無(wú)人貨架場(chǎng)景下的人體關(guān)節(jié)點(diǎn)定位算法研究*
2021-04-06 10:48:24李夢(mèng)瑤周亞同
計(jì)算機(jī)工程與科學(xué) 2021年3期
李夢(mèng)瑤,周亞同,韋 創(chuàng),李 民
(1.河北工業(yè)大學(xué)電子信息工程學(xué)院,天津 300401;2.華中科技大學(xué)水電與數(shù)字化工程學(xué)院,湖北 武漢 430074)
1 引言
隨著人工智能的發(fā)展,計(jì)算機(jī)視覺(jué)[1]和圖像處理等技術(shù)成功運(yùn)用到新零售[2]場(chǎng)景中,為零售商提供關(guān)于消費(fèi)者需求的全面數(shù)據(jù)。在新零售場(chǎng)景中,無(wú)人貨架作為消費(fèi)者選購(gòu)商品后可以自助掃碼結(jié)算的平臺(tái),能有效反饋消費(fèi)者的購(gòu)買(mǎi)需求和偏好情況。通過(guò)統(tǒng)計(jì)各類(lèi)商品被消費(fèi)者拿起瀏覽的次數(shù)或消費(fèi)者的購(gòu)買(mǎi)清單,可以分析消費(fèi)者購(gòu)買(mǎi)行為,以此調(diào)整備貨、進(jìn)貨策略,更好地滿(mǎn)足無(wú)人貨架場(chǎng)景的及時(shí)性需求,以改變傳統(tǒng)零售商供應(yīng)商品的低效、被動(dòng)模式。
實(shí)現(xiàn)準(zhǔn)確、高效定位無(wú)人貨架前顧客上身關(guān)節(jié)點(diǎn),是后續(xù)手持商品識(shí)別的重要基礎(chǔ)。近年來(lái),人體關(guān)節(jié)點(diǎn)的定位研究主要分為3類(lèi)[3 - 5]。
(1)基于硬件傳感器的研究方面。微軟于2010年研發(fā)的光學(xué)傳感器Kinect[6],能夠根據(jù)內(nèi)置算法實(shí)時(shí)獲取人體關(guān)節(jié)點(diǎn)。Shotton等[7,8]將Kinect獲取的人體深度圖像像素分類(lèi)為身體的多個(gè)部位,實(shí)現(xiàn)人體關(guān)節(jié)點(diǎn)檢測(cè)。李文陽(yáng)等[9]克服了光照因素對(duì)Kinect獲取的人體圖像造成的干擾,實(shí)現(xiàn)了人體關(guān)節(jié)點(diǎn)精確定位。Kinect等傳感設(shè)備雖能方便地獲取人體關(guān)節(jié)點(diǎn)位置信息,但對(duì)傳感攝像頭的依賴(lài)會(huì)導(dǎo)致應(yīng)用區(qū)域的局限性并且增加了視頻獲取成本。
(2)基于圖結(jié)構(gòu)模型的研究方面。該類(lèi)方法首先建立人體模型,并將其劃分為不同部位,再通過(guò)圖像處理提取特征實(shí)現(xiàn)人體關(guān)節(jié)點(diǎn)定位[10]。周倩等[11]基于細(xì)化算法提取人體骨架,在輪廓圖上進(jìn)行關(guān)節(jié)點(diǎn)精確定位。胡剛[12]提出一種對(duì)相鄰部位空間相對(duì)位置與其子部位方向之間關(guān)系進(jìn)行建模的關(guān)節(jié)點(diǎn)定位方法,克服了傳統(tǒng)圖結(jié)構(gòu)模型對(duì)人體建模的不足。基于圖模型的傳統(tǒng)方法對(duì)于關(guān)節(jié)點(diǎn)可見(jiàn)的情形能夠高效求解,但關(guān)節(jié)部位遮擋或存在外界環(huán)境等干擾因素會(huì)限制其表達(dá)能力,導(dǎo)致關(guān)節(jié)點(diǎn)定位精度下降。
