一種新型高效的移動(dòng)端深度學(xué)習(xí)圖像分類系統(tǒng)
2021-05-24 10:34:08劉國(guó)慶王麗華黃澤宇陳美燕
物聯(lián)網(wǎng)技術(shù) 2021年5期
任 磊,劉國(guó)慶,王麗華,黃澤宇,陳美燕
(1.中國(guó)電子科技集團(tuán)公司第二十研究所,陜西 西安 710068;2.西北大學(xué) 信息科學(xué)與技術(shù)學(xué)院,陜西 西安 710127)
0 引 言
智能手機(jī)、無人機(jī)、可穿戴攝像頭和自動(dòng)駕駛汽車等擁有高清攝像頭的移動(dòng)設(shè)備,極大地改變了人們的生活方式。移動(dòng)計(jì)算可以處理視頻流數(shù)據(jù),為用戶提供多種服務(wù)。例如,無人機(jī)可以監(jiān)控交通量,識(shí)別特定區(qū)域的道路標(biāo)志;自動(dòng)駕駛汽車可以分析車載攝像頭傳輸?shù)牧饕曨l,識(shí)別物體、行人、其他車輛和交通燈。此外,用戶也可以佩戴增強(qiáng)現(xiàn)實(shí)頭盔與現(xiàn)實(shí)世界進(jìn)行互動(dòng)。這些智能服務(wù)一般都是通過分析和計(jì)算連續(xù)的視頻信息提供的。在過去幾年里,基于深度學(xué)習(xí)的方法在各種計(jì)算機(jī)視覺任務(wù)中表現(xiàn)出了其優(yōu)勢(shì),這得益于CNN可以提取圖像或流媒體視頻數(shù)據(jù)幀。
與云計(jì)算相比,在移動(dòng)設(shè)備上處理深度學(xué)習(xí)有天然優(yōu)勢(shì)。整個(gè)工作流程不用將數(shù)據(jù)上傳到云,可以在離線運(yùn)行的同時(shí)避免云計(jì)算過程中數(shù)據(jù)傳輸與異地存儲(chǔ)帶來的隱私風(fēng)險(xiǎn)。雖然深度學(xué)習(xí)模型具有卓越的性能,但是CNN中的卷積層需要消耗大量的計(jì)算量和能量資源,給設(shè)備帶來了嚴(yán)峻的挑戰(zhàn)。AlexNet[1]、VGG[2]、GoogleNet[3]、ResNet[4]都 是 ILSVRC 的優(yōu)秀算法模型,其中,AlexNet的Top5錯(cuò)誤率為16.4%,但它擁有6 000萬個(gè)參數(shù),如果用float 32存儲(chǔ)這些參數(shù),它將占用移動(dòng)設(shè)備上228 MB的內(nèi)存,與此同時(shí),AlexNet卷積層的FLOPS為663 MB,約占整個(gè)模型FLOPS的92%。顯然,AlexNet并不適合資源有限的移動(dòng)設(shè)備。VGG也是一個(gè)經(jīng)典的分類模型,Top5錯(cuò)誤率達(dá)到7.3%,在準(zhǔn)確率上有較大的提高,其參數(shù)是AlexNet的3倍。不論考慮計(jì)算量還是內(nèi)存開銷,在移動(dòng)設(shè)備上部署深度學(xué)習(xí)模型都是一個(gè)更為嚴(yán)峻的挑戰(zhàn)。GoogleNet和ResNet也必須要面對(duì)這個(gè)問題。為了解決這個(gè)問題,研究人員使用一種主流技術(shù),即壓縮預(yù)先訓(xùn)練的深度學(xué)習(xí)模型。這種策略能夠有效地對(duì)神經(jīng)網(wǎng)絡(luò)模型進(jìn)行修剪,但都是以犧牲精度為代價(jià)的。
本文把分類任務(wù)分為兩個(gè)階段:第一階段定義為粗粒度聚類過程,這個(gè)階段最主要的作用是減少解空間(神經(jīng)網(wǎng)絡(luò)模型需要識(shí)別數(shù)據(jù)集中包含的類數(shù))。在此之后,可以將數(shù)據(jù)聚類為幾個(gè)彼此不相關(guān)的小數(shù)據(jù)集,但在同一聚類中的圖像比在不同聚類中的圖像具有更強(qiáng)的相似性;第二階段是分類過程,在這一階段設(shè)計(jì)了幾個(gè)自定義的輕量級(jí)分類器,分別識(shí)別圖像的特定類。
