基于MapReduce框架的一種并行大數據算法的研究
2021-04-04 10:48:17馮占偉
現代信息科技 2021年18期
關鍵詞:數據挖掘



摘? 要:為了在社交媒體數據中找出相應內容,可以通過大數據挖掘的算法對社交媒體數據進行處理。文章提出了一種處理Twitter數據挖掘的大數據算法,為保證可擴展性,基于MapReduce框架提出并行數據挖掘的大數據算法。通過實驗證明了該算法是高效的,在計算上,盡管數據集大小增加,執行速度仍然可以顯著增加,并且加速比隨著數據集大小的增加和數據節點數量的增加而增大。
關鍵詞:社會媒體;數據挖掘;大數據算法;推特數據;MapReduce
中圖分類號:TP311 文獻標識碼:A 文章編號:2096-4706(2021)18-0031-04
Abstract: In order to find out the corresponding content in the social media data, the social media data can be processed through the algorithm of big data mining. This paper proposes a big data algorithm for Twitter data mining. In order to ensure the scalability, we propose a parallel big data algorithm based on MapReduce framework. Experimental results show that the algorithm is efficient. Although the size of the data set increases, the execution speed can still significantly increase, and the speedup ratio increases with the increase of the size of the data set and the number of data nodes.
Keywords: social media; data mining; big data algorithm; twitter data; MapReduce
0? 引? 言
最近的一些研究表明,在社交媒體上表達的輿論可能與各種社會問題相關。為了找出在社交媒體數據中實際發現的內容,通過數據挖掘可以處理大量數據,稱為大數據算法[1,2]。本文中提出了一個處理Twitter數據挖掘的大數據算法。此外,為了保證可擴展性,采用Map Reduce框架來并行化所提出的算法。在過去十年中,隨著Web 2.0技術和通信工程的快速發展,社交媒體的普及和擴展已經相當驚人[3]。社交媒體產生的大量數據有可能為市場和消費者行為提供一些新見解。這同樣適用于政治、環境、娛樂業、股票市場等其他社會學問題。數據挖掘的關鍵功能是從數據中提取知識,而社交媒體就像一個廣闊的未曾觸動過的而充滿價值的數據土地,在這塊土地上使用數據挖掘技術有一個明顯的動機,例如,作為社交媒體的典型例子,Twitter是一個微博應用程序,允許感興趣的用戶對其他用戶的想法或生活中的某些事件實時跟蹤和評論。作為最受歡迎的社交媒體之一,每天有數百萬用戶發布超過1.4億條推文。這種情況意味著Twitter數據是一種把有價值的數據作為一種集體知識的語料庫,最近引起了各個領域的研究者的廣泛關注。
