基于機器學習的文本半自動類別標注方法
2021-04-26 08:20:24宮衍圣蔡科平王志強李鑫鑫靖穩峰
工程數學學報 2021年6期
宮衍圣, 蔡科平, 王志強, 李鑫鑫, 靖穩峰
(1. 中鐵第一勘察設計院集團有限公司,西安 710043; 2. 西安工業大學,西安 710021;3. 國網浙江省電力公司信息與通信分公司,杭州 310007;4. 西安交通大學數學與統計學院,西安 710049)
0 引言
數據標注是監督學習的一個重要環節。它是指對采集到的圖像、語音、文本等數據對象進行不同類別的標識,為數據分析或人工智能算法提供訓練數據。常見的數據標注任務包括類別標注、區域標注、描點標注等。類別標注是指從給定的標簽集中選擇合適的標簽分配給數據對象,通俗地說就是對所給定的圖像、語音或文本數據指定一個類別標簽,達到與其他數據區分的目的。
人工標注是進行數據標注的基本方法,標注人員需要熟悉領域專業知識才能實現正確標注。此種標注方法需要耗費大量的人力、財力,其效率低下。隨著機器學習技術的發展,使用機器學習輔助的半自動化數據標注方法不斷發展,成為大數據背景下更加常用的數據標注方法[1]。
本文提出了一種對數據科學與人工智能領域的文章進行半自動化標注的方法。首先應用爬蟲程序獲取了42034 篇數據科學與人工智能類的科技論文摘要數據,然后通過“構建領域語料庫–單詞向量化–文本向量化–文本聚類–提取當前類中關鍵主題特征詞–對主題詞進行人工歸納得到當前類標簽–訓練文本分類模型–應用訓練好的模型進行文章標注”。該方法大大提高了文章類別標注效率,可作為論文推薦系統的基本技術。新方法具有很好的遷移性能,可適用于多種自然語言處理任務中不同領域的文本信息類別標注。
1 文本自動化標注模型構建
1.1 文本向量表示
文本向量化是自然語言處理最基本的工作。文本向量化之前,需要獲取每個單詞的向量表示。本文基于爬蟲程序獲取的數據科學與人工智能類文章摘要構建領域語料庫,在此語料庫上使用Word2vec[2]、Paragraph2vec[3]和TF-IDF(Term Trequency-Inverse Document Frequency)等方法得到單詞的向量表示。
