基于混合神經網絡的惡意TLS流量識別研究
2021-04-12 05:18:26韋佶宏鄭榮鋒劉嘉勇
計算機工程與應用 2021年7期
韋佶宏,鄭榮鋒,劉嘉勇
1.四川大學 網絡空間安全學院,成都 610065
2.四川大學 電子信息學院,成都 610065
基于網絡行為特征的惡意流量識別一直是研究的熱點。Cisco 在2018 年發布的報告顯示,從2015 年到2016 年,網絡流量的加密率增長了近91%,60%以上的互聯網流量都是加密的[1]。Trustwave 2019年的一份全球安全報告顯示,在2018年全年檢測到的惡意軟件中,近67%的惡意軟件使用加密混淆技術來避免行為暴露[2]。傳統的基于明文特征的DPI、DFI檢測方法不再適用[3-6],這給加密流量精準識別和分類帶來了巨大的挑戰。
TLS是一種為應用程序提供隱私的加密協議,通常用于封裝常見的應用層協議,如HTTP、SMTP協議。由于其良好的兼容性與擴展性,被廣泛應用于各個領域。目前對于TLS 等加密協議的流量的檢測主要有兩種方法,一種是利用數據流的元數據來進行檢測,提取包括最大包長度和到達間隔時間等統計性特征,然后進行機器學習建模訓練,對惡意TLS 流量進行檢測[7-8];另一種方法是利用同一個通信實體的其他通信行為,如DNS、HTTP 等來輔助檢測[9-10]。但利用統計性特征來進行機器學習建模極大地依賴專家經驗,惡意軟件的快速迭代升級可能會使得部分由專家經驗挑選出的特征失效,導致識別率的降低。更重要的是,有些產生很大分類價值的特征并不能根據經驗直覺找出來[11]。而利用其他通信行為來進行輔助檢測數據收集難度大,同時也不能有效地對惡意流量所屬的家族種類進行區分。
深度學習在計算機視覺任務[12]和語音識別任務[13]等諸多方面都有出色的表現,隨著各種類型的神經網絡結構和不同的訓練機制的出現,深度學習已經成為處理復雜問題的一種可行且強大的方法。但僅僅依靠深度神經網絡自動挖掘出的特征進行識別,不僅訓練難度巨大,識別率也并不理想。如何充分發揮深度學習方法在挖掘深層空間特征方面的能力,同時利用好已有的專家經驗優勢成為了一個需要解決的困境。
針對以上問題,本文提出了一種基于混合神經網絡的HNNIM(Hybrid Neural Network Identification Model)模型。模型由兩層構成:第一層用于特征提取,第二層利用提取出的特征作為輸入進行建模,用于識別與分類。第一層最終提取的特征有兩部分,其中一部分特征使用深度神經網絡進行自動挖掘,另一部分特征使用并行的深度神經網絡篩選根據專家經驗挑選出的特征。然后將這些由多個深度神經網絡挖掘和篩選出來的特征進行組合,作為第二層的深度神經網絡的輸入,進一步挖掘深層空間特征。在降低對專家經驗依賴性的同時,發揮出深度神經網絡的深層空間特征挖掘能力,進而提高對惡意TLS流量的識別與分類的性能。
