基于飛騰M6678的向量數學庫優化技術研究?
2021-04-06 07:13:34
艦船電子工程 2021年3期
(中船重工(武漢)凌久電子有限責任公司 武漢 430074)
1 引言
飛騰M6678為國產化數字信號處理器(Digital Signal Processor,DSP),單核心的浮點理論運算速度達到16GFLOPS,具有功能強大的FFT協處理器,同時兼容TMS320C6678處理器的SIMD指令集。
基礎數學庫是高性能計算的核心基礎軟件。與傳統的標量運算不同,向量數學庫為提升大點數下的數學運算性能而構建,向量化帶來的加速比高,性能提升明顯。這對于促進國產化芯片行業的蓬勃發展至關重要。向量數學庫已經在ARM微處理器[1~2]和國產CPU[3]平臺進行了向量化優化[4~6]的嘗試。
雖然處理器架構不同,但是向量化的許多方法都是類似的,比如地址對齊[7]、使用SIMD指令[8]和軟件流水[9~10]。其中地址對齊提高了訪存的速度,SIMD指令利用了指令的位寬[11]實現了數據運算的并行,而軟件流水,類似于工廠的流水線,函數循環并非順序執行,第一次循環還未執行完畢,第二次循環已經開始了。但是,僅有這些方法,無法在DSP上完成向量化優化。本文針對飛騰M6678處理器,構建向量數學庫。
目前,飛騰M6678處理器上能夠運算的數學函數庫有兩個,一個是標準C數學函數庫,一個是TI公司提供的MATHLIB函數庫。上述兩個數學函數庫都只能滿足標量運算的性能要求,當進行大點數的向量數學運算時,無法充分利用DSP的并行運算能力。前者在向量化運算過程中效率低下,后者將代碼由內聯函數封裝,編譯器可以根據算法的實現,自行嘗試向量化的優化。
數學運算在飛騰M6678處理器上進行性能測試。測試點數選擇1024,結果如表1。
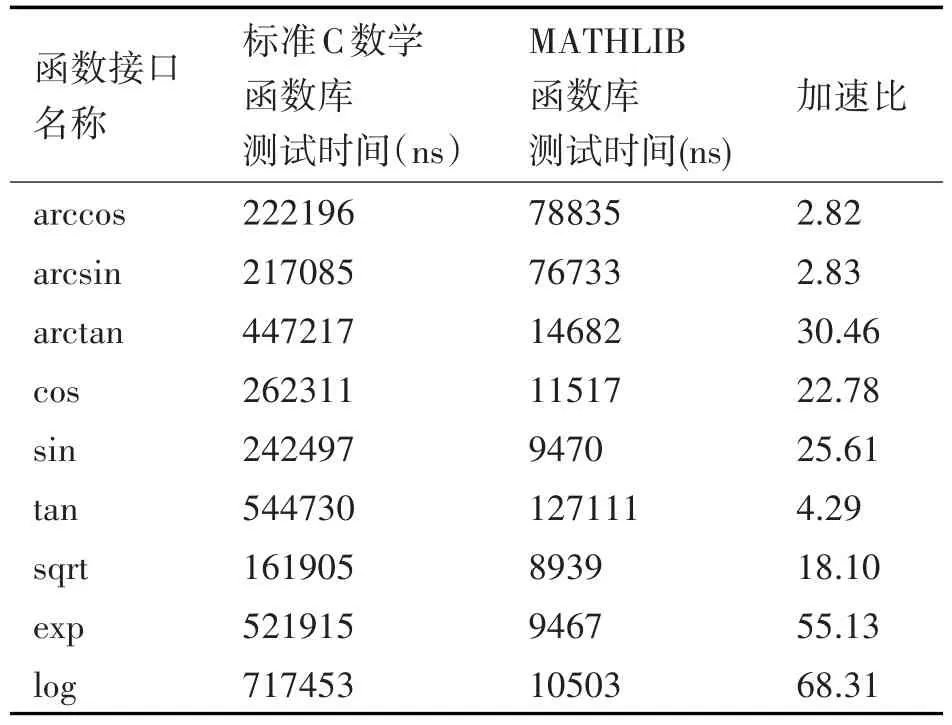
表1 數學運算性能測試
