基于注意力機制的跨分辨率行人重識別
2021-04-13 01:59:30廖華年徐新
北京航空航天大學學報 2021年3期
廖華年,徐新,2,3,*
(1.武漢科技大學 計算機科學與技術學院,武漢430065;2.武漢科技大學 智能信息處理與實時工業系統湖北省重點實驗室,武漢430065;3.武漢大學 深圳研究院,深圳518000)
隨著平安城市、雪亮工程、天網工程的推進,視頻監控系統得到了發展和普及的同時,視頻偵查技術也進入了廣泛運用階段,利用視頻智能分析技術,自動地從海量監控數據中對特定的行人目標進行檢索、分析、比對的方式正在逐漸取代人工判別。行人重識別[1](person Re-identification,Re-ID)作為智能視頻偵查的關鍵技術之一,在實際應用方面對于預防犯罪、嫌犯追蹤和治安管理都具有積極作用。
行人重識別旨在匹配不同監控攝像頭視圖下相同身份類信息圖像,它不僅需要解決同一攝像頭下的行人遮擋、姿勢、角度、光線等問題,還需注意到不同攝像頭之間存在的攝像頭規格不同。無約束的成像條件給行人重識別帶來了一定的挑戰,大多數現有的行人重識別方法都假設查詢圖像和圖庫圖像具有相似且足夠高的分辨率。然而,由于攝像頭和行人之間的距離不受約束且不同攝像頭之間的參數可能不同,導致行人圖像往往具有不同的分辨率,這種分辨率不匹配問題給行人重識別帶來了困難。與高分辨率(High Resolution,HR)圖像相比,低分辨率(Low Resolution,LR)圖像包含的身份細節要少得多,直接跨分辨率匹配圖像對將導致性能顯著下降。
為了解決分辨率不匹配問題,許多研究者開展了低分辨率行人重識別的研究[2-3],但性能提升不大。隨著深度學習的不斷發展,引入深度學習概念后的跨分辨率行人重識別任務[4-9]取得了較大的進步。早期的工作主要是通過建立高分辨率圖像與低分辨率圖像特征之間的映射關系來解決跨分辨率的匹配問題,Jing等[2]設計了一種半耦合低秩字典學習方法構建高低分辨率之間的聯系;Li等[3]則是先假設同一行人的不同圖像在某個特征空間具有相似的結構,從而得到一個跨分辨率圖像對齊網絡,將高、低分辨率關系引入到距離度量方法中。但是在無約束的成像條件下,行人圖像分辨率是不同且多樣的,無法一一對應,查詢圖像與檢索圖像分辨率比例并不是一個固定的值,在實際場景中,多個行人圖像對之間的分辨率比例多樣,早期工作中提出的方法并不適用。
受上述工作的啟發,Jiao等[4]提出的圖像超分辨率(Super-Resolution,SR)和行人身份識別聯合學習方法,通過2、3、4三個尺度的超分辨網絡,恢復對應尺度的低分辨率行人圖像中對身份識別有效的高頻外表信息,解決低分辨率行人重識別問題。Wang等[5]提出將2、4、8三個尺度的超分辨網絡級聯起來,通過逐步恢復低分辨率圖像細節信息,最后與圖庫圖像進行距離度量。盡管這些方法在跨分辨率行人重識別上取得了一定的效果,但這些方法都需要預先定義圖像對之間的尺度比例,再通過與之適配的放大因子模塊進行圖像超分辨率重建工作。
