基于改進(jìn)LMD方法的風(fēng)電機(jī)組齒輪箱故障診斷研究
2021-05-11 13:52:26李輝,鄧奇
自動(dòng)化儀表 2021年3期
李 輝,鄧 奇
(西安理工大學(xué)電氣工程學(xué)院,陜西 西安 710048)
0 引言
近年來,由于全球環(huán)境惡化和資源短缺,使得世界各國(guó)逐漸開始重視開發(fā)和利用可再生能源。其中,風(fēng)力發(fā)電已逐漸成為可再生能源活躍的熱點(diǎn)。齒輪箱作為風(fēng)電機(jī)組的核心零部件之一,由于其特殊的工作環(huán)境,較易發(fā)生故障,且一旦出現(xiàn)故障必定造成巨大的經(jīng)濟(jì)損失[1-2]。因此,對(duì)風(fēng)電機(jī)組齒輪箱進(jìn)行故障診斷,對(duì)提高發(fā)電效率和節(jié)約成本具有十分重要的意義。
風(fēng)電機(jī)組齒輪箱振動(dòng)信號(hào)具有非線性和非平穩(wěn)性等特點(diǎn)。針對(duì)非線性和非平穩(wěn)信號(hào),其分析常采用時(shí)頻分析方法。常用的時(shí)頻分析方法有經(jīng)驗(yàn)?zāi)B(tài)分解(empirical mode decomposition,EMD)、小波變換、短時(shí)傅里葉變換、魏格納威利分布。EMD是一種自適應(yīng)的將信號(hào)分解為多個(gè)固有模態(tài)分量(intrinsic mode component,IMF)的方法。但EMD存在嚴(yán)重的端點(diǎn)效應(yīng)和模態(tài)混疊問題。小波變換方法雖然對(duì)線性信號(hào)的處理比較好,但不適用于非線性和非平穩(wěn)信號(hào)。短時(shí)傅里葉變換、魏格納威利分布雖能在一定程度上描述信號(hào)的瞬時(shí)頻率分布,但都以傅里葉變換為基礎(chǔ),沒有從根本上解決傅里葉變換的弊端。
局部均值分解[3](local mean decomposition,LMD)是由Jonathan S.Smith提出的一種新的自適應(yīng)非平穩(wěn)信號(hào)的處理方法。該方法將復(fù)雜的多分量調(diào)幅調(diào)頻信號(hào)分解為單分量的調(diào)幅調(diào)頻信號(hào)。其分解結(jié)果不僅能準(zhǔn)確反映出信號(hào)的時(shí)頻分布,且特別適合分析多分量非平穩(wěn)信號(hào)[4]。程軍圣等[5]將局部均值分解方法與反向傳播(back propagation,BP)神經(jīng)網(wǎng)絡(luò)結(jié)合起來,并應(yīng)用到滾動(dòng)軸承故障診斷中。李慧梅等[6]提出基于 LMD 的邊際譜的滾動(dòng)軸承故障診斷方法。結(jié)果表明,該方法能夠有效地提取滾動(dòng)軸承的特征頻率。胡勁松等[7]將三次樣條插值過程引入LMD,用于計(jì)算局部均值函數(shù)和包絡(luò)估計(jì)函數(shù),使LMD算法的計(jì)算效率和精度都有了一定的提升。雖然LMD在EMD的基礎(chǔ)上作了改進(jìn),但LMD依然存在模態(tài)混疊現(xiàn)象,使得分解結(jié)果產(chǎn)生偏差,最終影響故障診斷的準(zhǔn)確性。
