偏置自糾錯最小和譯碼算法
2021-05-10 03:10:24周志偉孫發魚白瑞青
探測與控制學報 2021年2期
周志偉,孫發魚,白瑞青
(西安機電信息技術研究所,陜西 西安 710065)
0 引言
信道編碼是為了克服信息在信道傳輸過程中受到干擾和噪聲,保證通信系統的傳輸可靠性而設計的一類抗干擾的技術。目前PCM/FM遙測系統中較多采用的是多符號檢測和Turbo乘積碼技術[1-2]。相比于Turbo碼,LDPC碼有更加優異的譯碼性能,低的譯碼復雜度和高度并行化帶來較短的譯碼時延,在高碼率時的優勢更加明顯[3]。好的譯碼算法應該可以在保證性能的基礎上降低譯碼的復雜度。目前LDPC譯碼主要采用置信傳播譯碼,通過該譯碼算法可以得到與最大似然譯碼一樣優異的性能,但是也導致算法的復雜度過高,尤其在碼長過長時,譯碼的復雜度往往隨著碼長的增加呈指數型增長。為了降低譯碼的復雜度,研究人員對其進行了深入的探索與改進,之后提出了最小和譯碼算法,該算法是將對數似然比算法中的對數運算簡化為比較運算,極大地降低了譯碼復雜度,但是性能上帶來了一定的損失[4]。針對置信傳播譯碼復雜度高以及最小和算法性能不佳的問題,本文提出偏置自糾錯最小和譯碼算法。
1 LDPC碼譯碼算法
1.1 LDPC表示方法
LDPC碼是一種(n,k)線性分組碼,其中碼長為n,信息序列長度為k,由m×(n-k)校驗矩陣H唯一決定。H的每一個列向量對應一個碼字,每一個行向量對應一個校驗方程[5]。 其中LDPC碼校驗矩陣H包含大量的零元素,只有少量的非零元素,這種稀疏特性大大降低了譯碼復雜度。
一般校驗矩陣H以矩陣和Tanner圖兩種形式來表示,下面給出了一個5行10列行重為4列重為2的校驗方程和校驗矩陣。
(1)

(2)
該LDPC碼Tanner圖如圖1所示,圖中a為校驗節點,b為變量節點。通過Tanner圖可以直觀地展現迭代譯碼的過程。可以看出,Tanner圖是雙向圖,可以用G={(V,E)}表示,其中V表示節點的集合,V=Va∪Vb。若校驗矩陣H維度為m×n,則變量節點數量有n個,以Vb=(b1b2…bn)表示,每個Vb中元素對應H的一列或一個碼字。校驗節點數量有m個,以Va=(a1a2…an)表示,每個Va中元素對應一行。所有邊的集合用E屬于Vb∪Va來表示,同種節點間無相連邊。校驗矩陣每有一個非零元素,校驗節點和變量節點間就會存在一條邊進行連接。
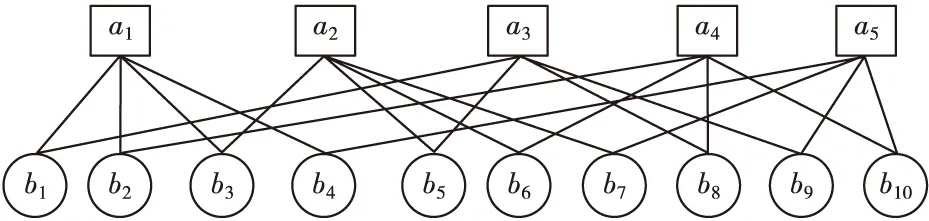
圖1 Tanner圖Fig.1 Tanner
1.2 LDPC譯碼
譯碼算法的選取直接決定了是否能激發出碼本身具有的潛在優勢,特別是在譯較長碼的時候,譯碼復雜度往往伴隨碼長的增加呈指數型增長,因此選取好的譯碼算法可以在保證性能的基礎上減小譯碼的復雜度,易于硬件實現[6]。
LDPC碼有很多種譯碼方法,本質上都是基于Tanner圖的消息迭代譯碼算法。
置信傳播譯碼是根據軟迭代信息進行概率譯碼,每一輪迭代都需要對碼字中的各個碼字關于接收碼字和信道參數的后驗概率進行估算,因此置信傳播譯碼算法是一種逐比特最大后驗概率算法,所有迭代過程可以看作有校驗矩陣決定的Tanner圖上進行消息傳遞的過程[7]。在討論算法前,先介紹算法符號代表的含義:
a∈{1,2,3,…,M},校驗矩陣的第a個校驗節點;
v∈{1,2,3,…,N},校驗矩陣的第v個變量節點;
s表示算法的迭代次數;
S(s)(Qv)迭代次數為s時第v個變量的后驗概率;
M(a)表示與校驗節點a連接的變量節點的集合;
N(v)表示與變量節點v連接的校驗節點的集合;
