基于馬爾科夫隨機場的電信欺詐用戶檢測方法
2021-04-09 13:37:18高雅詩李靜林
無線電工程 2021年3期
高雅詩,李靜林
(北京郵電大學 計算機學院,北京 100876)
0 引言
近年來,頻發的電信欺詐犯罪給百姓造成了巨大的財產損失,為此,司法機關和電信企業采取各種措施來防范電信欺詐,從大數據技術方面入手,運用人工智能方法以求遏制電信欺詐行為。
早期欺詐檢測使用基礎機器學習的算法進行用戶通話特征分析[1-2],之后又引入自然語言處理,通過用戶通話內容進行欺詐預測[3]。一些學者還使用了神經網絡與其他相關模型相結合來完成欺詐檢測[4]。以上方法均可以有效地幫助識別電信欺詐用戶,但主要使用用戶的通話內容,所需的數據存在特征維度大、需求時間跨度長等問題。
如今,對于欺詐的預測逐漸利用到了社交網絡。目前,基于社交網絡結構的方法可以分為2類:基于隨機游走(Random Walk,RW)的方法和基于循環置信傳播(Loopy Belief Propagation,LBP)的方法。RW主要是以邊權對邊緣概率的相對重要性(信任等級)建模[5-8];LBP則是用邊權模擬共享相同標簽的趨勢[9-11]。RW一般無法同時鑒別正常異常,LBP一般不可擴展,不能保證收斂。
目前,大部分電信欺詐行為檢測主要針對用戶的通話數據特征進行檢測,少有利用用戶社交關系進行分類的情況,且后者大多利用用戶社交網絡的拓撲關系劃分社區的方法,忽略了用戶自身的數據特征。
面對大規模的電信用戶欺詐行為預測分析,仍存在以下挑戰:① 通信社交網絡的建立。通信用戶節點多,網絡拓撲結構復雜,計算復雜度隨之指數型增加,需要找到合適的網絡數據計算方法。② 將概率理論與社交網絡結合。主流的電信欺詐檢測利用有監督的分類器進行二分類分析,生成離散型結果,誤差影響較大,需要利用概率方式在社交網絡中計算電信欺詐用戶的欺詐概率,形成半監督式分類模型。③ 將用戶數據的統計特征與社交網絡結合。社交網絡的相關算法主要利用了社交網絡的拓撲關系,忽視了數據本身的特征,需要將用戶的數據特征置入到社交網絡中,幫助優化預測模型。
針對以上問題,可以用概率圖模型來嘗試解決。利用概率圖模型中的馬爾科夫隨機場(Markov Random Field,MRF)對通信用戶社交網絡進行建模,根據通話用戶的欺詐行為特征設計相關的圖結構及相應的概率分布關系,對用戶的行為特征與用戶間親密度關系加以描述,最終利用相關算法進行分析預測。
1 基于MRF的電信用戶欺詐行為建模
MRF是概率圖模型中的一種生成式模型[12],利用概率論中的貝葉斯原理,建立數據間的概率分布關系。根據電信用戶的社交特點,利用MRF模型來設計相應的邏輯結構,搭建電信用戶欺詐行為的概率分布,以輔助完成對欺詐行為的分析預測。電信用戶的MRF可設為G(V,E),節點V表示通信網絡中的各個用戶,擁有各自的數據特征,設為先驗概率;邊E表示各個節點間的相關關系,利用整體社交網絡關系,形成MRF的聯合概率,從而構成整體的概率分布。由此在隨機場中傳遞節點的特征信息,獲得各節點的后驗概率來判斷最終的分類預測結果。電信欺詐檢測流程如圖1所示。

圖1 電信欺詐檢測流程Fig.1 Telecom fraud detection flow
