關鍵人臉輪廓區域卡通風格化生成算法
2021-04-10 05:56:56范林龍張笑欽
圖學學報 2021年1期
范林龍,李 毅,張笑欽
關鍵人臉輪廓區域卡通風格化生成算法
范林龍1,李 毅1,張笑欽2
(1. 溫州大學計算機與人工智能學院,浙江 溫州 325035; 2. 溫州大學大數據與信息技術研究院,浙江 溫州 325035)
針對人臉輪廓特征區域的局部化限定,結合關鍵特征點的提取和臉部鄰近顏色區域的融合,并引入注意力機制,提出了一種基于CycleGAN的關鍵人臉輪廓區域卡通風格化生成算法,以此作為初始樣本構建生成對抗網絡(GAN)并獲取自然融合的局部卡通風格化人臉圖像。利用人臉輪廓及關鍵特征點進行提取,結合顏色特征信息限定關鍵人臉風格化區域,并通過局部區域二值化生成關鍵區域人臉預處理的采樣圖像;為了使生成圖像能夠自然匹配所提取特征區域,利用均值濾波操作對所提取區域的邊緣輪廓進行平滑羽化處理,并相應地擴展風格化生成圖像的過渡區域;最后通過構建基于無監督學習的生成對抗網絡,使用訓練數據集進行人臉圖像局部輪廓特征區域的卡通風格化生成。算法對人臉輪廓區域的邊緣及鄰近區域顏色進行濾波處理,可實現良好的邊緣輪廓過渡融合,生成自然的人臉局部輪廓區域的卡通風格化圖像。實驗結果表明,該算法對于人臉圖像的生成具有很高的魯棒性,能夠應用于各種尺度人臉圖像的風格化生成。
人臉特征;局部區域;對抗生成網絡;風格化
人臉特征已廣泛地應用于人臉輪廓提取、分割、識別[1-3]、檢索[4-5]和分類等眾多研究領域。作為人體自然特征最重要的表征區域,人臉輪廓和關鍵器官特征點的提取技術,對于人體的生物識別、目標跟蹤和行為分析具有非常重要的理論價值。尤其是在基于機器視覺技術的人工智能領域,快速并準確的人臉特征提取經常作為算法的首要條件之一。
近年來,基于特征提取的人臉關鍵區域風格化生成技術受到了市場的極大關注[6-7]。涌現了一大批基于人臉區域特征提取的應用技術[8-9],如人臉圖像的編輯美化、視頻人臉風格貼圖、“變臉”(Deepfakes)等,在影視娛樂、動漫游戲、廣告宣傳領域得到了廣泛應用。采用傳統的圖像處理技術,能夠實現人臉關鍵特征的風格改變和遷移,從而達到美化人臉圖像的目的。隨著計算機視覺領域的發展,采用深度學習技術,能夠實現更加智能快速的人臉特征風格化及特征融合。
傳統的人臉風格化方法是利用圖像處理的技術[10],通過提取人臉面部特征位置,根據所需表情從素材庫中調取相應的五官貼圖,進行匹配或替換生成卡通圖像;在視頻圖像處理領域[11],利用非真實感渲染,通過學習特定風格的筆觸特征[12],模擬表現人臉區域的藝術化特質;在圖像濾波研究領域,研究人員利用Kuwahara濾波器[13]平滑權重函數代替矩形區域,考慮各向異性的權重函數形成聚類的方法,能夠在平滑圖像的同時保留圖像有意義的邊緣信息,從而提高圖像風格化的結果。
近年來,隨著深度學習的快速發展,基于對抗生成網絡(generative adversarial networks,GAN)的人臉生成領域成為研究熱點[14-15]。在人臉圖像合成領域,FaceID-GAN將傳統的GAN進行擴展,通過加入分類器,確保了生成的人臉具有高質量的身份保留輸出,并遵循網絡信息的對稱性特點,減小訓練難度,以實現多視角和表情的人臉圖像生成。清華大學的學者提出了一種專用的全局場景卡通風格化的GAN架構的CartoonGAN[16],能夠有效地學習使用不成對的數據集進行訓練,通過利用稀疏正則化語義損失函數,推進了邊緣的對抗損失,保證了清晰的生成圖像邊緣。最近,一種新的標簽協助加強版CycleGAN網絡被提出生成卡通風格化人臉圖像[17],通過面部特征定義一致性的同時,指導在網絡模型中訓練局部鑒別器,從用戶研究、特定辨識度、結果的總體評價3個方向對網絡進行構建研究,使最終的生成圖像取得了很好的結果。本文基于CycleGAN的深度學習網絡架構,對于局部關鍵區域卡通風格化的研究,結合人臉輪廓區域分割技術,局部特征的稀疏化提取,能夠有效地減少網絡的學習時間,具有很大地應用價值。
基于CycleGAN技術的關鍵人臉輪廓區域卡通風格化生成算法,如圖1所示。通過人臉輪廓特征區域的局部化限定,結合關鍵特征點的提取和臉部鄰近顏色區域的融合,并引入無監督學習的注意力機制(attention mechanism),以此作為初始樣本構建GAN并獲取自然融合的局部卡通風格化人臉圖像。

