基于聚類分析與遷移學(xué)習(xí)的入侵檢測方法
2021-05-14 07:15:22黃清蘭
電腦與電信 2021年3期
黃清蘭
(福建商學(xué)院信息技術(shù)中心,福建 福州 350012)
1 引言
在新的智能網(wǎng)絡(luò)行為出現(xiàn)的情景下,基于異常的入侵檢測要能有效地實現(xiàn)新網(wǎng)絡(luò)攻擊行為的檢測,具有一定的挑戰(zhàn)性。目前基于傳統(tǒng)的機器學(xué)習(xí)、深度學(xué)習(xí)、集成學(xué)習(xí)、統(tǒng)計分析、遷移學(xué)習(xí)等技術(shù)被廣泛應(yīng)用于基于異常的入侵檢測領(lǐng)域[1]。
傳統(tǒng)的機器學(xué)習(xí)技術(shù)主要如聚類、支持向量機、決策樹等。基于聚類的方法可以選擇不依賴標簽樣本進行異常檢測。依賴標簽樣本進行異常檢測的技術(shù)主要是利用分類技術(shù),研究比較多的是結(jié)合其他的機器學(xué)習(xí)技術(shù)進行應(yīng)用。陳虹等[2]使用深度信念網(wǎng)絡(luò)分別對訓(xùn)練集和測試集進行特征抽取,然后使用Xgboost算法進行分類檢測。文獻[3]是基于遷移學(xué)習(xí)技術(shù),針對兩個不同分布和特征空間的網(wǎng)絡(luò)樣本數(shù)據(jù),通過分析源域和目標域之間的相似性,提出了一種將兩者樣本集映射到相同維度的特征空間方法,該方法能有效地遷移源域數(shù)據(jù)來預(yù)測目標域網(wǎng)絡(luò)樣本數(shù)據(jù)的分類檢測。
基于統(tǒng)計分析、遷移學(xué)習(xí)的入侵檢測技術(shù)相較基于傳統(tǒng)機器學(xué)習(xí)來說研究比較少,由于傳統(tǒng)機器學(xué)習(xí)技術(shù)在訓(xùn)練和測試樣本分布不一致的情況下,表現(xiàn)效果不佳,而實際情況往往是分布不一致的樣本,入侵檢測領(lǐng)域也是如此。如何在數(shù)據(jù)分布不一致的情況,提高入侵檢測分類的準確率。本文結(jié)合聚類、統(tǒng)計抽樣技術(shù)和遷移學(xué)習(xí),提出了一種基于聚類分析與遷移學(xué)習(xí)的入侵檢測方法(Intrusion Detection Method Based on Cluster Analysis and Transfer learning,CATL)。
2 相關(guān)知識
2.1 K-means++和Xgboost
