基于3D可擴展PE陣列CNN加速器的設計*
2021-04-06 10:48:18蘇梓培陳弟虎
計算機工程與科學 2021年3期
關鍵詞:排序
蘇梓培,楊 鑫,陳弟虎,粟 濤
(中山大學電子與信息工程學院,廣東 廣州 510275)
1 引言
隨著科技的日益發展,人們開始著重于對人工智能的研究。在計算機視覺領域,卷積神經網絡CNN運用十分廣泛,且在各種各樣的應用中遍地開花。CNN模型的數據量不斷增大,精確度不斷提高,同時帶來的是模型的復雜化,計算量的劇增。而在一些特別的移動端的應用需求(如無人駕駛)中,對于數據量巨大的CNN網絡,需要十分快速的前饋計算來滿足需求,因此研究CNN加速器顯得十分必要。
現在有許多研究CNN加速器的工作,而隨著CNN的發展,層數越來越多,數據量越來越大,卷積操作越來越復雜,使得神經網絡的計算無法簡單地映射到直接對應的硬件上,要考慮到各種硬件部件的復用。運算的基本單位為一個 PE(Processing Element),而不同的 PE 也對應著不同的架構:有的PE是一個乘加器,如文獻[1,2],通過 PE 間數據傳輸進行數據復用;有的 PE 是多個乘加器與加法樹的組合,如文獻[3,4];也有的 PE 除了乘加器,還包括數據傳輸與 FIFO,如文獻[5,6]。
但是,不同的應用場景對加速器的具體需求不一樣。應用的場景不同,硬件資源約束不同,使用網絡也不同,因此需要能夠快速尋找并快速設計性能較優的CNN加速器。且現有移動端所使用的網絡層數偏中。而MobileNet中提出的深度可分離卷積的運用也越來越多,因此需要適配DW(Depthwise)/PW(Pointwise)/CONV(Convolution)的加速器架構。文獻[7,8]設計了專門用于深度可分離卷積的神經網絡,但這些神經網絡不能兼容經典的卷積。
針對上述問題,本文提出了一個基于3D可擴展PE陣列的CNN加速器,能夠很好地根據不同的網絡和硬件資源進行適配,并根據約束找到最優的3D-PE每一維的PE數量。該加速器支持CONV、DW CONV(Depthwise Convolution)和PW CONV(Pointwise Convolution)功能,支持目前常見的移動端網絡,如yolo-tiny、mobile-net等。最后使用該加速器構建了一個實時的目標檢測系統。
2 3D可擴展PE陣列介紹
在CNN神經網絡中卷積運算的運算量巨大,因此需要進行并行運算。現有的嵌入式移動端的CNN加速主要采用2D的PE陣列進行并行加速,即沒有并行運算通道的運算,只對其中一個通道的寬與高的像素運算進行并行化。
2D的PE陣列對大的特征圖能夠很好地進行并行加速,并且能得到很好的性能。但是,2D的加速存在上限,如果網絡的特征圖的尺寸(寬/高)比較小,但是通道數比較多,在2D上會存在PE的浪費,而不能很好地利用這些PE對其他通道進行并行運算。
