基于申威眾核處理器的圣維南求解程序的并行與優化*
2021-05-18 09:32:10丁哲昭儲根深胡長軍
計算機工程與科學 2021年5期
丁哲昭,儲根深,胡長軍,李 揚
( 北京科技大學計算機與通信工程學院,北京 100083 )
1 引言
水文模擬是多個水文物理活動耦合的復雜過程,在大規模水文模擬程序中,單步模擬可以分為坡面產流和河道匯流2部分進行。其中,河道匯流模型又可分為水文學模型和水力學模型2類。水文學模型以馬斯京根(Muskingum)及其改進方法為代表,模型相對比較簡單;而水力學模型則以圣維南(Saint-Venant)方程組及其簡化模型為代表,這類模型不只考慮時間因素,同時在控制方程中還要考慮空間因素。使用圣維南方程組進行河道匯流模擬,可以有效提高程序對流域水系在時間和空間尺度上的描述能力[1],同時能夠提高模擬結果的精度,對于模擬精度要求較高的場景有著重要的應用價值[2]。
一般常用數值模擬方法來求圣維南方程組的數值解,這一求解過程隨著模擬規模和精度的提高,程序的計算量會變得非常龐大。本文通過求解圣維南方程組對河道匯流過程進行模擬,求解程序基于有限體積法FVM (Finite Volume Method)實現,串行程序運行時間隨問題規模和模擬時長的增大而呈線性增長,滿足需求的計算耗時在后續應用于監控、預測等項目時是不可接受的。因此,本文的研究意義在于將目前制約大規模水文模擬程序運行速度的圣維南求解程序移植到“神威·太湖之光”超級計算機上,針對該超算采用的SW26010異構眾核處理器,使用MPI和athread庫設計主從異步并行加速方案;針對計算模式、通信模式、任務劃分等模塊進行深入優化,研究從核陣列的高效使用方式,發揮我國國產超算強大的計算能力,以提高大規模水文模擬程序中河道匯流過程的模擬速度。
2 圣維南方程用于匯流模擬的原理
2.1 用一維圣維南方程組表示河道匯流過程
圣維南方程用一組連續方程和運動方程表示非恒定流在明渠中的運動狀態[3]。其中,連續方程,也稱為質量方程,如式(1)所示:
(1)
其中,x表示河道沿程位置,t表示時間,Q(t,x)表示河道流量,以下用Q表示,A(t,x)表示過水斷面面積,以下用A表示。
式(1)可以由質量守恒定律推導得出[4],反映了河道中的水量平衡關系,即河道蓄水量的變化率等于沿程流量的變化率。
運動方程,也稱為能量方程,如式(2)所示:
(2)
其中,h(t,x)表示水深,式中用h表示,g為重力加速度,運動方程右側為摩阻項。
式(2)可以由牛頓第二定律推導得出,反映的是功能轉化的關系。
圣維南方程組表明了明渠非恒定流水力要素與時間t和沿程坐標x之間的函數關系,可適用于任意斷面的明渠河道。與傳統的水文學模型如馬斯金根匯流模型相比,圣維南方程組引入了空間信息對水力要素的影響,并描述了各種水力要素之間的函數關系,使模擬結果更加全面而細化。因此,圣維南方程組在洪水模擬、流量監測等水文模擬領域有著十分重要的地位。
2.2 基于FVM的一維圣維南方程組求解算法
圣維南方程組是一組一階擬線性雙曲型偏微分方程組,在實際工程應用中給出的條件下,由于很難求解其精確的解析解,對于這類偏微分方程組,一般考慮使用有限元法、有限差分法或有限體積法等數值方法求解其近似的數值解。
