基于樞軸語(yǔ)言的漢越神經(jīng)機(jī)器翻譯偽平行語(yǔ)料生成*
2021-04-06 10:48:28賈承勛余正濤文永華于志強(qiáng)
計(jì)算機(jī)工程與科學(xué) 2021年3期
賈承勛,賴 華,余正濤,文永華,于志強(qiáng)
(1.昆明理工大學(xué)信息工程與自動(dòng)化學(xué)院,云南 昆明 650500;2.昆明理工大學(xué)云南省人工智能重點(diǎn)實(shí)驗(yàn)室,云南 昆明 650500)
1 引言
神經(jīng)機(jī)器翻譯NMT(Neural Machine Translation)是目前機(jī)器翻譯領(lǐng)域的熱點(diǎn)研究方法,相較于統(tǒng)計(jì)機(jī)器翻譯SMT(Statistical Machine Translation)[1],神經(jīng)機(jī)器翻譯在大量的平行句對(duì)上取得了更好的翻譯效果[2,3],但是神經(jīng)機(jī)器翻譯在平行語(yǔ)料匱乏的低資源環(huán)境下,效果并不理想[4]。為緩解語(yǔ)料缺乏困境,早期研究者們利用人工標(biāo)注方式擴(kuò)充語(yǔ)料,然而人工標(biāo)注具有周期長(zhǎng)、成本高的缺點(diǎn),因此研究者們開(kāi)始關(guān)注語(yǔ)料的自動(dòng)擴(kuò)充方法[5]。漢語(yǔ)-越南語(yǔ)是典型的低資源語(yǔ)言對(duì),漢越神經(jīng)機(jī)器翻譯同樣面臨數(shù)據(jù)稀缺問(wèn)題[6],這一問(wèn)題嚴(yán)重影響神經(jīng)機(jī)器翻譯在實(shí)際中的應(yīng)用,因此如何通過(guò)語(yǔ)料擴(kuò)充手段改善漢越神經(jīng)機(jī)器翻譯的性能是值得研究的問(wèn)題。
目前通過(guò)生成偽平行數(shù)據(jù)緩解數(shù)據(jù)稀疏問(wèn)題,是低資源神經(jīng)機(jī)器翻譯的一個(gè)重要研究方向[7]。對(duì)于偽平行數(shù)據(jù)擴(kuò)充的研究,目前主要有2種方式:抽取式和生成式。抽取式是根據(jù)一定規(guī)則從可比語(yǔ)料、樞軸語(yǔ)料或者2種語(yǔ)言的單語(yǔ)語(yǔ)料中抽取偽平行語(yǔ)料[8 - 11];生成式是在已有小規(guī)模平行語(yǔ)料的前提下,通過(guò)詞的替換、單語(yǔ)數(shù)據(jù)回譯[12]和建立樞軸模型等方法,生成更多的偽平行數(shù)據(jù)[12 - 14]。
目前基于生成式的偽平行數(shù)據(jù)擴(kuò)充方法的有效性已經(jīng)得到了充分驗(yàn)證,但缺少對(duì)這些方法融合利用方面的研究。
因此,本文針對(duì)漢越神經(jīng)機(jī)器翻譯任務(wù),對(duì)基于詞的替換、單語(yǔ)數(shù)據(jù)回譯和基于樞軸語(yǔ)言3種生成式方法的融合利用進(jìn)行研究。在基于樞軸語(yǔ)言方法的基礎(chǔ)上,將詞替換和回譯2種方法融合進(jìn)來(lái),在樞軸方法生成偽平行數(shù)據(jù)的過(guò)程中,生成質(zhì)量更優(yōu)的漢越偽平行數(shù)據(jù),然后利用語(yǔ)言模型對(duì)生成的偽平行數(shù)據(jù)進(jìn)行篩選,優(yōu)化偽平行數(shù)據(jù)的質(zhì)量。實(shí)驗(yàn)表明,本文方法相比單一的生成式方法性能有明顯提高。
2 相關(guān)工作
近年來(lái),國(guó)內(nèi)外相關(guān)研究人員針對(duì)小規(guī)模平行語(yǔ)料進(jìn)行偽平行語(yǔ)料生成的方法進(jìn)行了廣泛研究,并取得了一系列成果。目前在神經(jīng)機(jī)器翻譯中能有效生成偽平行數(shù)據(jù)的方法主要有3種。
