空洞殘差U型網絡用于視網膜血管分割
2021-04-12 05:19:34胡揚濤李世成易玉根
計算機工程與應用 2021年7期
胡揚濤,裴 洋,林 川,李世成,易玉根
1.中國人民解放軍聯勤保障部隊 第908醫院眼科,南昌 330002
2.江西師范大學 軟件學院,南昌 330022
青光眼是世界上第一種不可逆轉的致盲性眼科疾病,也是成為世界上第二大致盲疾病。青光眼疾病的早期并沒有明顯的癥狀,往往到晚期才會暴露出來,但一旦發生將不可逆轉。由于其隱蔽性強、致盲率高以及危害性大,因此,眼科醫生強調及時進行眼底檢查,并盡早發現和早治療。在臨床試驗中,醫生通常是通過觀察視杯和視網膜面積的結構變化以及視網膜血管的變化來篩選和診斷青光眼。然而,傳統的方法是將眼底圖像與醫生的主觀醫學經驗相結合,費時費力且重復性高,還極容易造成檢查結果存在差異。此外,尤其在邊遠地區,受醫療設備和臨床眼科醫生的限制,患者在眼底檢查中更是容易出現誤診與漏診現象。近年來,隨著人工智能與計算機視覺技術的迅速發展和應用,計算機輔助診斷技術將圖像處理和深度學習技術相結合,通過模擬人腦神經元的工作模式建立網絡模型,實現對眼底疾病的智能輔助篩查和診斷[1]。計算機輔助診斷首先從眼底圖像中分割視網膜血管、視盤和視杯結構,然后分析各結構的變化以篩選青光眼疾病。因此,視網膜血管分割在輔助診斷過程中起著關鍵性的作用。
盡管現有的分割方法可以分割出視網膜血管的結構,但仍存在精度低、靈敏度差和分割區域錯誤等問題。針對上述問題,本文旨在利用深度學習技術對視網膜血管結構進行準確分割,協助眼科醫生進行青光眼診斷,防止青光眼導致的失明。
1 相關工作
目前研究者提出大量的血管分割方法,大概可以分為基于傳統的方法和基于深度學習的方法[2]。
1.1 基于傳統分割方法
基于傳統的分割算法大致可以分為基于區域分割的方法、基于邊緣檢測的方法、基于形態學的方法、基于活動輪廓模型的方法、基于機器學習的方法[3]。