與上述工作不同,受人類視覺注意力機制(Attention mechanism,Attention)[13]的影響,本文提出了基于注意力機制的局部超分辨率聯合身份學習網絡解決上述問題。具體來說,Attention的目的是輔助網絡找到更利于識別的局部,但是即使是同一行人的不同分辨率圖像的顯著區域也會有一定的差異,因此提出了一個基于注意力機制的跨分辨率行人重識別方法,首先查詢圖像輸入到由編碼解碼網絡組成的Attention網絡,目的是得到唯一的且利于識別任務的注意力圖;然后通過核動態上采樣的方法[14],任意尺度的重建低分辨率圖像;最后經過行人重識別網絡得到分類結果。本文主要貢獻如下:
1)提出了基于通道和空間注意力機制的跨分辨率行人重識別方法。該方法主要意圖在通過關注和比較不同分辨率行人圖像對相同位置的顯著區域,然后利用自編碼網絡的學習,得到任意分辨率行人圖像的利于識別的局部區域。
2)使用任意上采樣因子的跨分辨率重識別方法,使得網絡能夠處理任意低分辨率的查詢圖像的重建。經過注意力機制得到的局部區域能夠被重建到與圖庫圖像同一分辨率。
1 相關工作
由于在真實場景下,背景[15]、姿態、照明[16]、視角、相機[17]等條件變化很大,在無約束的成像條件下,人的圖像分辨率的變化可能是最常見的,匹配不同分辨率的行人樣本需要行人重識別算法關注不同的視覺特征。例如,圖1展示了某商場不同攝像頭下的行人圖像,在高分辨率的圖像樣本中,可以通過發型或者衣服標志來區分不同行人,如C分別與A、D進行匹配,可以得出A和C是同一行人,D為不同行人。但在低分辨率圖像樣本中人眼都無法觀察到這些細節,比如B難以判定和A、C是否為同一行人,對于機器而言這些用于區分行人的標識在低分辨率圖像中是不可用的,ReID方法需要借助于剪影或全局紋理來進行可靠的匹配。而且,同一個人的高分辨率和低分辨率樣本的差異甚至可能比不同人在相似分辨率下的樣本差異更大。因此,需要對ReID方法進行專門的處理,以處理人物圖像的跨分辨率變化。
解決行人重識別方向中的分辨率問題,最簡單的方法是使用更大的數據集覆蓋盡可能多的分辨率比例,從而構建高低分辨率之間的關系,但是這需要大量的數據和標注,且難以羅列出所有的分辨率比例場景。
1.1 學習低、高分辨率圖像的關系

圖1 跨分辨率行人圖像Fig.1 Cross-resolution pedestrian image
早期的工作主要是學習低、高分辨率圖像之間的映射關系。2015年,Jing等[2]使用字典學習的方法學習低、高分辨率圖像之間的映射函數,通過得到的映射函數實現1/8尺度(低分辨率、高分辨率圖像分辨率比為1∶8)的LR圖像與HR圖像之間的轉換;Li等[3]通過尋找給定的1/4尺度的低、高分辨率圖像在某特征空間中的對齊關系計算圖像對之間的距離,從而判斷是否為同一行人,這種做法必須滿足同一行人的不同圖像應該在某個特征空間具有相似的結構這一假設;Wang等[6]提出了將尺度漸變曲線投影到特征空間分類,解決多低分辨率行人重識別問題;Chen等[7]通過對低、高分辨率圖像的特征分布進行對齊,解決跨分辨率行人重識別問題。但這幾種方法只涉及到粗糙的外觀信息和身份信息,豐富的高分辨率圖像的細粒度細節在學習過程中被丟棄了。