圖1 人臉關鍵特征區域和局部卡通風格化
本文首先利用人臉輪廓及關鍵特征點進行提取,結合顏色特征信息限定關鍵人臉風格化區域,并通過局部區域二值化生成特征區域人臉預處理的采樣圖像;為了使生成圖像能夠自然匹配所提取特征區域,利用均值濾波操作對所提取區域的邊緣輪廓進行平滑羽化處理,并相應地擴展風格化生成圖像的過渡區域;然后通過構建基于CycleGAN的GAN,調整樣本區域進行訓練學習;最后,使用訓練數據集進行人臉圖像局部輪廓特征區域的卡通風格化生成。具體步驟如下:
步驟1. 首先輸入一張圖片,利用DLIB的HOG特征檢測器檢測人臉區域,得到包圍區域頂點坐標;根據頂點坐標,確定人臉矩形框,同時計算獲得一個最小化人臉橢圓特征區域,將此橢圓區域記為Mask 1。
步驟2. 限定矩形區域內人臉關鍵點,通過68點的關鍵點檢測方法,得到人臉特征關鍵點區域Mask 2。同時采集計算臉部區域膚色獲得感興趣區(region of interest,ROI) Mask 3。通過計算獲得最終人臉學習ROI區域Mask。
步驟3.根據所得ROI區域,結合構建基于U-GAT-IT方法的無監督注意力機制網絡來實現圖像的轉化與融合。通過與Mask進行并集計算,獲得局部區域內的卡通生成圖像。
步驟4. 最后利用泊松融合的方法將轉換后的圖像與原始圖片進行融合。同時,對于臉部區域不夠明顯的區域,采用均值濾波,通過調整網絡卷積核大小來進行臉部輪廓邊緣的平滑操作,能夠達到很好地擴寬過度邊緣的效果。算法框架流程如圖2所示。

圖2 人臉關鍵區域風格化生成算法流程圖
1 人臉局部特征區域的風格化方法設計
1.1 基于人臉關鍵特征的輪廓提取
Mask 1. 在計算機視覺及圖像處理中,梯度方向直方圖(histogram oriented gradient,HOG)是一種基于形狀邊緣特征,能對物體進行檢測的描述算子,基本思想是利用梯度信息很好地反映圖像目標的邊緣信息,并通過局部梯度的大小將圖像局部的外觀和形狀特征化。利用DLIB的HOG特征檢測器檢測人臉區域[1],即

