基于SPSS 大學生創業環境指標體系構建與實證
2021-04-20 09:30:34高煥,諶悅
電子設計工程 2021年6期
高 煥,諶 悅
(西安職業技術學院生物工程學院,陜西西安 710077)
SPSS(Statistical Product and Service Solutions)結合了統計學分析運算、數據挖掘、預測分析和決策支持任務等功能[1],可以為用戶提供數據錄入、數據管理、統計分析運算、圖表分析、資料編輯、輸出管理、數據挖掘、預測分析等服務[2]。統計功能包括描述性統計、均值比較、一般線性模型、相關分析、回歸分析、方差分析、主成分分析和因子分析、卡方檢驗、t 檢驗和非參數檢驗、聚類分析、對數線性模型等[3-4],涵蓋了《教育統計學》中的所有項目。利用SPSS 軟件運用定性與定量相結合的方法[5-7],提升大學生創業環境評價精準度,有助于更好梳理創業環境指標體系中的薄弱點,有針對性地改善創業環境,激發學生創業意愿。
1 大學生創業環境指標體系
1.1 大學生創業環境指標體系構建需求分析
在大學生創業環境指標體系構建中,通過運用SPSS 軟件,可以收集影響大學生創業環境整體情況的因子,整理、檢驗因子數據,分析因子對大學生創業環境影響的顯著性等,確保該指標體系滿足用戶需求。用SPSS 統計分析軟件,構建大學生創業環境指標體系,提升大學生創業環境分析的精準性,提高工作效率,滿足指標體系構建需求。
1.2 大學生創業環境指標體系構建
1)大學生創業環境指標體系構建思路
該研究通過文獻研究法,對以往研究者關于創業環境的構成要素進行匯總梳理,對國內外創業環境構成要素進行對比,認為GEM 模型對創業環境的概括最全面,能夠較完整地反映影響大學生創業的各類環境要素[8-11]。基于此,該研究在參考GEM 模型基礎上,通過調研走訪,聽取專家相關意見,考慮指標體系設計的科學性、可實施性、全面性等原則,構建了大學生創業環境指標體系。
2)大學生創業環境指標體系設計
根據構建思路,該研究主要將指標體系劃分為4個層次,分別為目標層、系統層、準則層和指標層。
①目標層是對大學生創業環境總體情況的反映。
②系統層是在綜合參考GEM 模型基礎上構建而成的,具體包括資金環境、政策環境、市場環境、教育環境、文化環境5 個系統。
③準則層是在系統層基礎上的進一步細化,具體分為13 個層面,其中資金環境系統層細化為4 個層面,政策環境系統層細化為2 個層面,市場環境細化為2 個層面,教育環境細化為3 個層面,文化環境細化為2 個層面。
④指標層用來具體描述準則層,反映準則層情況,文中共遴選了具有代表性的25項具體指標。
1.3 大學生創業環境指標體系理論模型與研究設計
1)理論模型
該研究在GEM 基礎上構建了大學生創業環境指標體系,認為大學生創業總體環境由資金環境、政策環境、市場環境、教育環境、文化環境5 個環境指標要素構成,如表1 所示,并假設該指標體系能夠較準確反映大學生創業環境總體情況,提出了以下研究假設。
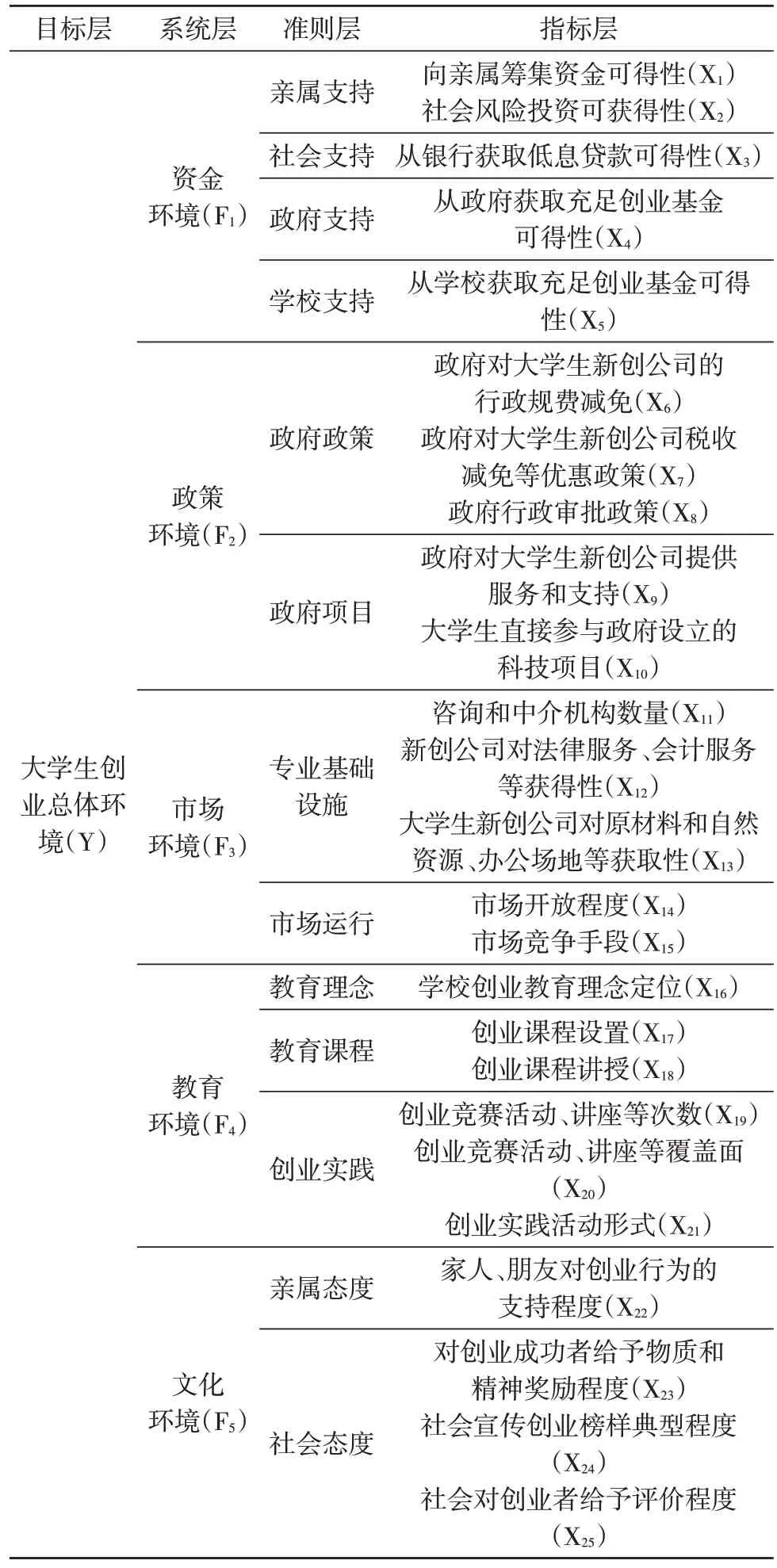