1.2 級聯圖像超分辨率
利用圖像超分辨率可以恢復圖像信息,解決細粒度區別信息丟失的問題。Jiao等[4]提出了超分辨率和行人身份識別聯合學習方法,能夠通過增強低分辨率行人圖像中對身份識別有用處的高頻外表信息解決低分辨率行人重識別問題中的由于分辨率不同帶來的信息量差異的問題。Wang等[5]提出了級聯超分辨網絡通過逐步恢復低分辨率圖像細節再與圖像檢索庫中的高分辨率圖像匹配。Li等[8]在低分辨率圖像和高分辨率圖像中提取的特征表示上添加了一個對抗損失用來學習分辨率不變的表示,同時通過端到端的方式恢復低分辨率輸入圖像中缺失的細節。盡管這些方法帶來了一些性能提升,但它們需要對預先定義的超分辨率模型進行培訓,然而實際問題中查詢和圖庫圖像之間的分辨率差異通常是未知的,即無法預先定義圖像對之間分辨率差異的倍數,并且梯度在這樣一個級聯的重模型[18]中反向傳播的難度要大得多,因此這類方法存在模型訓練效果不佳的問題,直接使用超分辨率模型不太適合ReID任務。
1.3 多任務學習
為了解決超分辨率任務和ReID任務之間模型效果訓練不佳的問題,受到低分辨率人臉識別工作[9-10]的啟發,Cheng等[11]提出了一個正則化方法將超分辨率、ReID任務聯系起來,讓超分辨率作為ReID任務的輔助任務,通過這種有效的結合訓練方式解決訓練不佳的問題。然而這種方法也是無差別的恢復低分辨率圖像中缺失的信息,不僅使得超分辨率任務的計算量龐大,而且低分辨率圖像中的部分不利于識別的信息被恢復也給行人匹配引入了干擾。Mao等[12]通過區分行人圖像的前景和背景信息解決了此問題,但這種簡單的劃分行人為前景和其他物體為背景可能會丟失背景中的有用信息,比如路標、特色建筑、隨身物品等。
針對以上問題,本文提出了基于注意力機制的跨分辨率行人重識別方法,利用空間、通道雙重注意力機制的特性,得到查詢圖像中利于身份識別的局部區域,采用動態地預測上采樣濾波器權重的方法解決任意放大因子的圖像重建任務,精準獲取行人圖像中缺失的身份識別信息。
2 主要方法
許多前期工作在行人重識別網絡前加入了圖像超分辨率網絡,以恢復低分辨率圖像中的信息。這種方法可以通過對低分辨率圖像的重建恢復高頻細節,但是也放大了其他信息的干擾。受文獻[19]的啟發,本文提出基于注意力機制的局部跨分辨率聯合身份學習網絡,其網絡架構主要由2部分組成:注意力模塊和任意尺度超分辨率模塊。通過一個自編碼器,跳躍連接訓練ID損失和注意力損失,逐步學習分辨率不變的特征,得到注意力模塊融合得到的前景等顯著區域信息,再通過任意尺度超分辨率模塊對該部分進行重建,輸出特征以此來計算交叉熵損失。