Perthame等人[5]提出了一種用有限體積法對帶有底坡源項的一維圣維南方程組進行求解的方法,在文獻[5]中將圣維南方程組的連續方程和運動方程表示為式(3)和式(4)所示:
(3)
(4)
其中,u(t,x)∈R表示沿程方向上斷面的平均流速,式中用u表示,模擬時間t≥0,位置x∈R,h≥0。
在這種形式中,引入了底坡源項Z(x),下文用Z表示,h+Z表示河道水平面,并忽略了部分摩阻項,空間上只考慮沿程流動方向,并且把河道抽象為單位寬度,斷面的平均流量q(t,x)可以用hu表示。一維河道示意圖如圖1所示。
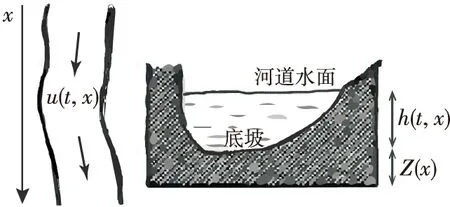
Figure 1 Diagram of 1D channel’s side view圖1 一維河道示意圖
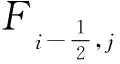
(5)
(6)
其中,j為時間步。
由于計算每個單元的平均值需要兩側邊界的通量值,因此,將河道劃分為t_cell個單元后,還需要在兩側再補充2個控制單元,用于C1和Cn單元的更新,而補充的2個單元的模擬值則由用戶設定的周期性邊界條件來進行更新。

Figure 2 Diagram of channel partition圖2 河道劃分示意圖
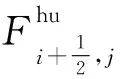
(7)
其中,弗勞德數Fr和無量綱變量K表示為:
(8)
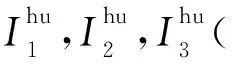
2.3 圣維南求解程序的計算熱點
圣維南求解程序的輸入參數有河道長度L、地形Z(x)、模擬時長T、河道劃分單元數t_cell、積分迭代次數N和精度e,還需要給出初始時刻各點平均水深h(0,x)和斷面平均流量q(0,x)。
程序在應用于大規模水文模擬軟件的匯流過程時,雖然能夠得到更準確的模擬結果,但計算量會隨精度成比增加。對于500 km長的河道進行100 s的匯流模擬,在不同劃分單元和積分迭代次數的設置下,串行程序的性能如表1所示。

Table 1 Runtime of program with different accuracy表1 不同精度下串行程序的執行時間
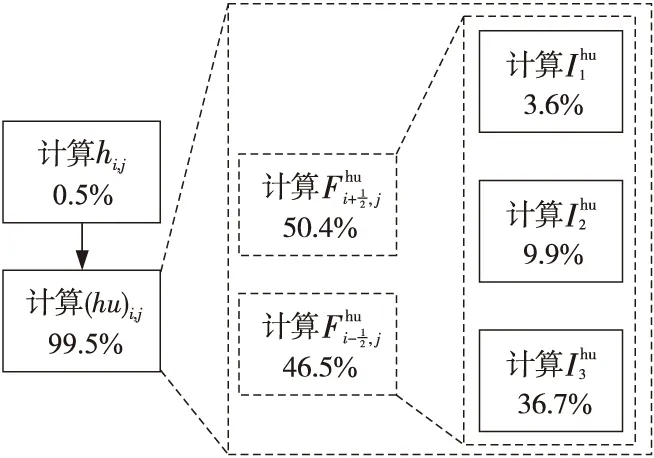
Figure 3 Performance of Saint-Venant solver圖3 圣維南求解程序的性能分析
3 “神威·太湖之光”平臺介紹
3.1 神威·太湖之光
“神威·太湖之光”是國家863計劃支持下研制出的新一代超級計算機,是世界上第1臺峰值性能超過100 PFlop/s的超級計算機,峰值性能可達125.7 PFlop/s,持續性能達93.0 PFlops,整機由40 960塊國產異構處理器“申威26010”(SW26010)構成,共有10 649 600個核心[6,7]。“申威26010”異構眾核處理器片上集成了4個運算核組,每個核組包含1個運算控制核心(主核,MPE)、1個運算核心陣列(8×8的從核陣列,CPE)和1個存儲控制器(MC),共計260個運算核心,其系統架構圖如圖4所示。核心工作頻率為1.45 GHz,處理器的浮點性能為3.06 TFlop/s。