其中,G,G,(,)分別為像素點(,)在水平方向及垂直方向的梯度以及像素的灰度值。
最終得到包圍區域頂點坐標,通過這2個點可以計算出中心坐標及半徑。根據面部特征盡可能去擬合額頭區域。
Mask 2.關鍵點算法是基于集成回歸樹(ensemble of regression tress,ERT)算法,即梯度提高學習的回歸樹方法,如圖3所示。該算法通過建立一個級聯的殘差回歸樹(gradient boosting decistion tree,GBDT)使人臉的當前形狀逐步回歸到真實形狀。每一個GBDT的每一個葉子節點上均存儲著一個殘差回歸量,當輸入落到一個節點時,就將殘差加到該輸入上,起到回歸的目的,最終將所有殘差疊加在一起,就完成了人臉對齊的目的,即
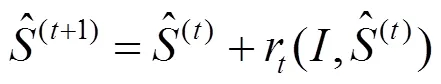
其中,為第t級回歸器的形狀,是一個由坐標組成的向量,更新策略采用GBDT梯度提升決策樹,即每級回歸器學習均是當前形狀與樣本形狀的殘差。
最終得到68個關鍵點的坐標,包含眼鏡、眉毛、鼻子、嘴巴等主要特征,取最外層27個點得到一個不規則形狀Mask 2,如圖4所示。
Mask 3. 根據膚色提取特征,采用YCrCb顏色空間Cr分量+Otsu法閾值分割。

圖4 關鍵點坐標圖
(1) 將RGB圖像轉換到YCrCb顏色空間,提取Cr分量圖像;
(2) 對Cr做自二值化閾值分割處理(Otsu算法)。Otsu算法(最大類間方差法)采用的是聚類的思想,將圖像的灰度數按灰度級分成2個部分,并使其灰度值差異最大,每個部分之間的灰度差異最小,通過方差的計算尋找一個合適的灰度級別進行劃分。在二值化時采用Otsu算法自動選取閾值并進行二值化。Otsu算法被認為是圖像分割中閾值選取的最佳算法,計算簡單,不受圖像亮度和對比度的影響。因此,使用類間方差最大的分割意味著錯分概率最小。
圖像總平均灰度為
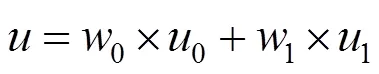
其中,為設定的閾值,初始值為圖像的平均灰度;0為分開后前景像素點數占圖像的比例;0為分開后前景像素點的平均灰度;1為分開后背景像素點數占圖像的比例;1為分開后背景像素點的平均灰度。從個灰度級遍歷,當為某值時,前景和背景的方差最大,則該值便是要求的閾值。其中,方差的計算為
該式計算量較大,可簡化為
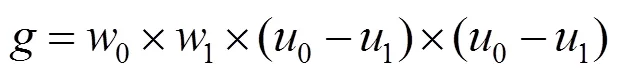
最終將3個Mask合并,得到需要提取的圖像,即
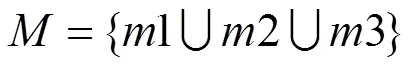
1.2 基于GAN的卡通風格化生成網絡
無監督圖像到圖像是本文采用的全新方法,如圖5所示,其結合了注意力模塊和自適應歸一化模塊。本文模型通過基于類激活器(class activation map,CAM)獲得的注意力圖以區分源域和目標域,引導圖像在生成時,聚焦于重要區域而忽略次要區域。這些注意力圖將被嵌入到生成器和鑒別器中,以聚焦生成語義上更重要的區域,從而促進模型變換,如圖6所示。
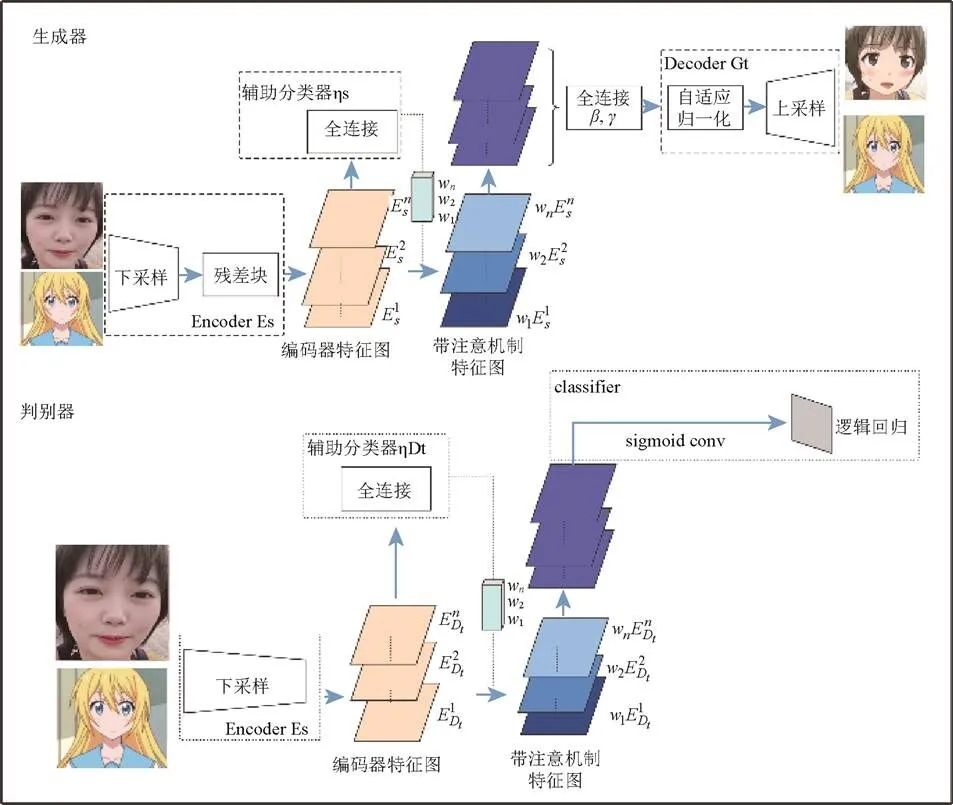
圖5 一種無監督圖像到圖像的對抗生成網絡

