基于大數據與神經網絡的道路擁堵優化技術與實現
2021-05-16 10:32:48肖權珈任紹坤楊錦濤
科學技術創新 2021年13期
肖權珈 楊 杰 任紹坤 楊錦濤
(中南大學,湖南 長沙410083)
1 研究現狀
在交通擁堵優化方面,主要從以下幾個角度做了重點研究。
1.1 城市規劃角度,如:交叉口合流沖突點改進[1]通過設置立交橋、人行通道,加強交通管理,優化公交站臺等方式,可以有效的解決合流、分流路口的嚴重沖突問題;或者適當控制城市擴規模,適當發展衛星城[2]著重利用衛星城來疏解大規模城市的部分功能。尤其分擔大城市的交通壓力。
1.2 從交通控制角度:基于人車流量組合來控制紅綠燈[3]即將攝像或影像采集設備所接受到的實時交通信息,包括人流、車流、障礙物等信息傳遞到數據計算終端,通過數據模型計算和遠期評估,確定不同道路區域的人流量和車流量。并結合現場人流車流的情況以及通行速度,預估各個路口所需的通行時間,并確定整體的最優通行策略,從而形成不同人流量和車流量的路口,分配不同的紅綠燈通行時間,確保道路通行順暢,提升道路通行效率。
1.3 根據公交流,應用BP 神經網絡預測城市短時交通流量。[4]另外可以運用物聯網技術的應用[5],即通過車聯網技術的應用,使得車輛及時通過車載設備及顯示終端,獲取云數據平臺所展現并計算的路況和通行信息,保證出行車輛及人員能夠合理規劃自身的出行方案,縮短出行的時間,提升出現效率,并且也能夠避免某個城市點位的大量擁堵產生。
2 道路擁堵解決方案
2.1 數據處理
對車流量進行預測依據的交通數據分為兩種:
2.1.1 歷史的交通數據。對歷史交通數據進行預處理后,再進行分析,可以得到路口的擁堵時段以及車流量規律等信息。基于歷史交通數據,進行初步預測。
2.1.2 路口實時采集的交通數據。我們根據路口實時采集的信息,可以對初步的預測結果進行修正。以上兩種不同來源交通大數據具有共同特點。按相關交通數據的類型和采集方式的不同,可以形成比較規范的數據集,主要包括:長期交通流量數據、瞬時交通車流數據、道路最大承載能力數據、通行時長數據、交通指示指令數據以及交通調度服務數據等;交通流量數據的重要參數包括:速度、流量、密度、起止時間、時間平均速度、空間平均速度等;
由于各種原因,如設備老化,道路結構破壞等,使得我們采集的數據常常出現異常值、冗余值、缺失值等等錯誤數據;而且在實際監測過程中也會出現數據丟失或者數據冗余的情況,所以需要進行數據清洗。
使用低階多項式滑動擬合法來識別錯誤數據:
時間序列表示為x(t)(t=1,2,3……n),則擬合多項式為m 階自回歸多項式:
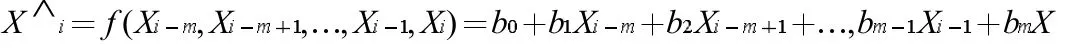
以上滑動擬合并識別錯誤數據的主要方法是通過測算數學期望值,并評估置信度來判斷數據是否符合置信度區間,并確定數據的錯誤與否。以時間序列進行計算X∧i,以及數學期望ζ=Xi-X∧i,錯誤數據與正常數據相比,它的信息值比正常值大的多,使用公式:

以低階多項式來大致判斷錯誤數據,為了簡化過程我們把所有錯誤數據剔除,然后結合該道路的路段信息,如路況、限速等,就可以由交通流量數據中的時間平均速度,實時判斷該路段是否發生擁堵。
2.2 BP 神經網絡預測模型
BP 神經網絡是目前應用最廣泛的一種人工神經網絡之一,它是一種多層前饋網絡,包含輸入層、隱含層和輸出層,同層單元之間不相連,它在輸入層和輸出層之間可有一個或多個隱含層。
從輸入層的特征來看,輸入層的神經元主要是根據樣本的不同屬性和類型綜合確定神經元緯度,輸入層要確保充分考慮到所有數據緯度及相關屬性的準確性。從隱藏層的特征來看,隱藏層主要是由用戶提供的數據閾值及相關條件組成,隱藏層作為重要的限制條件,能夠改變神經元的活性,保證預測模型的靈活性和可變性。前一層神經元和后一層神經元之間有權值。每個神經元都有輸入和輸出。輸入層的輸入和輸出都是訓練樣本的屬性值。
BP 神經網絡的結構較為簡單、易于硬件實現、并且工作狀態穩定,有許多優點。包括有自學習與自適應能力,可以簡化預測難度以及實現對大量數據進行處理等。交通數據非常龐大,BP 神經網絡能達到對大量且復雜的數據的一個較為精確的處理。因此,選用BP 神經網絡進行預測。
2.3 存儲一轉發模型(TUC 策略)
