融合語義信息的視頻摘要生成
2021-04-13 01:59:30滑蕊吳心筱趙文天
北京航空航天大學學報 2021年3期
滑蕊,吳心筱,趙文天
(北京理工大學 計算機學院,北京100081)
隨著視頻拍攝、存儲技術和網絡傳輸的飛速發展,互聯網上的視頻數據呈爆炸性增長[1]。但由于生活節奏越來越快,觀眾在沒有確定視頻是否符合他們的期望前,不會輕易花太多時間觀看完整視頻,觀眾更期望可以通過視頻預告等形式對視頻內容產生大致的了解。視頻摘要任務從原始視頻中提取具有代表性和多樣性的簡短摘要,使觀看者在不觀看完整視頻的情況下,快速掌握視頻的主要內容。
早期的視頻摘要方法[2-3]是基于無監督學習的,使用諸如外觀或運動特征等底層視覺信息和聚類方法來提取視頻摘要。近年來,深度神經網絡[4-8]被用于視頻摘要任務中,其主要致力于學習更具表示能力的視覺特征。這些方法將視頻摘要任務建模為視頻鏡頭子集的挑選,通過使用長短期記憶(Long Short-Term Memory,LSTM)單元來實現視頻摘要的生成。
隨著計算機視覺與自然語言處理的融合發展,視頻文本描述等許多跨模態任務引起了研究人員的廣泛關注。所以自然而然聯想到通過添加文本內容到視頻摘要任務中,利用語義信息對視覺任務進行監督從而獲取視頻摘要,部分近期研究[9-11]也開始研究視頻摘要中包含的語義信息。文獻[9]使用了視頻主題或視頻標題來提供視覺上下文信息,以標識原始視頻包含的重要語義信息。文獻[10-11]結合了自然語言處理領域中常用的一些方法,將語義信息添加到視頻摘要中。但這些工作提出的框架相對簡單,沒有對語義信息進行充分利用。
本文提出一種融合語義信息的視頻摘要生成模型,與現有的視頻摘要方法不同,該模型在訓練時,增加文本監督信息,從原始視頻鏡頭中挑選出具有語義信息的鏡頭。首先,利用卷積網絡提取視頻特征并獲得每幀對應的幀級重要性分數。其次,利用文本監督信息學習視覺-語義嵌入空間,將視覺特征和文本特征投影到嵌入空間中,通過計算跨域數據之間的相似性并使其靠近,從而使視覺特征可以學習更多的語義信息。本文還使用視頻文本描述生成模塊生成視頻對應的文本摘要,并通過與文本標注真值進行比較來優化視頻的幀級重要性分數。該模塊在測試時仍可用,可以為測試視頻生成對應的文本摘要。在測試時,現有的視頻摘要方法只能獲得視頻摘要,而本文模型在獲得具有語義信息的視頻摘要的同時,還可以獲得相應的文本摘要,可以更加直觀地反映視頻內容。