本文提出3D可擴展PE陣列,如圖1所示,PE 陣列分為3個維度,分別是PE的寬X、PE的高Y和PE的通道數C,分別對應特征圖的寬、高和輸入通道數。可擴展的意思是可以根據現場應用的約束,定義其3個維度上的PE數量參數。
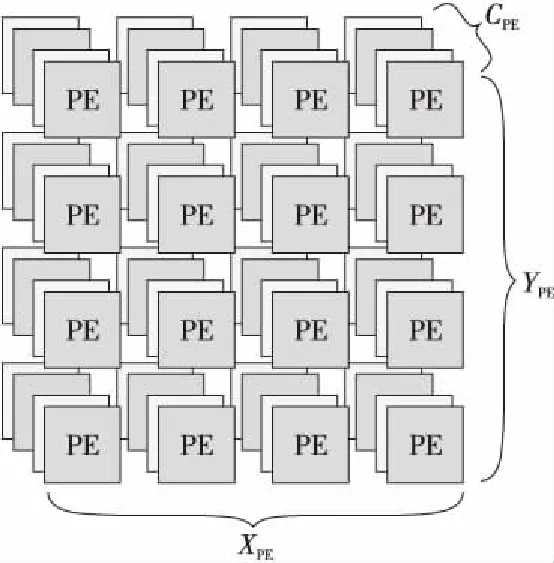
Figure 1 3D-PE array
本文設計的3D-PE陣列中,每個PE對應一個通道的一個像素點的輸出,在3×3 CONV與3×3 DW CONV中,每個PE負責執行9次乘加運算;在1×1 PW CONV 與全連接層中,每個PE負責執行1次乘加運算。
在1×1 PW CONV模式與全連接層的模式下,PE陣列的運算方式如圖2所示。例子中使用了2×2×2的PE陣列,灰色部分代表已經運算完成的特征圖部分,3D-PE先向右滑動窗口,當過了右邊界之后,就切換到下一行進行運算。
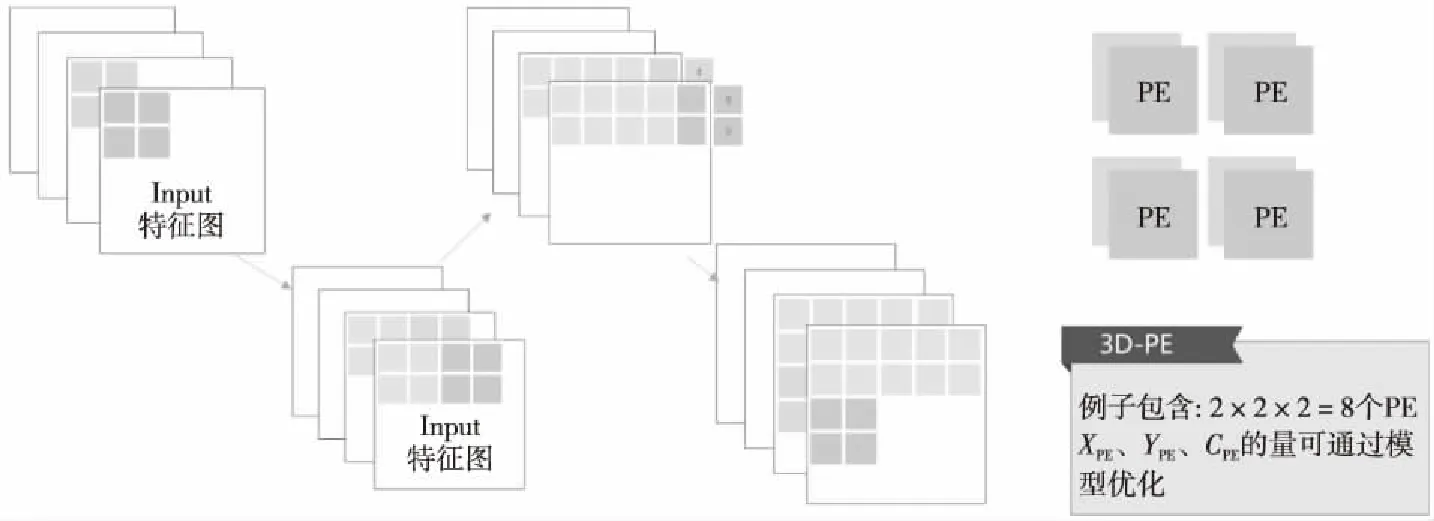
Figure 2 Sample diagram of 3D-PE array running 1×1 convolution
在CONV(3×3)模式與DW CONV模式下,3D-PE陣列的運作方式如圖3所示,每個PE表示一個輸出神經元,3×3卷積過程中,需要9個周期輸入9個數據,9個周期之后則同時得到個數與PE數量相同的輸出值。圖3中灰色部分為輸入緩存,只加載新數值,用過的2列數值可以復用。
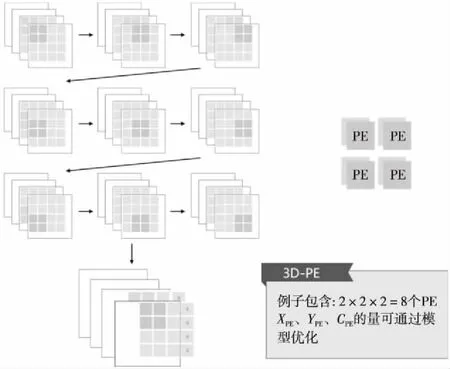
Figure 3 Sample diagram of 3D-PE array running 3×3 convolution
PE的數量根據應用場景的不同而有不同的約束,包括芯片面積約束和芯片功耗約束。很顯然,PE的數量越多,必定得到的并行度越高,得到的性能也越高,但是與此同時也會帶來面積功耗的增加,因此PE數量的選擇是根據應用場景進行折衷考慮得到的。因此,PE利用率則成為了其中一個關鍵的因素。越高的PE利用率,則可以在同樣的PE數量下得到更優的性能,在同樣的性能下使用更少的硬件。本文提出3D可擴展PE陣列,意在在約束PE數量的情況下,比起2D的陣列,能夠提高利用率,獲得更好的性能;同時能夠應對不同應用場景的約束,得到不同約束下的3個最優參數。
2.1 模型建立
在加速器的運算過程中,PE數量有限,并行程度有限。本文加速器采用的是3D的PE陣列,在3個維度進行并行。為了評判其具體性能,建立了相關數學模型,針對不同的運算層,有不同的計算量與并行方式。