首先,從數據科學與人工智能類會議和期刊上通過網絡爬蟲技術獲取到42 034 篇論文的標題和摘要作為原始數據,然后對這些數據進行預處理,預處理過程包含大小寫轉換、去標點符號、去停用詞、詞干化等;接著,通過預處理之后的數據構建了針對數據科學與人工智能這一特定領域的語料庫;最后,將經過預處理之后的文本使用詞嵌入技術得到32 266 個單詞的詞向量表示,每個單詞用一個200 維的實數向量表示。
TF-IDF 詞向量表示方法包含詞頻TF 與逆文檔頻率IDF 兩部分,它認為一個單詞對于文本分類的重要性正比于其在單個文本中的頻數,反比于其在全部文檔中的頻數[4]。單詞w的詞頻和逆文檔頻率分別記為TFw和IDFw,其計算公式如下

在文本向量化階段,將TF-IDFw作為w的權重,對當前論文中所有Word2vec 加權求和,從而獲取單詞的向量表示,通過這樣的方法使得論文中不同重要程度的單詞發揮不同的作用,具體實現步驟如下。
設語料庫中的論文數據集合為{t1,t2,··· ,tM},詞匯表(字典)矩陣為D=[w1,w2,··· ,wN],其中wi是第i個單詞的Word2vec 向量
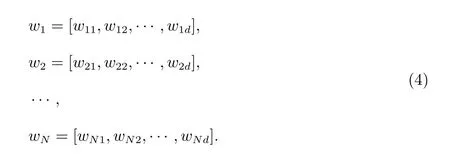

1.2 文本聚類
文本聚類是實現文本自動化標注的基礎,本文使用K-means 算法完成文本聚類。Kmeans 的聚類個數K值需事先確定,本文使用Robert 等人提出的Gap statistic 方法[5]選取最佳聚類簇數。K-means[6]初始聚類中心的選取使用K-means++算法[7]。本文使用Tadeusz Calinski 提出的CH 指標[8]衡量最終的文本聚類效果。
1.3 基于L1-LR 模型的類別主題詞分析
類別主題詞是能夠表示文章類別的關鍵詞。為了得到每一類論文的類別主題詞,本文采用帶有L1正則化的Logistic Regression 二分類模型–L1-LR 提取類別主題詞。