(3)基于深度學(xué)習(xí)[13]的研究方面。隨著人工智能的發(fā)展,基于卷積神經(jīng)網(wǎng)絡(luò)[14]的人體關(guān)節(jié)點(diǎn)提取算法也相繼獲得廣泛應(yīng)用。該類(lèi)方法不依賴(lài)硬件設(shè)備,成本低,自動(dòng)從大量樣本中學(xué)習(xí)特征,避免手工設(shè)計(jì)的復(fù)雜性,能夠更精確地定位人體關(guān)節(jié)點(diǎn)位置。2014年Toshev等[15]提出Deep Pose算法,其以分類(lèi)網(wǎng)絡(luò)AlexNet[16]為特征提取主干,并采用回歸歸一化關(guān)節(jié)點(diǎn)坐標(biāo)的方式在網(wǎng)絡(luò)中引入全連接層,增加了網(wǎng)絡(luò)參數(shù)和計(jì)算量,且關(guān)節(jié)點(diǎn)定位精度不高。2016年Wei等[17]提出卷積姿態(tài)機(jī)CPM(Convolutional Pose Machine)。CPM采用多階段級(jí)聯(lián)方式:即在每個(gè)階段,均將當(dāng)前階段圖像特征與上一階段輸出的置信圖共同作為下一階段的輸入,從而將空間信息和紋理信息融合,輸出精細(xì)化的關(guān)節(jié)點(diǎn)位置信息。2016年Newell等[18]提出Stacked Hourglass算法,其通過(guò)堆疊由殘差單元[19]構(gòu)成的沙漏模塊來(lái)提取不同尺寸的人體關(guān)節(jié)點(diǎn)特征,取得了較高精度。2017年Cao 等[20]提出能夠?qū)崟r(shí)檢測(cè)多人人體關(guān)節(jié)點(diǎn)的Open Pose,該算法利用自下而上的方式對(duì)人體關(guān)節(jié)點(diǎn)進(jìn)行定位,并利用復(fù)雜的特征向量親和域參數(shù)來(lái)不斷精確關(guān)節(jié)點(diǎn)位置。以上深度學(xué)習(xí)算法集中關(guān)注關(guān)節(jié)點(diǎn)定位精度,忽略了神經(jīng)網(wǎng)絡(luò)參數(shù)龐大和計(jì)算復(fù)雜等特點(diǎn),無(wú)法兼顧算法性能和檢測(cè)效率,限制了算法實(shí)用性。
針對(duì)上述問(wèn)題,本文就無(wú)人貨架旁存在單人的場(chǎng)景提出輕量級(jí)卷積姿態(tài)機(jī)L-CPM(Lightweight Convolutional Pose Machine)算法,主要通過(guò)引入輕量級(jí)卷積以及降低特征圖分辨率,減少CPM的計(jì)算量,提升關(guān)節(jié)點(diǎn)定位速度;提出基于超分辨率的卷積姿態(tài)機(jī)EP-L-CPM(Efficient Sub-Pixel Convolutional Neural Network and Lightweight Convolutional Pose Machine)算法,其通過(guò)在L-CPM中引入超分辨重建ESPCN(Efficient Sub-Pixel Convolutional Neural Network)來(lái)恢復(fù)丟失的特征信息,以進(jìn)一步提升關(guān)節(jié)點(diǎn)定位的精度。
2 相關(guān)理論
2.1 卷積姿態(tài)機(jī)結(jié)構(gòu)及原理
卷積姿態(tài)機(jī)CPM是一種典型的采用多階段級(jí)聯(lián)方式實(shí)現(xiàn)人體關(guān)節(jié)點(diǎn)定位的算法,其核心是通過(guò)順序化地使用大卷積核來(lái)獲得大感受野,并以不斷擴(kuò)大感受野的方式,隱式地讓網(wǎng)絡(luò)中的神經(jīng)元觀測(cè)到圖像全部的人體關(guān)節(jié)點(diǎn)信息,以提高關(guān)節(jié)點(diǎn)定位精度。這種方式在提高關(guān)節(jié)點(diǎn)定位精度的同時(shí),也大幅度增加了計(jì)算量,其結(jié)構(gòu)如圖1所示。
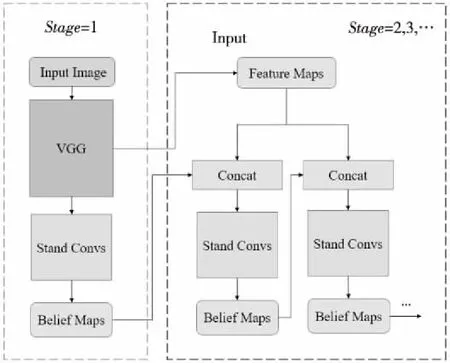
