基于可分離殘差卷積與語義補(bǔ)償?shù)腢?Net 壩面裂縫分割
2021-04-29 03:21:54馮春成李林靜
計(jì)算機(jī)工程 2021年4期
龐 杰,張 華,3,馮春成,3,李林靜
(1.特殊環(huán)境機(jī)器人技術(shù)四川省重點(diǎn)實(shí)驗(yàn)室,四川綿陽 621000;2.西南科技大學(xué)信息工程學(xué)院,四川綿陽 621000;3.清華四川能源互聯(lián)網(wǎng)研究院,成都 610213)
0 概述
水利樞紐是修建于河道中多類水工建筑物的綜合體,其具有防洪、供水、發(fā)電和航運(yùn)等功能,在保障與促進(jìn)社會(huì)經(jīng)濟(jì)發(fā)展中起到重要作用[1-2]。受工程建設(shè)水平和所在地的地質(zhì)、水文以及氣象等因素影響,水利樞紐中混凝土壩面易形成裂縫、脫落等缺陷[3]。通常采用缺陷檢測技術(shù)分析壩面缺陷,在此基礎(chǔ)上對水利樞紐進(jìn)行維護(hù),以確保其處于良好的工作狀態(tài)。因此,壩面缺陷檢測對潰壩防范和防震減災(zāi)具有重要意義[4]。
目前水利樞紐的壩面缺陷檢測以人工巡檢為主,存在耗時(shí)長、危險(xiǎn)性大和成本高等問題。隨著人工智能技術(shù)的不斷發(fā)展,自動(dòng)化水平較高的巡檢設(shè)備及安全評估系統(tǒng)[5]成為未來水利樞紐維護(hù)系統(tǒng)發(fā)展的必然趨勢。近年來,隨著以卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)為代表的深度學(xué)習(xí)技術(shù)的迅速發(fā)展,基于計(jì)算機(jī)視覺的分類、檢測和分割方法應(yīng)用日益廣泛[6]。針對建筑物表面缺陷檢測,文獻(xiàn)[7]提出一種基于深度卷積網(wǎng)絡(luò)的道路裂縫分類方法,對分辨率為99 像素×99 像素的彩色圖像進(jìn)行準(zhǔn)確分類。文獻(xiàn)[8]使用基于Faster-RCNN 的缺陷檢測方法,實(shí)現(xiàn)對混凝土裂縫、鋼筋腐蝕面以及螺栓腐蝕面的分層檢測與分類。文獻(xiàn)[9]利用全卷積網(wǎng)絡(luò)(Fully Convolutional Network,F(xiàn)CN)在彩色圖像上分割出裂縫缺陷,獲得精確的裂縫路徑和形態(tài)信息。與傳統(tǒng)分割算法相比,卷積神經(jīng)網(wǎng)絡(luò)能自動(dòng)提取與任務(wù)相關(guān)的魯棒特征,實(shí)現(xiàn)端到端的自動(dòng)缺陷檢測。
水利樞紐的混凝土壩面由于長期被水沖刷滲蝕,其圖像數(shù)據(jù)存在嚴(yán)重的亮度不均衡、相似干擾噪聲大、背景復(fù)雜以及裂縫前景與背景在像素?cái)?shù)量上不均衡等問題,造成壩面裂縫分割較困難。由于U-Net[10]網(wǎng)絡(luò)具有的對稱式編解碼結(jié)構(gòu)可融合卷積網(wǎng)絡(luò)低維和高維特征,保證輸入和輸出分辨率一致,具有較高分割精度,因此本文將U-Net 網(wǎng)絡(luò)應(yīng)用于水利樞紐的混凝土壩面裂縫圖像分割,并根據(jù)壩面圖像特點(diǎn)對其進(jìn)行改進(jìn),提出一種基于可分離殘差卷積和語義補(bǔ)償?shù)牧芽p分割方法。