基于長短期記憶網絡的電力系統量測缺失數據恢復方法
2021-05-12 03:16:58王子馨胡俊杰劉寶柱
電力建設 2021年5期
王子馨,胡俊杰,劉寶柱
(華北電力大學電氣與電子工程學院,北京市 102206)
0 引 言
隨著電網的快速發展,我國基本形成了送、受端結構清晰,交、直流協調發展的骨干網架[1-2]。電網規模的不斷擴大以及電力電子設備的不斷投入使電網的時空特性日益復雜[3-4]。傳統的監視控制與數據采集系統(supervisory control and data acquisition,SCADA)由于數據采集密度低以及傳輸過程間隔較長,無法滿足復雜系統狀態估計和動態實時監測的要求[5],而廣域測量系統(wide-area measurement system,WAMS)因其高精度、同步測量等優點,在系統動態分析控制等方面發揮著越來越重要的作用。
與此同時,隨著電力系統量測技術的快速發展及量測成本的不斷下降,量測數據呈現快速增長趨勢,逐步具備了大數據特征[6]。海量多類型的量測數據對電力系統狀態估計、設備評估、優化運行、事故分析等具有重要意義[7-8]。隨著數據挖掘技術的發展,海量量測數據的傳輸、存儲和分析也成為電力系統領域重要的研究方向。
在此背景下,獲取更為真實可靠的電力系統量測數據變得越來越重要。然而由于氣候變化、噪聲干擾、通信延遲等多種復雜因素影響,數據采集、量測、傳輸和存儲過程中往往存在數據缺失等問題,導致無法獲取真實可靠的量測數據。2009年,美國高德納信息咨詢公司(Gartner)針對140家公司做過一次調查,其中22%的公司估計其每年因數據質量問題造成的經濟損失高達2 000萬美元。2011年,美國California ISO發布的“五年計劃”指出北美約有10%至17%的量測數據存在質量問題。2017年,全球能源互聯網研究院在《大數據背景下電網數據質量研究與實踐》報告中指出目前我國電力系統量測數據存在較為嚴重的質量問題。缺失數據嚴重影響電力系統狀態估計、參數辨識等,導致電網運行狀態無法及時準確獲取,甚至威脅電網安全穩定運行[9-10]。
目前,國內外學者針對缺失數據問題提出了眾多處理方法,主要可分為后評估和預處理兩大分支。后評估是基于狀態估計的相關方法。該類方法利用冗余量測和系統拓撲結構,構造狀態方程恢復缺失數據。文獻[11]提出了一種基于擴展卡爾曼濾波的動態狀態估計方法,用于估計系統缺失的量測數據。文獻[12]利用時間相關性和測量一致性,提出了一種廣義魯棒估計器,實現缺失量測數據的恢復。后評估的方法雖然可實現缺失數據的準確恢復,但其估計時間較長,需要系統拓撲參數。預處理則為數據驅動,通過研究已知數據,獲取數據規律實現對缺失數據的補充。文獻[13]提出了一種線性插值的方法,恢復系統中缺失的相量數據。在此基礎上,文獻[14]將改進三次樣條插值與優先級分配策略相結合,提高了系統動態下缺失數據的恢復精度。文獻[15]提出基于低秩矩陣填充理論的電能質量感知數據補全方法。文獻[16]計及數據缺失曲線相似度,同樣將低秩矩陣填充理論用于恢復缺失的電量數據。文獻[17]則提出了一種基于張量分解的數據恢復方法,將數據分解為時間、位置和變量三個維度。同時,隨著深度學習技術在電力系統中的應用,電力系統量測數據的時序性、相關性、規律性都可以作為缺失數據恢復的重要依據。文獻[18]采用淺層自動編碼器神經網絡對數據間特性進行學習實現數據恢復。文獻[19]提出了改進生成式對抗網絡學習量測數據間復雜的時空特性,利用真實性約束及上下文相似性約束優化隱變量,從而實現數據準確恢復。但上述網絡模型較為復雜,不易于應用。此外,文獻[20]利用電力系統量測數據的時序特性,提出了一種基于長短期記憶(long short-term memory,LSTM)網絡的數據生成方法。文獻[21]同樣基于長短期記憶網絡提出了負荷短期預測的方法。LSTM網絡可有選擇記憶序列信息,對量測數據有著良好的適用性,且易于實現。
基于上述背景,本文計及電力系統量測數據的時序特性,提出一種基于長短期記憶網絡的電力系統量測缺失數據恢復方法。該方法可構造已有數據對缺失數據的映射,并可有選擇地記憶對缺失數據影響較大的信息。同時為進一步提高系統不同狀態和不同缺失位置下的恢復精度,提出基于隨機森林的狀態辨識方法和缺失數據恢復策略。最終通過仿真數據和實測數據進行驗證,結果表明該方法依靠數據驅動,在不同數量的缺失情況下恢復的數據均能保持較高的準確率。
1 基于LSTM網絡的缺失數據恢復
本節將重點介紹LSTM網絡單元結構,建立雙層全連接的LSTM網絡結構模型,并分析所提LSTM網絡應用于電力系統缺失數據恢復的適用性。
1.1 LSTM網絡單元結構
電力系統量測數據呈現時序特性,本文以廣域測量系統中同步相量測量單元(phasor measurement units,PMUs)量測數據為例進行分析。系統某動態條件下量測的結果如圖1所示。幅值X可看作時間t的函數,X=f(t)。假設在t3—t4時段幅值數據缺失。

