基于機器學習的交通流參數異常數據處理模型研究
2021-05-11 07:27:42賈樹林胡江宇馬雙寶羅維平
武漢紡織大學學報 2021年2期
關鍵詞:模型
周 博,賈樹林,胡江宇,馬雙寶, ,羅維平,
(1. 武漢紡織大學 機械工程與自動化學院,湖北 武漢 430200;2. 湖北省數字裝備重點實驗室,湖北 武漢 430200)
隨著私家車占有量急劇上升,城市交通網絡所面臨的負荷也與日俱增。在公路及城市道路中使用不同類型交通探測器收集實時交通數據,以對交通流進行預測、實時交通誘導以及道路通行能力預測分析提供及時可靠的數據支撐[1]。探測器收集數據的過程中存在諸多噪音,如設備的磨損導致精度的降低、雨雪天氣對探頭的影響及設備供電異常等,會對收集到的交通流數據質量產生一定的影響,因此需對收集的原始交通流數據進行故障數據的篩選修復。
針對交通流異常數據診斷,李琦等提出一種基于流量守恒定律的交通流數據質量評價與控制方法[2],可對異常值進行整體修復,但該方法具有較強地域局限性,魯棒性較低;苗旭等提出一種基于支持向量機模型的固定交通檢測器缺失數據綜合修復方法,可對交通流數據中缺失值進行填補[3],但對于數據中存在的異常值未進一步處理;鮑東玉等人根據交通運行狀態的統計相似性進行了研究和對比,選擇了IQR法作為數據修復的方法[4]。綜合前期學者研究,針對交通流數據的修復研究較為分化,缺乏較為完整數據處理體系,且大多基于統計原理,模型遷移能力有待提高。針對上述問題,本文提出基于機器學習及線性回歸模型構建出一種綜合數據清洗、奇異值、缺失值及異常值處理的交通流數據集成處理框架,對原始交通流數據進行有效性處理。
1 整體處理框架及數據來源
交通流數據主要包括速度、流量、時間占有率三個參數,數據采集過程中由于檢測設備故障及檢測環境對數據采集帶來的影響,交通流數據中存在的問題數據可分為缺失數據、重復數據、錯誤數據三大類,根據問題數據類型對其進行有效性處理,其整體流程如圖1 所示。本文所用數據來自蘭州2018年一月份城市及高速交通檢測器所采集原始數據集,采樣間隔為五分鐘,數據集來源于網絡數據庫。

圖1 數據有效性處理整體流程圖
2 異常數據清洗方法
2.1 奇異值處理
首先對三參數均為空值的數據及重復采樣的數據進行刪除,再通過三參數的基本關系對數據中的奇異值進行刪減。
對速度、流量、時間占有率三者關系進行相關性分析,當有車通過交通流數據采集器時三參數值均不為零;當無車通過采集器,三參數均為零;當車停在采集器邊時,速度及車流量為零,占有率為100%;根據此交通流機理,可得到交通流數據奇異值基礎篩選規則,如表1 所示(表中speed、occupancy、volume分別表示速度、時間占有率及流量)。

表1 交通流數據奇異值基礎篩選規則表
根據表1 所提供的基礎篩選規則可對原始數據中的奇異值進行初步篩選。
在交通流數據采集器的采樣間隔內無車通過時,車輛服從泊松分布,其公式如式(1)所示。

其中p(x)為在采樣間隔內通過采樣間隔的車輛的概率密度函數,m為間隔內到達的平均車輛數,依據此在置信水平α下,交通流數據采集器采樣間隔內有車輛到達的概率,即x>0 的概率如式(2)所示。
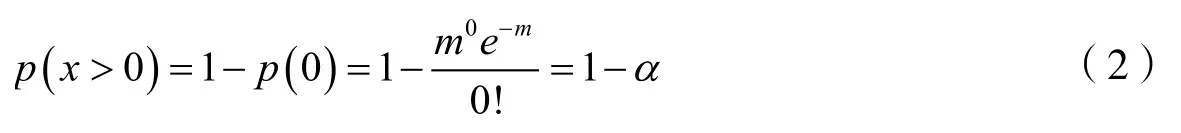
由此可得m=?ln α,可通過設置置信水平α進一步以概率來判斷三參數均為零是否為異常值,即m >?ln α時,有1 ?α的概率不會出現volume 為零的情況。
針對時間占有率為零其他兩者不為零的數據,分析其原因可能是由于傳感器不靈敏導致,根據交通流三參數線性關系如式(3)所示:


根據式(4)輸入合理范圍內的最大平均速度,平均有效車長及時間占有率即可得出最大流量閾值,并通過此篩選出奇異值。
2.2 基于隨機森林回歸模型缺失值處理
由于現有缺失數據插補方法主要包含單變量缺失值插補及多變量聯立缺失值差補兩大類,本數據集三參數均包含缺失值,為避免如均值填充、中值填充、上、下采樣等單變量缺失值方法所造成的數據原始分布改變及產生抽樣誤差,本文采用多變量聯立缺失值差補法對交通流數據集中缺失值進行填補。
通過對交通流三參數進行相關性分析,可以得到三參數相關性關系如表2 所示。