要完成這項(xiàng)工作,將面臨兩大挑戰(zhàn):一是需要得出一個(gè)粗粒度的聚類方法,用來劃分?jǐn)?shù)據(jù)集的解空間;二是現(xiàn)有的聚類模型都是為了對(duì)圖像進(jìn)行聚類,使圖像盡可能接近標(biāo)簽,目的是訓(xùn)練一個(gè)模型來推斷某一類的圖像信息。為了解決第一個(gè)問題,本文提出了一種粗粒度聚類方法,對(duì)圖像特征進(jìn)行粗聚類,將圖像分為不同的簇。此外,由于移動(dòng)設(shè)備的計(jì)算成本和能耗有限,需要一個(gè)標(biāo)準(zhǔn)來衡量模型是否可以在移動(dòng)設(shè)備上實(shí)現(xiàn),因此本文提出了一種能量預(yù)測(cè)模型來解決第二個(gè)挑戰(zhàn)。
本文系統(tǒng)的優(yōu)勢(shì)和主要工作如下:
(1)本文創(chuàng)新性地利用聚類和分類完成分類任務(wù),使用幾個(gè)輕量級(jí)的神經(jīng)網(wǎng)絡(luò)代替單一的龐大模型,使其在每次推理時(shí)消耗更少的資源。
(2)本文提出了一種能量預(yù)測(cè)方法,通過探索能量與計(jì)算量的關(guān)系,得到一個(gè)轉(zhuǎn)換因子,根據(jù)這個(gè)因子和模型的復(fù)雜性預(yù)測(cè)模型的能耗。
(3)對(duì)于解空間的劃分,本文模型在兩個(gè)階段都可以利用輕量級(jí)神經(jīng)網(wǎng)絡(luò)達(dá)到一定的精度,并且花費(fèi)較少的能量和時(shí)間進(jìn)行推斷。
1 相關(guān)工作
1.1 數(shù)據(jù)聚類
現(xiàn)有的聚類方法[5-6]大多利用或改進(jìn)傳統(tǒng)的機(jī)器學(xué)習(xí)技術(shù)聚類數(shù)據(jù),如K-means[6],這類機(jī)器學(xué)習(xí)聚類方法在cifa-100[7]、ILSVRC2012 1k[8]等各種數(shù)據(jù)集上準(zhǔn)確率較低,因?yàn)樗鼈円蕾囉赟IFT[9]、SURF[10]等特征提取算法,無法提高圖像的表示效果。文獻(xiàn)[11-12]利用深度神經(jīng)網(wǎng)絡(luò)逐步提取更有效的特征表示。深度聚類通過利用K-means對(duì)數(shù)據(jù)特征進(jìn)行聚類,然后使用聚類標(biāo)簽作為偽標(biāo)簽訓(xùn)練ConvNet,獲得了較好的精度[11]。DAC通過將圖像聚類任務(wù)轉(zhuǎn)化為二值兩兩分類問題對(duì)數(shù)據(jù)進(jìn)行聚類,分析對(duì)圖像是否屬于同一個(gè)聚類[12]。這些基于深度學(xué)習(xí)的聚類方法在一定程度上提高了聚類精度,雖然性能仍然不盡如人意,但是這些方法為粗粒度聚類提供了有價(jià)值的設(shè)計(jì)思路。
1.2 數(shù)據(jù)分類
圖像分類是計(jì)算機(jī)視覺領(lǐng)域的一個(gè)熱門課題,有很多優(yōu)秀的研究成果,具體見文獻(xiàn)[1-4]。這些成果為后來的研究提供了許多極好的思路,但是這些模型非常龐大,難以在移動(dòng)設(shè)備上實(shí)現(xiàn),文獻(xiàn)[13-14]致力于將普通模型壓縮成合適的模型。其中,文獻(xiàn)[13]提出了一種利用f×1和1×f濾波器的線性組合代替f×f濾波器實(shí)現(xiàn)低秩近似的壓縮方法。這些框架確實(shí)能在移動(dòng)設(shè)備上運(yùn)行,但它們中的大多數(shù)通過犧牲模型的準(zhǔn)確性來削減模型大小。