基于Mask R-CNN的多目標跟蹤算法
2021-05-26 02:23:42張彩麗劉廣文史浩東李英超
吉林大學學報(理學版) 2021年3期
關(guān)鍵詞:檢測
張彩麗, 劉廣文, 詹 旭, 史浩東, 才 華,3, 李英超
(1. 長春理工大學 電子信息工程學院, 長春 130022; 2. 長春理工大學 光電工程學院, 長春 130022;3. 長春中國光學科學技術(shù)館, 長春 130117)
0 引 言
目標跟蹤是計算機視覺領(lǐng)域中的一個重要研究方向, 在軍事和民用領(lǐng)域應用廣泛, 如視頻監(jiān)控、 人機交互、 無人駕駛、 虛擬現(xiàn)實和增強現(xiàn)實及醫(yī)學圖像處理等. 目標跟蹤包括單目標跟蹤和多目標跟蹤. 單目標跟蹤可通過目標的表觀建模或者運動建模, 處理光照、 形變、 遮擋等問題; 而多目標跟蹤問題較復雜, 除單目標跟蹤遇到的問題外, 還要考慮目標間的關(guān)聯(lián)匹配問題, 且在多目標跟蹤任務中經(jīng)常會遇到目標的頻繁遮擋、 軌跡開始終止時刻未知、 目標過小、 表觀相似、 目標間交互、 低幀率等問題.
多目標跟蹤主要目的為在給定的圖像序列中, 找到該圖像序列中的運動物體, 并將不同幀圖像中的運動物體一一對應, 然后給出這些不同物體的運動軌跡. 根據(jù)是否應用檢測可將多目標跟蹤分為基于檢測的跟蹤與基于首幀圖像框選的跟蹤. 基于首幀圖像框選的跟蹤無法跟蹤首幀圖像外新出現(xiàn)的目標, 所以其應用場景有限; 隨著近年檢測技術(shù)的不斷發(fā)展, 檢測精確度與準確度都在逐步提高, 從而使基于檢測的跟蹤成為首選. 如連續(xù)能量函數(shù)最小化算法(MTT)[1], 其從運動的整體性出發(fā), 將跟蹤問題視為一個能量最小化問題, 先結(jié)合檢測結(jié)果提出一個較貼合運動特征的能量函數(shù), 然后求得該能量函數(shù)的最優(yōu)解, 即為跟蹤結(jié)果.
多目標跟蹤的目標物體可以是任意的, 如行人、 車輛、 運動員、 各種動物等, 而目前研究最多的是行人跟蹤, 所以本文的研究對象也設(shè)定為行人. 對于行人多目標跟蹤的兩個重要問題為: 行人目標可能具有相似性和行人目標可能出現(xiàn)被遮擋問題. 這兩個問題都可由高準確率的檢測器與高準確率數(shù)據(jù)關(guān)聯(lián)解決.
近年來, 隨著深度學習技術(shù)的發(fā)展, 其不僅應用于檢測和識別中, 而且也越來越多地應用于基于檢測的跟蹤算法中. 利用深度學習得到精確的檢測結(jié)果, 使最終的跟蹤結(jié)果更準確. 如Wojke等[2]提出了結(jié)合深度數(shù)據(jù)關(guān)聯(lián)度量方法的簡易實時在線目標追蹤算法(DeepSort), 該算法使用卷積神經(jīng)網(wǎng)絡(CNN)提取檢測結(jié)果, 并通過運動信息與目標外觀信息進行數(shù)據(jù)關(guān)聯(lián), 最后利用級聯(lián)匹配完成長時間的多目標跟蹤; Voigtlaender等[3]提出了雙匹配注意網(wǎng)絡在線多目標跟蹤算法, 該算法將單目標跟蹤與數(shù)據(jù)關(guān)聯(lián)相結(jié)合, 使用時間注意網(wǎng)絡對不同的目標分配不同的注意力分數(shù), 最后使用空間注意力網(wǎng)絡處理嘈雜檢測和遮擋問題; 之后, Voigtlaender等[4]又提出了多目標跟蹤與分割算法(MOTS), 該算法創(chuàng)建了一個像素標記的跟蹤數(shù)據(jù)集, 并且提出一種新的多目標跟蹤度量指標, 最終使用一種聯(lián)合處理檢測、 跟蹤和分割與單一卷積網(wǎng)絡的基線方法, 實現(xiàn)長時間的多目標跟蹤. 由于目前的多目標跟蹤算法大部分是基于檢測的跟蹤, 檢測器和數(shù)據(jù)關(guān)聯(lián)的優(yōu)劣將對最終跟蹤結(jié)果有重要影響.
