上下游行業用電變化的因果關系及預測方法
2021-04-20 12:46:32包永迪楊一帆王旭強周佳禾
無線互聯科技 2021年4期
關鍵詞:模型
包永迪,楊一帆,王旭強,周佳禾
(國網天津市電力公司信息通信公司 數據管理服務中心,天津 300010)
0 引言
地區經濟與行業發展存在著密切的聯系。以細分行業為立足點,并結合相關發展數據和政府政策,可以分析地區經濟的產業結構,梳理區域內行業間的上下游關系,這對公司、政府等主體進行宏觀戰略制定具有重要意義。
目前,一些研究探討了電力消費結構與經濟增長、行業發展的關系[1-2],其結論表明電力消費結構與經濟和行業的發展存在明顯的相關性,而電力發展的趨勢也能反映經濟和行業發展的態勢。一些研究從商品鏈、企業或產業鏈的視角分析其上下游對其自身的影響[3-4],通過分析上下游關系來為其自身提供決策支持。然而,缺乏將這兩種視角結合起來的研究,即從電力消費結構的角度,探討相應層次的上下游關系。
本文提出了一種關聯性分析模型,利用天津市區域級、行業級的電力消費數據,從宏觀上分析區域內的行業上下游關系。除此以外,還對區域內的行業進行了用電量建模,從而預測行業在滯后時段內的用電量。
1 問題分析與數據收集
電力消費結構與地區經濟中的產業結構有著密切的聯系。基于一定的技術關聯,在產業結構內部客觀上存在著具有時空布局關系的鏈條式關聯形態,鏈條上的每一個節點都可以由一個細分行業來替代,因此這種關聯實際上揭示了行業間的上下游關系[5]。