表2 速度、流量、時間占有率三參數相關性分析
由表2 中數據可知速度與時間占有率、流量與時間占有率之間具有較強的相關性,速度與流量之間具有中等相關性,因此,本文采用隨機森林回歸模型對速度、流量、時間占有率三個變量中缺失的數據進行缺失值填補。
隨機森林是一種主流的機器學習算法,其底層是一種基于決策樹的集成算法,由“Classification And Regression Tree(CART)”與“Bagging”方法結合而成,在建模過程中通過bootstrap 隨機抽樣的方法構建樣本集以訓練模型,模型輸出結果是通過“投票”方式所決定的。由于其處理機制,隨機森林對噪音數據及缺失數據具有較好的容錯率,在處理高維數據時,能夠自主進行特征選擇,且抗過擬合的能力較強,魯棒性較高[5]。
在交通流數據中,由于速度、時間占有率及流量三參數均存在缺失值,可根據變量缺失量由少到多的順序對其缺失值進行填補。首先提取缺失數據最少的變量作為標簽,對其余變量中的缺失值進行均值填充后,構建特征矩陣;其次對標簽缺失值進行預測填補;最后使用填補完成的變量補充進數據集,再次進行排序及標簽、特征矩陣構建,對三參數進行循環填補后即可得到完整無缺失交通流數據集。
3 異常數據處理
3.1 基于孤立森林的異常值提取
在得到的完整交通流數據集后,通過繪制核密度圖觀察數據分布情況,如圖2 所示。
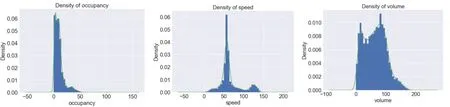
圖2 完整數據occupancy、speed、volume 三參數核密度圖
由圖2 可知三參數中均具有離群值,需對其進行異常值處理。首先采用箱線法對數據進行異常值分析。對經過前期處理的交通流數據進行箱線法描述,其結果如圖3 所示。
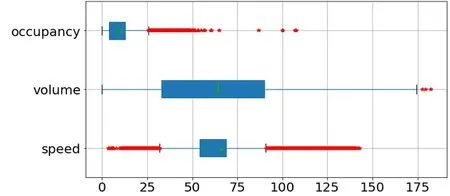
圖3 交通流數據箱線法分析圖
由圖3 中數據可得,occupancy、speed、volume 三者均存在異常值。在speed 變量中存在較多偏大偏小數據,在volume 變量中存在少量偏大數據,在occupancy 中存在較多偏大數據。數據整體存在較多異常情況,因此需對數據進行進一步異常值處理。
本文采用Isolation Forest 算法對異常數據進行提取,由于Isolation Forest 模型是基于樹模型的集成模型,因此在構建Isolation Forest 模型時首先需要通過數據訓練出m多個iTree,其步驟如下:
(1)對于給定數據集X,采用隨機抽樣法抽取D個子集放入根節點:

(2)從t個特征維度指定單個維度q,采用隨機原則產生切割點p:

(3)對數據空間通過切割點p生成的超平面劃分為兩個子空間,對于維度小與p的放入左子節點,大于的放入右子節點;
(4)遞歸(1)、(2)至iTreed 達到預定高低;
(5)循環所有步驟,至m個iTree 生成。
孤立森林生成后,將單個樣本輸入iTree,計算其平均高度,并對其進行歸一化處理,最后計算每個樣本的異常值分數,分數計算公式如式(5)所示。

對于捕捉到的異常值,Isolation Forest 算法所提供的接口可將異常值所對應的數據索引進行緩存,便于對異常值處理后對應地填回數據。通過將交通流數據傳入Isolation Forest 算法,得到的occupancy、speed、volume 三參數異常值數量如下表所示。

表3 速度、時間占有率及流量三參數異常值數量表
3.2 基于城市交通流參數的異常值填補模型
當交通流數據采集器采集到的數據中出現因硬件原因所造成的數據缺失的情況,可通過對交通流參數中兩兩之間構建關系模型,并通過已有數據對硬件故障進行數據修復,以進一步保證交通數據系統的正常運行。
3.2.1 速度-時間占有率模型求解
通過前期對交通流參數中速度與時間占有率兩者關系進行分析得出兩者具有很強的線性關系,因此建立一元線性回歸的數學模型如式(7)所示:

式中s為交通流速度;m為時間占有率;c0、c1為回歸系數及常數;ε為隨機誤差。此外,對于系統隨機的誤差需服從服從正態分布,滿足如式(8)所示關系:

對于所構建函數模型中的參數,可通過最小二乘法計算得出。最小二乘法是通過最小化誤差的平方和尋找參數的最佳匹配[5]。對于所構建的線性回歸模型,需檢驗其可行性即準確率,其中包括回歸方程及回歸系數的顯著性檢驗、殘差分析等。對于有效的線性回歸模型,殘差應服從均值為0 的正態分布。對所得回歸模型進行相關可行性檢驗所得計算結果如表4 所示。