為了減少由于求取局部均值函數(shù)帶來的誤差。本文提出了一種基于局部積分均值的LMD改進(jìn)算法,并成功應(yīng)用于風(fēng)電機(jī)組齒輪箱故障診斷中。
1 工作原理
1.1 LMD原理
LMD將原始信號(hào)分解為一系列PF分量與一個(gè)殘余項(xiàng)的和,每個(gè)PF分量可以看作是一個(gè)包絡(luò)信號(hào)和一個(gè)純調(diào)頻信號(hào)的乘積,具體的算法步驟如下。
①對(duì)于一個(gè)原始信號(hào)x(t),找出全部極值點(diǎn)ni,并求出相鄰兩個(gè)極值點(diǎn)之間的局部均值mi和局部包絡(luò)ai。
(1)
(2)
②將所有的局部均值mi和局部包絡(luò)ai在其對(duì)應(yīng)的極值點(diǎn)時(shí)刻tni和tni+1之間進(jìn)行直線延伸,再采用滑動(dòng)平均法進(jìn)行平滑處理,得到局部均值函數(shù)m11(t)和局部包絡(luò)估計(jì)函數(shù)a11(t)。
③將局部均值函數(shù)m11(t)從原始信號(hào)中分離出來,得到零均值信號(hào)h11(t)。
h11(t)=x(t)-m11(t)
(3)
④對(duì)h11(t)進(jìn)行解調(diào),得到s11(t)
(4)
重復(fù)上述步驟①~步驟②,可以得到有關(guān)s11(t)的局部包絡(luò)估計(jì)函數(shù)a12(t)。若a12(t)=1,則證明s11(t)為純調(diào)頻函數(shù);若a12(t)≠1,則需要重復(fù)上述迭代,直到式(5)成立,此時(shí)s1n(t)是一個(gè)純調(diào)頻信號(hào)。
a1(n+1)(t)=1
(5)
⑤將迭代過程中所產(chǎn)生的全部局部包絡(luò)估計(jì)函數(shù)相乘得到包絡(luò)信號(hào)a1(t)。
(6)
⑥原始信號(hào)的第1個(gè)PF分量為MPF1:
MPF1=a1(t)s1n(t)
(7)
原始信號(hào)的幅值為a1(t),根據(jù)調(diào)頻信號(hào)s1n(t)可以得到瞬時(shí)頻率為f1(t)。
(8)
⑦ 將MPF1從原始信號(hào)中分離出來,得到u1(t);將u1(t)作為原始信號(hào)重復(fù)步驟①~步驟⑥、循環(huán)k次,直到u1(t)成為一個(gè)單調(diào)函數(shù)為止。
原始信號(hào)x(t)被分解為k個(gè)PF分量和一個(gè)單調(diào)信號(hào)uk之和,即:
(9)
1.2 改進(jìn)的局部均值分解
本節(jié)將改變以往采用平均值的方法求取局部均值函數(shù),改用局部積分均值方法求取局部均值函數(shù)。具體步驟如下。
①找出原始信號(hào)中的所有極大值和極小值點(diǎn),將其按順序排列構(gòu)成(tk,xk)。
(10)
2 特征向量的提取