第1種是基于詞的替換方法。Fadaee等人[15]利用基于詞替換的翻譯數(shù)據(jù)增強(qiáng)技術(shù)TDA(Translation Data Augmentation),通過(guò)將平行句對(duì)中的高頻詞替換為平行句對(duì)中的低頻詞,從而得到新的偽平行句對(duì),但是當(dāng)出現(xiàn)一詞多譯的情況時(shí)效果不佳,且易出現(xiàn)噪聲;蔡子龍等人[16]首先對(duì)句子進(jìn)行分塊,找出句子中的最小翻譯單元MTU(Minimum Translation Unit),然后找到句子中最相似的2個(gè)模塊,通過(guò)對(duì)調(diào)他們的位置生成新的偽平行句對(duì),但是容易產(chǎn)生語(yǔ)法語(yǔ)義上的錯(cuò)誤,使偽平行數(shù)據(jù)質(zhì)量不佳。
第2種是利用單語(yǔ)數(shù)據(jù)進(jìn)行回譯的方法。Sennrich等人[12]利用現(xiàn)有的神經(jīng)機(jī)器翻譯模型提出了回譯方法(Back-Translation),通過(guò)利用已有的小規(guī)模平行句對(duì)訓(xùn)練2個(gè)不同翻譯方向的神經(jīng)機(jī)器翻譯模型,將目標(biāo)端單語(yǔ)數(shù)據(jù)翻譯成源語(yǔ)言,從而構(gòu)成偽平行數(shù)據(jù)。此方法有效提高了翻譯性能,但是嚴(yán)重依賴于小規(guī)模平行句對(duì)的質(zhì)量,并且不能解決零資源語(yǔ)言的數(shù)據(jù)稀疏問(wèn)題。
第3種是利用樞軸語(yǔ)言連接源語(yǔ)言和目標(biāo)語(yǔ)言的方法[17,18],使用源-樞軸模型將源語(yǔ)言翻譯成樞軸語(yǔ)言,然后使用樞軸目標(biāo)模型將樞軸語(yǔ)言翻譯成目標(biāo)語(yǔ)言,具體流程如圖1所示。Johnson等人[5]對(duì)基于樞軸的神經(jīng)機(jī)器翻譯方法進(jìn)行了改進(jìn),并表明基于樞軸的神經(jīng)機(jī)器翻譯的翻譯性能比無(wú)需增量訓(xùn)練的通用模型更好,該方法有效解決了零資源或只有小規(guī)模平行語(yǔ)料語(yǔ)言的數(shù)據(jù)稀疏問(wèn)題。李強(qiáng)等人[19]在統(tǒng)計(jì)機(jī)器翻譯上將樞軸方法分為系統(tǒng)級(jí)、語(yǔ)料級(jí)和短語(yǔ)級(jí)3種方法,通過(guò)擴(kuò)大生成訓(xùn)練數(shù)據(jù)的規(guī)模以及優(yōu)化詞對(duì)齊質(zhì)量的方式來(lái)提高翻譯性能。Wu等人[20]通過(guò)對(duì)雙語(yǔ)數(shù)據(jù)中的單語(yǔ)語(yǔ)料進(jìn)行翻譯的方法直接優(yōu)化最終的翻譯性能,即語(yǔ)料級(jí)的樞軸方法中,翻譯模型中所有參數(shù)的調(diào)優(yōu)直接通過(guò)優(yōu)化漢語(yǔ)至低資源語(yǔ)言的翻譯來(lái)完成,翻譯過(guò)程如圖2所示。
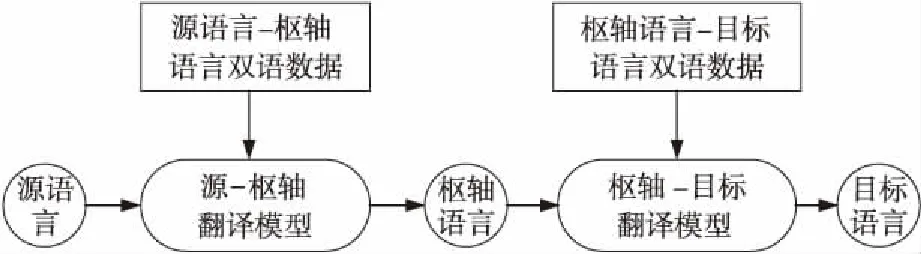
Figure 1 Flowchart of traditional pivot language method
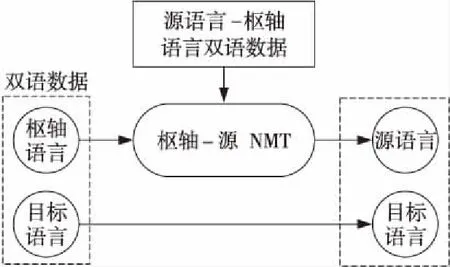
Figure 2 Flowchart of corpus-level approach to pivot translation
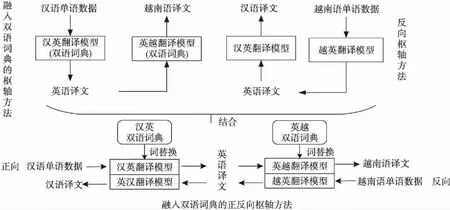
Figure 3 Flowchart of the method for generating pseudo-parallel data
在生成偽平行語(yǔ)料的方法中,使用樞軸語(yǔ)言連接源語(yǔ)言和目標(biāo)語(yǔ)言是一個(gè)重要方向,由于其簡(jiǎn)單有效,在傳統(tǒng)的統(tǒng)計(jì)機(jī)器翻譯中也被廣泛使用[18]。在神經(jīng)機(jī)器翻譯中,基于樞軸語(yǔ)言的方法已經(jīng)普遍用于偽平行數(shù)據(jù)的生成,但這種基于樞軸的方法通常需要將解碼過(guò)程分成2個(gè)步驟,第一個(gè)模型中出現(xiàn)翻譯錯(cuò)誤,會(huì)直接影響到下一個(gè)模型的訓(xùn)練效果,從而增加數(shù)據(jù)的模糊性。