本文的主要貢獻如下:
1)提出了一種融合語義信息的視頻摘要生成模型,通過學習視覺-語義嵌入空間豐富視覺特征的語義信息,以確保視頻摘要最大限度地保留原始視頻的語義信息。
2)本文模型能同時生成視頻摘要與文本摘要。這對于目前互聯網視頻的短片預告與推薦具有很強的現實意義。
3)在2個公開視頻摘要數據集SumMe和TVSum上,相比現有先進方法,本文模型F-score指標分別提高了0.5%和1.6%。
1 相關工作
1.1 視頻摘要
視頻摘要方法可以分為早期的傳統方法和近期的深度學習方法。傳統方法一般利用機器學習,提取底層視覺特征,并利用聚類方法提取視頻摘要。深度學習方法則利用神經網絡獲得更高級的視覺特征以指導視頻摘要生成。Zhao等[6]對LSTM網絡進行了改進,利用分層結構的自適應LSTM 網絡提取視頻摘要。Sharghi等[12]則在此基礎上結合行列式點過程(Determinantal Point Process,DPP)優化了視頻鏡頭子集的選擇問題。針對遞歸神經網絡占用資源過大、結構復雜不適合處理長視頻等問題,Rochan等[13]使用全卷積模型代替遞歸神經網絡,僅通過卷積網絡對視頻幀進行評價挑選也可以生成優質的視頻摘要。
近年來,深度學習無監督視頻摘要生成因其不需要依賴人工標注,引起了研究人員的關注。文獻[14-16]中認為好的視頻摘要能重建原始視頻,采用生成式對抗網絡(Generative Adversarial Networks,GAN)指導視頻摘要的生成,生成器用于生成視覺特征,判別器度量摘要視頻和原始視頻之間的相似度,以此優化網絡。在文獻[17-18]中,強化學習被應用于無監督視頻摘要,通過設計不同的獎勵函數實現無監督視頻摘要。但這些方法沒有考慮視頻內容的語義信息,僅通過無監督方法無法生成具有豐富語義信息的視頻摘要,很難滿足人們對準確反映視頻內容的視頻摘要的需求。
1.2 視頻文本描述
視頻文本描述(Video Captioning)旨在為視頻生成對應的文本描述,最常用的模型為編碼器-解碼器(encoder-decoder)。該模型使用卷積神經網絡(Convolutional Neural Network,CNN)或循環神經網絡(Recurrent Neural Network,RNN)對視頻進行編碼獲得視覺特征,然后使用語言模型對其進行解碼獲得文本描述。本文采用encoder-decoder模型,訓練時最大化生成人工標注的概率指導包含語義信息的視頻摘要生成,測試時使用該模塊生成相應的文本摘要。