圖1 動態數據示意圖
LSTM網絡是一種特殊的循環神經網絡(recurrent neural network,RNN),由于其獨特的門結構,使梯度沿時間反向傳播時可經過較長的距離,從而降低梯度消失的可能。同時,作為一種用于序列學習的體系結構,LSTM網絡可有選擇地篩選并遺忘之前序列中的某些信息以減少對后續序列的影響[22-23]。因此,LSTM網絡可用于如圖1所示的電力系統量測數據的處理,其單元結構如圖2所示。

圖2 LSTM網絡單元結構
LSTM網絡在傳統RNN的隱含層中增加了一個細胞狀態Ct,并利用遺忘門ft、輸入門it和輸出門ot實現對信息傳遞的控制。在t時刻,該網絡單元有3個輸入和2個輸出。輸入分別為當前時刻的輸入xt,上一時刻的輸出ht-1以及上一時刻的細胞狀態Ct-1。輸出為當前時刻的輸出ht和當前時刻的細胞狀態Ct。其中,ht負責記憶序列短期特征,Ct負責記憶序列長期特征。
遺忘門ft決定細胞狀態中保存或丟棄前序信息長期特征的程度,可表示為:
ft=σ(Wf·[ht-1,xt]+bf)
(1)
式中:ft為t-1時刻輸出ht-1、t時刻輸入xt和偏置項bf的激活值,激活函數為sigmoid,激活函數將ft縮放至0(完全遺忘)和1(完全記憶)之間;Wf為權重項,包括Wfx和Wfh。
輸入門it確定如何更新細胞狀態,即將新的信息選擇性地記憶到細胞狀態Ct,公式如下:
(2)

輸出門ot決定當前時刻的輸入,與輸入門類似,ht由ot和Ct確定攜帶的信息,公式如下:
(3)
式中:Wo為權重項,包括Wox和Who;bo為偏置項。
基于以上分析,將LSTM網絡應用于如圖1所示的幅值數據恢復,針對t3—t4時段的缺失數據,遺忘門會有選擇地增加前序信息中類似時段的數據(如t1—t2時段),遺忘其余部分時段的數據。同時由于幅值在t3時刻前正逐漸減小,輸入門會記憶序列短期的變化規律,將幅值逐漸減小的信息增加到細胞Ct中,最后通過輸出門決定輸出。通過上述若干非線性變化,可實現高維函數的逼近,挖掘幅值數據中的隱藏信息以實現t3—t4時段缺失數據的恢復。
1.2 雙層全連接LSTM網絡缺失數據恢復
為了更好耦合電力系統量測數據的時序特性,本文組合多個LSTM網絡單元,提出一種雙層全連接的LSTM網絡結構,可實現已知數據到缺失數據的映射,如圖3所示。