與文獻[20]不同的是,本文首先利用編碼解碼網絡學習分辨率不變特征,不同分辨率圖像經過編碼網絡學習得到中間特征fc,經過解碼網絡得到特征F;然后將特征F輸入到通道注意力模塊中經過一系列操作得到權重系數和特征F′,特征F′輸入到空間注意力模塊中得到相應的權重系數和融合特征,即一個包含身份區分信息的局部特征圖。網絡結構模型如圖2所示,本文將從2方面進行具體的闡述。
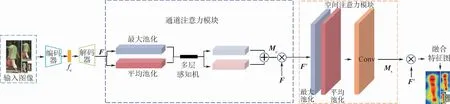
圖2 注意力網絡框架Fig.2 Framework of attention network
2.1 通道注意力機制
通道注意力的作用是得到有利于識別的特征信息,利用特征的通道間關系生成通道注意圖。由于特征圖的每個通道都被認為是特征檢測器,通道的注意力都集中在對輸入圖像有意義的地方。為了有效地計算通道注意力,壓縮了輸入特征圖的空間維數,對于空間信息的聚合,一般采用平均池法。具體的流程如圖2所示,本文查詢圖像x首先會經過自編碼器得到特征F,分別經過全局最大池化和全局平均池化,再經過多層感知機輸出特征,進行向量相加操作,生成一個通道注意力圖Mc,與做乘法操作的結果輸入到空間注意力模塊。Mc為
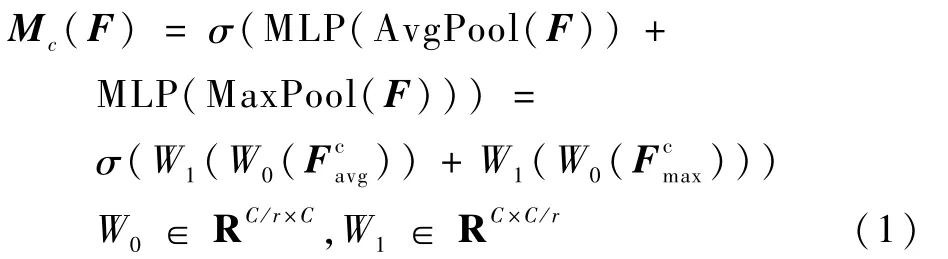
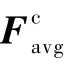
2.2 空間注意力機制
將通道注意力模塊的輸出特征圖作為本模塊的輸入特征圖。空間注意是通道注意的補充,如圖2右側所示,首先做一個基于通道的最大池化和平均池化,然后將結果基于通道做連接操作,通過一個卷積降維成單通道,最后激活生成空間特征Ms,并與本模塊的輸入特征做乘法,得到最終的生成特征。通過對通道注意特征的應用池化可以有效地突出顯示信息區域[21]。Ms的計算方式為
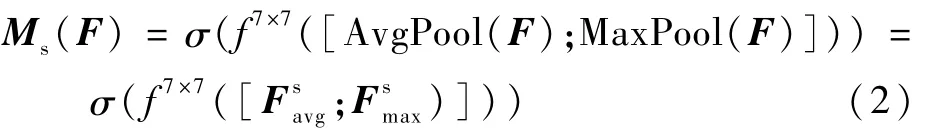
式中:f表示在注意力模塊的最后經過7×7的卷積操作。空間注意力機制的輸出需要與整個模塊輸入的特征F做一個乘法操作,得到最后的融合特征圖。
2.3 圖像超分辨率
由于復雜的實際場景和無約束的成像條件,獲取到的行人圖像并不一定是相近的分辨率,往往獲得的分辨率跨度比較大,因此無法預先定義一個尺度因子解決所有場景的圖像重建問題。對于跨分辨率行人重識別而言,如何將任意分辨率的查詢圖像轉換至與圖庫圖像為同一分辨率是關鍵。受文獻[22-24]啟發,采用一個動態的上采樣模塊代替傳統的放大模塊[14],動態的預測上采樣濾波器的權重,然后用這些權重生成高分辨率圖像,即能夠以任意的上采樣因子放大任意的查詢圖像。
首先通過特征學習[25]模塊提取到特征,對于超分辨率圖像中的每一個像素,都是由查詢圖像在像素上的特征和對應的濾波器權重決定的。通過FLR和ISR之間的映射函數—上采樣模塊,得到最終的超分辨率圖像。
上采樣模塊需要一個特定的卷積核或濾波器映射(i1,j1)和(i,j)的值,映射函數如下:
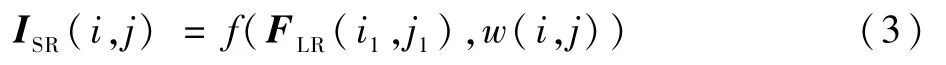