圖6 注意力機制圖
數據集具有不同形狀和紋理變化量,其變化結果的質量除與注意力機制有關,還受歸一化函數選擇的影響。參考批處理實例標準化(btch-instance normalization),采用了自適應層實例標準化(adaptive layer-instance normalization),適當地選擇實例標準化(instance normalization)和層標準化(layer normalization)之間的適當比率,在訓練期間從數據集中學習其參數。可選歸一化功能幫助注意力引導模型靈活控制紋理和形狀。主要內容歸納:
(1) 采用無監督圖像到圖像新的轉換方法,其集新的注意模塊和新的歸一化函數AdaLIN為一體。
(2) 注意模塊通過基于輔助分類器獲得的關注圖來區分源域和目標域,從而幫助模型知道在何處進行密集轉換。
(3) AdaLIN功能幫助注意力引導模型靈活地控制更改形狀和紋理的數量。
1.2.1 生成器
圖像依次經過一個下采樣模塊和一個殘差塊后,得到了編碼后的特征圖。其分為2路,一路是通過一個輔助分類器,得到有每個特征圖的權重信息,并與另外一路編碼后的特征圖相乘,得到有注意力的特征圖。注意力特征圖仍分為2路:①經過一個1×1卷積和激活函數層,得到1,···,特征圖。特征圖則通過全連接層置于解碼器中;②作為解碼器的輸入,經過一個自適應的殘差塊和自適應歸一化層上采樣模塊后得到生成結果。
首先計算的是實例的標準化和層標準化
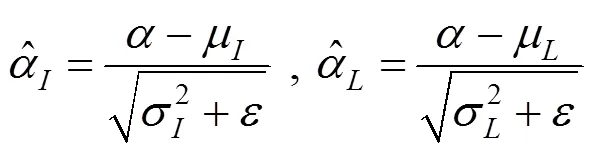
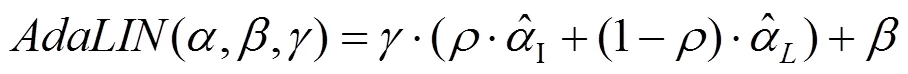
為了防止超出[0,1]范圍,對其進行了區間裁剪