基于區域的分割方法[4]主要根據區域特征的相似性進行分割,即將相似性較強的區域像素劃分為相同區域。該類方法又可以分為基于閾值的方法和基于區域生長的方法兩大類。基于閾值的方法是一種簡單且常用的方法,其思想是通過選取一定閾值,然后將每個像素與閾值作比較進行分類。該方法被廣泛應用于灰度圖像的分割,但其對于峰值不明顯的圖像分割效果較差。此外,閾值選擇在很大程度上影響其分割結果,因此如何選擇閾值成為核心問題。目前包括迭代閾值法、直方圖閾值法以及最大類間方差法等大量方法被提出。例如,文獻[5]首先對圖像背景進行均勻化和降噪,然后采用自適應局部閾值方法對血管圖進行粗逼近,最后通過曲率分析和形態重建進行細分割估計視網膜血管。基于區域生長的方法主要根據事先定義的生長準則,以一組“種子”點為起點,逐步通過加入相鄰的像素或者區域擴大其區域,直到達到條件停止區域擴充。該方法簡單且無需任何先驗知識,因此被廣泛應用于復雜的圖像分割任務中。但由于它屬于一種迭代的方法,將會造成極大的空間與時間開銷。此外,“種子”點的選擇是該類方法成功的關鍵。例如,文獻[6]使用各向異性擴散濾光器來平滑圖像并保持血管邊界,然后利用區域生長方法和水平集方法實現視網膜血管分割。
基于邊緣檢測的方法[7]主要是利用圖像不同區域交界處有著明顯的屬性變化的特性。該類方法首先根據一定算法確定圖像中的邊緣像素,然后將它們按照一定的規則連接起來形成特定的區域邊界,最后利用邊緣的灰度和紋理等特征的不連續性檢測邊緣,從而實現圖像分割。因此,該類方法的核心問題是如何確定邊緣像素。目前常用的方法包括基于一階或者二階的圖像微分算子、基于區域的Hough 變換方法、基于參數模型的擬合算子方法等[7]。
基于形態學的方法主要利用一組形態學基本運算原則(如:腐蝕與膨脹、開閉操作、高低帽變換等),進行緣檢測和特征提取。文獻[8]采用基于多方向多結構元素的形態學進行血管與其背景的分離,然后采用基于滯后閾值引導形態學操作排除二值圖像中干擾區域。文獻[9]提出改進的形態學與Otsu相結合的無監督視網膜血管分割算法,首先運用高低帽變換增強血管與背景的對比度,然后通過修正方法消除由視網膜疾病引起的光照問題,最后使用Otsu閾值方法分割血管。
基于活動輪廓模型的方法則通過設計不同的能量函數驅動活動輪廓線向血管邊界處演化,實現血管的分割。該類方法雖然精度高且穩定,但其運算量大,不適用于大規模數據集。文獻[10]提出一種新的無限活動輪廓模型,該模型使用圖像的混合區域信息。
