一種時空特征聚合的水下珊瑚礁魚檢測方法
2021-04-13 02:00:06陳智能史存存李軒涯賈彩燕黃磊
北京航空航天大學(xué)學(xué)報 2021年3期
陳智能,史存存,李軒涯,賈彩燕,黃磊
(1.中國科學(xué)院自動化研究所 數(shù)字內(nèi)容技術(shù)與服務(wù)研究中心,北京100190;2.北京交通大學(xué) 計算機(jī)與信息技術(shù)學(xué)院,北京100044;3.百度公司,北京100085; 4.中國海洋大學(xué) 信息科學(xué)與工程學(xué)院,青島266100)
珊瑚礁魚泛指生活在熱帶海洋珊瑚叢中的各種魚,它們種類繁多、形態(tài)各異、色彩斑斕,是最富活力和觀賞性的海洋生物群體之一。研究表明,珊瑚礁魚的種類、數(shù)量和活動痕跡是否豐富,直接反映了珊瑚礁生態(tài)系統(tǒng)的健康狀態(tài)和海洋生物多樣性豐富程度[1]。珊瑚礁魚活動的顯著變化,則往往與溫度劇變、水域污染和過度人類活動等事件緊密聯(lián)系[2]。通過監(jiān)測分析珊瑚礁魚的活動,可以快速、準(zhǔn)確、精細(xì)地掌握海洋生態(tài)系統(tǒng)的健康狀況。此外,珊瑚礁魚的分析研究還將有助于幫助海洋生物學(xué)家研究不同海洋動物的行為及其之間的相互作用[3]。目前,隨著全球大多數(shù)珊瑚礁生態(tài)系統(tǒng)呈退化趨勢,這一研究已經(jīng)得到了廣泛重視。
在海洋科學(xué)領(lǐng)域,最初人們主要采取人工撒網(wǎng)法[4]和潛水調(diào)查法[5]開展珊瑚礁魚活動調(diào)查。人工撒網(wǎng)法先由人在珊瑚礁水域撒網(wǎng)撈魚,再經(jīng)過海洋生物學(xué)家整理得到分析結(jié)果。潛水調(diào)查法由專業(yè)潛水員手持水下攝像機(jī)穿越珊瑚礁水域,通過對所拍攝影像進(jìn)行事后分析,得到調(diào)查范圍內(nèi)的珊瑚和珊瑚礁魚情況。雖然已被沿用很多年,它們的缺點也很明顯:執(zhí)行一次調(diào)查不僅消耗大量人力物力,而且會對魚類活動產(chǎn)生一定影響,此外還難以獲得大面積連續(xù)的監(jiān)測數(shù)據(jù)。隨著水下成像技術(shù)的發(fā)展,在珊瑚礁水域特定位置安裝水下攝像機(jī),采集珊瑚礁魚活動影像并進(jìn)行分析正在成為一種普遍接受的做法。相比于傳統(tǒng)調(diào)查方法,水下攝像既不影響珊瑚礁魚行為,同時也為后續(xù)分析提供了大量素材。目前,全球多個國家和地區(qū)的珊瑚礁水域都部署了水下攝像系統(tǒng)并產(chǎn)生了大量珊瑚礁魚監(jiān)控影像。對這些影像的分析催生了跨學(xué)科交叉研究需求:海洋生物學(xué)家手動分析每天產(chǎn)生的大量影像數(shù)據(jù)是不切實際的,迫切需要智能化的珊瑚礁魚分析技術(shù),能夠從真實水下環(huán)境采集的影像中,自動得到珊瑚礁魚的出現(xiàn)位置、種類、數(shù)量等信息。
在信息科學(xué)領(lǐng)域,視頻大數(shù)據(jù)智能分析是一個廣受關(guān)注的研究課題。特別是近年來,基于深度學(xué)習(xí)的視頻分析與理解取得了顯著突破,在大規(guī)模視頻分類與檢測[6-10]、細(xì)粒度圖像分類[11-12]等任務(wù)上,深度學(xué)習(xí)相比于傳統(tǒng)方法性能取得了大幅提升。但是,目前多以消費類視頻圖像及安防、交通等領(lǐng)域的監(jiān)控視頻為研究對象,對水下影像的分析相對較少。水下影像具有成像質(zhì)量不高、水下環(huán)境復(fù)雜等分析難點,此外具體到珊瑚礁魚檢測上,還存在視覺多樣性高、標(biāo)注數(shù)據(jù)有限等挑戰(zhàn),這些困難決定了直接應(yīng)用其他領(lǐng)域成熟的分析方法并不是最優(yōu)方案,需要專門研究珊瑚礁魚的有效檢測方法。
目前,已經(jīng)有一些針對珊瑚礁魚檢測分析的研究工作。早期研究多在受限情況下開展。例如,文獻(xiàn)[13]提出了一種基于輪廓匹配的魚識別方法,文獻(xiàn)[14]提出了一種基于特征變換和支持向量機(jī)的羅非魚自動分類方法,他們的實驗都是在已捕撈、拍照時擺放較規(guī)則的魚的圖像上開展。針對水下自然環(huán)境中生活的魚,文獻(xiàn)[15-16]從不同角度提出了聯(lián)合形狀和紋理特征的魚分類方法,結(jié)果表明,水下環(huán)境魚檢測分類的難度明顯大于之前的受限環(huán)境。面對水下珊瑚礁魚成像分辨率低的問題,Wei等[17]提出了一種利用互聯(lián)網(wǎng)高分辨率魚圖像進(jìn)行數(shù)據(jù)增強的珊瑚礁魚分類方法。圍繞真實水下監(jiān)控視頻珊瑚礁魚檢測的Sea-CLEF系列國際競賽[18],來自韓國首爾大學(xué)[19]、德國耶拿大學(xué)[20]的團(tuán)隊采用了運動前景提取與基于深度學(xué)習(xí)分類相結(jié)合的解決方案,取得了較好成績。