式中:ISR(i,j)為超分辨率圖像在(i,j)的像素值;f(·)表示計算像素值的特征映射函數;w(i,j)為像素點(i,j)的權重預測模塊(與式(5)相對應);FLR(i1,j1)表示在低分辨率圖像中像素點(i1,j1)的特征向量。
對于超分辨率圖像中的每個像素(i,j),可以通過一個投影轉換函數T得到:
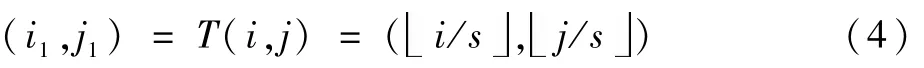
具體的可以看作一種可變步長機制,比如說當尺度因子s為2時,一個(i1,j1)像素決定超分辨率圖像上的2個點。若尺度因子為非整數的1.5,則一些像素決定2個像素,一些像素決定一個像素。無論如何,每一個超分辨率圖像上的像素都能找到一個(i1,j1)。
確定查詢圖像和超分辨率圖像之間的位置關系后還需要得到兩者之間特定的權重以及偏移量,可以通過如下公式得到:
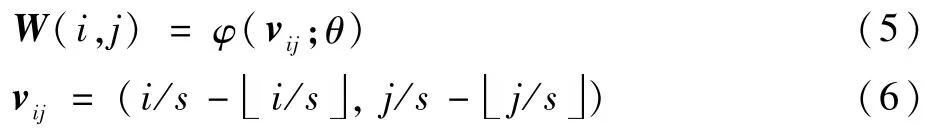
式中:W(i,j)為超分辨率圖像上像素(i,j)對應的卷積核權重;vij為和(i,j)關聯的向量;φ為權重預測網絡;θ為權重預測網絡的權重。
最后需要獲取(i1,j1)像素點的像素值。其特征映射表述為
將輸出的超分辨率圖像與圖庫圖像輸入到基線網絡[26]中得到最后的匹配結果。
3 實 驗
3.1 實驗環境和數據集
實驗是在2塊TITAN Xp GPU上進行的。該網絡基于Pytorch框架,網絡基本結構為Res-Net[26],基線網絡參考了文獻[12],并使用Adam優化器優化參數并將原始學習速率設置為10-3。通過3種主流的數據集對本文方法進行評價:Market1501[27]、CUHK03[28-29]和CAVIAR[30]。首先對這3個數據集以及相應評價標準進行說明。
MLRMarket1501:數據集包括了來自6個不同攝像機拍攝的1 501個行人。使用了DPM方法,將視頻中的行人裁剪出來。數據集劃分為訓練集和測試集,其中訓練集有751人,共12 936張圖片;測試集有750人,查詢圖像3 368張,圖庫圖像19 732張。然而該數據集所有圖像分辨率被處理至統一的大小128×64。因此通過下采樣的方法將數據集中的圖像處理為原尺度的1、1/2、1/4、1/8、1/16五種尺度。
MLRCUHK03:在實驗中采用了新的數據集協議,新協議將CUHK03數據集分為類似于Market1501的劃分方法,將來自10個攝像頭的1 467個行,劃分為由767個身份和700個身份組成的訓練集和測試集。數據集提供2種標注:第1種是人類手工標注行人框,第2種是通過DPM方法檢測得到行人框。雖然數據集中圖像分辨率是多樣的,但分辨率跨度不大,且其中尺度較低的圖像相較于低分辨率數據集分辨率偏高,因此通過下采樣的方法將數據集中的圖像處理至原尺度的1、1/2、1/4、1/8、1/16五種尺度。
CAVIAR:數據集包含由2臺攝像機捕獲的72個身份的1 220張圖像。丟棄了22個只出現在相機中的人,將剩下的人分成2部分,這2部分的身份標簽沒有重疊。
3.2 結果分析