Figure 1 Structure of CPM
CPM主要由2部分卷積層組成:由VGG構(gòu)成的特征提取骨架,其輸出為原始輸入(Input Image)的圖像特征,即FeatureMaps;一系列具有大尺寸卷積核的標(biāo)準(zhǔn)卷積層(Stand Convs),其主要用來(lái)提取空間特征,輸出為關(guān)節(jié)點(diǎn)置信圖,即Belief Maps。
2.2 ESPCN原理及分析
ESPCN是一種高效的超分辨率重構(gòu)算法[21]。通過(guò)核心操作亞像素卷積將在低分辨率LR(Low Resolution)特征圖上提取的特征進(jìn)行整合以重構(gòu)恢復(fù)高分辨率HR(High Resolution)特征圖,其原理如圖2所示。
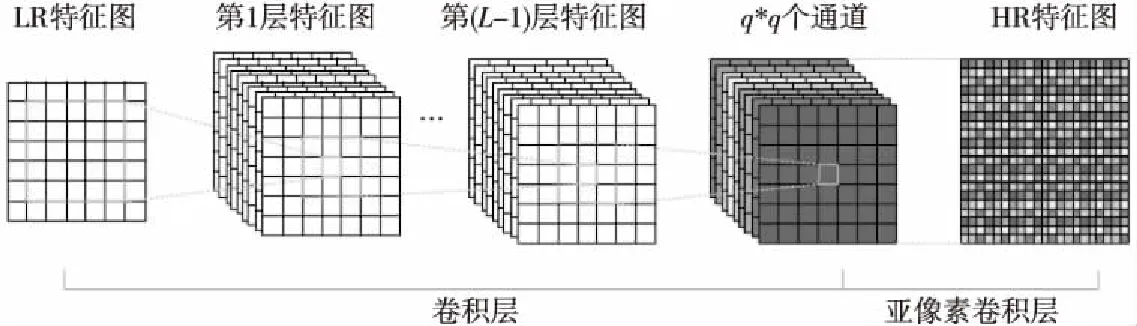
Figure 2 Schematic diagram of ESPCN (C=1)
具體地,在LR特征圖上提取特征的過(guò)程為:
f1(ILR;W1,b1)=φ(W1*ILR+b1)
(1)
fl(ILR;W1:l,b1:l)=φ(Wl*fl-1(ILR)+bl)
(2)
其中,l∈{1,…,L-1};L表示網(wǎng)絡(luò)層數(shù);Wl表示卷積核;bl表示偏置;φ()表示激活函數(shù);ILR代表輸入的LR特征圖。
HR特征圖重構(gòu)過(guò)程為:
IHR=fL(ILR)=ps(WL*fL-1(ILR)+bL)
(3)
其中,ps()代表亞像素卷積操作,IHR表示由ESPCN恢復(fù)得到的HR特征圖。亞像素卷積操作將尺寸為H×W×Cq2的LR輸出特征圖的像素重新排列成尺寸為qH×qW×C的HR特征圖,實(shí)現(xiàn)LR特征圖到HR特征圖的q倍放大,其中,H、W分別為圖像的高、寬,C為通道數(shù)。
3 輕量級(jí)卷積姿態(tài)機(jī)(L-CPM)算法
針對(duì)CPM算法存在計(jì)算量龐大的問(wèn)題,本文基于MobileNet思想[22]和下采樣理論[23]對(duì)CPM進(jìn)行改進(jìn),提出L-CPM算法,在保證關(guān)節(jié)點(diǎn)定位精度的前提下,實(shí)現(xiàn)算法整體計(jì)算量的下降。
MobileNet是針對(duì)移動(dòng)設(shè)備部署的輕量級(jí)網(wǎng)絡(luò),其核心結(jié)構(gòu)是深度可分離卷積(DS-Conv)。如圖3所示,該輕量級(jí)卷積模塊將標(biāo)準(zhǔn)卷積(Stand Conv)分解為一個(gè)深度卷積(DW Conv)和一個(gè)1ⅹ1的點(diǎn)卷積(PW Conv),其可以成倍地降低時(shí)間復(fù)雜度和空間復(fù)雜度,能更高效地執(zhí)行卷積操作。
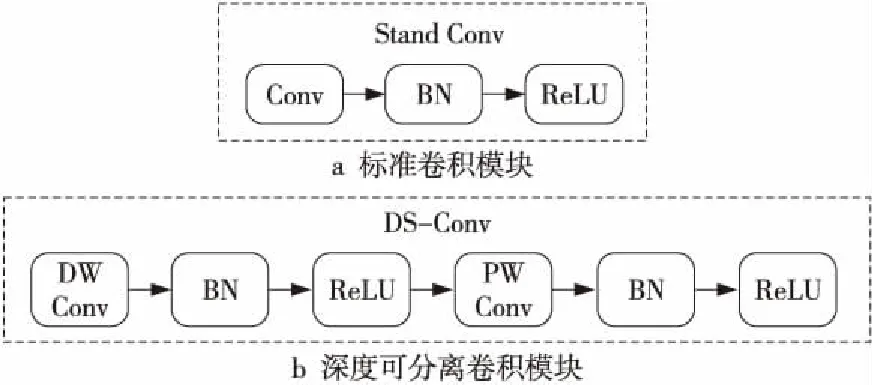
Figure 3 Schematic diagram of two different kinds of convolution modules
L-CPM結(jié)構(gòu)如圖4所示。由于CPM的計(jì)算量集中在由VGG構(gòu)成的特征提取骨架與具有大尺寸卷積核的Stand Convs。因此,一方面用MobileNet整體替換VGG,用DS-Conv替換Stand Convs;另一方面,利用下采樣(SubSampled)降低DS-Conv的輸出特征圖分辨率,通過(guò)減少冗余信息來(lái)進(jìn)一步減少算法計(jì)算量。
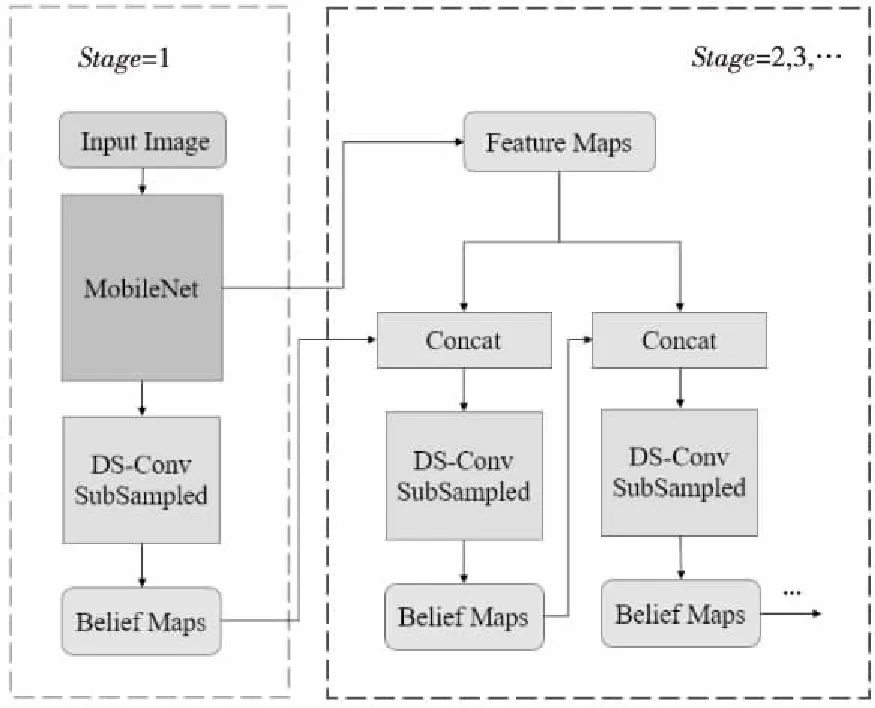
Figure 4 Structure of L-CPM
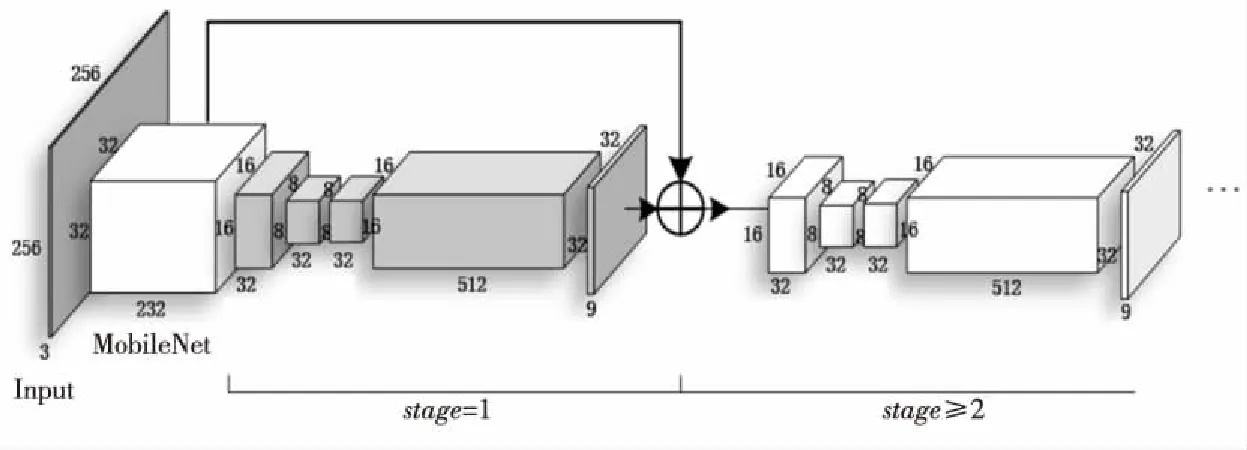
Figure 5 Internal structure of L-CPM