在U-Net 網(wǎng)絡(luò)的編碼端構(gòu)建大尺寸卷積核的可分離殘差模塊增大特征層感受野,在解碼端設(shè)計(jì)語義補(bǔ)償模塊彌補(bǔ)不同層級特征的語義差異,使用焦點(diǎn)損失作為類間損失,增大裂縫前景的損失權(quán)重并提高對困難樣本的注意力,同時(shí)增加中心損失縮小類內(nèi)特征間距,以提高網(wǎng)絡(luò)對像素的分類準(zhǔn)確度。
1 壩面裂縫分割方法
本文提出的壩面裂縫分割方法在U-Net 網(wǎng)絡(luò)基礎(chǔ)上進(jìn)行改進(jìn),改進(jìn)后的U-Net網(wǎng)絡(luò)結(jié)構(gòu)如圖1 所示。該網(wǎng)絡(luò)由全卷積網(wǎng)絡(luò)構(gòu)建的編碼和解碼兩部分組成。編碼部分利用1 個(gè)傳統(tǒng)的初始卷積模塊和4 個(gè)可分離殘差卷積模塊逐級對前一層輸出進(jìn)行卷積處理,每個(gè)卷積模塊由多個(gè)卷積(Conv)層組成,每個(gè)卷積層包含卷積核、批歸一化(Batch Normalization,BN)層及ReLU 激活函數(shù),通過最大值池化生成5 層不同尺度的語義特征。解碼部分先利用語義補(bǔ)償模塊對每層特征進(jìn)行補(bǔ)償,再逐級與反卷積擴(kuò)大尺寸后的輸出特征進(jìn)行拼接,并通過傳統(tǒng)卷積模塊得到后續(xù)輸出,最終利用Sigmoid 函數(shù)得到與輸入圖像分辨率一致的像素級裂縫類別概率圖。
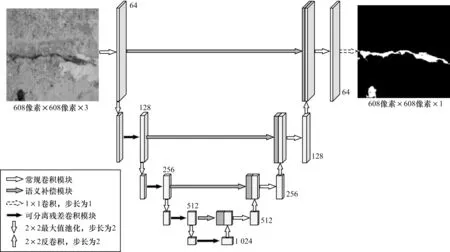
圖1 改進(jìn)U-Net 網(wǎng)絡(luò)結(jié)構(gòu)Fig.1 Structure of improved U-Net network
1.1 可分離殘差卷積模塊
增加特征提取骨干網(wǎng)絡(luò)層數(shù)、設(shè)置適當(dāng)大小感受野的卷積核以及減少網(wǎng)絡(luò)參數(shù)量與復(fù)雜度,在不降低網(wǎng)絡(luò)效率的同時(shí)可更有效地提取特征[11]。本文基于空間可分離卷積[12]思想,在編碼端設(shè)計(jì)一種感受野大小為7×7 的可分離殘差卷積模塊替換傳統(tǒng)2 層3×3 卷積核的卷積模塊,在擴(kuò)大感受野的同時(shí)減少計(jì)算量,如圖2 所示。利用殘差結(jié)構(gòu)[13]將卷積前底層邊緣特征與卷積后高層語義特征相結(jié)合,可降低卷積層中零填充操作引入的邊緣噪聲干擾。

圖2 傳統(tǒng)卷積模塊和可分離殘差卷積模塊結(jié)構(gòu)Fig.2 Structures of traditional convolutional module and separable residual convolutional module
在圖2 中,輸出卷積核通道數(shù)為N,輸入特征通道數(shù)為N/2,可分離殘差卷積模塊與傳統(tǒng)卷積模塊的感受野相同。每個(gè)卷積層參數(shù)量的計(jì)算公式為:

其中,kw和kh為卷積核尺寸。傳統(tǒng)卷積模塊和可分離殘差卷積模塊結(jié)構(gòu)的參數(shù)量分別為3N+13.5N2、4N+8N2,U-Net 網(wǎng)絡(luò)原有的2 層卷積模塊參數(shù)量為2N+9N2。由此可見,可分離殘差卷積模塊參數(shù)量更少,其具有更多卷積和激活等非線性操作,能賦予編碼端特征提取網(wǎng)絡(luò)更好的非線性能力。
1.2 語義補(bǔ)償模塊
U-Net 網(wǎng)絡(luò)在解碼過程中可實(shí)現(xiàn)多尺度特征相互融合,并將深層語義特征與淺層細(xì)節(jié)特征相結(jié)合。然而不同尺度的特征在經(jīng)過多次卷積池化操作后,會(huì)有一定語義與細(xì)節(jié)特征差異,且層級差異較大的特征層之間特征差異更大,若直接進(jìn)行特征拼接則會(huì)限制最終的分割結(jié)果[14]。因此,本文設(shè)計(jì)一種語義補(bǔ)償卷積模塊分別對不同尺度特征進(jìn)行補(bǔ)償,如圖3 所示。
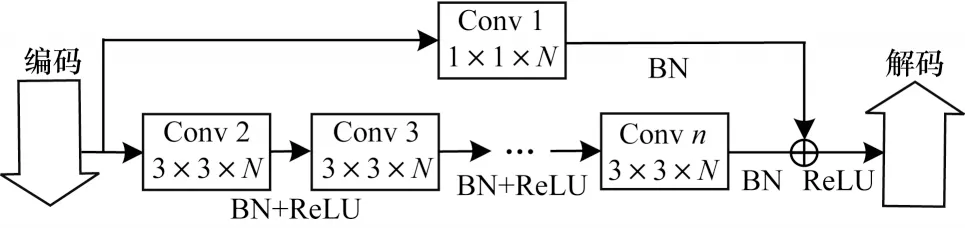
圖3 語義補(bǔ)償卷積模塊結(jié)構(gòu)Fig.3 Structure of semantic compensation convolutional module
語義補(bǔ)償卷積模塊是由一定數(shù)量的3×3 卷積層及一個(gè)1×1 卷積層組成的殘差結(jié)構(gòu),各層步長均為1。其中,3×3 卷積層為語義特征補(bǔ)償單元,1×1 卷積層為邊界特征保留單元,可分層級補(bǔ)償語義特征并防止邊界特征丟失。使用補(bǔ)償單元與保留單元提取高層特征,并在解碼過程中逐層增加補(bǔ)償單元,將上述特征在拼接特征層經(jīng)過語義補(bǔ)償與保留邊界特征后進(jìn)行線性疊加,再與前序特征拼接融合。
1.3 混合損失函數(shù)
語義分割網(wǎng)絡(luò)通常使用交叉熵等類間函數(shù)計(jì)算輸出與標(biāo)簽之間每個(gè)像素的差異,并以所有像素差異的平均值作為訓(xùn)練模型的目標(biāo)損失函數(shù)。
在水工建筑物壩面裂縫圖像分割的二分類任務(wù)中,裂縫前景與背景圖像的像素?cái)?shù)量嚴(yán)重不均衡導(dǎo)致背景損失占比較大,模型在訓(xùn)練過程中會(huì)更注重背景識別,從而降低對裂縫的識別性能。此外,壩面裂縫圖像背景中存在大量與裂縫相似的復(fù)雜干擾噪聲,在模型訓(xùn)練過程中會(huì)產(chǎn)生較多困難樣本,例如將裂縫識別為背景或?qū)⒈尘白R別為裂縫等。針對該問題,本文使用焦點(diǎn)損失函數(shù)[15]和中心損失函數(shù)[16]分別作為類間損失函數(shù)和類內(nèi)損失函數(shù),使模型學(xué)習(xí)到更緊湊和中心化的輸出概率特征值。將混合損失函數(shù)定義為:
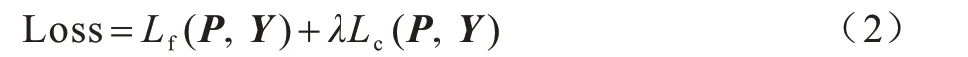
其中,Lf(P,Y)為焦點(diǎn)損失函數(shù),Lc(P,Y)為中心損失函數(shù),P和Y分別為訓(xùn)練圖像通過分割網(wǎng)絡(luò)輸出的概率特征圖和真實(shí)標(biāo)簽,λ為中心損失的權(quán)重,在本文中λ設(shè)置為1。
1.3.1 焦點(diǎn)損失
