一種顧及時間特征的船舶軌跡DBSCAN聚類算法
2021-05-11 03:41:20郭乃琨陳明劍
測繪工程 2021年3期
郭乃琨,陳明劍,陳 銳
(1.信息工程大學 地理空間信息學院,河南 鄭州 450001;2.92493部隊,遼寧 葫蘆島 125001)
近年來,全球衛星導航系統(Global Navigation Satellite System,GNSS)、北斗衛星導航系統(BeiDou Navigation Satellite System,BDS)等衛星導航定位系統迅速發展,已經成為國防軍事、國民經濟發展中必不可少的基礎設施[1]。
隨著世界海洋經濟的迅速發展,各國海洋貿易中的船舶數量隨之劇增,船舶自動識別系統(Auto Identification System,AIS)已被世界各國廣泛采用。全球船舶軌跡數量龐大、內容豐富,除了與常見的陸上軌跡一樣具有海量性、動態性、時序性特征外,還具有一系列的獨特性,陸上軌跡主要反映對象在陸地上的時空變化規律與行為模式,而船舶軌跡主要反映對象在海上的相應規律與模式;船舶軌跡在形成過程中,更多地受到水系的固有約束,并且其數據相比陸上軌跡具有更多的字段,屬性維度更高。因此,運用簡單、常規的數據分析方法很難從船舶軌跡中分析出全面、有價值的隱含信息。
聚類分析是眾多數據分析與挖掘方法中應用最廣泛的方法,通過衡量研究對象之間的相似度(距離度量),將相似度高的對象劃分為同類。按照聚類的目標、處理的數據以及具體應用領域的不同,聚類分析可分為基于劃分的聚類、基于層次的聚類、基于密度的聚類、基于網格的聚類和基于模型的聚類。其中,基于密度的聚類是近年來在交通流挖掘、商業中心選址、圖像分割與識別等諸多領域得到廣泛應用的經典聚類算法,其中又以基于密度的對噪聲魯棒的空間聚類算法(Density-Based Spatial Clustering of Application with Noise,DBSCAN)最為常用。DBSCAN算法相比其他算法無需指定簇的個數,可以對任意形狀的數據集進行聚類,常用于離群點監測。但經典的DBSCAN算法僅適用于空間聚類,對于具有時間、航速等多維、動態信息的船舶AIS軌跡而言不再適用。本文提出一種顧及時間特征的船舶軌跡DBSCAN聚類算法,在經典DBSCAN的基礎上,通過定義船舶軌跡間的時間距離來衡量其時間相似度,進而定義時空距離來衡量時空相似度,實現船舶軌跡的時空聚類。
1 相關工作
1.1 經典DBSCAN算法
DBSCAN是一種典型的基于密度的聚類算法,最初主要用于點或可視為點對象的聚類,通過將簇定義為密度相連的點的最大集合,可以有效找到樣本點的全部密集區域,這些密集區域即被視為聚類簇[2]。DBSCAN算法的聚類過程如圖1所示。

圖1 經典DBSCAN算法流程
目前的相關研究主要圍繞對經典DBSCAN算法的聚類效果改進而展開。許虎寅等[3]在DBSCAN算法的基礎上,提出一種改進的基于密度的聚類算法,有效減少核心點鄰域的重疊區域的查詢時間和次數;王光等[4]提出一種改進的自適應參數DBSCAN算法,對MinPts和Eps參數基于核密度估計進行確定,基于4種經典數據集的對比實驗證明該算法在參數選擇自動化和準確率方面的優勢;李建伏等[5]基于馬爾科夫鏈蒙特卡洛方法MCMC對DBSCAN方法進行改進,提出一種基于MCMC的DBSCAN算法DBSCAN++,并且與經典DBSCAN算法和OPTICS算法進行對比分析實驗,結果表明DBSCAN++算法聚類的高效性與準確性。
1.2 船舶軌跡聚類算法