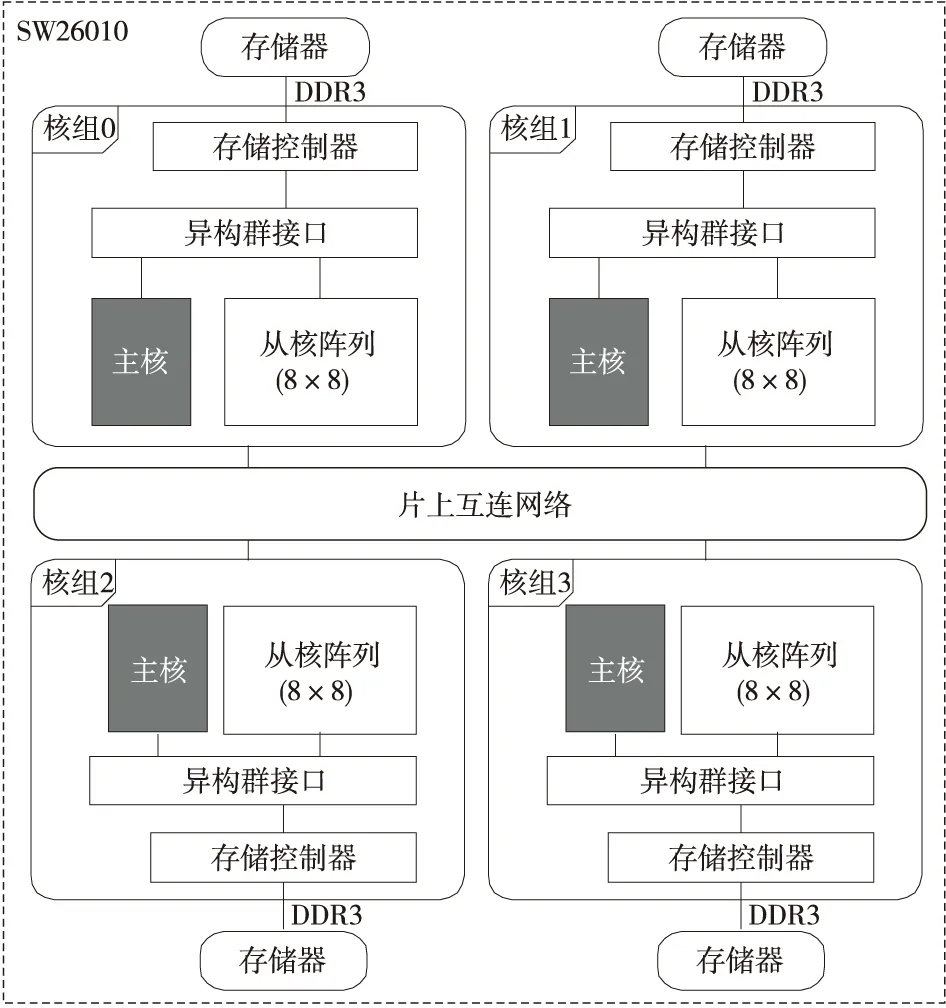
Figure 4 Architecture of Sunway processor圖4 申威處理器的架構圖
在該處理器中,主核和從核陣列共享主存空間,每個核組的本地內存為8 GB。4個核組的物理空間統一編址,主核和從核均可訪問結點上的所有主存空間。主核設有2級Cache,一級數據和指令Cache分離(各32 KB),二級指令和數據Cache共享(256 KB);從核設有一級指令Cache(16 KB)和核組內所有從核共享的二級指令Cache[8]。另外,每個從核都有一塊私有的64 KB的SPM(Scratch Pad Memory),稱為局存空間LDM(Local Data Memory),相當于用戶可控制的數據Cache。從核可以離散地訪問主存,也可通過DMA(Direct Memory Access)方式從主存批量讀寫數據,從核陣列內部支持寄存器級的高效通信。主核具有完整的中斷處理和空間管理功能,同時支持超標量、亂序執行等[8]。
從核陣列由于其計算核心數量眾多、易于擴展等特點,成為了申威異構體系架構下最重要的加速設備,但其能夠進行高效訪存的LDM存儲空間只有64 KB,因此,如何有效地利用好這有限的空間,也是后續進行移植、優化的重點。
系統環境方面,主核支持C、C++和Fortran語言,從核支持C語言和Fortran語言,并行編程語言支持MPI3.0、OpenMP3.1、Pthreads、OpenACC,還提供了自主設計的athread加速線程庫[9],可供用戶進行更底層的性能挖掘。
3.2 主從核并行設計模式
在“神威·太湖之光”超算上同時使用主核和從核陣列進行加速,根據任務分配策略的不同,一般可分為3種并行設計模式:
(1)主從協同并行。
主、從核平等地共同完成要加速的核心段的計算,適用于對LDM存儲空間要求不高、從核可在LDM內獨立完成計算的情況。這種并行模式需要考慮負載平衡和通信量等問題,否則會出現計算資源浪費的情況。
(2)主從動態并行。
主核負責動態地給從核分配計算任務和等待接收計算結果,從核負責接收任務、計算和寫回結果,適用于計算任務較復雜、子任務間需要頻繁通信的情況。
(3)主從異步并行。
主核向從核分配計算任務后,將計算任務加載到從核上,由從核陣列負責核心段的計算,主核則繼續進行其他計算/通信或I/O等操作,適用于計算任務邏輯較簡單、不需要主核進行額外控制的情況。
對于圣維南求解程序,網格單元值的更新只與上一輪迭代的數據相關,一次循環中在核心計算部分不存在單元間的通信,因此主從核并行方案可以選擇采用異步并行模式,在分配數據后各自執行不同的任務。
4 圣維南求解程序的并行化及移植優化方案
4.1 主核間的MPI并行化
對于并行程序,按照劃分對象的不同,一般可分為任務并行和數據并行。考慮到圣維南求解程序的數值求解是一個迭代求解的過程,各次循環之間和子步驟之間的依賴性很強(主要是時間步相關),因此本節采用數據劃分的并行化方案,即根據使用的進程數n,將河道劃分的單元總數t_cell平均分成n_cell個單元,再通過MPI通信將各段數據分配給各個進程,如圖5所示。每個進程負責計算不同單元上的邊界通量,并各自完成對n_cell個單元上河道在總時間T內的模擬計算,實現程序在“神威·太湖之光”超算主核間的并行化。