1.2.2 判別器
判別器的設計結合了全局判別器(global discriminator)以及局部判別器(local discriminator)的原理,將全局和局部判別結果進行連接。判別器中加入了分類激活映射(class activation mapping,CAM)模塊[18],雖然CAM未在判別器下做域的分類,但由于注意力圖能夠注意到目標域中真實圖像和偽圖像之間的差異并對其進行微調,所以注意力模塊的加入有助于判別圖像真偽。
1.2.3 CAM與輔助分類器
CAM對圖片中的關鍵部分進行定位[18]。通過圖像下采樣和殘差塊得到的編碼器特征圖,經過平均池化(global average pooling)和最大池化(global max pooling)后得到依托通道數的特征向量。創建可學習參數權重,經過全連接層壓縮。對于編碼器特征圖的每一個通道,可賦予一個權重,該權重決定了這一通道對應特征的重要性,從而實現了特征映射(feature map)的注意力機制。
當生成器可以很好地區分源域和目標域輸入時,注意力模塊可以幫助模型知道在何處進行密集轉換。將平均池化和最大池化得到的注意力圖做連接,經過一層卷積層還原為輸入通道數,最終送入 AdaLIN中進行自適應歸一化處理。
1.2.4 損失函數
本文模型的完整目標包括4個損失函數。可使用最小二乘GAN目標進行穩定訓練,而不是使用Least Squares GAN。對抗性損失使用Adversarial loss匹配翻譯圖像與目標圖像分布的差異

循環損失為了緩解模式崩潰問題,cycle-gan架構下的環一致性loss,A翻譯到B,然后B翻譯到A’,A和A’需要相同,loss采用的是1loss。

身份丟失為了確保輸入圖像和輸出圖像的顏色分布相似,本文將身份一致性約束應用于生成器,即

生成器和鑒別器的CAM loss不同表現為:
生成器CAM loss,采用的是BCE_loss

鑒別器CAM loss,采用的是MSE

用CAM的原因是利用輔助分類器η和ηD的信息,給定一個圖像∈{X,X},G→和D了解當前狀態下2個域之間的最大區別是什么。
最后,聯合訓練編碼器、解碼器、鑒別器和輔助分類器,以優化最終目標

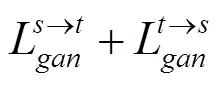
通過訓練,可以得到轉換成卡通風格化的圖片,然后利用泊松融合法將轉換后的圖片與原始臉部圖片進行融合,并對邊緣部分進行濾波操作,保證圖片平滑過度,最終完成局部人臉輪廓提取區域風格化的操作。
2 實驗結果與分析
2.1 數據集與損失函數
本文采用一個由真實圖片和動畫作品組成的數據集,所有圖像均已調整為256×256進行訓練,自定義數據集采用女性照片作為訓練數據和測試數據,數據來源均是從Anime Planet爬取。首先檢索動漫角色人物,然后提取面部圖像。訓練數據集的大小為3 400,測試數據集的大小為100,圖像均為256×256,如圖7所示。

圖7 Selfie2anime數據集
損失函數包括:①判別器損失曲線(圖8):Discriminator_loss表示判別器鑒別偽造數據和真實數據的能力,損失值越小,鑒別能力越強;②生成器損失曲線(圖9):Generator_loss表示偽造圖片技術的能力,損失值越低,說明偽造能力越強。

圖8 判別器損失曲線
綜上,從圖8和圖9可以看出,無論是Discriminator_loss還是Generator_loss都有著明顯的變化,雖然損失函數在訓練中發生振蕩,是因為生成器和判別器彼此會消除對方的學習。不過損失函數圖像最終很明顯均呈下降趨勢,隨著迭代次數的增加,Discriminator_loss以及Generator_loss都明顯降低,鑒別能力和偽造能力均明顯增強。直到鑒別器無法分出數據是真實的還是生成器生成的數據時,這時對抗的過程達到一個動態的平衡。