在原有交叉熵?fù)p失的基礎(chǔ)上增加兩個(gè)調(diào)節(jié)參數(shù)α和β,將其作為壩面裂縫分割的焦點(diǎn)損失函數(shù),相關(guān)定義如下:
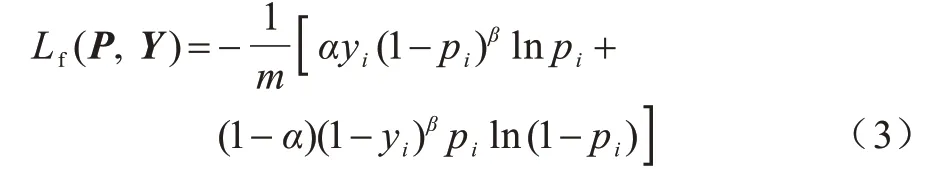
其中,m為所有像素的個(gè)數(shù),y為第i個(gè)像素的標(biāo)簽信息。
假設(shè)1 為裂縫、0 為背景,則標(biāo)簽為裂縫(y=1)而識別為背景(p<0.5)或者標(biāo)簽為背景(y=0)而識別為裂縫(p≥0.5)的像素為困難樣本,標(biāo)簽和識別結(jié)果全為裂縫或者全為背景的像素為簡單樣本。(1-p)β及pβ分別為裂縫和背景兩類像素的困難樣本權(quán)重,本文增大困難像素樣本權(quán)重并減小簡單像素樣本權(quán)重,設(shè)置β=2[15]。1-α與α分別為背景及裂縫的像素占比,通過賦予不同類型像素的損失權(quán)重來平衡兩類像素?cái)?shù)量,并根據(jù)計(jì)算得到的裂縫及背景像素?cái)?shù)量比例,設(shè)置α=0.01。
1.3.2 中心損失
由于訓(xùn)練數(shù)據(jù)與測試數(shù)據(jù)的分布不一致,僅使用類間損失函數(shù)作為訓(xùn)練目標(biāo)函數(shù),盡管可實(shí)現(xiàn)測試集輸出的特征類間可分,但同類樣本輸出的特征分布是離散的,仍存在誤判的困難像素樣本。因此,本文在以焦點(diǎn)損失為類間損失的基礎(chǔ)上增加中心損失作為類內(nèi)損失,從而得到更緊湊的輸出特征,中心損失函數(shù)定義如下:
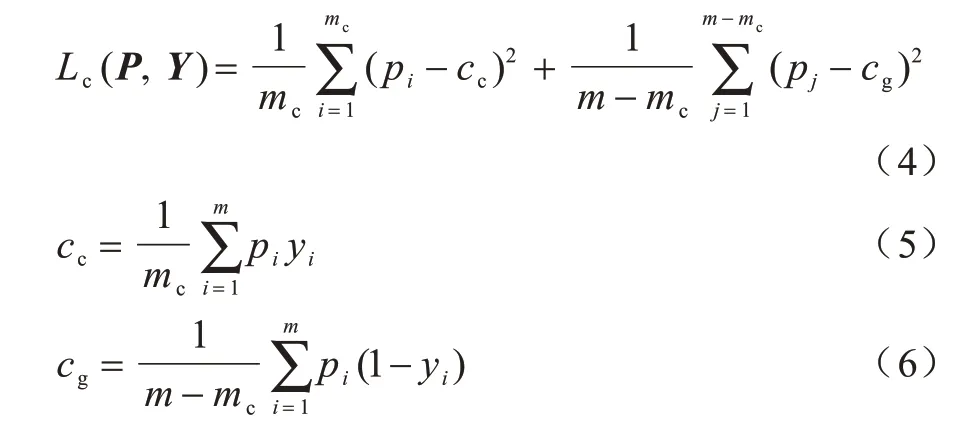
其中,mc是標(biāo)簽為裂縫的像素?cái)?shù)量,m-mc是標(biāo)簽為背景的像素?cái)?shù)量,cc是標(biāo)簽為裂縫的像素所得預(yù)測概率的均值中心,cg是標(biāo)簽為背景的像素所得預(yù)測概率的均值中心。每批次訓(xùn)練迭代均需重新計(jì)算上述兩個(gè)均值中心。
2 實(shí)驗(yàn)與結(jié)果分析
為驗(yàn)證上述壩面裂縫分割方法的有效性,本文進(jìn)行一系列消融實(shí)驗(yàn)分別評估可分離殘差卷積模塊、語義補(bǔ)償卷積模塊以及混合損失函數(shù)的性能,再與主流的圖像分割方法進(jìn)行對比分析。
2.1 實(shí)驗(yàn)數(shù)據(jù)集
由于目前無公開的水工建筑物壩面裂縫圖像數(shù)據(jù)集,本文利用清華四川能源互聯(lián)網(wǎng)研究院提供的中國西南部某大型水電站壩面圖像數(shù)據(jù)自制水工建筑物壩面裂縫圖像數(shù)據(jù)集。該數(shù)據(jù)集含有1 000 張圖像,每張圖像分辨率為608 像素×608 像素,所有裂縫像素區(qū)域均由人工標(biāo)注完成。從該數(shù)據(jù)集中隨機(jī)抽取200 張圖像作為測試集,其余800 張圖像作為訓(xùn)練集。
2.2 實(shí)驗(yàn)環(huán)境