表1 大學生創業環境指標體系
①資金環境越充足,大學生創業總體環境越好。資金環境用來反映大學生在創業過程中能夠獲得金融支持的程度,包括政府撥款、家庭親屬贈予、創業資本、權益資本等創業資金來源。
②政策環境越寬松,大學生創業總體環境越好。政策環境主要用來反映政府對大學生創業的扶持力度,其內容包括政府政策與政府項目,諸如政府政策中涉及到的與創業有關的稅收優惠減免政策、財政扶持政策、行政規費減免等有利于創業的政策以及政府政策的具體化操作,比如大學生能否直接參與政府科技項目等。
③市場環境越好,大學生創業總體環境越好。市場環境主要用來反映大學生在創業過程中可以獲得的“軟件資源”和“硬件資源”,包括市場環境、獲取商業服務的可得性,獲得公共基礎設施、自然資源、交通設施、通訊設施的可得性等。
④教育環境越完善,大學生創業總體環境越好。教育環境主要用來反映大學生接受創業教育的情況,體現在大學生通過教育獲得的創業技能、創業思維等方面。
⑤文化環境越鼓勵創業,大學生創業總體環境越好。文化環境主要用來反映社會文化以及社會規范對大學生創業的態度,包括是否支持創業,以及對大學生創業成敗的評價等。
2)研究設計與變量說明
該研究所用的調查問卷是在之前構建的大學生創業總體環境指標體系的框架基礎上設計而成的。主要由三部分構成,分別是個人基本信息、大學生創業總體環境評價、大學生創業環境指標。在大學生創業總體環境評價和大學生創業環境指標下各設置了5 個肯定性題項,采用Likert 五星級量表記錄調查對象從“很差”到“很好”的評價態度,分別賦值1~5進行計分。
在研究過程中,共涉及6 個主要研究變量,其中大學生創業總體環境(Y)為因變量,資金環境(F1)、政策環境(F2)、市場環境(F3)、教育環境(F4)、文化環境(F5)為自變量。
2 大學生創業環境指標體系數據處理
2.1 搭建SPSS軟件應用平臺
對于大學生創業環境指標體系的設計,基于SPSS 軟件進行驗證、優化指標體系,其SPSS 軟件應用平臺如圖1 所示。
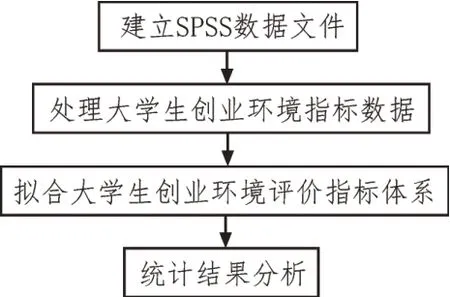
圖1 SPSS應用平臺
1)建立SPSS 數據文件:通過SPSS 讀取調研數據時,要注意利用SPSS 命令(TYPE 子命令、SHEEET 子命令、CELLRANGE 子命令、READNAMES 子命令)將數據表中的題目、變量名等信息排除在數據之外。讀取調研數據的命令語句如下:
GTE DATA
/TYPE=XLS
/FILE=調研數據儲存的根目錄
/SHEEET=NAME′大學生創業環境總體情況′
/CELLRANGE=RANGE′A2:AE′
/READNAMES=on.
2)處理大學生創業環境指標數據:通過SPSS 對調研數據進行信度和效度分析,使用因子分析法對調研數據進行主成分分析,利用因子分析的結果計算出主成分。
3)擬合大學生創業環境評價指標體系:通過SPSS,采用回歸分析法,檢驗大學生創業總體情況(Y)和資金環境(F1)、政策環境(F2)、市場環境(F3)、教育環境(F4)、文化環境(F5)之間的關系。