基于機器學習的血管分割方法主要是針對血管結構定義不同于眼底圖像中其他區域的特征向量,然后采用有監督、無監督以及半監督學習算法,將圖像像素分成血管或非血管像素,從而實現血管的分割[11]。文獻[12]提出一種基于多特征融合的有監督視網膜血管提取方法,該方法首先提取不同類型的特征,然后通過隨機森林訓練視網膜血管分類器,最后根據血管圖像灰度信息和連通域信息進行后續處理得到最終的血管。文獻[13]給出基于極限學習機快速的血管提取方法。綜述性文獻[14]給出了大量基于機器學習的血管提取方法。
1.2 基于深度學習的分割方法
受深度學習在自然圖像分類、自然語言處理等領域的成功應用,基于深度學習的圖像分割方法也隨之發展起來。基于深度學習的圖像分割方法主要利用深度學習模型提取原始圖像的深度特征,然后結合不同的分類器實現血管分割[15-16]。文獻[17]中介紹了大量的方法,本文主要簡單回顧基于特征編碼和基于上采樣這兩類方法。
在基于特征編碼方法中,VGGNet[18]和ResNet[19]是兩種非常重要的網絡結構。VGGNet主要由大小3×3的卷積核和2×2 的最大池化層疊加而成,構建16~19 層深度的卷積神經網絡,其優點可以解決傳統網絡加深產生參數爆炸的問題。ResNet 的核心思想是引入了恒等映射,直接將原始的輸入信息傳輸到下一層,并在過程中只能學習前一個網絡輸出的殘差。因此解決了隨著深度學習網絡加深導致的梯度消失的問題。
基于上采樣方法中,全卷積神經網絡(Fully Convolutional Network,FCN)[20]和U 型網絡(U-Net)[21]是兩個具有代表性的網絡模型。該類方法在采樣過程中會損失部分信息,從而得到更為重要的特征,因此在一定程度上通過上采樣操作可以得到更精確的分割邊界。但此過程是不可逆轉的,有時甚至會導致圖像分辨率低以及細節丟失。FCN 方法是一種反卷積-升采樣結構,其核心思想是經過采樣擴大像素,再進行卷積并通過學習獲得權值。其優點是可以接受任意大小的輸入圖像,并保留其空間信息,解決了圖像語義級分割問題。