1 識別與分類方法
1.1 惡意TLS流量特征分析
文章主要關注隱藏于TLS協議1.2及之前版本的惡意行為的通信流量。由于傳輸內容已經被TLS 協議保護,很難通過內容檢測來發現惡意行為,目前研究的關注點更多地轉移到了協議交互信息以及下層通信的信息等不被加密方法所影響的明文信息、統計性信息上,每一個TLS 連接都會以握手開始。如果客戶端此前并未與服務器建立會話,那么雙方會執行一次完整的握手流程來協商TLS會話。在這個過程中,通信雙方協商連接參數,并且完成身份驗證。根據使用的功能的不同,整個過程通常需要交換6~10 條消息,一個對服務器進行身份驗證的完整TLS握手過程如圖1所示。
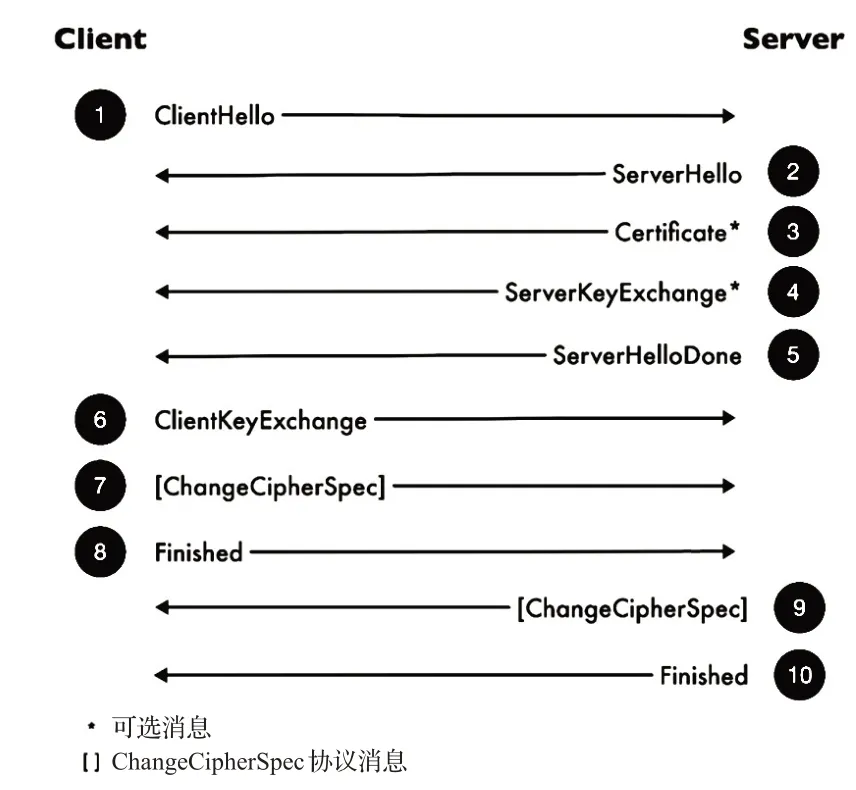
圖1 進行身份驗證的完整TLS握手過程
TLS握手的信息在流量識別中起著重要的作用,其中的ClientHello、ServerHello、Certificate等消息報文中,包括密碼套件順序、版本號、公鑰長度、TLS Extension、所傳輸的證書是否是自簽名等特征均可使惡意TLS 流量與正常流量產生一定的區分度[14-15]。
Internet協議和連接統計數據對流量和流量的識別具有重要意義,通信流中傳輸層的端口、IP 和協議信息等連接記錄也是一個重要的分類特征[16]。流行為被描述為監控數據包發送過程的一種方式,而每個惡意軟件家族都擁有不同的流行為,流中每個包的到達時間對分類起著至關重要的作用[17]。
綜上,本文將主要參考TLS 握手信息、下層通信的信息作為分類特征空間。
1.2 HNNIM模型
傳統的機器學習方法中,特征工程非常重要,因為這些淺層算法沒有足夠大的假設空間來自動學習有用的表示。而在深度學習方法中,特征工程部分均由深度神經網絡訓練后自行挖掘和篩選出有效特征,更多的工作是針對深度神經網絡的結構和算法進行選擇和優化。但是深度神經網絡不需要特征工程并不意味著能夠隨意使用原始流量數據作為輸入,自動學習到潛在的有效特征;有意義的特征輸入空間可以在使用更少的計算資源的同時獲得更好的訓練效果。
相比于使用傳統機器學習方法配合時間序列等統計性特征來構建分類器,一維卷積神經網絡在挖掘序列特征方面有著顯著的改進[18]。同樣,將具有2個卷積層,2個池化層和3個完全連接層的二維卷積神經網絡用于協議和應用程序分類任務,并將序列數據轉換為2D 圖像,最終產生的CNN 模型優于傳統機器學習方法和多層感知機模型[19]。