2 融合語義信息的視頻摘要生成模型
本文提出了一種融合語義信息的視頻摘要生成模型,如圖1所示,該模型可分為3個模塊:幀級分數加權模塊、視覺-語義嵌入模塊和視頻文本描述生成模塊。
在本節中,首先介紹視頻摘要生成網絡;其次將介紹網絡的訓練過程;最后展示了測試過程中如何同時生成視頻摘要和文本摘要。
2.1 模型介紹
2.1.1 幀級分數加權模塊
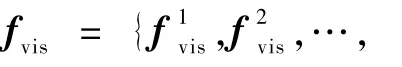
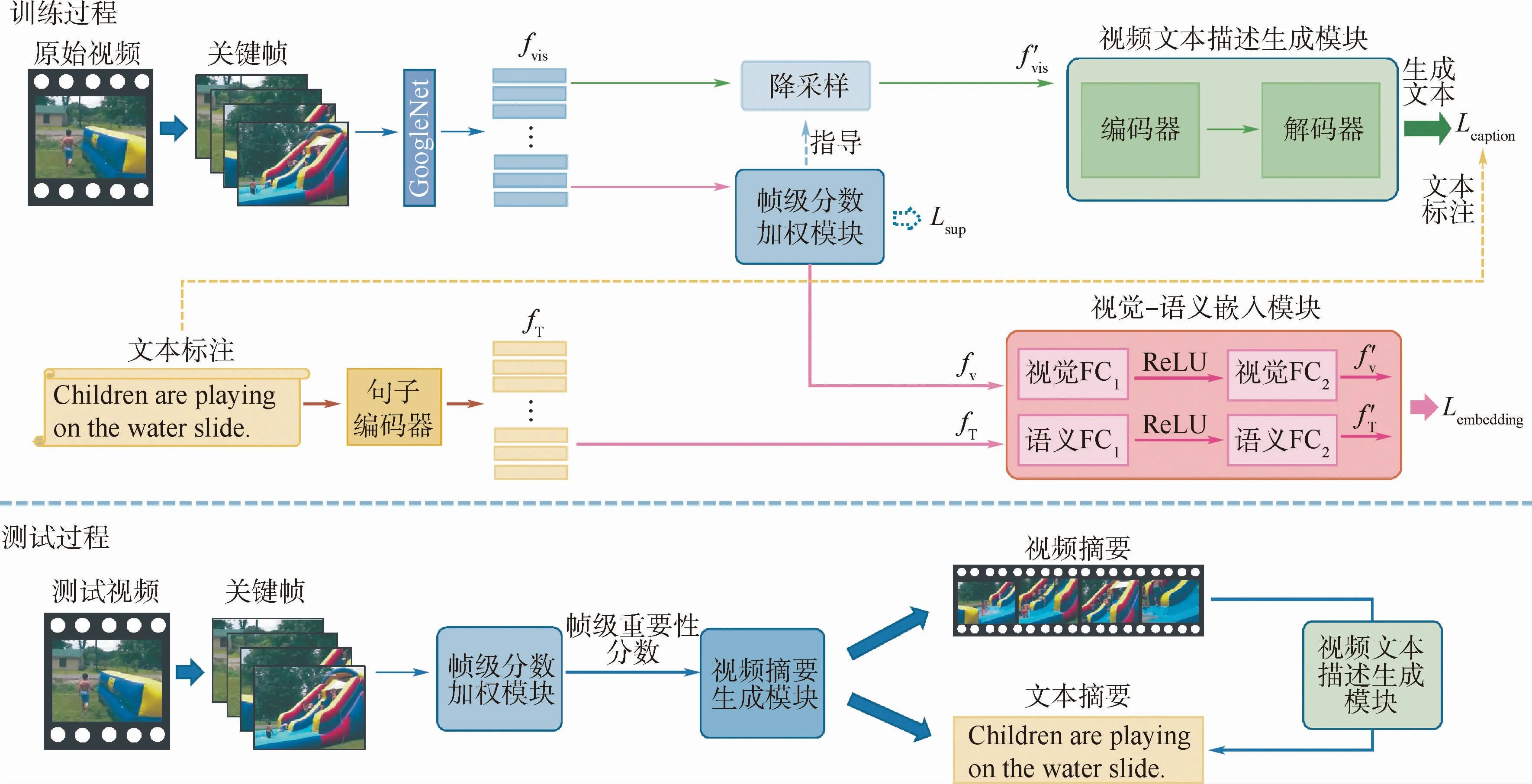
圖1 融合語義信息的視頻摘要生成流程Fig.1 Flowchart of video summarization by learning semantic information
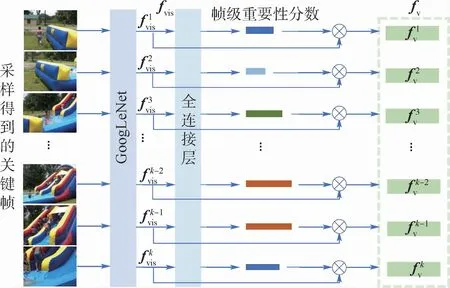
圖2 幀級分數加權模塊框架Fig.2 Framework of frame-level score weighting module

2.1.2 視覺-語義嵌入模塊
本文為數據集中每個視頻都提供了3~6句簡明的文本標注。使用詞嵌入表示文本中出現的單詞,之后利用LSTM 網絡處理詞向量從而獲得句子向量,該特征用fT表示。獲得視頻的視覺特征和文本特征表示后,將視覺特征和文本特征投射到一個公共的嵌入空間中,通過使文本特征和視覺特征相互靠近,豐富視覺特征中的語義信息。該模塊共有2個網絡分支,分別負責對視覺特征與文本特征進行處理,由于視覺特征fV與文本特征fT維度并不相同,通過2個具有非線性層的2層全連接網絡分別對fV與fT進行映射,使特征達到相同維度。將每個視頻的視覺和文字特征表示映射到嵌入空間中,分別用f′V和f′T表示,以使用各種度量標準來衡量投影的視覺和文本特征之間的相似性。本文中為了使2種特征彼此靠近,使用均方誤差損失函數:
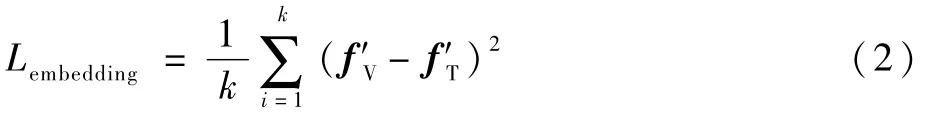
2.1.3 視頻文本描述生成模塊
本文使用encoder-decoder模型生成視頻文本描述生成模塊,視頻文本描述生成模塊可以最直觀地展示網絡是否擁有選擇具有最豐富語義信息的鏡頭以生成視頻摘要的能力。從原始視頻關鍵幀中提取出的視覺特征fvis,將經過降采樣操作后降維成f′vis后送入視頻文本描述生成模塊,降采樣操作是通過幀級分數加權模塊得到每幀對應的分數后,從中挑選出分數最高的前N幀所對應的視覺特征,按時序順序排列后組成f′vis。