不同的運算層,每次使用PE陣列需要的周期數不一樣,3×3卷積需要9個周期進行乘加運算,而1×1的PW CONV和全連接層則只需要1個周期便可得到結果,而深度可分離卷積輸入通道與輸出通道一一對應。把需要使用PE陣列的次數與每次使用所需要的周期數相乘,得到每一層需要的周期數。把整個網絡需要的周期數累加起來,就可以得到該網絡運行需要的周期數,其計算方式如式(1)~式(5)所示:
(1)
(2)
(3)
(4)
(5)
其中,XPE表示PE陣列的寬,YPE表示PE陣列的高,CPE表示PE陣列的通道數,w表示特征圖的寬,h表示特征圖的高,Cin表示特征圖的通道數,Cyclei表示第i層運算的周期數。
通過以上運算得到網絡運行所需要的周期數,就可以從側面了解網絡運行的性能,因此就可以據此評判參數的優劣。當CPE為1時,就等同于使用的是2D-PE陣列。
2.2 性能分析
本節首先分析PE數量不斷增加時2D-PE陣列的CNN加速器的性能提高情況。當PE數量增加時,選取2D的最優參數XPE與YPE進行計算,采用mobile-net-v1網絡,分別對上限為256與1 024個PE數量進行測量,計算結果如圖4所示。GOPS與PE數量的關系如圖4a所示。隨著PE數量的增加,的確可以帶來性能的提高,但是存在邊際效益遞減的情況:當PE數量增加到一定值后,繼續增加PE帶來的性能提升幅度下降。圖4b表示的是GOPS/PE與PE數量的關系。從圖4b中可以看出,前面增加PE令GOPS/PE呈現波動性的特征,表示增加PE的數量仍能保持提高性能的優勢,但是后面繼續增加PE的數量只會讓GOPS/PE逐漸下降。圖4中2D的PE陣列加速,在PE數量增加到一定程度后,將會出現更多的PE浪費。就mobile-net-v1而言,PE數量到達60左右后就出現了明顯的增長停滯。
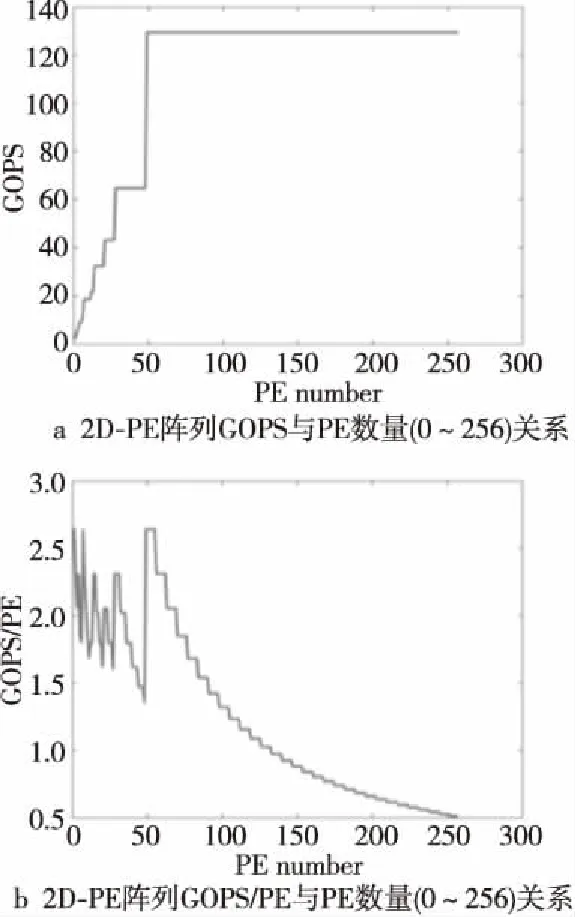
Figure 4 Statistical graph of the marginal effect of total PE number on 2D-PE array
因此,本文設計引入了3D-PE陣列,使PE陣列的并行度能夠更加靈活,且不會像2D-PE陣列一樣快速到達瓶頸。與上述2D-PE進行同樣的操作,對mobile-net-v1進行測量,計算結果如圖5所示。從圖5a可以看出,增加PE數量,GOPS的提升幾乎是線性的,即使PE數量到了1 024個依然可以線性增長,這說明3D-PE陣列可以跨越2D-PE陣列的瓶頸,進行卷積操作的加速運算時性能能夠更優。圖5b中可以看出,GOPS/PE在震蕩,原因是存在一些更優的3D參數組合,存在一定的震蕩范圍。
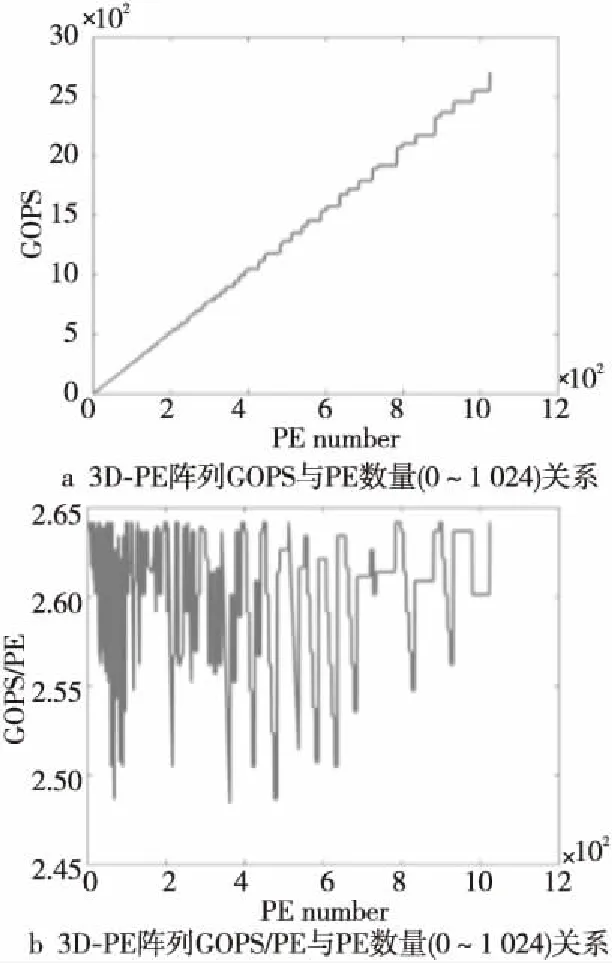