1.1 電信用戶的特征情況分析
社交網絡中,一般存在5種用戶的相關特征:屬性特征、網絡特征、內容特征、活動特征與輔助特征[13]。本文使用電信通話用戶的通話數據,根據電信用戶的通話情況,可以提取出如下特征:
屬性特征:基于用戶的長期用戶詳單,可以據此分析用戶的日常通話行為,作為代表用戶屬性的特征。
網絡特征:利用用戶間的通話關系,可以構建出電信用戶的通信社交網絡,并在網絡中總結出相關網絡特征,例如度、中心性和聚類系數等。
活動特征:根據用戶間的通信活動情況,例如用戶間通話時長、通話頻次和呼損原因,作為活動特征計入在特征范圍內。
根據以上特征可以為節點特征、節點間特征添加對應的計算因子,最終通過信度傳播來更新聯合概率,推算出節點的預測值。
1.2 用戶節點先驗概率的設計
MRF中節點的先驗概率一般由該節點的特征來表示,此模型利用電信用戶的屬性特征來進行計算。將節點u的分類情況設為Xu,當Xu=1時,該用戶為正常用戶;反之,該用戶為欺詐用戶。同時,將電信用戶的長期特征設為cu,主要包括通信用戶的通話頻度、通話平均時長和通話時間區間等,作為行為向量特征。在此基礎上,使用邏輯回歸來進行先驗概率的計算:
(1)
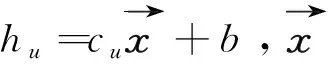
在社交網絡中,用戶間存在相互影響的相互關系。可設置根據前期對電信用戶的調研工作,總結以下基本情況:
① 雙向:經常相互通信的用戶雙方有相似的通信特征,存在同構相似,符合社交網絡中社區集中的特點。
② 單入:欺詐用戶通常不會作為被叫用戶接到正常用戶的通話,所以一般情況下,欺詐用戶的主叫用戶為欺詐用戶。
③ 單出:正常用戶通常不會主動與欺詐用戶通話,所以一般情況下,正常用戶的被叫用戶為正常用戶。
根據此情況,可以設計出在鄰居用戶影響下,節點u的先驗概率的情況。根據社交網絡中的有向邊情況,設置節點u的雙向鄰居集合N(u)、單向被叫鄰居集合I(u)、單向主叫鄰居集合O(u),每一個鄰居都對節點有不同影響力設為Yuv。據此可根據鄰居節點不同情況,設計不同的先驗概率計算方法。
面對雙向通話的用戶,二者間存在相互影響,會將自身的信譽度傳播給其鄰居,使其逐漸同質化,由此可得:
(2)
面對單向被叫用戶,如果鄰居為正常用戶,則可以推出該用戶大概率為正常用戶;反之,則不能確定該用戶是否為欺詐用戶。所以,單向被叫用戶只受正常用戶的信譽度影響。面向單向主叫用戶,如果鄰居為欺詐用戶,則可以推出該用戶大概率為欺詐用戶;反之,則不能確定該用戶是否為欺詐用戶,所以,單向主叫用戶只受欺詐用戶的信譽度影響。據此可以得到,根據鄰居影響的用戶節點的先驗概率分布φu(xu)為:
(3)

1.3 用戶關系連接邊的勢函數設計
MRF中節點的先驗概率確定后,再考慮邊的表達方式。網絡中的邊表示的是用戶之間的相關關系,在傳導過程中根據之前確定的欺詐用戶與正常用戶之間的關系,可以設計用戶間的勢函數。由文獻[15]中的雙向邊勢函數可推導出單向邊的勢函數為:
(4)
式中,wuv為兩用戶節點間的親密關系程度。根據社交網絡的情況,可以利用二者的相似關系來確定二者的親密度關系,本文使用了皮爾森相似度來進行計算:
(5)