本文實(shí)驗(yàn)采用Intel i7-7700K CPU@4.20 GHz 處理器,NVDIA GTX TITAN XP 25GB GPU,16 GB內(nèi)存,Ubuntu 16.04 操作系統(tǒng),Python 3.6 編程語言,Pytorch 1.3 和CUDA 10.0 深度學(xué)習(xí)框架。在訓(xùn)練過程中采用Adam 梯度下降法,優(yōu)化器的學(xué)習(xí)率設(shè)置為0.000 1,批處理大小為4,取測試集平均損失值最小的模型作為最終模型。在訓(xùn)練和測試過程中,將概率值不小于0.5 的像素識別為裂縫前景,其他像素為背景。
2.3 訓(xùn)練圖像的預(yù)處理
針對壩面圖像的亮度不均衡、對比度差異明顯以及背景干擾噪聲復(fù)雜等特點(diǎn),本文在模型訓(xùn)練過程中使用水平翻轉(zhuǎn)、亮度及對比度隨機(jī)調(diào)整、幾何形變3 種方法隨機(jī)組合對每批訓(xùn)練圖像及標(biāo)簽進(jìn)行預(yù)處理,每種方法獨(dú)立進(jìn)行,使用概率均為0.5。上述方法可在不增大數(shù)據(jù)集規(guī)模的同時(shí)增加訓(xùn)練集的多樣性,從而提升分割模型的泛化能力。
2.3.1 亮度及對比度隨機(jī)調(diào)整
使用灰度平均值u及均方差σ描述圖像X的亮度及對比度,其表達(dá)式如下:

其中,xi為第i個(gè)像素的灰度值,m為像素?cái)?shù)量。
為保證調(diào)整后圖像與原圖像具有較顯著的差異性,生成變換系數(shù)η,其表達(dá)式如下:

為增強(qiáng)調(diào)整后圖像的隨機(jī)性,將255η與2η作為正態(tài)分布曲線的平均值與標(biāo)準(zhǔn)差,生成服從該分布的亮度值及對比度值2ησ。調(diào)整后的圖像表示為:

其中,ε為一個(gè)極小值常數(shù)。服從正態(tài)分布的參數(shù)可使調(diào)整后圖像的數(shù)據(jù)分布具有一定隨機(jī)性,且與原圖像差異較大。
2.3.2 幾何形變
基于裂縫區(qū)域的不規(guī)則性,使用幾何三角函數(shù)對所訓(xùn)練圖像中每個(gè)像素的位置進(jìn)行變換,可達(dá)到形變效果。幾何形變方式定義為:
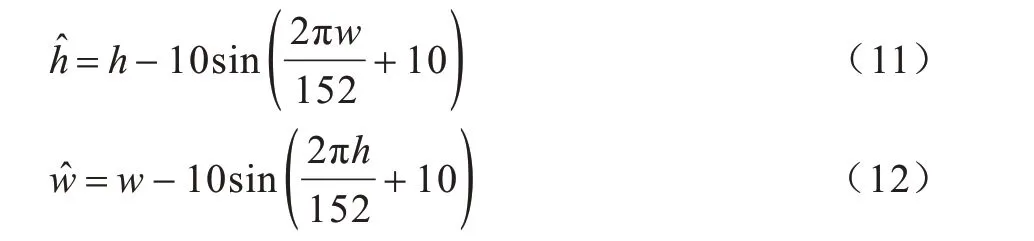
其中,h、、w和分別為形變前后的坐標(biāo)位置。
3 種預(yù)處理方法的效果示例如圖4 所示。圖4(a)以網(wǎng)格圖的形式描述了幾何形變的預(yù)處理過程,圖4(b)為原始數(shù)據(jù)圖像經(jīng)過水平翻轉(zhuǎn)、隨機(jī)亮度及對比度調(diào)整、幾何形變3 種預(yù)處理前后的圖像,圖4(c)為原始數(shù)據(jù)圖像對應(yīng)的標(biāo)簽圖像同樣經(jīng)過3 種預(yù)處理前后的圖像。

圖4 預(yù)處理前后的效果圖Fig.4 Effect images before and after preprocessing
2.4 評價(jià)指標(biāo)
本文實(shí)驗(yàn)分別采用準(zhǔn)確率(PA)、召回率(Rc)、F1值和交并比(Intersection over Union,IoU)評價(jià)不同方法的裂縫分割性能[17],其中F1 值與IoU 為語義分割實(shí)驗(yàn)中綜合度量指標(biāo)。上述指標(biāo)分別定義如下:

其中,TP 為正確預(yù)測為裂縫的像素個(gè)數(shù),F(xiàn)P 為錯(cuò)誤預(yù)測背景為裂縫的像素個(gè)數(shù),F(xiàn)N 為錯(cuò)誤預(yù)測裂縫為背景的像素個(gè)數(shù)。
2.5 訓(xùn)練過程分析
圖5 為本文提出的壩面裂縫分割模型(以下稱為本文模型)在訓(xùn)練過程中訓(xùn)練損失值與驗(yàn)證損失值的變化情況。可以看出,本文模型在訓(xùn)練過程中的損失值迅速衰減,并在迭代80 輪后趨于收斂。由此可知,該模型未出現(xiàn)過擬合現(xiàn)象,具有良好的泛化性能。
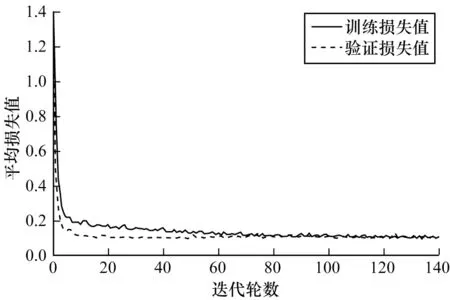
圖5 本文模型在訓(xùn)練過程中的損失衰減曲線Fig.5 Loss attenuation curve of the proposed model in the training process
2.6 消融實(shí)驗(yàn)
在U-Net 網(wǎng)絡(luò)基礎(chǔ)上,逐個(gè)添加可分離殘差卷積模塊、語義補(bǔ)償卷積模塊、焦點(diǎn)損失函數(shù)及中心損失函數(shù),將本文方法與上述方法的裂縫分割性能進(jìn)行對比,結(jié)果如表1 所示。可以看出,本文方法針對壩面圖像提出的一系列措施均能提高裂縫分割性能,本文方法的F1 值及IoU 較U-Net 網(wǎng)絡(luò)分別提高1.32 個(gè)百分點(diǎn)和1.54 個(gè)百分點(diǎn)。

表1 不同方法的裂縫分割性能對比結(jié)果Table 1 Crack segmentation performance comparison results of different methods %
本文進(jìn)一步對類內(nèi)中心損失函數(shù)的有效性進(jìn)行評估,圖6 為表1 中實(shí)驗(yàn)4 和實(shí)驗(yàn)5 訓(xùn)練所得模型對相同測試圖像輸出概率值的分布密度曲線。可以看出,僅使用焦點(diǎn)損失函數(shù)的網(wǎng)絡(luò)輸出概率值分布較離散,且具有更多的像素輸出概率值分布在0.5 左右,仍有較多的困難像素樣本,而增加中心損失函數(shù)的網(wǎng)絡(luò)輸出概率值分布更集中,聚集于0.75 左右的極點(diǎn)兩側(cè),處于0.5 左右的困難像素樣本數(shù)量明顯減少。由上述結(jié)果可知,中心損失函數(shù)不能有效增大類間的差異性,且降低了裂縫像素輸出概率值的中心平均值。結(jié)合表1 的分析結(jié)果可知,焦點(diǎn)損失函數(shù)+中心損失函數(shù)較焦點(diǎn)損失函數(shù)的F1 值及IoU 分別增加0.44 個(gè)百分點(diǎn)和0.52 個(gè)百分點(diǎn),表明中心損失函數(shù)能有效縮小類內(nèi)像素輸出概率特征值的差異,提升對困難像素樣本的識別性能。

圖6 不同模型的輸出概率值分布密度曲線Fig.6 Output probability value distribution density curves of different models