定義二元Logistic Regression 函數[9]

本文使用坐標軸下降法進行求解[9],具體求解步驟如下。
算法1L1-LR 二分類模型求解

輸入:M 個數據點xi =(xi1,xi2,··· ,xin), i=1,2,··· ,M,每個數據有n 個特征輸出:每個特征的權重參數絕對值|θi|排序步驟1:隨機初始化參數向量為θ(0);步驟2:對于第k(k ≥1)輪迭代,依次求θ(k)i , i=1,2,··· ,n,有θ(k)1 =argmin ),θ1 J(θ1,θ(k-1)2,··· ,θ(k-1)n θ(k)2 =argmin ),θ2 J(θ(k)1 ,θ2,θ(k-1)3,··· ,θ(k-1)n··· ,θ(k)n =argmin J(θ(k)θn 1 ,θ(k)2 ,··· ,θ(k)n-1,θn);步驟3:檢查θ(k)向量和θ(k-1)向量在各個方向上的收斂情況,如果θ(k)和θ(k-1)在所有的方向上都滿足收斂條件,那么θ(k)為最終結果,否則繼續轉入步驟2,開始第k+1 輪迭代。
2 文本自動類別標注方法
在上述工作的基礎上,本文提出一種有效的文本類別自動標注方法,詳細步驟如下。算法2 基于機器學習的文本自動類別標注

輸入:通過網絡爬蟲獲取的M 篇數據科學與人工智能領域相關論文摘要X ={x1,x2,··· ,xM}輸出:所有論文數據最終的類別劃分信息,包括類別數、每篇論文所屬類別
步驟1:對原始數據預處理,得到數據科學與人工智能領域語料庫,取出語料庫中頻數最高的2000 個單詞構成詞典D;
步驟2:在語料庫上訓練Word2vec 或Paragraph2vec 詞嵌入模型,將每個單詞表示成一個d維的實數向量,d一般取值200;
步驟3:選擇以下一種方式得到文本向量化表示矩陣T:
1) 文本中所有單詞的Word2vec 向量累加;
2) TF-IDF 矩陣×Word2vec 矩陣;
3) 文本中所有單詞的Paragraph2vec 向量累加;
4) TF-IDF 矩陣×Paragraph2vec 矩陣;步驟4:文本聚類:
1) 將T輸入Gap statiatic 算法中得到最佳聚類簇數K;
2) 將T和K輸入K-means 算法中完成聚類,其中初始質心的選取使用Kmeans++方法優化;
3) 使用CH 指標衡量聚類效果;步驟5:類別主題分析:1) 構建K個二分類數據集。數據集i:屬于第i類的樣本標記為正樣本,其余K-1 類樣本標記為負樣本;
2) 使用SMOTE 算法[10]均衡正負類樣本數據量;
3) 對數據集i,用L1-LR 二分類模型提取類別特征詞;步驟6:對K個L1-LR 二分類模型中模型變量對應的權重絕對值排序,在詞典D中選取絕對值最大的若干系數所對應的單詞作為主題詞,最后根據這些主題詞歸納得得到K個類論文的標簽。
3 實驗過程與結果分析
3.1 文本聚類實驗結果
1) Gap statistic
由于K-means 算法具有隨機性,每次運行Gap statistic 方法選出的最佳聚類簇數K可能不一樣,故將上文提到的4 種不同的文本表示方式作為聚類的輸入矩陣,分別通過Gap statistic 方法得到的最佳K值為20。
2) 文本向量化方式
本文對表1 中所列的4 種文本向量化的速度以及聚類效果進行了對比,從實驗結果中可以看出,單獨使用詞嵌入向量累加來表示文本的方式CH 指標雖略高于詞嵌入與TF-IDF 值加權求和的文本向量化方式,但在生成文本向量時,卻要付出高于700 多倍的時間。因此,本文綜合考慮聚類效果CH 指標值與生成文本向量表示的時間,最終選用Word2vec 詞嵌入與TF-IDF 值加權求和的方式進行文本表示。
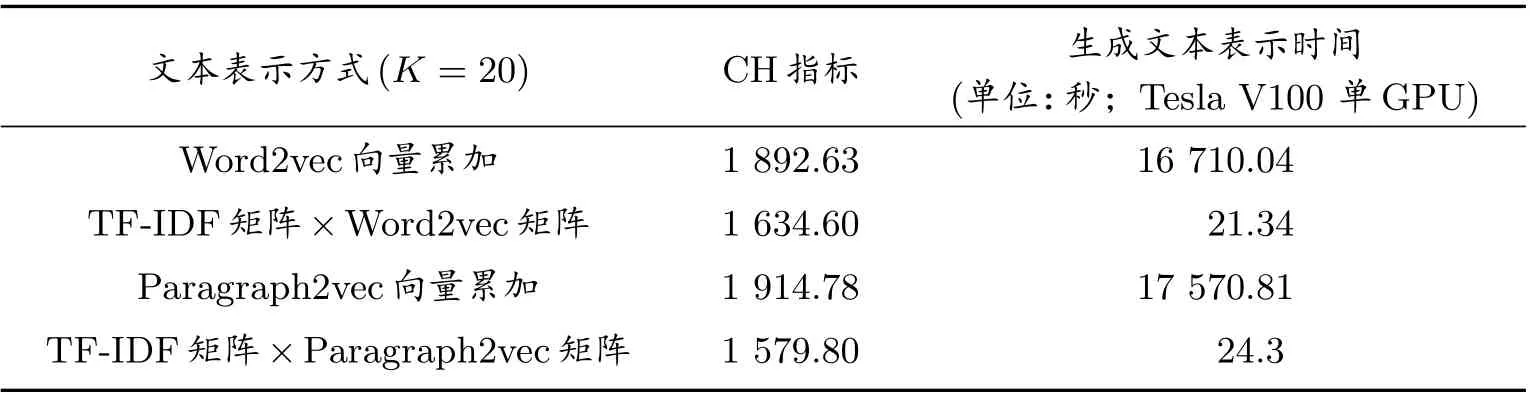
表1 不同的文本表示方法實驗結果對比
對算法進行時間復雜度分析,解釋文本向量化方式速度上的差異。