多尺度熵(multiscale sample entropy,MSE)是Costa在2005年提出的理論[6-8],是在樣本熵的基礎(chǔ)上引入尺度因子,表述時(shí)間序列在粗粒化下的樣本熵趨勢(shì),從而分析信號(hào)在不同尺度因子下的復(fù)雜程度和自相似性。多尺度熵的具體步驟如下所示。
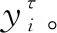
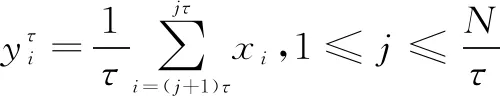
(18)
②根據(jù)尺度因子τ,考慮m維矢量Yτ(i),表示在尺度因子τ下的m個(gè)連續(xù)yτ值,其中m為嵌入維數(shù)。
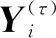
(19)
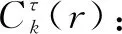
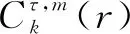
(20)
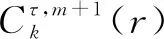
⑦對(duì)于一個(gè)長(zhǎng)度為N的原始時(shí)間序列Xi,其樣本熵值為:
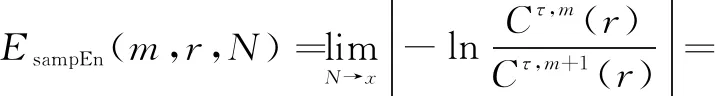
(21)
影響多尺度熵計(jì)算精度的參數(shù)有尺度因子τ、相似容限r(nóng)、嵌入維數(shù)m和信號(hào)長(zhǎng)度N。一般情況下,取r=0.1~0.25SD(SD為原始時(shí)間信號(hào)的標(biāo)準(zhǔn)差),m=2,τ=20,N需足夠大。本文取r=0.2SD,N=2 048。
將多尺度熵作為信號(hào)的特征,得到一個(gè)反映故障信息的特征向量T,即:
T={CMSE1,CMSE2,…,CMSEτ}
3 極限學(xué)習(xí)機(jī)
極限學(xué)習(xí)機(jī)[9](extreme learning machine,ELM)是一種針對(duì)單隱含層前饋神經(jīng)網(wǎng)絡(luò)算法。其最突出的特點(diǎn)是學(xué)習(xí)速度快、泛化能力強(qiáng)、參數(shù)設(shè)定簡(jiǎn)單等。
假設(shè)有Q個(gè)帶標(biāo)簽的數(shù)據(jù)樣本(Xh,Yh)。其中,1≤h≤Q,Xh=[xh1,xh2,…,xhs]T∈Rs為第h個(gè)輸入樣本,Yh=[yh1,yh2,…,yhs]T∈Rr為與之對(duì)應(yīng)的目標(biāo)輸出,s為輸入樣本的維數(shù)。若單隱含層前饋神經(jīng)網(wǎng)絡(luò)中輸入層、隱含層和輸出層的單元數(shù)分別為s、l、r,則該網(wǎng)絡(luò)的輸出可表示為:
式中:g為激活函數(shù);Wc為輸入權(quán)值;bc為第c個(gè)隱含層單元對(duì)應(yīng)的偏置;βc為輸出權(quán)值;Oh為第h個(gè)樣本對(duì)應(yīng)的輸出。
ELM網(wǎng)絡(luò)訓(xùn)練的目標(biāo)是使得輸出誤差最小化,因此定義訓(xùn)練樣本的最小損失函數(shù)為:
式中:H為隱含層單元的輸出矩陣;β為輸出權(quán)值矩陣;Y為樣本目標(biāo)輸出矩陣。