行業上下游關系反映了整個產業結構背后的價值、企業、供需、空間關系。國內外學者對行業上下游關系及產業結構做了一些相關的研究。然而,這些研究在揭示行業上下游關系時,往往具有特定的限制,缺乏適應性強的方法,還有一些研究則是基于主觀上的定性分析,而非利用定量的方法反映客觀狀況。因此,本文提出了一種定量分析的具有較強適應性的方法,即通過研究電力消費結構來揭示行業的上下游關系。
研究行業上下游之間的時間周期、關聯程度可以抽象為對多個時間序列進行滯后周期的分析和驗證。有很多方法可以分析時間序列間的動態關系,其中最被廣泛使用的方法就是向量自回歸模型(VAR)。向量自回歸模型是一種計量經濟學方法,可以在不帶有任何約束條件的前提下,估計聯合內生變量的動態關系。另外,在判定行業上下游關系時,依靠經驗和相關查證仍然不夠客觀。因此本文利用格蘭杰因果檢驗方法對變量間進行雙向因果檢驗。
本文使用的電力數據來自于天津市國家電網電力系統內部獲取的天津市不同行業用電量數據,行業按三大產業分為3個大類,數據為按行業分類的2012年1月—2019年9月的月度用電量。
2 上下游行業用電關聯性分析模型
上下游行業用電關聯性分析模型是用來預測某一區域內行業上下游關系的模型。首先需要搜集相關的月度電力數據,并按照行業進行整理,然后將數據進行歸一化等預處理操作。模型主要從時間序列分析出發,利用格蘭杰因果關系檢驗驗證行業之間是否會互相影響,在此基礎上構建向量自回歸模型找出存在的線性關系。