近期相關(guān)工作更傾向于利用深度學(xué)習(xí)目標(biāo)檢測模型來解決珊瑚礁魚檢測問題。例如,文獻(xiàn)[21]提出了一個相鄰層特征融合的全卷積網(wǎng)絡(luò)進(jìn)行珊瑚礁魚檢測。為更好應(yīng)對水下復(fù)雜環(huán)境,Zhuang等[22]提出了先用SSD模型[23]檢測珊瑚礁魚,再用ResNet網(wǎng)絡(luò)[24]對檢測前景進(jìn)行分類的方法。印度韋洛爾技術(shù)大學(xué)的研究團(tuán)隊[25]評估了不同主干網(wǎng)Faster R-CNN模型[26]在該競賽上的檢測性能。德國杜塞爾多夫大學(xué)的學(xué)者[27]提出了一種基于YOLO模型[28]的改進(jìn)方法,取得了較好的檢測效果。
上述研究雖然顯著推動了珊瑚礁魚自動檢測技術(shù)的發(fā)展,但仍存在一些不足:將珊瑚礁魚檢測視為一個前景提取及分類的任務(wù),或?qū)⑵湟暈橐粋€圖像目標(biāo)檢測加上時序后處理的任務(wù)。前者雖然前景提取時能一定程度利用視頻時序信息抑制水下復(fù)雜環(huán)境造成的負(fù)面影響,但其將檢測過程切分成了前景提取和分類2個獨立的子任務(wù),二者無法相互促進(jìn)和增強,檢測性能受到限制。對于后者,由于檢測時忽視了時序維度,且受目標(biāo)大小有限、環(huán)境復(fù)雜等的影響,深度模型難以提取高質(zhì)量檢測特征,易造成誤檢和漏檢,雖然時序后處理可消除一部分錯誤,但這也很難稱之為視頻時序信息的深入利用。
認(rèn)識到特征辨識力不足是制約當(dāng)前檢測精度提升的關(guān)鍵因素,本文提出了一種時空特征聚合的水下珊瑚礁魚檢測方法。具體地,設(shè)計了一個新穎的卷積網(wǎng)絡(luò)結(jié)構(gòu)以提取更具辨識力的時空聯(lián)合特征。該網(wǎng)絡(luò)從SSD模型發(fā)展而來。同時,其包含一個多層視覺特征聚合模塊,以提取更豐富的視覺特征,以及一個時序特征聚合模塊,可結(jié)合運動目標(biāo)生成時序強化的特征表示。通過以上2個模塊實現(xiàn)對空間和時間2個維度特征的聚合,得到了可有效表征水下視覺目標(biāo)的時空聯(lián)合特征。公開數(shù)據(jù)集上的實驗表明,本文方法可提升真實水下環(huán)境珊瑚礁魚檢測的精度。
本文的主要貢獻(xiàn)如下:
1)提出了一個多層視覺特征聚合的深度網(wǎng)絡(luò)模塊,設(shè)計了自頂向下的切分和自底向上的歸并,可實現(xiàn)不同分辨率多層卷積特征圖的聚合。
2)提出了一個時序特征聚合的深度網(wǎng)絡(luò)模塊,可結(jié)合運動目標(biāo)融合相鄰幀的卷積特征圖,從時序維度強化所提取特征。
3)通過集成以上2個模塊,提出了一個時空特征聚合的深度目標(biāo)檢測網(wǎng)絡(luò),可實現(xiàn)對視頻目標(biāo)特征的有效提取及檢測。
4)公開數(shù)據(jù)集的實驗表明,本文方法可以有效檢測真實水下環(huán)境中的珊瑚礁魚,相比于傳統(tǒng)方法和模型取得了更好的檢測精度。
1 相關(guān)技術(shù)
本節(jié)對珊瑚礁魚檢測方法中涉及或相關(guān)的技術(shù)進(jìn)行簡要介紹,具體包括前景提取及分類、圖像目標(biāo)檢測和視頻目標(biāo)檢測3個方面。
1.1 前景提取及分類
前景提取及分類方法將珊瑚礁魚檢測視為一個前景目標(biāo)提取及分類問題。由于當(dāng)前水下攝像采集的都是固定場景視頻,借鑒安防、交通監(jiān)控等領(lǐng)域的分析經(jīng)驗,利用多幀圖像平均、高斯混合模型[29]等方法可以對這類視頻進(jìn)行背景建模,進(jìn)而可以通過背景差減和適當(dāng)后處理,提取當(dāng)前幀中的運動區(qū)域。將這些區(qū)域視為前景目標(biāo)從圖像中截取出來并歸一化到特定大小,即可作為深度神經(jīng)網(wǎng)絡(luò)或其他機(jī)器學(xué)習(xí)模型的輸入,構(gòu)建相應(yīng)分類模型實 現(xiàn) 珊 瑚 礁 魚 檢 測。AlexNet[30]、GoogleNet[31]、ResNet[24]都是現(xiàn)有文獻(xiàn)中用到的分類網(wǎng)絡(luò)。
前景提取的效果是這類方法能否取得好的結(jié)果的關(guān)鍵。由于珊瑚礁魚在圖像中通常只是一小部分,且受到影像分辨率低,以及水流、背景目標(biāo)運動(如珊瑚擺動)等的影響,所提取的前景通常會有較多噪聲。分類網(wǎng)絡(luò)雖然可以濾除其中一部分,但因前景目標(biāo)提取不完整、提取冗余等因素,不可避免會對分類精度造成一定影響。
1.2 圖像目標(biāo)檢測