基于深度學習的目標檢測算法主要分為兩類: two-stage算法和one-stage算法. 其中, two-stage算法是基于候選區(qū)域的目標檢測算法, 經(jīng)典方法包括R-CNN[5],Fast R-CNN[6],Faster R-CNN[7]和Mask R-CNN[8]等; one-stage算法是基于回歸的端到端目標檢測算法, 主流方法有YOLO[9],SSD[10]和DSOD[11]算法等. 這兩種目標檢測算法之間的主要區(qū)別在于其是否分為兩個階段進行檢測, 前者由檢測和分類兩個階段組成, 后者則將這兩個階段融合到一個階段進行. 在性能上, one-stage網(wǎng)絡速度快, 但two-stage網(wǎng)絡準確率更高. 為了多目標跟蹤結(jié)果的準確性, 本文選用two-stage網(wǎng)絡中的Mask R-CNN作為檢測網(wǎng)絡.
數(shù)據(jù)關(guān)聯(lián)優(yōu)化算法可在當前幀圖像到來時就給出當前幀圖像檢測結(jié)果與已有跟蹤目標軌跡的關(guān)聯(lián)匹配結(jié)果, 而不利用未來幀圖像的信息, 從信號處理的角度即相當于一種濾波操作. 目前常用的目標關(guān)聯(lián)方法有最近鄰算法、 概率數(shù)據(jù)關(guān)聯(lián)算法、 多假設(shè)多幀分配算法、 匈牙利算法等. 但這些數(shù)據(jù)關(guān)聯(lián)算法在面對高相似度和遮擋問題時, 效果均不佳, 可能會出現(xiàn)跟蹤失敗的結(jié)果.
本文采用改進匈牙利算法作為數(shù)據(jù)關(guān)聯(lián)算法, 針對發(fā)生遮擋的物體采用級聯(lián)匹配方式. 首先使用Mask R-CNN[8]檢測待跟蹤目標, 再利用Kalman濾波器預測下幀圖像中跟蹤目標的位置與邊界框大小; 然后采用改進匈牙利算法進行數(shù)據(jù)關(guān)聯(lián), 確定行人目標的運動軌跡; 最后針對發(fā)生遮擋的物體加入跟蹤軌跡修正方案.
1 算法設(shè)計
為提高多目標跟蹤的跟蹤準確度及應對遮擋問題時有較好的跟蹤效果. 本文使用Mask R-CNN作為檢測器, 檢測出當前幀圖像中不同大小的行人目標并確定對應的檢測框坐標及可信度; 將檢測器檢測的本幀結(jié)果輸入到Kalman濾波器中預測下幀圖像中行人目標的位置與邊界框大小; 采用改進匈牙利算法利用檢測結(jié)果與預測結(jié)果做數(shù)據(jù)關(guān)聯(lián), 以做到更好的匹配; 針對發(fā)生遮擋的物體加入跟蹤軌跡修正方案, 以實現(xiàn)最終有效準確地跟蹤. 最終實現(xiàn)了55.1%的跟蹤準確度且針對遮擋問題效果較好.
1.1 目標檢測網(wǎng)絡
Mask R-CNN深度神經(jīng)網(wǎng)絡由許多基礎(chǔ)網(wǎng)絡層組成, 主要有卷積層、 池化層、 激活函數(shù)層、 Batch normlization層以及全連接層等.本文選用Mask R-CNN網(wǎng)絡作為檢測器, 在Faster R-CNN的基礎(chǔ)上, 加入Mask branch(FCN)用于生成物體的掩模(object mask), 同時把RoI pooling修改成RoI Align用于處理mask與原圖中物體對不齊的問題. Mask R-CNN整體結(jié)構(gòu)如圖1所示.