本文基于對深度神經網絡潛力和泛化能力的理解,以及通過對惡意TLS流量的特征分析,設計了一個多神經網絡混合的HNNIM 模型,以此來實現對惡意TLS 流量的有效識別與分類,具體結構如圖2所示。
模型的第一層,由并行的深度神經網絡組成,主要用于挖掘和篩選特征。其中特征由兩部分組成,一部分使用深度神經網絡自動挖掘每個流中多個TCP 包頭部的深層空間特征、ClientHello與ServerHello消息報文的深層空間特征,另一部分使用深度神經網絡進一步篩選根據專家經驗挑選出來的特征。
在TCP 包頭部特征的挖掘上,本文選擇了一維卷積神經網絡(CNN-1D)來進行特征挖掘工作,充分挖掘這些頭部信息隱含的包括時間在內的序列關系。在ClientHello和ServerHello消息報文的特征選擇上,具有同樣大小、類似行為特征流序列,在映射到二維圖像上時,應該具有某種相似性,所以在這部分選擇了二維卷積神經網絡(CNN-2D)來進行特征挖掘工作。在篩選根據專家經驗挑選的特征部分,由于選擇出來的特征都是離散值,因此為了消除不同特征之間的量綱影響,采用了One-Hot Code(獨熱碼)編碼方案對特征進行歸一化處理,然后作為只有單個隱藏層的全連接神經網絡的輸入,進一步篩選特征。最終,三個部分的神經網絡分別將輸出的特征維度縮小至同樣大小。
模型的第二層,是具有一個輸入層,兩個隱藏層以及一個輸出層的全連接深度神經網絡。第一部分的三個并行的深度神經網絡特征挖掘和篩選工作完成后,將這些特征進行聚合,作為第二部分的輸入,并進行訓練,產生最終的識別與分類模型。
1.3 HNNIM模型的特征空間
在TCP流數據中,使用10~30個Packet的TCP協議頭部信息已經足以在很多數據集中進行流量分類[20]。因此在使用CNN-1D 神經網絡提取TCP 包頭部深層空間特征部分,本文使用單個流中的前30個Packet的TCP協議頭部信息,共600 字節序列來作為特征輸入空間,記為Input_1,即把神經網絡的輸入維度設置為600 維。其中所提取的每個Packet 的TCP 協議頭信息的寬度設為20,如果溢出則進行截斷;若單個流中Packet 數目不足30,則進行zero-padding操作,用0進行填充補足。