目前3種生成式方法都有各自的優(yōu)勢(shì)和不足,目前還沒(méi)有將這些方法進(jìn)行融合的研究,因此本文在將生成式方法相結(jié)合的基礎(chǔ)上,提出了融入雙語(yǔ)詞典的正反向樞軸方法。首先,針對(duì)基于樞軸的方法存在許多無(wú)法有效翻譯的詞和短語(yǔ),會(huì)使翻譯錯(cuò)誤連續(xù)傳遞,影響生成的偽平行數(shù)據(jù)的質(zhì)量,同時(shí)無(wú)法在所有的翻譯任務(wù)上都獲得最優(yōu)的翻譯性能的問(wèn)題,本文對(duì)源語(yǔ)言單語(yǔ)數(shù)據(jù)進(jìn)行一次正向的樞軸語(yǔ)言翻譯生成偽平行數(shù)據(jù)后,再對(duì)目標(biāo)語(yǔ)言的單語(yǔ)數(shù)據(jù)進(jìn)行一次反向的傳統(tǒng)樞軸語(yǔ)言方法的翻譯過(guò)程,以此實(shí)現(xiàn)樞軸語(yǔ)言方法和回譯方法的結(jié)合;其次,在上述改進(jìn)的基礎(chǔ)上,通過(guò)構(gòu)建雙語(yǔ)詞典[21]進(jìn)行稀有詞的替換,將雙語(yǔ)詞典輸入到源-樞軸和樞軸-目標(biāo)的神經(jīng)機(jī)器翻譯模型中訓(xùn)練,將樞軸方法、回譯和詞替換3種方法結(jié)合并生成更多的偽平行數(shù)據(jù);最后將生成的偽平行數(shù)據(jù)通過(guò)語(yǔ)言模型進(jìn)行篩選,將篩選后的偽平行數(shù)據(jù)與原始數(shù)據(jù)混合進(jìn)行模型訓(xùn)練。
3 漢越偽平行數(shù)據(jù)生成方法
目前在神經(jīng)機(jī)器翻譯的樞軸語(yǔ)言方法中,并沒(méi)有在詞級(jí)上對(duì)樞軸方法進(jìn)行分析,針對(duì)其存在的問(wèn)題,本文結(jié)合了詞替換的思想,在樞軸方法的基礎(chǔ)上融入利用稀有詞構(gòu)建的雙語(yǔ)詞典,減小了詞和短語(yǔ)翻譯錯(cuò)誤的幾率,從而緩解錯(cuò)誤傳播的問(wèn)題;針對(duì)零資源語(yǔ)言的數(shù)據(jù)稀疏問(wèn)題,將樞軸方法與回譯方法相結(jié)合,進(jìn)行一次反向的樞軸翻譯過(guò)程,即按照目標(biāo)→樞軸→源的方向再次對(duì)數(shù)據(jù)進(jìn)行擴(kuò)充;融入雙語(yǔ)詞典的正反向樞軸方法是一種將詞替換方法、回譯方法和樞軸語(yǔ)言方法結(jié)合利用的方法。樞軸語(yǔ)言的選擇對(duì)基于樞軸語(yǔ)言的方法有著至關(guān)重要的影響,需要選擇同時(shí)與源語(yǔ)言和目標(biāo)語(yǔ)言都具有大量可利用數(shù)據(jù)資源的語(yǔ)言作為樞軸語(yǔ)言。本文源語(yǔ)言為漢語(yǔ),目標(biāo)語(yǔ)言為越南語(yǔ),由于漢英、英越機(jī)器翻譯可以獲得大規(guī)模高質(zhì)量的平行語(yǔ)料,因此以英語(yǔ)作為樞軸語(yǔ)言對(duì)漢越偽平行語(yǔ)料生成方法展開(kāi)研究。
圖3中漢英翻譯模型和英漢翻譯模型為利用同一訓(xùn)練數(shù)據(jù)訓(xùn)練的神經(jīng)機(jī)器翻譯模型,同理英越和越英翻譯模型。本文結(jié)合了詞替換的思想,在樞軸方法的基礎(chǔ)上融入了利用稀有詞構(gòu)建的雙語(yǔ)詞典,減小了詞和短語(yǔ)翻譯錯(cuò)誤的幾率,從而緩解錯(cuò)誤傳遞問(wèn)題;針對(duì)零資源語(yǔ)言數(shù)據(jù)稀疏問(wèn)題,在樞軸方法的基礎(chǔ)上與回譯方法相結(jié)合,在正向樞軸翻譯后再利用額外的越南語(yǔ)數(shù)據(jù)進(jìn)行反向的樞軸翻譯,即按照目標(biāo)→樞軸→源的方向再次對(duì)數(shù)據(jù)進(jìn)行擴(kuò)充;而在此方法基礎(chǔ)上將雙語(yǔ)詞典結(jié)合進(jìn)來(lái),在翻譯數(shù)據(jù)的過(guò)程中進(jìn)行稀有詞的替換,這便是本文提出的融入雙語(yǔ)詞典的正反向樞軸方法。
3.1 融入雙語(yǔ)詞典的樞軸方法
本文利用稀有詞,即常規(guī)詞表以外的詞來(lái)構(gòu)建雙語(yǔ)詞典。使用GIZA++工具對(duì)語(yǔ)料進(jìn)行對(duì)齊處理得到對(duì)齊結(jié)果,排除常規(guī)詞表內(nèi)的詞來(lái)構(gòu)建雙語(yǔ)詞典,對(duì)于一詞多譯的情況,只保留對(duì)齊概率最大的詞。本文使用Li等人[22]的方法在模型翻譯過(guò)程中融入雙語(yǔ)詞典進(jìn)行詞的替換。