但由于每個像素的上采樣都是單獨分開執行的,因此沒有考慮像素之間的關系和缺乏空間一致性,從而導致部分結果模糊以及對圖像細節處理不敏感。U-Net 是FCN 的改進網絡模型,它主要由收縮路徑(特征提取)和擴展路徑(上采樣)兩部分組成。收縮路徑部分用于捕獲圖像中的上下文信息,而上采樣部分則用于恢復圖像位置信息。U-Net能夠訓練相對較少的數據樣本獲得較好的性能,因此,U-Net被廣泛應用于醫學相關領域。隨著深度學習的快速發展,大量基于深度學習的血管分割方法也被提出[17]。例如:Fu 等[22]提出基于卷積神經網絡(Convolutional Neural Network,CNN)和全連通條件隨機域(Conditional Random Field,CRF)的視網膜血管分割方法,該方法利用CNN 和CRF 集成深度學習網絡用來分割視網膜血管。梁禮明等[23]提出一種融合DenseNet和U-Net兩個模型的視網膜血管分割算法,提高了視網膜血管的分割準確性。Gu等[24]提出一種上下文編碼器網絡(Context Encoder Network,CE-Net)來捕獲更多高級信息用于2D醫學圖像分割。
2 空洞殘差U型網絡
U 型網絡(U-Net)[21]是一種基于像素級別的語義分割網絡,對醫學圖像等小型圖像數據集表現出較好的分割性能。因此,將U-Net 作為基本框架,能夠很好的解決小樣本問題。但U-Net 由收縮路徑和擴張路徑兩條路徑組成,收縮路徑通過下采樣操作逐漸減小圖像的空間維度,而擴張路徑通過上采樣操作逐漸修復對象的細節和空間維度。因此,在經過卷積和下采樣后會存在梯度消失、結構信息丟失、損耗等問題。針對上述問題,本文引入殘差網絡(ResNet)和空洞卷積(Atrous Convolution)模塊,將其整合到U-Net網絡中,提出一種新的網絡結構稱為空洞殘差U 型網絡(AR-Unet),該網絡體系結構如圖1所示。AR-Unet能夠在不損失信息的情況下進一步擴大感受野和提高物體之間的相關性,從而提高血管分割的性能。