Figure 5 Diagram of channel grid mapping to the processors圖5 河道數據劃分映射示意圖
MPI并行程序與串行程序相比整體執行邏輯沒有變化,只是每個進程只負責一段河道的模擬,但需要進行額外的MPI集合和點對點通信。
在選擇本次迭代的時間步長dt時,需要用到全部單元的h和hu的原有值。由于河道數據被分散地分配到了各個進程,因此本文令每個進程各自先算出本段對應的時間步長dt_i,再使用MPI_Gather函數將各進程的dt_i匯總到進程0,進程0根據各段的dt_i再計算得到全局河道對應的時間步長dt,并使用MPI_Bcast廣播給其他各個進程,流程如圖6所示。
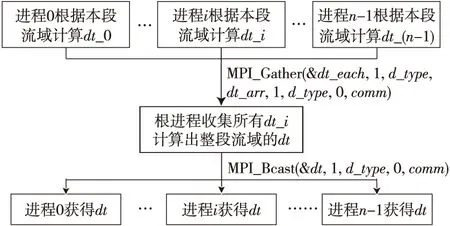
Figure 6 MPI communication when calculating the global time steps圖6 確定全局時間步長時的MPI通信
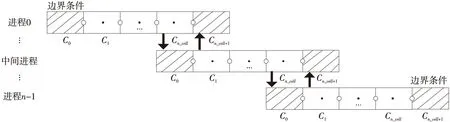
Figure 7 MPI communication when updating the boundary grids圖7 更新邊界值時的進程間通信
另外,除了確定時間步長時需要進行集合通信,各進程完成本段求解任務后進行邊界值更新時,還需要進行進程間的點對點通信。由于計算每個單元需要用到兩側邊界的通量值,所以,對于圖2劃分的t_cell+2個單元,通過求解算法可以得到中間t_cell個單元的模擬值,在串行程序中,C0和Ct_cell+1單元的值需要通過周期性邊界條件進行更新;而在MPI并行程序中,所有進程可以分為中間進程和邊界進程,對于中間進程,需要分別與其兩側的進程進行通信,因為這些中間流域段原本是連續的,擴展的兩側單元應該是相鄰子流域段模擬部分邊界的真實值;對于邊界進程,與其他子流域相連的一側需要與相鄰進程進行點對點通信來交換邊界值,而邊界一側則與串行程序相同,需要根據用戶設置的周期性邊界條件來進行更新,通信過程如圖7所示。
4.2 基于athread庫的從核加速
athread庫是針對SW26010處理器的主從加速編程模型所設計的加速線程庫,通過athread接口控制從核的創建、運行、同步和通信等操作。由于主從核采用統一編址,從核可以直接訪問主存,但效率較差,一般對大量數據會使用DMA方式使從核連續地訪問主存,將數據加載到LDM,計算完成后再通過DMA批量傳回主存。
使用“神威·太湖之光”超算的從核陣列對圣維南求解程序進行線程級并行,需要將熱點函數編寫為從核函數,將指定計算任務加載到從核上執行。首先確定要加速的代碼段是2.3節中指出的計算斷面平均流量的3處積分函數I1,I2,I3,其中,計算各單元兩側的Fi+1/2和Fi-1/2時均需計算這3個積分函數。為了后續使主從核可以異步處理任務,這里編寫了2個從核函數來分別計算這2個邊界通量值,每個函數主要完成一個循環計算段,計算結果是二維數組I[3][n_cell+2]。基于從核陣列的并行化也采用數據劃分,主核根據本進程內的n_cell和可用從核數s_num分配計算單元,形成2層數據劃分,如圖8所示。