在傳統(tǒng)的樞軸語(yǔ)言方法中采取2種不同的方式結(jié)合雙語(yǔ)詞典,第1種是利用現(xiàn)有數(shù)據(jù)構(gòu)建出源到樞軸的雙語(yǔ)詞典SP(Source to Pivot)和樞軸到目標(biāo)語(yǔ)言的雙語(yǔ)詞典PT(Pivot to Target),將2個(gè)雙語(yǔ)詞典直接融入到相應(yīng)的模型中;第2種是在第1種方法的基礎(chǔ)上,將2個(gè)雙語(yǔ)詞典相結(jié)合,將其中英語(yǔ)部分相同的詞保留,對(duì)不包含在原詞典的英語(yǔ)詞進(jìn)行人工整理。例如,“Monday”這個(gè)詞既存在詞典SP中又存在于詞典PT中,則保留,而“Jesus”這個(gè)詞只存在于詞典PT中,則將其人工添加到詞典SP中,如圖4所示。整合后得到的雙語(yǔ)詞典命名為SPT(Source to Pivot add Target)和PTS(Pivot to Target add Source),然后將其融入到相應(yīng)的模型中。
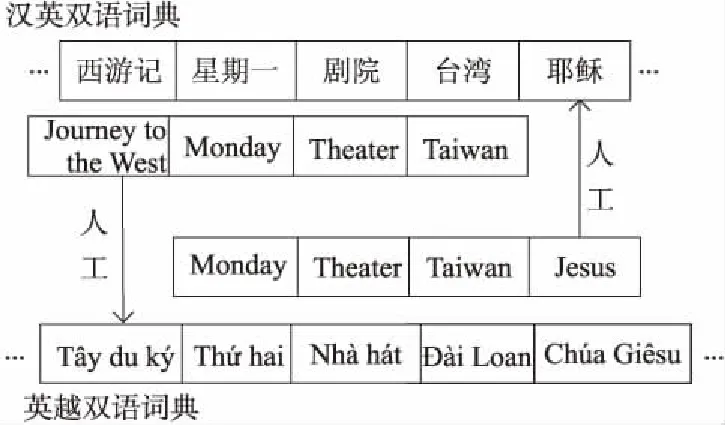
Figure 4 Building integrated bilingual dictionary
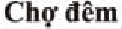
Figure 5 Comparison of traditional pivot language method and integrated bilingual dictionary pivot method
3.2 反向樞軸方法
在對(duì)生成偽平行數(shù)據(jù)的方法進(jìn)行結(jié)合時(shí),為了進(jìn)一步提升生成數(shù)據(jù)的數(shù)量,本文將結(jié)合回譯的思想。在執(zhí)行原樞軸方向的基礎(chǔ)上,直接進(jìn)行目標(biāo)到源語(yǔ)言的回譯會(huì)受到2種語(yǔ)言之間數(shù)據(jù)稀缺性和形態(tài)差異的影響,因此也可以將這個(gè)過(guò)程分為2個(gè)簡(jiǎn)單的步驟。原樞軸方向?yàn)樵础鷺休S→目標(biāo),進(jìn)行回譯的反向樞軸即為目標(biāo)→樞軸→源方向,如圖6所示。
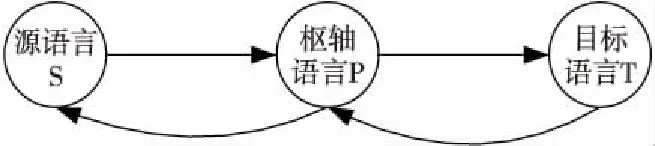
Figure 6 Combination of pivot and back-translation
首先將目標(biāo)語(yǔ)言單語(yǔ)數(shù)據(jù)翻譯為樞軸語(yǔ)言,然后再將其翻譯為源語(yǔ)言,形成偽平行數(shù)據(jù),最后與正向樞軸生成的偽數(shù)據(jù)混合。此方法的優(yōu)點(diǎn)是可以直接建模,并且不需修改模型框架及參數(shù),存在大量的目標(biāo)語(yǔ)言T到樞軸語(yǔ)言P的雙語(yǔ)數(shù)據(jù)集,可以利用目標(biāo)語(yǔ)言單語(yǔ)數(shù)據(jù)生成更多的偽平行數(shù)據(jù)。圖7為利用越南語(yǔ)句子反向樞軸生成偽平行句子的流程示例。
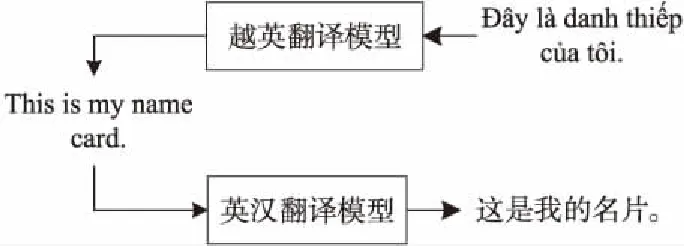
Figure 7 Example of reverse pivot process
利用越英翻譯模型將越南語(yǔ)單語(yǔ)數(shù)據(jù)翻譯成英語(yǔ),然后通過(guò)英漢翻譯模型將其翻譯成漢語(yǔ)數(shù)據(jù),以此反向樞軸生成偽平行數(shù)據(jù),并與正向樞軸方法生成的偽平行數(shù)據(jù)一起與原始數(shù)據(jù)混合進(jìn)行模型訓(xùn)練。
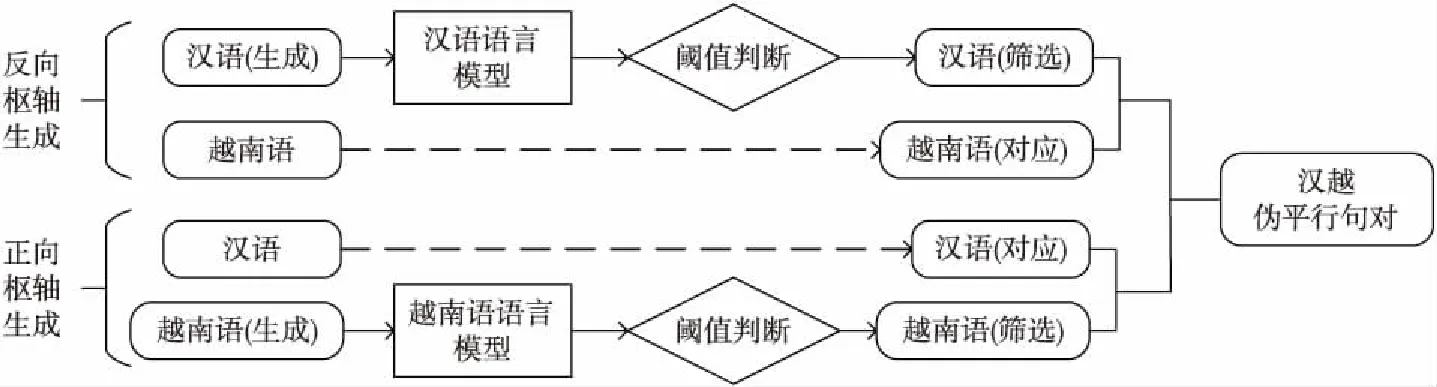
Figure 8 Filtering pseudo-parallel sentences by language model
3.3 融入雙語(yǔ)詞典的正反向樞軸方法