在數據挖掘領域,已經有一些優秀的作品通過不同的興趣點對Twitter數據進行了分析。這包括預測票房收入和工業平均指數的走勢等[4-7]。他們的研究表明,嵌入在社交媒體中的數據有很大的力量,確實可以用來做出準確的預測。與人工專家系統不同,來自社交媒體的龐大數量的信息代表了挖掘數據的極好機會,以提取具有特定結果預測的知識。這種社交媒體數據可以用來建立模型,以匯總來自集體社區的意見,并獲得一些有用的針對他們的行為的洞察,這可以用來預測未來的趨勢。此外,它可以用來收集人們對特定產品的評論信息。可以證明這些評論的分析對于營銷和廣告活動的設計非常具有價值。
通過對過去社會化媒體數據挖掘工作的評估,我們發現社會化媒體數據挖掘最迫切需要解決的研究問題是準確地學習能夠揭示情感的觀點。在社交媒體上發布的大規模模糊和非結構化內容,具有快速處理社交媒體中大數據的能力。本文提出了一種大數據算法,同時也提出了一種并行算法,以處理大數據,從大量的Twitter數據中挖掘有用的見解。
1? 本文提出的大數據挖掘算法
1.1? 情感詞的情感分類
首先給出以下定義,使問題形式化:
定義1:(記錄集LD)設LD={d1,d2,…,dn}是收集的社會媒體文本數據的集合,由m個句子組成。
定義2:(同義詞集列表SL)設SL={a1,a2,…,am}是媒體環境中的同義詞集列表,由m標記的單詞數組成。
定義3:(情緒值集SV)設SV={x1,x2,…,xm}是同義詞集列表SL的每個元素的情感價值的收藏品,由m個分類數或數值或向量組成。
定義的隸屬函數的輸入應該是數字值或數字矢量,并且應該相對地包含語言術語的實際含義。情感同義詞列表中用于隸屬函數條目初始情感值已經通過SentiWordNet 3.0查詢[8]。在所提出的方法中,模糊分區被定義為[正+,正,中,負,負-],也被定義為語言術語{l1,l2,…,ln}。通過這種方式,可以使用這些模糊分區來定義和確定具有清晰數值的隸屬函數。由于輸入數據的性質和定義的語言術語經常會產生符合高斯分布的隨機情感組合,所以如式(1)所示的高斯函數被用于定義隸屬函數。在同義詞集列表的基礎上,可以選擇特定同義詞集的初始情感值作為定義的隸屬函數的輸入,并且對于不同的語言學術語,高斯函數的參數根據選擇的同義詞集標簽被不同地定義。
特殊語言術語li的隸屬函數μFsi(x;μi,σi)可以定義為式(2):
在上面的定義式中,參數σi是高斯分布的標準偏差,它被定義為固定值[0.25,0.15,0.125],以符合情感值的理論平均分布。
1.2? Twitter數據集轉換為矩陣
為了充分表示社會媒體中確定的非結構化和嵌入的觀點,使用2.1節計算出的模糊值向量。本節提出了一種使用矩陣操作的新方法,將采集到的數據集轉換成多級矩陣。
首先,介紹了增加維度的過程:
定義4:(頂層屬性)設:UA=是通用屬性集,它總結了描述社交媒體數據的所有屬性。設子集Ec={Ec1,Ec2,…,Ep},Ec∈UA是社會媒體數據本質特征的頂層屬性集。
定義5:(中間分層屬性)設子集E′=,E′∈UA是直接構成和補充Ec元素的中間分層屬性集。
定義6:(底部分層屬性)設子集E={E1,E2,…,En},E∈UA是底層屬性集,間接描述E′的每個元素的特性。
使用上述定義,所提出的方法的總體思想遵循了增加維度的過程。它將嵌入在社交媒體中的所有關系定義為一個圖形,頂層屬性是要分析的目標屬性,例如“蘋果公司”,中間層屬性是屬于頂層屬性的屬性,例如目標公司生產的“iPhone 5s”等產品,與目標直接相關。定義底層分層屬性來描述中間層的屬性,以豐富目標的隱藏信息。例如,諸如“電池”等術語是產品的特征。結合直接和間接的劃分操作,所提出的維度提升過程可以顯著地測量目標對象丟失和隱藏的信息,它明顯優于其他現有的直接社交媒體挖掘方法。
1.3? 定義數據集和LDij數據塊作為矩陣
整個收集社交媒體數據可先初步轉化為多級矩陣的子矩陣,并進一步給出了以下定義:
定義7:(數據塊)假設記錄集可以劃分為m×n數據塊LDij,使用底部分層屬性集E={E1,E2,…,En}作為列;使用一組有序的序列對象S={S1,S2,…,Sm}作為行。