降采樣操作必不可少,因為原始視頻幀序列過長,且鏡頭變換豐富,包含較多的冗余信息,故將整個視頻直接輸入視頻文本描述生成模塊后編碼器對視覺內容的編碼能力會大大降低。降采樣操作可以通過幀級重要性分數選擇最具代表性的視覺特征,同時也可通過損失項的反饋調整幀級重要性分數,從而不斷選擇更好的關鍵幀用于文本生成,是十分必要的。
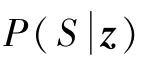

2.2 網絡訓練
本文使用Adam優化器訓練模型,通過使用Adam逐漸降低損失項,以逐步更新網絡的參數。
2.2.1 預訓練
由于TVSum 和SumMe中包含的數據量很少,僅通過訓練小樣本數據無法達到文本生成的實驗目的,因此利用現有的大型視頻文本描述數據集對視頻文本描述生成模塊進行預訓練。MSRVTT數據集[19]包含了10 000個視頻片段,每個視頻都標注了20條英文句子,視頻平均時長約為10 s,視頻內容采集自網絡,包含各種類型的拍攝內容。實驗證明,通過使用MSR-VTT對模型進行預訓練確實可以有效緩解由樣本不足引起的問題。
2.2.2 稀疏約束
為了充分利用SumMe和TVSum數據集提供的幀級重要性分數標注,本文還為網絡添加了稀疏約束。稀疏約束的計算是利用在訓練階段關鍵幀計算獲得的幀級重要性分數si,與數據集中提供的用戶標注的幀級重要性分數^si進行交叉熵損失計算:
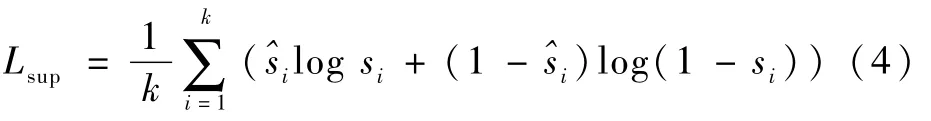
當利用稀疏約束時,訓練網絡的總損失函數為
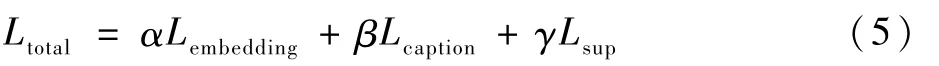
式中:α、β、γ均為需要人工調節的超參數,當不使用稀疏約束時,γ為0。
2.3 視頻摘要生成與文本摘要生成
測試時,模型不使用文本標注和句子編碼器,只使用訓練時得到的視頻文本描述生成模塊來生成視頻摘要和文本摘要。
對于視頻分割,本文使用Potapov等[20]提出的KTS技術分割出不重疊的鏡頭。對于鏡頭重要性分數的計算,則是通過將鏡頭中包含的關鍵幀的幀級重要性分數求平均得到的。為了生成視頻摘要,本文通過最大化鏡頭總分來選擇鏡頭,同時確保視頻摘要長度不超過視頻長度的15%,實際上,選擇滿足條件的鏡頭這一問題等價于0/1背包問題,也稱為NP困難(Non-deterministic Ploynomial Hard)問題。
