融合網(wǎng)絡(luò)結(jié)構(gòu)信息及文本內(nèi)容的標(biāo)簽推薦方法
2021-04-20 14:06:46車冰倩
計(jì)算機(jī)應(yīng)用 2021年4期
車冰倩,周 棟
(湖南科技大學(xué)計(jì)算機(jī)科學(xué)與工程學(xué)院,湖南湘潭 411201)
0 引言
隨著數(shù)字資源的快速增長(zhǎng),標(biāo)簽推薦越來(lái)越受到人們的關(guān)注。最新的研究表明,除標(biāo)題、描述和用戶評(píng)論等其他文本功能外,標(biāo)簽?zāi)軌驅(qū)Y源進(jìn)行分類和建立索引,是組織和檢索內(nèi)容的有效方式[1],被廣泛應(yīng)用于各種自然語(yǔ)言處理任務(wù)中,例如情感分類[2]、內(nèi)容推薦[3]等為在線內(nèi)容推薦合適的標(biāo)簽是自然語(yǔ)言處理中的一項(xiàng)重要任務(wù)。從內(nèi)容創(chuàng)建者的角度來(lái)看,標(biāo)簽推薦有助于為創(chuàng)建者提高所選標(biāo)簽質(zhì)量和用戶體驗(yàn);從內(nèi)容消費(fèi)者角度來(lái)看,標(biāo)簽推薦有助于為消費(fèi)者的搜索和檢索請(qǐng)求提供更好的服務(wù)[4]。然而,手動(dòng)標(biāo)記通常既費(fèi)時(shí)又費(fèi)力。因此,為了提高數(shù)據(jù)管理效率和簡(jiǎn)化標(biāo)注過(guò)程,有必要用到自動(dòng)標(biāo)簽推薦系統(tǒng)。
目前已有研究者提出了許多自動(dòng)標(biāo)簽推薦方法。一些研究利用傳統(tǒng)的方法(如詞頻-逆文檔頻率(Term Frequency-Inverse Document Frequency,TF-IDF)、N-grams 等)人工提取文本內(nèi)容特征進(jìn)行標(biāo)簽推薦[5-6]。此外,潛在狄利克雷分布(Latent Dirichlet Allocation,LDA)模型[7-8]或其擴(kuò)展的主題模型[9-10]用于從文本內(nèi)容中提取隱含的主題信息,基于這些主題信息計(jì)算文本之間的相似性,再通過(guò)文本間的語(yǔ)義相似度進(jìn)行標(biāo)簽推薦。近年來(lái),使用深度學(xué)習(xí)模型對(duì)文本內(nèi)容中的隱藏信息建模(如詞序信息、上下文信息等)后,進(jìn)行標(biāo)簽推薦也成為了當(dāng)下研究熱點(diǎn)之一[11]。常用的模型包括卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)[12]和循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network,RNN)[13]等。但是這些方法主要是通過(guò)挖掘文本的內(nèi)容信息,從資源本體的角度來(lái)設(shè)計(jì)標(biāo)簽推薦方法。實(shí)際上,很多文本并非獨(dú)立存在。例如,文本數(shù)據(jù)可通過(guò)文本間的詞共現(xiàn)關(guān)系而聯(lián)系到一起,文本中的詞與文本之間具有隱含的網(wǎng)絡(luò)結(jié)構(gòu)信息。研究表明,文本內(nèi)容層面的信息和網(wǎng)絡(luò)結(jié)構(gòu)層面的信息獨(dú)立存在,但又相互關(guān)聯(lián)和影響,從不同的角度共同對(duì)一個(gè)文本的語(yǔ)義特征進(jìn)行概括會(huì)得到更好的結(jié)果[14]。尤其在某方面信息缺乏時(shí),內(nèi)容和結(jié)構(gòu)兩方面信息可以互為補(bǔ)充,從而改進(jìn)推薦的效果[15]。因此,需要充分利用文本之間的網(wǎng)絡(luò)結(jié)構(gòu)信息和文本內(nèi)容信息進(jìn)一步提高推薦的準(zhǔn)確性。
基于上述分析,本文提出一種融合網(wǎng)絡(luò)結(jié)構(gòu)信息和文本內(nèi)容、基于G-RNN(Graph Attention-Based Recurrent Neural Network)模型的標(biāo)簽推薦方法。該方法首先將文檔與詞匯作為節(jié)點(diǎn)構(gòu)建異構(gòu)網(wǎng)絡(luò)圖;然后,基于圖卷積神經(jīng)網(wǎng)絡(luò)(Graph Convolutional neural Network,GCN)[16]建立基于這些節(jié)點(diǎn)的文本異構(gòu)圖,捕獲高階鄰域信息,獲取文本間的網(wǎng)絡(luò)結(jié)構(gòu)信息;接下來(lái)基于RNN 模型獲取文本的內(nèi)容信息;最后通過(guò)注意力機(jī)制對(duì)文本網(wǎng)絡(luò)結(jié)構(gòu)信息和文本內(nèi)容信息進(jìn)行交互建模。在三個(gè)真實(shí)數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果表明,本文方法明顯優(yōu)于對(duì)比的基線方法。本文的主要工作如下:
1)提出了一種基于注意力機(jī)制的混合標(biāo)簽推薦模型。該模型融合了文本間網(wǎng)絡(luò)結(jié)構(gòu)信息和文本內(nèi)容信息,可以提取更好的文本語(yǔ)義特征,解決現(xiàn)有標(biāo)簽推薦模型中文本語(yǔ)義特征提取不充分的問(wèn)題。
2)同時(shí)考慮到RNN 的四種變體對(duì)提取文本內(nèi)容信息的影響,并用實(shí)驗(yàn)進(jìn)行了對(duì)比驗(yàn)證。實(shí)驗(yàn)結(jié)果表明,與現(xiàn)有的幾種基線方法相比,本文提出的融合網(wǎng)絡(luò)結(jié)構(gòu)信息和文本內(nèi)容信息的標(biāo)簽推薦方法具有更好的性能。
1 相關(guān)工作
標(biāo)簽推薦技術(shù)已經(jīng)引起了學(xué)者的廣泛關(guān)注和研究,并根據(jù)具體問(wèn)題提出了多種推薦方法。總的來(lái)說(shuō)可以將這些推薦方法分為基于傳統(tǒng)語(yǔ)義的方法和基于深度語(yǔ)義的方法。其中基于傳統(tǒng)語(yǔ)義的方法主要分為兩類[17]:基于協(xié)同過(guò)濾的方法和基于內(nèi)容的方法。
基于協(xié)同過(guò)濾的方法核心思想是利用歷史評(píng)分信息進(jìn)行標(biāo)簽推薦;Feng 等[18]將社會(huì)標(biāo)簽系統(tǒng)建模為多類型圖,通過(guò)學(xué)習(xí)圖中節(jié)點(diǎn)和邊的權(quán)重來(lái)推薦標(biāo)簽;Fang 等[19]提出了一種新的個(gè)性化標(biāo)簽推薦方法,該方法可視為典型張量分解的非線性擴(kuò)展;Zhao 等[20]將標(biāo)簽數(shù)據(jù)中的關(guān)系建模為異構(gòu)圖,并提出了一個(gè)標(biāo)簽推薦的排序算法框架。
與基于協(xié)同過(guò)濾的方法相比,基于內(nèi)容的方法是將內(nèi)容作為輸入,因此可以用于為新內(nèi)容推薦標(biāo)簽,從而避免基于協(xié)同過(guò)濾方法的冷啟動(dòng)問(wèn)題。典型的基于內(nèi)容的標(biāo)簽推薦技術(shù)是使用主題模型推薦標(biāo)簽。Krestel 等[7]使用LDA,利用主題分布找出與目標(biāo)資源具有相同主題的資源的標(biāo)簽作為擴(kuò)展標(biāo)簽集;Si 等[21]提出了一種基于擴(kuò)展LDA 的標(biāo)簽推薦方法,該模型通過(guò)在生成過(guò)程中添加標(biāo)簽變量來(lái)擴(kuò)展LDA 模型;Ding等[22]提出了一種針對(duì)微博推薦標(biāo)簽的主題翻譯模型,該模型將標(biāo)簽推薦建模為從內(nèi)容到標(biāo)簽的翻譯過(guò)程;Godin等[23]設(shè)計(jì)和實(shí)現(xiàn)了基于樸素貝葉斯技術(shù)的二進(jìn)制分類器,該分類器區(qū)分英語(yǔ)和非英語(yǔ)推文來(lái)推薦標(biāo)簽。
基于深度語(yǔ)義的方法通過(guò)基于深度神經(jīng)網(wǎng)絡(luò)的模型學(xué)習(xí)文本表示以捕獲文本內(nèi)容,然后將該文本表示分類給不同的標(biāo)簽用來(lái)實(shí)現(xiàn)標(biāo)簽推薦。Weston 等[12]提出了一種基于CNN的推薦模型,該模型將單詞以及整個(gè)文本內(nèi)容表示嵌入在CNN 體系結(jié)構(gòu)的中間層中以學(xué)習(xí)語(yǔ)義嵌入;Gong 等[24]采用了具有注意力機(jī)制的CNN 模型來(lái)執(zhí)行標(biāo)簽推薦任務(wù);Li 等[25]利用基于主題注意力的長(zhǎng)短時(shí)記憶(Topical attention-based Long Short-Term Memory,TLSTM)神經(jīng)網(wǎng)絡(luò)進(jìn)行標(biāo)簽推薦;Huang 等[26]在文獻(xiàn)[24]和文獻(xiàn)[25]的基礎(chǔ)上,提出了一種基于注意力機(jī)制的記憶網(wǎng)絡(luò)的標(biāo)簽推薦模型,用記憶網(wǎng)絡(luò)代替CNN 和LSTM 進(jìn)行標(biāo)簽推薦;Li 等[27]提出了一種將CNN 和長(zhǎng)短時(shí)記憶(Long Short-Term Memory,LSTM)網(wǎng)絡(luò)相結(jié)合的標(biāo)簽推薦模型;Tang 等[28]采用了具有注意力機(jī)制的門(mén)控循環(huán)單元(Gated Recurrent Unit,GRU)模型,同時(shí)建模文本內(nèi)容和標(biāo)簽進(jìn)行標(biāo)簽推薦;Shi等[29]提出了一種基于注意力機(jī)制的雙向長(zhǎng)短時(shí)記憶網(wǎng)絡(luò)(Bi-directional LSTM,Bi-LSTM)標(biāo)簽推薦模型。