Figure 5 Statistical graph of the marginal effect of total PE number on 3D-PE array
然而即使是PE數量相同,3個維度不同的參數也會有很明顯的性能差別。當PE數量相同,XPE、YPE、CPE3個并行參數不同時,性能差距也會很大,如圖6所示高谷與低谷相差甚遠。因此,通過模型可以計算出在同樣的PE數量條件下,可以得到更優性能的3D的并行參數。
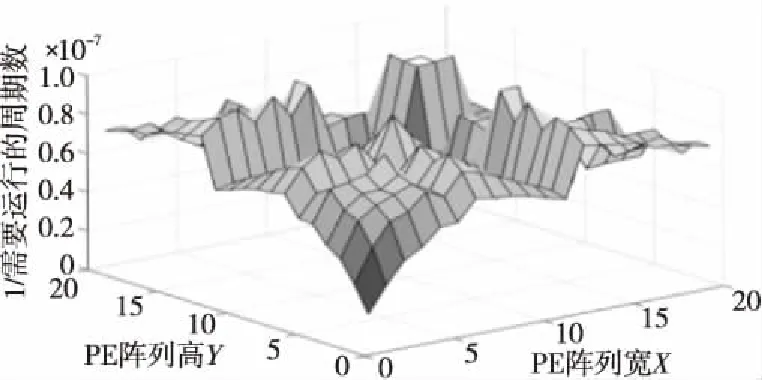
Figure 6 Performance difference caused by three different parameters of 3D-PE
如上所述,使用3D-PE陣列可以更好地利用PE,可以更加靈活地配置PE陣列在3個維度上的并行度。因此,相比2D陣列,本文設計引入的3D-PE陣列存在其優勢。
3 CNN加速器硬件實現
3.1 整體結構
本文CNN加速器的整體架構如圖7所示。其核心思路是,整個加速器由一個中央控制器Controller進行控制,通過中央控制器控制每個子模塊的工作模式和狀態。加速器設置有2個數據Buffer,在一層運算中分別作為Input Buffer和Output Buffer,而他們的功能是復用的,即在一層運算中,若數據可以完全被存放進Buffer中,那么進入下一層運算前,就不需要重新把數據輸出到內存,也不再需要從內存中導入數據,這樣就可以減少CNN加速器訪存時間。
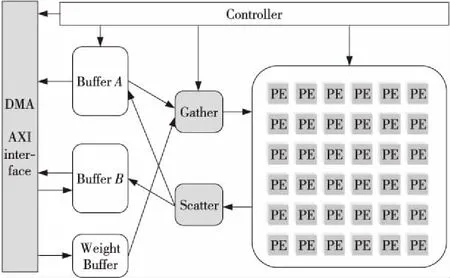
Figure 7 Schematic diagram of the overall architecture of the CNN accelerator
同時設置了一個權值Buffer,因為權值文件是比較大的,也不能完全存放在芯片上,因此會在每層運算期間對內存中的權值進行訪問,而暫時緩存的Buffer就是權值Buffer。由于本設置采用了權值全復用的策略,權值被送入計算單元陣列之后就可以被完全復用,因此可以在權值Buffer中釋放掉其空間,設計為FIFO的形式。采用權值Buffer可以把訪問權值的時間隱藏在計算時間當中。
由于計算模塊中采用了3D-PE陣列的形式,數據是并行進入陣列的,而且不同的卷積操作中,數據進入時序與方式會有些許差別,因此在Buffer和計算模塊中間插入了負責協調和重排序以及緩存數據的模塊,作為Buffer和計算模塊之間的一個緩沖。
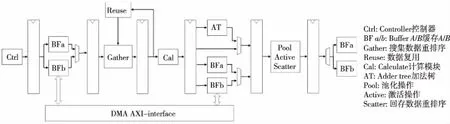
Figure 8 CNN accelerator pipeline design