2.1 數據搜集與預處理
搜集的數據主要以月度電力數據為主,為了使模型結果具有可信度,必須搜集具有足夠跨度的電力月度數據,本文利用了共計93個月月度電力數據,然后將電力數據以CSV形式進行存儲。
為了方便處理,統一量度,本文將整理好的電力數據利用歸一化方法完成了預處理。這里使用離差標準化方法即:
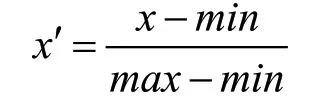
2.2 向量自回歸模型與格蘭杰因果關系檢驗模型
向量自回歸模型描述了一組聯合內生變量隨時間演變的關系,并且可以通過將一組變量建模為由其過去值組成的線性函數。根據過去時間段數量上的不同,VAR模型可以有相應的變體,通常情況下,一個p階的VAR模型指的是考量過去p個時間段的VAR模型,并可以表示成如下矩陣形式:
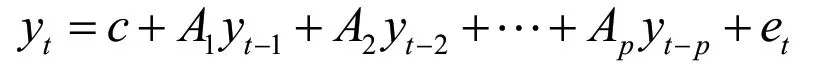
其中,yt-1表示相比于yt提前了i個時間周期的向量,c則是作為模型偏移常數的k維向量,A是維k×k的非時變矩陣,et則是用作誤差項的k維向量。
格蘭杰因果關系檢驗是用于分析變量間因果關系的一種方法。給定兩個變量X和Y的時間序列,則可以定義格蘭杰因果關系:若單獨由Y的過去信息對Y進行預測的效果,不及同時利用變量X和Y的過去信息對Y進行預測的效果,則可以認為變量X有利于解釋變量Y發生的變化,這時就可以認為變量X是導致變量Y的格蘭杰原因。