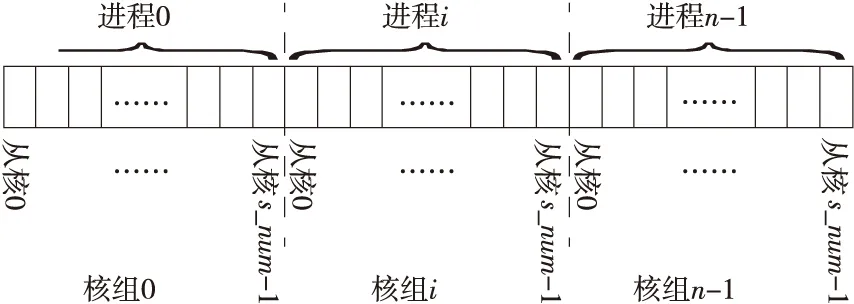
Figure 8 Diagram of channel partition in heterogeneous manycore parallel scheme圖8 主從核混合加速方案的數據劃分示意圖
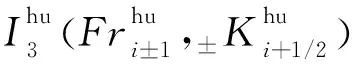
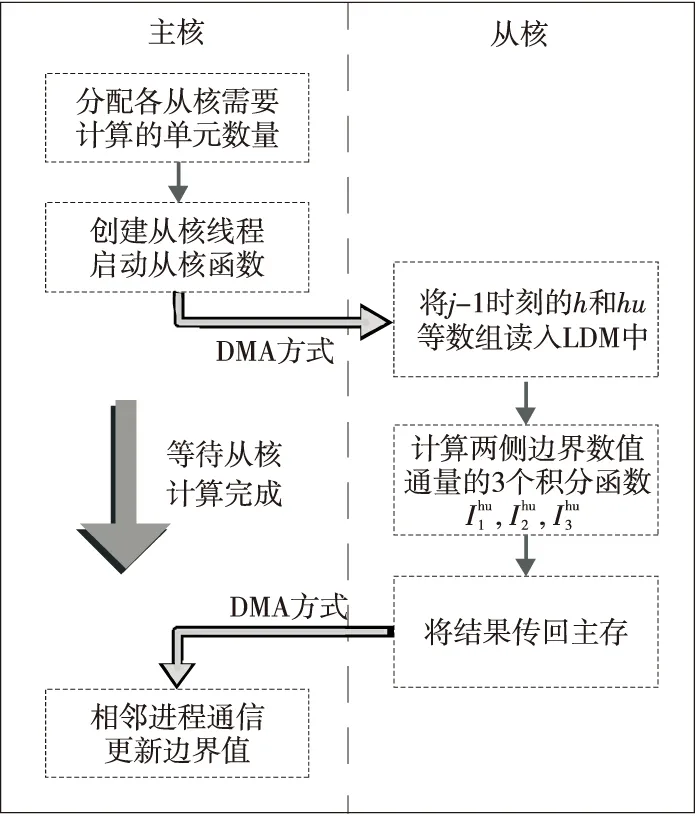
Figure 9 Execution flow chart of master-slave core in one time step圖9 單步計算中主從核執行流程圖
4.3 程序的性能分析及優化
“神威·太湖之光”超算上的大規模并行程序的執行時間Tp與計算量W、計算性能E、訪存量M、訪存帶寬MBW、通信量COM和網絡帶寬NBW有關,可以簡單表示為式(9)所示[10]:
(9)
總執行時間可以看作由計算時間、訪存時間和通信時間3大部分組成,優化瓶頸就在于這三者之中的最大值。使用gprof性能測試工具對移植后的圣維南求解程序進行性能分析,測試規模為:t_cell為32 000個,模擬總時間T為60 s,積分迭代次數N為1 000,模擬流域長度L為635 km,精度e為10-4;運行時使用4個核組(進程),每個核組使用64個從核,運行時間占比最多的4個操作如表2所示。
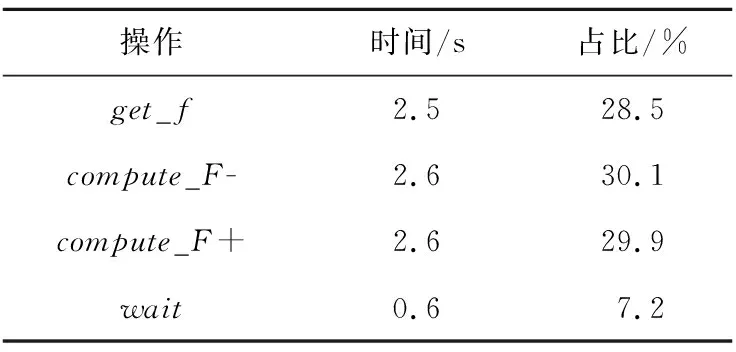
Table 2 Runtime analysis of programs表2 程序運行時間分析
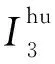
此外,訪存時間也仍有可優化的余地。除了使用DMA方式批量讀寫數據,還需要充分利用訪存帶寬,把多個數據打包,將多次DMA操作合并,可以提高數據的重用率[11]。
核組間的通信開銷對比計算時間和訪存開銷而言相對較小,MPI通信只有在每個時間步循環中的前后,即計算全局時間步長dt時有2次集合通信,和更新邊界值時有2*(n-1)次點對點通信(n為進程數),針對這部分通信開銷進行優化,對程序的整體加速效果預計不是很明顯。

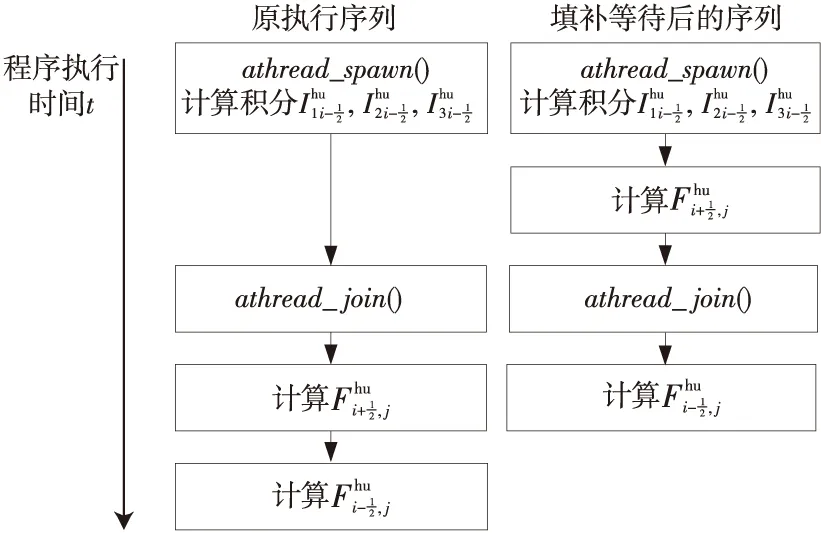
Figure 10 Calculation overlapping with the wait function圖10 計算與等待操作重疊
4.4 浮點運算的向量化
SIMD(Single Instruction Multiple Data)向量化是集成在處理器中的一種加速手段[12],通過將幾個變量之間的標量運算轉化成一組向量運算,挖掘迭代循環間的數據并行性[13]。SW26010支持256位SIMD擴展,如圖11所示。在將標準類型的數據替換為向量數據時,sw5cc編譯器對數據在內存中的地址有對界要求,需要保證floatv4向量類型的變量在內存中是16字節對界的,否則不對界的load/store指令會引發異常。
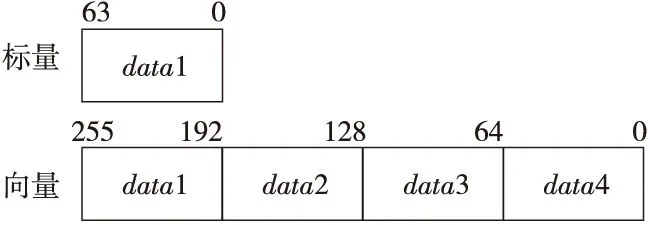