4)統計結果分析:通過模型擬合優度、回歸方程整體顯著性檢驗、系數顯著性檢驗來得出自變量對因變量的影響程度。
2.2 數據處理分析代碼實現
import pandas as pd
import seaborn as sns
from sklearn.linear_model import Linear Regression
import matplotlib.pyplot as plt
From sklearn.cross_validation import train_test_split
#通過read_csv 來讀取目的數據集
Dimensions_data=pd.read_csv("C:/Users/Administrator/Desktop/Dimensions.csv")
#清洗不需要的數據
new_Dimensions_data=Dimensions_data.ix[:,1:]
#得到所需要的數據集且查看其前幾列以及數據形狀
print(′head:′,new_Dimensions_data.head(),′ Shape:′,new_Dimensions_data.shape)
#數據描述
print(new_Dimensions_data.describe())
#缺失值檢驗
print(new_Dimensions_data[new_Dimensions_data.isnull()==True].count())
new_Dimensions_data.boxplot()
plt.savefig("boxplot.jpg")
plt.show()
##相關系數矩陣r(相關系數)=x 和y 的協方差/(x 的標準差*y 的標準差)==cov(x,y)/σx*σy
#相關系數:0~0.3 表示弱相關,0.3~0.6 表示中等程度相關,0.6~1 表示強相關
print(new_Dimensions_data.corr())
#建立散點圖來查看數據集里的數據分布
#seaborn 的pairplot 函數繪制X 的每一維度和對應Y 的散點圖。通過設置size 和aspect 參數來調節顯示的大小和比例。
# 通過加入一個參數kind='reg',seaborn 可添加一條最佳擬合直線和95%的置信帶。
sns.pairplot(new_Dimensions_data,x_vars=[′F1′,′F2′,′F3,″F4′,′F5′,′F6′,′F7′,′F8′,′F9′],y_vars=′environment′,size=7,aspect=0.8,kind=′reg′)
plt.savefig("pairplot.jpg")
plt.show()
#利用sklearn 對數據集進行劃分,以此來創建訓練集和測試集
#train_size 表示訓練集所占總數據集的比例
X_train,X_test,Y_train,Y_test=train_test_split(new_Dimensions_data.ix[:,:3],new_Dimensions_data.environment,train_size=.80)