因此,對于LD中的任何數據塊,LDij表示與屬性Ei相關的數據記錄,并按對象Sj進行分類。
然后,根據定義(4)中,記錄集的任何元素都可以表示為dj=a1×X1+a2×X2+…ag×Xg。為了更好地從每個數據塊LDij分組記錄,一個補充的信息因子ξi被定義為適合社交媒體數據中重復和不完整的信息,目的是降低后期矩陣操作的計算代價。
定義8:(補充信息因子)設ξ={ξ1,ξ2,…,ξn}為補充信息因子,根據每條記錄將所有出現的同義詞信息記錄為矩陣。
ξj可以測量任何一個補充信息,比如它在句子中的順序,或者它的出現時間是1。因此,例子中的語言情感極性[P+,P Ne N N-]的定量矢量對每個特征是唯一的,與特征的值相同,因此對每個記錄依次使用每個特征的這些定量向量來構造數據塊LDij的數據矩陣是合理的,如下所示,一個示例性描述中假設在LDij中存在一定數量的p記錄與許多K補充信息因子:
從上面的數據矩陣可以看出,行數等于數據記錄的數量,說明它是一個相當巨大的矩陣。從前面的例子可以看出,在真實的社交媒體環境中,所定義的特征與例子中的情感詞匯一樣重復。此外,為了將選擇的數據塊的問題進行分類為幾個類別,僅關注測量預定義的特征就足夠了,但是不一定要將每個數據記錄進行分類并全部包括在數據塊中,因此,從上面開始,一種應用二進制系統的方法被提出,它顯著地減少數據矩陣中的行數,這可以降低數據矩陣的復雜度和計算成本。
首先,該方法對所有數據塊中的特征向量進行了歸納,刪除其他相同的特征,構造出整個數據集的歸納特征集,例如,這個歸納特征集可以包括在記錄集LD中找到的所有情緒詞匯。然后,由于不需要順序地保留數據矩陣的所有記錄,下一步是確定每個數據記錄中是否存在特定特征。二進制數字系統用于標記每個數據記錄中的每個特征。在二進制系統中,計數只使用兩個符號0和1,當數字達到1時,增量將其重置為0,并且還向左增加下一個數字。
在發現感興趣的模糊關聯規則的基礎上,通過度量所有相關規則,將該算法擴展到目標預測中。更具體地說,任何模糊規則lq-lc的置信度可定義為:
2? 實驗分析與結果
為了評價所提出的大數據算法是否可以處理社交媒體數據的大規模收集,采用MapReduce框架并行化,以提高處理速度。實驗中使用的Twitter數據集是由OACM設計的網絡爬蟲系統Twitter.com收集的數據[9],它包括2015年3月至2016年3月的所有推文,其中包含了超過5億條文本記錄。實驗的環境是Intel i7 3720QM和2 GB RAM的CPU;操作系統是Ubuntu12.04 X86_64 GNU/Linux;以及SUN Java jdk 1.7.0_25。Hadoop集群由4個節點組成,端到端TCP套接字的帶寬可達100 MB/s,對于每個NodeData,最大線程數為8。
2.1? 基于并行化的大數據算法的MapReduce框架
基于該算法的處理過程,本文設計了兩個Map Reduce作業來有效地并行化作業,是生成候選屬性作業和生成模糊規則作業。生成候選屬性作業的目的是基于兩個屬性對之間的關系來推斷多個屬性之間的關系。使用生成候選屬性作業的輸出,生成模糊規則作業被設計為優化所識別的興趣模糊規則并計算每個規則權重以訓練分類模型。更具體地說,生成候選屬性作業包含一個Map函數,其偽碼在算法1所示。輸入數據集作為<key,value>對的序列文件存儲在HDFS上,其中關鍵字是將該記錄從序列文件移動到起始點偏移量,并且該值是記錄集LD的內容。整個社交媒體數據集LD被分割并廣播到所有的數據節點,并被并行掃描。對于每個映射任務,輸出<key’,value’>對,其中key’是候選屬性的值,value’是具有模糊值VBi的相應屬性矩陣。
算法1:生成候選屬性作業<key,value>的Map函數
Input: the offset as key, the record set LD as value.