圖9 生成器損失曲線
2.2 實驗結果分析
為了測試本文方法的可行性和有效性,采用該算法,對不同的輸入圖像進行處理,得到局部人臉輪廓提取的區域風格化效果圖像。以下實驗均在Windows10操作系統中完成,Intel(R) Core(TM) i9-9900K CPU 3.6 GHz GeForce RTX 2080 Ti,16 G內存,Pycharm python編程實現,實驗結果如圖10所示。

圖10 實驗最終生成效果圖
同時,還將本文算法模型與其他圖像遷移模型進行了對比,如圖11所示,實驗結果很好地展現了本文算法的優良性。圖11(b)由于CAM模塊的聚焦,很明顯眼睛周圍的轉換要比其他模型好,圖像之間不同形狀和紋理變化量,其變化結果的質量除了與注意力機制有關,也明顯受到歸一化函數選擇的影響。通過這2個模塊,其轉換后的目標圖像不論從細節、形狀都得到了極大的提升。
實驗結果表明注意力模塊(圖12)和AdaLIN (圖13)可以在含有定制網絡架構和超參數的各種數據集中產生更加喜人的效果。輔助分類器獲得的注意力機制圖可以指導生成器更加關注源域和目標域之間的不同區域。此外,還發現,在引導模型靈活地控制形狀更改和紋理數量上,AdaLIN也發揮著重要作用。
通過本文方法生成的區域卡通風格化效果圖片色彩鮮明。轉換后的人物頭像生動形象,具有卡通動漫人物所特有的特征,對局部卡通藝術風格結果圖像進行了較好的模擬。

圖11 不同GAN圖像遷移模型((a)源圖像;(b)本文結果;(c)基于CycleGAN的結果;(d)基于UNIT的結果;(e)基于MUNIT的結果;(f)基于DRIT的結果;(g)基于AGGAN的結果;(h)基于CartoonGAN的結果)

圖12 CAM模塊分析((a)源圖像;(b)生成器的注意力圖;(c~d)鑒別器的局部注意力圖和全局注意力圖;(e)帶有CAM模塊的結果;(f)不帶CAM模塊的結果)
(1) 采用CAM模塊分析。對于CAM模塊,通過消融實驗來確定生成器和辨別器使用的注意力模塊的優點。如圖12(b)特征圖幫助生成器聚焦于與目標域更具辨別力的源圖像區域。如圖12(c)和(d)所示,分別通過可視化鑒別器的局部注意力圖和全局注意力圖判別鑒別器集中注意力的區域,以確定目標圖像是真實的還是偽造的。生成器可以用注意力圖調整鑒別器所關注的區域。請注意,本文結合了2個感受野大小不同的鑒別器的全局和局部注意力圖。可以幫助生成器捕獲全局結構(比如面部區域和眼睛周圍)作為局部區域。有了這些信息,一些區域的解析會更加謹慎。如圖12(e)所示的關注模塊的結果驗證了在圖像翻譯任務中利用關注特征圖的有利效果。另一方面,可以看到在沒有使用注意力模塊的情況下根本無法完成良好的遷移,如圖12(f)所示。