圖5所示為L(zhǎng)-CPM內(nèi)部結(jié)構(gòu)圖,展示了L-CPM 引入深度可分離卷積和下采樣后的結(jié)果,輸出特征圖尺寸由原來(lái)的32×32降為了16×16和8×8。
4 基于超分辨率重建的卷積姿態(tài)機(jī)(EP-L-CPM)算法
L-CPM 引入下采樣后,計(jì)算量會(huì)進(jìn)一步減少。這種通過(guò)縮減輸出特征圖分辨率來(lái)提升人體關(guān)節(jié)點(diǎn)定位速度的方式,會(huì)不可避免地產(chǎn)生卷積輸出特征丟失,降低人體關(guān)節(jié)點(diǎn)定位精度。因此,本文提出一種基于超分辨率重建的卷積姿態(tài)機(jī)(EP-L-CPM),通過(guò)在L-CPM中引入超分辨率重建(ESPCN)來(lái)恢復(fù)丟失的特征信息。EP-L-CPM架構(gòu)如圖6所示。
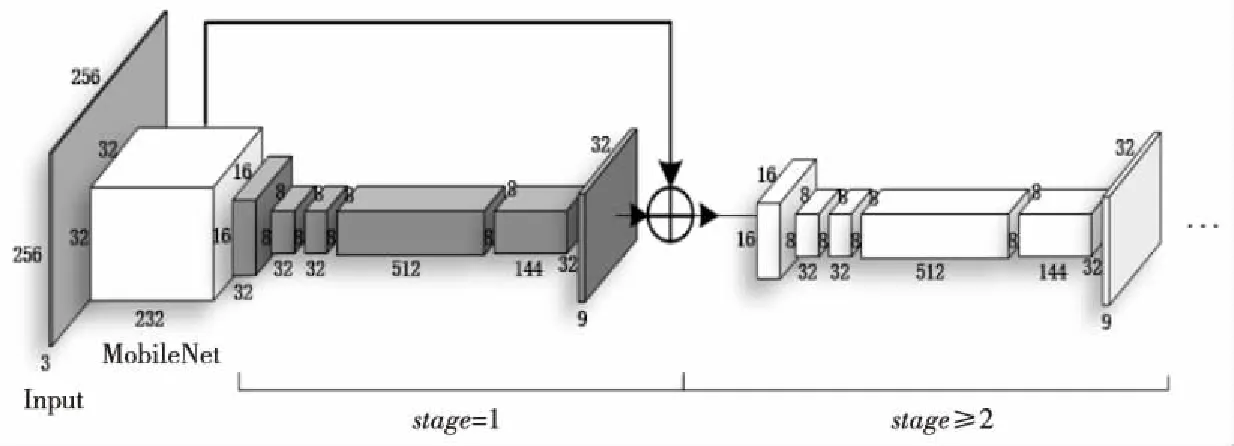
Figure 7 Internal structure of EP-L-CPM

Figure 6 Structure of EP-L-CPM
ESPCN作用在L-CPM的最后端,利用亞像素卷積操作對(duì)輸出特征圖的像素進(jìn)行重新排列,以實(shí)現(xiàn)特征圖從低分辨率到高分辨率的變換,該過(guò)程雖然命名為亞像素卷積,但實(shí)際上并沒(méi)有進(jìn)行卷積操作;在重建過(guò)程中,增加了輸出LR特征圖的通道數(shù),使得LR特征圖鄰域像素點(diǎn)間的信息得到充分利用,能高質(zhì)量重建HR特征圖。因此,EP-L-CPM在保證不增加算法整體計(jì)算量的前提下,能實(shí)現(xiàn)關(guān)節(jié)點(diǎn)定位精度的提升。
引入ESPCN后的EP-L-CPM的具體內(nèi)部結(jié)構(gòu)如圖7所示。從圖7可以看出,通道數(shù)為144、尺寸為8ⅹ8的輸出特征圖,其寬和高分別擴(kuò)大了4倍,最終重建得到通道數(shù)為9、尺寸為32×32的輸出特征圖。
5 實(shí)驗(yàn)設(shè)備及指標(biāo)
5.1 實(shí)驗(yàn)設(shè)備
為驗(yàn)證本文提出的算法在實(shí)際無(wú)人貨架應(yīng)用場(chǎng)景中的有效性,設(shè)計(jì)了一系列對(duì)比實(shí)驗(yàn)。所有實(shí)驗(yàn)均在TensorFlow1.12、Python3.68、具有4塊11 GB的顯存、核心頻率1.48 GHz的NVIDIA GeForce GTX 1080服務(wù)器上運(yùn)行。
5.2 實(shí)驗(yàn)參數(shù)設(shè)置
CPM、L-CPM、EP-L-CPM 3種算法均通過(guò)均方誤差損失函數(shù)MSE(Mean Square Error)來(lái)衡量所預(yù)測(cè)的關(guān)節(jié)點(diǎn)熱力圖與真實(shí)關(guān)節(jié)點(diǎn)熱力圖之間的差異程度,其表達(dá)式如式(4)所示,并采用Adam(Adaptive moment estimation)的方式對(duì)損失函數(shù)進(jìn)行迭代優(yōu)化。同時(shí),將batch size設(shè)置為16,初始學(xué)習(xí)率設(shè)置為10-4,且學(xué)習(xí)率以指數(shù)衰減方式隨著迭代次數(shù)的增加而減小。
(4)
其中,N表示樣本的個(gè)數(shù),f(xi)與yi分別表示第i個(gè)樣本的預(yù)測(cè)值與真實(shí)值。
5.3 實(shí)驗(yàn)評(píng)價(jià)指標(biāo)
實(shí)驗(yàn)效果從精度(PCKh)、計(jì)算量(operations)和視覺(jué)效果等方面進(jìn)行評(píng)價(jià)。相關(guān)評(píng)價(jià)指標(biāo)表達(dá)式為:
(1)精度(PCKh)。
(5)