a′∈M(a)/v表示與第a個校驗節點相連的除去第v個變量節點的其他變量節點的集合;
v′∈N(v)/a表示與第v個變量節點相連的除去第a個校驗節點的其他變量節點的集合;

S(s)(Ra,v)在第s次迭代過程中,由第a個校驗節點傳遞給第v個變量節點的信息;
S(s)(Qv,a)在第s次迭代過程中,由第v個變量節點傳遞給第a個校驗節點的信息。
1.2.1 置信傳播算法
設編碼器輸出的碼字為ci,在AWGN信道下進行BPSK,輸出為xi(xi=2ci-1);經過信道后,譯碼器接收變量為yi,其中yi=xi+n,n服從高斯分布N(0,σ2)。
1) 初始化
根據接收變量yi,來計算ci=1的條件概率:
令P(xi=1)=P(xi=-1)=1/2,則:
從定義可知,Pv1是接收變量yi得到關于ci=1的消息。
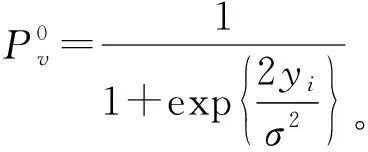
根據校驗矩陣H,若hij=1,則變量節點vi與校驗節點ai連接,定義變量消息:
迭代過程主要由兩個更新步驟組成,執行迭代這兩個步驟,對每一比特的后驗概率進行準確的估算。
2) 校驗節點更新:對變量消息進行計算得到新的校驗消息。
在二進制M維序列中,如果任意的一位ai(i=1,2,3,…,M)的概率為P(ai=1)=Pi,則該序列中含有偶數個1的概率為:
含有奇數個1的概率為:
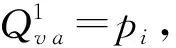
3) 變量節點更新:對校驗消息進行計算得到新的變量消息。
(1)
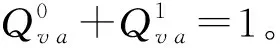
4) 譯碼判決
每一輪迭代完成后,對每個信息比特xi(i=1,2,3,…,n)計算其后驗概率:
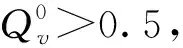
最后可以得出對發送碼字的一個估計c′=[c1,c2,c3,…,cn]。計算其伴隨式S=cHT,如果S=0,則譯碼成功,結束其迭代;否則繼續迭代,若迭代次數達到預先設定的最大值仍未成功,則失敗,結束迭代。
1.2.2 最小和算法
置信傳播算法中含有大量的乘除運算,不利于硬件實現,對于硬件開發而言,實現乘法運算消耗的資源比加法運算和比較運算大的多,時延大。除此之外,在實際應用中,由于噪聲方差σ2需要通過信道估計獲取的準確度沒有辦法保證,所以迭代信息不易獲取,因此提出了最小和譯碼算法[8]。
1) 初始化
將初始信道信息傳遞給變量節點作為初始信息:
2) 校驗節點更新
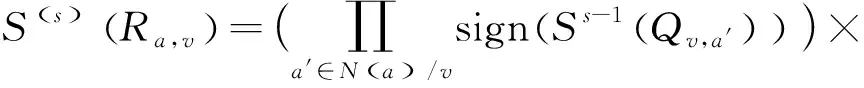
3) 變量節點更新
4) 計算后驗概率
5) 譯碼判決
該算法在校驗節點的更新中運用了符號運算與比較運算代替了乘積運算,極大地降低了運算的復雜度,并且在迭代中使用的初始信息2yi/σ2簡化為yi,極大地減小了獲取信息的復雜度。但是由于最小和算法是對校驗節點更新的簡化,因此降低譯碼復雜度的同時也使譯碼性能下降,本文提出偏置自糾錯最小和譯碼算法,引進在校驗節點的更新過程中加入偏置系數α,同時改變其變量節點的更新過程,刪除變量節點更新過程中的不可靠信息。
2 偏置自糾錯最小和算法
1) 初始化
將初始信道信息傳遞給變量節點作為初始信息:
2) 校驗節點更新
3) 計算后驗概率
4) 變量節點更新
L(l)(Qa,v)=
6) 譯碼判決