K-means算法是基于劃分的經(jīng)典聚類算法,在面對大數(shù)據(jù)聚類分析的情況,該算法相較于其他的聚類算法,更為高效。K-means算法是隨機選取初始聚類中心,而聚類結(jié)果很大程度會受初始聚類中心的選擇而呈現(xiàn)出較大差異,使其不能保證聚類結(jié)果的準確性。針對此問題,Arthur等[4]提出的K-means改進算法K-means++,該算法除了在初始聚類中心選取方式與K-means算法不一樣,其它步驟是一樣的。Kmeans++算法的初始聚類中心選取的基本思路是要使得選取的初始聚類中心相互間的距離要盡可能遠。
Xgboost是經(jīng)典的集成學(xué)習(xí)算法,被廣泛應(yīng)用于回歸和分類問題,它是一個優(yōu)化的分布式梯度提升決策樹的改進算法,使用正則化提升技術(shù)來防止過擬合,具有高效、靈活等優(yōu)點。
2.2 基于實例的簡單遷移分類模型
遷移學(xué)習(xí)[5]主要的概念是域和任務(wù)。域D={X,P(X)},其中X為樣本集即特征空間,P(X)為邊緣概率分布。任務(wù)T={Y,f(X)},其中Y為樣本的標簽集即標簽空間,f(X)為預(yù)測函數(shù)表示的是條件概率分布P(X|Y)。假設(shè)源域Ds={Xs,P(Xs)},源任務(wù)Ts={Ys,f(Xs)},目標域Dt={Xt,P(Xt)},目標任務(wù)Tt={Yt,f(Xt)}。遷移學(xué)習(xí)從已學(xué)習(xí)的相關(guān)任務(wù)中轉(zhuǎn)移知識用以輔助新任務(wù)的知識學(xué)習(xí),在源域和源任務(wù)中轉(zhuǎn)移相關(guān)知識用以輔助目標任務(wù)的知識學(xué)習(xí)。依據(jù)轉(zhuǎn)移知識的不同,遷移學(xué)習(xí)可以分為基于實例的遷移學(xué)習(xí)、基于模型的遷移學(xué)習(xí)、基于參數(shù)的遷移學(xué)習(xí)等。
基于實例的遷移學(xué)習(xí)[6]是一種歸納式遷移學(xué)習(xí)方法,又分為基于單源實例和基于多源實例,研究比較多的是基于單源實例的方法,該方法假設(shè)存在部分的訓(xùn)練集Dd={Xd,P(Xd)}和測試樣本分布一致,但該部分訓(xùn)練集不足以訓(xùn)練一個好的分類模型進行測試樣本的分類預(yù)測的情況下,需要利用Dd來遷移有益的源域訓(xùn)練樣本Ds進行分類模型訓(xùn)練。簡單遷移策略[7]具體流程如圖1所示。
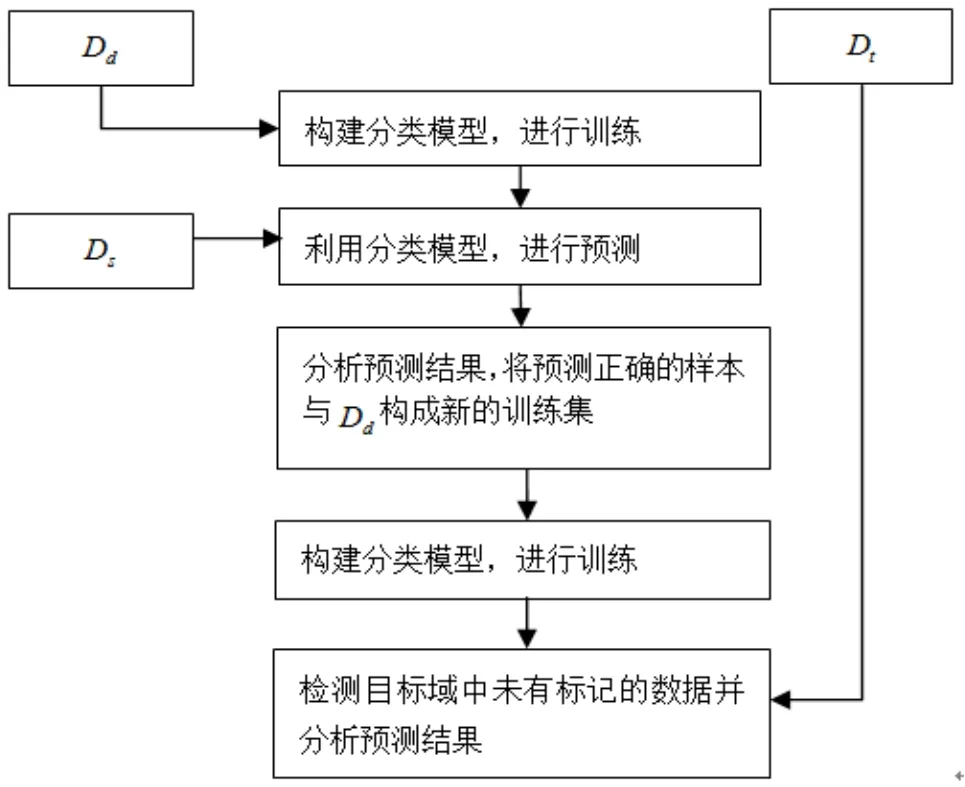
圖1 基于實例的簡單遷移分類模型流程
通過使用目標域中部分有標記的訓(xùn)練數(shù)據(jù)集Dd進行分類模型訓(xùn)練,將訓(xùn)練好的分類模型用以預(yù)測源域的訓(xùn)練數(shù)據(jù),將源域中分類正確的數(shù)據(jù)進行遷移,與Dd構(gòu)成新的訓(xùn)練樣本進行訓(xùn)練,將訓(xùn)練好的分類模型用于預(yù)測目標域中未有標記的數(shù)據(jù)Dt,但該方法的前提是假設(shè)Dd與目標域中未有標記的數(shù)據(jù)分布一致。該遷移策略簡單易行,但是實際應(yīng)用場景中,如何獲取Dd使其分布相似于目標域中未有標記的數(shù)據(jù),是影響其使用效果的重要方面。