圖像目標(biāo)檢測方法將珊瑚礁魚檢測視為一個基于單幀圖像的目標(biāo)檢測問題。圖像目標(biāo)檢測是隨著深度學(xué)習(xí)技術(shù)發(fā)展性能得到顯著提升的領(lǐng)域之一。根據(jù)檢測原理的不同,現(xiàn)有檢測方法主要分為兩階段方法和一階段方法兩大類。
兩階段方法一般包含2個網(wǎng)絡(luò):候選區(qū)域生成網(wǎng)絡(luò)和檢測網(wǎng)絡(luò)。首先,使用候選區(qū)域生成網(wǎng)絡(luò)在圖像特征圖上生成目標(biāo)候選框;然后,使用檢測網(wǎng)絡(luò)對生成的目標(biāo)候選框進(jìn)行中心位置和長寬的回歸,并進(jìn)行分類。典型的兩階段方法包括Faster R-CNN[26]、Cascade R-CNN[32]等。
一階段方法通過對目標(biāo)位置、大小和長寬比進(jìn)行密集的采樣來檢測目標(biāo)。這類方法先在特征圖的每個位置根據(jù)不同的大小和長寬比預(yù)定義固定數(shù)量的默認(rèn)框,再對默認(rèn)框的中心位置和長寬進(jìn)行回歸,并對其包含的物體進(jìn)行分類判別。典型的一階段方法有YOLO[28]、SSD[23]等。
除以上方法,近年來也有一些考慮目標(biāo)定位損失[33]和無需預(yù)定義默認(rèn)框[34]的方法被提出來并取得良好檢測性能。此外,強化網(wǎng)絡(luò)所提取特征的辨識力也是提升目標(biāo)檢測性能的重要方向。這方面代表性工作有特征金字塔網(wǎng)絡(luò)FPN[35]、默認(rèn)框可適配學(xué)習(xí)的RefineDet[36]等。
具體到珊瑚礁魚檢測方面,目前有文獻(xiàn)用到Faster R-CNN[26]、SSD[23]和YOLO[28]。因視頻幀分辨率低、水下環(huán)境復(fù)雜、魚體態(tài)呈多維變化等特點,所提取特征質(zhì)量不可避免受到影響,制約了以上方法的精度。為此,文獻(xiàn)[22,27]提出利用額外分類器來強化檢測結(jié)果,這一做法的效果主要體現(xiàn)在減少誤判上,對漏判則作用不大。
1.3 視頻目標(biāo)檢測
視頻目標(biāo)檢測泛指同時利用圖像靜態(tài)特征和視頻運動信息實現(xiàn)檢測的各種方法。目前,主要有2類視頻目標(biāo)檢測方法:第1類是圖像目標(biāo)檢測及后處理。先在多幀圖像上進(jìn)行目標(biāo)檢測,再采取適當(dāng)后處理,得到視頻級檢測結(jié)果。這類方法是圖像目標(biāo)檢測方法的簡單延伸,其存在難以充分利用檢測結(jié)果的時序相關(guān)性等不足。第2類方法利用可同時接受視覺和時序信息作為輸入的深度模型進(jìn)行檢測。目前,已經(jīng)有一些相關(guān)的網(wǎng)絡(luò)結(jié)構(gòu)被提出來。例如,利用2個卷積神經(jīng)網(wǎng)絡(luò)分別處理視覺和運動信息的雙流神經(jīng)網(wǎng)絡(luò)[6],利用卷積神經(jīng)網(wǎng)絡(luò)提取單幀圖像視覺特征,進(jìn)而用長短時記憶神經(jīng)網(wǎng)絡(luò)建模相鄰幀之間相關(guān)性的CNN-LSTM結(jié)構(gòu)[7],利用3D卷積提取時空聯(lián)合特征的三維卷積神經(jīng)網(wǎng)絡(luò)[9]。這些方法統(tǒng)籌考慮了時空域,因而可以提取到更為強大的特征,從而提升行為識別、視頻分類等多個視頻任務(wù)的分析精度。
由于珊瑚礁魚通常只占視頻幀的一小塊區(qū)域,且其位置隨著時間變化,構(gòu)建有效的局部視覺和時序特征表示是視頻目標(biāo)檢測的關(guān)鍵。這方面典型工作有光流引導(dǎo)特征聚合網(wǎng)絡(luò)[10],依據(jù)光流方向聚合相鄰幀特征圖以強化對當(dāng)前幀目標(biāo)的表示,可適當(dāng)緩解目標(biāo)因運動模糊、面積過小、罕見姿態(tài)等問題導(dǎo)致的檢測困難。此外,也有學(xué)者研究了同時進(jìn)行目標(biāo)檢測和跟蹤的網(wǎng)絡(luò)[37],通過二者的互補提升檢測性能。
2 本文方法
2.1 整體網(wǎng)絡(luò)結(jié)構(gòu)
本節(jié)介紹提出的時空特征聚合水下珊瑚礁魚檢測方法。圖1給出了時空特征聚合神經(jīng)網(wǎng)絡(luò)的整體結(jié)構(gòu)。可以看到,該網(wǎng)絡(luò)接受當(dāng)前視頻幀及前后相鄰幀作為輸入。當(dāng)前幀通過圖中c1~cf組成的視覺特征聚合模塊(Visual Feature Aggregation,VFA),生成一個融合了多層卷積特征圖、信息更豐富的新視覺特征圖。同時,對于其中參與目標(biāo)預(yù)測的特征圖(cf,c15~c19),通過圖中實線框表示的時序特征聚合模塊(Temporal Feature Aggregation,TFA)對當(dāng)前幀及相鄰幀特征圖予以聚合,從而生成具備更強表示能力的時空聚合特征(Visual-Temporal Feature Aggregation,VTFA)。珊瑚礁魚檢測將在空間分辨率逐步降低的多個聚合特征圖上進(jìn)行。