由表1可知,ARCTAN、COS、SIN、EXP和LOG運算的加速比均超過了20,向量化程度高,可向量化的空間小[12]。因此,本文性能優化的重點應該是ARCCOS、ARCSIN、TAN和SQRT。
本文以MATHLIB函數庫為基礎,結合DSP的硬件特性,對數學函數進行向量化優化,實現了高性能向量數學庫。
2 函數實現
數學庫常用的實現方法有級數法、迭代法、查表法、有理數逼近法、逐位法、CORDIC[13]算法。但是以上算法都各自存在自己的問題,級數法和迭代法運算量大,查表法占用空間大,只能計算一定區間內的三角函數,有理數逼近法的向量化空間小,逐位法和CORDIC算法適合只有加法器,沒有乘法器的處理器架構。文獻[14]算法實現了雙精度浮點數學運算的向量化,然而大多數數學運算只需要單精度就足夠了。本文實現的是單精度浮點向量數學庫,ARCCOS、ARCSIN選用泰勒級數法實現,SQRT選用牛頓迭代法[15]實現,TAN采用公式SIN/COS實現。DSP良好的乘加運算能力,很好地滿足了級數法和迭代法對運算能力的要求。
上述4個函數的實現均需要進行求倒數或者求平方根倒數的運算。為提高函數運算性能,不同于簡單使用符號“/”,本文用DSP指令[16]RCPSP和RSQRSP實現,其中RCPSP進行浮點的求倒數運算,RSQRSP進行浮點的求平方根倒數運算。一方面,編譯器省去了解碼、譯碼的時間,另一方面,能夠正常開啟軟件流水。
上述指令經過測試后發現,運算性能相較于符號“/”提高了兩個數量級,但是運算精度很低,達不到大多數應用場景的要求。為了提高運算性能的同時保證數據精度,引入牛頓迭代法。
不加推導的給出牛頓迭代法的基本公式為
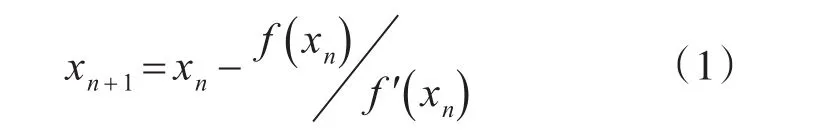
已經證明,如果是連續的、并且待求的零點是孤立的,那么該零點周圍存在一個區域,只要初始值位與這個鄰近區域,那么牛頓法必定收斂。