從這些研究結(jié)果來(lái)看,更準(zhǔn)確地獲取文本隱含語(yǔ)義信息有助于促進(jìn)標(biāo)簽推薦的準(zhǔn)確性。然而,許多真實(shí)數(shù)據(jù)集是以圖或者網(wǎng)絡(luò)形式出現(xiàn)的。圖是一種特殊的數(shù)據(jù)格式,可以用來(lái)表示現(xiàn)實(shí)世界中的各種網(wǎng)絡(luò)信息。在圖中,節(jié)點(diǎn)由邊連接,通過(guò)深度學(xué)習(xí)模型可以將圖中的節(jié)點(diǎn)映射到向量空間中,充分挖掘向量空間中的節(jié)點(diǎn)進(jìn)行分類。然而,到目前為止,很少有研究關(guān)注將圖卷積神經(jīng)網(wǎng)絡(luò)應(yīng)用于標(biāo)簽推薦,以充分挖掘文本中的詞與文本本身之間的隱含網(wǎng)絡(luò)結(jié)構(gòu)信息,進(jìn)一步提升標(biāo)簽推薦的性能。
最近,Yao 等[30]利用圖卷積神經(jīng)網(wǎng)絡(luò)進(jìn)行文本分類。受此啟發(fā),本文提出了一種融合文本間網(wǎng)絡(luò)結(jié)構(gòu)信息和文本內(nèi)容的方法,該方法采用的標(biāo)簽推薦模型為G-RNN 模型。與以往的工作相比,G-RNN 模型在RNN 提取文本內(nèi)容信息的基礎(chǔ)上通過(guò)注意力機(jī)制結(jié)合了使用GCN 提取的文本間的網(wǎng)絡(luò)結(jié)構(gòu)信息,使用更豐富的文本信息挖掘標(biāo)簽,能夠有效提升推薦標(biāo)簽的準(zhǔn)確度。
2 自動(dòng)標(biāo)簽推薦方法
圖1 為本文提出的自動(dòng)標(biāo)簽推薦方法采用的標(biāo)簽推薦模型G-RNN,表1為本文常用符號(hào)及其說(shuō)明。
2.1 問(wèn)題定義
本文將標(biāo)簽推薦任務(wù)作為多分類問(wèn)題進(jìn)行處理。為更好地提取特征進(jìn)行文本表示,本文考慮了注意力機(jī)制,并提出了一種融合網(wǎng)絡(luò)結(jié)構(gòu)信息和文本內(nèi)容信息的標(biāo)簽推薦方法。
通常,語(yǔ)料庫(kù)中全部文本可以表示為D={d1,d2,…,di,…,d|D|},其中|D|指語(yǔ)料庫(kù)中包含的文本數(shù)量;語(yǔ)料庫(kù)中全部詞匯可以表示為W={w1,w2,…,wi,…,w|W|},其中|W|語(yǔ)料庫(kù)中包含的詞匯數(shù)量;單個(gè)文本內(nèi)容可以表示為其中wi指文本的第i個(gè)詞匯,|di|指文本包含的詞匯數(shù)目。對(duì)于一個(gè)新文本,標(biāo)簽推薦的任務(wù)是為這個(gè)新文本推薦功能語(yǔ)義相近的標(biāo)簽。本文提出的標(biāo)簽推薦模型由三部分組成:1)文本間網(wǎng)絡(luò)結(jié)構(gòu)信息提取。本文首先將文檔與詞匯作為節(jié)點(diǎn)構(gòu)建文本異構(gòu)圖,使用GCN 捕獲高階鄰域信息,從而獲取文本間網(wǎng)絡(luò)結(jié)構(gòu)信息。2)文本內(nèi)容信息提取。本文使用四種不同的RNN 變體對(duì)文本內(nèi)容中的隱藏信息(如詞序信息、上下文信息等)進(jìn)行編碼提取特征。3)注意力機(jī)制。本文使用注意力機(jī)制將文本網(wǎng)絡(luò)結(jié)構(gòu)信息與文本內(nèi)容信息相融合,通過(guò)softmax層獲取最終的推薦標(biāo)簽。
這三個(gè)部分的基礎(chǔ)是每個(gè)單詞都被表示為低維、連續(xù)的實(shí)值向量,也稱為單詞嵌入[31-32]。所有詞向量都堆疊在詞嵌入矩陣其中R 表示實(shí)數(shù)集向量空間,dim是詞向量的維數(shù),xi是wi對(duì)應(yīng)的詞向量。使用嵌入學(xué)習(xí)算法對(duì)來(lái)自文本語(yǔ)料庫(kù)的單詞向量的值進(jìn)行預(yù)訓(xùn)練,以更好地利用單詞的語(yǔ)義和語(yǔ)法關(guān)聯(lián)信息[32]。給定文本內(nèi)容,對(duì)文本中每個(gè)詞進(jìn)行嵌入,得到輸入層向量。為保證文本向量輸入長(zhǎng)度一致,設(shè)定單個(gè)文本最長(zhǎng)文本長(zhǎng)度為N,文本di可用(x1,x2,…,xN)表示。