在獲得視頻摘要后,本文將視頻摘要中的幀級重要性分數排名前N的視覺特征,按時間順序送入訓練過程中獲得的視頻文本描述生成模塊,來獲得相應的文本摘要。
3 實驗結果與分析
3.1 實驗設置
3.1.1 數據集
本文在SumMe[21]和TVSum[22]數據集上評估模型。SumMe由25個用戶視頻組成,涵蓋了各種主題,例如假期和體育。SumMe中的每個視頻時長在1~6 min之間,并由15~18個人提供標注。TVSum包含50個視頻,其中包括新聞、紀錄片等主題。每個視頻時長從2~10 min不等。與SumMe類似,TVSum中的每個視頻都有20個標注,用于提供幀級重要性評分。
3.1.2 文本標注
上述2個數據集僅提供視頻和幀級重要性分數,無法對視頻長期語義進行建模。為此,為數據集TVSum和SumMe提供了文本標注,為2個數據集每個視頻提供相互獨立的3~6個簡短的句子,以描述視頻的主要內容。
3.1.3 評價指標
使用文獻[23]中的方法對視頻摘要進行評價,即通過度量模型生成的視頻摘要與人工選擇的視頻摘要間的一致性來評估機器所生成摘要的性能。假設A為機器生成的摘要,B為人工選擇的摘要,DA為A的持續時間,DB為B的持續時間,DAB為AB重復部分的持續時間,則精度P和召回率R分別定義為

用于評估視頻摘要的F-score定義為
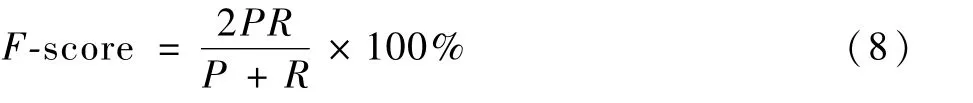
文本摘要通過圖像描述任務中常用的3個指標來進行評價,分別為BLEU1、ROUGE-L和CIDEr。BLEU1用于判斷句子生成的準確性,ROUGE-L用于計算句子生成的召回率,CIDEr則體現的是生成句子與人工共識的匹配度,以上指標越高證明句子生成效果越好。
3.1.4 實驗細節
使用在ImageNet上預訓練的GoogLeNet作為獲取視頻特征的網絡模型,每個視頻以2 fps(fps為幀/s)的幀率對關鍵幀進行采樣。每幀圖像特征維度為1 024,句子特征維度為512,在視覺語義視頻嵌入空間中將共同被映射為256維的向量。描述生成模型的編碼器和解碼器為單層LSTM 網絡,隱藏層維度設置為512。在大型視頻文本描述數據集MSR-VTT上預訓練視頻文本描述生成模塊,對其中每個視頻都均勻采樣40幀,所以框架中降采樣參數N也設置為40。在聯合訓練中,為了實現在預訓練模型上的微調,學習率設置為0.0001。將2個數據集分別進行訓練測試,其中每個數據集中80%的視頻用于訓練,其余用于測試。