船舶軌跡聚類的目的是采用相關的聚類算法對軌跡數據進行聚類,找出具有相似船舶運動演化方式的軌跡簇[6-8],揭示船舶軌跡間潛在的關系,分析船舶交通流特征或個體船舶的行為。通過對船舶軌跡數據進行處理和聚類分析,可以對船舶的運動規律進行量化,并進一步探測船舶的異常行為,從而有效提升海上交通態勢感知能力,為海事安全監控與預測提供決策支持。船舶軌跡數據一般是指基于AIS的軌跡數據[9],主要是從AIS基站獲得,因此當前大部分的船舶軌跡聚類研究均為針對船舶AIS數據的聚類分析,其分析流程如圖2所示。

圖2 船舶AIS軌跡聚類流程
船舶 AIS軌跡數據采集的過程中,需要對船舶 AIS軌跡數據進行預處理,以提高數據質量,常見的預處理過程包括數據編碼與清洗、缺失數據處理、降維處理、數據壓縮等內容:船舶軌跡聚類方面,Huttenlocher等人[10]證明利用Hausdorff距離比其他度量兩個點之間距離的相關算法具有更強的魯棒性;Zheng等[11]將K-Means聚類算法用于船舶軌跡的聚類,用歐式距離計算船舶軌跡相似度,利用開源數據挖掘工具WEKA對長江某航段船舶到達時間、船舶噸位、船舶類型等屬性分別進行聚類,獲得有價值的交通特性信息[12];Vries等人[13]將船舶軌跡看作時間序列,采用態時間規整(Dynamic Time Warping,DTW)和ED來計算軌跡的相似度;Pallotta等人[14-15]對DBSCAN算法進行改進,采用增量DBSCAN算法對船舶AIS軌跡數據中的轉向點聚類,在此基礎上分析船舶的交通流模式。Liu等人[16]在考慮船舶軌跡數據中非空間屬性(如船速、航向等)基礎上,對DBSCAN算法進行改進,在輸入參數中新增船舶最大的船速變化量(MaxSpd)和最大的航向變化量(MaxDir)兩個變量。
1.3 相關研究分析
傳統的軌跡聚類方法主要面向居民日常出行、活動和旅游等現實場景,如常見的出租車軌跡聚類、熱點區域分析、居民出行模式挖掘、載客路徑挖掘、重要興趣點識別等,面對復雜問題時需要設置的條件和參數較多,并且大部分方法的可移植性較差,很難被應用到新的數據集上。上述船舶軌跡聚類的相關研究中,基于距離的聚類方法對船舶軌跡進行聚類具有算法簡單、實現容易的優點,但由于基于距離的軌跡相似度度量方法本身的不足,仍然存在容易丟失軌跡局部特征信息等不足;與基于距離的船舶軌跡聚類方法相比,采用經典DBSCAN等基于密度的聚類算法對船舶軌跡進行聚類,其優勢主要表現在能發現任意形狀的船舶軌跡簇,且對異常的船舶軌跡魯棒性較強,軌跡聚集的結構與樣本軌跡的遍歷順序也無關。但DBSCAN算法主要適用于空間聚類,即通過定義空間距離對象的空間相似度進行衡量,對于具有典型的多維、時變和空間動態特征的船舶軌跡很難達到理想的聚類分析效果。
2 顧及時間特征的船舶軌跡DBSCAN聚類算法
2.1 算法概述
鑒于經典DBSCAN算法主要適用于空間聚類,對具有時變動態信息的船舶軌跡聚類適用性差的現狀,本文提出一種顧及時間特征的船舶軌跡DBSCAN聚類算法。該算法在經典DBSCAN空間聚類算法的基礎上,首先對船舶軌跡數據進行數據編碼與清洗、缺失數據處理、數據壓縮等一系列預處理,在此基礎上提出了基于OD(Origin-Destination)點 、SP(Stay-Point)點以及TF(Trajectory-Feature)點的軌跡特征點提取方法,以此生成船舶AIS軌跡的子軌跡;然后提出船舶子軌跡段之間的時間距離度量方法,并通過設置權重調整時空特征敏感度,最后使用DBSCAN算法對時空鄰域密度進行聚類分析,進而挖掘船舶軌跡的典型時空運動模式。相比于空間聚類,顧及時間特征的船舶軌跡DBSCAN聚類算法可以同時兼顧船舶軌跡的空間與時間特征,得到的聚類可以更加細化,移動通道更準確,有利于對船舶的移動規律做更進一步的分析,進而為合理規劃航路及海事監管中的熱點航道提取和異常事件預防提供有效的決策手段和參考信息。
