微處理器下的數字集成電路測試系統設計
2021-04-02 02:13:18李蘇蘇謝玉巧
計算機測量與控制 2021年3期
關鍵詞:故障
鄭 宇,方 嵐,李蘇蘇,謝玉巧
(華東光電集成器件研究所,吉林 吉林 132001)
0 引言
數字集成電路芯片的設計、加工、系統整合方面的技術研究近來發展迅猛,但國內相關工作平臺的設計與實現工作相對滯后。提供一個無需生產環境即可實現對數字集成電路進行相關測試的微處理器嵌入平臺,是本文的研究重點。相關研究中,基于布爾差分法在微處理器的嵌入式控制下,對針對測試碼集合對微處理器進行激勵-反饋測試,是數字集成電路測試系統的主要實現模式。
代鵬(2020)等研究了一二次融合開關技術在數字集成電路測試系統中的應用及相關的電氣細化設計[1]。王玉菡(2020)等研究了相變存儲器單元在高速電流脈沖條件下的數字集成電路測試系統中的應用[2]。開關技術和寄存技術是高頻信號發生的關鍵技術,在對高頻數字集成電路的測試中,測試系統本身的高頻性能必須超過待測試數字集成電路的高頻信號需求且保留一定冗余。田強(2020)等研究了一種基于V58300平臺的數字集成電路測試系統二次開發設計[3]。使用既有數字集成電路測試系統并通過二次開發過程使其潛在性能得到充分開發,也是當前數字集成電路測試平臺開發的重要方向。石君(2020)等及王金萍(2020)分別對數字集成電路測試系統的相關算法[4]和測試方法[5]進行了研究。鄭永豐(2019)等研究了在數字集成電路測試平臺中融入射頻信號發生功能的工程實現方法[6]。
基于上述技術文獻的前期研究,本文基于TL5708-EVM-1000-64GE8GD-I開發板,設計一種可提供750MHz測試頻率環境的數字集成電路測試系統。設計過程介紹如下。
1 數字集成電路的測試原理與可用技術分析
1.1 數字集成電路測試的任務模式
基于測試碼構成的測試集,通過對數字集成電路的輸入激勵獲取其輸出響應,進而判斷數字集成電路的不同故障模式。是當前數字集成電路測試系統的基本測試策略。詳見圖1。
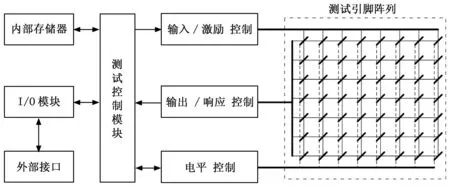
圖1 集成電路測試系統的基本構成策略