3.1.5 對比方法
選擇了6種最新的視頻摘要模型與本文模型進行比較:vsLSTM[4]、dppLSTM[4]、SUM-GANsup[5]、DRDSNsup[17]、SASUMsup[11]、CSNetsup[24]。vsLSTM 是 一種利用LSTM 的視頻摘要生成模型,也是較為基礎的一種模型。dppLSTM 同樣是一種利用LSTM的視頻摘要生成模型,它通過使用DPP來選擇內容多樣化的關鍵幀。SUM-GANsup是一種利用VAE和GAN的視頻摘要生成模型。DR-DSNsup是一種無標簽的強化學習視頻摘要生成模型。SASUMsup是一個同樣融合語義參與視頻摘要模型。CSNetsup是另一種利用VAE和GAN的視頻摘要生成模型。上述視頻摘要模型均為有監督模型。
3.2 定量結果與分析
首先介紹本文方法的2種不同設置。
本文方法(無監督):本文提出的融合語義信息的視頻摘要生成模型,沒有任何稀疏性約束。
本文方法(有監督):由人工標注的視頻摘要Lsup監督的融合語義信息的視頻摘要生成模型。
如表1所示,與最先進的方法相比,本文模型具有更好的性能。本文無監督方法僅使用提供的帶標注的文本描述,其結果幾乎與其他帶有人工標注的視頻摘要的有監督方法相當。本文有監督方法在所有數據集中的表現優于所有引用的方法,F-score指標較目前效果最好的CSNetsup方法在2個數據集上分別提高了0.5%和1.6%,這證明融合語義信息的視頻摘要確實能夠生成更高質量的視頻摘要。
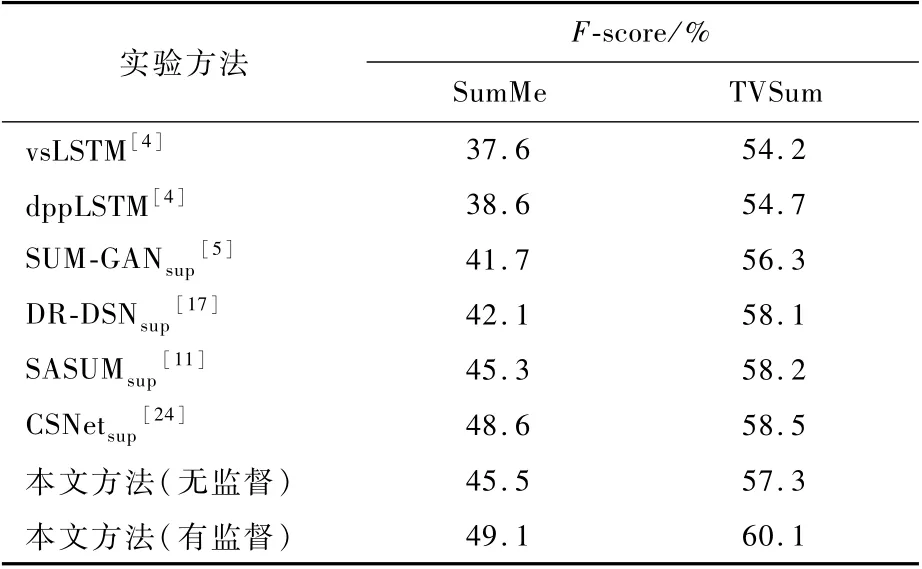
表1 與6個最新方法之間的F-score比較Table 1 Performance comparison(F-score)between our frameworks and six state-ofthe-art methods
接下來分析本文方法2種不同設置產生的實驗結果。本文有監督方法的性能優于本文無監督方法2.8% ~3.6%。顯然,這是因為本文有監督方法使用數據集提供的幀級重要性分數作為監督,因此相比于本文無監督方法生成的摘要,本文有監督方法生成的摘要與人工選擇的視頻摘要更具有一致性。