對(duì)于詞替換、回譯和樞軸3種方法的結(jié)合,是在樞軸方法融入雙語(yǔ)詞典的基礎(chǔ)上,執(zhí)行反向樞軸的翻譯過(guò)程,與單純的反向樞軸方法不同的是,此次結(jié)合在反向樞軸的過(guò)程中融入了雙語(yǔ)詞典,可以較好地利用源語(yǔ)言和目標(biāo)語(yǔ)言單語(yǔ)數(shù)據(jù),同時(shí)可以有效地減少兩步翻譯的錯(cuò)誤傳遞,提升反向樞軸生成的偽平行數(shù)據(jù)的質(zhì)量,以此生成更多質(zhì)量較高的偽數(shù)據(jù),與正向樞軸翻譯生成的數(shù)據(jù)混合,然后進(jìn)行模型訓(xùn)練。
本文方法的整體流程如圖3所示,將雙語(yǔ)詞典分別融入到對(duì)應(yīng)的模型中,然后將漢語(yǔ)單語(yǔ)數(shù)據(jù)通過(guò)漢英翻譯模型翻譯為英語(yǔ)譯文,再通過(guò)英越翻譯模型翻譯為越南語(yǔ)譯文,以此正向樞軸方法生成偽平行數(shù)據(jù);其次將越南語(yǔ)單語(yǔ)數(shù)據(jù)通過(guò)越英翻譯模型翻譯為英語(yǔ)譯文,再通過(guò)英漢翻譯模型翻譯為漢語(yǔ)譯文,以此反向樞軸生成偽平行數(shù)據(jù)。最后將生成的偽平行數(shù)據(jù)與原始數(shù)據(jù)混合訓(xùn)練漢越神經(jīng)機(jī)器翻譯模型。
3.4 基于語(yǔ)言模型的偽平行數(shù)據(jù)篩選
通過(guò)融入雙語(yǔ)詞典的正反向樞軸方法可以生成新的偽平行數(shù)據(jù),但在低資源環(huán)境中很難有效地訓(xùn)練良好的回譯模型,并且引入樞軸方法可能會(huì)產(chǎn)生部分語(yǔ)義問(wèn)題,難免會(huì)增加數(shù)據(jù)的噪聲,噪聲的存在可能會(huì)降低源語(yǔ)言-目標(biāo)低資源語(yǔ)言的翻譯性能。為改善這一問(wèn)題,本文利用語(yǔ)言模型對(duì)生成的偽平行數(shù)據(jù)進(jìn)行篩選。由于循環(huán)神經(jīng)網(wǎng)絡(luò)RNN(Recurrent Neural Network)可以將每個(gè)詞映射到一個(gè)緊湊的連續(xù)向量空間,該空間使用相對(duì)小的參數(shù)集合并使用循環(huán)連接來(lái)建模長(zhǎng)距離上下文依賴,因此本文選用循環(huán)神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型RNNLM(Recurrent Neural Network Language Model)[23]進(jìn)行偽平行數(shù)據(jù)的篩選,具體流程如圖8所示。
首先利用大量漢語(yǔ)和越南語(yǔ)分別訓(xùn)練漢語(yǔ)語(yǔ)言模型和越南語(yǔ)語(yǔ)言模型,通過(guò)訓(xùn)練的語(yǔ)言模型對(duì)翻譯生成的句子進(jìn)行打分,利用預(yù)先訓(xùn)練的漢語(yǔ)語(yǔ)言模型對(duì)反向樞軸生成的偽平行句對(duì)中的漢語(yǔ)句子進(jìn)行打分,利用訓(xùn)練的越南語(yǔ)語(yǔ)言模型對(duì)正向樞軸方法生成的偽平行句對(duì)中的越南語(yǔ)句子進(jìn)行打分,通過(guò)設(shè)置一個(gè)合理的閾值,將評(píng)分低于此值的句子刪除,以此實(shí)現(xiàn)偽平行數(shù)據(jù)的篩選,從而可以減少訓(xùn)練模型的計(jì)算次數(shù),同時(shí)降低時(shí)間復(fù)雜度。用篩選后得到的偽平行數(shù)據(jù)與原始數(shù)據(jù)一起訓(xùn)練最終的漢越神經(jīng)機(jī)器翻譯模型。
4 實(shí)驗(yàn)及結(jié)果分析
4.1 實(shí)驗(yàn)設(shè)置
實(shí)驗(yàn)中傳統(tǒng)樞軸方法和語(yǔ)料級(jí)方法中使用的漢英雙語(yǔ)數(shù)據(jù)均來(lái)自WMT2017(Workshop on Machine Translation 2017),使用的英越雙語(yǔ)數(shù)據(jù)同樣來(lái)自WMT2017,生成漢越偽平行數(shù)據(jù)使用的漢語(yǔ)單語(yǔ)數(shù)據(jù)來(lái)自TED2013(Technology Entertainment Design 2013)中漢語(yǔ)數(shù)據(jù)的前10萬(wàn)句,反向樞軸中使用的越南語(yǔ)單語(yǔ)數(shù)據(jù)來(lái)自Wikipedia。實(shí)驗(yàn)樞軸語(yǔ)言均為英語(yǔ),其中各個(gè)實(shí)驗(yàn)步驟的數(shù)據(jù)如表1所示。