圖1 Mask R-CNN整體結(jié)構(gòu)
由圖1可見, 卷積神經(jīng)網(wǎng)絡(CNN)部分使用深度殘差網(wǎng)絡(ResNet101)進行一系列卷積操作提取圖像特征, 與特征金字塔網(wǎng)絡(FPN)共同構(gòu)成骨干網(wǎng)絡. ResNet有5層特征輸出, FPN的作用是特征融合. 這些不同的組合特征, 一方面經(jīng)過區(qū)域推薦網(wǎng)絡(RPN)判斷前景和背景進行二值分類并生成候選框, 另一方面結(jié)合生成的候選框通過RoI Align 操作與特征圖中的像素對應, 隨后的一個分支用于分類和回歸, 另一個分支用于分割生成掩膜.
Mask R-CNN的損失函數(shù)計算過程為
L=Lcls+Lbox+Lmask,
(1)
其中:Lmask為分割誤差;

(2)
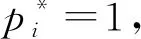
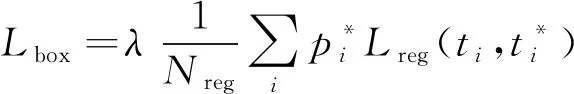
(3)
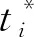
掩膜分支對于每個RoI有K個m×m維的輸出, 編碼了K個m×m像素的二元掩膜,k為輸入維度, 即類別數(shù). 在每個維度都采用Sigmoid函數(shù), 將Lmask定義為平均二元交叉熵損失. 對于每個與真實邊界框相關(guān)聯(lián)的RoI,Lmask僅在第k個掩膜上定義. 將圖像輸入Mask R-CNN后可得到行人目標的位置信息, 包括行人目標檢測框左上角的坐標、 檢測框的長寬及檢測框中檢測物體的置信度, 為下一步跟蹤器提供信息數(shù)據(jù).
1.2 跟蹤器
當用Mask R-CNN獲得每幀圖像中行人目標對應的檢測框坐標及可信度后, 需執(zhí)行對同一行人目標的跟蹤操作, 并使其形成軌跡. 本文采用Kalman濾波器[12]預測下一幀圖像的目標位置, 將Mask R-CNN的檢測結(jié)果輸入Kalman濾波器, 得到該幀的估計值; 然后采用改進匈牙利算法進行數(shù)據(jù)關(guān)聯(lián), 利用檢測框與預測框的交并比及顏色直方圖, 確定行人目標的運動軌跡; 最后對運動軌跡中發(fā)生遮擋的物體加入跟蹤軌跡修正方案, 從而得到更精準的跟蹤軌跡.
1.2.1 Kalman濾波
Kalman濾波利用目標的動態(tài)信息去掉噪聲的影響, 得到一個關(guān)于目標位置的估計[13]. 通過遞歸估計方法, 在已知上幀圖像的估計值(上幀圖像Kalman濾波所得預測結(jié)果)及當前幀圖像的觀測值(當前幀圖像的Mask R-CNN檢測結(jié)果)后, 計算當前幀圖像的估計值. Kalman濾波算法通常通過狀態(tài)方程和觀測方程描述[14]:
xk=Axk-1+Buk-1+ωk-1,
(4)
xk=(xok,vxk,yok,vyk)T,
(5)
zk=Hxk+vk,
(6)
zk=(xok,yok)T.
(7)
式(4)為狀態(tài)方程,xk為第k幀圖像的系統(tǒng)狀態(tài)向量(第k幀圖像估計值),A和B為狀態(tài)轉(zhuǎn)移矩陣,uk-1為系統(tǒng)控制量,ωk-1是協(xié)方差為Q的零均值高斯噪聲. 由式(5)可知,xk包含x和y方向及位置. 式(6)為觀測方程,zk為第k幀圖像的系統(tǒng)觀測向量(第k幀圖像的檢測值),H為觀測矩陣,vk是協(xié)方差為R的零均值高斯噪聲. 由式(7)可知,zk包含x和y方向的位置.