已知字典D大小為N,文本集合T長度為M,文本平均長度為L,詞嵌入維度為d,詞嵌入矩陣W ∈RN×d,TF-IDF 稀疏矩陣F ∈RM×N,F的稀疏度為a=F中0 元個數/F中所有元素個數,a ∈[0,1],使用TF-IDF 值與Word2vec 詞嵌入向量加權求和的方式對文本進行向量表示,只需將稀疏矩陣F與矩陣W相乘即可實現,此方法的時間復雜度為O1=O(M×N+a×M×N×d);而使用詞嵌入向量累加的方式,對一個論文數據中的所有單詞,需遍歷詞嵌入矩陣找到其向量表示,再累加,所需時間復雜度為O2=O(L×M×N×d)?O1,這也從理論上驗證了實驗結果的準確性。
3) 文本聚類結果展示
表2 和表3 中分別展示了第0 類、第3 類中的部分文本標題,可以看到,通過本文提出的文本聚類算法,聚出來的文本幾乎均屬于同一類,對這些標題進行歸納,可以大致確定第0 類為強化學習、Q 學習相關類,第3 類為NLP(文本分類、機器翻譯、情感分析等)類,第9 類為CT/MRI 等醫學影像分析,對于剩下的類采取同樣方式進行歸納,這里不再一一列舉,之后再將這些結果與L1正則化結果對比分析,歸納出每一類論文的類別標簽。

表2 第0 類部分論文標題

表3 第3 類部分論文標題

續表
3.2 類別主題分析結果
1)L1-LR 二分類模型結果
圖1 至圖3 分別展示了使用SMOTE、Borderline-SMOTE 和ADASYN 方法的L1-LR 二分類模型在驗證集上的accuracy、precision、recall 和f1-score 結果值,可以看出:

圖1 基于SMOTE 上采樣的L1-LR 二分類結果
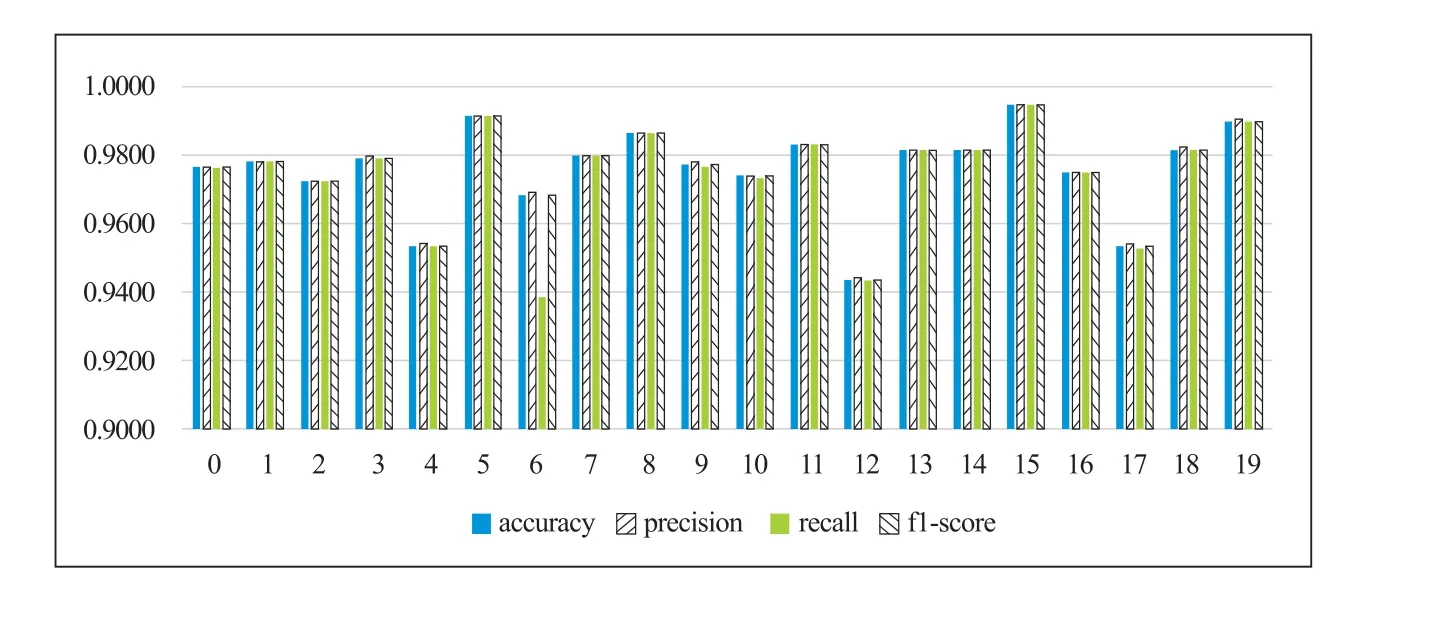
圖2 基于Borderline-SMOTE 上采樣的L1-LR 二分類結果
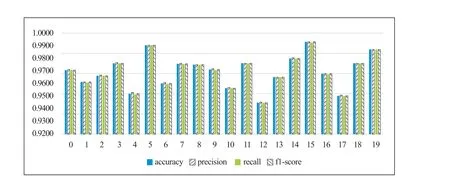
圖3 基于ADASYN 上采樣的L1-LR 二分類結果
(a) 三種采樣方式得到的結果基本一致;
(b) 20 個二分類任務的accuracy、precision、recall 和f1-score 值均高于0.94,訓練的二分類模型在驗證集上表現良好,無欠擬合或過擬合現象;
(c) 通過訓練好的L1-LR 二分類模型進行特征詞篩選完全可行。