與這類工作相比,一些神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)方法直接設(shè)計(jì)輕量化模型,見文獻(xiàn)[15-18]。文獻(xiàn)[16]提出了包含擠壓層和擴(kuò)展層的火災(zāi)模塊,以減小模型參數(shù),文獻(xiàn)[17]采用組卷積和通道shuffle兩種操作減少參數(shù)。本文提出了一種考慮解決方案空間和能量消耗的高效深度學(xué)習(xí)框架,使基于卷積網(wǎng)絡(luò)的模型可在資源感知型移動(dòng)設(shè)備上執(zhí)行。
2 系統(tǒng)設(shè)計(jì)
本節(jié)主要介紹了系統(tǒng)設(shè)計(jì)模型,闡述了使用粗粒度聚類的必要性,以及所使用的聚類方法,通過自定義的神經(jīng)網(wǎng)絡(luò)框架對(duì)解空間劃分產(chǎn)生的每個(gè)聚類數(shù)據(jù)進(jìn)行分類。
2.1 解空間
將解空間定義為一個(gè)完整數(shù)據(jù)集需要識(shí)別特定數(shù)量的類。一般來說,隨著樣本數(shù)據(jù)量的增加,數(shù)據(jù)集的解空間也隨之增大。目前在圖像或視頻幀分類方面有很多研究成果能夠表現(xiàn)出良好的圖像分析性能。但是,這些基于神經(jīng)網(wǎng)絡(luò)的模型通常情況下參數(shù)較多,結(jié)構(gòu)極其復(fù)雜,不適合移動(dòng)設(shè)備。盡管壓縮模型可以減少模型在計(jì)算和內(nèi)存上的消耗,但對(duì)于資源有限的移動(dòng)設(shè)備來說,仍然存在不可忽視的問題。此外,由于壓縮方法可能會(huì)對(duì)一些可以產(chǎn)生良好特征的導(dǎo)入濾波器進(jìn)行刪減,壓縮后的模型通常不能達(dá)到與原始模型相同的性能。現(xiàn)實(shí)世界的對(duì)象是不可估計(jì)的,單一的數(shù)據(jù)集不能代表現(xiàn)實(shí)世界的數(shù)據(jù)和數(shù)據(jù)分布。當(dāng)不斷向原始數(shù)據(jù)集中添加新的圖像,使解空間變得更大時(shí),傳統(tǒng)的單一神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)方法會(huì)使模型變得更加復(fù)雜和繁瑣,甚至難以設(shè)計(jì)。針對(duì)這種情況,本文提出了一種新的分類模型,將分類任務(wù)分為兩步,即大規(guī)模解空間劃分和自定義神經(jīng)網(wǎng)絡(luò)框架設(shè)計(jì)。
2.2 大規(guī)模解空間劃分
首先將一個(gè)大的數(shù)據(jù)集劃分成若干個(gè)小的數(shù)據(jù)集,以減小解空間的規(guī)模,該過程如圖1所示。為了劃分?jǐn)?shù)據(jù)集,一種簡(jiǎn)單的方法是將整個(gè)數(shù)據(jù)集中的圖像隨機(jī)分布到K(K<N,N是一個(gè)數(shù)據(jù)集中的類數(shù))個(gè)小數(shù)據(jù)集中。理想情況下,希望小數(shù)據(jù)集具有弱相關(guān)性,甚至彼此無關(guān),但每個(gè)小數(shù)據(jù)集中的數(shù)據(jù)具有強(qiáng)相關(guān)性。針對(duì)這一思想,聚類是實(shí)現(xiàn)這一目標(biāo)的合理方法,然而,傳統(tǒng)的機(jī)器學(xué)習(xí)技術(shù)由于精度較低,已經(jīng)不能適應(yīng)當(dāng)前的要求。因此,本文利用基于CNN的模型劃分?jǐn)?shù)據(jù)集來減少解空間,并將該聚類模型定義為粗粒度聚類模型,該模型的體系結(jié)構(gòu)見表1所列,在此過程中需要識(shí)別的聚類數(shù)目比傳統(tǒng)基于CNN的聚類模型要少,所以聚類模型就會(huì)變成輕量級(jí),本文也采取了一些技術(shù)來提高模型的性能,使模型易于在移動(dòng)設(shè)備上實(shí)現(xiàn),接下來將詳細(xì)介紹基于CNN的粗粒度聚類方法。