牛頓迭代法具有平方收斂的性能,這意味著,牛頓法每迭代一次,計算結果精度將提高一倍。FLOAT類型有效位數為7位,RCPSP和RSQRSP運算精度為1/256,即有效位數為2位,使用牛頓法迭代2次,即可以完全滿足精度要求。
3 函數優化
3.1 確定算法的性能瓶頸
優化的第一步是找到算法的性能瓶頸。以開平方運算為例,對迭代法的代碼進行性能分析。MATHLIB源碼如下:


表2統計了單次循環體內,各個計算單元所需要的時鐘周期數。
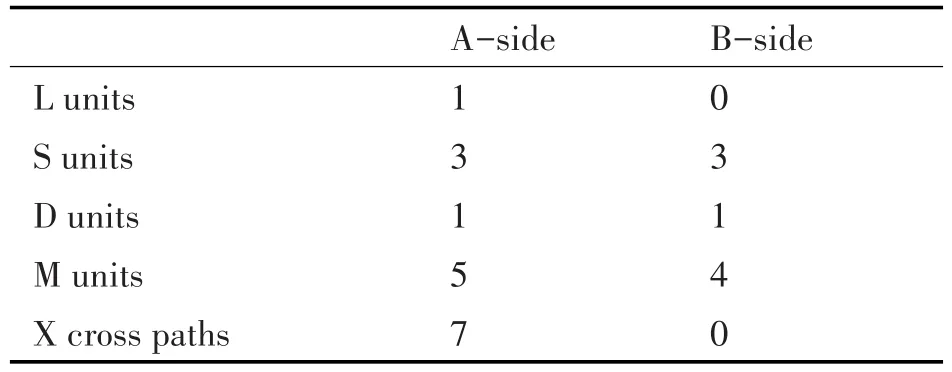
表2 原單次循環性能分析
由于各個運算單元可以并行執行,那么循環體執行一次的周期數就等于表中最大的時鐘周期數。由表2可知,循環體執行一次的周期數等于7。多達7次的跨組寄存器訪問導致性能下降。同時,乘法計算單元使用負荷也很大。另外,RSQRSP執行時間遠低于牛頓迭代法執行時間。
因此,過多的跨組寄存器訪問,是開平方運算的性能瓶頸。
3.2 均衡負載
均衡負載的方法根據M6678的計算單元結構所提出。
如圖1 DSP內核中有兩套4個截然不同的處理單元,當處理float型數據時,M處理乘法運算、L處理加法和轉換運算、S處理比較和倒數運算、D處理數據的加載和存儲。這8個處理單元可以獨立并行執行。但是,計算單元訪問不同組的寄存器,會導致運算時間的消耗。
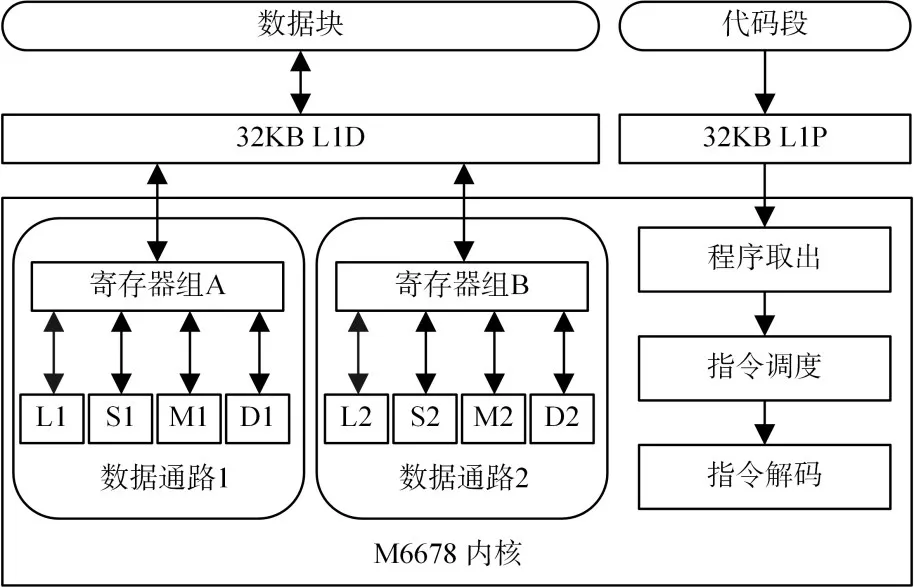
圖1 M6678內核數據處理示意圖
均衡負載,要求A、B兩組處理單元的使用次數大體一致,不要出現某個處理單元的負荷過大,其他處理單元在旁邊等待的情況。
本文采用循環展開的方式使得負載均衡。循環展開,就是減少循環次數的同時,將循環體擴大。以開平方運算為例,將循環體擴大一倍,使得原來的第一次循環由A組執行,原來的第二次循環由B組執行。這樣一來,循環體內不再需要跨組寄存器的訪問。