2) 類別特征詞提取結果
每個二分類模型訓練完成后,會返回字典中所有單詞對應的L1權重值,將權重絕對值較大的特征詞挑選出來,隨機選取了其中6 類的結果展示在表4 中。這些特征詞對于所屬的二分類任務發揮了重要作用,說明可以用于區分當前類與非當前類,或者可以作為當前類的主題詞,或者可以作為其他類的主題詞,因此L1正則化特征詞選擇結果可以用于輔助論文數據類別標注工作。
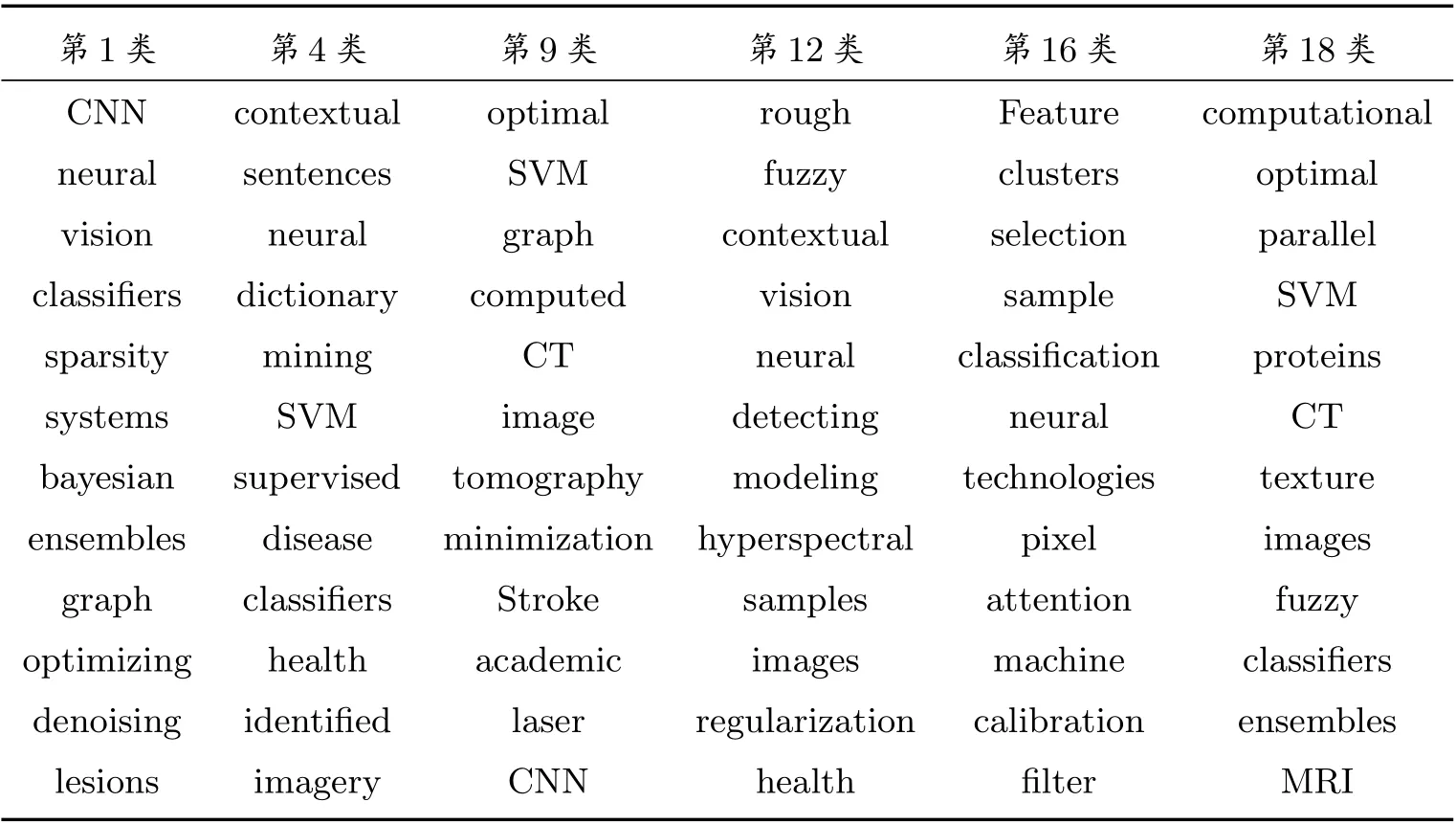
表4 L1 正則化特征詞提取結果展示
同時,本文在此部分做了對照實驗,使用經典TextRank 關鍵詞提取算法[11],對每一類中心的文本提取關鍵詞,作為這一類的主題詞,提取出來的關鍵詞見表5 所示。
從表5 中可以看出,TextRank 算法提取出的關鍵詞會將諸如data、model、method、result 等不具備明顯類別區分意義的詞匯篩選出來,原因在于使用此方法時,每一類中只用到了類中心一篇論文數據的信息,不具備說服力,效果自然很差。而表4 中L1正則化方法提取出來的絕大多數單詞,具備明顯的類別含義,可以作為類別的主題詞,因此本文最終選取L1-LR 模型提取類別特征詞。

表5 TextRank 關鍵詞算法提取結果
3.3 論文類別標注結果
綜合考慮文本聚類以及類別主題分析的實驗結果,本文實現了數據科學與人工智能類論文的類別標注,詳細結果展示在表6 中。
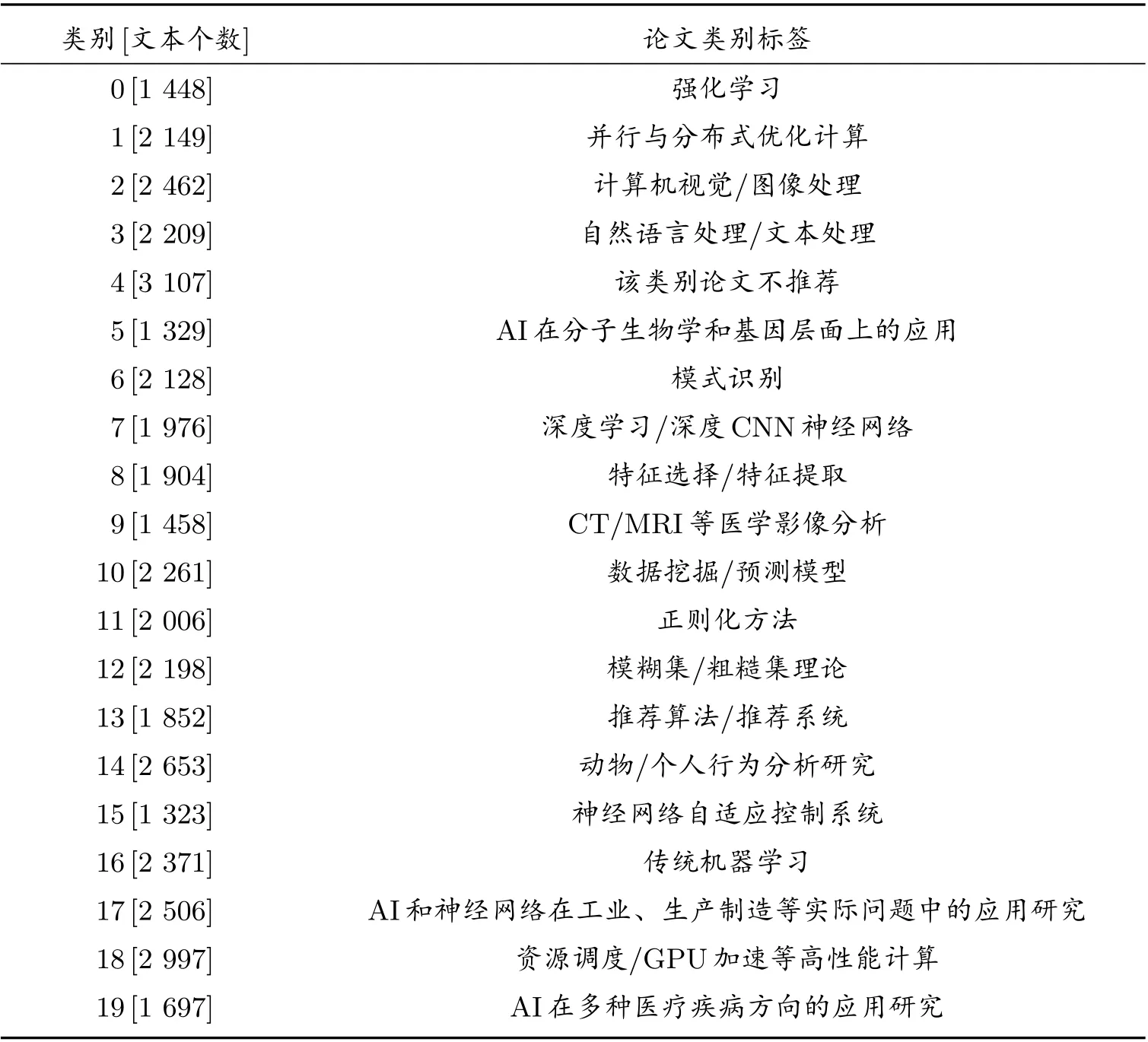
表6 論文類別標注結果
3.4 應用–數據科學與人工智能論文推薦系統
本文提出了一種基于機器學習方法的半自動論文類別標注算法,對42 034 篇數據科學與人工智能類的科技論文進行了類別標注。為驗證標注結果的有效性,同時也為了將本文所做工作應用到實際問題中,在得到了所有論文的類別之后,將其按一定比例劃分為訓練集與驗證集,構建文本分類器,并提出了一種基于文本分類的推薦算法,將其應用到數據科學與人工智能類科技論文推薦系統中。首先,通過分類器得到新論文的主題標簽;之后計算用戶輸入的查詢關鍵詞與論文類別之間的相似度完成論文的推薦,按相似度值排序,為用戶推薦最新發表的TOP20 篇論文。