在該系統框架中,若一層的數據可以被一個Buffer緩存起來,那么在2層之間就完全不需要進行數據的load和store操作,只需要從內存中載入該層所需的權值,這樣就能減少訪存時間,只需要訪存必要的輸入特征圖和輸出的最終結果,大大減少了整個CNN的運行時間。
接下來具體介紹加速器的數據通路和流水線設計。本文的CNN加速器采用了類似中央處理器的組織架構,把控制器類比為指令發射模塊,將控制信號與數據一起在流水線上進行流水,可以保證每個模塊的控制信號的正確運行。流水線設置為從數據Input Buffer中取數值,到最后運算結束存回Output Buffer這一數據通路。整體的流水線設計如圖8所示。
整條流水線可以分為以下幾個步驟:取數據、重排序、計算、重排序和存數據。
(1)取數據:流水線執行的最開端,是Controller發出“指令”,向Data Buffer申請訪問,根據當前運行層,BufferA、BufferB中的一個為Input Buffer,另一個為Output Buffer。從Input Buffer的每個bank中取出一個數據,發送到重排序模塊。
(2)重排序:此時Controller發出的指令也沿著流水線到達了重排序(Gather)模塊,該模塊對送入計算陣列之前的數據進行重排序。除了從Buffer讀到的數據以外,還有數據復用的不需要重新從Buffer訪問的數據。因此,需要對從Buffer讀取的數據和在同一模塊中復用的之前的數據進行統一規整,得到重排序后的數據。之后再把排序好的數據發送到計算陣列模塊進行后續運算。
(3)計算:計算所需要的數據已經經過了Gather模塊排序,只需要對數據進行運算即可。而計算陣列在計算過程中,不同的卷積運算層會有不同的計算模式,根據不同的計算模式,對數據通路進行控制,這個會在后續章節進行詳細描述。計算模塊包括卷積、全連接、池化和激活等操作。某些運算模式中(比如3×3 CONV),計算的過程還需要加部分和,這個部分和產生于之前計算模塊的輸出,部分和存儲在Output Buffer,當計算模塊需要部分和時會讀取Output Buffer中的數據。
(4)重排序與存儲數據:最后,從計算模塊中計算出來的數值,看需要是否進行池化和激活操作,之后再經過一次重排序,得到與Output Buffer的多個bank相對應的數據排序,然后將重排序后的數據進行存儲,作為部分和或者該層的輸出。
3.2 PE結構
首先描述PE的基本結構,如圖9所示。PE陣列存在3個數據級,分別是Input REG輸入寄存器級、MAC PE計算陣列級和Output REG輸出寄存器級。
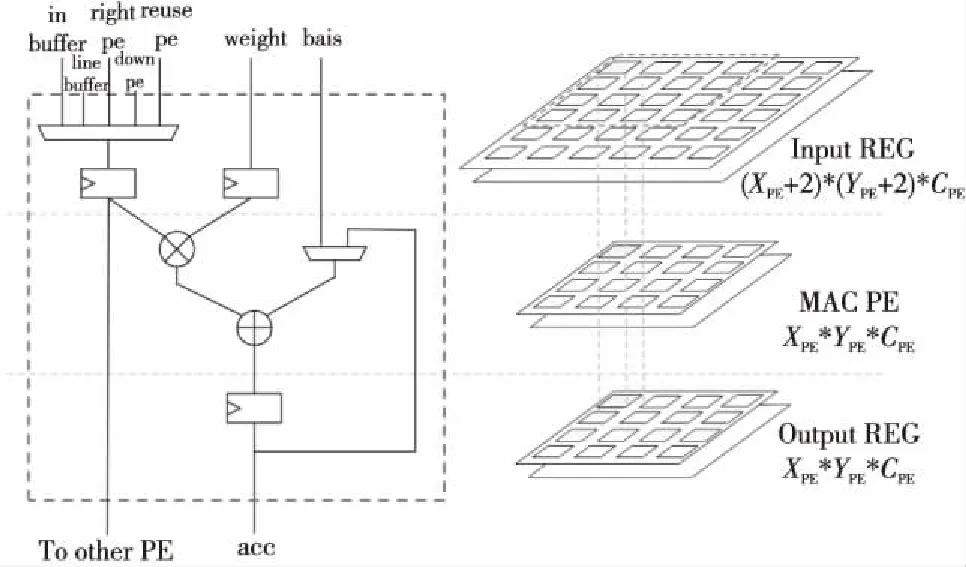
Figure 9 Schematic diagram of PE structure