圖3 雙層LSTM網絡模型
設時間t內,幅值數據為D=X1,X2, …,Xmn。對幅值數據標準化處理,令m個數據為1組,共n組,首先建立模型的輸入層。每組數據對應一個輸入xi,其中x1={X1,X2, …,Xm},x2={X2,X3, … ,Xm+1}, …,xn={X(n-1)m+1, X(n-1)m+2, … ,Xnm}。然后將多個LSTM單元組合為一層,通過兩層LSTM網絡與Dense全連接組成形成隱藏層。第一層LSTM網絡將輸入的xi通過特定結構隱投影到高維空間,其中包含了幅值數據Xi,Xi+1, … ,Xi+m間的相互關系。同時根據獨特的門結構進行判斷,決定記憶或遺忘某些特征。第二層LSTM網絡將hi提煉為與恢復數據X′m+k+i具有線性關系的多變量。Dense全連接層可視為回歸層(regression layer),將LSTM網絡提取的特征hi(狀態變量)轉化為恢復的缺失數據X′m+k+i。輸出層最后通過迭代和反標準化實現對缺失數據的恢復。
本文對于上述網絡采用反向傳播算法(backpropagation through time algorithm, BPTT)[24],計算網絡中各參數值。通過反向計算每個神經元的誤差項δ,誤差項將沿著時間反向并向上一層傳播。根據誤差項可得各時刻權重梯度,即可完成所提LSTM網絡訓練,同時也避免了梯度爆炸和梯度消失的問題。
2 基于隨機森林的量測數據狀態辨識
由于量測數據可能處于系統不同運行狀態下,而不同狀態下的數據時序特性不同,所需LSTM網絡模型參數不同,因此需提出一種數據狀態的辨識方法。隨機森林方法綜合Bagging集成學習算法和隨機子空間方法的思想,算法構建簡單,準確性高,比傳統決策樹方法具有更強的泛化能力[25],因此,本文提出基于隨機森林的數據狀態辨識方法。電力系統穩態量測數據和動態量測數據如圖4所示。

圖4 穩態數據和動態數據
圖4中,方框表示量測數據D=X1,X2, … ,Xkj,藍色方框表示穩態數據,紅色方框表示動態數據,其中穩態數據和動態數據各占50%。令j個數據為一組,共k組,數據量Q=k×j。設穩態數據組的狀態標簽s1=0,動態數據組的狀態標簽s2=1。由于穩態數據較為平穩,離散程度較低,動態數據波動性強,離散程度高,且變化規律明顯,所以將各數據組的均值a、標準差b、極值差c、斜率均值d和斜率極值e作為特征屬性,通過學習上述特征屬性實現對兩類數據的辨識。
首先通過Bootstrap重采樣方法對樣本數據D進行有放回的m次抽樣,生成m個訓練子集S,其中訓練子集樣本數應小于Q。然后從上述5個特征屬性中隨機選取w個,對各訓練子集構造分類回歸樹(classification and regression tree,CART)。分類回歸樹基于基尼系數選擇特征,構造過程如下。
1)設訓練子集S中存在穩態數據和動態數據,則訓練子集的基尼系數為:
(4)
式中:p1表示子集中穩態數據的概率;p2表示動態數據的概率。
2)假設根據特征a中某屬性值ai劃分訓練子集,訓練子集分為S1和S2,則在特征a下的基尼系數為:
(5)
式中:|·|表示訓練子集中的樣本數。
上述各特征均為連續特征,需離散化處理。設連續特征均值a有z個不同取值,將這些值從小到大排列,得到特征值集合{a1,a2,… ,az},取各區間[ai,ai+1)中點作為候選劃分點,可得集合Pa:
(6)
3)根據式(5),計算各候選劃分點的基尼系數,將基尼系數最小的候選劃分點作為分支節點對訓練集中數據進行分類,不斷遞歸計算,直至形成分類回歸樹。
最后,重復進行M次重采樣和特征選取,可得M個決策樹,形成隨機森林。將測試樣本輸入隨機森林,對各決策樹的辨識結果采用基于集成投票的思想,選出票數最多的數據狀態,得到隨機森林方法的辨識結果。
3 量測缺失數據恢復策略及流程
考慮到電力系統缺失數據的隨機性,本文提出了一種考慮不同缺失位置的量測數據恢復策略,如表1所示。在固定時間窗的前提下,對時間窗內的量測缺失數據進行恢復。