通過分析大量的TLS流量,發現將提取的ClientHello消息報文的數據寬度為設置為520 字節,ServerHello消息報文的數據寬度設置為264 字節已經足夠囊括絕大部分TLS 流中的ClientHello 與ServerHello 消息報文的報文信息。因此,在使用CNN-2D神經網絡提取這兩個消息報文的深層空間特征部分,將特征輸入空間維度設置為784 維,同樣采取不足的部分進行zero-padding 操作,溢出的部分進行截斷的策略進行處理,記為Input_2,然后將784字節序列轉化為28×28大小的灰度圖。
在根據專家經驗挑選特征的部分,除了ClientHello、ServerHello消息報文中的明文字段[13],Certificate消息報文的證書鏈中end-user certificate 的一些字段也具有能夠使惡意流量與正常流量產生區分度的特征[9],因此,在這部分還添加了Certificate相關的一些特征。
除了參考已有的有效特征,本文在特征選擇方面也做了一些工作。Homem等人[21]之前的工作表明可通過熵值的高低來有效判斷域名是否隨機生成,因此本文通過計算ClientHello 消息報文中的域名字段的熵值來判斷是否隨機生成來作為一個特征;同時,基于Alexa.com統計的全球訪問量排名前100 萬的域名生成一個白名單,去判斷ClientHello消息報文中的域名信息是否存在于其中,以此作為一個特征;在Certificate消息報文的特征中,添加了包括end-user 證書里使用的簽名算法、公鑰長度等特征。
除了TLS握手階段的明文特征外,還采用了一些針對TCP 流的統計性特征,包括每個Packet 的長度分布、到達時間序列分布特征,每個Packet的TCP頭部字段的字節分布特征。此外,文獻[22]使用馬爾可夫矩陣來存儲順序Packet之間的關系。受其方法的啟發,本文應用馬爾可夫轉移矩陣來表示流行為,并記錄前后的關系。因此分別計算前30個Packet的長度分布Markov轉移矩陣,時間分布Markov轉移矩陣來作為一個特征。
在列出根據經驗判斷能夠視為有效特征的所有特征后,使用遞歸特征消除(RFE)方法[11],將不產生分類價值的特征去掉,減小輸入特征維度,篩選出的特征共26種,記為Input_3,最終篩選出的特征如表1所示。
1.4 HNNIM模型訓練
神經網絡的訓練采用基于梯度的方法,它根據對代價函數計算偏導數來更新參數。代價函數為各個類的每個樣本的損失函數之和的平均值,即式(1):
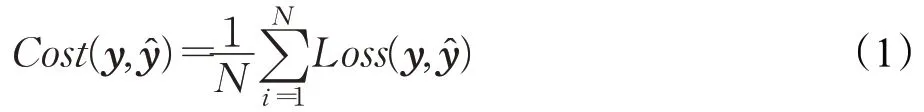
其中y為訓練結果,?為真實值。設每個神經元的第l層的參數為W(l)和b(l),η為學習率,它們的更新方式如(2)、(3)所示:
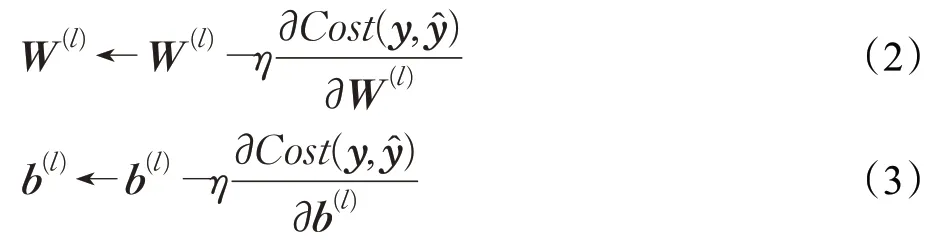
如果通過鏈式法則逐一對每個參數進行求偏導數比較低效,會導致很多重復計算的步驟,因此使用反向傳播算法來高效地計算梯度。目前為止,學習率η仍然是一個全局性的參數,這會導致某些已經優化到極小值附近的參數因為其他參數的影響而再次波動。為了適應這種情況,本文使用Adam(Adaptive moment estimation)優化方案[23],該算法通過計算梯度的一階矩估計和二階矩估計來為不同的參數設計獨立的自適應性學習率,讓學習率能夠自適應調整,以此來避免在訓練過程中可能陷入的局部最優困境。
在隱藏層里,為了避免梯度消失的問題,選用了ReLu作為激活函數,公式如式(4)所示:

在二分類任務中,輸出層神經元的激活函數選擇了對分類問題更有效果的Sigmoid 函數,代價函數采用了更適用于二分類場景的二元交叉熵函數來替代均方誤差函數,它們的函數公式如(5)、(6)所示:
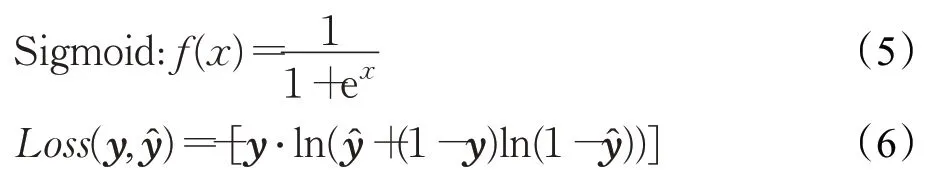
在多分類任務中,選擇了Softmax 函數作為輸出層神經元的激活函數,它將多個神經元的輸出,映射到(0,1)區間內,轉化為對應類別的概率。代價函數則采用了更適用于多分類場景的多元交叉熵函數Categorical Cross Entropy,它們的函數公式如(7)、(8)所示,其中c表示分類類別數目:
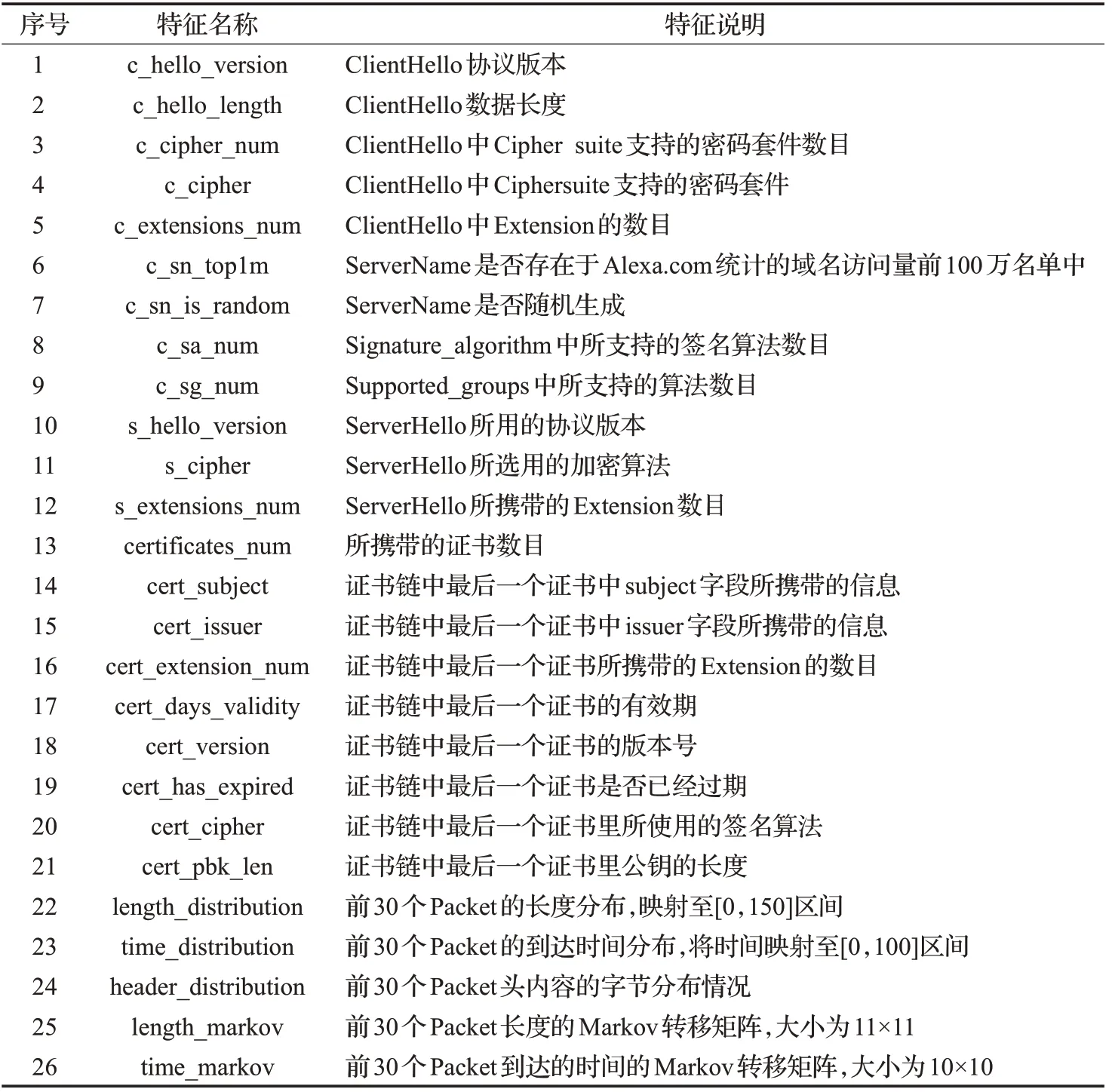
表1 根據經驗挑選的特征詳細表
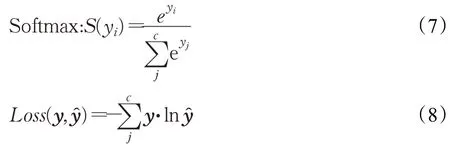
此外,在每個隱藏層還使用了Dropout 方法來減小神經網絡的體積,避免過擬合[24]。文章的目的并不是優化這些學習算法,而是找出一個比較合適的算法和結構,從而產生更好的效果。
1.5 識別與分類方法總結
HNNIM 模型在第一層進行了特征篩選工作,利用一維卷積神經網絡對潛在的序列特征進行挖掘;利用二維卷積神經對映射到圖上的流量信息進行特征挖掘;利用深度神經網絡對根據專家經驗選取的特征作進一步篩選;從不同的維度來降低整體的特征空間,降低對專家經驗的依賴性。
第二層的全連接深度神經網絡使用篩選后的特征作為輸入,在特征搜索空間縮小的情況下能夠加快模型收斂速度,提升識別率。
綜上,通過所提出的HNNIM模型,配合根據專家經驗選擇出的特征,可以構建分類器來識別惡意TLS 流量,并對它們進行惡意家族的分類,本文的實驗也將基于以上結構和方法進行展開。