Input REG輸入寄存器級為計算前的數據緩存,存放著即將要計算的數據。Input REG的個數比PE的個數要多,在計算3×3卷積的時候,需要多出2行2列的數據來進行緩存。于是這些數據在Input REG級里進行流動,且進行復用。
考慮數據復用的情況,整個PE陣列之間具有很強的數據復用性,因此在輸入數據的寄存器前面,有對數據復用進行選擇的多路選擇器。正如本文前面所提到的,PE的數據復用分為PE陣列內的復用與PE陣列運算間的復用。PE陣列內的復用,數據來源可以是其右面PE的寄存器,也可以是其左下PE的寄存器。而PE陣列運算間的復用,數據來源可以是line_buffer,上一次運算中沒完全利用的最右端緩存的數據。當然,數據來源還可以是無法進行復用時,從Input Buffer中讀取的數據。
因此,PE的輸入數據來源共有5個,同時PE的輸入數據寄存器同時要對其值進行輸出,以供其他PE進行數據復用。PE所處在PE陣列的位置不同,其具體的部分結構也不一樣,體現為輸入的多選器不同。不是所有的PE都需要5個輸入來源。每個PE都需要的輸入來源為:Input Buffer、右邊PE的數據復用、左下面PE的數據復用。最上面2行PE還需要增加line-buffer作為輸入來源。最左2列PE需要增加上一次的最右兩側的PE數據作為數據來源。
MAC PE計算陣列級,主體為一個乘加器,在乘法器前面均有寄存器對輸入數據與輸入權值進行寄存。乘法的輸入一個是輸入的數據,另一個是輸入的權值,加法器的輸入分別是乘法器的輸出,以及偏置與部分和的2選1。經過乘加器運算后的輸出保存到輸出寄存器中。
Output REG輸出寄存器級,存放經過MAC計算得出的數值。由于全連接層、3×3卷積、1×1卷積都需要把通道間的數值進行累加,且輸出只有一個通道,但是,3×3深度可分離卷積同時得到多個輸出通道的數據,因此本文加速器設置了多通道輸出寄存器。但是,當運算的不是深度可分離卷積時,數值會采用第1個通道的輸出寄存器作為緩存。第1個通道的輸出寄存器前有一個選擇器,選擇經過通道間加法樹或者第1通道的PE輸出。而其他的輸出寄存器則對應每個MAC通道的輸出,作為深度可分離卷積時的輸出寄存。
接下來說明PE陣列運算間的數據復用,如圖10所示,PE陣列計算完一個單元后,往后滑窗時也同時有數據的復用,以及一排運算完成后,切換到下一排時,也需要對行進行數據復用。正如圖10所示,輸入寄存器緩存的最右2列可以復用給下一次的最左2列,同時,最下面2行的數據要保存到line-buffer中。在運算到下一排時,前2行的數據則從line-buffer中讀取。這樣可以防止同一個數據需要在大的Input Buffer中讀取,降低了片上Buffer結構的復雜性,訪問Input Buffer的地址也變得連續,而且減少了反復訪問Input Buffer的功耗。