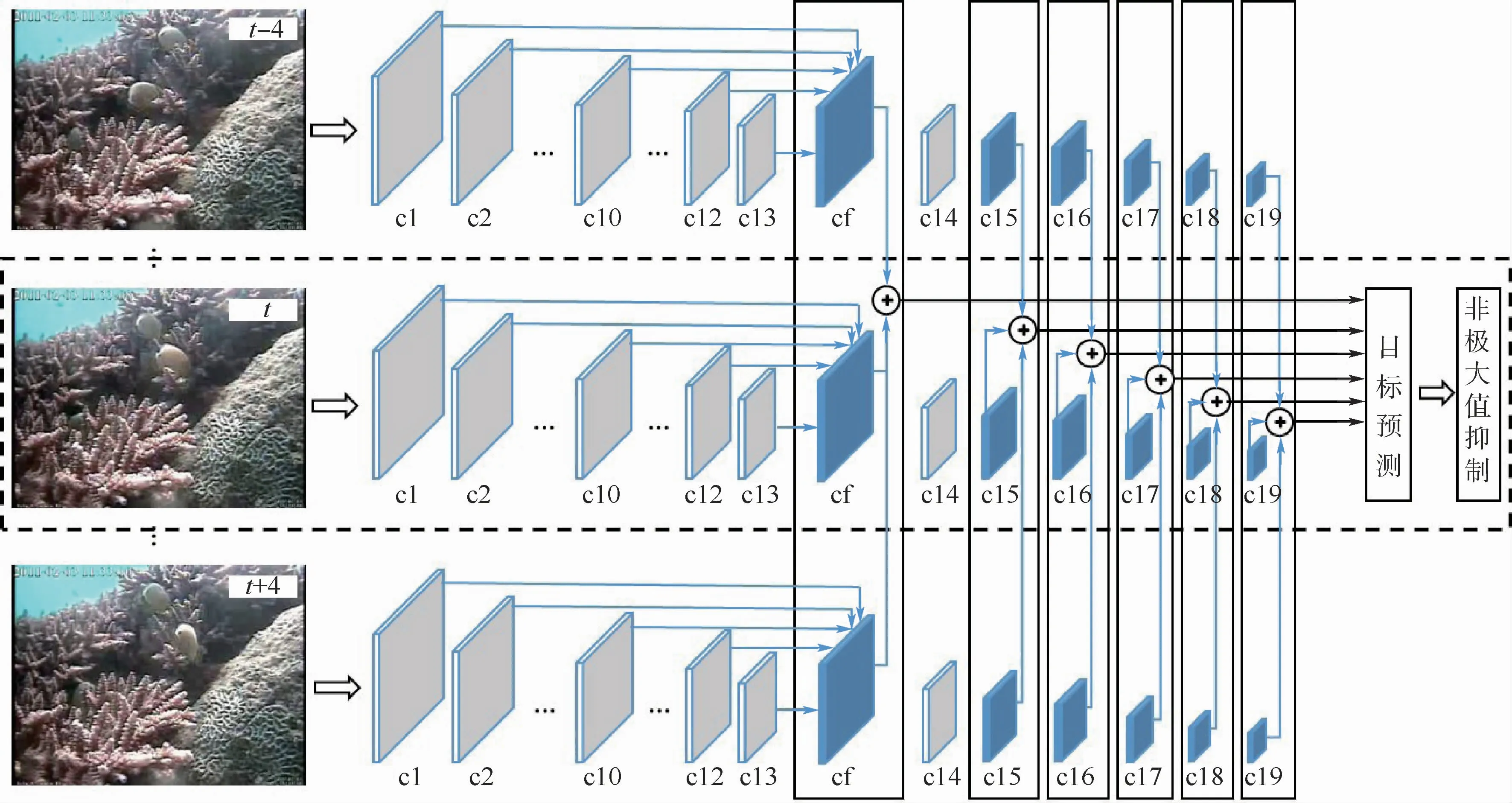
圖1 本文時空特征聚合神經(jīng)網(wǎng)絡(luò)的整體結(jié)構(gòu)Fig.1 Overall architecture of the proposed spatio-temporal features aggregation neural network
本文網(wǎng)絡(luò)可視為一種從SSD模型[23]發(fā)展而來的復(fù)合結(jié)構(gòu),在其單幀圖像處理通道中(見圖1中虛線框),類似于 SSD 利用卷積神經(jīng)網(wǎng)絡(luò)VGG16[38]作為特征提取主干網(wǎng),其中基本卷積層c1~c13與VGG16一致,最后2個全連接層和分類層被截斷,予以替換的是6個空間分辨率逐步降低的新增卷積層(c14~c19)。在SSD中,目標(biāo)檢測將在c10、c15~c19這6個不同尺度的卷積特征圖上進(jìn)行。
損失函數(shù)方面,本文網(wǎng)絡(luò)與SSD的形式相同,整個網(wǎng)絡(luò)的損失函數(shù)定義為
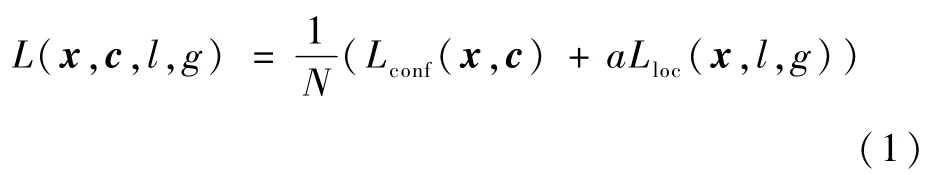
式中:x為記錄預(yù)測框和標(biāo)注框匹配情況的矩陣;c為當(dāng)前樣本的預(yù)測置信度向量;l和g分別為預(yù)測框和標(biāo)注框的坐標(biāo)信息;N為當(dāng)前幀預(yù)測框數(shù)量;Lconf和Lloc分別為類別損失和定位損失;a為一個用于平衡2類損失的參數(shù),本文設(shè)置為1。以上損失項的計算公式可參見文獻(xiàn)[23]。
不同于SSD,本文網(wǎng)絡(luò)的目標(biāo)預(yù)測是在經(jīng)過單幀圖像多層特征圖聚合與/或相鄰幀同層特征圖聚合后生成的時空強化特征圖上進(jìn)行,這2個聚合模塊正是本文的創(chuàng)新之處。
2.2 視覺特征聚合模塊
源自VGG16的基本卷積層中,SSD僅用c10進(jìn)行預(yù)測,忽視了其他層信息。水下監(jiān)控視頻由于質(zhì)量低、成像環(huán)境復(fù)雜且珊瑚礁魚目標(biāo)通常較小,基本卷積層特征圖上的信息對于檢測來說尤其重要。基于此,本文設(shè)計了一個視覺特征聚合模塊對基本卷積層進(jìn)行更有效的利用,以提高水下復(fù)雜環(huán)境中的珊瑚礁魚檢測性能。
視覺特征聚合模塊由一個自頂向下的切分和一個自底向上的歸并操作組成。切分過程迭代地將卷積層分成不同的組,形成了一個自頂向下的切分結(jié)構(gòu)。在這個結(jié)構(gòu)的最頂層,所有卷積層都在同一組。當(dāng)卷積層數(shù)量n是偶數(shù)時,在下一層它們將從中間切分,分成2個各含有n/2個層的組;當(dāng)卷積層的數(shù)量n是奇數(shù)時,在下一層最中間的卷積層將被視為一個單獨的組,其左右兩邊的卷積層被分為另外2個組,各含有(n-1)/2個層。基于這一原則,卷積層可以不斷被切分,直至每個組中卷積層的數(shù)量小于等于2,此時切分過程停止。圖2(a)的上半部分給出了一個切分的例子。
基于以上切分結(jié)果,自底向上的歸并從下往上不斷合并每個組中的特征圖,最終形成了一個聚合了所有卷積特征圖的特征。具體地,卷積層歸并時涉及對2個或3個分辨率和通道數(shù)可能不同的特征圖融合。由于卷積神經(jīng)網(wǎng)絡(luò)特征圖從淺層到深層滿足分辨率不變或遞減的規(guī)律,對于2個特征圖融合的情況:若分辨率不同,將低分辨率特征圖上采樣到與高分辨率特征圖具有相同大小,再進(jìn)行融合;若分辨率相同則直接融合。對于3個特征圖融合的情況,先保持中間層特征圖的分辨率不變,若其淺層方向特征圖分辨率大于中間層,則通過下采樣將其降采樣到與中間層特征圖相同分辨率再融合;若其深層方向特征圖分辨率小于中間層,則將其上采樣到與中間層特征圖一樣大小再進(jìn)行融合;若淺層和/或深層方向特征圖分辨率與中間層的一致,則直接融合。通過迭代進(jìn)行融合操作,最終所有特征圖將會被融合成一個具有適中分辨率的聚合特征圖,如圖2(a)下半部分所示,該特征圖將會替換c10進(jìn)行預(yù)測。
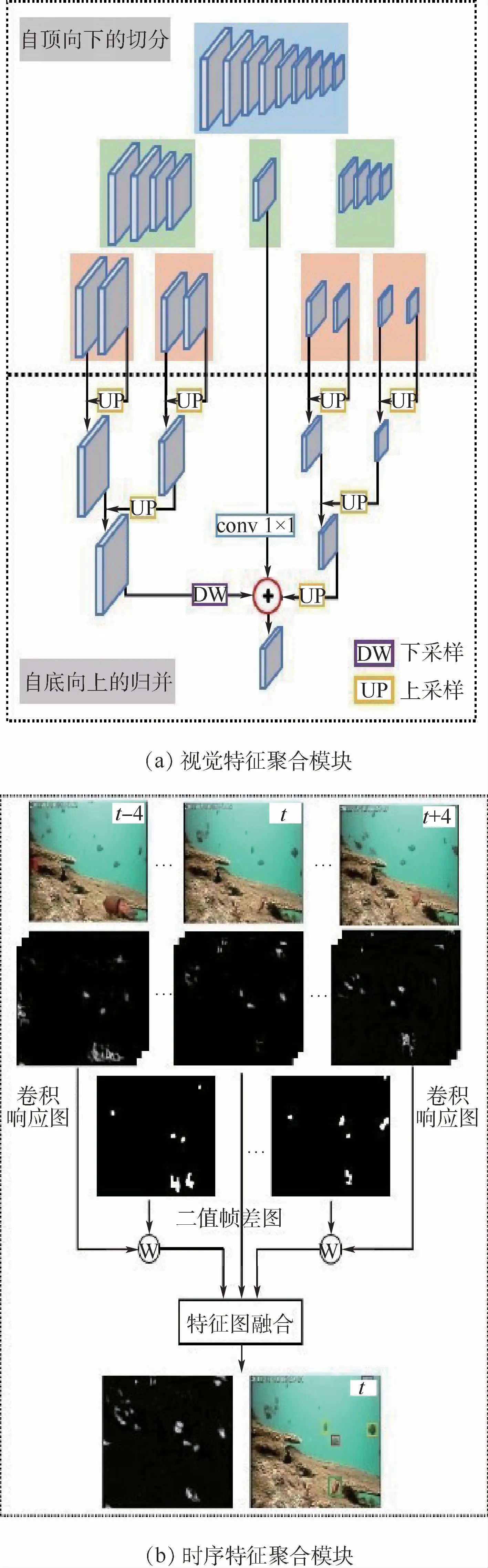
圖2 本文提出的視覺特征聚合模塊和時序特征聚合模塊Fig.2 The proposed visual feature aggregation module and temporal feature aggregation module