本文有監督方法在SumMe和TVSum上的表現分別為49.1%和60.1%,之所以在2個數據集上的性能具有較大差異,是因為SumMe的視頻內容變化緩慢且場景中的對象很少,而在TVSum中場景是多變的。豐富多樣的鏡頭可能會在視頻摘要生成過程中占據更大的優勢,如果整個視頻都是過于相似的鏡頭,則會對鏡頭挑選的邊界更加模糊,從而導致生成的視頻摘要評分較低。
表2展示了在本文有監督方法中,不同評估標準下在SumMe和TVSum數據集上生成視頻摘要的性能。可以看出文本摘要可以一定程度上描述視頻內容,之后也會在3.4.2節中定性展示文本生成的效果。不過由于視頻摘要任務數據集數據量過小,文本摘要性能受到了很大影響,容易生成結構較為單一的短句。

表2 不同數據集生成的文本摘要評測Table 2 Evaluation of text summaries generated by different datasets
3.3 消融實驗
為了驗證視頻摘要模型中的視覺-語義嵌入模塊和視頻文本描述生成模塊,本文在TVSum數據集上進行消融實驗,通過分別從模型中排除不同模塊來展示每個模塊對網絡性能的貢獻。此外,如果不使用這2個模塊中的任何一個,則該問題將歸結為最基本的視頻匯總問題,即損失函數只能使用Lsup。為了保持實驗參數的一致性,本文將采用有監督方法來進行消融實驗,以確保Lsup可用。從表3數據中可以看出,應用不同模塊時F-score分數將逐漸增加,當2個模塊同時應用時達到實驗的最優結果。這證明本文提出的2個模塊確實能夠指導具有語義信息的關鍵幀獲得更高的幀級重要性分數,從而生成更優質的視頻摘要。

表3 TVSum 數據集上的消融實驗結果Table 3 Results of ablation experiment on TVSum
3.4 定性結果與分析
3.4.1 視頻摘要示例
選擇用TVSum數據集中一則“寵物美容”相關新聞視頻來展示視頻摘要的生成情況。圖3(a)展示了原始視頻內容,可以看到原始視頻除寵物美容相關鏡頭外,還包含新聞片頭片尾、采訪路人等畫面。圖3還分別展示了本文無監督方法、本文有監督方法、本文有監督方法但不含視頻文本描述生成模塊、本文有監督方法但不含視覺-語義嵌入模塊4種設置下,從原始視頻中挑選的視頻摘要情況。圖中淺色條形圖表示人工標注的幀級重要性分數,深色條形圖表示該設置下挑選的視頻摘要。
從圖3(b)~(e)可以看出,每種設置都能夠很好地生成針對整個視頻的視頻摘要,挑選的視頻摘要覆蓋了人工標注的峰值,能夠反映出原始視頻是一則與寵物相關的視頻,這表明本文模型可以從視頻中提取出語義豐富的視頻鏡頭,生成優質的視頻摘要。