表1 不同位置下恢復策略
綜上所述,結合雙層全連接的LSTM網絡、隨機森林的數據狀態辨識以及不同缺失位置恢復策略,可得電力系統量測缺失數據恢復流程,如圖5所示。首先將包含缺失數據的樣本輸入訓練好的隨機森林中進行數據狀態辨識。若為穩態數據,則根據缺失數據在整體數據中的具體位置選擇對應的恢復策略,并輸入LSTM-s網絡進行恢復;若為動態數據,則在判斷缺失數據所處位置后,根據其對應的恢復策略,輸入LSTM-d網絡進行恢復。其中LSTM-s網絡參數利用穩態數據訓練,LSTM-d網絡參數利用動態數據訓練。

圖5 缺失數據恢復流程
4 算例分析
本文方法計算環境:CPU為Core i7-9700k,主頻為3.6 GHz,內存為16 GB,GPU為NVIDIA GTX 2070,編程平臺為Python 3.7。
經大量仿真測試,LSTM網絡及隨機森林的最優參數按下列方法進行設置。LSTM網絡參數設置如下:輸入層維度為1;隱藏層層數為3,第一層LSTM神經元個數為64,第二層LSTM神經元個數為64,Dense層神經元個數為32;輸出層維度為1,采用Adam優化算法更新LSTM網絡權重。隨機森林方法的參數設置如下:決策樹個數M為81,隨機特征數w為3。若采用其他參數,缺失數據恢復精度將存在不同程度的降低。
為驗證本文所提方法的有效性,利用如圖6所示的IEEE 10機39節點系統仿真數據與西北地區某750 kV變電站實測母線電壓幅值數據進行驗證并與現有方法進行對比。
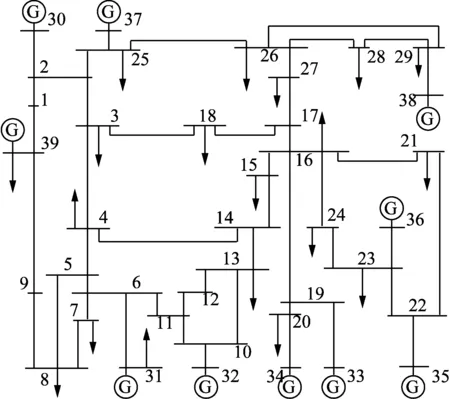
圖6 IEEE 10機39節點拓撲
4.1 仿真數據測試
在仿真系統穩態下,設置0.2 Hz的低頻振蕩,記錄母線1電壓幅值數據,上送頻率100 Hz,仿真數據如圖7所示。由圖7可知,系統運行約1.6 s后發生低頻振蕩。藍色表示穩態數據為160個,紅色表示動態數據為240個。

圖7 穩態和動態仿真數據
首先設置不同的缺失數據占比,仿真次數為100次。采用本文所提隨機森林方法測試數據狀態辨識精度(對應圖5中隨機森林部分),并與文獻[25]的決策樹法進行對比,結果如圖8所示。

圖8 仿真數據狀態辨識結果
由圖8可知,隨著缺失數據占比的增加,兩種方法的辨識精度均不同程度降低,當缺失數據占比為10%至60%時,本文所提隨機森林的數據狀態辨識方法的平均準確率約為98.5%,并且均高于決策樹法。
然后針對圖7的仿真數據,在缺失數據數占比為10%時,改變缺失數據位置,結合所提隨機森林狀態辨識與LSTM網絡恢復方法對缺失數據進行恢復(對應圖5中LSTM網絡部分),并與僅采用LSTM網絡的恢復方法、文獻[13]的插值法和文獻[16]的低秩法對比,恢復數據的均方根誤差見表2。