對于融合過程中的特征圖通道數(shù)可能不一致的情況,以(三層融合的)中間層或(兩層融合中)淺層方向的特征圖為基準(zhǔn),融合前先通過1×1的卷積將其他層特征圖的通道數(shù)予以對齊。注意到,該特征聚合模塊不僅適用于VGG16主干網(wǎng),也可以推廣到其他卷積主干網(wǎng)。相比于僅利用c10進(jìn)行預(yù)測,以及文獻(xiàn)[21]僅融合相鄰預(yù)測層的方案,本文視覺特征聚合模塊以一種合理且可擴(kuò)展的方式聚合了多個基本卷積層的特征圖,提供了更豐富的局部細(xì)節(jié)和上下文信息,有利于更好刻畫視頻幀中的珊瑚礁魚目標(biāo)。
2.3 時序特征聚合模塊
珊瑚礁魚在水下游動時體態(tài)呈多維變化,當(dāng)其部分遮擋或以罕見體態(tài)出現(xiàn)時,不可避免會帶來檢測困難。融合相鄰幀特征顯然有利于緩解該問題。基于此,本文設(shè)計了時序特征聚合模塊在相鄰幀上融合運動目標(biāo)相關(guān)的特征圖,以生成更強化的特征表示。
時序特征聚合模塊的示意圖如圖2(b)所示。對于輸入到網(wǎng)絡(luò)的當(dāng)前視頻幀及其前后相鄰幀,利用圖1所示的主干網(wǎng)結(jié)構(gòu)提取每幀圖像各個卷積層的特征圖,這些特征圖記錄了目標(biāo)在當(dāng)前圖像上的卷積響應(yīng)值。基于此,在特征圖上計算當(dāng)前幀與每個相鄰幀的幀差圖,對幀差圖進(jìn)行灰度化和二值化并結(jié)合適當(dāng)后處理,如圖2(b)所示,記錄了當(dāng)前幀與其相鄰幀之間運動信息的二值幀差圖。
對于網(wǎng)絡(luò)中參與目標(biāo)預(yù)測的特征圖,通過以下公式對其進(jìn)行時序聚合:
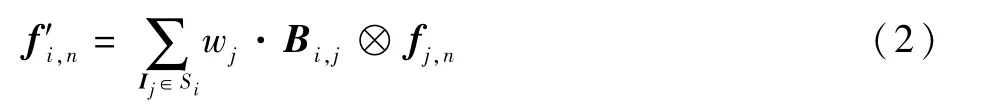
式中:fj,n為視頻幀Ij聚合前的第n層特征圖;f′i,n為視頻幀Ii聚合后的第n層特征圖;Bi,j為Ii與Ij的二值幀差圖,當(dāng)i=j時,Bi,j為值全為1的矩陣;“?”為對應(yīng)相乘操作;Si=(Ii-k,Ii-k+1,…,Ii+k)為Ii及其相鄰幀集合,k為鄰域邊界;wj為Ij對應(yīng)的權(quán)重,即
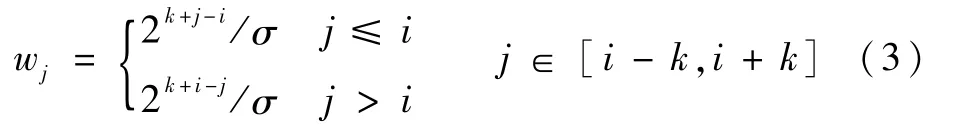
其中:σ為歸一化因子,以確保所有權(quán)重之和為1。

式(2)以線性加權(quán)的方式,將相鄰幀特征圖中對應(yīng)幀差運動區(qū)域的特征融合到當(dāng)前幀同層特征圖中。這一做法可以生成一個以當(dāng)前幀運動目標(biāo)為中心,適當(dāng)囊括其周邊區(qū)域,時序強化的特征。由于珊瑚礁魚是視頻中的運動主體,這一做法可有效緩解當(dāng)前幀珊瑚礁魚目標(biāo)因運動模糊、罕見姿態(tài)等帶來的特征表示困難。
以上時序融合在所有6個參與目標(biāo)預(yù)測的卷積特征圖上都將進(jìn)行,其中包括了一個通過視覺特征聚合模塊生成的預(yù)測層。因此,網(wǎng)絡(luò)可提取到時空聯(lián)合的強化特征更好地進(jìn)行目標(biāo)檢測。注意到,文獻(xiàn)[10]也提出了一種光流引導(dǎo)的相鄰幀特征圖融合方法。本文與其有2點區(qū)別:①在融合區(qū)域確定上,文獻(xiàn)[10]先計算兩幀之間的光流,再依此將每幀光流前景對應(yīng)的特征圖位移后再與當(dāng)前幀相應(yīng)位置疊加融合。與之對應(yīng),本文采用了計算代價顯著降低的幀差運算,融合區(qū)域也是相對更寬泛的幀差前景區(qū)域。采用這一做法主要是考慮到低質(zhì)量視頻中光流計算誤差較大,容易導(dǎo)致位移估計不準(zhǔn)確。此外,認(rèn)為魚周邊區(qū)域的特征也有助于檢測。②在相鄰幀融合的權(quán)重上,文獻(xiàn)[10]用余弦相似度動態(tài)計算當(dāng)前幀與相鄰幀的權(quán)重,而本文采用的是一個以當(dāng)前幀為中心的類高斯分布權(quán)重,直接賦予與當(dāng)前幀更鄰近的相鄰幀更大權(quán)重。這一做法在降低計算量的同時,也一定程度避免了相似度計算對噪聲敏感的影響。
上述融合中,時序聚合的鄰域k是一個重要參數(shù)。大的k值融合的相鄰幀多,但網(wǎng)絡(luò)結(jié)構(gòu)更復(fù)雜,計算代價更高;小的k值則有時序信息融合不充分的隱患。此外,選定k值后,鄰域中圖像分析的采樣間隔也是一個需要明確的細(xì)節(jié)。將在消融實驗中論證不同做法的區(qū)別。
2.4 后處理
基于幀級檢測結(jié)果及置信度,本文先利用非極大值抑制消除單幀圖像上的冗余檢測框,再提出了一個時序后處理以提升珊瑚礁魚檢測精度。該后處理旨在改善部分情況下珊瑚礁魚檢測得分置信度過低,易造成漏檢和誤檢的現(xiàn)象。具體地,在得到單幀檢測結(jié)果后,先將相鄰幀中滿足檢測類別相同且IoU>0.5的檢測框標(biāo)記成檢測對,再將檢測對中檢測框得分統(tǒng)一為置信度高的得分。通過這種方式,一定程度利用了目標(biāo)的時序互補性強化了檢測得分,使檢測結(jié)果更穩(wěn)定。上述非極大值抑制和時序后處理如圖3所示。