2 實驗結果與分析
2.1 實驗數據及環境
在本文的實驗中,使用CICIDS 2017數據集[25]中的正常流量、CTU-Normal-Capture數據集[26]的流量來作為正常流量;Malware-Traffic-Analysis[27]、CTU-Malware-Capture[26]數據集的流量作為惡意流量。這些流量并不全部都是TLS 流量,且部分流量具有重復,因此本文還對流量樣本進行了預處理,將無關干擾信息過濾,僅使用承載于TCP協議層上的非重復TLS流量。
獲取到的流量數據為pcap格式,是由多個通信實體在某個時間段內產生的通信數據,因此還根據五元組將原始流量分割為TCP 協議流數據,每一條TCP 協議流數據包含兩個相互通信的實體某個時間段內完整的TLS通信信息。將TLS流量中ClientHello報文中的Extension 條目下的ServerName 子項、整個ClientHello 報文的長度、整個ServerHello報文的長度均相同的兩條通信流定義為重復條目,將其中一條剔除。將從單條流中提取的特征作為一個樣本,最終提取的樣本具體數據如表2所示。
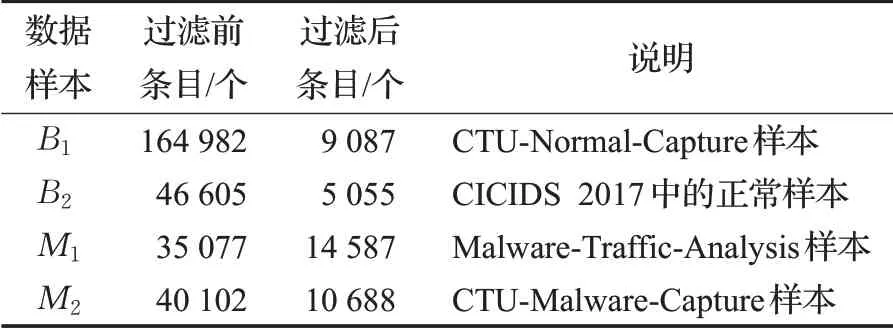
表2 數據集樣本
在獲取的數據樣本集{M1}中,部分樣本具有明確的惡意家族標簽,共計9 種惡意家族。因此,本文選擇將這些樣本用于多分類實驗,最終樣本數據如表3 所示,其中M1?{M1i,i=1,2,3…}。
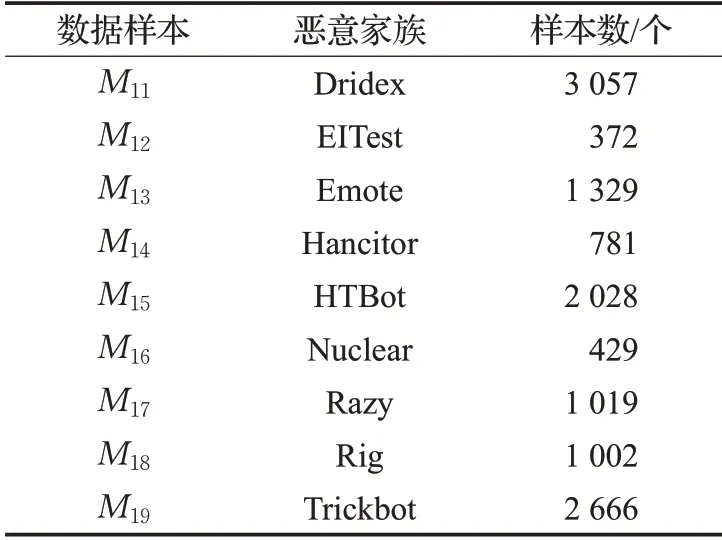
表3 Malware-Traffic-Analysis惡意家族樣本
2.2 實驗評估指標
收集到的樣本數目并不均衡,在二分類的任務中準確率的參考價值有限。同時二分類任務中的關注點更多地是在惡意樣本的識別結果上,故二分類任務的實驗結果由召回精確率調和平均數(F1)、召回率(Recall)、精確率(Precision)來衡量。在多分類任務中,主要的關注點在每個惡意家族的識別正確率上,因此實驗結果由準確率(Accuracy)來衡量。

其中,TP表示將屬于某分類的加密流量正確識別為該分類,FP表示將不屬于某分類的加密流量識別為該分類,TN表示將不屬于某分類的加密流量識別為非該分類,FN表示將屬于某分類的加密流量識別為非該分類。精確率、召回率反映了識別方法在每個類別流量數據上的識別效果;F1是均衡精確率和召回率獲得的綜合評價指標,F1越高表明算法在各個類型的分類性能越好。
2.3 實驗結果與分析