表1 粗粒度聚類網(wǎng)絡(luò)結(jié)構(gòu)
圖1 解空間劃分
(1)卷積層
卷積層是卷積網(wǎng)絡(luò)中計(jì)算密集型的一層,它涉及大量的卷積計(jì)算,因此,為ConvNet選擇合適的濾波器是很有意義的。在粗粒度聚類的神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)中,只使用了3×3的核,因?yàn)?×3的核相比1×1的核具有更大的接受域。在神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)中沒有使用5×5或7×7濾波器,是希望減少參數(shù)并獲得同等的性能。值得一提的是,兩個(gè)連續(xù)的3×3濾波器可以分析有25個(gè)像素信息的特征圖,相當(dāng)于一個(gè)5×5濾波器,這使得神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)能力與其他實(shí)現(xiàn)5×5濾波器的算法相當(dāng)甚至更強(qiáng)。
(2)限制層
本文期望用神經(jīng)網(wǎng)絡(luò)的輸出來完成粗粒度聚類。為了獲得更好的特征表示,避免損失函數(shù)中存在ln 0等無意義的解,對(duì)ConvNet生成的輸出進(jìn)行限制,使其保持一定的間隔,這有利于訓(xùn)練ConvNet。具體來說,在神經(jīng)網(wǎng)絡(luò)模型的最后一層之后實(shí)現(xiàn)了限制,將每個(gè)元素限制為(0,1)。該過程的表述如下:

式中:Lin,Lout分別為限制層的輸入和輸出;K表示粗粒度聚類后簇?cái)?shù)的超參數(shù)。
式(1)限制了神經(jīng)網(wǎng)絡(luò)輸出的所有元素,式(2)限制輸出為一個(gè)單位向量。這個(gè)過程只是對(duì)神經(jīng)網(wǎng)絡(luò)的輸出進(jìn)行線性變換,使其學(xué)習(xí)效率更高。在實(shí)現(xiàn)限制層后,對(duì)限制層生成的輸出進(jìn)行聚類,將聚類標(biāo)簽作為偽標(biāo)簽,以分類方式訓(xùn)練模型。
(3)聚類步驟
受深度聚類[11]的啟發(fā),認(rèn)為選擇什么樣的方法對(duì)特征輸出聚類并不重要,只需要一種聚類模式就可以給出聚類圖像所屬的標(biāo)準(zhǔn)。因此,本文選擇K-means聚類方法完成這一步。當(dāng)?shù)玫骄垲悩?biāo)簽時(shí),將聚類標(biāo)簽轉(zhuǎn)換為一個(gè)熱向量,使得數(shù)據(jù)集中的每幅圖像與熱標(biāo)簽相關(guān);可以使輸出的限制和聚類標(biāo)簽擁有相同的維度,其中,k與限制層中表示聚類數(shù)的K相同。
(4)損失函數(shù)
在這一部分中,分布p(x),q(x)分別表示樣本圖像的偽標(biāo)簽和神經(jīng)網(wǎng)絡(luò)模型的輸出,兩者中的x都是特征信息。使用Kullback-Leibler(KL)散度度量特征表示與偽標(biāo)簽之間的差異。注意KL散度是對(duì)兩個(gè)不同分布p(x)和q(x)的非對(duì)稱度量。由式(5)可知,右邊第一項(xiàng)為p(x)的熵,在優(yōu)化過程中為常數(shù),因此,只關(guān)注后一項(xiàng),它被定義為交叉熵,傳播損失來更新神經(jīng)網(wǎng)絡(luò)的權(quán)值。通過解決以下問題計(jì)算損失:

(5)粗粒度聚類標(biāo)簽推理
對(duì)于映像,它必須屬于某個(gè)集群。理想情況下,圖像特征可以是標(biāo)準(zhǔn)的one-hot向量的一種形式,值為1的指標(biāo)是圖像所屬的聚類。基于這一觀點(diǎn),分析了神經(jīng)網(wǎng)絡(luò)模型對(duì)聚類圖像的輸出。訓(xùn)練后,基于卷積神經(jīng)網(wǎng)絡(luò)的聚類模型可以從圖像中提取有效的特征,通過分析神經(jīng)網(wǎng)絡(luò)的輸出對(duì)數(shù)據(jù)進(jìn)行分類是可取的,該過程可制定如下:

式中:li為k維張量,是圖像i的卷積神經(jīng)網(wǎng)絡(luò)的輸出;f(*)為映射函數(shù);ω為模型的權(quán)值;ci是圖像i的聚類標(biāo)號(hào),由張量的最大值產(chǎn)生。理想情況下,一幅圖像的特征li是一個(gè)熱點(diǎn)向量,1表示該圖像屬于這個(gè)簇,0表示該圖像不屬于這個(gè)簇。然而,在現(xiàn)實(shí)中很難通過訓(xùn)練模型得到全局最優(yōu)解,因此,取CNN產(chǎn)生的高級(jí)表示的最大響應(yīng)。
2.3 自定義神經(jīng)網(wǎng)絡(luò)框架設(shè)計(jì)
這部分詳細(xì)介紹了自定義神經(jīng)網(wǎng)絡(luò)框架的設(shè)計(jì)。設(shè)計(jì)K分類器分別對(duì)粗粒度聚類過程生成的K個(gè)數(shù)據(jù)集進(jìn)行分類,從聚類步驟中得到一個(gè)有意義的結(jié)論,即聚類的大小不同。因此,本文提出一種自定義的神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)策略,使模型能夠有效地在目標(biāo)設(shè)備上運(yùn)行,接下來,介紹了神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)中的能量預(yù)測(cè)模型和其他細(xì)節(jié)。
在手機(jī)上實(shí)現(xiàn)深度學(xué)習(xí)模型最重要的問題是能耗和計(jì)算。執(zhí)行一次推理所產(chǎn)生的能量決定了手機(jī)的工作時(shí)間。對(duì)于深度學(xué)習(xí)模型,能耗主要來自兩個(gè)方面:占用的CPU資源;RAM與ROM之間的數(shù)據(jù)交換。這兩個(gè)方面都受到模型處理圖像產(chǎn)生的計(jì)算量的影響。為了確保模型能夠在移動(dòng)設(shè)備上有效地執(zhí)行,本文提出了一個(gè)能量預(yù)測(cè)模型,該模型可以預(yù)測(cè)神經(jīng)網(wǎng)絡(luò)在處理圖像過程中因?yàn)橛?jì)算而產(chǎn)生的能量消耗,預(yù)測(cè)能耗的方法可表述如下:

式中:O代表神經(jīng)網(wǎng)絡(luò)的計(jì)算;Cin,Cout分別是第j個(gè)卷積層的輸入通道和輸出通道;hj-1,ωj-1是輸入要素圖的大小;K是內(nèi)核的大小;Ri代表與特定計(jì)算有關(guān)的能耗;α是能量開銷和計(jì)算量的轉(zhuǎn)換因子,每個(gè)分類器都有自己的轉(zhuǎn)換因子。