基于上述設計電信用戶的MRF,G=(V,E)中先驗函數φu(xu)與勢函數φuv(xu,xv),可以求得MRF中的聯合概率分布:
(6)

2 利用循環置信傳播推導后驗概率
置信傳播算法利用節點與節點之間相互傳遞信息更新當前整個MRF的標記狀態,是基于MRF的一種近似計算。該算法是一種迭代的方法,可以解決概率圖模型概率推斷問題,而且所有信息的傳播可以并行實現。經過多次迭代后,所有節點的信度不再發生變化,就稱此時每一個節點的標記即為最優標記,MRF也達到了收斂狀態,從而得到最優的聯合概率,最終求出節點的后驗概率,作為該節點的欺詐預測概率。
2.1 置信傳播算法
置信傳播算法一般分為sum-product和max-product兩種傳播模式,本文使用max-product進行相關計算。
具體消息傳播公式為:
(7)
式中,包含所有其他傳入節點u的消息乘積;L(v)/u表示節點v的MRF一階鄰域中排除目標節點u的鄰域;mvu(xu)可以通過網絡中的消息傳播不斷迭代,用自身上次迭代的消息結果結合節點u自身的先驗概率和節點u與鄰居v之間的勢函數,計算出此次迭代mvu(xu)的結果。理想情況下,當節點間的消息傳遞不再變化,則達到完全收斂,此時會得到MRF的最優聯合概率分布。根據聯合概率分布求得各個節點的后驗概率:
(8)
式中,zu為歸一化函數。在具體實驗過程中,循環置信傳播不能保證在有限次循環之后能夠完全收斂,所以設置收斂線α∈[10-4,10-7],2次消息變化較小時,則可以認為該過程已實現收斂。
2.2 循環置信傳播的優化
為簡化最終的函數表達方式,算法中設pu表示Pr(xu=1),qu表示φu(xu=1),mvu表示mvu(xu=1)。因為歸一化不影響先驗概率的計算和消息傳遞的效果,所以φu(xu=1)+φu(xu=-1)=1,mvu(xu=1)+mvu(xu=-1)=1,化簡后為:
(9)
置信傳播算法中,仍存在可擴展性不足,主要是因為算法中在社交網絡圖的每一個邊緣都在進行信息上的維護,其關鍵原因在于2個節點不能同時向對方傳遞消息,實質上是當用戶節點v向其鄰居節點u準備消息時,它排除了鄰居節點u發送給用戶節點v本身的消息。文獻[15]指出,計算節點(v,u)間消息傳遞mvu中沒有排除鄰居節點u給用戶節點v的消息,并不影響MRF的收斂性。算法優化時,消息傳播可以允許當v為u準備消息時,u發送給v的消息。消息傳播公式變換為:
(10)
3 實驗分析
3.1 實驗數據分析
本模型采用運營商的真實數據集,其中記錄了從2019年5月27日-6月8日所有的cdr呼叫詳單,共計4 582 674條數據,欺詐行為數據82 133條,并且數據集中僅包含在采樣期內活躍的用戶。具體用戶特征如表1所示。

表1 用戶特征
在實驗前,首先進行數據預處理,了解數據的分布情況,對數據進行清理工作。對通話記錄按照時間長度進行數據劃分并特征提取,將整合處理后的數據分為3類。目前,將特征分為3部分:一是單條數據下的通話特征,例如通話時間區間、通話時長和呼損原因等,用于2節點間的關系計算;二是單個主叫用戶在單日的通話特征,通話次數、通話平均時長,通話高頻區間等,用于該節點的主要屬性特征計算;三是單個主叫用戶的長期的通話特征,其時間跨度較長,后期可加入時間特征進行迭代更新。此外,對數據集進行隨機采樣處理,其中70%數據用于訓練,10%數據用于驗證,20%數據用于測試。