圖1 G-RNN模型Fig.1 G-RNN model

表1 常用符號(hào)及其含義Tab.1 Common symbols and their meanings
2.2 文本間網(wǎng)絡(luò)結(jié)構(gòu)信息提取
語(yǔ)料庫(kù)中文本間網(wǎng)絡(luò)結(jié)構(gòu)信息的提取主要是基于文檔及文檔間詞共現(xiàn)信息構(gòu)建異構(gòu)文本圖,通過(guò)GCN 實(shí)現(xiàn)建模。本節(jié)將分為兩步介紹該過(guò)程:第一步,構(gòu)建異構(gòu)文本圖;第二步,使用GCN對(duì)異構(gòu)文本圖進(jìn)行建模計(jì)算獲取文檔嵌入向量。
2.2.1 異構(gòu)文本圖構(gòu)建
該部分將介紹如何從語(yǔ)料庫(kù)中構(gòu)建異構(gòu)文本圖。具體任務(wù)為,給定語(yǔ)料庫(kù)D,構(gòu)建異構(gòu)圖G=(V,E),其中V是圖的節(jié)點(diǎn)集合,E是圖的邊集合。節(jié)點(diǎn)指文檔以及語(yǔ)料庫(kù)中去重后的全部詞匯,邊是基于文本間詞的共現(xiàn)和整個(gè)語(yǔ)料庫(kù)中詞的共現(xiàn)來(lái)構(gòu)建的,其中文檔與共現(xiàn)詞進(jìn)行連接,共現(xiàn)詞與共現(xiàn)詞之間進(jìn)行連接。文檔節(jié)點(diǎn)和單詞節(jié)點(diǎn)之間的邊的權(quán)重是文檔中該詞的TF-IDF 值,其中詞頻(TF)為單詞在文檔中出現(xiàn)的次數(shù),逆文檔頻率(IDF)是包含該詞的文檔數(shù)量的倒數(shù)的對(duì)數(shù)。為了更好地收集全局詞共現(xiàn)信息,本文對(duì)語(yǔ)料庫(kù)中的所有文檔使用固定大小的滑動(dòng)窗口收集信息。單詞節(jié)點(diǎn)與單詞節(jié)點(diǎn)之間的邊的權(quán)重使用點(diǎn)互信息(Point-wise Mutual Information,PMI)來(lái)計(jì)算。任意節(jié)點(diǎn)i與節(jié)點(diǎn)j之間的邊的權(quán)值定義為:

其中:#S(i)是語(yǔ)料庫(kù)中包含單詞i的滑動(dòng)窗口的數(shù)量;#S(i,j)是包含單詞i和j的滑動(dòng)窗口的數(shù)量;#S是語(yǔ)料庫(kù)中滑動(dòng)窗口的總數(shù)。正PMI 值意味著語(yǔ)料庫(kù)中單詞的高語(yǔ)義相關(guān)性,而負(fù)PMI 值表示語(yǔ)料庫(kù)中很少或沒(méi)有語(yǔ)義相關(guān)性。因此,本文僅在PMI為正值的詞對(duì)之間添加邊。
2.2.2 圖編碼器
Kipf等[16]在2017 年提出的GCN 是一個(gè)多層神經(jīng)網(wǎng)絡(luò),它是對(duì)圖形結(jié)構(gòu)數(shù)據(jù)的傳統(tǒng)卷積算法的變體。它直接對(duì)圖進(jìn)行操作,并根據(jù)節(jié)點(diǎn)的鄰域?qū)傩詺w納出節(jié)點(diǎn)的嵌入向量。
在構(gòu)建了異構(gòu)文本圖后,可獲取到異構(gòu)圖的鄰接矩陣A及其度矩陣M,其中由于節(jié)點(diǎn)自循環(huán),A的對(duì)角線元素為1。同時(shí)本文將特征矩陣設(shè)置為單位矩陣I。將鄰接矩陣A與特征矩陣送入兩層GCN 中進(jìn)行建模和卷積運(yùn)算,形成詞和文檔的嵌入表示向量,第二層的節(jié)點(diǎn)嵌入與標(biāo)簽集的大小相同。

2.3 文本內(nèi)容信息提取
一般而言,局部序列特征的提取是對(duì)文本進(jìn)行編碼,將文本中嵌入的一系列單詞轉(zhuǎn)換成固定的二維向量的過(guò)程。有許多研究使用RNN 的變體[13,27-29]來(lái)進(jìn)行文本編碼。GCN 可以有效地提取全局特征,而RNN 的變體(如LSTM、Bi-LSTM、GRU、Bi-GRU)適合對(duì)文本進(jìn)行編碼提取局部序列特征。因此,本文將使用RNN 的四個(gè)變體對(duì)文本進(jìn)行編碼提取局部序列特征。
本文首先通過(guò)預(yù)訓(xùn)練得到給定文本(x1,x2,…,xN),使用三層RNN 的變體按順序進(jìn)行序列建模。RNN 的變體按順序?qū)ζ溥M(jìn)行處理,獲取到所有的隱藏向量[h1,h2,…,hN]。
1)基于LSTM的序列編碼器。
LSTM[33]在每個(gè)單元使用輸入門(mén)、遺忘門(mén)和輸出門(mén)來(lái)控制信息沿著序列的傳遞。文本中每個(gè)單詞按序列分別輸入到一個(gè)LSTM 單元。對(duì)于t時(shí)刻LSTM 單元的輸入xt,給定t-1 時(shí)刻的輸出ht-1和單元狀態(tài)ct-1,LSTM 單元使用輸入門(mén)gt,遺忘門(mén)ft,輸出門(mén)ot和描述當(dāng)前輸入的單元狀態(tài)獲取到t時(shí)刻的輸出ht和單元狀態(tài)ct。在對(duì)文本進(jìn)行編碼時(shí),t時(shí)刻的LSTM單元的更新公式如下所示:

其中:σ為sigmoid函數(shù);Wg、Wf、Wc和Wo是加權(quán)矩陣,而bg、bf、bc和bo是偏移量。
2)基于Bi-LSTM的序列編碼器。
Bi-LSTM 是基于眾所周知的LSTM 模型[33]開(kāi)發(fā)的雙向神經(jīng)網(wǎng)絡(luò)。一個(gè)Bi-LSTM單元包含兩個(gè)LSTM單元,用于捕獲文本中的前向和后向信息。在本文中,t-1 時(shí)刻的前向LSTM單元的輸出記為,t-1 時(shí)刻的后向LSTM 單元的輸出記為。因此,t時(shí)刻的Bi-LSTM單元的更新公式如下所示:

3)基于GRU的序列編碼器。
GRU[34]在每個(gè)單元使用重置門(mén)、更新門(mén)來(lái)控制信息沿著序列的傳遞。同LSTM 的序列編碼器一樣,文本中每個(gè)單詞分別輸入到一個(gè)GRU 單元。對(duì)于t時(shí)刻GRU 單元的輸入xt,給定t-1 時(shí)刻的輸出ht-1,GRU 使用重置門(mén)rt,更新門(mén)zt和當(dāng)前時(shí)刻待輸入的隱藏狀態(tài)信息獲取到t時(shí)刻的輸出ht。在對(duì)文本進(jìn)行編碼時(shí),t時(shí)刻的GRU的更新公式如下所示:

其中:σ為sigmoid 函數(shù);Wr、Wz、Wh~是加權(quán)矩陣,而br、bz、bh~是偏移量。
4)基于Bi-GRU的序列編碼器。
Bi-GRU 是基于眾所周知的GRU 模型[34]開(kāi)發(fā)的雙向神經(jīng)網(wǎng)絡(luò)。一個(gè)Bi-GRU 單元包含兩個(gè)GRU 單元,用于捕獲文本中的前向和后向信息。在本文中,t-1 時(shí)刻的前向GRU 單元的輸出記為時(shí)刻的后向GRU 單元的輸出記為因此,t時(shí)刻的Bi-GRU單元的更新公式如下所示:

綜上所述,RNN 層可得到文本序列隱藏向量序列[h1,h2,…,hN]。
2.4 注意力機(jī)制
本文引入了注意力機(jī)制對(duì)網(wǎng)絡(luò)結(jié)構(gòu)信息和文本內(nèi)容信息進(jìn)行整合。給定文本di,使用GCN 獲取到矩陣F2中對(duì)應(yīng)文本di的文檔嵌入向量θdi∈RK×1,K為語(yǔ)料庫(kù)中標(biāo)簽數(shù)量,使用RNN 按順序?qū)ξ谋綿i進(jìn)行處理,獲取到所有的隱藏向量[h1,h2,…,hN]。注意力層將為每個(gè)文本連續(xù)輸出向量vec∈Rμ×1。輸出向量為每個(gè)隱藏狀態(tài)hj的加權(quán)和:

其中:μ為RNN 隱藏層維數(shù);Wa∈Rμ×K,Ua∈Rμ×μ和la∈Rμ×1是權(quán)重矩陣;aj∈[0,1]是hj的注意力權(quán)重且1。
接下來(lái)將輸出向量vec=[v1,v2,…,vK]饋送到線性層,該線性層的輸出長(zhǎng)度為所有標(biāo)簽的數(shù)量。通過(guò)softmax 層輸出選出概率高標(biāo)簽作為推薦標(biāo)簽:

本文將標(biāo)簽推薦建模為多分類任務(wù),通過(guò)最小化標(biāo)簽分類的交叉熵誤差,以監(jiān)督的方式訓(xùn)練模型。損失函數(shù)如下:

其中:Y是訓(xùn)練集;y和T是訓(xùn)練集文檔及其對(duì)應(yīng)標(biāo)簽集;Ti是正在預(yù)測(cè)的當(dāng)前標(biāo)簽;p(Ti|y)是為輸入文檔y選擇標(biāo)簽Ti的概率。
3 實(shí)驗(yàn)與結(jié)果分析
將本文方法中的標(biāo)簽?zāi)P虶-RNN 應(yīng)用于標(biāo)簽推薦任務(wù)以評(píng)估性能。
3.1 數(shù)據(jù)集
本文實(shí)驗(yàn)使用了三個(gè)數(shù)據(jù)集:Math(Mathematics Stack Exchange)、AU(Ask Ubuntu)和SO(Stack Overflow)。所有數(shù)據(jù)集均已正式發(fā)布并公開(kāi)可用(https://archive.org/details/stackexchange)。每個(gè)數(shù)據(jù)集包含多個(gè)帖子,每個(gè)帖子包含一段文本內(nèi)容(標(biāo)題和正文)以及相應(yīng)的標(biāo)簽。實(shí)驗(yàn)對(duì)數(shù)據(jù)集執(zhí)行以下預(yù)處理步驟。首先,刪除所有標(biāo)點(diǎn)符號(hào),然后將其余的字符串拆分為單個(gè)單詞,進(jìn)行去除停用詞和詞干還原處理。其次,刪除文本內(nèi)容中的一些低頻詞以減少噪聲,計(jì)算每個(gè)單詞的頻率并將詞匯表中每個(gè)數(shù)據(jù)集的最頻繁出現(xiàn)的單詞保留在詞匯表中。最后,由于很少使用低頻標(biāo)簽,因此同時(shí)對(duì)標(biāo)簽的頻率進(jìn)行計(jì)數(shù),并保留最常用的標(biāo)簽。本文隨機(jī)選擇AU數(shù)據(jù)集和SO 數(shù)據(jù)集的一個(gè)子集,AU、SO、Math 分別包含65 653、57 984、64 983 篇帖子,18 508、22 730、26 214 個(gè)去重詞匯,71 030、69 117、78 200 個(gè)節(jié)點(diǎn),600、200、717 個(gè)標(biāo)簽。對(duì)于每個(gè)真實(shí)數(shù)據(jù)集,隨機(jī)選擇80%的數(shù)據(jù)作為訓(xùn)練集,并在訓(xùn)練集中隨機(jī)選擇10%的數(shù)據(jù)作為驗(yàn)證集,其余的20%作為測(cè)試集,詳細(xì)數(shù)據(jù)集信息匯總?cè)绫?所示。