圖3 非極大值抑制和本文提出的時序后處理Fig.3 Non-maximum suppression and the proposed temporal post-processing
本文網(wǎng)絡(luò)實現(xiàn)時,由于當(dāng)前幀預(yù)測需要利用前后相鄰幀特征圖,為避免重復(fù)提取圖像特征,在確定鄰域參數(shù)k及其采樣間隔后,將申請一個公共緩存空間存儲以當(dāng)前幀為中心,鄰域內(nèi)所有采樣圖像參與預(yù)測的卷積特征圖。這樣,每幀檢測時,只需計算當(dāng)前幀的時空聯(lián)合聚合特征圖以開展以當(dāng)前幀為中心的目標(biāo)檢測。對一個視頻幀序列,則只需按時序?qū)λ胁蓸訋貜?fù)以上過程,相應(yīng)調(diào)整緩存空間內(nèi)容,即可依次計算所有采樣幀上的檢測結(jié)果。
3 實驗與結(jié)果
3.1 數(shù)據(jù)集
用SeaCLEF國際競賽[18]數(shù)據(jù)作為本文實驗數(shù)據(jù)集。該數(shù)據(jù)集提供了5個不同場景和日期的93個水下監(jiān)控視頻,給出了其中出現(xiàn)的15種珊瑚礁魚的逐幀標(biāo)注,包括魚的類別和矩形框形式的位置信息,共有21 396個標(biāo)注樣例。該數(shù)據(jù)集涵蓋了圖像分辨率低、水下環(huán)境復(fù)雜、魚體態(tài)變化大等一系列真實水下監(jiān)控視頻包含的檢測難點。
競賽將數(shù)據(jù)集分成了訓(xùn)練集和測試集,分別包含20個和73個視頻的13 882個和7 514個標(biāo)注實例。訓(xùn)練集和測試集都涵蓋了全部的5個場景。但是,不同魚在數(shù)據(jù)集中的分布并不均勻,出現(xiàn)次數(shù)最多的網(wǎng)紋宅泥魚在訓(xùn)練集和測試集上分別出現(xiàn)了3165和5 046次,15種魚中黑緣單鰭魚在測試集中僅出現(xiàn)了8次,甚至鏡斑蝴蝶魚和黑鰭粗唇魚在測試集沒有出現(xiàn)。因此參考文獻(xiàn)[21],本文將上述3類魚從檢測任務(wù)中去除,構(gòu)成了一個包含12種珊瑚礁魚的目標(biāo)檢測任務(wù)。表1給出了這些魚的名稱,以及它們在訓(xùn)練集和測試集中的數(shù)量分布情況。
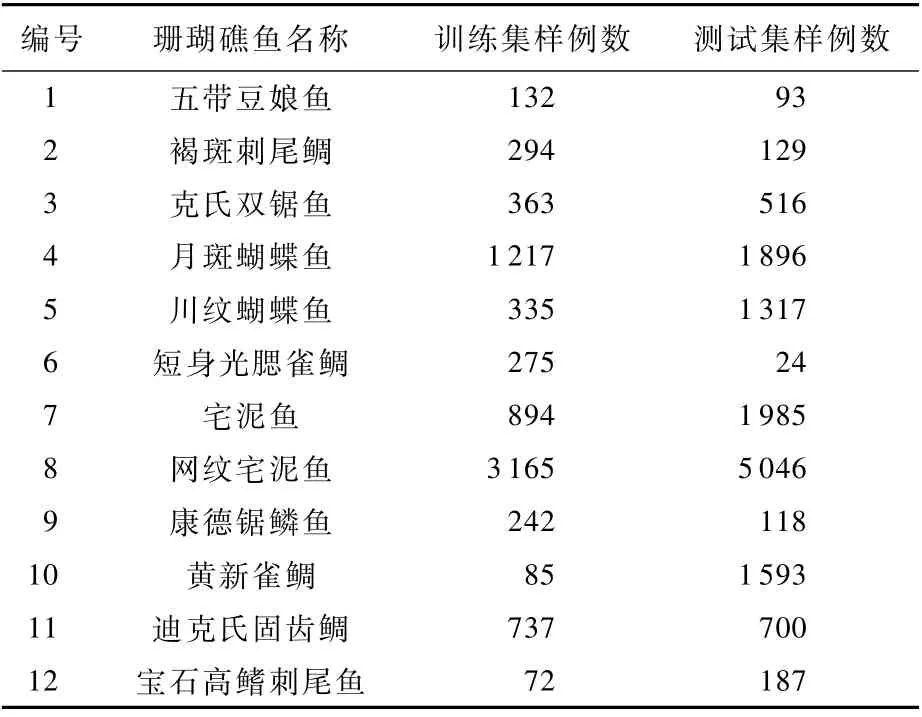
表1 SeaCLEF數(shù)據(jù)集中不同類別魚的數(shù)量Table 1 Numbers of different fish species on SeaCLEF dataset
3.2 實驗設(shè)置及評價指標(biāo)
本文采用一個兩步訓(xùn)練過程來訓(xùn)練網(wǎng)絡(luò)。第1步基于單幀圖像訓(xùn)練一個僅包含視覺特征聚合模塊的目標(biāo)檢測網(wǎng)絡(luò):先讀取ImageNet數(shù)據(jù)集的預(yù)訓(xùn)練參數(shù),再采用批量隨機(jī)梯度下降方法進(jìn)行訓(xùn)練,批的大小為32張圖像。設(shè)置網(wǎng)絡(luò)總共迭代訓(xùn)練120 000次。先將學(xué)習(xí)率設(shè)置為0.000 1進(jìn)行1 000次迭代的熱身訓(xùn)練,完成熱身訓(xùn)練以后將學(xué)習(xí)率升至0.001,迭代訓(xùn)練40 000次和80 000次之后,分別將學(xué)習(xí)率降低為0.000 1和0.000 01,以使網(wǎng)絡(luò)更好地收斂。梯度更新動量值為0.9。第2步訓(xùn)練基于第1步得到的參數(shù)訓(xùn)練整個網(wǎng)絡(luò)結(jié)構(gòu)。由于特征圖相加操作的可導(dǎo)性,整個網(wǎng)絡(luò)是端到端可訓(xùn)練的。第2步同樣采用批量隨機(jī)梯度下降的精調(diào)訓(xùn)練,批的大小為1張圖像,迭代輪數(shù)設(shè)置為60000次,其中前40000次與后20000次的學(xué)習(xí)率分別為0.000 1和0.000 01。采用了隨機(jī)剪裁和調(diào)整圖像對比度的數(shù)據(jù)增強方式。圖像在輸入網(wǎng)絡(luò)之前先將大小調(diào)整為300×400。全部訓(xùn)練在一個GTX Titan X GPU上完成,基于TensorFlow平臺完成整個模型訓(xùn)練需要約34 h。
推理階段,本文網(wǎng)絡(luò)接受當(dāng)前幀及其前后多個相鄰幀作為輸入,輸出當(dāng)前幀的檢測結(jié)果。檢測結(jié)果經(jīng)過2.4節(jié)的后處理,可得到視頻級檢測結(jié)果。評價指標(biāo)上,本文用目標(biāo)檢測領(lǐng)域廣泛使用的平均精度均值mAP,其定義為

