絡模型中進行實體識別,然后CRF模型將會對BiLSTM模型輸出的結果進行解碼操作,得到一個最優(yōu)標記序列,最后得到識別的實體信息。
2 遼代歷史文化知識圖譜整體構建方案
目前關于遼代歷史文化知識圖譜還未出現(xiàn)。因此本文定位于遼代歷史文化知識圖譜工程構建研究,旨在介紹我們開發(fā)的遼代歷史文化知識圖譜,其構建過程主要包括本體構建、知識抽取、知識融合等步驟。本體定義了遼代知識圖譜構建中所需要的實體及關系類型。基于本體對結構化數(shù)據(jù)、非結構化數(shù)據(jù)進行處理后存儲于Neo4j圖數(shù)據(jù)庫中。遼代歷史知識圖譜構建流程圖如圖1。
在遼代歷史文化知識圖譜的構建過程中,本文中知識圖譜構建所有數(shù)據(jù)類型包括結構化數(shù)據(jù)、半結構化數(shù)據(jù)和非結構化數(shù)據(jù),其中結構化數(shù)據(jù)來自網絡上通用領域百科知識圖譜中的數(shù)據(jù),本文中所有的通用領域知識圖譜為Ownthink及CN-DBpedia;半結構化數(shù)據(jù)主要來自百度百科、互動百科,針對半結構化數(shù)據(jù)通過使用包裝器來進行獲取,其中包裝器的生成方法有三大類:手工方法、包裝器歸納方法和自動抽取方法。本文主要使用手工方法,通過人工分析構建包裝器信息抽取的規(guī)則,以此來獲取網頁中的半結構化數(shù)據(jù);針對非結構化數(shù)據(jù)來自互聯(lián)網上關于遼代歷史相關網頁數(shù)據(jù),通過使用網絡爬蟲技術進行獲取大量的遼代歷史網頁文本數(shù)據(jù),然后在將獲得的網頁文本數(shù)據(jù)進行處理。處理過程主要通過增量迭代的方式逐步擴大知識規(guī)則。遼代歷史的非結構化數(shù)據(jù)主要包括網頁文章、史料書籍等,適合采用基于深度學習的有監(jiān)督方法。
通過上述技術手段大大的提升了遼代歷史知識圖譜構建的自動化程度。但作為一個遼代歷史知識圖譜,不僅要確保構建圖譜信息來源真實性和可靠性,還要保證知識來源的充分性。針對后者,充分利用現(xiàn)有知識庫中關于遼代歷史信息對其進行補充,通過抽取現(xiàn)有知識庫中與遼代歷史相關的三元組信息來充實本文中使用方法構建的知識圖譜,以保證有足夠多的數(shù)據(jù)量。
在數(shù)據(jù)處理過程中,充分使用中文分詞工具jieba分詞、正則表達式;在知識抽取過程中通過命名實體識別、關系抽取來獲取文本數(shù)據(jù)中的實體和關系,在進行命名實體部分本文采用BiLSTM-CRF神經網絡模型來進行抽取非結構化文本數(shù)據(jù)中的實體;在關系抽取過程中,使用網絡上集成的關系抽取工具DeepDive進行抽取文本的實體與實體之間的關系,從而構建知識圖譜所需要的三元組數(shù)據(jù)。在知識抽取和數(shù)據(jù)整合完成后,在對不同來源的同一實體進行對齊、合并的操作,最后獲得質量較高的三元組數(shù)據(jù),通過LOAD 語句存入Neo4j數(shù)據(jù)庫。