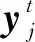
(2)計(jì)算量(operations)。
operations=2HW(CinK2+1)Cout
(6)
operations是衡量神經(jīng)網(wǎng)絡(luò)計(jì)算量的指標(biāo),單位為FLOPs,其值越小,表示網(wǎng)絡(luò)計(jì)算量越小,算法執(zhí)行速度越快。其中,Cin表示輸入特征圖的通道數(shù),H和W分別表示輸出特征圖的高和寬,K表示卷積核的大小,Cout表示輸出特征圖的通道數(shù)。
6 實(shí)驗(yàn)結(jié)果及分析
針對(duì)無(wú)人貨架實(shí)際應(yīng)用場(chǎng)景,只需對(duì)人體上半身關(guān)節(jié)點(diǎn)進(jìn)行檢測(cè)。待定位的關(guān)節(jié)點(diǎn)分別為:頸部、左肩、右肩、左肘部、右肘部、左手腕、右手腕、左手部、右手部共9個(gè)關(guān)節(jié)點(diǎn)。其中左手部為:左手食指根部、左手大拇指中部、左手中指根部3者中的一點(diǎn);右手部為:右手食指根部、右手大拇指中部、右手中指根部3者中的一點(diǎn)。
本文采用公開(kāi)人體姿態(tài)數(shù)據(jù)集(AI Challanger)和實(shí)際無(wú)人貨架場(chǎng)景人體姿態(tài)數(shù)據(jù)集來(lái)共同驗(yàn)證本文所提算法的可行性和優(yōu)越性。實(shí)驗(yàn)從精度(PCKh)、計(jì)算量(operations)和視覺(jué)效果等方面對(duì)算法進(jìn)行視覺(jué)觀察與定量對(duì)比分析。
6.1 公開(kāi)數(shù)據(jù)集上人體關(guān)節(jié)點(diǎn)定位效果分析
人體姿態(tài)數(shù)據(jù)集的復(fù)雜度取決于圖中人體肢體動(dòng)作復(fù)雜度、背景復(fù)雜度、光照影響和關(guān)節(jié)點(diǎn)是否存在遮擋等因素。影響因素越多,關(guān)節(jié)點(diǎn)定位檢測(cè)的難度越大。從公開(kāi)數(shù)據(jù)集(AI Challanger)中選取復(fù)雜程度不同的人體姿態(tài)圖像,分別使用CPM、L-CPM和EP-L-CPM算法對(duì)其進(jìn)行檢測(cè),并將關(guān)節(jié)點(diǎn)定位后的結(jié)果進(jìn)行熱力圖可視化。
圖8a~圖8c為待檢測(cè)的數(shù)據(jù)樣本,關(guān)節(jié)點(diǎn)定位檢測(cè)的難度逐漸增大,難度系數(shù)用σ表示(σ=1,2,3)。

Figure 8 Human postures to be detected in public dataset

Figure 9 Experimental results of three algorithms on public dataset (σ=1)

Figure 10 Experimental results of three algorithms on public dataset (σ=2)
圖9所示是分別使用3種算法對(duì)難度系數(shù)為σ=1的人體姿態(tài)圖定位檢測(cè)的效果。從圖9中可以看出,σ=1的人體姿態(tài)圖中的肢體動(dòng)作簡(jiǎn)單,且關(guān)節(jié)點(diǎn)之間不存在遮擋,利用3種算法均能成功檢測(cè)出全部待檢測(cè)的9個(gè)關(guān)節(jié)點(diǎn),且能精準(zhǔn)定位,初步驗(yàn)證改進(jìn)后的CPM即L-CPM和EP-L-CPM具備一定的檢測(cè)精度。圖10所示是分別使用CPM、L-CPM和EP-L-CPM 對(duì)難度系數(shù)σ=2的公開(kāi)數(shù)據(jù)樣本檢測(cè)的結(jié)果。