式中:APi為第i個目標(biāo)類別通過改變閾值得到的不同召回率下的平均精度;n為目標(biāo)類別個數(shù)。
3.3 消融實驗
通過消融實驗來驗證視覺特征聚合模塊和時序特征聚合模塊中特征圖的具體融合方式,以及時序融合時當(dāng)前幀的鄰域及采樣間隔。
融合方式方面,驗證視覺特征聚合模塊時,將網(wǎng)絡(luò)結(jié)構(gòu)設(shè)置為僅輸入當(dāng)前幀Ii的情況,此時網(wǎng)絡(luò)僅包含圖1中虛線框的部分。對比了對應(yīng)相加、取最大值和取平均值3種特征圖融合策略。表2給出了相應(yīng)的mAP值。可以看到,對應(yīng)相加取得了更好的性能。
驗證不同融合方式對時序特征聚合模塊的影響。先將網(wǎng)絡(luò)固定為輸入{Ii-4,Ii,Ii+4}3幀圖像的情況。為簡化起見,去除了網(wǎng)絡(luò)中的視覺特征聚合模塊。表2給出了上述3種情況下的mAP值。結(jié)果表明,取最大值進(jìn)行融合更有利于進(jìn)行珊瑚礁魚檢測。
分析采樣鄰域及間隔對結(jié)果的影響。受限于計算資源,僅考慮了輸入不超過5個視頻幀的情況。結(jié)合不同采樣間隔,將其分成了如表3和表4所示的11種情況,其中2表示考慮{Ii-2,Ii,Ii+2}3幀圖像的情況,46表示考慮{Ii-6,Ii-4,Ii,Ii+4,Ii+6}5幀圖像的情況,其余依此類推。實驗中網(wǎng)絡(luò)都未包括視覺特征聚合模塊。
可以看到,輸入5幀圖像可以取得比3幀圖像更好的檢測結(jié)果。這一點是符合預(yù)期的,因為聚合更多相鄰幀有利于提取更具辨識力的特征。此外,注意到與當(dāng)前幀間隔為6(3幀情況),以及4和8(5幀情況)時,相比于其他間隔情況下取得了更好的結(jié)果。幀數(shù)間隔大一般關(guān)聯(lián)著更大的運動區(qū)域,對應(yīng)到本文網(wǎng)絡(luò)則是更大范圍的特征融合。當(dāng)間隔相對適中時,可使得相鄰特征圖中目標(biāo)及合適范圍的周邊上下文得到更強化的刻畫,但若間隔過大,則容易融合到更多的噪聲而起到負(fù)面作用。基于以上結(jié)果,本文網(wǎng)絡(luò)結(jié)構(gòu)最終確定為接受{Ii-8,Ii-4,Ii,Ii+4,Ii+8}5幀圖像作為輸入,并將對應(yīng)相加和取最大值分別作為視覺特征聚合和時序特征聚合中多個特征圖的融合方式。
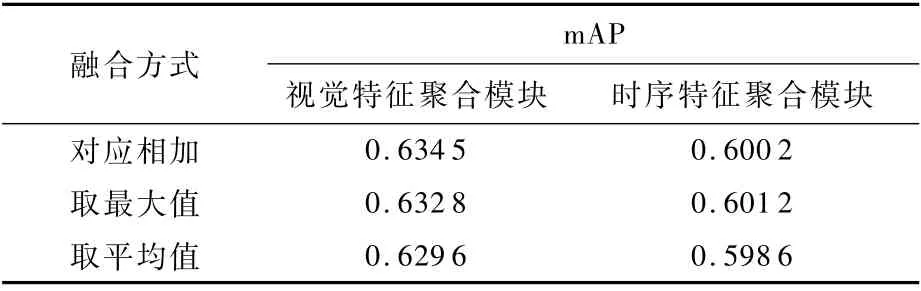
表2 不同融合方式及性能Table 2 Different fusion methods and their performance

表3 輸入為3幀圖像時不同參數(shù)下的網(wǎng)絡(luò)性能Table 3 Network perfor mance under different parameters when three-frame images are input

表4 輸入為5幀圖像時不同參數(shù)下的網(wǎng)絡(luò)性能Table 4 Network perfor mance under different parameters when five-frame images are input
3.4 實驗結(jié)果及對比分析
為評估檢測性能,將本文網(wǎng)絡(luò)及其衍生結(jié)構(gòu)和幾種主流方法與模型進(jìn)行了實驗比較。
BS+GoogleNet[20]:德國耶拿大學(xué)提出的基于前景提取及分類的珊瑚礁魚檢測方法。
Faster R-CNN[26]、YOLOv3[28]和SSD[23]:采用這3個主流目標(biāo)檢測模型進(jìn)行珊瑚礁魚檢測。
FFDet[21]:基于相鄰卷積層特征融合的珊瑚礁魚檢測方法。
FGFA[10]:光流引導(dǎo)的相鄰幀特征圖融合的檢測方法。
Ours-VTFA、Ours-VFA 和Ours-TFA:本 文 網(wǎng)絡(luò),以及本文網(wǎng)絡(luò)分別去除時序特征聚合模塊和視覺特征聚合模塊后對應(yīng)的珊瑚礁魚檢測方法。
表5給出了以上方法的圖像級和視頻級實驗結(jié)果及時間消耗。可以看到,Ours-VTFA方法相比于傳統(tǒng)基于前景提取及分類、主流目標(biāo)檢測模型取得了8.8% ~16.8%的相對性能提升,表明本文時空特征聚合網(wǎng)絡(luò)能更好地檢測水下珊瑚礁魚。同時,該方法也取得了比僅考慮其中一種模態(tài)聚合的Ours-VFA和Ours-TFA更好的效果,說明從時間和空間2個維度強化特征提取的互補性和必要性。