由于解空間的減小,可以利用輕權(quán)重神經(jīng)網(wǎng)絡(luò)對(duì)圖像進(jìn)行識(shí)別。因此,在分類器設(shè)計(jì)中,廣泛采用與聚類方法相同的神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)策略。確切地說,只是在卷積層中使用3×3個(gè)過濾器來分析圖像信息,在最后的卷積層之后加入LRN(Local Response,歸一化),使特征分布變得穩(wěn)定。值得注意的是,在最終的完全連接層之后添加softmax層,使用的損失函數(shù)是交叉熵,采用小批量梯度下降優(yōu)化函數(shù)解決了隨機(jī)梯度下降過程中損失不穩(wěn)定的問題。
3 性能測(cè)試預(yù)評(píng)估
在本節(jié)中用提出的系統(tǒng)對(duì)圖像進(jìn)行分類,并在CIFAR-10、CIFAR-100、ILSVRC2012 1k三個(gè)流行的數(shù)據(jù)集上評(píng)估其性能。
3.1 數(shù)據(jù)集和數(shù)據(jù)預(yù)處理
兩個(gè)CIFAR數(shù)據(jù)集包含50 000張訓(xùn)練圖像和10 000張像素為32×32的測(cè)試圖像。CIFAR-10包含10個(gè)類別,而CIFAR-100有100個(gè)更為細(xì)粒度的類別,也可以分為20個(gè)粗粒度的類別。ILSVRC2012 1k數(shù)據(jù)集有1 000個(gè)類別,共120萬張訓(xùn)練圖像和50 000張像素為96×96的測(cè)試圖像(調(diào)整ILSVRC2012的圖像大小以方便處理)。
因?yàn)榘言紨?shù)據(jù)集分為若干個(gè)不同的簇,所以就會(huì)導(dǎo)致每個(gè)簇中的圖像大幅度減少。因此,應(yīng)用了一些數(shù)據(jù)增強(qiáng)技術(shù)來擴(kuò)展數(shù)據(jù)集:首先對(duì)圖像零填充4個(gè)像素,然后隨機(jī)裁剪它們以生成大小為32×32的圖像;再人為地在圖像中產(chǎn)生一些噪點(diǎn);Z分?jǐn)?shù)歸一化用于提高原始數(shù)據(jù)的質(zhì)量,在此步驟中,通過通道均值減去圖像的像素?cái)?shù)據(jù),然后除以標(biāo)準(zhǔn)差。該過程可通過式(10)表示。這些主流的數(shù)據(jù)增強(qiáng)技術(shù)能夠擴(kuò)展原始數(shù)據(jù)集并增強(qiáng)神經(jīng)網(wǎng)絡(luò)的推理能力。

在第一階段將圖像分為幾個(gè)簇。在此階段中不需要使用標(biāo)簽訓(xùn)練模型,但是需要標(biāo)簽測(cè)試模型的性能。因此,采用一種簡(jiǎn)單的方法標(biāo)注圖像的粗粒度標(biāo)簽。注意,CIFAR-100數(shù)據(jù)集為每個(gè)圖像標(biāo)注了粗粒度標(biāo)簽,以表示它的超類,例如,時(shí)鐘、電視、鍵盤都是家用電器,因此,在此階段中不會(huì)對(duì)CIFAR-100做任何處理。在訓(xùn)練提出的模型之前,首先分析了100張圖像的潛在關(guān)系,然后對(duì)原始數(shù)據(jù)集進(jìn)行粗粒度標(biāo)記,最后為數(shù)據(jù)集添加粗粒度列表。
3.2 粗粒度聚類
在對(duì)聚類性能評(píng)估的初步研究中,引入了NMI度量?jī)蓚€(gè)不同的賦值X,Y之間共享的信息。NMI公式如下:
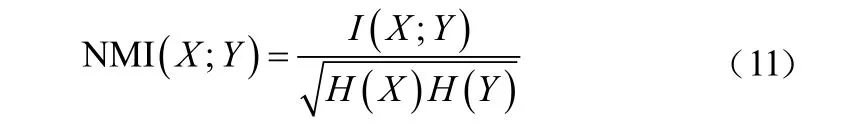
式中:I(*)為X,Y的互信息;H(*)表示熵。具體來說,如果NMI的值越小,則兩個(gè)賦值的相關(guān)性越獨(dú)立。
(1)聚類和粗粒度標(biāo)簽之間的關(guān)聯(lián)