偏置自糾錯算法通過在校驗節點的更新過程中引入偏置系數,彌補了最小和算法近似運算帶來的損失,同時改變其變量節點更新過程,在連續兩次迭代中,如果變量節點更新結果符號相異,就把變量節點的更新結果取零,刪除了變量節點更新過程中的不確定信息,使譯碼性能得到提高。這種算法只是增加了加法運算與比較運算,相比于傳統的置信傳播算法的乘積運算的復雜程度可以忽略不計,更加容易硬件實現。相比于最小和算法,只是加入一點代價就極大提高譯碼的性能。
3 算法仿真
3.1 算法復雜度分析
表1列出了置信傳播算法、最小和算法、偏置自糾錯算法3種算法節點更新所需要的乘法、加法、比較及其他運算的次數,其中da表示校驗節點的度,dv表示變量節點的度。
偏置自糾錯最小和算法存在加法運算、比較運算以及極少數的乘法運算,而置信傳播算法中存在著大量的乘法運算,隨著碼長的增加,其計算復雜度呈指數型增加。相對于置信傳播算法,偏置自糾錯算法大大節省了計算量,更容易硬件實現,同時相比于最小和算法,本文提出的偏置自糾錯算法在只增加加法運算及比較運算的前提下,極大地提高了譯碼性能。

表1 算法次數Tab.1 Number of algorithms
3.2 仿真結果及分析
偏置自糾錯算法中的偏置因子α,是影響譯碼性能的關鍵因數之一,若是偏置因子選取合適,則可以使偏置自糾錯算法在性能上逼近置信傳播算法。本文給出了4種偏置因子α的性能曲線,如圖2所示。
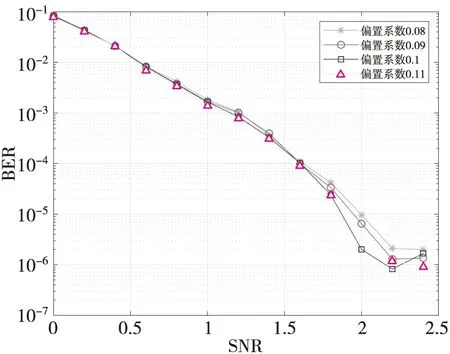
圖2 偏置自糾錯最小和算法在不同偏置系數下的性能Fig.2 The performance of the bias selfcorrecting minimum sum algorithm under different bias coefficients
從圖2可以得到,當偏置系數α=0.1 時,該算法譯碼性能最佳,同時在硬件實現上比較簡單,只需通過加法器與比較器就可以實現。通過以上分析,本文選取α=0.1 為該算法的偏置因子。
為了充分衡量偏置自糾錯最小和譯碼的性能,在AWGN信道下,采用了BPSK調試的方式,分別對硬判決、置信傳播、最小和以及本文所提出的偏置自糾錯最小和譯碼算法進行了仿真分析。LDPC碼采用碼長為1 024的規則碼,碼率為1/2,最大迭代次數為30次。
圖3給出了不同譯碼算法的誤碼率與信噪比曲線的仿真結果圖。通過曲線可以看出置信傳播算法的性能最好,硬判決譯碼的性能最差,當誤碼率為10-5時,置信傳播算法與偏置自糾錯算法算法相比有0.1 dB的增益,但是置信傳播算法的譯碼復雜度相比于偏置自糾錯算法要高,隨著碼長的增加和迭代次數的變大,譯碼復雜度會越來越高。同時由于最小和算法采用了近似的方法損失了部分的性能,偏置自糾錯算法引入偏置因子,改變了變量節點的更新過程,刪除了變量節點更新過程中的不可靠信息,彌補了最小和算法帶來的損耗,使其性能逼近置信傳播算法。
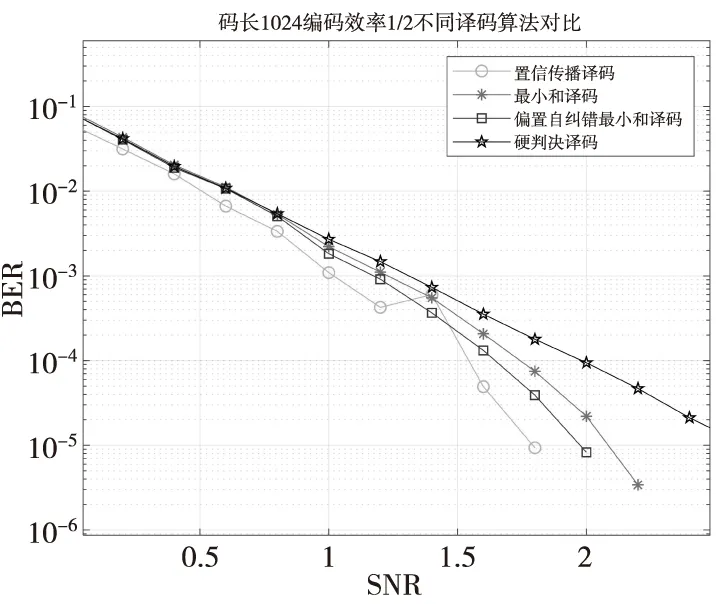
圖3 不同譯碼算法性能比較Fig.3 Performance comparison of different decoding algorithms
4 結論
本文提出偏置自糾錯最小和譯碼算法,該算法的主要思想是通過添加偏置系數,改變其變量節點的更新過程,刪除變量節點更新過程中的不可靠信息,彌補了最小和算法由于近似運算帶來的損耗,使其性能逼近置信傳播算法。仿真結果表明,本文提出的偏置自糾錯最小和算法,相較于置信傳播算法,運算復雜度降低,擁有較小的時延,性能優于最小和算法,易于硬件實現,具有一定的研究和應用價值。
雖然初步完成所需工作,但是如何找出適用于偏置自糾錯最小和譯碼算法的最優性能參數,還需要做大量工作。