Kalman濾波器算法由5個主要方程組成, 其流程如下:
1) 使用狀態(tài)方程根據(jù)上一幀圖像的狀態(tài)預測本幀圖像的狀態(tài). 若令圖像當前幀為k, 則用第(k-1)幀狀態(tài), 可預測圖像第k幀(本幀)的狀態(tài)為
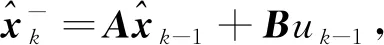
(8)
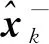
2) 完成圖像的本幀狀態(tài)預測后, 需更新系統(tǒng)協(xié)方差. 估計誤差協(xié)方差更新方程為
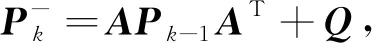
(9)

3) 通過1)和2)得到了系統(tǒng)的預測值, 整合預測值和觀測值, 第k幀圖像最優(yōu)解的求解方程為

(10)
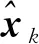
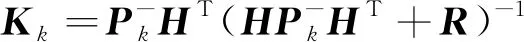
(11)
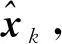

(12)
Kalman濾波可去除檢測結(jié)果中的噪聲部分, 在無適合匹配檢測框的情況下, 可使用Kalman濾波預測物體的位置. 經(jīng)過Kalman濾波得到跟蹤預測框的位置信息, 可為下一步應用匈牙利算法提供信息數(shù)據(jù).
1.2.2 改進的匈牙利算法
匈牙利算法本質(zhì)為一個指派問題, 是圖論中尋找最大匹配的算法. 二分圖也稱為二部圖, 是一種特殊模型[15]. 將一個圖的頂點劃分為兩個不相交子集, 使得每條邊都分別連接兩個集合中的頂點. 如果存在這樣的劃分, 則該圖為一個二分圖. 在多目標跟蹤中可將二分圖理解為視頻中連續(xù)兩幀圖像中的所有檢測框, 第一幀圖像所有檢測框的集合記為U, 第二幀圖像所有檢測框的集合記為V. 同一幀圖像的不同檢測框不會為同一個目標, 所以不需要互相關(guān)聯(lián), 相鄰兩幀圖像的檢測框需要相互聯(lián)通, 最終將相鄰兩幀圖像的檢測框盡量兩兩匹配.
傳統(tǒng)的匈牙利算法是單純基于交并比(iou)的算法, 即求得Mask R-CNN所得檢測框與Kalman濾波所得預測框的iou, 通過匈牙利算法求得iou最大的匹配. 此時雖然速度快, 但準確度較差. 本文在原基于交并比(iou)的匈牙利算法基礎(chǔ)上加入表觀特征的顏色直方圖[16]. 顏色直方圖屬于表觀特征中的目標表示, 顏色特征可有效表示全局目標, 其通過描述不同色彩在整張圖像中所占的比例表示圖像特征, 且具有不受圖像旋轉(zhuǎn)和平移變化影響的優(yōu)點. 一般顏色直方圖在HSV色系下提取.
將HSV的3個分量進行量化, 量化后的取值范圍為{0,1,2,…,LH-1},{0,1,2,…,LS-1},{0,1,2,…,LV-1}, 按(H,S,V)形式排列取值范圍為{0,1,…,LH-1,…,LH+LS-1,…,LH+LS+LV-1}. 設(shè)顏色i的像素點有mi個, 則圖像的像素點總數(shù)為
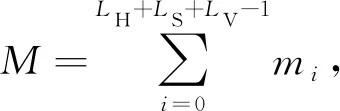
(13)
顏色i出現(xiàn)的概率為
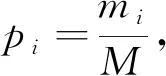
(14)
pi即為顏色直方圖.
將顏色直方圖應用于目標跟蹤時, 可采用巴氏距離計算兩個直方圖的相似度, 公式如下:
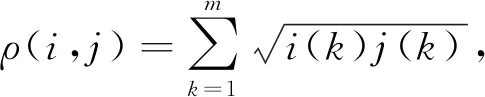
(15)
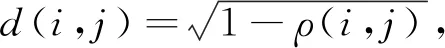
(16)

(17)
其中ρ(i,j)為兩個直方圖的巴氏系數(shù),i(k)為Kalman濾波器預測目標圖像的直方圖,j(k)為Mask R-CNN檢測目標圖像直方圖分布,d(i,j)為兩個直方圖的巴氏距離, 其值越小則兩個圖相似度越高,Cappr(i,j)為表觀關(guān)聯(lián)系數(shù).
