基于信息增益的管道堵塞聲學檢測方法?
2021-04-28 16:20:34朱雪峰吳建德
振動、測試與診斷 2021年2期
朱雪峰, 馮 早, 吳建德, 馬 軍
(1.昆明理工大學信息工程與自動化學院 昆明,650500)(2.昆明理工大學云南省人工智能重點實驗室 昆明,650500)
引言
供/排水管道是城市建設和社會發展的生命線,在管道運行狀態中,過載、疲勞、環境污染等因素會導致管道內部出現裂縫、堵塞、泄漏等功能性缺陷,進而降低管道的使用壽命。堵塞是管道運行中普遍存在的一種現象,管道出現輕微堵塞時,如果不能夠被及時發現并加以處理,隨時間的推移,堵塞面積不斷增大,最終形成嚴重堵塞。嚴重堵塞將降低管道的運載能力和系統的可靠性,增加環境污染的可能性和系統的冗余性,并且導致系統中部分管道超壓,增加泄漏的可能性,最終造成水資源的嚴重浪費和環境污染[1]。若輕微堵塞能夠被及時發現并加以處理,就能最大限度地減少嚴重堵塞和多重堵塞造成的損失。由于管道深埋于地下,使得對其運行狀態的評估具有復雜性和挑戰性。因此,埋地管道運行狀態的無損檢測,對保證管道正常運行的高效性與可靠性具有重要意義,是城市基礎設施維護的重點和難點[2]。
迄今為止,已出現聽音法、機器人檢測法等多種檢測方法,但都有一定的缺陷。聽音法的檢測結果嚴重依賴人工經驗。機器人檢測法是利用電荷藕合器件圖像傳感設備(charged coupled device,簡稱CCD)對管道內部進行檢測,設備的購置價格和維護費用過高,檢測效率低。然而,聲學檢測作為一種無損檢測方法,具有操作簡單、檢測范圍長、成本低及不嚴重依賴檢測人員的主觀性等優點,在檢測管道運行狀態中廣泛應用。但在實際檢測中,聲波經過聲阻抗不連續界面會發生不同程度的反射、折射、衍射等物理現象,造成在不同的頻率范圍內,聲波對管道的運行狀態敏感度不同。因此,回波信號在不同頻率范圍內攜帶的信息量不同,即不同頻率的分量特征權重各異。研究表明,在大多數(99%)管道泄漏的情況下,聲能主要集中在頻率范圍為0~100 Hz的低頻分量,這說明聲學信號具有明顯的頻域局部特征[3]。孫潔娣等[4]提出基于K-L散度的PF分量選擇算法,選取含有管道泄漏狀態的主要PF特征分量,從而完成對管道泄漏的定位。文玉梅等[5]利用頻譜內能量分布的差異選擇各分量內的特征向量,實現了供水管道泄漏的辨識。肖啟陽等[6]根據峭度值選取包含管道微小泄漏的沖擊成分分量,實現管道微小泄漏的檢測。以上的研究均是對管道泄漏狀態進行識別,對管道堵塞這方面的研究較少。但是,聲學信號在不同頻率范圍內對堵塞的敏感程度受管道內徑、長度、埋設情況等因素的影響,且與堵塞物大小和堵塞程度有關。因此,有必要在堵塞條件下對聲學信號不同頻率包含的特征信息量進行詳細分析。
基于上述分析,筆者首先對采集到的聲學信號進行離散小波變換(discrete wavelet transformation,簡稱DWT);其次,利用信息增益(information gain)簡化和篩選分量;最后,對篩選后的分量進行聲壓級變換,提取梅爾頻率倒譜系數(mel frequency cepstral coefficients,簡稱MFCC),作為特征向量輸入至極限學習機(extreme learning machine,簡稱ELM)中,實現了管道運行狀態的分類識別,對管道不同程度堵塞的檢測具有重要的實際意義。
1 管道堵塞識別的時頻分析原理
1.1 基于信息增益的聲學信號處理
采用聲波的“直入射”方法對管道運行狀態進行檢測時,聲學信號攜帶足夠的信息來識別管道的缺陷和堵塞。然而,聲學信號中包含體波、共振波、導波、散射波等各種成分和噪音,具有復雜的非線性和非平穩特性。
離散小波變換[7]是根據被分析信號的特征,選擇與信號頻譜相匹配的頻帶進一步分解,從而對信號進行全面的時頻分解,提高時頻分辨率,也就是說離散小波變換是對滿足條件的頻段進行分解,其中,db系列的小波基是故障診斷中常用的[8]。假設原始信號x(n)中的頻率范圍是[0,fs],則每個節點的頻率段為fs/n2,分解后獲得多個分量,部分分量與管道堵塞信息緊密相關,而其他的分量則與堵塞無關或是噪聲干擾成分。因此,有必要對分量信息進行篩選,為此提出一種基于信息增益的分量篩選方法。
基于信息增益篩選分量的基本原理如下:給定樣本集D和連續屬性a,假定a在D上出現n個不同的取值,將這些值從小到大進行排序,記為{a1,a2,...,an}。相鄰 的屬性取 值ai與ai+1,t在區 間[ai,ai+1]取任意值所產生的劃分結果相同。因此,對于連續屬性a,把區間[ai,ai+1]的中位點作為候選劃分點,劃分點t可將D給定樣本集分為子集,其中屬性a的取值范圍小于或等于t的樣本為,屬性a的取值范圍大于t的樣本為其信息增益[9]的計算公式為