本文主要驗證HNNIM模型與已有的傳統機器學習方法、自動挖掘特征的深度學習方法是否有提升。在傳統機器學習方法中,目前常用于流量分類的有隨機森林、SVM、XGBoost 等模型[11];在深度學習方法中,文獻[28]提出了一種將原始通信流量前784字節視為圖像,作為卷積神經網絡(CNN)的輸入,由神經網絡自行挖掘深層空間特征的方法。但為了控制變量,本文僅采用上述的模型來作為對比,特征部分改為與本文所選的特征一致。
在HNNIM 模型的超參數中,所有的神經網絡初始學習率設為0.003,Dropout 為0.4,一維卷積神經網絡中,設置4 個大小為4 的卷積核,使用2 個卷積層與1 個池化層以及2個完全連接層。二維卷積神經網絡中,設置32個大小為3×3的卷積核;使用2個卷積層與1個池化層以及2 個完全連接層,迭代次數Epoch 為20,數據大小batch size為500,對比實驗中的CNN模型,使用同樣的參數進行訓練。隨機森林模型中,弱學習器的最大迭代次數n_estimators設為128,其余均采用模型默認參數;SVM 模型中,使用線性核函數,無需設置額外的超參數;在XGBoost 模型中,booster 使用樹模型gbtree,更新過程中的收縮步長eta 設置為0.25,樹的最大深度max_depth設置為5,其余均使用默認參數。
2.3.1 二分類效果對比
實驗使用{B1,M1}數據集來訓練模型,使用{B2,M2}數據集進行驗證,以此來充分驗證模型的泛化能力。實驗結果如表4所示。
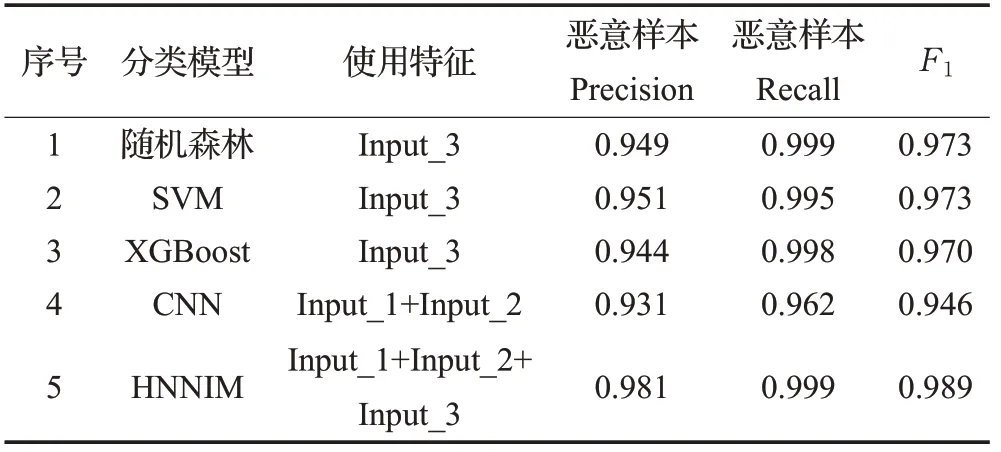
表4 二分類實驗結果
實驗結果顯示,自動挖掘特征的CNN 模型的精確率為0.944,召回率為0.962,F1值為0.946,均顯著低于傳統機器學習方法中的隨機森林、SVM、XGBoost 模型。這一方面表明了根據專家經驗挑選的特征能夠在一定程度上對正常與惡意流量進行區分,傳統機器學習方法因此取得了較好的效果;另一方面也表明了僅利用深度神經網絡自動挖掘特征來進行分類,其結果并不一定就優于傳統機器學習方法。
HNNIM模型最終的精確率為0.981,召回率為0.999,F1值為0.989,均要高于其他任一模型。因此,它有效地利用了根據專家經驗挑選的特征(Input_3),并充分發揮深度神經網絡挖掘深層空間特征的能力。
2.3.2 多分類效果對比