Figure 11 Scalar and vector of single precision floating圖11 以單精度浮點數為例的標量和向量
一條向量運算等價于一個由標量運算構成的小循環,相當于是將循環展開,用一條向量指令完成對4個標量數據的處理,如示例1和示例2所示,可以有效減少中間的重復指令,并降低循環間的控制相關性。
示例1數組相加的標量計算:
1 datatypea[D],b[D],c[D];
2fori=0 toDstep 1do
3c[i]=a[i]+b[i]
4endfor
示例2數組相加的向量計算:
1 datatypea[D],b[D],c[D];
2 v_datatypev_a,v_b,v_c;
3fori=0 toDstep 4do
4simd_load(v_a,&a[i]);
5simd_load(v_b,&b[i]);
6v_c←v_a+v_b;
7simd_store(v_c,&c[i]);
8endfor
在4.2節實現的2個從核函數的計算部分存在大段的循環,而且每次循環的計算結果僅為一個單元的平均值,前后2次循環之間不存在數據相關或控制相關性,因此將計算段SIMD向量化,可以有效減少計算的執行時間。從核函數中處理的變量類型都是float,可改寫為floatv4類型的向量,把從核函數中get_f的計算循環段分裂,改寫為64*4的向量運算,即1次向量操作處理4個單精度浮點運算。理論上通過向量化可以獲得4倍的加速效果。另外,通過重新排列運算順序,盡可能多地將運算改寫為(A[+/-]B)×C的形式,使用乘加融合部件可以進一步提高計算性能[14]。
4.5 計算-通信的重疊優化
雙緩沖技術一般常用于消除圖像在屏幕上的閃爍問題[15]、網絡傳輸中對數據的接收丟失問題[16]和計算機的多級緩存機制[17]等方面,其思想是通過開辟多個緩沖區,并預取下一次要處理的數據,以減少通信等操作的開銷。
同樣,雙緩沖機制也可以用在從核函數的優化上。在從核函數中,外層循環是對s_cell個單元的遍歷,在每次循環中先以DMA方式將本次計算的數據從主存拷貝到LDM中,計算完畢后,再以DMA方式將結果送回主存,如圖12a所示。而加入雙緩沖機制后,將額外開辟一組暫存數組,并將128個單元為一組作為循環計算單位,外層循環是對s_cell的遍歷,即s_cell除以128;在外層的第i個循環中,預取下一輪即第i+1個循環所需的數據,但本次只需判斷第i次的數據是否已經取成功;同樣地,在第i個循環中,把第i次的計算結果回傳到主存后,只判斷第i-1次的計算結果是否回傳成功,延遲判斷是否發送成功,如圖12b所示。
Figure 12 Comparison of the execution logic of calculation section before and after using double buffering圖12 使用雙緩沖前后計算段執行邏輯的對比
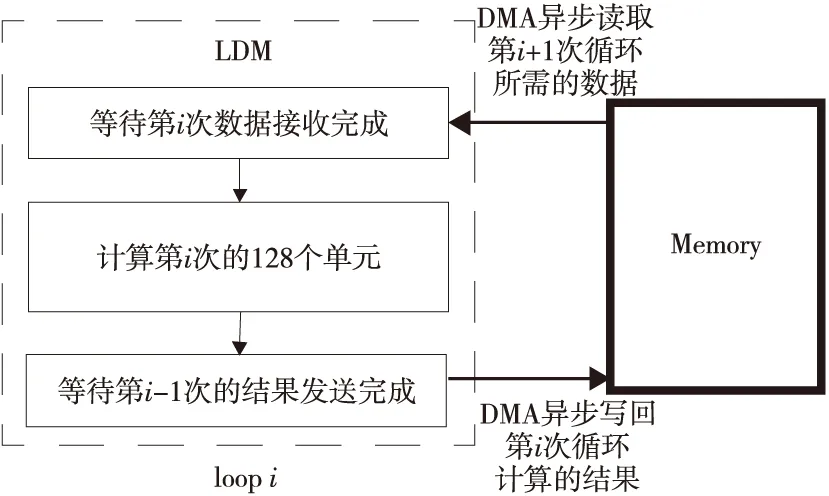
Figure 13 Communication hiding when using double buffering圖13 雙緩沖機制下的通信隱藏示意圖