圖13 AdLIN模塊分析((a)源圖像;(b)本文結果;(c)僅在解碼器使用IN的結果;(d)僅在解碼器使用LN的結果;(e)僅在解碼器使用AdaLIN的結果;(f)僅在解碼器使用GN的結果)
(2) AdaLIN結構分析。本文將AdaLIN應用到了生成器的解碼器上,殘差塊在解碼器中的作用是嵌入特征,上采樣卷積塊在解碼器中的作用是從嵌入特征生成目標域圖像。如果門參數的學習值接近1,則意味著對應層更多地依賴于IN。同樣地,如果學習的值接近于0,則意味著對應層更多依賴于LN。如圖13(c)所示,僅在解碼器中使用IN時,源域的特征(例如,耳環和顴骨周圍的陰影)由于在殘差塊中使用的(基于Channel-wise的規范化特征統計)按信道的規范化特征統計而被很好地保留。然而,由于上采樣卷積塊中的IN無法捕獲全局樣式,因此對目標域樣式的轉換量有些不足。另一方面,如圖13(d)所示,如果在解碼器中僅使用LN,則借助于在上采樣卷積中使用的(基于layer-wise的規范化特征統計)分層歸一化特征統計,可以充分地轉換目標域樣式。但是,在殘差塊中使用LN,對源域圖像的特征保留較少。對2種極端情況的分析表明,在特征表示層中更多地依賴于IN而不是LN來保持源域的語義特征是有益的,而對于從特征嵌入中實際生成圖像的上采樣層則相反。因此,在無監督的圖像到圖像轉換任務中,根據源域和目標域的分布來調整解碼器中IN和LN的比例的AdaLIN更為可取。圖13(e)和(f)是采用AdaIN和GN的結果。顯然與這些方法相比,采用AdaLIN方法顯示出更好的效果。
3 結束語
本文提出了一種新的基于GAN技術的關鍵人臉輪廓區域卡通風格化生成算法。首先利用人臉輪廓及關鍵特征點的提取,結合顏色特征信息限定關鍵人臉風格化區域,并通過采用二值化技術生成關鍵區域人臉預處理的采樣圖像;為了使生成圖像能夠自然匹配所提取區域,利用均值濾波操作對所提取區域的邊緣輪廓進行平滑羽化操作,并相應地擴展風格化生成圖像的過渡區域;然后通過構建基于無監督圖像到圖像轉換方法,調整樣本區域進行訓練學習;最后,使用訓練數據集進行人臉圖像局部輪廓特征區域的卡通風格化生成。本文算法由于對人臉輪廓區域的邊緣及背景顏色進行濾波處理,而且在初始化階段對采樣區域進行了尺寸的自適應修正,在量化生成的過程中,能夠實現良好的邊緣輪廓過渡融合,生成了自然的人臉局部輪廓區域的卡通風格化圖像。本文算法對于人臉圖像的生成具有很高的魯棒性,能夠應用于各種尺度人臉圖像的風格化生成,適用范圍非常廣泛。
[1] ZHANG X Q, WANG D, ZHOU Z Y, et al. Robust low-rank tensor recovery with rectification and alignment[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2019, PP(99): 1-1.
[2] ZHANG X Q, JIANG R H, WANG T, et al. Attention-based interpolation network for video deblurring[EB/OL]. [2020-10-20]. https://doi.org/10.1016/j.neucom.2020.04.147.
[3] ZHOU E J, FAN H Q, CAO Z M, et al. Extensive facial landmark localization with coarse-to-fine convolutional network cascade[C]//2013 IEEE International Conference on Computer Vision Workshops. New York: IEEE Press, 2013: 386-391.
[4] WU Y, HASSNER T, KIM K, et al. Facial landmark detection with tweaked convolutional neural networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 40(12): 3067-3074.
[5] KOWALSKI M, NARUNIEC J, TRZCINSKI T. Deep alignment network: a convolutional neural network for robust face alignment[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). New York: IEEE Press, 2017: 2034-2043.
[6] WANG N N, GAO X B, TAO D C, et al. Facial feature point detection: a comprehensive survey[J]. Neurocomputing, 2018, 275: 50-65.
[7] ZHANG Y, DONG W M, DEUSSEN O, et al. Data-driven face cartoon stylization[C]//SIGGRAPH Asia 2014 Technical Briefs on - SIGGRAPH ASIA’14. New York: ACM Press, 2014: 201-300.
[8] SUN Y, WANG X G, TANG X O. Deep convolutional network cascade for facial point detection[C]//2013 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2013: 3476-3483.
[9] ZHANG Z P, LUO P, LOY C C, et al. Facial landmark detection by deep multi-task learning[M]//Computer Vision – ECCV 2014. Cham: Springer International Publishing, 2014: 94-108.
[10] XU Z J, CHEN H, ZHU S C, et al. A hierarchical compositional model for face representation and sketching[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(6): 955-969.
[11] WINNEM?LLER H, OLSEN S C, GOOCH B. Real-time video abstraction[J].ACM Transactions on Graphics, 2006, 25(3): 1221-1226.
[12] KYPRIANIDIS J E, COLLOMOSSE J, WANG T H, et al. State of the “art”: a taxonomy of artistic stylization techniques for images and video[J]. IEEE Transactions on Visualization and Computer Graphics, 2013, 19(5): 866-885.
[13] PAPARI G, PETKOV N, CAMPISI P. Artistic edge and corner enhancing smoothing[J]. IEEE Transactions on Image Processing, 2007, 16(10): 2449-2462.