在進行格蘭杰因果關系檢驗前,必須具備的一個條件是變量的時間序列必須具有平穩性,否則可能會出現虛假回歸問題。
2.3 建模過程與計算示例
整個建模過程可以分為6個步驟。
(1)平穩性檢驗。利用單位根檢驗法可以進行平穩性檢驗。若存在單位根則時間序列不平穩,當變量不平穩時,需要進行進一步差分,一般一階差分后時間序列達到平穩,可繼續進行協整檢驗。
(2)協整檢驗。針對非平穩的單個序列,但它們的線性組合可能是平穩的,若平穩性檢驗后為一階單整的,且為非平穩時間序列,則各變量之間可能存在協整關系,如果某組要對所選擇的內生變量進行VAR模型的構建,需要驗證兩者之間是否具有相同的趨勢,所以要進行協整檢驗,以判斷各個變量之間是否存在長期穩定的協整關系,處理各變量之間的是否存在偽回歸問題。
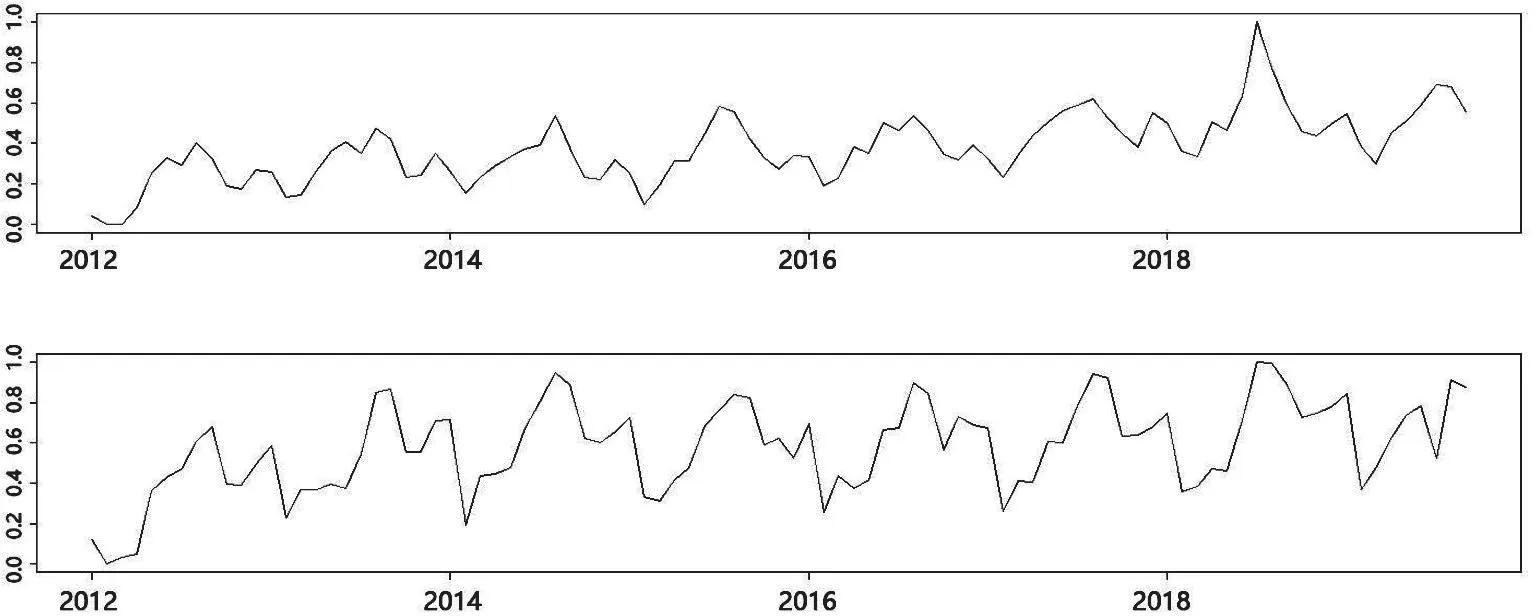
圖1 農業、農副產品加工業用電量趨勢
(3)確定滯后階數。兩個時間序列回歸存在一定的滯后階數,其代表在幾個時間點內的數據是較為相關的。通過AIC或HQ等不同信息準則選擇出合適的結果。
(4)格蘭杰因果關系檢驗。利用上一步選擇的滯后階數進行雙變量的雙向格蘭杰因果關系檢驗,判斷兩變量是否對對方具有顯著影響。在當前應用場景下,主要思想就是先利用目標行業自身時間序列進行AR模型的構建,即用前幾個月的用電量對下個月回歸,然后在此基礎上加入另一行業前幾個月的電量數據,同樣對目標行業進行回歸,若此時得到的回歸模型好于之前,則說明此行業對目標行業有顯著影響。