當(dāng)激活函數(shù)無限可微時(shí),單隱含層前饋神經(jīng)網(wǎng)絡(luò)的參數(shù)不必全部調(diào)整,Wc和bc可隨機(jī)初始化并在訓(xùn)練中保持不變,而輸出權(quán)值矩陣β可通過式(22)的最小二乘解得到。
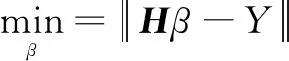
(22)
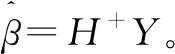
4 故障診斷
為了解決LMD在故障診斷中識(shí)別精度不高的問題,本文采用改進(jìn)的LMD進(jìn)行故障診斷。其具體步驟如下。
①信號(hào)采集。利用振動(dòng)傳感器采集風(fēng)電機(jī)組齒輪箱的故障信號(hào)。
②LMD分解。采用改進(jìn)的LMD對(duì)信號(hào)進(jìn)行分解,得到n個(gè)PF分量。
③計(jì)算互相關(guān)系數(shù)。計(jì)算每個(gè)PF分量和原始信號(hào)的互相關(guān)系數(shù)。
④重構(gòu)信號(hào)。將互相關(guān)系數(shù)大于0.3的PF分量進(jìn)行重構(gòu)。
⑤將重構(gòu)信號(hào)的多尺度熵作為特征向量T。
⑥構(gòu)建極限學(xué)習(xí)機(jī)故障診斷模型。用構(gòu)建的訓(xùn)練樣本集進(jìn)行訓(xùn)練,得到最終的極限學(xué)習(xí)機(jī)故障診斷模型。
⑦故障識(shí)別。將構(gòu)建的測(cè)試樣本集輸入到分類器中,實(shí)現(xiàn)風(fēng)電機(jī)組齒輪箱故障識(shí)別。
5 仿真分析和試驗(yàn)驗(yàn)證
5.1 仿真分析
為了驗(yàn)證改進(jìn)局部均值分解能有效抑制模態(tài)混疊現(xiàn)象,采用AM-FM信號(hào)進(jìn)行仿真分析。該仿真信號(hào)由調(diào)幅頻率為5 Hz,基頻為60 Hz,調(diào)頻頻率為8 Hz的AM-FM信號(hào)和調(diào)幅頻率為10 Hz的正弦信號(hào)構(gòu)成,其表達(dá)式為:
LMD分解如圖1所示。
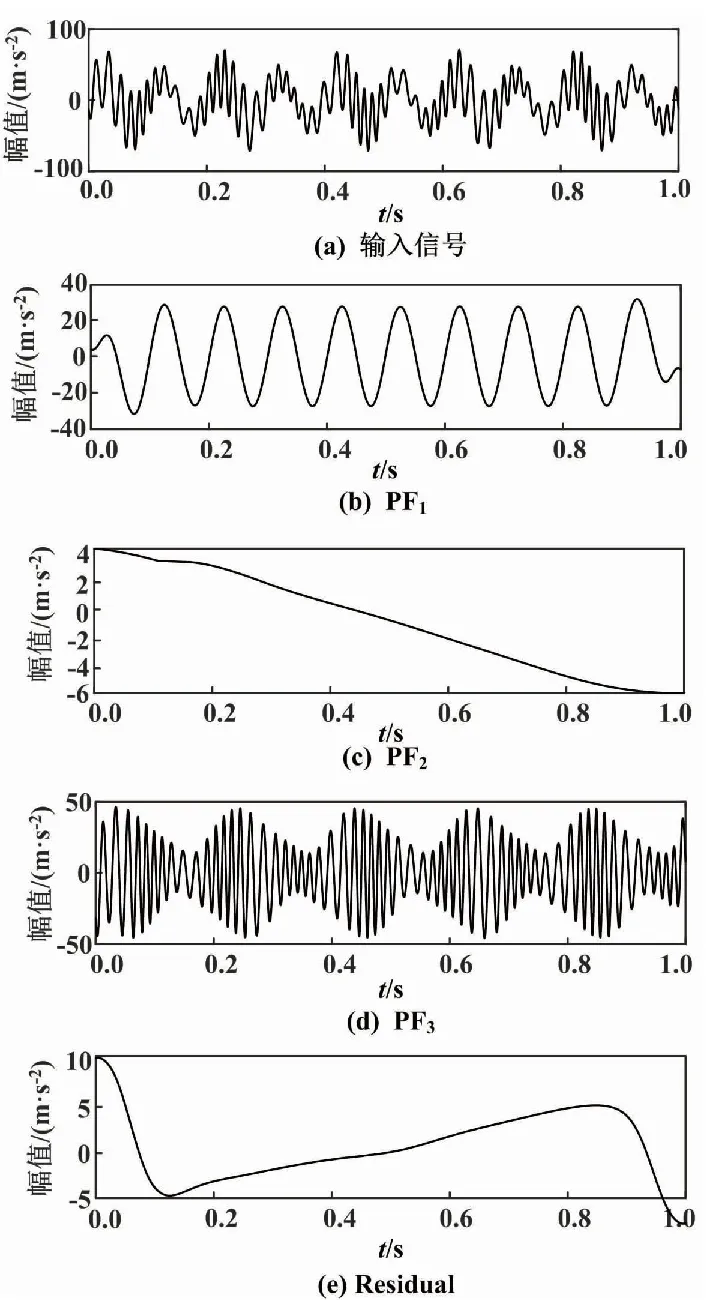
圖1 LMD分解圖
由LMD分解時(shí)域圖可知,采用LMD分解將仿真信號(hào)錯(cuò)誤地分解為3個(gè)PF分量。由PF1包絡(luò)頻譜圖可以看出,PF1中出現(xiàn)模態(tài)混疊現(xiàn)象,在50 Hz左右兩端出現(xiàn)了干擾信號(hào)。
改進(jìn)LMD分解如圖2所示。采用改進(jìn)LMD將信號(hào)準(zhǔn)確的分解為2個(gè)PF分量。由PF1包絡(luò)頻譜圖可知,PF1中未出現(xiàn)模態(tài)混疊現(xiàn)象。通過對(duì)比分析,證明了改進(jìn)LMD方法能有效地抑制模態(tài)混疊現(xiàn)象,分解結(jié)果更準(zhǔn)確。
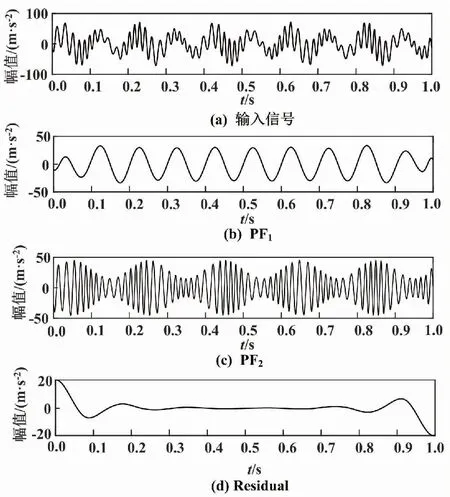
圖2 改進(jìn)LMD分解圖
5.2 試驗(yàn)驗(yàn)證