表2 數(shù)據(jù)集詳細(xì)信息Tab.2 Detail information of datasets
3.2 評(píng)測(cè)標(biāo)準(zhǔn)
本文采用準(zhǔn)確率、召回率以及F1值對(duì)本文方法的效果進(jìn)行評(píng)估。
準(zhǔn)確率表示推薦的標(biāo)簽集中相關(guān)標(biāo)簽所占的比例,其計(jì)算如下所示:

其中:@k表示推薦的標(biāo)簽個(gè)數(shù);tagλk表示推薦的標(biāo)簽集合;tagλdi表示文本di真實(shí)標(biāo)簽集合。
召回率表示推薦的相關(guān)標(biāo)簽占所有相關(guān)標(biāo)簽的比例,其計(jì)算如下所示:

F1 值融合了召回率和準(zhǔn)確率,是它們兩者的調(diào)和平均值,其計(jì)算如下所示:

3.3 基線和實(shí)驗(yàn)設(shè)置
3.3.1 基線方法
實(shí)驗(yàn)選擇以下基線方法進(jìn)行比較:
1)Maxide[35]。該方法使用傳統(tǒng)的矩陣補(bǔ)齊模型對(duì)文本內(nèi)容進(jìn)行建模推薦標(biāo)簽,是一種傳統(tǒng)的標(biāo)簽推薦多標(biāo)簽學(xué)習(xí)方法。
2)TagSpace[12]。該方法使用CNN 對(duì)文本內(nèi)容信息建模得到文本的嵌入表示,通過(guò)標(biāo)簽得分函數(shù)對(duì)候選標(biāo)簽進(jìn)行排序得到推薦標(biāo)簽。
3)LSTM[25]。該方法使用LSTM 對(duì)文本內(nèi)容信息進(jìn)行建模得到隱藏向量,添加softmax 層以輸出所有候選標(biāo)簽的推薦概率分布。
4)TLSTM[25]。該方法將LSTM模型的隱藏向量與LDA模型得到的主題向量通過(guò)注意力機(jī)制進(jìn)行結(jié)合,添加softmax 層以輸出所有候選標(biāo)簽的推薦概率分布。
5)GCN[30]。該模型直接使用GCN 進(jìn)行標(biāo)簽推薦,將文檔節(jié)點(diǎn)的特征向量視為文檔向量,添加softmax 層以輸出所有候選標(biāo)簽的推薦概率分布。注意,該模型并未對(duì)文本內(nèi)容進(jìn)行建模。
6)G-LSTM。本文提出的G-RNN 模型的第一個(gè)變體,本文將GCN 層的文檔嵌入向量與LSTM 最后一層的隱藏向量通過(guò)注意力機(jī)制進(jìn)行結(jié)合,添加softmax 層以輸出所有候選標(biāo)簽的推薦概率分布。
7)G-BiLSTM。本文將GCN 層的文檔嵌入向量與Bi-LSTM 最后一層的隱藏向量通過(guò)注意力機(jī)制進(jìn)行結(jié)合,添加softmax層以輸出所有候選標(biāo)簽的推薦概率分布。
8)G-GRU。本文將GCN 層的文檔嵌入向量與GRU 最后一層的隱藏向量通過(guò)注意力機(jī)制進(jìn)行結(jié)合,添加softmax 層以輸出所有候選標(biāo)簽的推薦概率分布。
9)G-BiGRU。本文將GCN 層的文檔嵌入向量與Bi-GRU最后一層的隱藏向量通過(guò)注意力機(jī)制進(jìn)行結(jié)合,添加softmax層以輸出所有候選標(biāo)簽的推薦概率分布。
3.3.2 實(shí)驗(yàn)設(shè)置
本文使用了兩層GCN[16]和三層RNN[28]。對(duì)于GCN部分,設(shè)置第一個(gè)卷積層的嵌入大小為300,滑動(dòng)窗口大小為20。對(duì)于RNN 部分,將最大文本長(zhǎng)度設(shè)置為40,使用詞向量模型Word2Vec 對(duì)單詞進(jìn)行預(yù)訓(xùn)練,單詞嵌入維數(shù)設(shè)置為100。對(duì)于LSTM/GRU的神經(jīng)元,其隱藏狀態(tài)的維數(shù)設(shè)置為500。在訓(xùn)練模型時(shí),采用Adam 優(yōu)化器[36]進(jìn)行模型訓(xùn)練。為了防止過(guò)度擬合,將學(xué)習(xí)率設(shè)置為0.02,dropout 為0.5,損失權(quán)重為0,并在損失不再減少時(shí)停止訓(xùn)練過(guò)程。
實(shí)驗(yàn)平臺(tái)為Windows 10 系統(tǒng)下的PyCharm Community 2019,所有跟蹤實(shí)驗(yàn)均在配置為Intel Core i7-9750CPU,顯卡為NVIDIA GeForce GTX 1650Ti,內(nèi)存為16 GB 的計(jì)算機(jī)上完成,采用Keras深度學(xué)習(xí)框架。
3.4 性能評(píng)估
表3為不同模型在不同評(píng)價(jià)指標(biāo)下的性能比較,圖2~4對(duì)比顯示了使用GCN 和RNN 變體同時(shí)獲取網(wǎng)絡(luò)結(jié)構(gòu)信息和內(nèi)容信息進(jìn)行推薦的性能。