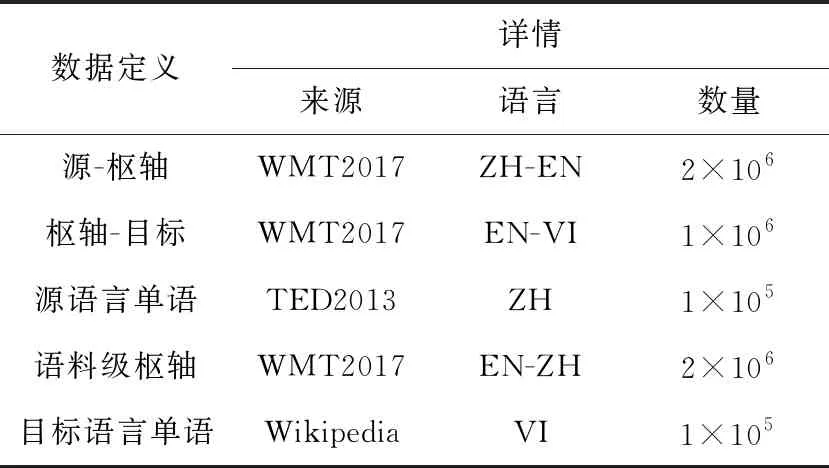
Table 1 Experimental data
通過(guò)網(wǎng)絡(luò)爬蟲(chóng)獲取漢越數(shù)據(jù),在進(jìn)行實(shí)驗(yàn)之前對(duì)語(yǔ)料做了清洗和Tokenizaiton處理,除去空行并過(guò)濾長(zhǎng)度大于50的句子,最終獲得183 000個(gè)漢越雙語(yǔ)平行句對(duì)。使用結(jié)巴分詞工具對(duì)漢語(yǔ)數(shù)據(jù)進(jìn)行分詞處理,從原始雙語(yǔ)數(shù)據(jù)中分別隨機(jī)抽取1 500個(gè)平行句對(duì)作為實(shí)驗(yàn)的驗(yàn)證集和測(cè)試集。并將與偽平行數(shù)據(jù)一起訓(xùn)練翻譯模型的原始數(shù)據(jù)分為10萬(wàn)和18萬(wàn)分別進(jìn)行實(shí)驗(yàn),采用原始數(shù)據(jù)直接訓(xùn)練的回譯方法、詞典替換方法和傳統(tǒng)樞軸方法作為基準(zhǔn)實(shí)驗(yàn)(baseline),其中詞表大小設(shè)置為30 000,為防止出現(xiàn)過(guò)擬合現(xiàn)象,在多次實(shí)驗(yàn)調(diào)整后將迭代損失值設(shè)置為0.1,批大小為128,隱藏單元大小為512,輪次為20,訓(xùn)練步長(zhǎng)為2×105,使用BLEU4作為評(píng)測(cè)指標(biāo)。
4.2 實(shí)驗(yàn)結(jié)果
實(shí)驗(yàn)均利用Transformer模型架構(gòu)進(jìn)行本文所有翻譯模型的訓(xùn)練。傳統(tǒng)的樞軸方法利用漢英200萬(wàn)平行語(yǔ)料和英越100萬(wàn)平行語(yǔ)料訓(xùn)練模型,回譯和詞典替換方法則使用10萬(wàn)原始漢越雙語(yǔ)語(yǔ)料進(jìn)行訓(xùn)練。為了驗(yàn)證生成的偽平行數(shù)據(jù)的有效性,利用語(yǔ)言模型對(duì)生成的偽平行數(shù)據(jù)進(jìn)行篩選,然后與原始數(shù)據(jù)混合打亂一起訓(xùn)練最終的漢越神經(jīng)機(jī)器翻譯模型,為了測(cè)試與不同語(yǔ)料規(guī)模的數(shù)據(jù)混合生成的偽平行數(shù)據(jù)的有效性,還設(shè)置了在18萬(wàn)規(guī)模的數(shù)據(jù)集中添加偽平行數(shù)據(jù)的對(duì)比實(shí)驗(yàn)。為了保證實(shí)驗(yàn)結(jié)果的可靠性,每組的實(shí)驗(yàn)結(jié)果的BLEU值都是利用相同測(cè)試集進(jìn)行實(shí)驗(yàn)得到的,實(shí)驗(yàn)結(jié)果如表2所示。
實(shí)驗(yàn)結(jié)果可分為2個(gè)部分,第1~5行是基準(zhǔn)實(shí)驗(yàn),第6~9行是利用語(yǔ)言模型對(duì)本文方法生成的偽平行數(shù)據(jù)進(jìn)行篩選后與不同規(guī)模的平行雙語(yǔ)數(shù)據(jù)進(jìn)行混合訓(xùn)練的實(shí)驗(yàn)結(jié)果,是對(duì)漢越神經(jīng)機(jī)器翻譯性能提升效果的驗(yàn)證。由實(shí)驗(yàn)結(jié)果可知,利用融入雙語(yǔ)詞典并結(jié)合回譯的樞軸方法生成的偽平行數(shù)據(jù)進(jìn)行訓(xùn)練,提升效果最好,經(jīng)過(guò)語(yǔ)言模型篩選后,性能獲得了進(jìn)一步提升。