其中:Gain(D,a,t)是給定樣本集D基于劃分點t二分后的信息增益。
基于信息增益篩選分量選擇的主要步驟如下:
1)計算給定樣本集D;
2)對于每個屬性a即分量,計算信息增益Gain(D,a,t)和劃分點
3)篩選Gain(D,a,t)的最大值,并將對應的分量選擇為決策樹的根節點;根據計算得到的劃分點,將樣本集D分裂為兩份,其中大于t的樣本為小于或等于t的樣本為4)將剩余的分量作為前節點的數據集,選取信息增益最大的分量為根節點分裂的非葉子節點;
5)對于每一個分量,如果信息增益值大于給定閾值,則重復步驟3和步驟4;
6)如果最大信息增益小于一個給定閾值,則停止分量選擇,完成分量篩選。
聲壓級變換(sound pressure level,簡稱SPL)[10]使聲學信號在相對于振幅較高的成分中,振幅較低的成分得以拉高,以便觀察掩蓋在低振幅噪聲中的特征信號。因此,采用聲壓級變換對聲學信號內容進行放大,增加不同程度堵塞之間的區分度,使管道不同運行狀態的特征信息在后續分解中更易提取。聲壓級計算公式為

其中:pe為原始聲學信號的聲壓有效值;p0為參考聲壓的有效值,文中參考聲壓取1×10-5Pa。
1.2 基于MFCC和ELM的管道堵塞識別
當聲波沿著管道軸線傳播時,遇到堵塞物會出現共振波,峰值會發生相應變化,峰值為共振峰,表示堵塞物的主要頻率成分,而共振峰攜帶管道運行狀態的辨識屬性,利用梅爾頻率倒譜系數[11]來描述共振峰的信息,達到提取管道不同運行狀態特征參數的目的。
極限學習機因具有結構簡單、學習速度快等優點得到廣泛應用。Huang等[12]提出的一種針對訓練單隱藏層前饋神經結構(single hidden layer feed forward neural network,簡稱SLFN)的極限學習機算法,并將其應用在故障診斷中,其具有參數調整簡單、學習速度快、隨機產生并后續不需要實時調整連接權值以及隱含節點閾值等顯著特點。
ELM的網絡輸出為
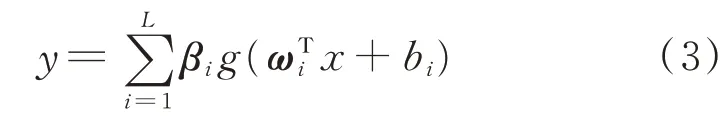
設
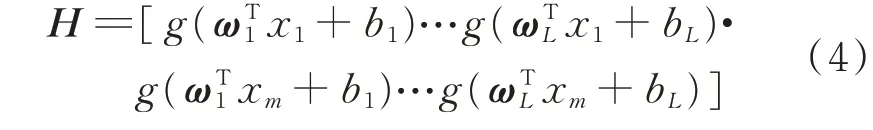
ωi與bi為隨機生成,這使得ELM直接產生全局最優解,其求解最終轉化成范數最小二乘解,求解速度快。
ELM的優化目標為