同時,循環展開前的乘法單元在一次循環內,共執行了9次,其中A組執行了5次,B組執行了4次,等待了1次,此時負載不均衡。循環展開后,A組和B組的乘法單元均執行了9次,沒有等待時間。也就是說,原本兩次循環,共計10次乘法計算的時間,循環展開后,只需要9次乘法計算的時間了。
3.3 指令級SIMD優化
解決了負載均衡的問題,本文使用指令級SIMD優化方法著手解決第二個瓶頸,即9次乘法運算。
通常需要運算的FLOAT、INT型數據都是32位,甚至有16位的SHORT類型,然而M6678的每個運算單元均是64位位寬。因此,調用SIMD指令集,可以充分利用運算單元的位寬,一個指令在一個時鐘周期內,可以同時完成幾個數據的運算。同時,使用指令集也節省了編譯器調用指令的時間。編譯器可以在一個時鐘周期內完成指令預取、取指、譯碼、訪問、讀取、執行的所有操作。
前文提到的開平方運算中,通過AMEMD8_CONST、FTOD、DMPYSP、DSUBSP指令完成迭代法的數據位并行,減少乘法計算單元的使用負荷。
3.4 減小循環體的條件分支
開平方運算經過前兩個小節的優化,計算單元的占用達到了最小,但是由于兩個分支條件的存在,軟件流水不能完全開啟。
為了減小循環體的條件分支,本文將原來的循環體分成了兩個小的循環體,第一個循環體進行計算,第二個循環體進行特殊值的處理。
至此,開平方運算完成了向量化的優化。優化后的代碼性能分析如下。
由表3可知,循環體內執行的最大時鐘周期數等于乘法計算單元執行的周期數9,此時A、B兩組乘法計算單元負載均衡。數據位并行和循環展開都分別將循環點數減少了2倍,因此表2中循環體執行1次,相當于表1中循環體執行4次。這意味著,原有代碼執行4次循環共計28個時鐘周期的操作,優化后9個時鐘周期就完成了。當然,實際優化的效率并沒有這么高,還應考慮條件分支處理循環產生的耗時。
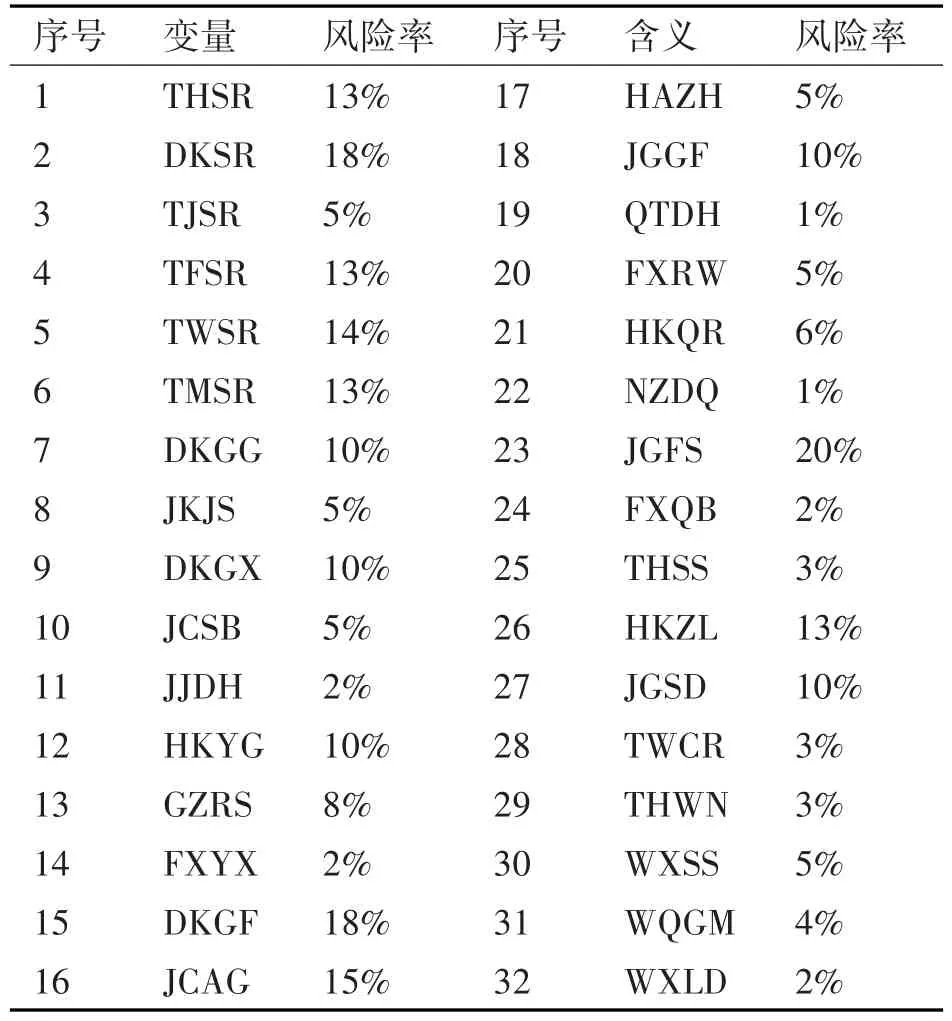