在本文實驗中,為了評價Re-ID的方法,計算出所有候選數據集的累積匹配曲線[27](Cumulative Matching Characteristics,CMC)的Rank1和Rank5。表1和表2展示了本文方法與主流的跨分辨率行人重識別方法在3個數據集上的實驗結果對比。表中最佳的2個結果分別用加粗和下劃線形式突出顯示。
在Market1501數據集上,本文方法和其他主流方法的定量結果對比如表1所示。對比近年來效果較好的行人重識別方法[31],以及大部分跨分辨率行人重識別方法,其中INTACT為近年來處理跨分辨率行人重識別問題的性能最優的方法,該方法為基于多任務學習的方法,通過正則化改進方法,使得模型訓練更簡單,其Rank1和Rank5分別為88.1%和95.0%,而本文方法獲得了90.2%和94.3%,Rank1準確率提高了2.1%,優于前面對比的方法。除了客觀數據的對比,還在Market1501數據集上分別進行了實驗,由圖3可以看出RIPR[12]中幾個不匹配樣本的例子,使用本文方法得到了解決。圖3中三角標“△”是指不匹配的樣本,“1”、“2”和“3”對應于前3個檢索到的圖庫樣本。
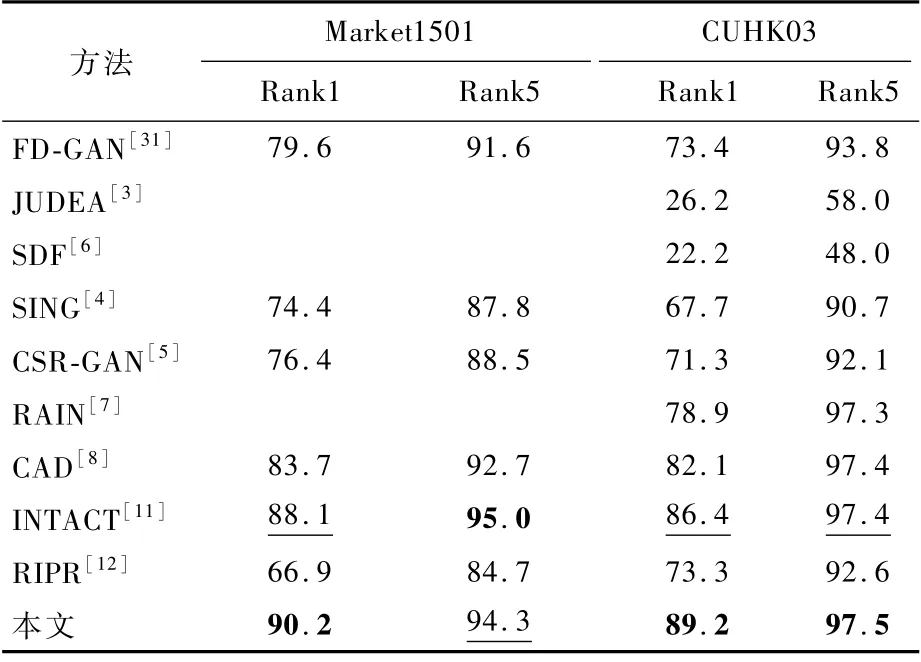
表1 現有方法在Market1501和CUHK03數據集上的定量結果對比Table 1 Quantitative r esult comparison of existing methods on Market1501和CUHK 03 datasets%
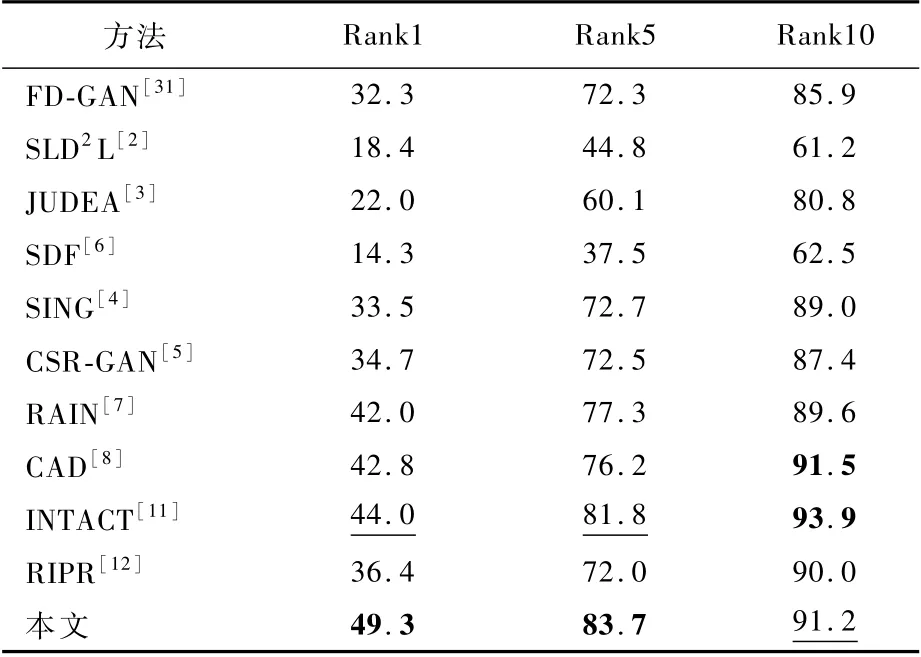
表2 現有方法在CAVIAR數據集上的定量結果對比Table 2 Quantitative result comparison of existing methods on CAVIAR dataset %

圖3 各模型主觀性能對比Fig.3 Subjective performance comparison of various models
在CUHK03數據集上,本文方法使用了新的CUHK03協議[29]進行訓練,由于CUHK03數據集更接近真實情況,圖像是來自于幾個月來錄制的一系列視頻,無約束的成像條件也導致了圖像分辨率的多樣性。因此本文方法在此數據集上取得了比MLRMarket1501數據集更大的進步。同基于局部超分辨率RIPR[12]方法對比,本文方法Rank1提高了15.9%,進一步說明了只恢復前景區域會丟失背景中有利于識別的信息。相較于性能最優的INTACT方法Rank1和Rank5分別提高了2.8%和0.1%。這些數據都證明了本文方法對在跨分辨率場景的有效性。