print("原始數據特征:",new_Dimensions_data.ix[:,:9].shape,
",訓練數據特征:",X_train.shape,
",測試數據特征:",X_test.shape)
print("原始數據標簽:",new_Dimensions_data.environment.shape,
",訓練數據標簽:",Y_train.shape,
",測試數據標簽:",Y_test.shape)
model=Linear Regression()
model.fit(X_train,Y_train)
a=model.intercept_#截距
b=model.coef_#回歸系數
print("最佳擬合線:截距",a,",回歸系數:",b,")
#y=b0+b1X1+b2X2+b3X3+b4X4+b5X5
#R 方檢測
#決定系數r平方
#對于評估模型的精確度
#y 誤差平方和=Σ(y 實際值-y 預測值)^2
#y 的總波動=Σ(y 實際值-y 平均值)^2
#有多少百分比的y 波動沒有被回歸擬合線所描述=SSE/總波動
#有多少百分比的y 波動被回歸線描述=1-SSE/總波動=決定系數R 平方
#對于決定系數R 平方來說1)回歸線擬合程度:有多少百分比的y 波動刻印有回歸線來描述(x 的波動變化)
#2)值大小:R 平方越高,回歸模型越精確(取值范圍0~1),1 無誤差,0 無法完成擬合
score=model.score(X_test,Y_test)
print(score)
#對線性回歸進行預測
Y_pred=model.predict(X_test)
print(Y_pred)
plt.plot(range(len(Y_pred)),Y_pred,'b',label="predict")
#顯示圖像[12]
#plt.savefig("predict.jpg")
plt.show()
plt.figure()
plt.plot(range(len(Y_pred)),Y_pred,′b′,label="predict")
plt.plot(range(len(Y_pred)),Y_test,′r′,label="test")
plt.legend(loc="upper right")#顯示圖中的標簽
plt.x label("the number of environment")
plt.y label('value of environment')
plt.savefig("ROC.jpg")
plt.show()
3 大學生創業環境指標體系實證
為了檢驗該研究構建的大學生創業環境指標體系是否與實際調研數據一致,利用經過主成分分析處理后的調研數據對構建的大學生創業環境指標體系進行線性回歸[13-17]。
3.1 信度與有效度檢驗