其中:C為懲罰系數。
式(5)可有以下求解

其中:(HTH+CI)⊥為矩陣HTH+CI的morepenrose廣義逆;H為隱藏節點的輸出;T為期望輸出。
極限學習機的學習速度非常快,在ωi和bi隨機賦值并且保持不變的情況下,僅需要確定輸出權重β來逼近任意訓練的樣本即可。而傳統的基于梯度下降的BP神經網絡模型每次迭代需要調整n?(L+1)+L?(M+1)個值,且BP神經網絡模型為了保證系統的穩定性通常選擇較小的學習率,易出現學習時間加長、陷入局部最優、過擬合等問題。鑒于ELM的優點,文中選用該方法對處理后管道運行狀態信號進行識別。
1.3 基于聲學檢測的管道堵塞識別系統流程
針對埋地管道不同程度堵塞特征難以提取的問題,筆者提出了一種將離散小波變換、信息增益、聲壓級、梅爾頻率倒譜系數以及極限學習機相結合的堵塞識別方法,其具體步驟如圖1所示。
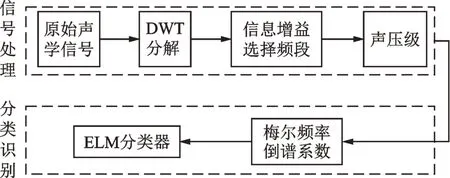
圖1 基于聲學檢測的管道堵塞識別系統流程Fig.1 Blockage detection system based on acoustic technology
1)分別選取管道正常運行狀態、堵塞運行狀態、多重堵塞運行狀態的聲學信號進行頻域分析,初步觀察得到不同運行狀態的特征頻率;
2)根據特征頻率,對聲學信號進行離散小波變換,獲得表征原始信號特征不同頻率的分量信號;
3)對離散小波包分解得到的各個分量計算信息增益,分量的信息增益值根據決策樹篩選原則進行篩選,設定一個閾值,將篩選后的信息增益值與設定的閾值進行比較,若該分量信號的信息增益值小于閾值,則停止篩選;
4)對信息增益值篩選后的分量信號進行聲壓級變換;
5)提取聲壓級變換之后聲學信號的梅爾頻率倒譜系數作為特征集合;
6)將特征集合輸入至極限學習機分類器,得到管道運行狀態的識別。
2 管道堵塞檢測平臺搭建
如圖2所示,實驗室搭建了管道堵塞的聲學檢測實驗平臺[13]。本實驗采用黏土制成的半圓柱體模擬堵塞物,激勵信號選取正弦掃頻信號,因為正弦掃頻信號的頻帶可以按需求調節,用它去激勵多自由度的系統時,可以使聲學信號對管道敏感的頻率范圍內能量集中,易于激發出該頻段內所需的信息,多用于戶外檢測使用的激勵信號。實驗參數如下:黏土管道直徑為150 mm,長為14.4 m。檢測時,使用裝有LabVIEW軟件的計算機控制虛擬儀器產生頻率為100~6 000 Hz的正弦掃頻信號,然后通過ILBVIEW軟件的DAQ助手,控制NI PXIe-6363數據采集卡的模擬輸出端口,輸出模擬電壓信號,經過功率放大器放大后,驅動聲卡產生音頻信號,通過揚聲器將音頻信號發射至管道中,作為激勵信號源,該聲波信號在管道內部與聲阻抗不連續界面經過復雜的相互作用,被置于管道首端的麥克風接收回波信號,經濾波器濾波后上傳至計算機中存儲,濾波器的濾波范圍為100~4 000 Hz,采樣頻率為44 100 Hz,通過分析接收的信號確定管道內部聲學性能的變化,其中選用Analog Devices Inc公司型號為LM4950的功率放大器,選用Visaton公司型號為FR874OHM的 揚 聲 器,選 用Knowles Acoustics公司型號為SPM0208HE5的麥克風。