視覺特征聚合方面,對比于沒有特征融合的SSD和采用相鄰層視覺特征融合的FFDet,Ours-VFA方法取得了更好的檢測性能,說明基本卷積層聚合生成的特征圖可以更好地描述珊瑚礁魚的類別和位置信息,挖掘利用基本卷積層特征對低質(zhì)量水下視頻中珊瑚礁魚檢測具有重要價值。此外,注意到Ours-VFA方法的檢測速度顯著快于FGFA等高精度方法,僅略遜于精度不如它的SSD和FFDet。Ours-VFA方法不失為一種速度和精度得到較好折中的檢測方案。
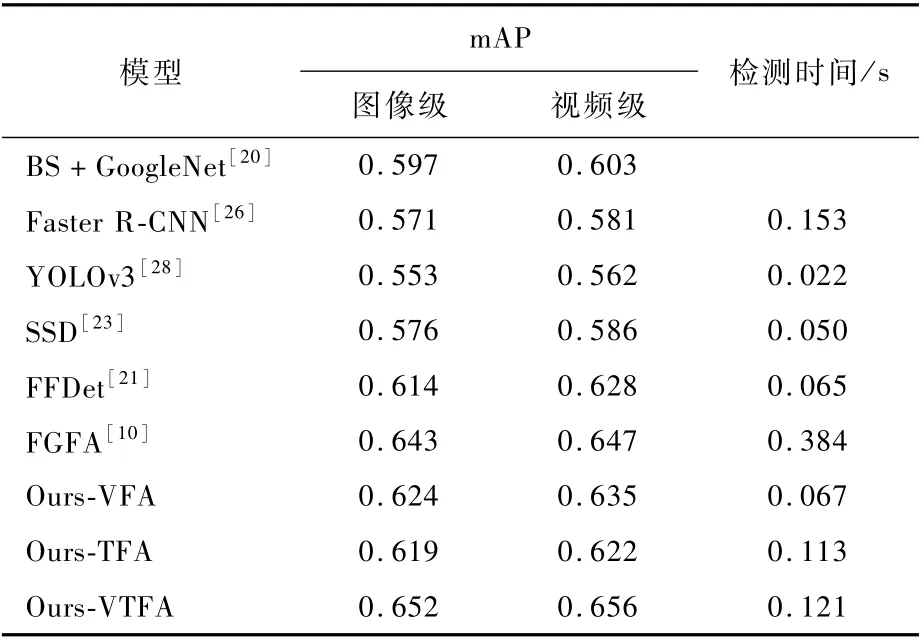
表5 不同方法的檢測性能Table 5 Detection perfor mance of differ ent methods
時序特征聚合方面,Ours-TFA方法與SSD的區(qū)別在于:前者在網(wǎng)絡(luò)中聚合了相鄰幀對應(yīng)運動區(qū)域的特征圖,即獲得了6.3%的mAP相對提升,驗證了時序維度的挖掘利用有助于提升檢測性能。本文基于幀差的相鄰幀聚合方法可以融合相鄰幀目標(biāo)周邊的上下文區(qū)域,有助于提取更加有效的特征。該方法雖然檢測性能低于FGFA,但時間消耗減少了2倍以上,主要是幀差計算的代價顯著低于光流計算。在Ours-VFA方法的基礎(chǔ)上進(jìn)一步融入時序特征聚合模塊,可繼續(xù)提升檢測性能,再次說明了本文網(wǎng)絡(luò)可以互補地聚合時間和空間維度的特征。注意到,Ours-VTFA方法可以取得優(yōu)于FGFA的實驗結(jié)果,且檢測時間也縮短了2倍以上,這也再一次凸顯了聚合基本卷積層特征的重要性。此外,所有方法采用了本文后處理技術(shù)后,檢測精度均有一定提升,表明網(wǎng)絡(luò)內(nèi)外挖掘的時序信息具有一定互補性,在不同層次利用它們可進(jìn)一步提升檢測精度。
圖4給出了各種檢測模型在不同珊瑚礁魚類別上的檢測結(jié)果。其中,每種魚的8個檢測結(jié)果從左到右分別是Faster R-CNN、YOLOv3、SSD、FFDet、FGFA、Ours-VFA、Ours-TFA 和 Ours-VTFA 8種方法取得的。可以看到,不同類型魚的檢測結(jié)果差異巨大。即使性能最好的方法,在褐斑刺尾鯛上的AP值也不超過0.1。與之對應(yīng),無論是哪種方法,在宅泥魚、克氏雙鋸魚和月斑蝴蝶魚上都取得了較高AP值。從兩方面解釋造成以上顯著類間差異的原因:①珊瑚礁魚樣本數(shù)量在類別上分布不均。結(jié)合表1可看到,AP值高的魚類別樣本較多,而AP低的魚類別樣本較少,訓(xùn)練數(shù)據(jù)是否豐富,一定程度上影響了所構(gòu)建模型的檢測精度。②不同類型魚的視覺辨識難度各不相同,導(dǎo)致檢測難度不一。水下低質(zhì)量視頻中魚的檢測主要依賴對魚顏色和形態(tài)輪廓等的刻畫,在訓(xùn)練數(shù)據(jù)相對充足的情況下,部分顏色和形態(tài)易于辨識,區(qū)分度較大的魚可以被高精度的檢測,宅泥魚和月斑蝴蝶魚均屬于此類。但是,當(dāng)訓(xùn)練數(shù)據(jù)較少,且魚的區(qū)分性特征在低質(zhì)量視頻中不突出,易與其他目標(biāo)混淆時,如褐斑刺尾鯛,檢測精度則受到嚴(yán)重影響。以上實驗表明,水下監(jiān)控視頻中珊瑚礁魚的高精度檢測仍然是一個極具挑戰(zhàn)的技術(shù)難點。
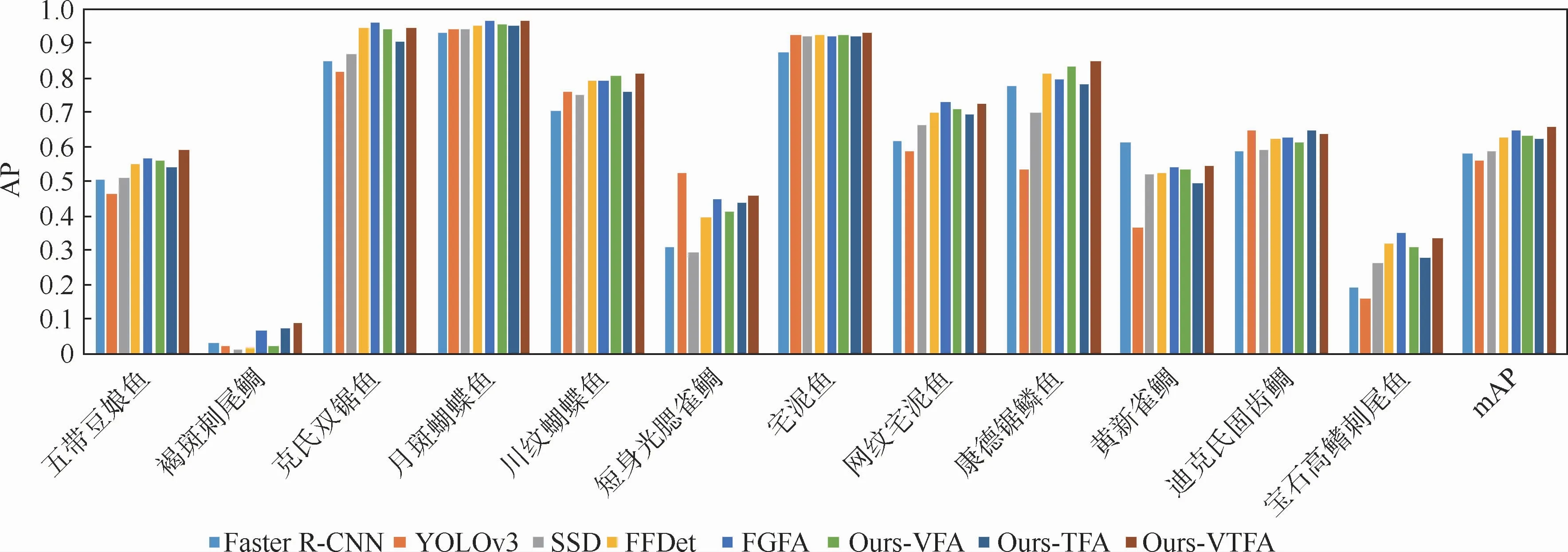
圖4 各種檢測模型在不同珊瑚礁魚類別上的檢測結(jié)果Fig.4 Detection results of different coral reef fish species by various detection models
4 結(jié)束語
認(rèn)識到從充滿挑戰(zhàn)的水下監(jiān)控視頻中檢測珊瑚礁魚的重要價值,本文提出了一種時空特征聚合的水下珊瑚礁魚檢測方法。該方法從時間和空間2個維度出發(fā),分別設(shè)計了一個視覺特征聚合模塊以融合多層不同分辨率的卷積特征圖,以及一個時序特征聚合模塊以實現(xiàn)幀差引導(dǎo)的相鄰幀卷積特征圖融合。SeaCLEF數(shù)據(jù)集上的實驗基本驗證了以上2個特征聚合模塊的有效性。本文基于以上聚合模塊提出的檢測模型相比于多個典型方法和模型,可以取得更好的檢測精度。
檢測性能的提升主要歸功于提取了更具表征力的時空聯(lián)合特征。除了特征,數(shù)據(jù)和模型也是影響檢測精度的關(guān)鍵因素。在下一步工作中,一方面將探索如何利用互聯(lián)網(wǎng)上公開的珊瑚礁魚視頻圖像,進(jìn)一步提升低質(zhì)量水下視頻中珊瑚礁魚的檢測精度。另一方面,還將關(guān)注如何利用生成對抗網(wǎng)絡(luò)等技術(shù),生成更多高質(zhì)量和多樣化的珊瑚礁魚訓(xùn)練樣本,從而構(gòu)建更加魯棒有效的珊瑚礁魚檢測模型。此外,還計劃在開源深度學(xué)習(xí)平臺飛槳上復(fù)現(xiàn)該方法。
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