(5)擬合VAR模型。同樣使用滯后階數以及回歸的方法,計算VAR模型的系數,得到相應階數的方程。
(6)脈沖響應分析以及預測。利用上一步得到的VAR模型衡量脈沖響應值,并進行分析和預測。脈沖響應值即衡量在外部波動后存在的影響強度,正值代表正向影響,負值表示負向影響,絕對值越大,影響越強。
3 實驗結果與分析
3.1 實驗環境
本文實驗的硬件平臺為Intel(R)Core(TM)i7-9750H CPU@2.60 GHz、16 GB內存、1 TB大小的SSD硬盤以及Windows10操作系統,軟件環境為R及RStudio。
3.2 平穩性檢驗與滯后階數
依靠經驗和相關查證可以預想,農業與農副產品加工業存在一定的上下游關系。
首先進行兩個行業的時間序列圖對比,如圖1所示,可以看見趨勢具有相似性,符合猜想預期。
經檢驗后兩序列平穩,無須進行協整檢驗,這里選取的滯后階數為3。
3.3 格蘭杰因果關系檢驗
進行格蘭杰因果關系檢驗,結果如圖2所示。
兩者P值均遠小于0.01,可認為互相之間均存在顯著的影響。

圖2 農業、農副產品加工業格蘭杰因果關系檢驗
3.4 擬合VAR模型
進一步進行VAR模型擬合,結果如圖3所示,農業主要與1、3月前的用電量和1、2月前的農副產品加工業用電量顯著相關,而農副產品與1、2、3月前的農業用電量顯著相關。
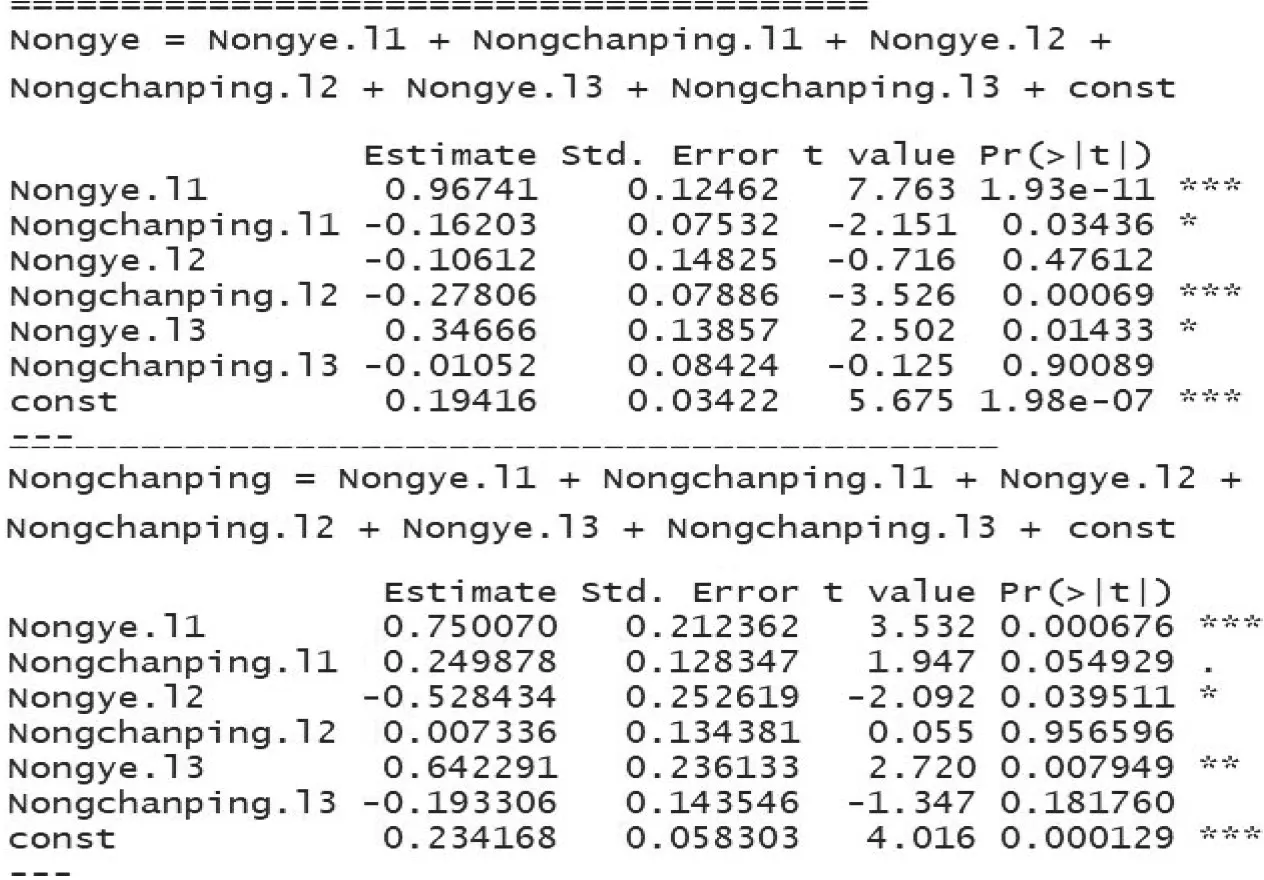
圖3 農業、農副產品加工業VAR模型擬合結果