為了清晰地對AR-Unet的網絡結構進行描述,將圖1 中的AR-Unet 結構簡化為如圖2 所示。圖2 中A 和C分別表示收縮路徑(特征提取)和擴展路徑(上采樣)部分,且每部分又分別由四個小模塊組成。不同于原始的U-Net,為了減少結構信息丟失損耗和加快網絡收斂,將A 部分中每個模塊的第二個卷積模塊(Conv)替換為殘差模塊(Resnet Block)得到新的網絡結構如圖3所示,殘差模塊定義為如圖4 所示。B 部分將原先的卷積層模塊替換為空洞卷積模塊,擴大感受野,提高物體間相關性,其結構如圖5 所示。C 中的每個模塊結構如圖6所示。
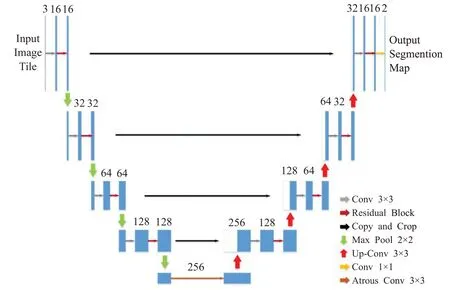
圖1 AR-Unet體系結構
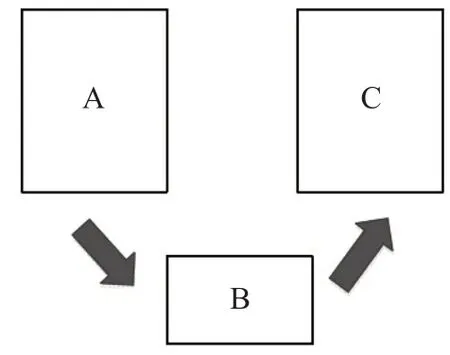
圖2 AR-Unet模型分塊圖
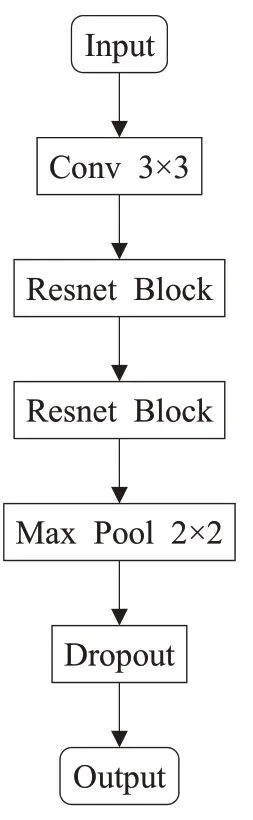
圖3 收縮路徑結構圖
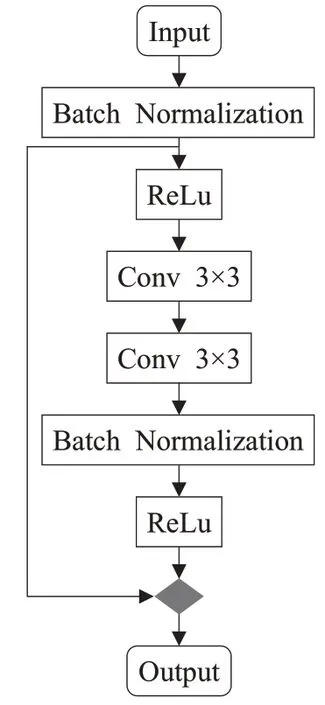
圖4 ResNet Block結構圖
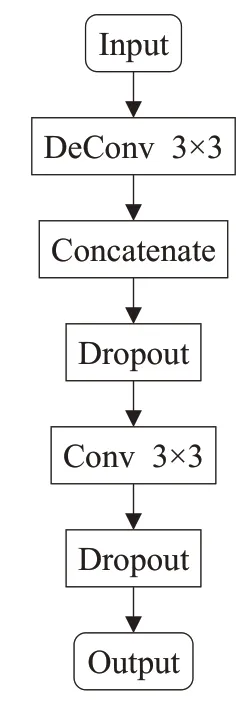
圖5 擴張路徑結構圖
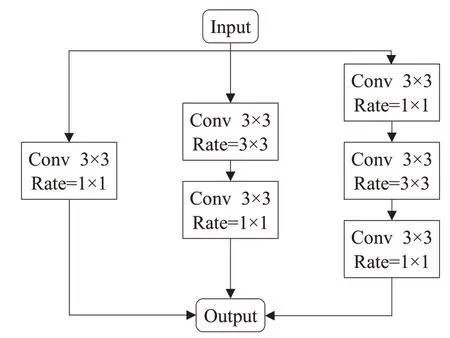
圖6 空洞卷積結構圖
3 實驗
首先介紹三個常用的數據集和多個重要的性能評價指標;然后,介紹實驗平臺和實驗參數配置;最后,設計實驗驗證AR-Unet方法的性能,并且與最新方法進行比較。
3.1 實驗數據集
為了驗證AR-Unet的有效性,實驗中采用了DRIVE[25]、STARE[26]和CHASE[27]三個數據集,每個數據集包含兩組專家手動標記血管的圖像。本實驗中使用第一組作為標準進行訓練和測試,具體信息如表1 所示,從表中可知每個數據集的圖像數量較少且分辨率高。

表1 實驗中所采用的數據庫具體信息
3.2 評價指標