圖1中,存儲器用來存儲相關策略和測試集,I/O模塊和外部接口用于連接外部控制設備,主要是桌面級工作站。以上模塊及測試控制模塊即核心開發板均屬于通用模塊,硬件開發壓力較小。測試系統的核心硬件開發任務來自測試引腳陣列及其控制器模塊的開發。詳見圖2。
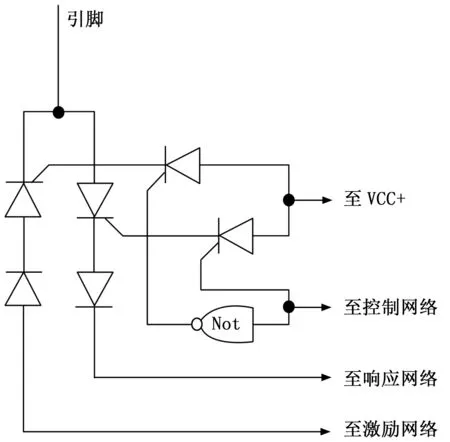
圖2 集成電路測試系統引腳設計圖
圖2中,使用一個非門電路對數據回路的輸入輸出進行晶閘管控制,形成一二次融合開關架構,從而進一步實現引腳的多用途復用。引腳的排列按照ICCC電氣標準進行布局,可以實現對大部分標準封裝數字集成電路的直接插入并進行引腳定義。
1.2 數字集成電路測試的布爾差分算法
對所有通過測試集可以測出的可測故障(Detectable Fault)編制測試集,且保持測試集的冗余度,分析所有可測故障的控制性,及所有測試集的相互包含和交集關系。最終構建測試集F(x)。
如果F(x)=F(x1,x2,…,xn)屬于對所有變量有效的邏輯函數,那么其布爾差分定義函數為:
(1)
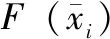
即數據響應錯誤可以向錯誤集傳導,實現對所有可測故障的有效測量控制。
1.3 核心開發板的選型及引腳定義
本文選擇TL5708-EVM-1000-64GE8GD-I開發板進行系統開發,該開發板提供8GByte的eMMC存儲空間,提供1GByte的DDRIII高速動態存儲器,ARM總線頻率1 000 MHz,DSP總線頻率750 MHz,除ARM A15核心處理器(CPU)外,還提供一個SGX544 3D+GC320的浮點處理器(GPU),具有較強的大數據分析處理能力。外部接口方面,支持GPMC拓展鄔。可提供128 pix的DSP同步雙工并行接入。
其中,為了滿足一個32×32點陣的測試引腳陣列的DSP同步掃描,且支持至少32路輸入輸出控制,則應占用至少64 pix的I/O引腳進行掃描管理,至少占用16pix對引腳狀態鎖存器進行管理。同時,還應提供一個4×4鍵盤狀態掃描模塊,需要占用8 pix控制引腳,提供一個對MAX7219八位管控制器的控制功能,需要4 pix控制引腳。系統的擴展存儲通訊在DATA總線上,外部通訊接口通訊在USB3.0總線上。