KMO 檢驗和Bartlett 球度檢驗是因子分析前的檢驗,主要用來衡量問卷結構效度,判斷調查數據是否適合因子分析。該研究的檢驗結果KMO 均大于0.8,Bartlett 球度檢驗P值=0.000<0.05,如表2 所示。表明所選調研數據成球形分布,數據之間具有相關性,十分適合做因子分析。通過對大學生創業環境調查問卷的總體以及各指標進行可信度檢驗,Cronbach’s Alpha 系數均大于0.7,如表3 所示,表明該調查具有較好的內在一致性,可靠性較強。
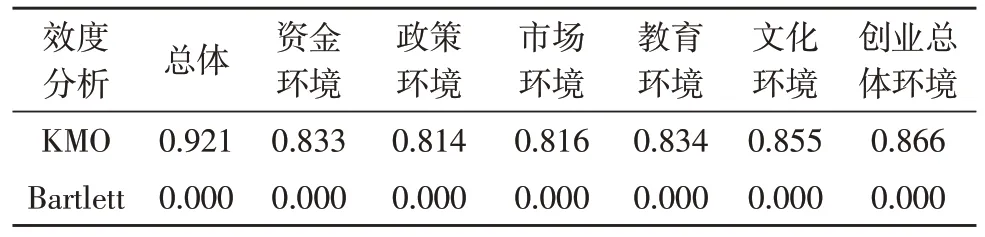
表2 KMO 和Bartlett 的檢驗

表3 可靠性統計量
3.2 創業環境指標對創業總體環境回歸分析
將經過主成分計算得分的5 個維度作為自變量,創業總體環境作為因變量,基于SPSS 軟件進行多元線性回歸分析[18-19],如表4 所示。
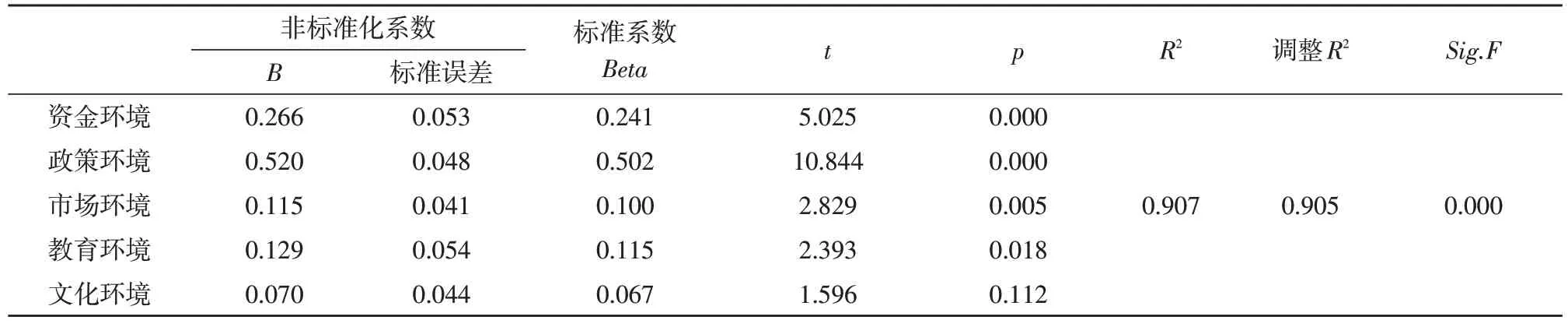
表4 線性回歸分析結果
3.3 研究結論
1)以創業環境指標的5 個維度為自變量,以創業總體環境為因變量進行回歸分析的結果顯示,回歸模型整體的解釋度較高,5 個維度可以解釋創業環境總體情況的90%的變差,設計的大學生創業環境評價指標體系模型與實際調研數據之間擬合度較好。因此,可以判定資金環境、政策環境、市場環境、教育環境以及文化環境能較好地反映大學生創業整體環境。但是仍有一部分因素未在研究中得到揭示,在今后的研究中需要更加全面考慮影響因素。
2)設計的大學生創業環境指標體系模型中,資金環境、政策環境、市場環境、教育環境以及文化環境的系數均為正值,符合研究預期,表明改善創業環境指標5個維度均有助于大學生創業環境總體情況的提升。但是,各維度對大學生創業環境總體情況的影響程度不同,其中資金環境、政策環境、市場環境、教育環境均對大學生創業環境總體情況的影響顯著,文化環境的影響未通過顯著性檢驗,對大學生創業環境總體情況的影響不顯著。
3)大學生創業環境總體情況是一個相對復雜的系統,影響創業環境總體情況的因素也有很多,隨著時代發展,創業環境評價指標體系也會不斷進行完善和改進,是一個開放發展的系統。
4 結束語
該研究基于GEM 模型構建了大學生創業環境指標體系,通過SPSS 軟件驗證了該體系能夠較為科學地反映大學生創業環境整體情況,有利于快速獲得大學生創業環境整體情況,有針對性地改善創業環境,從而提高了大學生創業的意愿和成功率。
猜你喜歡
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中國生殖健康(2020年6期)2020-02-01 06:28:50
新世紀智能(英語備考)(2019年12期)2020-01-13 06:07:18
下一代英才(酷炫少年)(2019年3期)2019-03-25 02:34:18
中國生殖健康(2019年11期)2019-01-07 01:28:02
中國生殖健康(2018年6期)2018-11-06 07:09:28
黃河之聲(2017年14期)2017-10-11 09:03:59
北方音樂(2017年7期)2017-05-16 00:32:46
教育與職業(2014年16期)2014-01-19 01:24:34