表3 不同模型在top-1、top-3、top-5下在三個(gè)數(shù)據(jù)集上的性能比較Tab.3 Performance comparison on three datasets by different models with top-1,top-3,top-5

圖2 各模型在三個(gè)數(shù)據(jù)集上的準(zhǔn)確率比較Fig.2 Precision comparison of different models on three datasets

圖3 各模型在三個(gè)數(shù)據(jù)集上的召回率比較Fig.3 Recall comparison of different models on three datasets

圖4 各模型在三個(gè)數(shù)據(jù)集上的F1值比較Fig.4 F1 comparison of different models on three datasets
從圖2~4 可以看出:本文提出的方法上在三個(gè)數(shù)據(jù)集上的總體性能優(yōu)于基線方法。在召回率指標(biāo)上,G-BiGRU 模型基于三個(gè)數(shù)據(jù)集較最優(yōu)基線方法平均提高了5.5%;在F1 值指標(biāo)上,G-BiGRU 模型基于三個(gè)數(shù)據(jù)集較最優(yōu)基線方法平均提高了5.2%。與三種評(píng)價(jià)標(biāo)準(zhǔn)最優(yōu)的基線進(jìn)行比較,在Math 數(shù)據(jù)集上,G-BiGRU 模型準(zhǔn)確率平均提高2.3%,召回率平均提高3.8%,F(xiàn)1 值平均提高7.0%;在AU 數(shù)據(jù)集上,G-BiGRU 模型召回率平均提高8.4%,F(xiàn)1 值平均提高3.8%;在SO數(shù)據(jù)集上,G-BiGRU模型召回率平均提高4.2%,F(xiàn)1值平均提高4.8%。總體上,G-BiGRU 模型的準(zhǔn)確率提高有限,原因是Math 數(shù)據(jù)集文本較長(zhǎng),可獲取更多的文本內(nèi)容信息,而其他兩個(gè)數(shù)據(jù)集文本較短,對(duì)文本信息的提取效果較差。G-BiGRU 模型的召回率提高較多,G-BiGRU 模型的F1 值較其他基線方法也都有提升。
從圖2~4還可看出:使用GCN 和Bi-GRU 結(jié)合的G-BiGRU模型整體性能最高。GCN和LSTM、GRU結(jié)合的G-LSTM 和GGRU 模型在融合文本間網(wǎng)絡(luò)結(jié)構(gòu)信息基礎(chǔ)上同時(shí)考慮了文本內(nèi)容信息,所以比單純使用GCN效果好。GCN和Bi-LSTM、Bi-GRU結(jié)合的G-BiLSTM 和G-BiGRU模型在融合網(wǎng)絡(luò)結(jié)構(gòu)信息基礎(chǔ)上同時(shí)考慮了文本內(nèi)容上下文信息,所以效果較好。由于Bi-GRU 單元較Bi-LSTM 單元更加簡(jiǎn)潔、高效和收斂速度更快,較GRU 單元更全面提取了文本的內(nèi)容信息,所以使用RNN 變體中的Bi-GRU 模型與GCN 模型相結(jié)合是推薦標(biāo)簽的理想選擇。
綜上所述,對(duì)于本文采用的3 種評(píng)估標(biāo)準(zhǔn),本文方法比其他基線方法效果好,原因是該方法同時(shí)使用了文本間網(wǎng)絡(luò)結(jié)構(gòu)信息和文本內(nèi)容信息,可以推薦更加準(zhǔn)確的標(biāo)簽。雖然TLSTM 使用LSTM 和LDA 同時(shí)提取文本的內(nèi)容的隱藏信息和主題信息來(lái)推薦標(biāo)簽,但是仍沒(méi)有考慮到文本與文本之前隱含的網(wǎng)絡(luò)結(jié)構(gòu)信息,而這些信息可以用來(lái)提高推薦的性能。雖然GCN 通過(guò)提取文本間網(wǎng)絡(luò)結(jié)構(gòu)信息來(lái)推薦標(biāo)簽,但是沒(méi)有考慮到文本內(nèi)容信息,而這些信息對(duì)于推薦性能的提高也是必不可少的。