針對簡單遷移策略使用的關(guān)鍵問題:Dd的獲取方式,CATL算法首先設(shè)計了基于聚類的統(tǒng)計層次抽樣技術(shù)進行Dd的獲取,而后利用簡單遷移策略進行入侵分類檢測,CATL算法是基于實例的簡單遷移策略應(yīng)用的算法,也是一種混合算法。
3 CATL算法
假設(shè)目標域D={X,P(X)},其樣本量為N,固定比例R為Dd占D的比例,源域Ds={Xs,P(Xs)},Ts={Ys,f(Xs)},D和Ds的特征和標簽空間一致,P(X)≠P(Xs)。
CATL算法實現(xiàn)的具體流程如圖2所示,其設(shè)計主要有兩大步驟:
(1)通過K-means++算法進行聚類劃分X,X是不包含標簽的樣本數(shù)據(jù)集,若聚類個數(shù)為K,初始化依據(jù)式(1)產(chǎn)生,則聚類劃分的子總體集合G={G1,G2,…,Gk},從所劃分的每個子總體中按固定的比例R抽取樣本,所抽取的樣本集合并為Xd,Xd可以代表原總體樣本X的分布,將所抽取的樣本集Xd進行標記形成Dd,測試集Dt={X-Xd,P(X-Xd)}。

其中聚類個數(shù)之所以按式(1)進行初始化,是為了盡可能使聚類劃分的每個子總體都能抽到樣本并入Xd,若聚類個數(shù)遠大于Dd樣本量,導(dǎo)致Dd嚴重偏向于大類(子總體所含樣本量比較大)。
(2)使用Xgboost算法對Dd進行訓(xùn)練,將訓(xùn)練好的Xgboost模型用于測試Ds,將Ds中分類正確的樣本進行遷移,與Dd合并構(gòu)成新訓(xùn)練樣本,再用Xgboost算法對新訓(xùn)練樣本進行訓(xùn)練,將訓(xùn)練好的新模型對測試集Dt進行分類檢測。
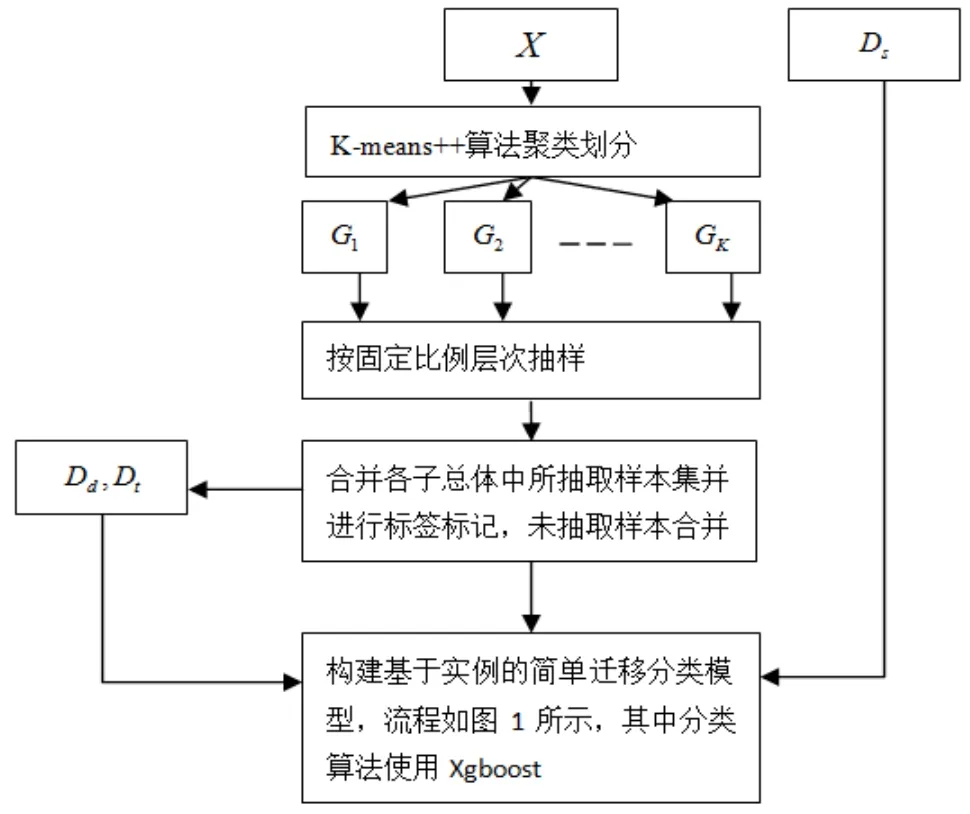
圖2 CATL算法流程
4 實驗分析
入侵檢測數(shù)據(jù)集采用NSL-KDD,該數(shù)據(jù)集有41個特征屬性和一個類別標簽,類別標簽值為正常和非正常,其中KDDTrain為訓(xùn)練集,KDDTest為測試集,兩者的數(shù)據(jù)分布是不一致的[6]。KDDTrain可認為源域,都是有標記的數(shù)據(jù),KDDTest為目標域。
CATL算法是基于實例的簡單遷移分類模型,分類算法的評估指標常見的[8]有準確率(Accuracy)、精確率(Precision)、召回率(Recall)和F1值。F1值權(quán)衡了精確率和召回率,其公示如式2。為了評價CATL算法的有效性,本文使用準確率和F1值作為評價指標。