實驗中采用準確度(Accuracy,ACC)、精度(Precision,PPV)、真陽率(True Positive Rate,TPR)、假陽率(False Positive Rate,FPR)、真陰率(True Negative Rate,TNR)、F-measure(F1)、Jaccard相似度和AUC等評價指標對分割算法的性能進行分析,其定義分別如下:

其中,真陽性數(TP)表示將正例預測為正例的數量,假陽性數(FP)表示將負例預測為正例的數量,假陰性數(FN)表示將負例預測為負例的數量,真陰性數(TN)表示將正例預測為負例的數量,SR 代表實際分割結果,GT 代表真實結果。各項評價指標的值越大,說明算法性能越好。
3.3 實驗配置及參數設置
AR-Unet 模型開發集成環境為PyCharm,基于Tesnorflow 的Keras 框架。運行平臺為Window 系統,GPU 為GeForce RTX 2080,內存32 GB。采用Adam優化方法對參數進行優化,學習率設定為0.001,損失函數采用交叉熵。實驗迭代訓練次數為200 次,batch_size為4。
3.4 實驗結果與分析
首先,本文將AR-Unet與U-Net、U-Net*兩種模型進行比較,其中U-Net*是指在U-Net 的池化操作后增加Dropout 層,防止過擬合現象。實驗結果如表2~4 所示。實驗結果表現AR-Unet 在大多數指標上都達到了最佳。在DRIVE數據集中,AR-Unet在TPR、F1和AUC三個指標要明顯高于U-Net 和U-Net*,指標JS 和ACC也要稍微高于U-Net 和U-Net*。在STARE 數據集中,AR-Unet在TPR、F1和AUC三個指標要明顯高于U-Net和U-Net*,指標PPV、JS 和ACC 也要稍微高于U-Net 和U-Net*。在CHASE 數據集中,AR-Unet 在TNR、JS、ACC和AUC四個指標要略高于U-Net和U-Net*。總體而言,實驗結果表明AR-Unet方法具有較好的視網膜血管分割性能。

表2 在DRIVE數據集上性能比較

表3 在STARE數據集上性能比較

表4 在CHASE數據集上性能比較