根據基本的存儲一轉發模型來進行車輛調度,就是當車輛按照既有的路線行進時,如果道路中的實際車流量超過該段道路所能承載的最大車流量(飽和值),車輛就需要提前停止行進并在相應路口等待,直到當前方道路車流量恢復平穩或者能接受新入車輛后,等待路口的交通信號燈再做出改變,引導車流通行。
從實際看,存儲- 轉發模型是一個相對簡單的交通模型,通過存儲- 轉發的機制,將道路和車流調配分解為兩個簡單的節點,在運用此模型時,我們假定建輸出流為u,如果道路路況及車流都能滿足相應條件,輸出流u 在某一個時間段內可以使用下邊的公式表示:

S 為相關道路中的最大車流承載能力和承載量,G 是可通行的交通信號燈持續時間,C 是相應路口紅綠燈所需的一個周期時間。由于每個階段時間T 應該與離散時間C 相等。u 為在每個階段時間T 中的平均車流量,而不是在紅燈時間的0 或者綠燈時間的飽和車流量S。換句話說,假設每個車道車流量是連續不間斷的,從存儲- 轉發模型可以得出以下結論:
(1)每個階段時間T 應該與離散時間C 相等。
(2)沒有描述紅燈時間或者綠燈時間車輛排隊情況。
(3)不能連貫的表示每個十字路口每個相位的情況。
當然,為了避免這些沖突和復雜情況的出現,一些非線性規劃、二次規劃等高效優化方法也應運而生,并可通過這些方法來協調復雜的交通網絡問題。
3 交通擁堵優化實現
在實現之前,定義了一部分假設,而這些假設都是在道路中車輛不飽和的情況下存在的,得到的綠燈時間是基于歷史需求而得出的。通過綠燈時間來控制網絡達到最優狀態并且道路中車輛排隊數量為零。然而,在現實中,車輛的數目是動態改變的。所以,如何確定綠色時間的值可能是最優,并且可以控制交通情況比較惡劣的交通狀況。
通過LQ 方法來實現最小化性能標準,LQ 方法的控制法則為:
g (k) = gn-L. x ( k )
通過實驗模擬及數據仿真可以得出,增益矩陣L 對道路車流量數據變化所產生的變化較小,相應敏感度角度,尤其是在轉彎率與最大飽和流量變化時更加明顯。gN 為理想狀態下假設的最優時間。L 為常量反饋增益矩陣,L 是由A, B, Q, R 共同決定的,矩陣的規范如下:
(1)控制間隔:在選取并存儲- 轉發策略時,根據實際需要,應該對每個控制點的時間進行規范和控制,無論是控制時間間隔太長或者太短,都不利于得出精確結果。因此結合大多數路口及城市實際交通控制情況,將時間間隔設置為90 秒。
(2)道路的數量:交通網絡中道路的數量對TUC 策略中LQ方法的應用產生影響。
(3) 相位:交通網絡中十字路口的相位對TUC 策略中LQV方法的應用具體重要影響。
(4)每個道路的v:以四個相位的十字路口為例,駛入與駛出相同路口的車流導向圖也具備相同的規律。(如圖1、圖2)
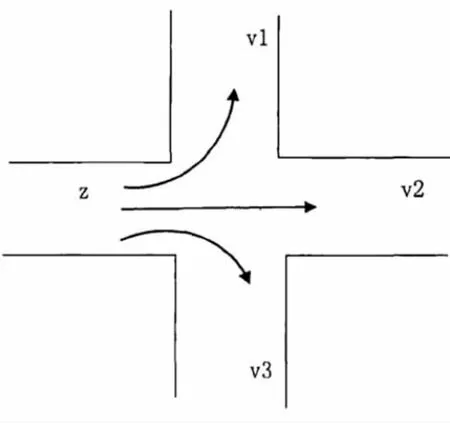
圖1 駛入道路Z 的車流導向
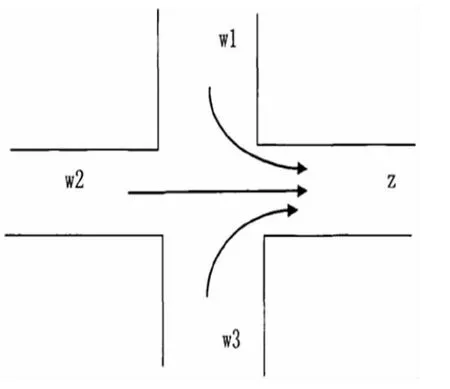
圖2 駛出道路z 的車流導向圖
(5)每個道路的S:測算道路的飽和流量,一般需要結合實際路段的特定情況,包括限制車速、道路寬度、道路長度、當地的執行標準等得出。
(6)t:這里是指每個道路路口車輛的轉彎率,按照相關設定以及實際道路通行的情況看,此數據對LQ 方法應用具有較大影響。
(7)R:R=rI,由試錯法得出,我們取r=0.00050。
(8)Q:Q 是考慮到每個鏈路上車速不同,長度不同而提出的因子,致使每個鏈路都達到最優,Q 的取值為對角線為每條鏈路的最大值的倒數,其他元素都是0 的矩陣。
由于gN為理想狀態下假設的最優時間,所以可列公式:
g ( k ) = g ( k - 1) - L *[ x (k ) - x( k-1)]
g(k-1)為k-1 階段有效綠燈時間,x(k-1)為k-1 階段道路中的車輛數,g(k)為k 階段有效綠燈時間,x(k)為階段道路中的車輛數,L 為狀態反饋矩陣。
4 結論
智慧城市是未來城市發展的趨勢,而智能交通是智慧城市的一個重要組成部分,也是一個研究的熱點。以計算機技術為主,綜合了交通學科的相關理論。運用互聯網+的思維,為傳統的交通領域賦能。通過運用了神經網絡進行預測,與傳統的預測方法相比較,對信息源準確度要求不高,有較好的容錯能力。與以往的交通調控相比,加入了用戶與交通控制系統之間的“互動”,形成一個正反饋機制,并將大數據技術結合交通領域相關知識,對信號優化和路徑規劃都建立了相關的模型,在智能交通方向做了一些探索,且成果也可運用到無人駕駛系統中去。