在神經(jīng)網(wǎng)絡(luò)訓(xùn)練之后,通過報(bào)告NMI的演變顯示聚類與人工或自然粗粒度標(biāo)簽之間的動(dòng)態(tài)關(guān)聯(lián)。該度量的目標(biāo)是度量模型的性能,以預(yù)測(cè)圖像的粗粒度簇級(jí)信息。當(dāng)對(duì)一個(gè)神經(jīng)網(wǎng)絡(luò)模型進(jìn)行訓(xùn)練時(shí),模型會(huì)逐漸更新權(quán)重,使推理更加有效。在圖2中,分別展示了CIFAR-10、CIFAR-100和ILSVRC2012 1k數(shù)據(jù)集在訓(xùn)練過程中聚類和粗粒度標(biāo)簽的趨勢(shì)。可以發(fā)現(xiàn),這三條曲線都持續(xù)上升,即粗粒度簇與標(biāo)簽之間的依賴性不斷增加,這說明本文模型可以逐漸產(chǎn)生有效的特征信息來提高聚類性能。
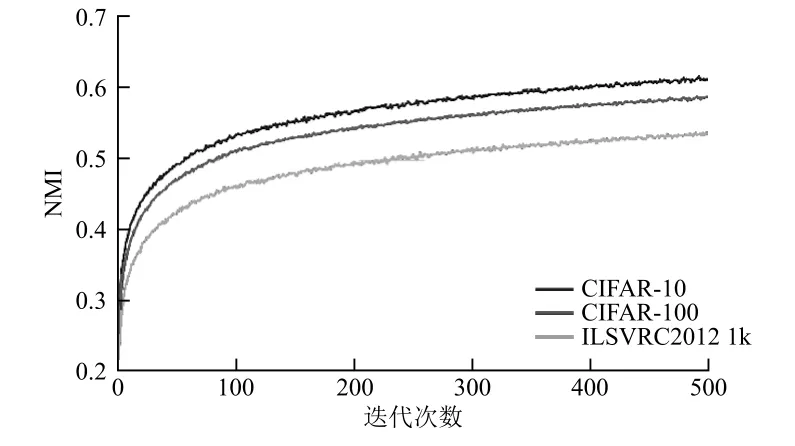
圖2 聚類和粗粒度標(biāo)簽的趨勢(shì)
(2)相鄰訓(xùn)練階段簇間的關(guān)聯(lián)
這一部分簡(jiǎn)要分析了聚類模型在訓(xùn)練階段的穩(wěn)定性。在訓(xùn)練過程中,該模型根據(jù)圖像的特征信息對(duì)圖像進(jìn)行聚類。然而,由于圖像分配的變化情況未知,因此無法斷言聚類的穩(wěn)定性。因此,本文分析了簇在相鄰時(shí)間(t-1和t)的分布。在圖3中報(bào)告了相鄰訓(xùn)練時(shí)段的NMI,以表示模型的內(nèi)部變化。圖中顯示,NMI不斷增加,即訓(xùn)練過程中重新分配的圖像數(shù)量變少,此度量表示本文模型可以有效地對(duì)圖像進(jìn)行聚類,使圖像分布穩(wěn)定。
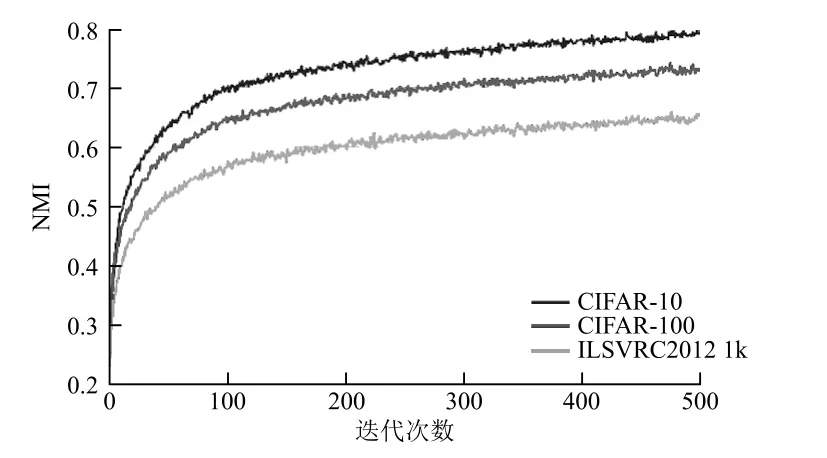
圖3 相鄰訓(xùn)練時(shí)段的NMI變化
(3)粗粒度聚類性能
本文創(chuàng)新性地探索使用粗粒度聚類來劃分原始數(shù)據(jù)集的解空間,因此沒有將聚類性能與其他旨在預(yù)測(cè)特定類的工作進(jìn)行比較。為了將本文模型與其他已有的工作進(jìn)行比較,對(duì)本文模型進(jìn)行了擴(kuò)展,使其能夠預(yù)測(cè)圖像的某類信息。表2中展示了模型在兩個(gè)方面的性能,即NMI和精度。首先,基于深度學(xué)習(xí)方法(如DAC)的性能優(yōu)于傳統(tǒng)機(jī)器學(xué)習(xí)方法(如K-means),因此可以得到特征信息比聚類方法更重要的結(jié)論;其次,與其他工作相比,本文擴(kuò)展模型表現(xiàn)出不錯(cuò)的性能,因?yàn)楸疚闹辉O(shè)計(jì)了一個(gè)簡(jiǎn)單的基于深度學(xué)習(xí)的方法來劃分?jǐn)?shù)據(jù)集的解空間,因此,粗粒度聚類方法在這些聚類方法中能夠表現(xiàn)出最好的性能。
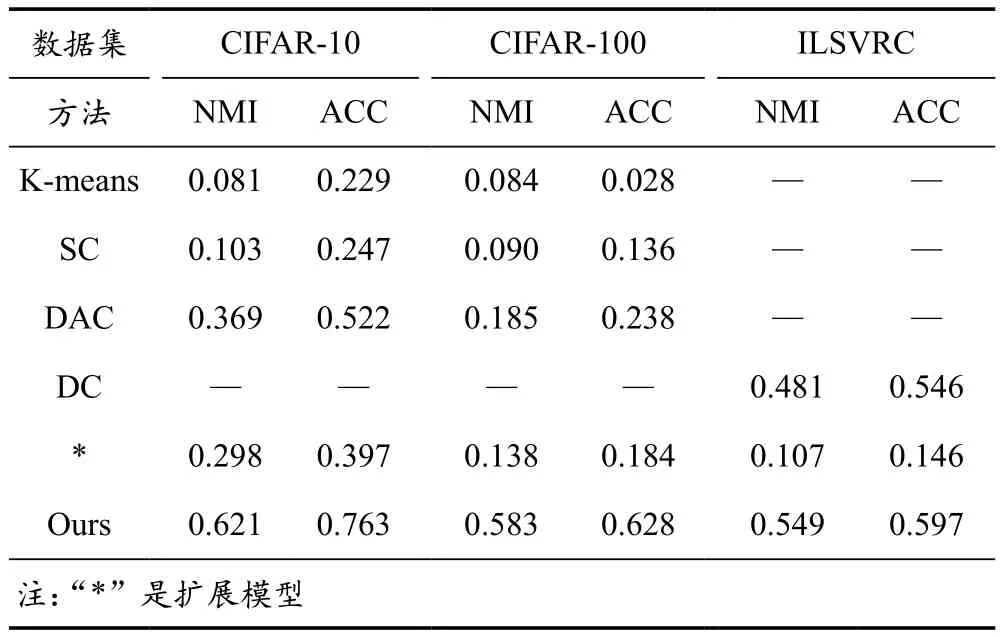
表2 不同聚類方法在三個(gè)數(shù)據(jù)集上的聚類性能對(duì)比
3.3 分類器
本文主要從分類精度和能耗兩個(gè)方面來評(píng)估系統(tǒng)性能。前者驗(yàn)證了模型推理的有效性,后者保證了模型在目標(biāo)設(shè)備上的良好性能。可以用式(8)獲得近似的能耗,然后通過對(duì)預(yù)測(cè)能量和能量存儲(chǔ)量的分析,判斷模型是否適用于移動(dòng)設(shè)備。圖4給出了本文系統(tǒng)和其他主流模型在2個(gè)數(shù)據(jù)集上的性能(數(shù)據(jù)取自其他論文)。本文系統(tǒng)達(dá)到了與其他移動(dòng)服務(wù)模型相當(dāng)?shù)木龋@表明本文系統(tǒng)能夠滿足用戶的需求。在評(píng)估了系統(tǒng)的準(zhǔn)確性之后,使用能量預(yù)測(cè)模型評(píng)估該模型是否能夠有效地在手機(jī)上運(yùn)行。在表3中,本文展示了在ILSVRC2012 1k上訓(xùn)練的幾個(gè)模型的能耗和一些其他特征。計(jì)算量和權(quán)重參數(shù)會(huì)對(duì)內(nèi)存、CPU和GPU造成巨大的壓力,所以計(jì)算量和參數(shù)在一定程度上可以代表能耗。通過與其他模型的比較,發(fā)現(xiàn)本文模型計(jì)算量比其他模型要少,在無人機(jī)上推理一次僅消耗264 mA。因此,本文模型可以滿足目前大多數(shù)移動(dòng)設(shè)備的需求。