由上述實(shí)驗(yàn)結(jié)果可知,改進(jìn)前U-Net 的各項(xiàng)評價(jià)指標(biāo)均低于改進(jìn)的各個(gè)裂縫分割方法。其中,綜合指標(biāo)F1 值及IoU 隨著改進(jìn)措施的增加而提升,說明本文提出的各項(xiàng)改進(jìn)措施能有效提升裂縫分割性能。
2.7 與其他網(wǎng)絡(luò)的對比
將本文方法與改進(jìn)前U-Net 方法以及SegNet[18]、FCN-8S[19]及DeepLab V3[20]3 種經(jīng)典裂縫分割方法進(jìn)行對比。其中,SegNet 利用末級單層特征層進(jìn)行圖像分割,F(xiàn)CN-8S 基于跳接結(jié)構(gòu)將末端3 層特征融合后進(jìn)行圖像分割,DeepLab V3 使用空洞卷積及空間金字塔池化模塊進(jìn)行圖像分割。上述方法的部分裂縫分割效果與評價(jià)指標(biāo)結(jié)果分別如圖7 和表2 所示。可以看出,SegNet 和FCN-8S 的裂縫分割效果較差,DeepLab V3及U-Net的裂縫分割效果稍好且U-Net優(yōu)于DeepLab V3,本文方法的裂縫分割效果最佳。本文以U-Net 為基礎(chǔ)網(wǎng)絡(luò),通過一系列改進(jìn)措施有效提升了對包含細(xì)小裂縫區(qū)域的困難樣本的識別性能,本文方法對壩面裂縫的分割效果較其他方法更優(yōu)。

圖7 不同方法的部分裂縫分割效果圖Fig.7 Partial effect images of crack segmentation with different methods
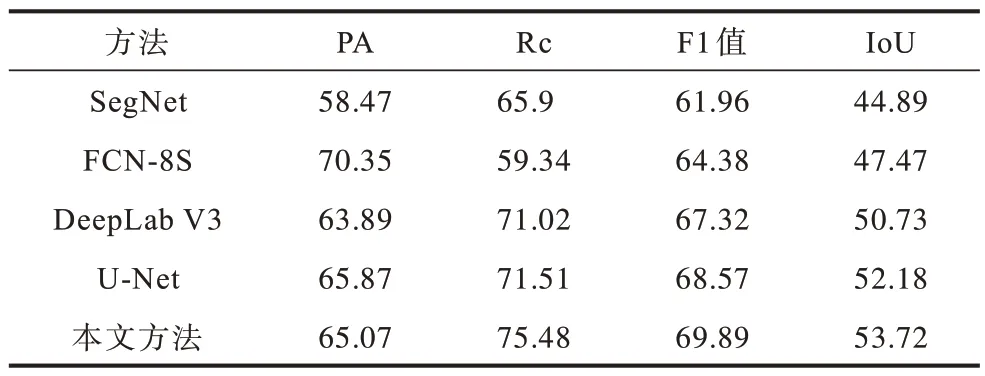
表2 不同方法的裂縫分割指標(biāo)結(jié)果Table 2 Crack segmentation index results of different methods %
3 結(jié)束語
針對壩面圖像在復(fù)雜環(huán)境下存在的像素不均衡、干擾噪聲大等問題,本文基于改進(jìn)U-Net 提出一種壩面裂縫分割方法。在U-Net 網(wǎng)絡(luò)編碼端使用可分離殘差卷積模塊增大感受野,在解碼端增加語義特征補(bǔ)償模塊改善特征融合效果,將焦點(diǎn)損失函數(shù)及中心損失函數(shù)作為目標(biāo)函數(shù)提高對裂縫前景像素與困難樣本像素的注意力,采用幾何形變以及圖像亮度和對比度隨機(jī)變換的方法對訓(xùn)練的圖像進(jìn)行預(yù)處理。實(shí)驗(yàn)結(jié)果表明,本文方法較改進(jìn)前U-Net的F1 值和交并比分別提高1.32 個(gè)百分點(diǎn)及1.54 個(gè)百分點(diǎn),分割效果較SegNet、FCN-8S 等傳統(tǒng)方法更優(yōu)。后續(xù)將精簡分割模型減少參數(shù)量,進(jìn)一步提高該方法的檢測實(shí)時(shí)性。
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學(xué)學(xué)報(bào)(2015年2期)2015-02-27 08:28:11
河南科技(2014年23期)2014-02-27 14:19:15
當(dāng)代修辭學(xué)(2011年6期)2011-01-29 02:49:50