第6行為融入雙語(yǔ)詞典的樞軸方法,在10萬(wàn)的數(shù)據(jù)集上比傳統(tǒng)樞軸方法的BLEU值高0.33,相比直接訓(xùn)練的模型提高了0.61,在18萬(wàn)的數(shù)據(jù)集上相比直接訓(xùn)練的模型的BLEU值提高了0.48;第7行為融入了整合后雙語(yǔ)詞典的樞軸方法,效果比傳統(tǒng)樞軸方法的BLEU值提高了0.43,并且在10萬(wàn)和18萬(wàn)的數(shù)據(jù)集上的對(duì)比都具有較好的改進(jìn)效果;第8行為反向樞軸的方法,同樣具有較好的改進(jìn)效果,但由于反向樞軸生成的偽平行數(shù)據(jù)質(zhì)量不佳,因此提升效果相對(duì)于單回譯方法略低一點(diǎn);第9行為融入雙語(yǔ)詞典的正反向樞軸方法,使用的漢語(yǔ)和越南語(yǔ)單語(yǔ)數(shù)據(jù)均為10萬(wàn),相比傳統(tǒng)樞軸方法的BLEU值提升了0.64,在18萬(wàn)的數(shù)據(jù)集上依然可以取得較好的提升,相對(duì)于直接訓(xùn)練BLEU值提升了0.89,取得了最好的翻譯效果。
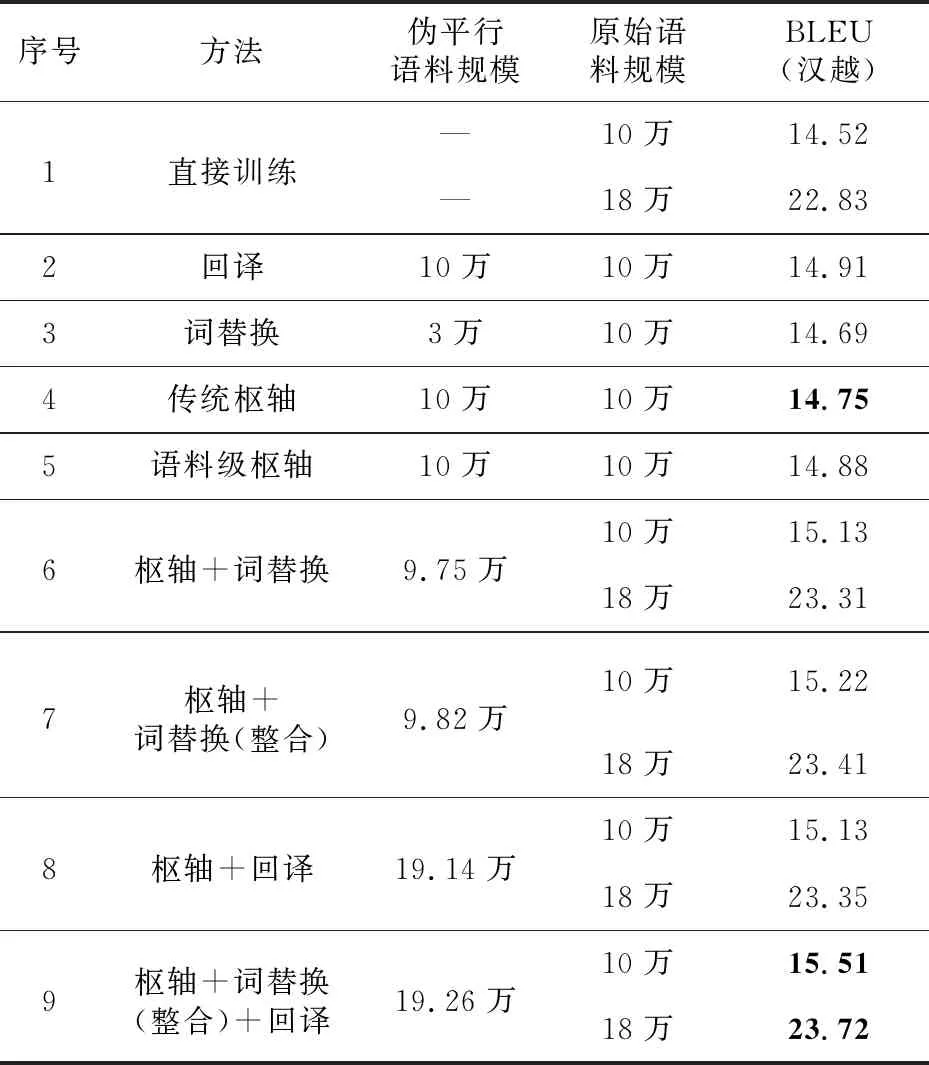
Table 2 Experimental results comparison between the generative methods and proposed method
4.3 實(shí)驗(yàn)對(duì)比分析
由實(shí)驗(yàn)結(jié)果可知,在樞軸語(yǔ)言方法中融入雙語(yǔ)詞典后翻譯性能總體都有所提升,將雙語(yǔ)詞典進(jìn)行整合后融入樞軸翻譯方法中,可以進(jìn)一步提升漢越神經(jīng)機(jī)器翻譯模型的性能。翻譯性能與訓(xùn)練數(shù)據(jù)的數(shù)量、質(zhì)量以及語(yǔ)言本身的差異性息息相關(guān),為了更好地分析本文方法生成的偽平行數(shù)據(jù)提升翻譯性能的原因,本文對(duì)生成的偽平行數(shù)據(jù)進(jìn)行了分析評(píng)估。
4.3.1 困惑度分析
為了檢驗(yàn)生成的偽平行數(shù)據(jù)的可用性,利用循環(huán)神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型RNNLM和生成的偽平行數(shù)據(jù)訓(xùn)練語(yǔ)言模型,通過(guò)測(cè)試其困惑度PPL(PerPLexity),對(duì)生成句對(duì)的流利性進(jìn)行評(píng)估,檢測(cè)偽平行數(shù)據(jù)的質(zhì)量。此實(shí)驗(yàn)中訓(xùn)練語(yǔ)言模型的數(shù)據(jù)均為生成的漢越偽平行數(shù)據(jù),結(jié)果如表3所示。
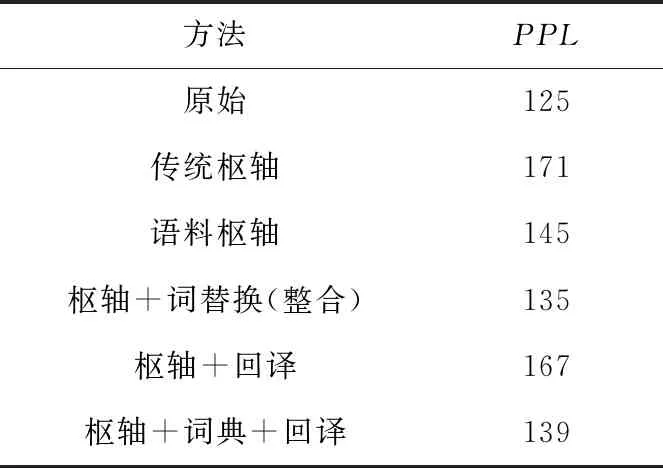
Table 3 Evaluation results of Chinese-Vietnamese pseudo-parallel data perplexity
實(shí)驗(yàn)中均使用同一測(cè)試集進(jìn)行評(píng)價(jià),其句子都是正常的句子,給測(cè)試集中的句子賦予較高正確概率值的語(yǔ)言模型較好,當(dāng)語(yǔ)言模型訓(xùn)練完之后,訓(xùn)練好的語(yǔ)言模型在測(cè)試集上的正確概率越高越好。語(yǔ)言模型困惑度的評(píng)判標(biāo)準(zhǔn)是,困惑度越小,句子正確的概率越大,語(yǔ)言模型就越好。由表3所示實(shí)驗(yàn)結(jié)果可知,本文方法可以降低困惑度,提高偽平行數(shù)據(jù)的語(yǔ)義流暢性。
4.3.2 句子打分
為了評(píng)測(cè)生成的偽數(shù)據(jù)的語(yǔ)法語(yǔ)義的準(zhǔn)確性,利用語(yǔ)言模型來(lái)對(duì)生成的漢越偽數(shù)據(jù)進(jìn)行句子打分,以此對(duì)偽平行數(shù)據(jù)的質(zhì)量進(jìn)行評(píng)估。對(duì)語(yǔ)言模型打分實(shí)質(zhì)上是評(píng)估這個(gè)句子出現(xiàn)的概率,數(shù)據(jù)較少的情況下分?jǐn)?shù)一般都很小。分?jǐn)?shù)是對(duì)句子概率取對(duì)數(shù)后的結(jié)果,因此分值一般為負(fù)數(shù),分?jǐn)?shù)越高這個(gè)句子出現(xiàn)的可能性越高,即語(yǔ)法語(yǔ)義正確的可能性更高。通過(guò)設(shè)置一個(gè)閾值,能夠有效地將語(yǔ)法語(yǔ)義有誤的句子篩選出來(lái),因此本實(shí)驗(yàn)依然使用語(yǔ)言模型的得分評(píng)價(jià)生成的漢越偽平行語(yǔ)料在語(yǔ)法語(yǔ)義上的正確性。