圖10a中CPM檢測(cè)出8個(gè)關(guān)節(jié)點(diǎn),由于圖中人體左肩膀存在部分遮擋,具有一定檢測(cè)難度,因此該關(guān)節(jié)點(diǎn)出現(xiàn)漏檢。圖10b中L-CPM 算法的檢測(cè)效果要明顯優(yōu)于CPM的,左肩膀關(guān)節(jié)點(diǎn)沒(méi)有出現(xiàn)漏檢的情況,但此關(guān)節(jié)點(diǎn)的定位精度在視覺(jué)效果上不及EP-L-CPM的,位置存在偏差,定位效果存在提升空間。圖10c中EP-L-CPM 算法解決了CPM算法出現(xiàn)的問(wèn)題,視覺(jué)效果有很大的提升,9個(gè)待檢測(cè)關(guān)節(jié)點(diǎn)均被成功檢出,且實(shí)現(xiàn)了精準(zhǔn)定位。圖11a~圖11c是不同算法在難度系數(shù)為σ=3的人體姿態(tài)圖上的檢測(cè)效果。隨著檢測(cè)難度系數(shù)的增加,3種算法之間的差異逐漸擴(kuò)大。圖中人體右肩膀存在遮擋、右手部與背景相融,因此該2處關(guān)節(jié)點(diǎn)的檢測(cè)存在挑戰(zhàn)。CPM檢測(cè)效果最差,右肩膀和右手部均出現(xiàn)漏檢。L-CPM 檢測(cè)效果有所改善,僅有右手部一處出現(xiàn)漏檢。EP-L-CPM 算法不僅將9個(gè)關(guān)節(jié)點(diǎn)均成功檢出,且關(guān)節(jié)點(diǎn)定位最為精確,雖然右肩膀位置存在偏差,但也基本能達(dá)到要求,表明EP-L-CPM算法的定位效果最好。
圖12是對(duì)3種算法在不同難度系數(shù)(σ=1,2,3)的公開(kāi)數(shù)據(jù)樣本上定位效果的定量比較。在相同檢測(cè)難度水平下,數(shù)據(jù)柱從左到右依次表示CPM、L-CPM和EP-L-CPM的PCKh值。從圖12中可知,當(dāng)檢測(cè)難度較低時(shí),3種算法均能表現(xiàn)出較好的定位效果;隨著檢測(cè)難度的提高,CPM、L-CPM和EP-L-CPM的PCKh值均出現(xiàn)不同水平的下降。其中,CPM的PCKh值要明顯低于L-CPM與EP-L-CPM的,表明其定位精度最低。EP-L-CPM的PCKh值最高,表明在3種算法中,利用該算法所正確預(yù)測(cè)出的關(guān)節(jié)點(diǎn)所占比例最大,即其能檢測(cè)出最多數(shù)量的與真實(shí)標(biāo)注位置間的偏差距離在特定閾值之內(nèi)的關(guān)節(jié)點(diǎn)。
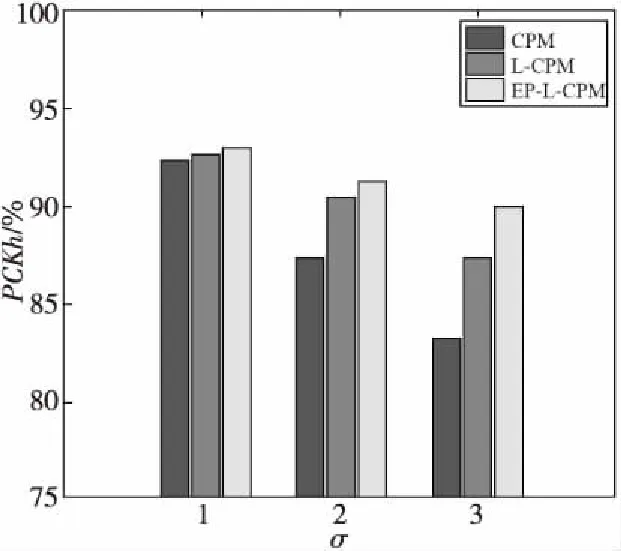
Figure 12 PCKh histogram of comparative experiment on public dataset

Figure 13 Human posture to be detected on reality scene dataset
6.2 實(shí)際無(wú)人貨架場(chǎng)景下人體關(guān)節(jié)點(diǎn)定位效果分析
為進(jìn)一步驗(yàn)證本文所提算法的性能,設(shè)計(jì)實(shí)驗(yàn)對(duì)無(wú)人貨架實(shí)際應(yīng)用場(chǎng)景中的人體姿態(tài)圖像進(jìn)行定位檢測(cè)。從實(shí)際場(chǎng)景中選取不同難度系數(shù)(σ=1,2,3)的人體姿態(tài)圖像,使用CPM、L-CPM和EP-L-CPM算法對(duì)其進(jìn)行檢測(cè),并將關(guān)節(jié)點(diǎn)定位后的結(jié)果進(jìn)行熱力圖可視化。