對于本文多目標跟蹤中的數(shù)據(jù)關(guān)聯(lián), 首先已完成了用Mask R-CNN網(wǎng)絡檢測出當前幀圖像中的n個行人目標以及邊界框的坐標位置, 使用Kalman濾波根據(jù)上幀圖像的跟蹤結(jié)果完成了當前幀圖像行人目標位置的估計, 得到m個預測結(jié)果, 即m條軌跡. 在已獲得的Mask R-CNN檢測和Kalman濾波獲得的預測結(jié)果后, 先計算兩者的交并比(iou)[17], 再獲得前后幀目標圖像的顏色直方圖, 最后利用iou和直方圖特征加權(quán)構(gòu)造關(guān)聯(lián)矩陣, 表達式如下:
Cij=αCiou(i,j)+βCappr(i,j),
(18)
其中Ciou(i,j)為檢測框與預測框的面積交并比iou,Cappr(i,j)為表觀關(guān)聯(lián)系數(shù),α,β為歸一化權(quán)重系數(shù). 最后將匈牙利算法的關(guān)聯(lián)結(jié)果與Kalman濾波器預測結(jié)果進行匹配, 形成最終的多軌跡跟蹤結(jié)果.
1.2.3 異常軌跡修正

圖2 遮擋情況下的行人跟蹤結(jié)果
當跟蹤目標被部分遮擋時, 利用改進匈牙利算法進行數(shù)據(jù)關(guān)聯(lián), 雖然可能跟蹤到目標, 但效果較差. 例如, 一個行人從開始被遮擋到遮擋結(jié)束的過程如圖2所示. 由圖2可見, 遮擋前后跟蹤目標的ID發(fā)生了轉(zhuǎn)變, 即跟蹤軌跡有發(fā)生中斷的情況[18]. 針對該現(xiàn)象, 本文提出軌跡修正算法, 以減少因遮擋出現(xiàn)的軌跡中斷, 即跟蹤目標ID變換現(xiàn)象.

1.3 算法流程
本文算法流程如圖3所示. 先采用Mask R-CNN網(wǎng)絡進行檢測操作, 檢測出視頻幀圖像中的待跟蹤行人目標; 然后利用Kalman濾波對下一幀圖像中行人目標的具體位置進行估計和預測; 最后使用改進的匈牙利算法將檢測與預測進行匹配, 得到多條長時間目標跟蹤軌跡.
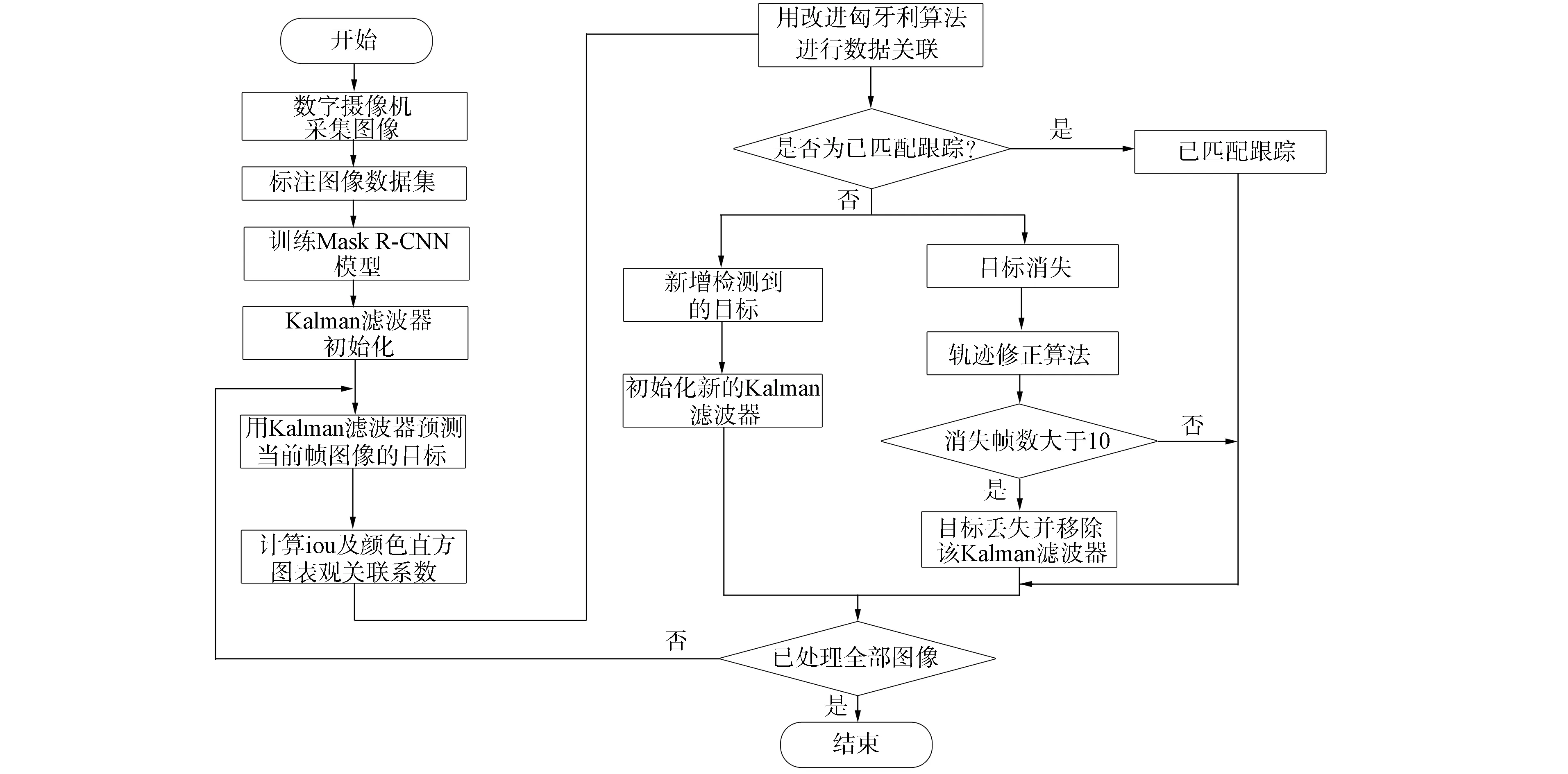
圖3 本文算法流程