圖7~9 列出了U-Net、U-Net*和AR-Unet 三個網絡模型在三個數據集上的視網膜血管分割的可視化結果。AR-Unet可以很好地分割出了U-net和U-net*部分丟失的細微血管,并保留了更多的血管中的細節。因此,其結果進一步驗證了AR-Unet對于低對比度的視網膜血管具有一定的魯棒性。
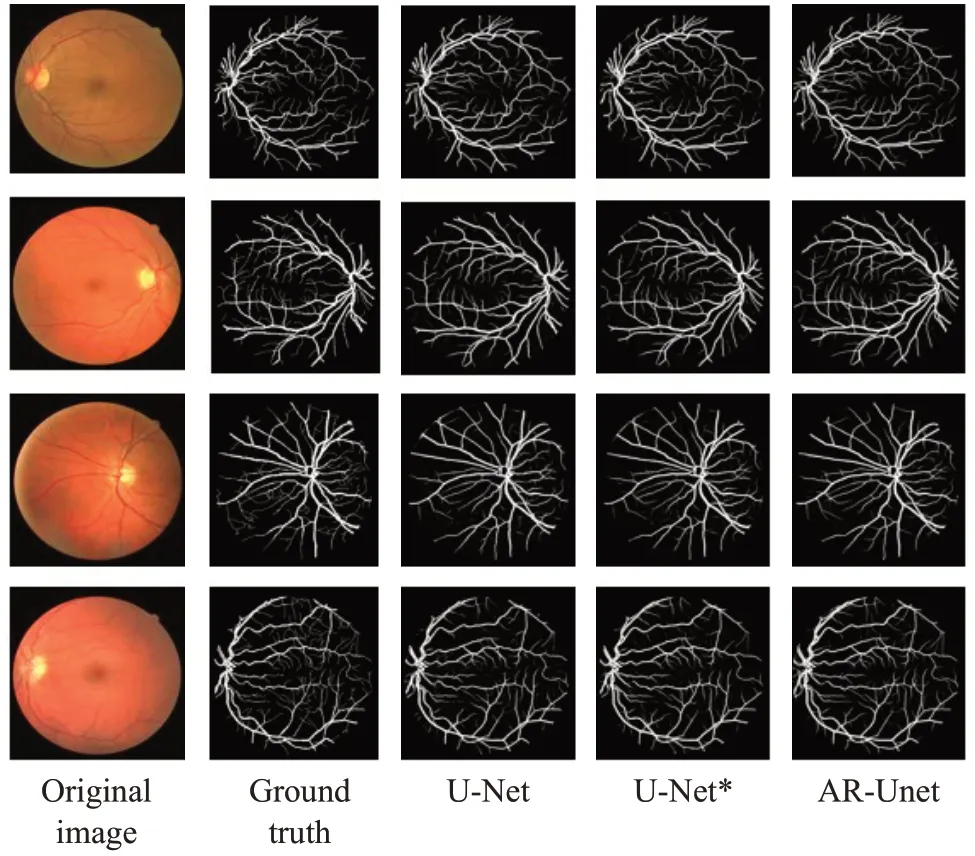
圖7 在DRIVE數據集上的分割結果
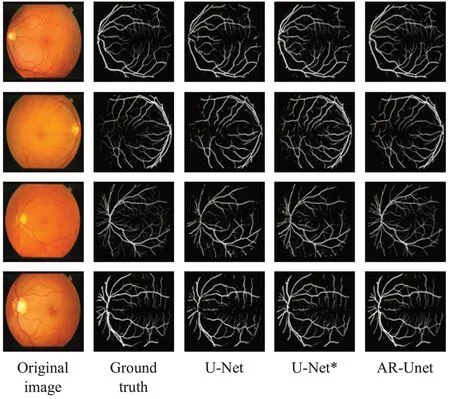
圖8 在STARE數據集上的分割結果
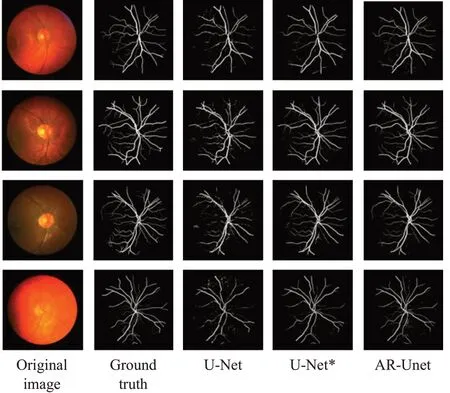
圖9 在CHASE數據集上的分割結果
其次,將AR-Unet方法與當前具有代表性的方法進行比較。在三個數據集上的實驗結果如表5~7所示,其中對比方法的實驗結果來自于相應的參考文獻,表中“—”表示參考文獻沒有給出相應的結果。實驗結果表明,AR-Unet方法在視網膜血管分割任務上的性能要優于其他對比方法。
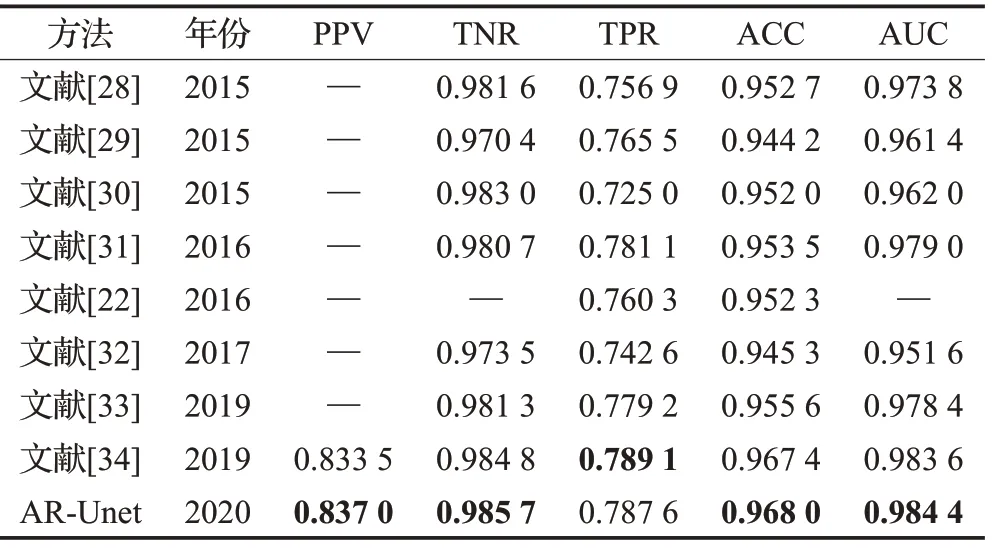
表5 在DRIVE數據集上與其他方法的比較
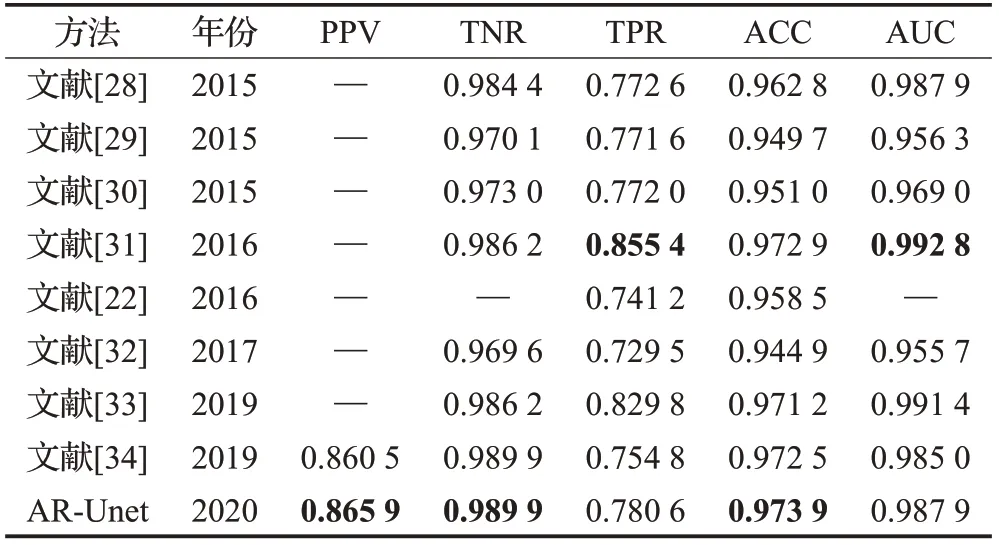
表6 在STARE數據集上與其他方法的比較
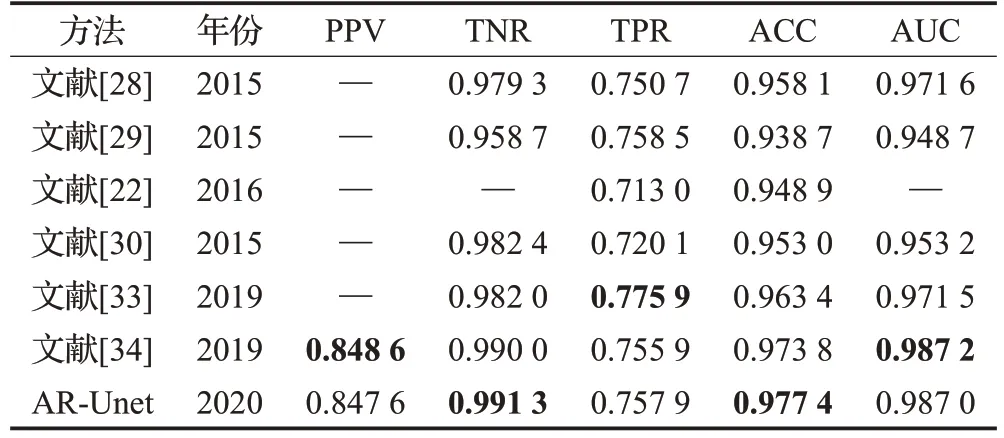
表7 在CHASE數據集上與其他方法的比較
4 結束語
目前大部分方法能夠準確分割出視網膜血管結構,但血管分割時仍然存在部分信息丟失導致部分微小血管不能很好的分割出來的問題,為此,本文提出一種新的網絡稱為AR-Unet。首先主要通過結合U-net和殘差網絡,AR-Unet 網絡能夠很好地處理結構信息丟失、損耗等問題。然后,通過增加空洞卷積模塊,在不損失信息的情況下,擴大了感受野,提高物體之間的相關性,AR-Unet 網絡使得血管分割更加精確。在三個公開數據集上與目前具有代表性的方法進行比較,實驗結果表示AR-Unet 方法在大多數性能評價指標優于對比方法。由于醫學圖像人工標注費時費力,導致樣本較少,通過數據增強也只能增加部分樣本。因此,未來工作將考慮通過生成式對抗網絡(GAN)來增加數據樣本。