圖4 準(zhǔn)確性比較
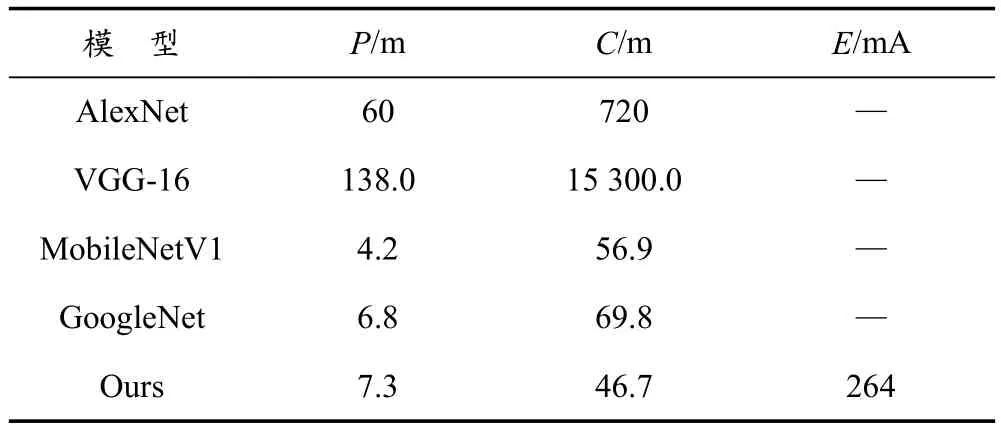
表3 能量消耗和其他特征的比較
4 結(jié) 語
本文提出了一種新的神經(jīng)網(wǎng)絡(luò),通過引入劃分解空間和分類數(shù)據(jù)兩個(gè)階段對(duì)數(shù)據(jù)進(jìn)行分類。前者利用粗粒度聚類方法,允許將數(shù)據(jù)分布到多個(gè)聚類中,后者由上一步產(chǎn)生的具有相同聚類數(shù)的一系列分類器對(duì)每個(gè)聚類進(jìn)行精確分類。這個(gè)過程的優(yōu)點(diǎn)是:可以在兩個(gè)步驟中減輕神經(jīng)網(wǎng)絡(luò)模型的壓力,例如,在聚類步驟中只需要找到一個(gè)大致的聚類模式,使神經(jīng)網(wǎng)絡(luò)不要過于龐大,而在推理步驟中只需要將一個(gè)輕量級(jí)的模型調(diào)用到內(nèi)存中,它可能是單個(gè)模型所占大小的一小部分,這個(gè)過程的結(jié)果使得模型消耗更少的能量,有利于在各種手機(jī)上實(shí)現(xiàn)該模型。與現(xiàn)有的單一神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)方法相比,本文系統(tǒng)在解空間發(fā)生變化時(shí)是等價(jià)穩(wěn)定的,因?yàn)樵诘谝浑A段劃分解空間時(shí),本文模型將數(shù)據(jù)分布到一個(gè)簇中,例如,利用多個(gè)數(shù)據(jù)集代替原來的數(shù)據(jù)集減輕數(shù)據(jù)集的壓力,通過增加解空間產(chǎn)生神經(jīng)網(wǎng)絡(luò)。大量實(shí)驗(yàn)結(jié)果表明,本文模型在CIFAR-10、CIFAR-100和ILSVRC2012 1k的數(shù)據(jù)集上具有良好的性能,并且能耗較低,可以在手機(jī)上進(jìn)行有效的處理。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
兒童故事畫報(bào)(2019年5期)2019-05-26 14:26:14
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長(zhǎng)指南(2015年7期)2015-08-11 15:03:12
小雪花·成長(zhǎng)指南(2015年4期)2015-05-19 14:47:56

- 物聯(lián)網(wǎng)技術(shù)的其它文章
- 新工科背景下醫(yī)學(xué)院校物聯(lián)網(wǎng)專業(yè)人才培養(yǎng)研究
- “1+X”證書制度下高職物聯(lián)網(wǎng)專業(yè)人才培養(yǎng)模式探究
- 新工科背景下軍隊(duì)院校物聯(lián)網(wǎng)工程專業(yè)師資隊(duì)伍建設(shè)初探
- 新工科背景下嵌入式微處理器原理與應(yīng)用實(shí)踐教學(xué)建設(shè)
- 軍隊(duì)院校物聯(lián)網(wǎng)工程專業(yè)實(shí)驗(yàn)室建設(shè)方案研究
- 基于ZigBee智慧農(nóng)業(yè)控制系統(tǒng)的研究與設(shè)計(jì)