其引腳定義如表1。
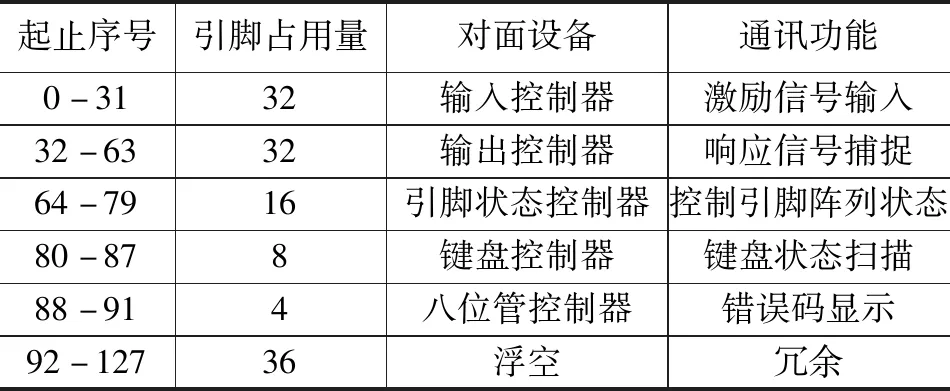
表1 TL5708引腳定義表
表1中,冗余引腳共36 pix,占全部引腳的28.1%。其中主控信號引腳80 pix,占全部引腳的62.5%。
2 數字集成電路測試軟件設計
2.1 軟件基礎算法
如圖3,該數字基層電路測試系統的核心算法,來自其對測試集的順序遍歷和逐一判斷,當發現基于布爾差分算法的正確響應時,直接跳轉下一時鐘循環,順序遍歷下一條測試集數據,而當發現基于布爾差分算法的錯誤響應時,根據其響應結果判斷該可測故障的類型并計入到錯誤信息匯總表中。最終系統會將時鐘循環過程中的錯誤狀態進行一次判斷,當不存在錯誤標志信息時,則直接顯示PASS結果,而當存在錯誤標志信息時,則輸出所有錯誤標志信息。
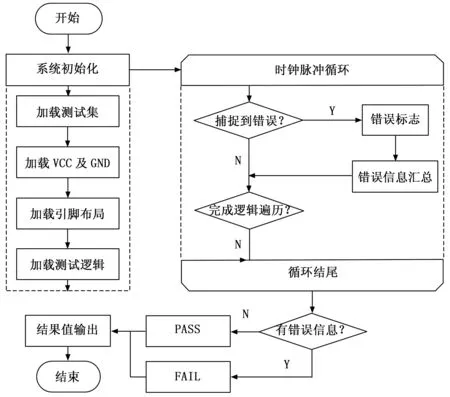
圖3 基于布爾差分算法的數字集成電路軟件設計流程圖
在基礎布爾差分算法的支持下,該軟件實現方式可以實現對大部分可測故障的有效控制測量,但仍存在諸多不足:
首先,對不可測故障的測試存在短板。在單純布爾差分算法下,存在可測故障(Detectable Fault)和不可測故障(Undetectable Fault)的差別,前者指可以通過固定的測試集反饋結果反映出被測試集成電路故障的測試結果,后者指無法通過固定的測試集反饋結果反映出被測試集成電路故障的測試結果。且電氣工程視角下,芯片存在固定故障(Stuck Fault)橋接故障(Bridging Fault)時滯故障(Delay Fault)等,固定故障指某一位輸出值保持電平不可控且不可變的電氣問題,橋接故障指某二位或二位以上的輸出值出現短路表現出電平的非邏輯性的同步變化問題,時滯故障指集成電路的高頻響應能力低于預期使其在高頻狀態下不能做出正確響應的問題。這些故障很難在單純使用布爾差分算法的前提下完成評價。