圖13a~圖13c為待檢測(cè)的數(shù)據(jù)樣本,關(guān)節(jié)點(diǎn)定位檢測(cè)的難度逐漸增大。圖14中是分別使用CPM、L-CPM 和EP-L-CPM對(duì)難度系數(shù)σ=1的實(shí)際場(chǎng)景數(shù)據(jù)樣本的檢測(cè)效果。由圖14a~圖14c對(duì)比可以看出,在樣本難度系數(shù)較低的水平下,3種算法的檢測(cè)效果接近,均能精確定位出待檢測(cè)的9個(gè)關(guān)節(jié)點(diǎn)。進(jìn)一步驗(yàn)證了L-CPM與EP-L-CPM算法在實(shí)際無(wú)人貨架場(chǎng)景中的有效性。

Figure 14 Experimental results of three algorithms on reality scene dataset(σ=1)
圖15a~圖15c分別對(duì)應(yīng)3種算法對(duì)難度系數(shù)為σ=2的人體姿態(tài)圖的檢測(cè)效果。由于圖中人體出現(xiàn)彎腰狀態(tài),導(dǎo)致左肘部和左手腕不易辨別,檢測(cè)存在難度。從圖15a中可以看出,CPM算法表現(xiàn)不佳,只檢測(cè)出左肘部,存在漏檢。圖15b中L-CPM算法的檢測(cè)效果較CPM有明顯的提升。其中,左肘部和左手腕關(guān)節(jié)點(diǎn)未出現(xiàn)漏檢情況,但左肘部位置定位不精確,與左手腕造成混淆,存在一定的誤差。圖15c中EP-L-CPM算法的檢測(cè)精度要明顯優(yōu)于CPM的,左肘部和左手腕2個(gè)檢測(cè)難度最高的關(guān)節(jié)點(diǎn)均被成功檢出,且實(shí)現(xiàn)了精準(zhǔn)定位。

Figure 15 Experimental results of three algorithms on reality scene dataset(σ=2)
再次使用3種算法對(duì)難度系數(shù)σ=3的人體姿態(tài)圖進(jìn)行檢測(cè)。圖中人體衣著為純黑色且呈彎腰狀態(tài),使得右肘部不僅難以辨別且與背景顏色融為一體;另外,左手腕存在部分遮擋,因此該2處關(guān)節(jié)點(diǎn)的檢測(cè)存在難度。根據(jù)圖16a~圖16c中的視覺(jué)效果,將3種算法按精度升序進(jìn)行排列為:CPM、L-CPM、EP-L-CPM。圖16c中L-CPM算法精確定位出5個(gè)關(guān)節(jié)點(diǎn),左手腕出現(xiàn)漏檢。圖16b中EP-L-CPM算法將6個(gè)關(guān)節(jié)點(diǎn)均成功檢出,雖然左手腕位置存在偏差,但基本上滿(mǎn)足要求。圖16c中L-CPM算法精確定位出5個(gè)關(guān)節(jié)點(diǎn),左手腕出現(xiàn)漏檢。該實(shí)驗(yàn)也間接證明了在實(shí)際場(chǎng)景的定位檢測(cè)中,EP-L-CPM的效果最優(yōu)。

Figure 16 Experimental results of three algorithms on reality scene dataset(σ=3)
圖17是3種算法對(duì)不同難度系數(shù)(σ=1,2,3)的實(shí)際場(chǎng)景人體姿態(tài)圖檢測(cè)效果的定量評(píng)價(jià)指標(biāo)。在相同檢測(cè)難度水平下,數(shù)據(jù)柱從左到右依次表示CPM、L-CPM、EP-L-CPM的PCKh值。從圖17中可以看出,當(dāng)σ=1時(shí),CPM的表現(xiàn)要稍差于L-CPM與EP-L-CPM,但差異較小;隨著檢測(cè)難度的增加,差異逐漸增大,CPM的定位精度明顯低于L-CPM和EP-L-CPM的。其中,EP-L-CPM的定位精度最高,L-CPM的檢測(cè)效果不及EP-L-CPM的。
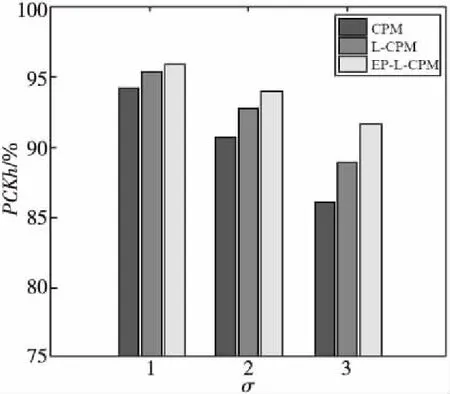
Figure 17 PCKh histogram of comparative experiment on reality scene dataset
6.3 算法性能評(píng)估及分析