3.2 用戶親密度的計算方式對比
在設置MRF勢函數的過程中,主要利用了節點間的親密度關系進行計算。計算用戶間的親密度主要利用用戶間的相似關系或者社交關系,例如余弦相似性、歐氏距離相似性和皮爾森相似性等;或利用用戶間的信任度計算,其中,直接信任度計算主要通過節點的關聯關系進行,在網絡G中若u和v有直接聯系,則u對v有直接信任關系,直接信任度T(u,v)為1,否則為0。歸一化處理后得到的直接信任度:
(11)
本文就以上幾種方式進行對比,各相似度關系計算結果對比如圖2所示。

圖2 各相似度關系計算結果對比Fig.2 Comparison of similarity relationship calculation results
僅利用節點間的社交關系,在歸一化后結果差距不明顯,導致最終結果欠佳。皮爾森與優化余弦相似性算法相同,只是歸一化方法不同,3種相似性準確度結果差距不明顯,僅僅在召回率上有較小差別。利用歐氏距離相似性計算用戶間的親密度,效果更好。
3.3 模型分類結果對比
實驗中采用基礎的分類器模型進行比較:
邏輯回歸:對數幾率模型,使用其固有的logistic函數估計概率,完成二分類任務。
決策樹:決策分類樹,利用樹節點代表數據屬性特征,進行分類決策。
隨機森林:多個決策樹的分類器。
XGBoost:提升樹模型,boosting算法中的一種,將許多CART回歸樹模型集成在一起,形成一個強分類器。
MRF:先驗函數為用戶標簽,勢函數均為常數值>0.5。
LR+MRF:利用邏輯回歸方式將用戶特征轉換為用戶節點的先驗概率,將用戶間的親密關系程度作為用戶間的勢函數。
將用戶詳單數據置入各模型中,結果如表2所示。
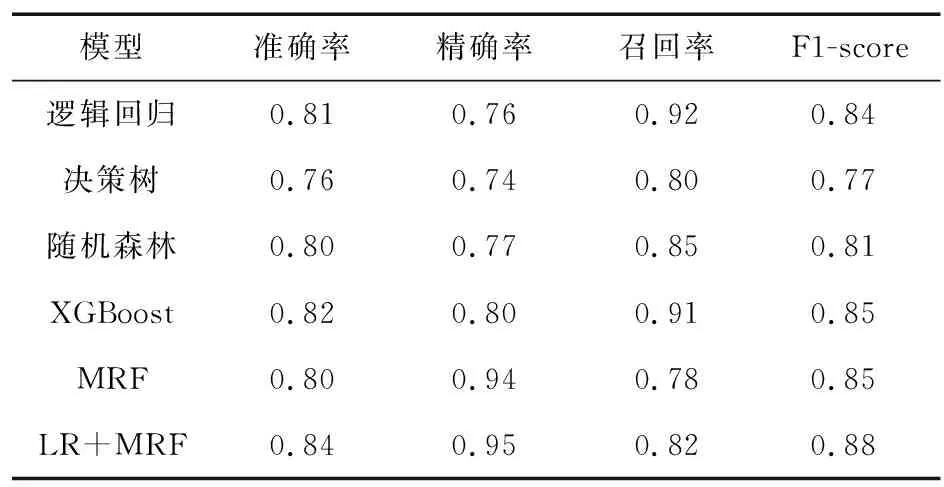
表2 各模型分類結果
由表2可以看出,基于MRF的欺詐用戶分析模型可以有效地對存在欺詐行為的用戶加以區分。其中,精確率較基礎分類模型有了較大提高,主要是因為模型將用戶的基本特征和用戶間關系特征利用概率圖算法連接起來,從而提高了模型的精確率。而模型的召回率較低,主要原因在于數據中的欺詐用戶占比較小,分布較為分散,欺詐用戶二者間連通性較弱,導致召回率比沒有利用網絡關系的模型低。綜上,通過基于MRF的社交網絡模型,能夠對用戶欺詐行為進行較好的預測。
4 結束語
提出了一種基于MRF的電信欺詐行為分析模型,在此隨機場中利用邏輯回歸對用戶節點賦特征值,設計節點間親密度表示節點間的關聯關系,之后利用循環置信傳播方式計算MRF的消息傳播得到最終的后驗概率,完成欺詐用戶行為的預測判斷。通過將真實數據集置入MRF模型中,與其他欺詐檢測方法進行比對,對本文模型進行評估。實驗證明,利用概率圖MRF與邏輯回歸相結合對電信欺詐行為進行檢測,能夠獲得較優的結果。之后的研究中,可以通過引入更多的通話特征,對具體算法進一步優化,以更好地完成電信欺詐行為的預測。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