其次,無法對數字集成電路提出統觀性的評價。傳統測試條件下,較容易實現對出現可測故障的數字集成電路做出評價,但假定該集成電路處于無故障狀態為狀態0,而出現可測故障的狀態為狀態1,那么會有相當一部分集成電路模塊處于介于0與1之間的故障狀態。即該系統無法就不可測故障做出論斷的前提下,較容易出現測試敏感度低,無法發現不穩定故障的系統設計問題。為判斷出系統故障狀態<1的統觀性評價結果,需要在測試軟件中引入機器學習模塊以提供相應判斷功能。
2.2 軟件的機器學習功能實現
針對特定目標集成電路芯片的測試集,在單純布爾差分算法支持下,會輸出一組特定的判斷結果。該結果一般包含3 000~6 000條記錄不等。如果對這些記錄進行統一輸入到模糊神經元網絡中進行判斷,則模糊神經元網絡的節點數量將空前增多,特別是這些記錄的大部分數據處于無故障的判斷結果條件下。所以,在實際構建模糊神經元網絡的過程中,需要引入模糊神經元的概念,先對上述輸出結果進行折疊和歸一化,即對數據進行前置模糊,最終的輸出數據,再進行解模糊輸出,即可判斷出對應的判斷結果。
以6 000條測試數據為例,如果對其進行三維折疊,則可形成一組18×18×19的三維矩陣,對上述矩陣進行歸一化處理后,可以得到一組18×18和一組18×19的歸一化二維矩陣,進一步歸一化后,可得四列分別為18、18、18、19單元的歸一化評價結果,對這些結果進行神經元網絡分析,可以在深度卷積條件下實現對數據的二值化輸出,最終為判斷結果提供待解模糊計算的一組投影在(0,1)區間上的雙精度浮點結果(Double)。詳見圖4。
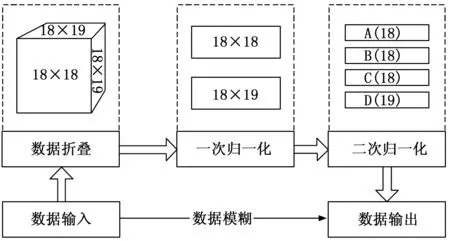
圖4 數據的模糊過程
圖4中,數據歸一化算法的計算過程是首先獲得該列數據的最大值和最小值,根據該列數據的最大值和最小值對每個單元數據求取線性投影,進而將該線性投影值累加,從而得到該列數據的歸一化結果,即:
(2)
式中:數列A的min值與max值與相鄰數列無關,如果該數列中最大值最小值均為0,則輸出值R的輸出值必為0。
鑒于該模糊矩陣,本文模糊神經網絡的設計策略如圖5。
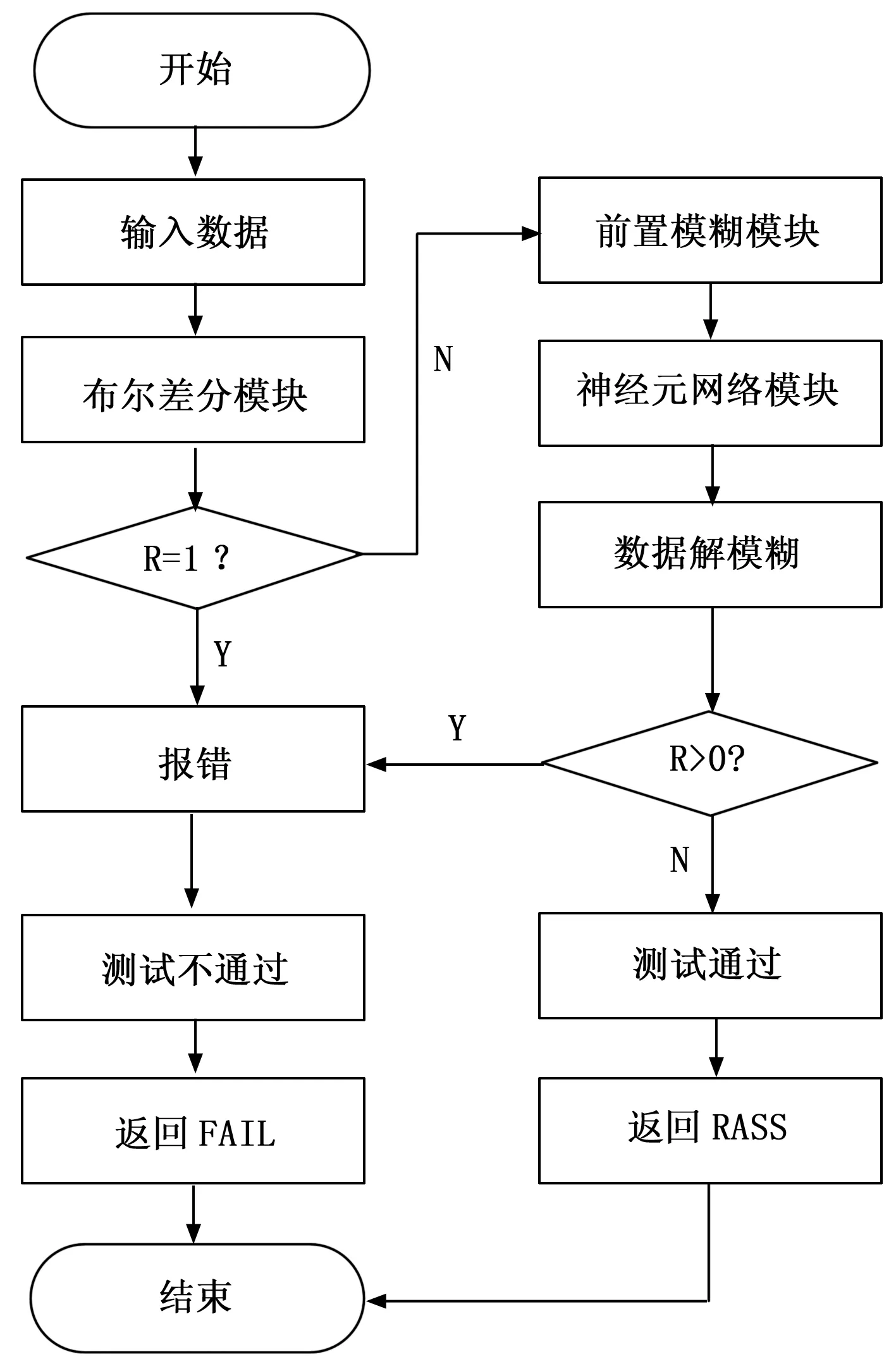
圖5 本文模糊神經元網絡模塊設計示意圖