[14] ZHANG K P, ZHANG Z P, LI Z F, et al. Joint face detection and alignment using multitask cascaded convolutional networks[J]. IEEE Signal Processing Letters, 2016, 23(10): 1499-1503.
[15] SHEN Y J, LUO P, LUO P, et al. FaceID-GAN: learning a symmetry three-player GAN for identity-preserving face synthesis[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 821-830.
[16] CHEN Y, LAI Y K, LIU Y J. CartoonGAN: generative adversarial networks for photo cartoonization[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2018: 9465-9474.
[17] WU R Z, GU X D, TAO X, et al. Landmark assisted CycleGAN for cartoon face generation[EB/OL]. [2019-10-04]. https://arxiv.org/abs/1907.01424.
[18] ZHOU B L, KHOSLA A, LAPEDRIZA A, et al. Learning deep features for discriminative localization[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). New York: IEEE Press, 2016: 2921-2929.
Generative adversarial network-based local facial stylization generation algorithm
FAN Lin-long1, LI Yi1, ZHANG Xiao-qin2
(1. College of Computer Science and Artificial Intelligence, Wenzhou University, Wenzhou Zhejiang 325035, China; 2. Institute of Big Data and Information Technology of Wenzhou University, Wenzhou Zhejiang 325035, China)
In view of the localized facial contour features, combining with the extraction of key feature points and the fusion of adjacent color regions of the face, we presented a CycleGAN-based local facial stylization generation algorithm, and constructed the deep learning network with the attention mechanism to generate the local facial cartoon stylization. The sample facial images were marked by using the local area binarization method to constrain the key features and points. In order to naturally match the generated image with the extracted features, the mean filtering operation was utilized to smooth and feather the edge contour of the extracted region. Finally, the generative adversarial networks (GAN) network was constructed, and the training data set was employed to generate cartoon stylization images in the local contour feature area of facial images. The experiment results show that the presented algorithm exhibits high robustness for generating facial stylization, and that it can be applied to the generation of stylized facial images of various scales.
facial features; local area;generative adversarial networks; stylization
TP 391
10.11996/JG.j.2095-302X.2021010044
A
2095-302X(2021)01-0044-08
2020-04-13;
13 April,2020;
2020-08-02
2 August,2020
國家重點研發計劃項目(2018YFB1004904);溫州市科技計劃項目(G20180036,R20200025)
:The National Key Research and Development Program of China (2018YFB1004904);Basic Science and Technology Project ofWenzhou (G20180036, R20200025)
范林龍(1997–),男,四川成都人,本科生。主要研究方向為計算機視覺。E-mail:4624986@qq.com
FAN Lin-long (1997-), male, undergraduate. His main research interest covers computer vision. E-mail:4624986@qq.com
李 毅(1984–),男,寧夏銀川人,講師,博士。主要研究方向為計算機圖形學、計算機視覺等。E-mail:liyi@wzu.edu.cn
LI Yi (1984–), male, lecturer, Ph.D. His main research interests cover computer graphics, computer vision, etc. E-mail:liyi@wzu.edu.cn
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
今日農業(2021年9期)2021-11-26 07:41:24
發明與創新·小學生(2021年3期)2021-03-25 11:48:49
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