表2 不同缺失位置對數據恢復精度的影響
由表2可知,本文所提結合隨機森林狀態辨識與LSTM網絡恢復方法受缺失數據位置的影響較小;由于不同缺失位置下數據狀態不同,因此僅采用LSTM網絡的恢復方法受其影響較大,無法準確恢復缺失數據,須結合基于隨機森林的數據狀態辨識方法;插值法無法較好地恢復動態下的數據;低秩法在過渡階段的恢復誤差較大。中部數據為穩態到動態的過渡階段,因此4種方法在該情況下的恢復精度均有不同程度的降低。
接下來將缺失數據設置位于序列中部,改變缺失占比,對比4種方法的恢復結果,如表3所示。

表3 不同缺失占比對數據恢復精度的影響
由表3可知,插值法在缺失數據較多時,無法準確恢復缺失數據。在缺失占比為30%時,僅本文所提方法可有效恢復缺失數據,可見本文所提方法受缺失占比的影響較小。
在此基礎上,設置圖7中的動態數據存在20%的缺失數據,采用所提雙層全連接的LSTM網絡對缺失數據進行恢復,并與插值法、低秩法進行對比。由于該過程未涉及數據狀態辨識,因此無須使用基于隨機森林的狀態辨識方法,恢復結果如圖9所示。

圖9 動態缺失數據恢復結果
通過計算可知,本文所提量測缺失數據恢復方法的均方根誤差為0.18%,插值法的均方根誤差為4.61%,低秩方法的均方根誤差為1.17%。可見本文所提方法恢復精度較高,可有效恢復動態下的缺失數據。
4.2 現場數據驗證
選用西北地區某750 kV變電站實測母線電壓幅值數據驗證所提方法的有效性。實測數據均為穩態數據,如圖10所示。在不同母線實測數據中設置多種動態數據,首先驗證所提數據狀態辨識方法的有效性,結果如表4所示。

圖10 現場實測母線電壓幅值數據

表4 不同方法對現場數據狀態辨識結果對比
由表4可知,對于不同母線實測數據,隨機森林方法的辨識準確率均高于決策樹法,即隨機森林方法具有較好的泛化性,不受現場噪聲等的影響。
在如圖10所示的位置設置缺失數據,采用時間窗為0.5 s的量測數據進行恢復,保證缺失數據的位置位于中部,并與插值法、低秩法進行對比,結果如圖11所示。

圖11 現場實測數據恢復結果
由圖11可知,本文所提恢復方法的均方根誤差為0.94%,插值法的均方根誤差為3.1%,低秩法的均方根誤差為2.6%。可見本文所提的LSTM網絡的缺失數據恢復方法對實測缺失數據的恢復精度最高,可適用于現場量測數據。
5 結 論
本文提出了一種基于長短期記憶網絡的電力系統量測缺失數據恢復方法。該方法可有效辨識系統量測數據的不同狀態,進而實現對量測缺失數據的準確恢復,有效提高數據的可用性。本文研究主要結論如下:
1)基于長短期記憶網絡對電力系統量測數據規律選擇記憶的特性,提出了一種雙層全連接的LSTM網絡模型,實現從已知數據到缺失數據的映射。
2)提出一種基于隨機森林的數據狀態辨識方法,有效區別系統穩態、動態數據,為后續缺失數據恢復提供基礎。
3)提出一種考慮缺失數據位置的恢復策略,根據數據的缺失位置匹配相應的恢復策略提高恢復精度。
4)通過仿真和實測數據測試表明所提方法可有效恢復系統穩態、動態下的缺失數據,亦可提高現有方法的恢復精度。
本文暫未計及不良數據對量測缺失數據恢復的影響,后續將進一步針對不良數據檢測辨識展開研究。
猜你喜歡
學苑創造·A版(2020年10期)2020-11-06 05:21:26
兒童故事畫報(2019年5期)2019-05-26 14:26:14
作文周刊·小學一年級版(2016年27期)2017-06-03 23:21:17
絲綢之路(2016年9期)2016-05-14 14:36:33
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
海外文摘(2016年4期)2016-04-15 22:28:55
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