Output: <key’, value’> pair
1.Map<attribute, vector> map= split(value.toString());
2. for(attribute: map.getkey()){
3. take name as key’;
4.matrix=new SimpleMatrix(attribute.getFuzzySetSize(), aimAttr. getFuzzySetSize());
5. i=0;
6. for(double value : map.get(attribute)){
7.matrix.insertRow(i++,0,min(value,aimAttr.getFuzzy Vector()));}
8. take matrix as value’;
9. output <key’, value’>}
在同一個數據節點中,中間數據的處理不會涉及過多的通信成本。因此,根據映射函數的輸出,組合函數也被用來組合相同數據節點的中間數據和屬性的模糊度。Combine函數的偽代碼如算法2所示,其輸出<key',value'>對的序列文件,其中key’是候選屬性之間的組合的名稱,并且value’由屬性矩陣與相同數據節點中的模糊值{VBi,VBi+1,…,VBi+m}組成。
算法2:生成候選屬性作業(KEY, V)的Combine函數
Input: key is the name of combinations between candidate attributes, V is the list of according attribute matrix with fuzzy values assigned to the same DataNode.
Output: <key’, value’> pair
1. Initiation a new Matrix argument(outMatrix);
2. while(V.hasNext()){
3. Matrix m = V.next();
4. outMatrix = outMatrix.add(m);}
5. Take key as key’;
6. Take outMatrix as value’
7. output < key’, value’> pair;
合并動作完成后,使用約簡函數對所有數據節點訓練數據中同一屬性的模糊度進行求和,生成所有候選屬性關聯,并存儲在MongoDB中。
2.2? 提出的大數據算法的評價
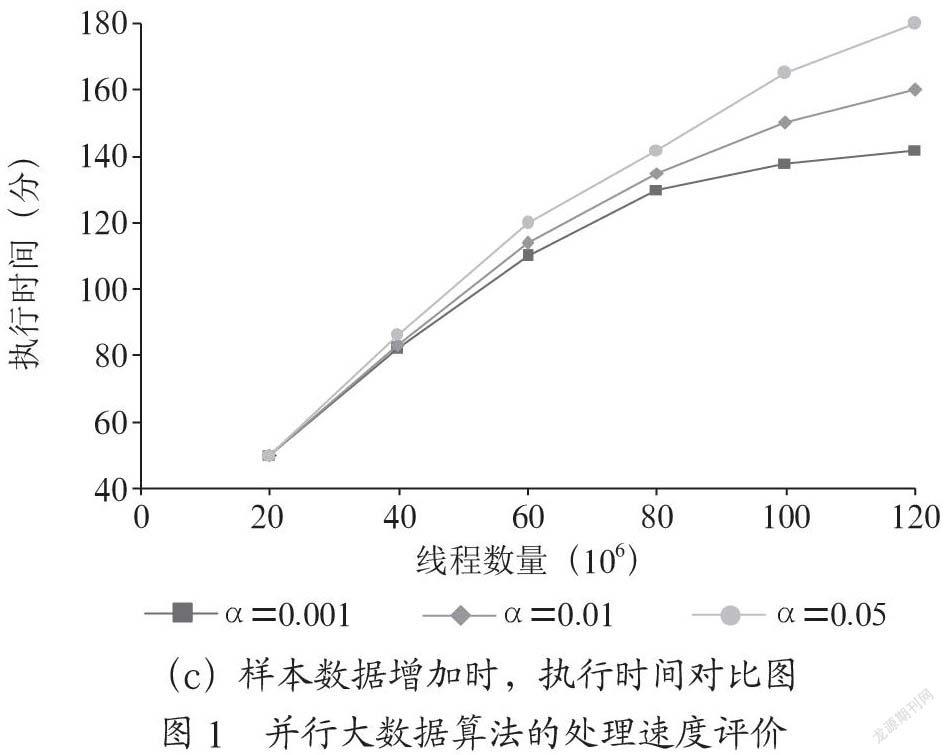
將所收集的Twitter數據集應用于所提出的并行大數據算法的實驗表明,如圖1所示,借助于Map Reduce框架,大量樣本的處理速度遠大于沒有Map Reduce的版本,并且隨著樣本數量的增加,執行時間也逐漸增加,而非MapReduce版本的執行時間則迅速增加。增加數據集的大小說明代碼的非通信部分占用更多的時間,因為有更多的I/O和事務處理。說明并行版本可以減少總體通信時間的百分比。當線程數量從8個變為32個時,另一個評估所提出的算法的性能的實驗說明處理速度隨著線程數量的增加而增加。此外,通過設置不同的卡方檢驗閾值來確定符合條件的候選人,與第一輪掃描相比,該算法在啟動多屬性挖掘過程時,可以顯著減少掃描數據庫所需的時間。
一般而言,結果表明所提出的并行算法具有次線性性能,隨著數據庫規模的增大,程序實際上變得更有效率,這意味著所提出的大數據算法具有處理大型社交媒體數據集的能力。在Map Reduce框架的幫助下,將整個數據集劃分為若干個按照數據節點處理的子集,以保存程序掃描數據集時的大小,并將算法過程生成的中間數據存儲在HDFS中,以節約程序掃描數據集的時間。這些處理也可以提高所提出的算法的處理速度,并且可以通過實驗結果來證明。
將所提出的大數據算法應用于收集到的Twitter數據,通過計算Twitter消息中表達的情感來挖掘社交媒體的觀點。
3? 結? 論
通過對近期社交網絡輿情挖掘的最新評價,本文已確定并強調了最引人注目的研究問題,即準確地了解可能揭示在社交媒體上發布的大量模糊和非結構化內容的觀點,并具有處理社交媒體大數據的快速處理能力。通過提出的大數據算法,通過提出的大數據算法,本文研究得到高效的實驗結果。為了確保可擴展性,采用Map Reduce框架來并行化所提出的算法,通過使用社交媒體數據集,可以證明該算法的潛力。在計算上,盡管數據集大小增加,但是執行速度可以顯著增加。事實上,隨著數據集大小的增加以及數據節點數量的增加,加速比也隨之增加。
參考文獻:
[1] KAPLAN A M,HAENLEIN M. Users of the world,unite! The challenges and opportunities of Social Media [J].Business Horizons,2010,53(1):59-68.
[2] WANG F Y,CARLEY K M,ZENG D,et al. Social Computing:From Social Informatics to Social Intelligence [J].IEEE Intelligent Systems,2007,22(2),79-83.
[3] ULICNY B,KOKAR M,MATHEUS C. Metrics for monitoring a social political blogosphere:A Malaysian case study [J].IEEE Internet Computing,2010,14(2),34-44.
[4] JOSHI M,DAS D,GIMPEL K,et al. Movie Reviews and Revenues:An Experiment in Text Regression [C]//HLT'10 Human Language Technologies:The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics.Los Angeles:Association for Computational Linguistics,2010:293-296.
[5] BOLLEN J,MAO H N,ZENG X J. Twitter mood predicts the stock market [J]. Journal of Computational Science,2011,2(1):1-8.
[6] ZHU F D,SUN H,YAN X F. Network mining and analysis for social applications [C]//KDD'14:Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining.New York:Association for Computing Machinery,2014.
[7] LI J,QIN Q M,HAN J W,et al. Mining Trajectory Data and Geotagged Data in Social Media for Road Map Inference [J/OL].Transactions in GIS,2014,19(1):1-18.[2021-06-16].https://onlinelibrary.wiley.com/doi/10.1111/tgis.12072.
[8] BACCIANELLA S,ESULI A,SEBASTIANI F. SentiWordNet 3.0: An Enhanced Lexical Resource for Sentiment Analysis and Opinion Mining [J/OL].LREC,2010,10:2200-2204.[2021-06-16].http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.180.4108.
[9] CHAN K C C,WONG A K C,CHIU D K Y. Learning Sequential Patterns for Probabilistic Inductive Prediction [C]//IEEE Transactions on Systems,Man,and Cybernetics,1994,24(10):1532-1547.
作者簡介:馮占偉(1981—),男,漢族,黑龍江巴彥人,講師,碩士,研究方向:軟件工程。
猜你喜歡
艦船科學技術(2022年14期)2022-09-22 03:10:36
大眾投資指南(2021年35期)2021-02-16 01:06:26
中國交通信息化(2020年1期)2020-07-27 02:50:04
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
西安工程大學學報(2014年2期)2014-02-28 18:03:05
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
電子設計工程(2014年18期)2014-02-27 12:00:12