2.2 算法流程
本文提出的顧及時間特征的船舶軌跡DBSCAN聚類算法流程如圖3所示。

圖3 顧及時間特征的船舶AIS軌跡聚類流程
2.2.1 船舶軌跡數據預處理
首先是數據準備工作,將采集到的船舶軌跡數據,利用空間關系型數據庫(如PostgreSQL)進行存儲,數據庫表的內容主要包括MMSI碼、船舶位置、航向、航速、船舶大小、UTC時間等。由于船舶AIS設備以“明碼”和“暗碼” 兩種壓縮編碼的形式傳輸數據,運用AIS數據解析程序從原始數據中提取所需內容并導入數據庫。
然后是軌跡數據預處理工作,船舶軌跡原始數據通常存在噪聲和偏差的問題。為了保證后續軌跡特征點選取的精度和速度,需要對船舶軌跡數據進行預處理:刪除MMSI碼錯誤的數據;刪除船舶位置的經緯度出現負值或是經度大于180°、緯度大于90°的數據;刪除航速為負值或大于60 kn的數據;刪除超過研究水域范圍的數據等。
2.2.2 特征點提取
將每條船舶軌跡按照OD點 、SP點和TF點的判定條件進行軌跡特征點的提取,將提取出的三類軌跡特征點組成代表該條軌跡運動規律的特征點集合。將集合中的相鄰特征點按時間先后順序排列依此連接生成該條軌跡的子軌跡。最終由這些特征點集合生成所有船舶軌跡的子軌跡集合。其中,通過如下方法對OD點、SP點和TF點進行篩選和提取。
首先,將每條船舶軌跡的起點和終點選取為該條船舶軌跡的OD點。然后通過設置時間閾值和速度閾值,如果相鄰軌跡點之間時間差大于特定的時間閾值,而兩個軌跡點的速度值都小于設定的速度閾值,則將兩個相鄰的軌跡點識別為該條船舶軌跡的停泊點,記為SP點。最后利用曲線邊緣檢測法對每條船舶軌跡的所有軌跡點進行識別,將符合判定條件的軌跡點選取為軌跡特征點,記為TF點,曲線邊緣檢測法的過程如下:
1)假設給定一條船舶運行軌跡,其中的P1(x1,y1),P2(x2,y2),P3(x3,y4)(x1 T12(x,y)=(y2-y1)(x-x1)+ (y-y1)(x2-x1). 2)計算軌跡點P3(x3,y3)關于正向直線方程T12的值,若T12(x3,y3)<0,則稱軌跡點P3(x3,y3)是關于正向直線的內點;若T12(x3,y3)>0,則稱軌跡點P3(x3,y3)是關于正向直線外點。 3)連接軌跡點P2(x2,y2)和P3(x3,y3)構成一條關于軌跡的正向直線T23,對應的正向直線方程為: T23(x,y)=(y3-y2)(x-x2)+ (y-y2)(x3-x2). 4)計算軌跡點P4(x4,y4)關于正向直線方程T23的值,并根據上述方法判斷軌跡點P4(x4,y4)為內點或外點。 5)若T12(x3,y3)·T23(x4,y4)<0,說明軌跡在P3(x3,y3)處方向有所改變,則軌跡點P3(x3,y3)是特征點,即為TF點,否則P3(x3,y3)不是TF點。 6)依次循環判斷,直到最后一個軌跡點,即可識別出船舶運行軌跡的所有TF點。 2.2.3 子軌跡段劃分 根據上述提取出的三類軌跡特征點(OD點、SP點和TF點)組成該船舶運行軌跡的特征點集合,將特征點集合中的相鄰特征點按時間先后順序排列,依次連接生成該條軌跡的子軌跡,其中相鄰兩個特征點的線段稱為子軌跡段,如圖4所示。 圖4 子軌跡段劃分流程 2.2.4 時空距離定義與計算 這一步主要計算任意兩子軌跡段之間的空間距離和時間距離,對得到的空間距離和時間距離進行加權求和得到融合后的時空距離。 1)空間距離定義與計算。本文中兩子軌跡段之間的空間距離是根據船舶位置信息計算得到的,包括平行距離、垂直距離和角度距離3個方面。