如圖5中,布爾差分算法模塊詳見圖3,前置模糊模塊詳見圖4,其他模塊將在下文中進行分析。該設計中,當使用布爾差分算法認定為故障芯片時,系統將不再啟動模糊神經元網絡的分析,可以節約大量的計算時間和計算資源。
3 神經元網絡軟件模塊的細部設計
3.1 神經元網絡的卷積策略設計
本文設計的前置模糊策略對輸入數據進行了大幅度壓縮,導致個案中約6 000條數據的數據輸入量被壓縮到A、B、C、D四個數列共73個雙精度浮點變量中,所以,其數據模糊過程屬于典型的熵增耗散過程。該過程使大部分數據實現了歸一化和去量綱化,數據丟失量較大,所以需要對輸入數據進行充分卷積,才可以實現對數據細節的深度挖掘。詳見圖6。
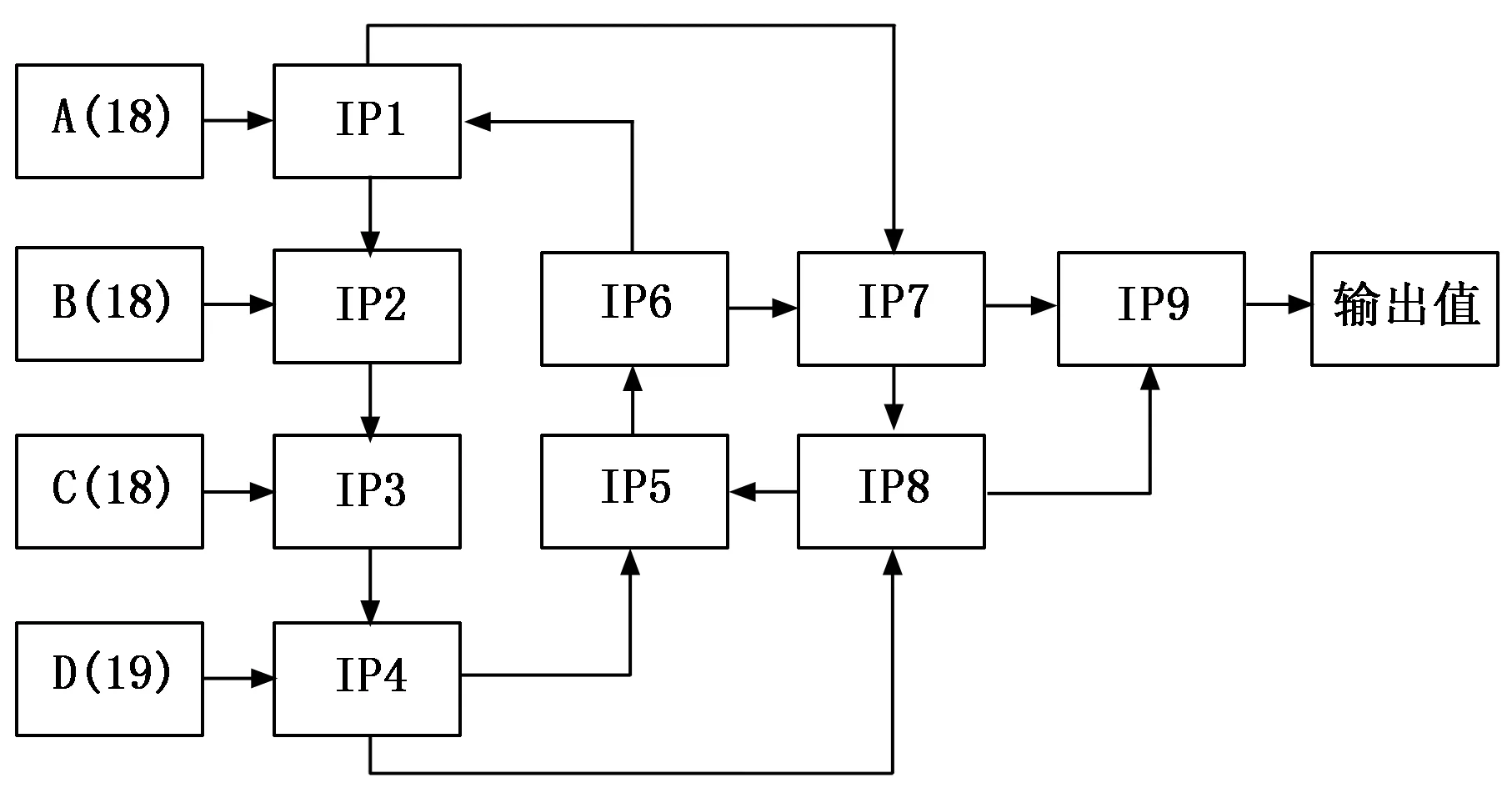
圖6 神經元網絡的卷積模式設計示意圖
圖6中設計了兩個卷積循環,其中神經元網絡模塊IP1-IP6構成第一重卷積循環,IP1負責采集數列A信息,IP2負責采集數列B信息,IP3負責采集數列C信息,IP4負責采集數列D信息,在數據卷積過程中完成信息采集,而在神經元網絡模塊IP5-IP8中進行第二重卷積循環,其中IP7負責整合IP6及IP1的輸出量,IP8負責采集IP7與IP4的輸出量,與IP5和IP6構成卷積循環后,整合IP7與IP8的輸出信息,構建數據輸出模塊IP9,輸出一個二值化數值。
文中,IP1至IP8的神經元模塊隱藏層結構相同,僅輸入層結構因為輸入需求的不同各有不同,其中IP1至IP4的輸入節點數較多,分別為待輸入的18~19個歸一化結果值,均為雙精度變量,外1個卷積值,同樣為雙精度變量。而IP5~IP8均為兩個內部卷積數據的輸入,均為雙精度變量。所有神經元網絡的輸出變量均為1個雙精度變量,需要同步向多個模塊提供數據支持的,將同一個輸出變量值同時分發到對應的模塊中。
該8個神經元模塊的中間層均按照4層設計,分別為23節點、17節點、7節點、3節點,輸出層均為1節點。而IP9神經元模塊采用5層中間層設計,分別為3節點、11節點、23節點、7節點、3節點。
3.2 神經元網絡的節點函數選擇