首先利用循環(huán)神經(jīng)網(wǎng)絡(luò)語(yǔ)言模型對(duì)漢語(yǔ)和越南語(yǔ)的單語(yǔ)語(yǔ)料中的句子進(jìn)行打分,以原始語(yǔ)料中句子的語(yǔ)法語(yǔ)義為基準(zhǔn);然后分別計(jì)算出漢語(yǔ)單語(yǔ)語(yǔ)料和越南語(yǔ)單語(yǔ)語(yǔ)料中句子的平均分,并將其作為基準(zhǔn)分?jǐn)?shù);最后同樣使用語(yǔ)言模型對(duì)生成的漢越偽平行句子分別進(jìn)行打分,這里使用的測(cè)試集包含1 000句語(yǔ)句,計(jì)算出其平均分,與基準(zhǔn)分?jǐn)?shù)進(jìn)行比較,表4所示為生成的越南語(yǔ)句子的評(píng)價(jià)結(jié)果,表5所示為反向樞軸生成的漢語(yǔ)句子的評(píng)價(jià)結(jié)果。

Table 4 Scoring results of generated Vietnamese sentence

Table 5 Scoring results of generated Chinese sentence
由打分結(jié)果可以看出,生成的漢越偽平行句對(duì)的分?jǐn)?shù)都略低于漢語(yǔ)和越南語(yǔ)測(cè)試集的基準(zhǔn)分?jǐn)?shù),而融入整合后雙語(yǔ)詞典的樞軸方法生成的越南語(yǔ)數(shù)據(jù)和融入整合雙語(yǔ)詞典的正反向樞軸方法生成的漢語(yǔ)數(shù)據(jù)的句子打分結(jié)果最接近基準(zhǔn)分?jǐn)?shù),因此我們認(rèn)為在樞軸方法基礎(chǔ)上將詞替換和回譯進(jìn)行結(jié)合的方式,使生成的漢越偽平行句對(duì)語(yǔ)法語(yǔ)義正確的可能性較高。
4.3.3 翻譯對(duì)比分析
通過(guò)例舉本文方法生成偽平行數(shù)據(jù)的典型句子樣例,對(duì)同一漢語(yǔ)句子所生成的偽平行數(shù)據(jù)進(jìn)行對(duì)比,可以直觀地觀察效果,對(duì)比樣例如表6所示。

Table 6 Example comparison of generating pseudo-parallel data

5 結(jié)束語(yǔ)
在漢越神經(jīng)機(jī)器翻譯任務(wù)上,針對(duì)資源稀缺型語(yǔ)言的訓(xùn)練數(shù)據(jù)稀缺問(wèn)題,將3種生成偽平行數(shù)據(jù)的方法進(jìn)行融合,提出了一種融入雙語(yǔ)詞典的正反向樞軸方法,以此生成漢越偽平行數(shù)據(jù),經(jīng)過(guò)語(yǔ)言模型篩選后與原始數(shù)據(jù)混合訓(xùn)練模型。實(shí)驗(yàn)結(jié)果表明,這種方法與單一的生成方法相比,可以在資源稀缺型神經(jīng)機(jī)器翻譯中更好地緩解數(shù)據(jù)稀疏問(wèn)題。接下來(lái)我們將繼續(xù)針對(duì)低資源神經(jīng)機(jī)器翻譯數(shù)據(jù)稀疏問(wèn)題,對(duì)樞軸方法進(jìn)行模型層面的融合研究。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
文苑(2020年4期)2020-05-30 12:35:30
小學(xué)生作文(中高年級(jí)適用)(2018年3期)2018-04-18 01:24:47
華北電力大學(xué)學(xué)報(bào)(社會(huì)科學(xué)版)(2016年4期)2016-12-01 03:59:30
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
少兒科學(xué)周刊·少年版(2015年4期)2015-07-07 21:11:17