設兩條子軌跡段Li和Lj,記為Li(si,ei)和Lj(sj,ej),其中si,ei和sj,ej分別為子軌跡段Li和子軌跡段Lj的起點和終點的位置信息,由子軌跡段Lj向Li垂直投影,如圖4所示,其中,Ps和Pe為Lj在Li上的垂直投影點。則子軌跡段Li和Lj之間的垂直距離為: 子軌跡段Li和Lj之間的平行距離為: d‖(Li,Lj)=MIN(l‖1,l‖2); 角度距離為: dθ(Li,Lj)= 綜上,得到子軌跡段Li和子軌跡段Lj之間的空間距離為: DS=d⊥(Li,Lj)+d‖(Li,Lj)+dθ(Li,Lj). Δtij=max(tie,tje)-min(tis,tjs). 則子軌跡段Li和Lj之間的時間距離DT為 其中,兩子軌跡段之間的時間距離由時間跨度、時間差和航速的速度均值共同決定。為了更簡單地計算時間距離,上述中的速度均值也可以采用子軌跡段中的任一點的速度,這是由于在短時間內,子軌跡段內的船舶航速基本不會變化。 使用均值絕對偏差對空間距離Ds標準化為: 其中,Dsn服從高斯分布;同理可按照上述過程得到時間距離的標準化值Dtn,則時空距離的算式為: DST=ωs×Dsn+ωt×Dtn. 其中,Dsn為將空間距離通過Z-Score分數方法進行標準化處理得到,Dtn為將時間距離DT通過Z-Score分數方法進行標準化處理得到,ws為空間距離的權重系數,wt為時間距離的權重系數,兩者表征空間距離和時間距離的敏感度,可根據實際情況進行設定,且滿足ωs+ωt=1。 5)船舶軌跡聚類。這一步主要根據獲取的時空距離,通過DBSCAN算法對各子軌跡段進行聚類。聚類時,從任一子軌跡段出發,計算與其他所有子軌跡線段間的時空距離,根據獲取的各子軌跡段間的時空距離,給定ε-鄰域范圍和最小線段參數(MinLns),統計滿足ε-鄰域范圍的線段個數,并與最小線段參數(MinLns)進行比較,當ε-鄰域范圍內的線段數目大于給定的最小線段參數(MinLns)時,該子軌跡段即為核心軌跡,形成一個聚類,其鄰域內的直接密度可達線段也將聚類到該類中,再對剩余的其他子軌跡段按照同樣的方式依次進行聚類擴展,得到最終的聚類結果;而其中未被聚成一類的子軌跡段則是孤立軌跡,不作處理。其中,關于DBSCAN的各項參數表示或計算如下:ε-鄰域范圍Nε(Li)為子軌跡段Li在線段集D(Li∈D)內所有與其時空距離不超過ε的軌跡集合,即表示為Nε(Li)={Li∈D|Ddist(Li,Lj)≤ε};子軌跡段Li的線段集為D(Li∈D),給定鄰域范圍ε和最小線段參數MinLns,若滿足|Nε(Li)|≥MinLns,則認為Li為核心軌跡;子軌跡段Li的線段集為D(Li∈D),給定參數鄰域范圍ε和最小線段參數MinLns,若Li為核心軌跡且Lj在Li的ε鄰域范圍內,則稱Lj從Li直接密度可達;子軌跡段Li的線段集為D(Li∈D),給定參數鄰域范圍ε和最小線段參數MinLns,若存在從Li到Lk直接密度可達,從Lk到Lj直接密度可達,則從Li到Lj密度可達;子軌跡段Li的線段集為D(Li∈D),給定參數鄰域范圍和最小線段參數MinLns,若存在Li和Lj均由Lk密度可達,則Li和Lj密度相連。 6)時間和空間距離權重系數確定。在上述流程中,時間距離和空間距離的權重系數需要確定。為了得到最佳的聚類效果,本文確定的原則是,基于戴維森堡丁(Davies Bouldin Index,DBI)指數[17]來量化不同權重系數下的聚類質量,而DBI指數與時空距離權重系數之間存在一一對應關系,含義是度量每個簇類最大相似度的均值,能夠較好的體現不同權重系數取值的聚類質量。