本文選用美國(guó)凱斯西儲(chǔ)大學(xué)電氣工程試驗(yàn)室提供的滾動(dòng)軸承試驗(yàn)數(shù)據(jù)進(jìn)行分析;采用6205-2RS JEM SKF型深溝球軸承;選用滾動(dòng)軸承驅(qū)動(dòng)端的故障數(shù)據(jù)進(jìn)行分析,其采樣頻率為12 kHz。以轉(zhuǎn)速為1 797 r/min、信號(hào)長(zhǎng)度為1 024的滾動(dòng)軸承內(nèi)圈故障為例進(jìn)行分析,由式(25)計(jì)算得到實(shí)際故障頻率為162.185 2 Hz。
(25)
式中:fr為滾動(dòng)軸承內(nèi)圈旋轉(zhuǎn)頻率;dw=0.312 6 mm為滾動(dòng)體直徑;zw=9為滾珠個(gè)數(shù);Dq=1.537 mm為軸承節(jié)徑;α=0為滾動(dòng)體接觸角。
分別采用LMD和改進(jìn)LMD方法對(duì)滾動(dòng)軸承內(nèi)圈故障信號(hào)進(jìn)行分解。LMD分解時(shí)域如圖3所示。改進(jìn)LMD分解時(shí)域如圖4所示。

圖3 LMD分解時(shí)域圖

圖4 改進(jìn)LMD分解時(shí)域圖
包絡(luò)頻譜如圖5所示。
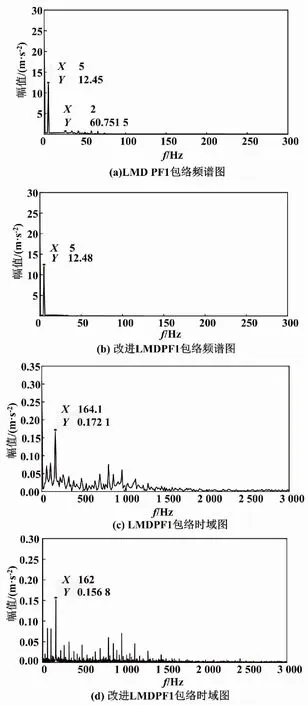
圖5 包絡(luò)頻譜圖
由圖5可知,故障信號(hào)的特征頻率為164.1 Hz,相比實(shí)際特征頻率大了1.914 8 Hz。從包絡(luò)頻譜圖可以得出,故障信號(hào)的特征頻率為162 Hz,相比實(shí)際特征頻率減小了0.185 2 Hz,與滾動(dòng)軸承內(nèi)圈故障特征頻率基本相同。通過對(duì)比采用LMD和改進(jìn)LMD方法對(duì)滾動(dòng)軸承內(nèi)圈故障進(jìn)行分解,結(jié)果表明改進(jìn)LMD方法的分解結(jié)果更準(zhǔn)確。
5.3 故障診斷
選取內(nèi)圈故障、外圈故障、滾珠故障及正常四種故障數(shù)據(jù)共200組,每組樣本長(zhǎng)度為2 048。其中,140組樣本作為訓(xùn)練樣本,其余60組樣本進(jìn)行分類正確率驗(yàn)證。對(duì)四種故障狀態(tài)設(shè)置相應(yīng)的標(biāo)簽,c=[1,2,3,4]。
首先分別采用LMD和改進(jìn)LMD方法對(duì)信號(hào)進(jìn)行分解,然后求取各PF分量和原始信號(hào)的互相關(guān)系數(shù),剔除互相關(guān)系數(shù)小于0.3的分量,對(duì)剩余PF分量進(jìn)行重構(gòu),求取重構(gòu)信號(hào)的多尺度熵值,將ELM作為分類器對(duì)滾動(dòng)軸承進(jìn)行模式識(shí)別。LMD分類結(jié)果如圖6所示。
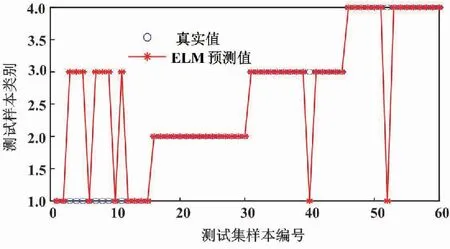
圖6 LMD分類結(jié)果
由圖6可知,采用LMD進(jìn)行預(yù)處理后,分類結(jié)果中有7組內(nèi)圈故障、1組滾珠故障和1組正常出現(xiàn)誤診斷,最終識(shí)別的準(zhǔn)確率為85%。改進(jìn)LMD分類結(jié)果如圖7所示。