表2 通用航空安全風險計算結果
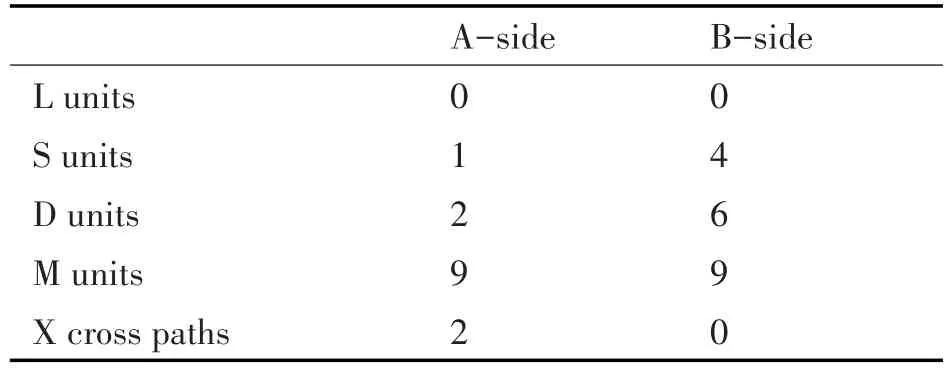
表3 優化后單次循環性能分析
4 性能測試與評價
本文測試的硬件平臺為飛騰M6678開發板,主頻1.0GHz,開發調試環境為CCS 5.5,數據運行地址為MSMC(多核共享內存)。
設計測試MATHLIB函數庫和本文優化的向量數學庫在M6678單核條件下的運算能力。測試數據規模分別為256、512、1024、2048,記錄兩個數學庫函數接口的執行時間,求出不同數據規模下,向量數學庫相較于MATHLIB函數庫的加速比。最后,求出不同數據規模下加速比的平均值,記錄于表4。

表4 部分典型向量數學運算的性能測試
由于MATHLIB函數庫各個接口已有的向量化程度不同,所以加速比也不相同。但是總地來說,優化效果是顯著的。
正確性方面,在浮點數據有效位數之內,向量數學庫與MATHLIB函數庫結果完全相等。這表明,向量數學庫完全能夠勝任大多數應用對運算精度的要求。
5 結語
本文針對飛騰M6678平臺下的向量數學庫,采用了DSP指令和牛頓迭代法進行改進。通過深入分析算法的性能瓶頸,提出了通用的SIMD優化方法,以及結合硬件特性的優化方法,充分利用了硬件資源,顯著提升了向量數學庫的運算性能。此外,總結的優化方法包括性能瓶頸的分析、循環展開、SIMD指令的使用和減小循環體分支,在飛騰M6678平臺下具有通用性,適用于大多數情況下的算法優化。下一步工作將主要圍繞更為復雜的信號處理和圖像處理向量庫進行性能優化。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
新民周刊(2016年15期)2016-04-19 18:12:04
新民周刊(2016年15期)2016-04-19 15:47:52
漫畫月刊·炫版(2014年3期)2014-05-27 04:17:21