DBI的值最小是0,不同權重系數下求得的DBI指數越小,聚類效果越好,同時也證明權重系數更優。DBI指數又稱分類適確性指標,是一種評估聚類算法優劣的指標,其計算方法為:首先假設實驗數據有m個時間序列,這些時間序列聚類為n個簇,m個時間序列設為輸入矩陣X,n個簇類設為N作為參數傳入算法,則DBI指數的算式為: 其中,各項參數的計算公式如下: 其中Xj代表簇類i中第j個數據點,也就是一個樣本點;Ai是簇類的質心;Ti是簇類中數據的個數。 2)距離值Mi,j定義為簇類i與簇類j的距離,算式為: 其中,ak,i代表簇類質心點的第k個值;Mi,j就是簇類i與簇類j質心的距離,即ak,i表示第i類的中心點的第k個屬性的值,Mi,j則就是第i類與第j類中心的距離。 3)相似度值Ri,j用于衡量第i類與第j類的相似度,算式為: 4)在上述基礎上,做一個基于簇類數n的n2的嵌套循環,對每一個簇類i計算Ri,j的最大值,記為Di=max(Ri,j),即簇類和其他類的最大的相似度值。然后對所有類的最大相似度取平均值就得到了DBI指數,算式為: 通過以上步驟,就能夠直觀地分析出不同權重下聚類結果質量的高低,從而確定聚類質量最優的權重系數,進而準確地對船舶運行的子軌跡進行聚類。 測試服務器為Thinkpad T440,AMD雙核CPU,4 GB內存,256 G固態硬盤容量;操作系統采用Windows 10 64位旗艦版,實驗程序運行環境為Pycharm 2018.1,程序語言及其版本為Python 3.6.2。 為對本文所提算法的有效性進行驗證,選取東海某海域(113°45′37″E~130°23′43″E,17°47′29″N~38°52′59″N)2016年2月9日到2016年3月6日真實船舶AIS軌跡數據進行測試,其中每條軌跡由相互緊鄰的樣本點連接而成。原始數據共計320 001個采樣點,按照船舶MMSI標識整理后共得到260條軌跡;由于部分軌跡中的船舶點位過少,生成的軌跡無法代表其航行軌跡,因此對這部分無效軌跡進行剔除,得到249條有效軌跡。 由于從上述初步得到的每條軌跡中提取關鍵點需要迭代的次數較多、工作量較大,需要對每條船舶軌跡進行壓縮。數據壓縮有多種方法,在GIS領域常見的矢量數據壓縮方法有道格拉斯-普克法(Douglas-Peucker Algorithm)、垂距法、光欄法等,其中道格拉斯-普克法較為經典且使用較廣。對于一條曲線軌跡,道格拉斯-普克法通過循環連接首尾兩點,并計算中間各點到上述連線的距離,將最大距離值dmax與限差D進行比較,若dmax 圖5 船舶AIS軌跡數據壓縮前后對比 在上述數據壓縮的基礎上,接下來對實驗船舶軌跡進行特征點提取。首先,通過對實驗數據的分析,將SP點的提取采取的時間閾值為8 min,航速閾值為0.8 kn。然后,通過對每條軌跡的OD點、SP點和TF點進行提取,從而得到能夠代表每條船舶軌跡的特征點集合,以此形成子軌跡集合。眾多子軌跡在某些子段處會出現重疊,因此按照上文的子軌跡段劃分方法對249條軌跡進行劃分,共得到2 396條子軌跡。然后利用本文提出的顧及時間特征的船舶軌跡DBSCAN算法對子軌跡段實施聚類,在確定時間距離和空間距離各自的權重系數時,利用DBI指數來進行判定,部分試驗結果如表1所示。 由表1可知,當空間距離權重ωs=0.56、時間距離權重ωT=0.44時,DBI的值最小,聚類效果最佳。因此,最終時空距離計算中的空間距離權重系數確定為0.56,時間距離權重確定為0.44。在此基礎上,利用本文的算法對上述所有的船舶子軌跡段進行聚類,最后對相似的子軌跡進行融合形成。