使用BERT(Bidirectional Encoder Representations from Transformers)算法[12]構建文本分類器,得到了在驗證集上準確率最高的模型,部分結果展示在表7 中。

表7 文本分類實驗結果對比
對于BERT 模型中詞庫文件這一參數,在訓練模型時分別加載了BERT 源碼自帶的vocab.txt 文件;將語料庫中詞頻大于0.01,小于0.7 的單詞選出來共1 349 個構成本文專用詞庫my vocab.txt 文件;本文構建的領域語料庫中所有單詞構成的詞庫myall vocab.txt 文件這三個txt 文件來對比實驗結果。
從表7 展示的文本分類實驗結果中,可以得到以下結論:
1) 在訓練BERT 文本分類模型時,使用本文構建的專用詞庫或領域語料庫比使用BERT 自帶的詞匯表文件在驗證集上的表現更好;
2) 將本文得到的論文類別標注結果經過BERT 算法之后,通過一定的調參可以在驗證集上得到較高的準確率,能夠得到一個效果很好的文本分類器,可以實現基于文本分類的科技論文推薦,這也證明了本文提出的論文半自動類別標注算法具有有效性與實踐應用意義。
4 結論
本文提出了一種結合機器學習算法與人工輔助工作的半自動文本類別標注方法,并以42 034 篇數據科學與人工智能類的科技論文作為實驗數據,驗證了半自動類別標注方法的有效性與實際意義。本文提出的半自動文本類別標注方法在保證標注結果準確性的前提上,大大提高了工作效率;且論文類別標注結果構建了一個數據科學與人工智能領域論文分類的數據集,為相關方向的研究者提供了便利。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
小學教學參考(2015年20期)2016-01-15 08:44:38
語文知識(2014年1期)2014-02-28 21:59:13