圖2 管道堵塞檢測實驗平臺圖Fig.2 Experimental platform of blockage detection
為模擬實際工況,在圖2所示的實驗平臺上分別進行不同程度堵塞的實驗,管道中有水流動用來模擬正常排水管道的運行條件,水流的速率由水泵設定,本實驗中模擬水流的最大速率為7 L/s,其他模擬水流速率為:0.42,1.00,1.80,4.25和6.10 L/s,用來形成不同高度的管內水位。實驗室定義管道堵塞程度為堵塞物高度占管道橫截面高度的百分比,高度為20,40和55 mm的模擬堵塞物分別放置在直徑為150 mm的管道中,這些剛性、無孔的堵塞物高度分別占管道截面積的13%,26%和37%,近似認定為輕微堵塞狀態、中度堵塞狀態和中重度堵塞狀態。
管道的運行狀態在本研究中設定為:正常運行空管狀態;正常運行狀態的空管中有常規部件三通件;存在單個堵塞物的運行狀態(包括高度為20 mm的堵塞物、高度為40 m的堵塞和高度為55 mm的堵塞;多重堵塞(包括40 mm堵塞和55 mm堵塞同時存在并放置在管內不同位置、40 mm堵塞和三通件同時存在、55 mm堵塞和三通件同時存在、40 mm堵塞物、55 mm堵塞和三通件同時存在))共計9種管道運行狀態。每種運行狀態的樣本數有40組,總計360組。
3 實驗結果與分析
3.1 聲學檢測信號分析
聲學信號在管道中傳播時,與管壁、堵塞物以及三通件發生碰撞,產生反射、折射和衍射,選擇典型管道運行狀態下的聲學信號的時域和頻域波形如圖3所示。

圖3 直入射聲學檢測信號時域和頻域波形圖Fig.3 Direct incidence acoustic waveform in time domain and frequency domain
如圖3所示,橫坐標的“距離”是聲波在管道中的傳播距離,便于在時頻域圖中確定管道尾端、堵塞物和三通件的大致位置。文中傳播距離等于傳播時間乘以聲音在空氣中的傳播速度(約340 m/s),因為在排水管道中,水流占管道橫截面積的20%,聲音多在空氣中傳播。圖3(a)為原始信號的時域波形圖,難以在時域波形中分辨出堵塞物的位置和堵塞物的大小,甚至和管道配件(三通件)混淆難以區分,主要原因在于環境噪聲的存在和不同的物體對不同范圍的頻帶響應不同。從圖3(b)的頻譜波形圖可知,堵塞物和三通件對超過6 000 Hz以上的頻率范圍不敏感,因此在頻域上頻率超過6 000 Hz之后,幅值不明顯。因此,對信號的下一步降噪和分解頻率范圍都在5 000 Hz以內,引入離散小波變換,從信噪比較低的原始聲學信號中提取出包含特征信息的分量。
根據此特點,對采樣頻率為44 100 Hz的聲學信號進行6層離散小波變換,如圖4所示。圖中:x為離散的聲波輸入信號;h為高通濾波器;g為低通濾波器;↓2為降采樣濾波器。經過第1層離散小波變換,聲學信號x被分解成頻率范圍為0~22 050 Hz的低頻分量和頻率范圍為22 050~44 100 Hz的高頻分量,去除高頻噪聲分量;對頻率范圍為0~22 050 Hz的低頻分量繼續第2層離散小波變換,得到頻率范圍為0~11 025 Hz的低頻分量和頻率范圍為11 025~22 050 Hz的高頻分量,不滿足頻率范圍低于5 000 Hz的要求,去除高頻噪聲分量;依次經過6層離散小波變換,聲學信號被分割成8個分量,其頻 率 由 低到高排列:0~689,689~1 378,1 378~2 068,2 068~2 757,2 757~3 446,3 446~4 134,4 134~4 823,4 823~5 513 Hz。
為便于分析和觀察,選取典型管道的運行狀態進行能譜圖分析。從圖5(a)中可知,顏色越淺表示此處的能量越大,從正常管道的能譜圖可以看出,信號的能量主要集中200~1 000 Hz頻率范圍內,除管道首端和尾端能量聚集,其他位置無能量聚集。對于單個堵塞和三通件,從圖5(b),(c)中可知,當管道中有三通件和堵塞物時,能量在此處具有良好的時頻聚集性,且與聲學理論相符合,能量在堵塞物處聚集,在三通件處稍微發散。對于多重堵塞,從圖5(d),(e),(f)中可知,隨著堵塞物的增加,各堵塞物和三通件間的能量逐漸衰減,不同運行狀態的能量出現的頻段仍保持相對穩定,但管道中存在兩個堵塞和三通件時,出現了能量的交疊。能譜圖能準確定位管道首端、尾端、堵塞及三通件的位置,但無法準確判定管道不同的運行狀態,因此需要進一步對管道運行狀態進行識別研究。