圖1 遼代歷史文化知識圖譜構建流程
3 遼代歷史文化知識抽取
3.1 模型整體框架
本文的BiLSTM- CRF模型框架如圖2。BiLSTM- CRF模型由三部分組成:第一部分輸入層,第二部分隱藏層,第三部分是標注層。其過程如下:首先將輸入的詞由one-hot向量映射為低維稠密的字向量,然后將得到的字向量序列作為輸入傳入到BiLSTM神經網絡模型中進行實體識別,最后CRF模型將會對BiLSTM模型輸出的結果進行解碼操作,得到一個最優(yōu)標記序列。
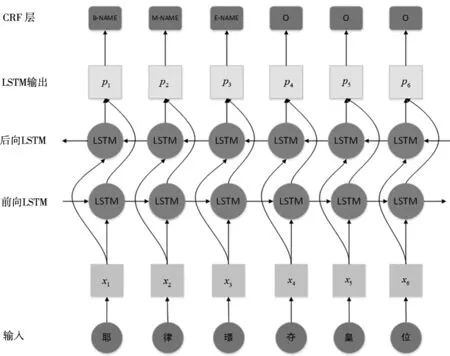
圖2 遼代歷史文化實體識別模型
3.2 BiLSTM 模塊
循環(huán)神經網絡(RNN)是神經網絡中一類重要的結構,從理論上來說,RNN可以動態(tài)的捕獲序列數(shù)據(jù)信息,但是在實際使用過程中容易出現(xiàn)梯度消失和梯度爆炸等問題,長短期記憶網絡[22](LSTM)可以很好的解決這類問題。對于命名實體識別來說,由于需要識別的實體句子分布位置不同,其文本中的上下文信息的重要程度也不同。為了更好的利用上下文中的信息,本文采用雙向LSTM結構進行模型訓練。
3.2.1 LSTM單元
LSTM是RNN的變體,旨在解決這些梯度消失的問題。基本上,一個LSTM單元由三個乘法門組成,這些門控制信息遺忘和傳遞給下一時間步驟的信息比例。這些門控單元為輸入門(Input Gate)、遺忘門(Forget Gate)、輸出門(Output Gate)。LSTM單元的基本結構如圖3。

圖3 LSTM網絡結構
其LSTM單元在t時刻更新公式如下:
it=σ(Wiht-1+Uixt+bi),
(1)
ft=σ(Wfht-1+Ufxt+bf),
(2)
(3)
(4)
ot=σ(Woht-1+Uoxt+bo),
(5)
ht=ot⊙tanh(ct)
。(6)

3.2.2 BiLSTM


圖4 BiLSTM網絡結構圖
3.3 CRF模塊
條件隨機場是一種概率無向圖模型[23],同時是序列標注任務中較為常見的一種算法,可以用于實體類別的標注。本文將CRF層作為神經網絡結構的最后一層,對BiLSTM模塊輸出的結果進行處理,獲得最優(yōu)的全局最優(yōu)標簽序列。
對于一個給定的文本,用X=(x1,x2,x3…xn)表示輸入句子,用y=(y1,y2,y3…yn)表示輸出標簽序列,那么該標簽序列得分為
(7)
式中:A轉移分數(shù)矩陣;Ai,j表示從標簽i轉移到標簽j的分數(shù)。
對所有可能的序列路徑進行歸一化處理,產生輸出序列y的概率分布,如
(8)
在訓練過程中,最大化關于正確標簽序列的對數(shù)概率如

(9)
式中,YX是對于輸入句子X的所有可能標簽序列。
在最終進行解碼時,選擇預測總分最高的序列作為最優(yōu)序列,公式為
(10)
4 實驗及結果分析
4.1 實驗數(shù)據(jù)準備
由于目前網上公開的數(shù)據(jù)集中缺乏關于遼代歷史文化的相關數(shù)據(jù),因此本文使用的數(shù)據(jù)集由10萬字左右的遼代歷史文化相關文本構成。通過爬蟲獲取網上相關文本數(shù)據(jù),然后將獲取的語料已經進行分詞、去停用詞等處理,對語料進行了人名、地名、時間、朝代等信息進行了實體標注。
監(jiān)督學習方式的主要標注模型包括BIO、BIEO、BMESO等,為了能夠清楚的表示語料中待識別的命名實體,本文在自建數(shù)據(jù)集采用BIO標記法進行標注。對于每個實體,將其第一個字標記為“B-(實體名稱)”,中間字標記為“I-(實體名稱)”,對于非實體標記為“O”,見表1。
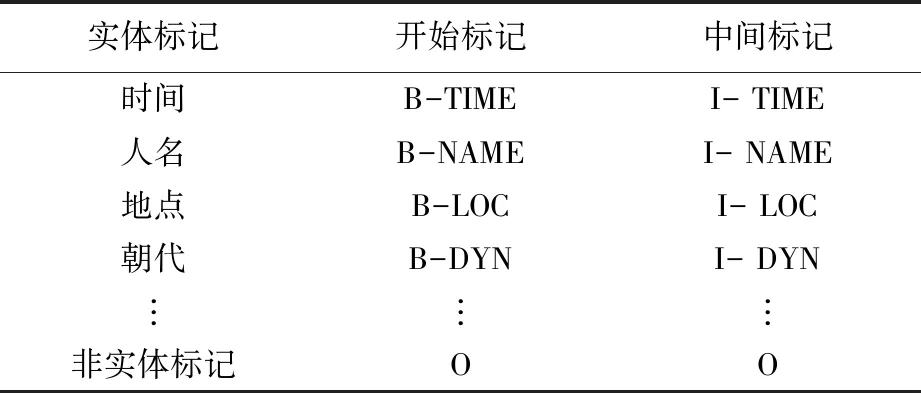
表1 BIO標注策略
使用BIO標注策略對給定的遼代歷史文化文本進行實體標注示例見表2。