同時對比圖3(b)與圖3(c),發現本文有監督方法相較于無監督方法表現更好。由于稀疏約束的加入,相比于無監督方法只注重于挑選具有代表性的視頻,本文有監督方法提取的視頻鏡頭覆蓋范圍更廣、彼此間隔更分明,生成的視頻摘要富含語義信息的同時還具有鏡頭多樣性。
在圖3(c)~(e)幾種有監督設置中,利用全部模塊的設置表現最佳。在缺失部分模塊的情況下,雖然摘要的代表性與多樣性依然較好,但還是容易挑選與語義信息不相關的鏡頭。如圖3(d)與圖3(e)中,2種設置下的模型都將新聞的片頭畫面挑選為視頻摘要,而應用全部模塊的有監督方法挑選的摘要幾乎不含這些無關鏡頭,這也正與3.3節中的消融實驗結果相對應。
關于視頻摘要的定性結果展示視頻可前往https://github.com/huarui1996/vsc進行觀看,后續更多相關數據也會在此開源。
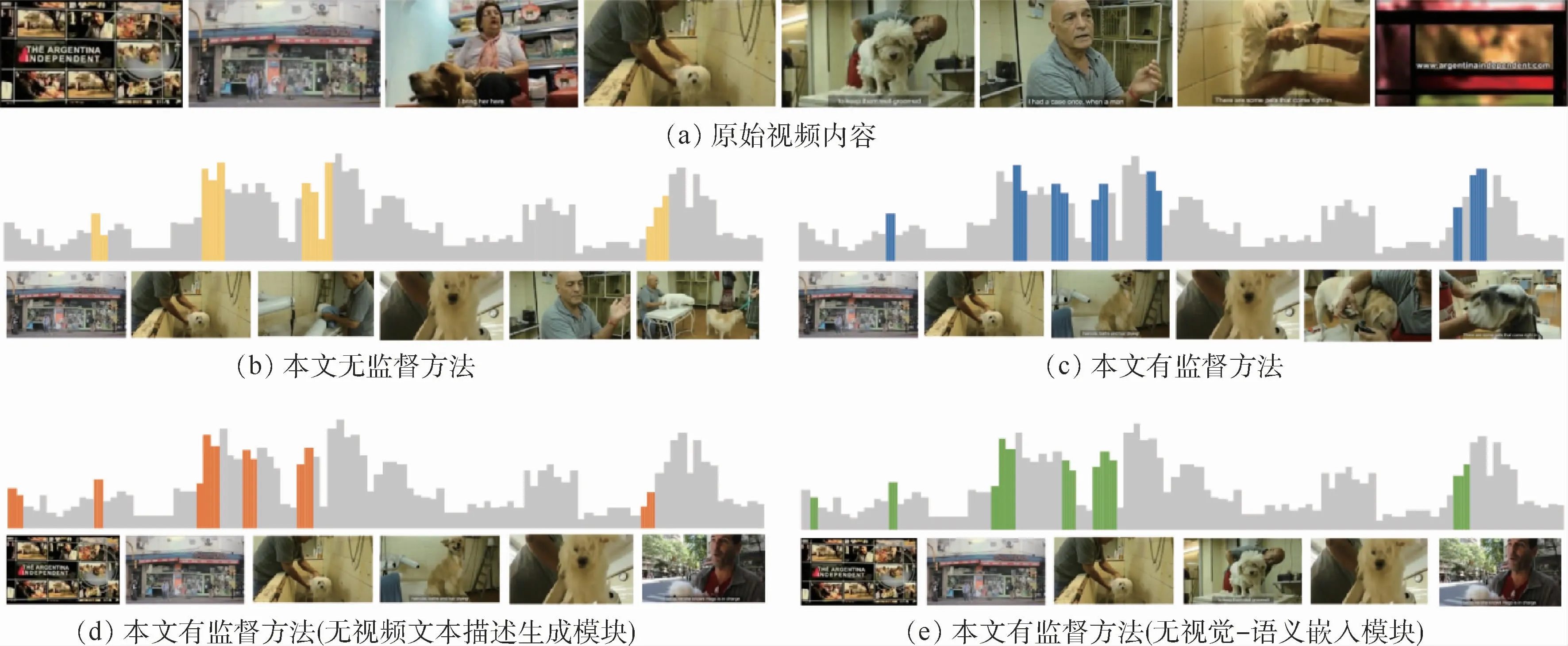
圖3 TVSum數據集中生成視頻摘要的示例Fig.3 Examples of video summarization in TVSum
3.4.2 視頻文本摘要對應

圖4 TVSum數據集中生成文本摘要的示例Fig.4 Examples of text summarization in TVSum
圖4展示了在TVSum數據集中,對名為Yi4Ij-2NM7U4的視頻同時生成的文本摘要和視頻摘要的內容對應,同時還展示了3個不同用戶對原始視頻添加的文本標注。可以看出,雖然本文模型生成句子的結構較為簡單,但是可以描述出視頻主要內容。
4 結 論
1)本文提出了一種融合語義信息的視頻摘要生成模型,該模型通過幀級分數加權模塊、視覺-語義嵌入模塊和視頻文本描述生成模塊3個模塊,使得視覺特征包含豐富的語義信息,可以同時生成具有語義信息的視頻摘要以及相應的文本摘要。
2)實驗結果表明,由本文模型生成視頻摘要能夠展示出原始視頻中重要的語義內容,同時文本摘要可以簡明地對視頻內容進行描述。
在未來的工作中,將利用多模態信息實現視頻摘要生成任務,并根據不同用戶的需求生成不同主題的視頻摘要。
猜你喜歡
人大建設(2020年4期)2020-09-21 03:39:12
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
浙江人大(2014年4期)2014-03-20 16:20:16