表4 速度—時間占有率模型回歸系數及顯著性檢驗結果
由表4 數據可知,對于所求變量之間存在線性關系,且線性回歸系數存在顯著意義。最終得到利用最小二乘法得到速度-時間占有率的線性回歸模型方程如式(9)所示。

3.2.2 流量-時間占有率模型求解
由流量-時間占有率散點圖可以看出,數據點分布呈非線性關系,根據假設構建二元回歸方程。建立流量-時間占有率二次曲線回歸方程模型如式(10)所示:通

過線性變換m1=m2變換為二元線性模型為:

對構建的流量-時間占有率線性回歸模型,輸入數據進行擬合,使用最小二乘法參數進行擬合估計,求解出其回歸模型,并對其進行相關性參數分析,其結果如表5 所示:

表5 流量—時間占有率模型回歸系數及顯著性檢驗結果
由表5 可知,經過計算,F 檢驗的概率p 值小于0.05 即流量與時間占有率之間存在二元線性關系;T檢驗的概率p 值小于0.05,即回歸系數有顯著意義[6-8]。最終經擬合檢驗得到的可行性流量-時間占有率模型如式(12)所示。
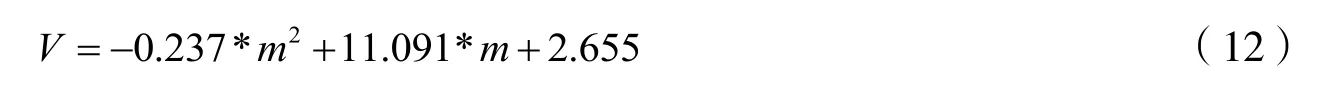
3.2.3 速度-流量模型求解
根據交通流三參數之間的相關性關系,對于速度-流量模型可聯立前期求出的流量-時間占有率及速度-時間占有率模型對其進行求解,其中時間占有率作為中間變量。
通過聯立式(9)及式(12)可得速度-流量模型如式(13)所示。
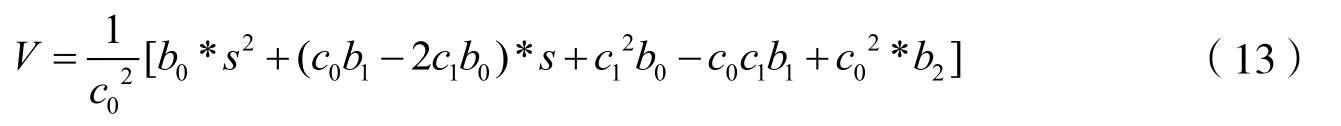
4 實驗結果及結論
在得到三參數對應模型后將提取出的異常值及其相關參數輸入模型,即可對異常數據進行預測,最終將所預測數據通過孤立森林模型中所保存的索引對數據進行替換,最終得到完整無缺失的數據集。
通過對數據集中異常值捕捉修正后,再次使用箱線法對數據整體進行觀測,其結果如圖4 所示。
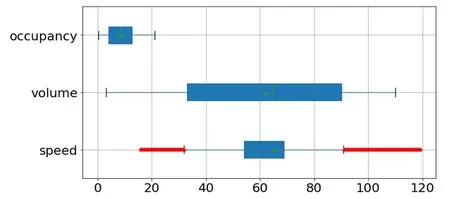
圖4 修正后數據集箱線圖
由圖 4 中信息可知,經過處理后的交通流數據集volume、occupancy 兩參數所有值均在正常閾值內,基本為正確數據,但speed 參數中仍存在大量偏離最大閾值范圍的數,根據交通流三參數基本規律對speed、occupancy 兩參數進行散點圖描述如圖5 所示。

圖5 車速-時間占有率關系圖
由圖5 信息可得,車速出現明顯分段聚集,大致分為0~60km/h 及80~120km/h 兩個區間,但在兩個區間內數據基本服從交通流參數關系,即速度與時間占有率成反比關系。分析出現區間分化的原因是由于數據集中所采集的數據來源包括城市公路及快車道(高架、高速等),由于不同車道中速度限制及車道寬度的影響所造成的速度分化情況。在城市內道路中速度閾值大致為0~60km/h,在高架等快速車道速度閾值為80~120km/h,但在不同車道由散點圖可知數據基本服從交通流參數關系,故通過箱線圖表現出的速度異常值為正常數據。
對交通流數據的異常值進行判斷修復是提高交通流信息數據有效性的基礎,本文提出一種融合奇異值分析及孤立森林的交通流異常數據診斷方法,基于多元線性回歸算法的異常值修復方法,經過實測數據檢驗,本文所構建數據處理模型可在很大程度上提升數據利用率,保證了交通流數據的可靠性與有效性,在今后研究中可對實時的交通流數據輸出有效性方面進行改進。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