本節(jié)從精度(PCKh)和計(jì)算量(operations)2個(gè)評(píng)價(jià)指標(biāo)出發(fā),對(duì)CPM、L-CPM和EP-L-CPM 3種定位算法的性能進(jìn)行定量分析。其中,計(jì)算量(operations)用來(lái)統(tǒng)計(jì)算法的浮點(diǎn)計(jì)算次數(shù),具體數(shù)值通過(guò)調(diào)用TensorFlow中的profiler.ProfileOptionBuilder.float_operation與profiler.Profile 2個(gè)API所得。為使3種定位算法的計(jì)算量對(duì)比更加直觀,將FLOPs轉(zhuǎn)換為GFLOPs的形式進(jìn)行分析(1 GFLOPs=109FLOPs)。由表1可以看出,CPM的定位精度最低,計(jì)算量最大。L-CPM在結(jié)合MobileNet與下采樣的優(yōu)勢(shì)后,計(jì)算量明顯下降,且定位精度得到進(jìn)一步提高,彌補(bǔ)了CPM的不足。其中,L-CPM 算法的精度為89.79%,較CPM有4.52%的提升,其計(jì)算量為CPM的1/64,成功實(shí)現(xiàn)了輕量化。EP-L-CPM在L-CPM的基礎(chǔ)上引入ESPCN,算法精度為92.46%,較L-CPM有2.67%的提升,有效彌補(bǔ)了L-CPM因通過(guò)下采樣來(lái)減小特征圖分辨率而出現(xiàn)的精度損失;另外,EP-L-CPM在3種算法中計(jì)算量最少,分析其原因是ESPCN利用亞像素卷積操作重建高分辨率特征圖恢復(fù)丟失特征信息的過(guò)程,為像素點(diǎn)的重新排列,因?qū)嶋H沒(méi)有進(jìn)行卷積,所以并未引入過(guò)多的計(jì)算量。綜合算法精度與計(jì)算量大小因素,EP-L-CPM在實(shí)際場(chǎng)景中的應(yīng)用優(yōu)勢(shì)更加明顯。因此,實(shí)驗(yàn)表現(xiàn)和理論分析表明了本文提出的L-CPM和EP-L-CPM算法的有效性和優(yōu)越性,在提高關(guān)節(jié)點(diǎn)定位精度的同時(shí),能最大限度地減少算法計(jì)算量。
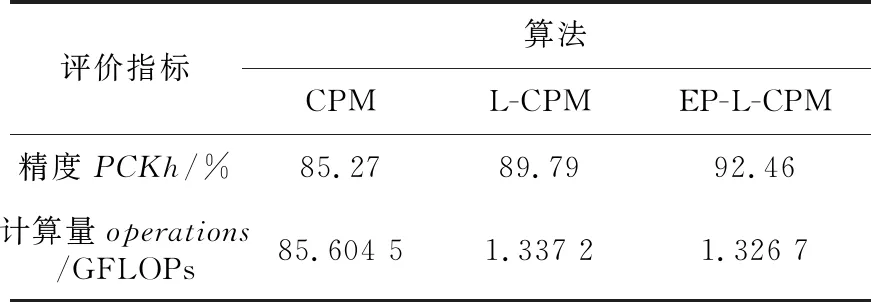
Table 1 Performance evaluation of different algorithms
7 結(jié)束語(yǔ)
本文將CPM、MobileNet、下采樣和ESPCN進(jìn)行優(yōu)勢(shì)結(jié)合,提出了L-CPM和EP-L-CPM算法并進(jìn)行了充分的對(duì)比實(shí)驗(yàn),驗(yàn)證了L-CPM和EP-L-CPM算法對(duì)各種人體姿態(tài)圖的定位檢測(cè)效果。根據(jù)本文中的理論分析和實(shí)驗(yàn)結(jié)果可以得出如下結(jié)論:
(1)L-CPM確實(shí)能夠有效結(jié)合CPM、MobileNet和下采樣的優(yōu)勢(shì),與單獨(dú)的CPM相比,L-CPM可以更精確地定位人體關(guān)節(jié)點(diǎn),且計(jì)算量顯著下降。
(2)EP-L-CPM作為L(zhǎng)-CPM的優(yōu)化算法,有效結(jié)合了L-CPM和ESPCN的優(yōu)勢(shì),從視覺(jué)效果與定量指標(biāo)2方面分析,EP-L-CPM較L-CPM具有更高的定位精度;且ESPCN中的亞像素卷積優(yōu)勢(shì),使EP-L-CPM的計(jì)算量在L-CPM的基礎(chǔ)上進(jìn)一步減少,表明了該算法的優(yōu)越性。
(3)綜合多種因素,EP-L-CPM是具有更高檢測(cè)精度和更小計(jì)算量的人體關(guān)節(jié)點(diǎn)定位算法,在實(shí)際應(yīng)用中具有突出的優(yōu)勢(shì)。
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