當(dāng)推薦標(biāo)簽個(gè)數(shù)逐漸增加時(shí),所有方法的召回率都不斷增加,這是因?yàn)橥扑]的真確標(biāo)簽數(shù)目越來(lái)越多,同時(shí),由于文本的真實(shí)標(biāo)簽數(shù)目有限,可以預(yù)測(cè)召回率隨著推薦標(biāo)簽個(gè)數(shù)的增多逐漸趨于穩(wěn)定。與此相反,基本上所有方法隨著標(biāo)簽個(gè)數(shù)的增加準(zhǔn)確率逐漸變小,這是因?yàn)橥扑]了越來(lái)越多的不準(zhǔn)確的標(biāo)簽。盡管本文模型在AU、SO 數(shù)據(jù)集上準(zhǔn)確率沒(méi)有超過(guò)每個(gè)基線模型,但是總體性能仍然非常令人滿意。這驗(yàn)證了融合網(wǎng)絡(luò)結(jié)構(gòu)信息和文本內(nèi)容信息在標(biāo)簽推薦中的有效性。
3.5 實(shí)例
為了更加清晰地體現(xiàn)實(shí)驗(yàn)的效果,首先,在測(cè)試數(shù)據(jù)集中隨機(jī)挑選一篇帖子,該帖子的題目為“Implementing and Enforcing Coding Standards”,正確標(biāo)簽為“c#,standards,coding-style”,使用具有代表性的基線TLSTM 模型和GCN 模型與本文最優(yōu)的變體模型G-BiGRU 模型分別對(duì)該帖子進(jìn)行標(biāo)簽推薦。
從表4 可以看出使用G-BiGRU 模型推薦出3 個(gè)正確標(biāo)簽,而TLSTM 模型和GCN 模型僅推薦出2 個(gè)正確標(biāo)簽。G-BiGRU 模型比TLSTM 模型和GCN 模型的效果好是因?yàn)镚-BiGRU 模型不僅使用了文本間的單詞共現(xiàn)信息,還同時(shí)使用了文本內(nèi)容信息。
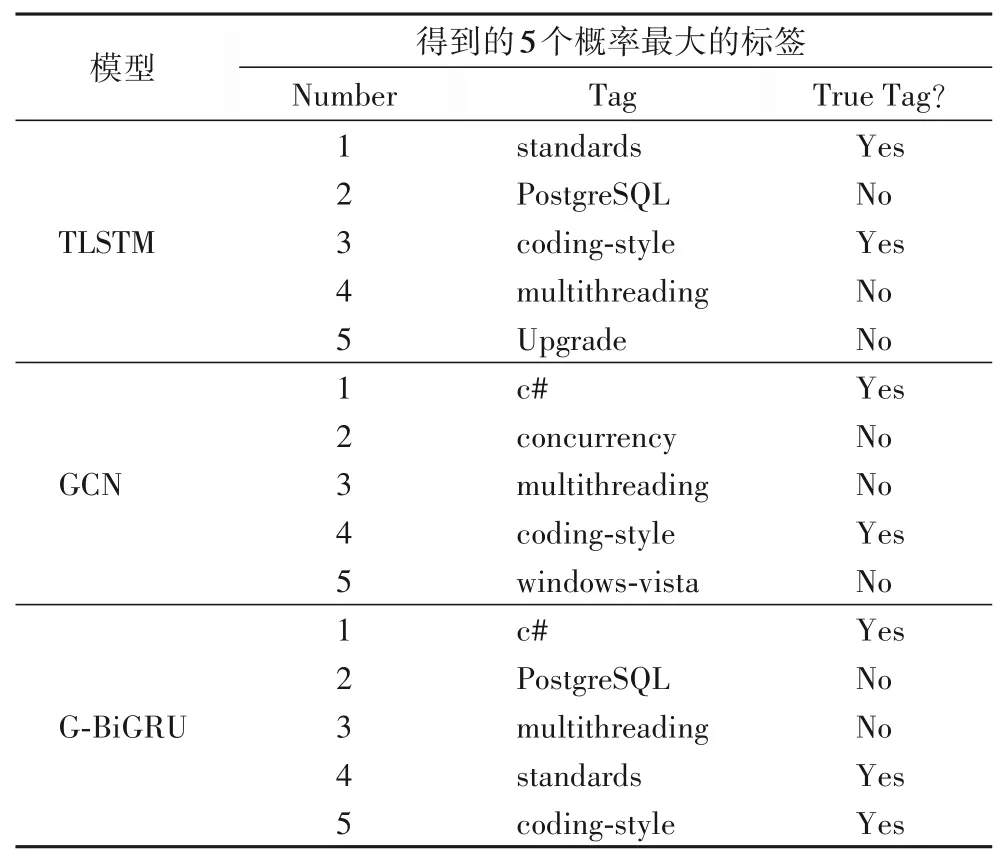
表4 對(duì)帖子推薦標(biāo)簽實(shí)例Tab.4 Examples of tag recommendation for a post
4 結(jié)語(yǔ)
本文提出了一種融合網(wǎng)絡(luò)結(jié)構(gòu)信息和文本內(nèi)容信息的標(biāo)簽推薦方法,該方法同時(shí)考慮了文本與文本之間的通過(guò)單詞共現(xiàn)信息可獲取到的隱藏網(wǎng)絡(luò)結(jié)構(gòu)信息和文本內(nèi)容的隱藏信息,并使用注意力機(jī)制結(jié)合兩種信息將標(biāo)簽推薦問(wèn)題轉(zhuǎn)化為一個(gè)多分類問(wèn)題。實(shí)驗(yàn)結(jié)果表明,同時(shí)考慮文本的網(wǎng)絡(luò)結(jié)構(gòu)信息和內(nèi)容信息可以有效地提高標(biāo)簽推薦的效果。目前的工作沒(méi)有考慮到標(biāo)簽與標(biāo)簽之間的語(yǔ)義聯(lián)系,因此,在未來(lái)將通過(guò)引入標(biāo)簽與標(biāo)簽之間的語(yǔ)義聯(lián)系或其他有用的輔助信息來(lái)進(jìn)行模型改進(jìn)。
猜你喜歡
科學(xué)大眾(2022年11期)2022-06-21 09:20:52
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
臺(tái)聲(2016年2期)2016-09-16 01:06:53
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
中外會(huì)展(2014年4期)2014-11-27 07:46:46
語(yǔ)文知識(shí)(2014年1期)2014-02-28 21:59:13
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