圖4 6層離散小波變換Fig.4 Six-level wavelet decomposition tree

圖5 管道運行狀態能譜圖Fig.5 Energy spectrum of pipeline operation state
由于不同頻率的聲波以不同的速率在反射面不同程度的反射,因而信號強度和在不同頻率范圍內對管道的運行狀態敏感度不同。分量中與管道堵塞無關的特征分量會給分類帶來干擾,導致分類的精度降低[14]。
分量篩選的目的是簡化特征空間,剔除復雜度,提高系統性能。一個分量能夠為分類模型帶來的信息越多,則該分量越重要,分類模型中它的有無將導致信息量發生較大變化,而前后信息量的差值就是這個分量給模型帶來的信息增益。因此,采用信息增益從8個原始分量中篩選出M個有效分量來識別管道的不同運行狀態。基于信息增益篩選有效分量的主要步驟如下。
1)計算給定樣本集D。選擇9類管道運行狀態,每個運行狀態各40個樣本,共計360個樣本,每個樣本有8個分量組成數據集D。
2)計算信息增益。根據式(1)計算得到360個樣本的信息增益和相應的劃分點。
3)根節點選擇。如圖6(a)所示,8個分量中“分量4”的信息增益值最大,選擇為決策樹的根節點;根據計算得到的劃分點,把數據集D分裂為兩份。
4)子節點選擇。對于剩下的7個分量,采用步驟2計算信息增益,選擇信息增益最大的分量為決策樹的葉節點。如圖6(b)所示,“分量1”是數據集D小于等于分量4中信息增益最大分量,選為第2層左子樹的子節點。如圖6(c)所示,“分量8”是數據集D大于分量4中信息增益最大值,選為第2層右子樹的子節點。經過第2層以后,數據被分為4份。
5)離散小波包分量剩下的5個,采用步驟2計算信息增益,信息增益給定閾值為0.1。如圖6(d)所示,“分量6”是第3層左子樹中信息增益最大,如圖6(e)所示,“分量3”是第3層右子樹中信息增益最大。
6)經過第3層篩選后,最大信息增益小于給定閾值0.1,停止并完成分量的篩選。

圖6 信息增益計算圖Fig.6 Information gain calculation diagram
決策樹的根節點為第1層信息增益最大值分量是分量4,經過第2層篩選,在左節點中信息增益最大的分量是分量1,右節點的最大分量是分量8,同理經過最后一層的篩選,只有左節點分量的信息增益值大于閾值,因此第3層的分量為分量6和分量3。由圖6可知,信息增益篩選后的分量為4,1,8,6,3。
對信息增益篩選后的分量進行聲壓級變換,增加不同分量之間的區分度,以便于提取特征。聲壓信號和聲壓級變換后信號的對比圖如圖7所示。
由圖7(a)可知,對于正常運行的管道有無三通件,其信號的拐點不易區分。由圖7(b)可知,經聲壓級變換后的信號拐點能明顯區分,離散小波變換能直接去除信號中高頻噪聲,聲壓級變換能更好地反映信號的局部特征,增加不同運行狀態之間的區分度,提高聲學信號的敏感度。

圖7 聲壓級變換圖Fig.7 Conversion diagram of sound pressure level
3.2 管道堵塞識別
分別采集正常管道、堵塞管道、多重堵塞管道的聲學信號,共計360個樣本,根據上文信號處理方法對信號進行相關處理,然后提取其MFCC特征。管道360個樣本的梅爾頻率倒譜系數能夠從總體上反映出管道正常運行和堵塞運行狀態的差異,管道運行狀態中有堵塞時,梅爾頻率倒譜系數有明顯的變化,具體分析如下:MFCC隨著堵塞程度的加深變化趨勢比較混亂,各分量曲線的波動大,說明MFCC對管道堵塞更為敏感。聲波在管道中傳播時,遇到三通件等管道的橫向連接,在一系列頻率范圍內信號均勻地反射,而遇到堵塞物,聲波以非均勻模式反映信號的強度。因此,梅爾頻率倒譜系數可作為管道運行狀態的識別依據。
隨機選取另一組的聲學檢測信號作為測試樣本,包括9類管道運行狀態,各20組樣本,總計180組樣本,分別提取8個分量,主成分分析篩選(principle component analysis,簡稱PCA)、信息增益篩選后4,1,8,6,3分量的特征參數集MFCC,分別輸入至ELM模型,測試管道運行狀態識別的準確率,識別結果如表1所示,表中LC為三通件(lateral connection,簡稱LC)。