步驟1) 用Mask R-CNN網(wǎng)絡進行檢測, 檢測出所有圖像中目標的坐標位置及其置信度;
步驟2) 根據(jù)第一幀圖像的檢測信息初始化Kalman濾波器, 并預測下一幀圖像中各行人目標的位置和大小;
步驟3) 讀入下一幀圖像的檢測結(jié)果, 計算此幀圖像檢測結(jié)果與預測結(jié)果的iou與顏色直方圖, 計算加權(quán)關(guān)聯(lián)矩陣, 用改進的匈牙利算法完成匹配;
步驟4) 若匹配結(jié)束后存在檢測目標剩余, 則用這些剩余檢測結(jié)果初始化新的Kalman濾波器; 若匹配結(jié)束后存在預測目標剩余, 則這些目標可能已消失在視野中或發(fā)生了遮擋情況, 用異常軌跡修復算法修復軌跡, 記錄此時圖像目標消失的幀數(shù), 當圖像目標消失幀數(shù)大于10幀時, 將該目標認定為目標已丟失并刪除其對應的Kalman濾波器;
步驟5) 判斷是否已遍歷整個圖像集, 若已處理全部圖像, 則結(jié)束程序; 否則轉(zhuǎn)步驟3).
2 實 驗
本文實驗數(shù)據(jù)集采用MOT16[19], 該數(shù)據(jù)集包括兩部分: 訓練集與測試集. 數(shù)據(jù)集包含多個行人目標, 且存在目標交互和遮擋現(xiàn)象. 這些數(shù)據(jù)集為攝像頭拍攝的一組連續(xù)圖像, 從第一張圖片到最后一張圖片, 其中包含多個目標, 不斷有出有進, 不斷運動. MOT16訓練集與測試集中各包含7組圖像集. 實驗環(huán)境: 8.00 GB內(nèi)存, 64位操作系統(tǒng), 軟件為Python 3.6.10.
2.1 對比方法
為更好證明本文算法的優(yōu)勢, 采用兩組對比實驗結(jié)果進行系統(tǒng)分析. 第一組為本文算法在MOT16數(shù)據(jù)集不同視頻序列的跟蹤結(jié)果, 分析該算法在不同場景的實驗結(jié)果; 第二組為本文算法與其他4種算法在MOT16數(shù)據(jù)集上跟蹤結(jié)果的對比, 4種對照算法為CppSORT[20],HCC[21],MOTDT[22]和MLT[23].