3.5 脈沖響應分析
由VAR模型得到的農業脈沖響應圖如圖4所示。在一個時間點對農業施加一個沖擊,對自己的影響隨時間逐漸減弱,到7月后消失,對農副產品加工業同樣具有相似的影響。
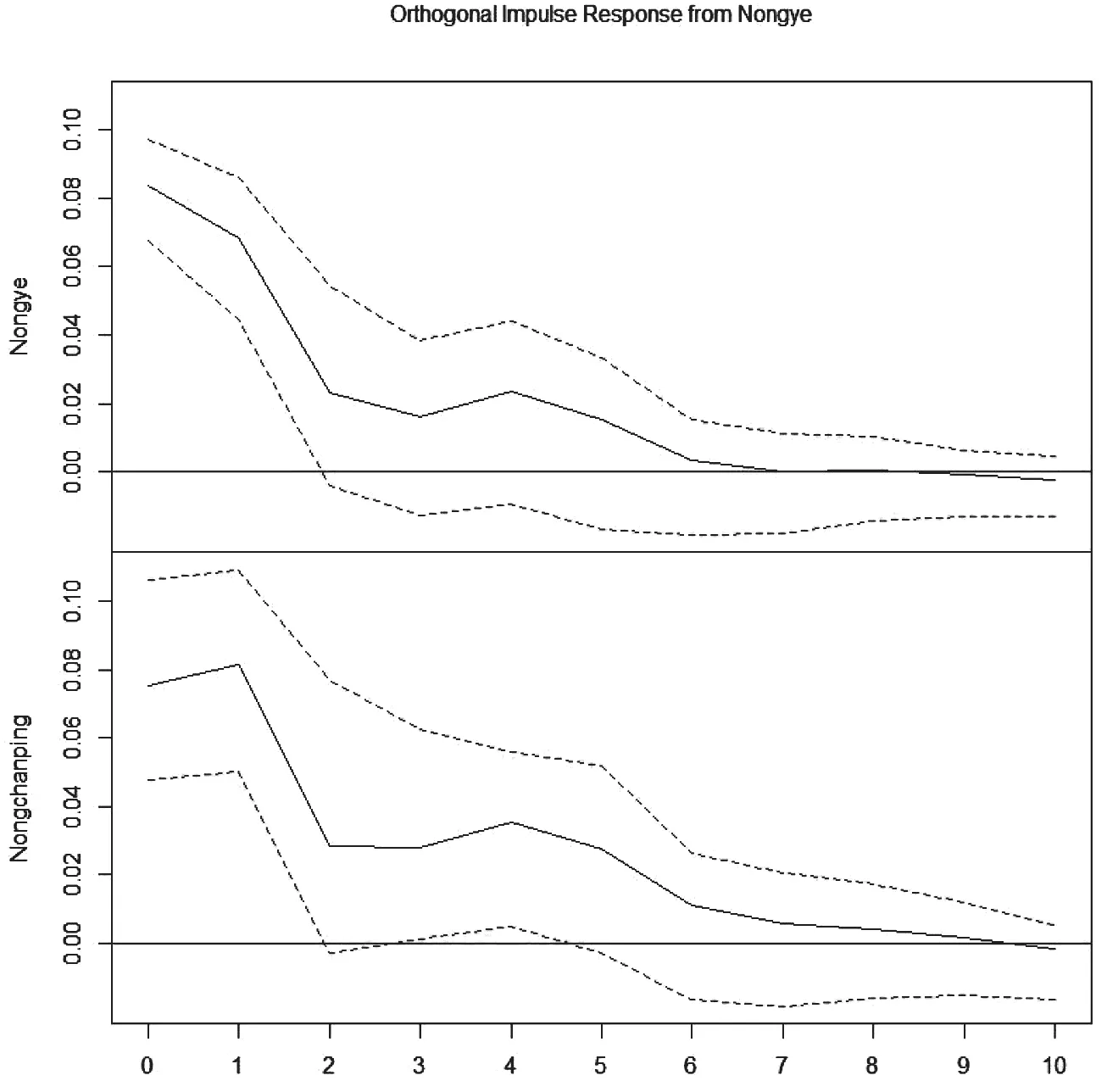
圖4 農業脈沖響應
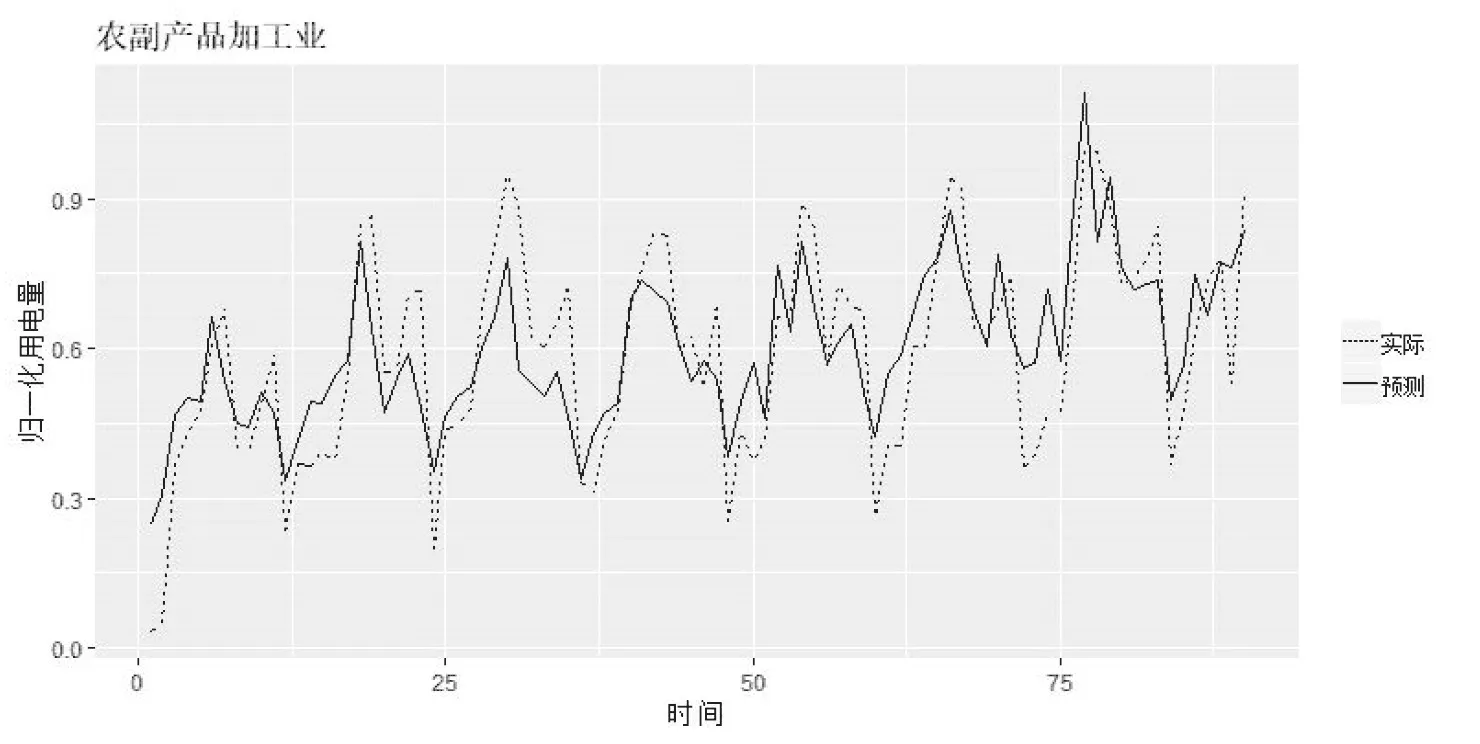
圖5 農業預測與實際電量對比(2012.3—2019.9)
3.6 用電量預測
利用VAR模型可以對后續電量進行預測,為檢驗預測結果的準確性,利用模型對每個月都進行擬合,農業預測與實際值對比如圖5所示。
農業的預測值與實際十分接近,而農副產品并不能完全吻合,但總體趨勢一致,這意味著VAR模型的有效性。因此,利用這種方法,可以對滯后時間段內用電量進行預測。
4 結語
本文利用關聯性分析方法,對區域內行業用電量進行建模,挖掘不同行業間的上下游關系。整個建模過程包括平穩性檢驗、協整檢驗、確定滯后階數、格蘭杰因果關系檢驗、擬合VAR模型、脈沖響應分析以及預測。實驗結果表明,使用關聯性分析建模,可以揭示行業上下游關系,預測滯后時間段內該行業未來的用電量,這意味著關聯性分析模型的有效性。除此以外,本文僅僅分析了兩個變量,若選擇更多的行業進行關聯分析,則可以得到更加準確的VAR模型和預測結果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