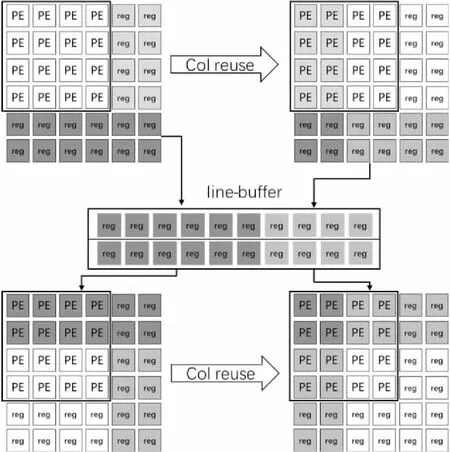
Figure 10 CNN accelerator pipeline design
4 CNN加速器實驗與結果分析
對本文加速器進行mobile-net-v1、yolo-v2網絡仿真,并測試其運算性能。該加速器的時鐘運行頻率為100 MHz。性能效率的計算公式如式(6)所示,表示的是真實性能/理論峰值性能。
(6)
其中,GOPSreal表示真實測得的GOPS,PEnumber表示PE的數量,f表示加速器的工作頻率。
本文加速器PE與DSP數量對等,一個DSP運算一個乘加運算,因此OP為2。得到實驗結果如表1所示。
從表1中得知,這2個網絡都有一個共同的特性,當PE數量增加時,GOPS可以得到明顯的提升,但是GOPS/PE與性能效率在下降。原因是PE數量增多了,有時候導致的空余PE會更多,也就是PE的利用率會下降,導致該性能參數下降。
而在性能上,不同的網絡也出現了不同的小趨勢。在PE數量偏少時,mobile-net-v1的性能比yolo-v2-tiny的要好,而PE數量偏多時,則是反過來,yolo-v2-tiny的性能比mobile-net-v1的更好。
而數據有一個不尋常的點,在PE數量為1 024時,yolo-v2-tiny的性能效率不但沒有下降,反而上升了。原因是3D-PE并行有3個維度的參數,PE數量是3個維度的總乘積,因此存在某些更優組合,而1 024個PE恰恰為更優的組合。
總體而言,隨著PE數量的增加,性能能夠得到提高,而PE的利用率會下降,這也是很直觀的結果。因此,本文加速器的優勢就體現出來了,能夠根據現實的需求進行PE數量的選擇,從而可以得到更優性能的加速器。
本文CNN加速器與文獻[1,7-11]中的研究進行性能對比,具體結果如表2所示。在與相關文獻進行比較的過程中,性能效率的計算方法是假設一個DSP一周期貢獻2個操作(本文加速器),使用同樣的方法對比,可以得到針對DSP資源消耗所產生的性能效率,因此對于相關文獻也假設一個DSP產生2個操作,因此該參數可以作為對DSP占用效率評估的重要參數。
在幾乎相同的DSP使用情況下,本文加速器的GOPS達到了中等水平,但是性能效率更高,且靈活性更強。靈活性從2個角度進行體現:(1)可以自由選擇不同的PE數量,選擇3個不同維度上的并行;(2)既可以運行普通的卷積,也可以運行深度可分離卷積用于移動端設備。
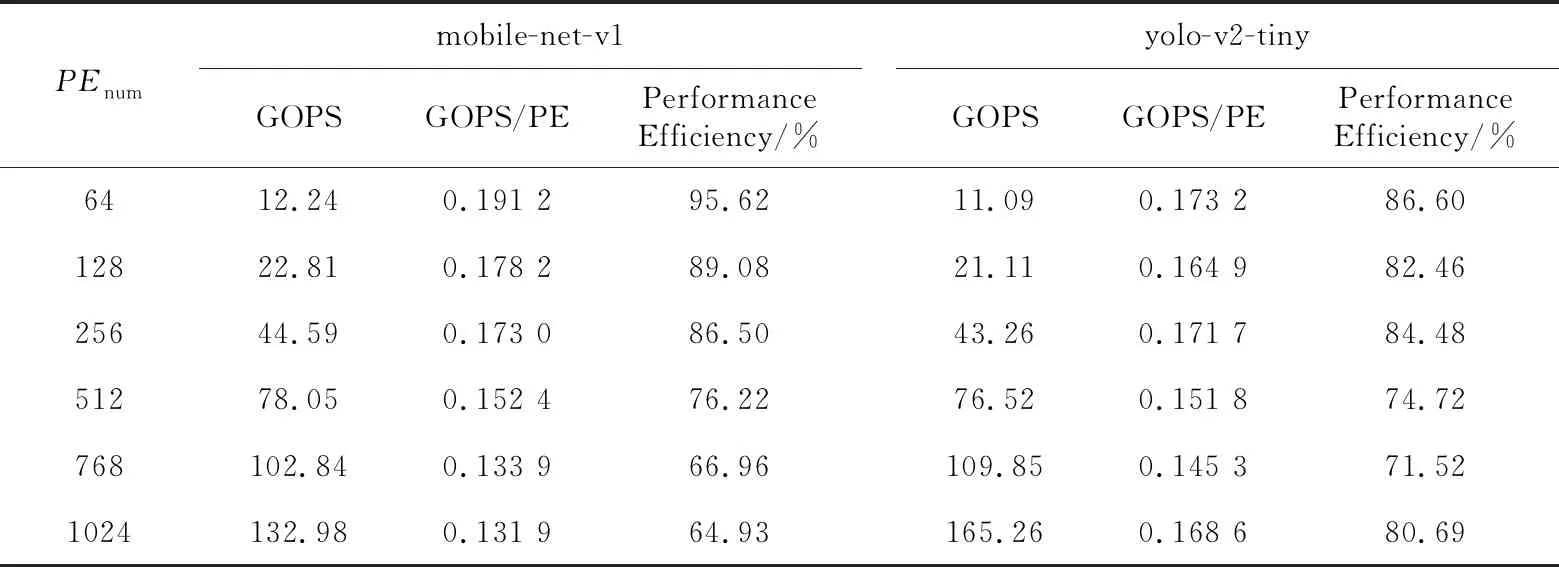
Table 1 Performance changes of mobile-net-v1 and yolo-v2-tiny with the growth of PE number