2.2 評價標準
實驗采用綜合評價指標跟蹤準確率(MOTA)、 跟蹤精度(MOTP)、 成功跟蹤的目標軌跡占真實目標軌跡比例(MT)、 丟失的目標軌道占真實目標軌跡比例(ML)、 跟蹤過程中發(fā)生的目標標簽切換總數(shù)(ID_SW)、 誤檢目標總數(shù)(FP)和漏檢目標總數(shù)(FN)進行定量分析[24].
2.3 實驗結(jié)果及分析
2.3.1 第一組實驗結(jié)果及分析
將本文算法在不同視頻序列上的跟蹤量化結(jié)果進行對比. 在MOT16測試集所有視頻序列上進行實驗, 所得量化結(jié)果列于表1. 本文主要研究跟蹤準確度及當存在目標遮擋情形時的標簽切換問題. 本文算法在不同測試集中的跟蹤準確度與標簽切換總數(shù)的性能分析如圖4所示.
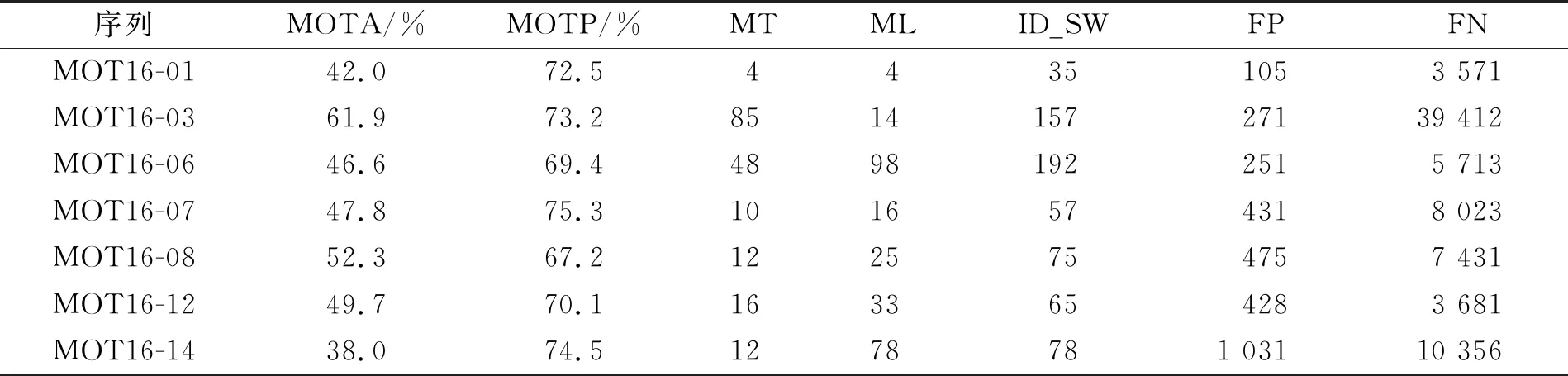
表1 本文算法在MOT16測試集不同序列上的量化跟蹤結(jié)果
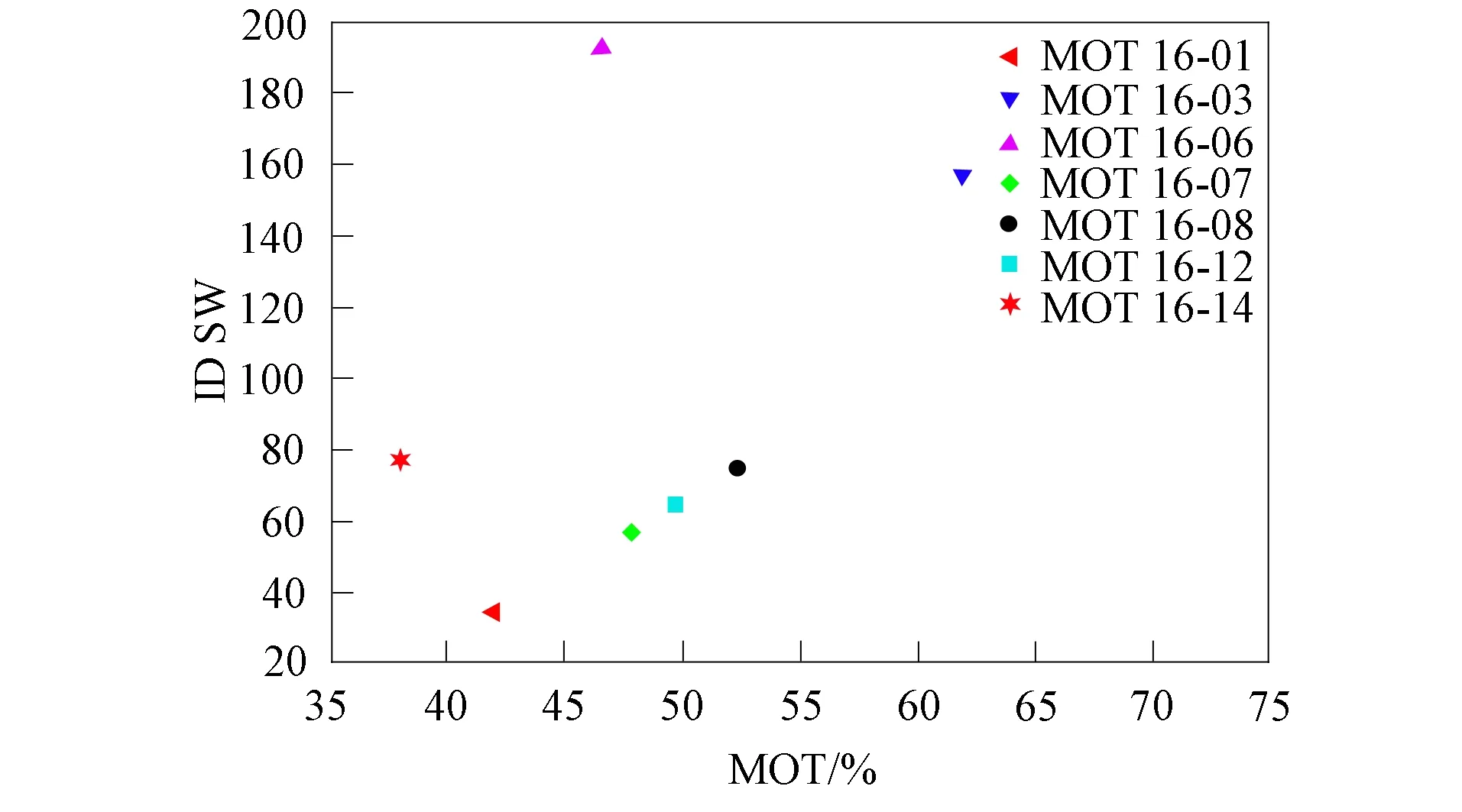
圖4 本文算法在不同測試集上的性能(標記點為MOTA和ID_SW)