圖12b中的2個虛線框是需要在雙緩沖流程外完成的拷貝和等待操作。加入雙緩沖策略后,在一次循環中通過拷貝和檢查不同輪次的數據(圖13b的2個灰框)可以省略圖9中從核傳輸數據的時間,判斷本次循環相關的DMA操作時無需等待,相當于使用異步DMA過程實現了除第1次和第n次以外通信和計算的完全重疊,如圖13所示,減少了部分通信開銷。
另外,從核LDM空間只有64 KB,而數據定義需要根據s_cell開辟空間,對從核數據進行更進一步地分段可以保證變量存儲不會超過LDM的空間限制,易于擴展到更高精度的計算。
5 性能測試與分析
5.1 實驗準備
本節將在“神威·太湖之光”超算上,對圣維南求解程序的核心計算部分使用本文提出的不同并行加速方案進行實驗和討論,并測試程序的可擴展性。在本節的所有測試中,程序參數設置的河道長度L均為635 km,積分迭代次數N為1 000次,舍入精度e為10-4。各結點上搭載的SW26010處理器的性能和實驗環境如表3所示。

Table 3 Testing environment表3 測試環境
5.2 并行優化測試與分析
為測試優化策略在SW26010異構眾核處理器上的性能,本節將對主從核各自的并行效果和基于主從核混合加速版本針對從核陣列所做的幾種細粒度優化方式進行測試。設置t_cell為32 000個,進行60 s模擬,程序的FVM數值求解部分在主從核上的測試結果如表4所示。

Table 4 Acceleration effect of the major segment表4 核心段并行加速效果
核心計算段在串行求解程序中約占90%,針對整個程序進行數據劃分的并行化程度較高。但是,未經優化的從核版本加速效果較差,在單核組測試中其對從核的使用效率不到40%,這一是因為單個從核的浮點計算性能要低于主核的;二是因為從核函數只是將2個compute_F函數加載到從核陣列上執行,加速部分占比相對于MPI并行程序較少,因此得到的加速效果也比較差。
再對幾種優化策略進行測試,算例規模t_cell為327 680個單元,模擬總時間T為60 s。提交作業時,使用4結點上的4主核+256從核,測試結果如表5所示。
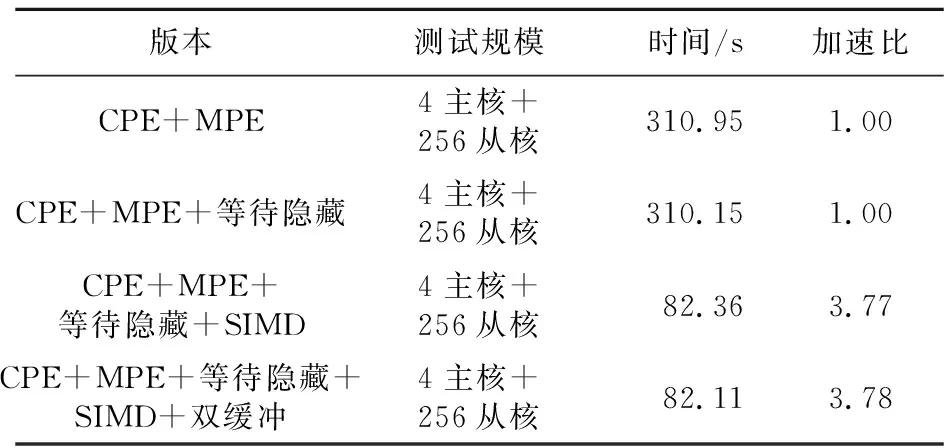
Table 5 Test results of different optimization strategies表5 不同優化策略的測試結果
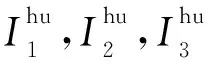
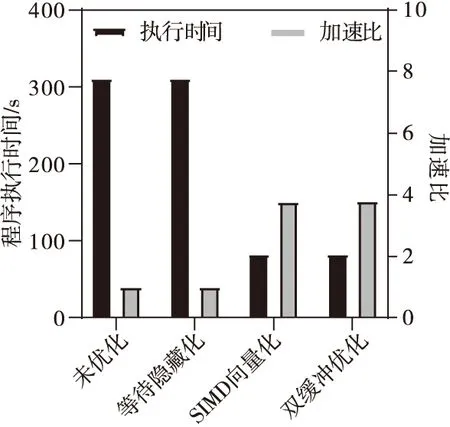
Figure 14 Comparison of several optimization strategies on CPEs(4 CGs)圖14 針對從核的幾種優化策略對比(4核組)
而雙緩沖優化的效果卻不是很明顯,這是因為在圣維南求解程序中,數據通信的耗時相對于計算部分來說比重較小,而雙緩沖優化是通過將計算與異步通信進行重疊來減少部分通信開銷,可加速的部分占比較少。這里同時使用向量化和雙緩沖進行優化,更多的是為了增加單從核可計算的單元數量,有效擴大程序的模擬規模。
5.3 并行程序的可擴展性測試