CAVIAR數據集是早期行人重識別主流數據集,由于早期的攝像頭性能較差,且攝像頭分布并不密集,采集數據也比較困難,數據集內圖像數量較少,且質量較差,一般的行人重識別方法在這一真實的數據集上性能很差。因此本文方法在此數據集上取得了比上述數據集更大的進步:①同基于單一低分辨率的方法SLD2L、JUDEA對比,本文方法Rank1提高了30.9%和27.3%,體現了任意上采樣因子的超分辨率重建在跨分辨行人重識別方法中的優越效果;②與基于級聯超分辨率的方法CSR-GAN、SING相比,本文方法Rank1提升了14.6%和15.8%,進一步說明了任意上采樣因子的超分辨率重建和級聯超分辨率重建相比的有效性;③CAD是基于分辨率不變表示的方法,可以處理未訓練過的尺度,本文方法在Rank1上也提高了6.5%,這有力地證明了基于注意力機制的方法和任意尺度因子的超分辨率重建相結合應用于行人重識別方法上對于跨分辨率問題的有效性。
3.3 消融實驗
為了驗證本文方法的注意力模塊和圖像超分辨率模塊在跨分辨率行人重識別問題上的有效性,采用不同的模型參數進行訓練,使用單一查詢模式在CUHK03數據集上進行實驗。如表3所示,ResNet50為基線模型,CAM 為通道注意力模塊,SAM 為 空 間 注 意 力 模 塊,Non-Local[32]、SENet[20]是常用于圖像分類領域的2個易于集成的注意力模塊,對于圖像分類有一定的作用,MASR表示任意放大因子的圖像超分辨模塊。所有的實驗均只改變了一個設置,其余設置與本文方法的設置相同。
首先,通過表3中不同注意力模塊的性能對比驗證通道注意力模塊和空間注意力模塊聯合作用的有效性,單獨使用通道注意力模塊或者空間注意力模塊,都顯著地提高了跨分辨率行人重識別的性能,當它們聯合使用時Rank1比主流的注意力機制Non-Local、SENet分別提升了8.2%、7.6%。同時,由于空間注意力機制將圖像中的空間域信息做對應的空間變換并保留關鍵信息,進一步挖掘了圖像中顯著且關鍵的區域,相比于通道注意力機制更有助于模型魯棒性的提高,對于模型性能有更加顯著的提升。
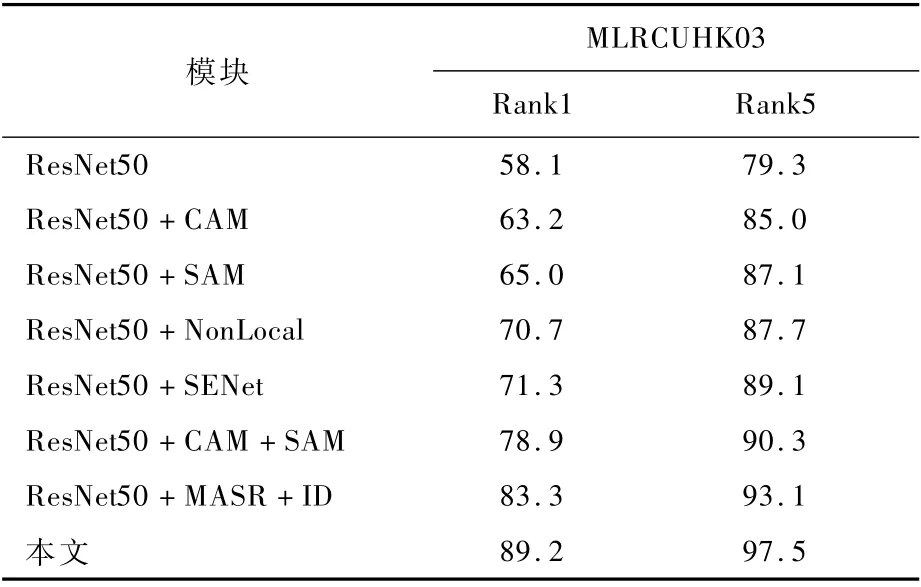
表3 各模塊消融實驗結果Table 3 Ablation experimental r esults of each module%
4 結束語
本文提出了一個用于跨分辨率行人重識別的方法。使用基于通道注意力機制和空間注意力機制相融合的方法來獲取更利于識別的特征和區域,同時解決了不同分辨率查詢圖像關注區域不同的問題。網絡中任意上采樣模塊在超分辨率重建上的應用極其有力地解決了圖像信息恢復過程中由于分辨率多樣性導致的網絡級聯訓練困難、計算量大、模型復雜等問題,從而使本文方法適用于更廣泛的場景。這2個互補的模塊被聯合訓練來優化行人重識別方法,在3個公開的數據集上與大量先進方法對比取得了最優或次優的效果,充分證明了本文引入的模塊的有效性。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
意林原創版(2016年10期)2016-11-25 10:28:30
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