表2 歷史文化文本命名實體標注示例
本實驗采用準確率P(Precision)、召回率R(Recall)以及F1值對模型進行評價。具體公式如下:
(11)
(12)
(13)
其中TP表示被判定為正樣本,實際預測也為正樣本,即判斷為正例的正確率;TN表示判定為負樣本,實際預測也為負樣本,即被正確預測的負例;FP表示判定為正樣本,實際預測為負樣本,即把負樣本判斷成了正樣本的誤報率;FN表示判定為負樣本,實際預測也為正樣本,即把正樣本判斷成負樣本的漏報率。
4.3 實驗環(huán)境
所有實驗采用的環(huán)境見表3。

表3 實驗環(huán)境
4.4 參數(shù)設置
本文所提及模型采用TensorFlow框架進行搭建,具體實驗參數(shù)設置見表4。

表4 實驗參數(shù)分
通過對學習率與迭代次數(shù)的調整,提升了模型的訓練精度和模型的泛化能力。
4.5 實驗結果
為了驗證本文方法的識別效果,分別采用CRF、BiLSTM、BiLSTM-CRF方法對自己構建的數(shù)據(jù)集進行命名實體識別。
(1)條件隨機場CRF。采用條件隨機場開源工具CRF++工具包,本文實驗所使用的版本為CRF++0.58,通過建立模型從而實現(xiàn)實體識別。
(2)BiLSTM。采用雙向LSTM神經網絡模型在自建數(shù)據(jù)集上進行實體識別。
(3)BiLSTM-CRF。采用雙向LSTM-CRF神經網絡模型在自建數(shù)據(jù)集上進行實體識別。
上述實驗對比結果見表5。

表5 實驗結果對比 /%
從表5中的實驗結果可以看出,在CRF模型和基于神經網絡的模型比較的過程中,基于神經網絡的模型在各個方面的性能都優(yōu)于CRF模型;在BiLSTM和BiLSTM-CRF模型的比較中可以看出,在添加了CRF進行序列標注的BiLSTM-CRF模型在各方面的效果都優(yōu)于BiLSTM,這說明CRF在進行解碼的過程中考慮到了全局的標簽信息,提升了模型的性能,在自建數(shù)據(jù)集上識別實體的效果相對較好,可以很大程度上識別出需要的三元組信息中的實體。
因此可以確定本文實驗中所使用BiLSTM-CRF模型可以較好的提取文本數(shù)據(jù)中的實體,達到構建知識圖譜的要求。
5 知識圖譜可視化展示
將獲取的遼代歷史文化知識圖譜的實體和關系采用Neo4j數(shù)據(jù)庫進行存儲,其中獲取的有朝代、帝王名稱、首都等,關系有主要國家、主要語言,所屬時期等,最后存儲的部分結果展示如圖5-圖6。

圖5 遼代部分知識圖譜可視化效果圖
圖6 歷史知識圖譜可視化查詢效果圖
6 結 語
本文提出了一種遼代歷史文化知識圖譜的構建流程,首先介紹了數(shù)據(jù)的獲取,獲取數(shù)據(jù)包括結構化數(shù)據(jù)、半結構化數(shù)據(jù)和非結構化數(shù)據(jù)。然后主要介紹了針對非結構化文本數(shù)據(jù)如何進行知識抽取,提出一種BiLSTM-CRF神經網絡模型進行實體抽取,F(xiàn)1值達到84.55%,根據(jù)實驗結果可知采用BiLSTM-CRF較好的抽取出非結構化文本中的實體。最后根據(jù)得到的實體關系構建知識圖譜三元組,將其存儲到Neo4j數(shù)據(jù)庫中,使用Echarts和Web 編程進行可視化展示。后續(xù)工作中,將會嘗試使用其他網絡模型進行非結構化文本中的實體關系抽取,同時會考慮加入Bert模型,進一步來提升實體識別的效果。同時會在本領域中標注更多的數(shù)據(jù),以此來獲得更好的實體關系抽取結果,保證得到的三元組信息更加可靠。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
全體育(2016年4期)2016-11-02 18:57:28
小學教學參考(2015年20期)2016-01-15 08:44:38
科普童話·百科探秘(2015年6期)2015-10-13 07:21:18
科普童話·百科探秘(2015年8期)2015-08-14 07:13:06