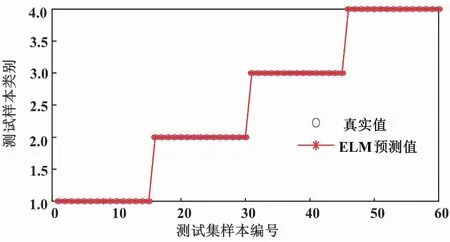
圖7 改進(jìn)LMD分類結(jié)果
由圖7可知,采用改進(jìn)LMD進(jìn)行預(yù)處理后,所有故障均被正確分類,最終識(shí)別的準(zhǔn)確率為100%。通過對(duì)比采用改進(jìn)LMD分解方法和LMD分解方法可得,采用改進(jìn)LMD方法分解最終故障識(shí)別的準(zhǔn)確率更高。
為了進(jìn)一步說明本文所提方法的有效性,將本文改進(jìn)的局部均值分解和極限學(xué)習(xí)機(jī)的故障診斷方法與支持向量機(jī)(support vector machine,SVM)、最小二乘支持向量機(jī)(least squares support vector machine,LSSVM)的故障診斷方法進(jìn)行比較,采用同一數(shù)據(jù)進(jìn)行模式識(shí)別。故障診斷結(jié)果對(duì)比如表1所示。

表1 故障診斷結(jié)果對(duì)比
上述分析可得,本文所提的基于改進(jìn)的LMD和極限學(xué)習(xí)機(jī)的故障診斷效果明顯好于其他2種故障診斷方法,充分說明了本文方法能提高故障診斷的識(shí)別精度。
6 結(jié)論
本文針對(duì)LMD方法中存在模態(tài)混疊問題,提出了基于局部積分均值的LMD改進(jìn)算法。通過仿真分析驗(yàn)證了本文所提方法能夠精準(zhǔn)地對(duì)仿真信號(hào)進(jìn)行分解,并有效地抑制了模態(tài)混疊現(xiàn)象。將本文所提的改進(jìn)LMD方法應(yīng)用到風(fēng)電機(jī)組齒輪箱故障診斷中,通過多尺度熵準(zhǔn)確提取出故障信號(hào)的特征向量,最后采用極限學(xué)習(xí)機(jī)進(jìn)行故障診斷。通過仿真分析,證明了本文所提方法優(yōu)于其他方法,為風(fēng)電機(jī)組的可靠運(yùn)行提供了可靠保障。
猜你喜歡
汽車維修與保養(yǎng)(2019年7期)2020-01-06 03:30:42
汽車維護(hù)與修理(2016年10期)2016-07-10 08:17:41
湖北經(jīng)濟(jì)學(xué)院學(xué)報(bào)·人文社科版(2015年8期)2015-12-29 05:53:07
重慶工商大學(xué)學(xué)報(bào)(自然科學(xué)版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(yǎng)(2015年6期)2015-04-17 03:31:50
上海電機(jī)學(xué)院學(xué)報(bào)(2015年4期)2015-02-28 14:30:00
汽車維護(hù)與修理(2015年2期)2015-02-28 12:15:39
計(jì)算物理(2014年2期)2014-03-11 17:01:39
振動(dòng)、測(cè)試與診斷(2014年5期)2014-03-01 01:14:21
機(jī)械與電子(2014年1期)2014-02-28 02:07:31