首選分析神經元模塊IP1-IP8的節點設計方式。在統計學意義上,該8個神經元網絡模塊的統計學意義均為充分挖掘數據細節,使數據細節得到充分展現,故其所有節點均可采用多項式函數進行迭代回歸管理。其節點函數為:
(3)
式中,Xi為輸入序列的第i個輸入結果;j為多項式階數;Aj為第j階多項式的待回歸變量;Y為該節點的輸出值;
神經元模塊IP9的統計學意義在于將接近于0值的判斷結果盡可能后移,但不能打破所以數據點投影的位置相對序列關系。在其輸出層需要構建一個二值化層,確保最終數據投影在(0,1)區間上。故IP9的隱藏層節點函數應為對數函數:
Y=∑(A·logeXi+B)
(4)
式中:A為該對數函數的斜率校正值的回歸結果;B為該對數函數的截距校正值的回歸結果;e為自然常數,用作對數底值,此處取近似值2.718 281 8;Xi為輸入序列的第i個輸入結果;Y為該節點的輸出值;
IP9模塊的輸出層應采用二值化函數進行管理,其節點函數為:
(5)
式中,A、B為該函數的待回歸變量;e為自然常數,用作冪底值,此處取近似值2.718 281 8;Xi為輸入序列的第i個輸入結果;Y為該節點的輸出值;
對上述節點設計進行統計,整合模塊設計的結果,可以得到該神經元網絡模塊的總設計架構,詳見表2。
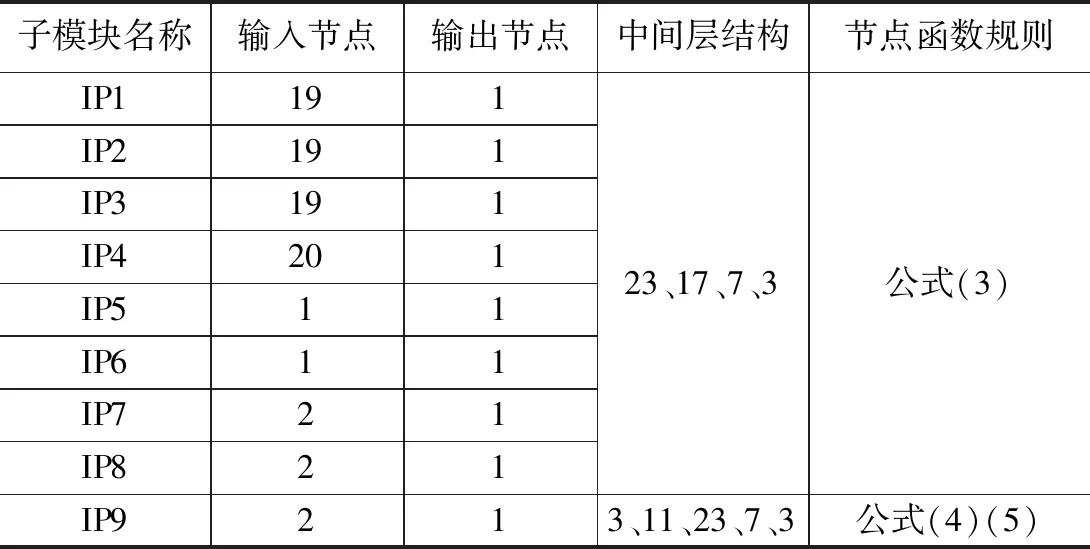
表2 神經元網絡各模塊的設計參數匯總
4 系統測試與測試結果討論
選擇40片MC6821集成電路與40片MAX7219芯片作為測試芯片,經過前期全面工程測試,每組芯片均為20片故障芯片與20片正常芯片,分別使用升級前算法RC1算法與升級后的RC2算法進行芯片故障測試。其測試結果如表3所示。
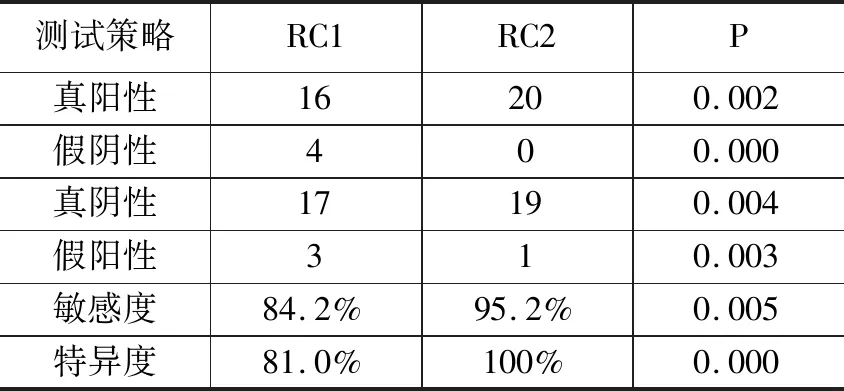
表3 算法升級前后的測試效果統計表
表3中可以看到,算法升級后的模糊神經元網絡算法合并布爾差分算法的RC2算法,相比較單純使用布爾差分算法,其測試敏感度從84.2%提升到95.2%,其測試特異度從81.0%提升到100%,所有測試結果經過SPSS信度分析,P<0.01,具有顯著統計學意義。故可認為,升級后的算法測試能力顯著優于升級前算法。