實驗過程中發現該算法對聚類參數ε和MinLns較為敏感,因此通過反復試驗,最終確定ε=0.003 nmile,MinLns=3時,聚類效果較為理想。結果如圖6所示。 表1 基于不同時、空距離權重取值的部分DBI指數計算結果 圖6 船舶AIS軌跡數據聚類前后對比 此外,為了驗證本文算法的優劣,將其與經典的DBSCAN空間聚類算法的效果進行對比。在選用相同的數據集的基礎上,兩者在耗時、準確度、分類數等方面的對比如表2所示。 表2 本文算法與經典DBSCAN算法的優劣對比 由圖6可知,在實驗船舶軌跡數據集上,通過本文的聚類算法,成功將軌跡數據集分成4個有效類簇(每個類簇以一種顏色表示),即本文算法成功地從原始軌跡中提取出4條典型軌跡,這4條軌跡可以形象地反映出該船舶在1個月時間內的空間位置變化規律和航行模式。由表2可知,本文提出的顧及時間特征的船舶軌跡聚類算法在耗時上略遜于經典DBSCAN算法,這是由于本文算法除了要計算空間距離外,還需要計算兩子軌跡之間的時間距離,然后計算時空距離,其中涉及的相似性度量相對復雜,因此使得算法的復雜度升高。但由于本文算法同時兼顧時空距離,更易于發現經典DBSCAN算法無法發現的隱蔽群,使得算法的準確率和聚類數目有較大提升。 此外,考慮本文算法隨著船舶軌跡數據集增長時的效能變化,分別在前文數據集27 d,45 d,60 d數據集上進行實驗,實驗流程與上述流程保持一致,統計不同數據集上的原始軌跡數、劃分子軌跡數和耗時如表3所示。 表3 基于不同規模數據集的本文算法性能對比 由表3可知,隨著數據集的增大,本文算法的耗時呈現急劇上升的趨勢,因此在后續研究中,需要關注如何優化算法的過程與結構,從而有效降低聚類的時間消耗。 作為時空大數據范疇中對地理信息環境中社會感知數據的重要表現形式,軌跡數據能夠有效表征時空對象的移動規律,具有重要的應用價值。船舶軌跡數據具有多維、動態特征,能夠表征船舶的時空移動狀態,為預測船舶的出行規律和行為模式提供信息支撐。本文在現有經典DBSCAN聚類算法的基礎上,設計并實現一種顧及時間特征的船舶軌跡DBSCAN聚類算法,通過引入時間相似性度量方法,對船舶軌跡數據進行分段并計算其時空距離,實現對船舶軌跡的時空聚類。最后進行實驗驗證,通過與經典DBSCAN算法進行效能對比,結果證實本文算法的有效性。不足之處在于隨著船舶軌跡數據規模的擴大,算法的耗時會急劇增長,因此如何對該算法進行優化,有效降低算法的聚類開銷,是后期的研究方向。
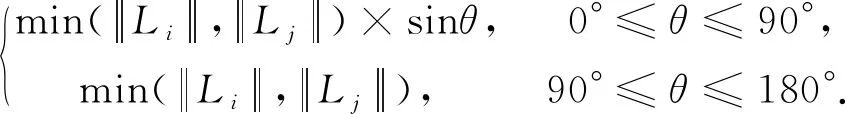



3 實驗驗證
3.1 實驗環境
3.2 實驗流程與結果




3.3 實驗分析

4 結束語
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28艦船科學技術(2022年14期)2022-09-22 03:07:40艦船科學技術(2022年2期)2022-03-29 01:12:44世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36小哥白尼(趣味科學)(2019年10期)2020-01-18 09:16:22瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28船舶標準化工程師(2019年4期)2019-07-24 07:21:12當代陜西(2019年10期)2019-06-03 10:12:04數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54中國船檢(2017年3期)2017-05-18 11:33:09