多分類任務中,使用M1數據集中已經分類好的樣本,共9 個類別,來作為訓練和驗證的樣本。部分惡意家族樣本相當少,本文采取over-sampling(上采樣)方案,應用經過改進的SMOTE算法[29],通過在少數類中加入隨機噪聲、干擾數據以及通過一定規則產生新的合成樣本,增加分類中少數類樣本的數量;針對樣本比較多的惡意家族樣本,使用under-sampling(下采樣)方案[30],減少該類樣本,以此來實現樣本均衡。最終每種惡意家族樣本的規模為1 000,實驗結果使用五折交叉驗證,將樣本平均分為5份,輪流將其中4份作為訓練集,余下一份作為測試集,最終結果為5次測試的均值。各個模型使用的特征輸入以及實驗結果,如表5所示。
各個模型實驗結果混淆矩陣如圖3所示。
實驗結果顯示,在多分類任務中,傳統機器學習方法中隨機森林、SVM、XGBoost 模型的平均準確率分別為79.36%、80.19%、77.97%;自動挖掘特征的CNN 模型的平均準確率為82.25%,均不夠理想。實驗中傳統機器學習方法的局限性開始體現,其分類效果依賴于根據專家經驗挑選的特征Input_3,但是這些特征從結果來看并不能很好地區分惡意家族種類;CNN 模型自動挖掘特征來進行分類,效果雖然比傳統機器學習方法有提升,但準確率也并沒有得到明顯的提升。HNNIM 模型最終平均準確率為89.28%,均高于其他模型,因此HNNIM 模型能夠充分結合這兩種方法的優點,分類結果有了較為顯著的提升。
通過上述實驗,可以發現僅使用根據專家經驗挑選特征或僅由機器自動挑選特征的模型存在的一些不足。僅使用傳統機器學習方法配合根據專家經驗挑選的特征容易受到場景的制約,同一特征在二分類和多分類場景中并不都獲得一致的分類收益;僅由神經網絡自動挑選特征,搜索空間大,訓練難度大,結果也仍有待提高。實驗結果表明,所提出的HNNIM 模型能夠有效地解決這一困境,獲得更好的識別和分類效果。值得指出的是,深度神經網絡受參數與優化方式的影響較大,仍然可以進一步嘗試調參以及使用不同的優化算法來提升它的性能。

表5 多分類實驗準確率 %
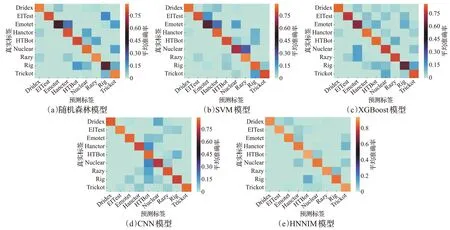
圖3 各模型多分類結果混淆矩陣
3 結語
由于TLS等加密協議的廣泛使用,目前的惡意加密流量識別方案逐漸失效,基于專家經驗的傳統機器學習方法受到專家經驗的制約較大,分類效果也不理想。本文提出的HNNIM 模型,結合TLS 協議握手階段的明文信息以及TCP協議頭部字段信息,能夠充分結合深度神經網絡挖掘深層空間特征的學習能力與現有專家經驗的優勢,降低對專家經驗的依賴,有效提升針對惡意TLS流量的識別與分類效果。
本文主要針對使用TLS1.2及以下版本的協議的惡意流量進行識別,針對隱藏于TLS1.3 協議下的惡意流量的有效識別將成為下一步研究的重點。