本節將對上述最優化版本的求解程序進行較大規模的弱可擴展性測試,測試中保持單個從核計算的單元數s_cell不變(這里為1 280個),令測試算例的問題規模隨著使用的計算核心數成比增加,即t_cell保持為令s_cell=1280時對應的值。設置匯流模擬總時間T為60 s;提交作業時,串行程序使用單進程,其余程序作業使用不同數量的核組,測試結果如表6所示。
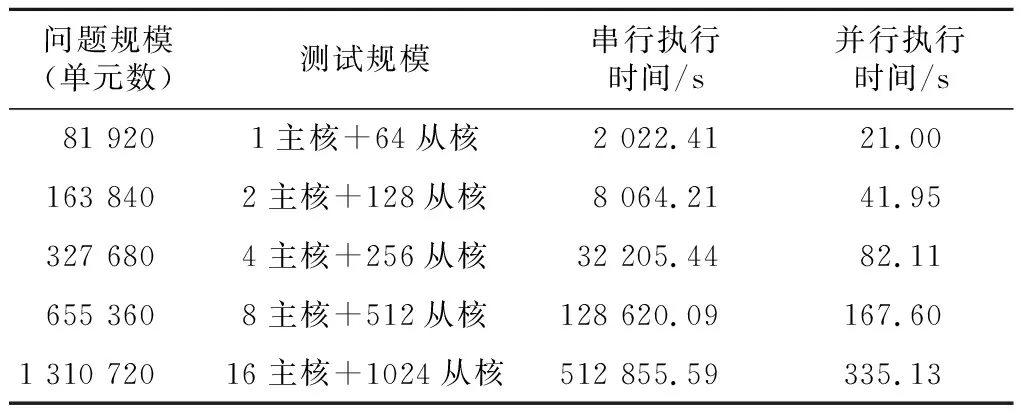
Table 6 Scalability testing of the parallel program表6 并行程序的可擴展性測試結果
如圖15所示,并行加速后的求解程序相對于串行程序的加速比近似呈線性增長,當模擬單元區間間隔變小后,程序中總的計算迭代循環次數會成倍增加,分到每個從核上的負載幾乎保持不變,根據Gustafson定律,程序的理論加速比會隨問題和并行規模而增大。在測試結果中可以看到,在1 310 720單元的測試規模下,使用16核組的圣維南求解程序的速度可提高到原來的1 530倍,加速效果非常明顯,并且在擴展到百萬單元規模進行測試的過程中,相對于串行程序的加速比始終能夠保持線性增長,并行程序對計算核心的使用效率幾乎不會降低,說明優化后的求解程序在“神威·太湖之光”超算上具有較好的可擴展性。
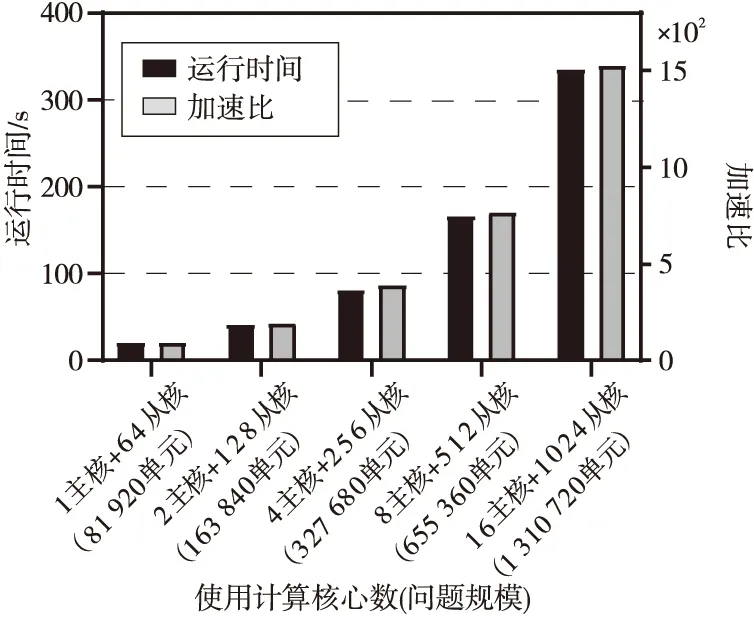
Figure 15 Weak scalability testing of the parallel program圖15 并行程序的弱可擴展性測試
6 結束語
本文為了提高大規模水文模擬軟件中圣維南求解程序的計算速度,對數值求解程序的執行框架和計算瓶頸進行了分析,實現了程序在“神威·太湖之光”超算上的移植和并行加速工作,針對申威處理器的異構眾核架構,做出了任務重排、SIMD向量化、雙緩沖等細粒度優化,FVM求解積分段的性能較優化前可提高3.78倍。加速后的程序在131萬網格單元的測試用例下可獲得超1 500倍加速比,加速效果非常明顯,并且在較大規模的可擴展性測試中,表現出了較強的可擴展性,后續程序也將應用于大規模流域的匯流過程模擬和監測中。
雖然目前程序的加速效果比較可觀,但未來還可以對求解程序進行其他改進。一是針對FVM求解方法本身進行優化,嘗試調整計算過程,減少冗余計算,或針對積分迭代次數進行內層循環的并行化,進一步提高并行粒度。二是為獲得空間上更加全面的模擬結果,可以將程序擴展到求解二維圣維南方程組,但同時需要重新設計并行方案及負載均衡策略。三是面向神威異構眾核架構,繼續挖掘從核的計算性能,考慮在編譯器級添加適當的優化選項,或是針對需要大量重復進行的數值計算,通過內嵌匯編指令,嘗試進一步提高計算速度。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中國外匯(2019年20期)2019-11-25 09:54:58
人大建設(2019年12期)2019-05-21 02:55:44
瞭望東方周刊(2017年42期)2017-12-05 18:49:38
環球時報(2017-03-30)2017-03-30 06:44:45
中國衛生(2015年3期)2015-11-19 02:53:32
民主與科學(2014年3期)2014-02-28 11:23:03