但是,該算法仍存在一些不足,這一不足體現在升級后算法不能完全排除將正常芯片認定為故障芯片的可能,即使用新算法的系統仍可能對無故障芯片發生誤報。此時,建議對同一芯片進行2次以上的測試,最終2次以上測試解決均相同時,認為測試結果有效。
傳統的基于工程分析的芯片測試工作往往需要耗費大量的時間成本和人力成本,特別是大規模硬件開發工作中,因為使用芯片較多,很難在整體硬件功能出現問題時找到問題原因。這也是類似航空航天等高復雜度系統出現問題后,故障排查周期可能長達數月甚至數年的主要原因。開發一種高可靠高可用高效率的集成電路故障分析系統,將是解決這一問題的關鍵。本文升級算法設計后,使得集成電路測試系統的分析效果得到了顯著提升,將使高精密高復雜度設備的故障排查工作效率得到顯著提升。
5 結束語
本文在傳統的數字集成電路故障測試系統中進行深度開發設計,通過選擇更高配置的嵌入系統,同時在傳統的布爾差分算法的基礎上,引入模糊神經網絡算法的機器學習功能對不可測故障進行更加精密的捕捉,升級后的算法使該測試系統獲得了更精確的測試結果。較以往通過升級優化布爾差分算法測試集以提升測試結果精確度的技術升級方案不同,該方案充分利用系統測試大數據資源,使用機器學習和人工智能概念,讓測試過程的諸多不可控性得到了有效控制。
猜你喜歡
汽車維修與保養(2019年7期)2020-01-06 03:30:42
汽車維護與修理(2016年10期)2016-07-10 08:17:41
鐵道通信信號(2016年4期)2016-06-01 12:10:19
電測與儀表(2016年5期)2016-04-22 01:13:50
汽車維修與保養(2015年12期)2015-04-18 07:51:49
汽車維修與保養(2015年8期)2015-04-17 03:32:52
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維修與保養(2015年7期)2015-04-17 02:12:40
汽車維修與保養(2015年2期)2015-04-17 01:30:34
汽車維護與修理(2015年2期)2015-02-28 12:15:39