表1 ELM的識別準確率Tab.1 The accuracy rate of ELM recognition
由表1可知,經篩選后管道運行狀態聲學信號的識別率準確率較篩選前有明顯的提高,說明分量篩選的有效性,不同分量之間特征參數的信息量不一樣。相比較利用PCA篩選分量,信息增益篩選分量的準確率高,這說明基于信息增益篩選分量的方法能最大程度的保留數據特征信息以及減少分量中冗余及噪聲特征的干擾的方式,提高了模型的識別精度。但對于管道的多重堵塞,識別準確率只有
50%~60%。
為進一步驗證本研究方法的有效性,利用信息增益篩選分量,分別采用支持向量機(support vector machine,簡稱SVM),BP神經網絡(back propagation,簡稱BP)和ELM來進行識別,并對識別結果進行比較,如表2,3所示。
由表2可知,若正常運行的管道和管道中只有單個堵塞時,基于SVM,BP神經網絡、ELM的方法,篩選前對管道運行狀態的識別準確率平均結果分別為76.6%,76.0%和77.4%,整體低于80%,識別準確率結果偏低。篩選后的識別結果分別是83.2%,87.4%和94.8%,識別準確率明顯提高。通過上述分析可知:利用信息增益篩選后的分量包含更多的管道運行狀態的特征,分量的篩選對特征提取是有效的,它不僅能大幅度減少數據量,也能夠用更少的識別時間來實現高準確率的識別。
上述結果表明,筆者所提出的方法不僅能有效識別運行狀態下管道的程度堵塞,而且能夠排除三通件等常規管道部件對堵塞識別的影響,提高管道狀態的識別準確率。對管道的多重堵塞采用相同的信號處理方法,得到不同分類器的識別準確率,如表3所示。

表3 管道多重堵塞的不同分類器識別準確率Tab.3 Recognition accuracy using different classifi?ers for multiple blockages in the pipe %
當管道中存在多重堵塞時,基于SVM,BP神經網絡、ELM的方法篩選前的識別平均結果分別為56.5%,58.5%和56.5%,都低于60%,整體偏低。這是因為采用“直入射”的聲波對管道多重堵塞進行檢測,其聲學信號由兩部分組成,首先出現的是共振波模態,其次是“類導波”模態,對于多重堵塞或堵塞物和三通件共存的管道,聲波的衰減強烈,造成共振波與“類導波”混疊,難以對多個堵塞進行準確的識別。今后可針對如何提高多重堵塞檢測的識別準確率展開研究。

表2 單個堵塞管道的不同分類器識別準確率Tab.2 The recognition accuracy using different clas?sifiers for single blockage into pipe %
4 結束語
目前,管道堵塞的聲學信號與堵塞類型、形狀、大小等因素有關,受管道材料、管徑大小、水流量、管道壓力以及周圍環境的影響。為了揭示管道堵塞信號的傳播機理,提高堵塞識別準確率,筆者提供一種快速、客觀和準確的方法來識別埋地管道堵塞的特征。針對離散小波變換后只有部分的分量包含管道堵塞信號的問題,提出基于信息增益的分量篩選方法,有效提取包含大量堵塞信息的特征分量,信號中有用的信息得到保留,又為深層次地挖掘信息起到十分關鍵的作用。對正常聲學信號和帶有三通件管道的聲學信號進行聲壓級變換,對比兩種信號的聲壓級波形,發現聲壓級變換能有效的從混合信號中反映管道運行的局部特征,增加不同運行狀態之間的區分度。將MFCC的特征參數與ELM分類器相結合,能夠準確地從含有噪聲的聲學信號中提取出堵塞特征,有效的識別管道不同程度的堵塞。但由于管道拓撲結構和檢測環境的復雜性,管道所處環境、堵塞形式、管道聲學傳播特性的多樣性,使得對于管道的多重堵塞問題還需要進一步探索與研究,主要包括以下兩方面:研究聲波在多重堵塞管道中的傳播特性、規律,建立聲波傳播模型和堵塞可能性預測模型。同時,研究主動聲波檢測技術,即向管道施加特殊激勵信號,通過管道傳播后,收集含有管道信息的信號,得到管道運行狀態的內在的各種信息。研究包括:激勵信號的類型、波長、頻率選擇;聲場分布;信號在不同管道材質的衰減及傳播方式。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
中國生殖健康(2019年3期)2019-02-01 06:12:26
中華手工(2017年2期)2017-06-06 23:00:31
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
中外會展(2014年4期)2014-11-27 07:46:46
環球時報(2010-02-11)2010-02-11 13:34:15
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