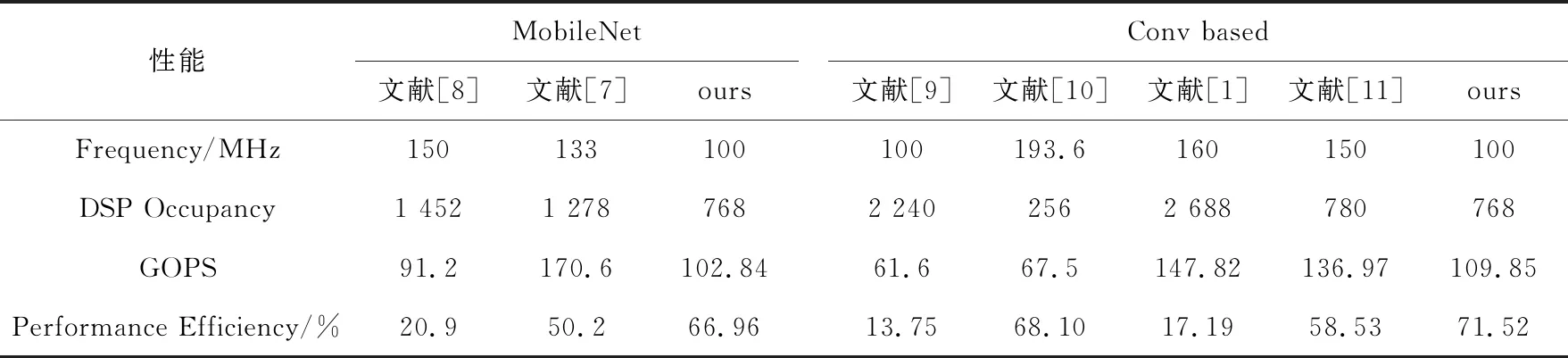
Table 2 Performance comparison between ours and others classical eonvolution accelerator
綜上所述,本文CNN加速器在GOPS性能下降的情況下,可以達到更高的性能效率和更大的靈活性。
文獻[12]提出了一個CNN加速器的便捷設計工具,可以優化各方面參數,其參數的優化與本文相似,但其硬件模板使用的是高級語言進行高層次綜合得到的RTL電路,而本文直接對RTL級硬件電路進行設計。且該文獻并沒有考慮現有移動端上熱門的深度可分離卷積。
最后對該CNN加速器采用XILINX的ZC706 FPGA開發板進行驗證。運行yolo-lite實時目標檢測的效果如圖11所示,卷積神經網絡運行性能達到53.65 fps。

Figure 11 Target detection effect
5 結束語
本文分析了現有CNN加速器的一些缺陷,并以此為切入點,提出了3D可擴展PE陣列的概念,本文CNN加速器可以針對不同的網絡和不同的硬件資源約束對3D可擴展PE陣列進行配置。CNN加速器在512個PE下運行yolo-v2-tiny達到76.52 GOPS、74.72%的性能效率,在512個PE下運行mobile-net-v1達到78.05 GOPS、76.22%的性能效率。該性能處于CNN加速器的中上水平,其優勢體現在具有一定的靈活性和兼容性,最后將其運用在了實際的實時目標檢測系統當中。
本文加速器提出了3D可擴展PE陣列,對于不同的硬件約束、不同的現實網絡運用需求,都可以很好地適配上。對于移動端嵌入式系統,CNN加速器不能太大,運行的網絡也比較輕量級,選擇使用本文CNN加速器十分適合。本文CNN加速器提出的3D可擴展PE陣列,對以后能夠發展出更多的CNN加速器架構,提供了一定的開拓性和創新性。
猜你喜歡
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
名家名作(2021年9期)2021-10-08 01:31:36
名家名作(2021年4期)2021-05-12 09:40:02
名家名作(2021年3期)2021-04-07 06:42:16
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
新世紀智能(語文備考)(2019年12期)2020-01-13 06:04:32
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
名家名作(2017年2期)2017-08-30 01:34:24