使用Python語言進行編程實驗,Xgboost算法使用的是Xgboost-0.82包,K-means++和對照實驗的算法都在scikitlearn中已實現(xiàn)。在隨機種子一樣的情況下,設(shè)置兩組實驗。第一組實驗:設(shè)置R為0.1%~1%間,步長為0.1%,不同比例下進行不同組遷移分類模型實驗,每組實驗執(zhí)行100次,實驗結(jié)果如圖3所示。由圖中可知,R為0.3%時準確率是最低的,出現(xiàn)異常值情況最多;在0.5%~0.9%間都有出現(xiàn)異常點,F(xiàn)1值和準確率平均值都在0.9左右;0.1%下波動性最小最穩(wěn)定,準確率和F1值都在0.83左右。
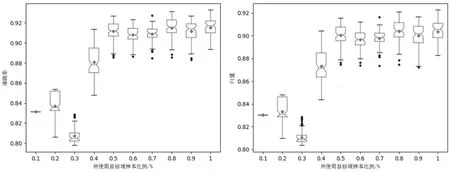
圖3 不同比例值下CATL算法的準確率和F1值的箱形圖
第二組實驗為對照組實驗,設(shè)置R=0.1%,因為該值下CATL算法波動性最小也最穩(wěn)定,對照實驗算法有Xgboost、AdaBoost、RandomForest和SVM算法,CATL模型中,Dd的樣本量為20,對照實驗結(jié)果如圖4所示。CATL算法相較于SVM準確率提高了9%左右,相較于Xgboost算法準確率提高了3%左右。
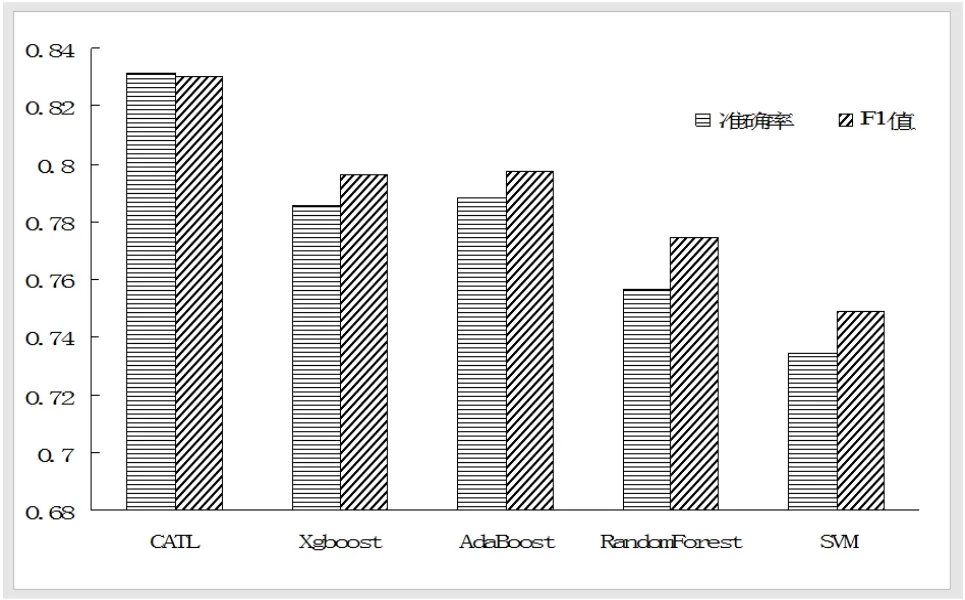
圖4 CATL算法與對照算法的性能比較
CATL算法在使用不同比例的目標域標記樣本下總體的執(zhí)行結(jié)果相較于傳統(tǒng)的分類算法性能都有明顯的提升,但該算法的穩(wěn)定性和精準性對比例值設(shè)置有很大的依賴性,結(jié)合實際需要進行設(shè)置。
5 結(jié)語
針對傳統(tǒng)機器學(xué)習(xí)算法在入侵檢測實際應(yīng)用中,訓(xùn)練和測試樣本分布不一致的情況下,檢測精準性低的問題,提出了CATL算法。經(jīng)過相關(guān)實驗測試,該算法在從目標域中獲取用于遷移分類訓(xùn)練的少量有標記數(shù)據(jù)20條的情況下,相較于SVM算法準確率和F1值都提高了9%左右,總體性能有一定的提高,但穩(wěn)定性相較于現(xiàn)有的分類學(xué)習(xí)算法較差,穩(wěn)定性比較依賴于比例值R。下一步工作,思考如何平衡CATL算法的精準性和穩(wěn)定性,對其進行改進,并應(yīng)用于高校的實際使用場景。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
小哥白尼(趣味科學(xué))(2019年6期)2019-10-10 01:01:50
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