由表1可見, 綜合各項性能指標, 本文算法在MOT16-03視頻序列上的跟蹤效果最佳, 在MOT16-14視頻序列上的跟蹤效果最差. 同時通過對圖4中各標記點的觀察, 在權(quán)衡MOTA和ID_SW后也可得到上述結(jié)論. 導致這種現(xiàn)象的原因為MOT16-03視頻序列背景簡單, 行人目標大小適宜且與背景對比明顯; MOT16-14原視頻序列背景復雜, 許多行人目標在視野中過小且與背景對比不明顯. MOT16-01視頻序列存在待跟蹤行人目標過小的情況, 使得最終跟蹤效果一般; MOT16-06視頻序列的圖像分辨率過低, 影響了最終的跟蹤效果; MOT16-07視頻序列中存在行人目標過小且在視頻中存在鏡面成像的現(xiàn)象, 這些因素都會影響最終的跟蹤結(jié)果; MOT16-08視頻序列存在行人目標過小且部分行人目標與背景區(qū)分度較低的現(xiàn)象, 影響了跟蹤結(jié)果; MOT16-12視頻序列中出現(xiàn)了相機晃動的現(xiàn)象且背景變化跨度較大, 導致最后跟蹤效果不佳. 因此, 跟蹤效果除與算法自身的性能相關(guān)外, 還與相機的分辨率、 背景的復雜度、 行人目標的大小等因素密切相關(guān).
2.3.2 第二組實驗結(jié)果及分析
將本文算法與MLT,MOTDT,HCC,CppSORT算法在MOT16數(shù)據(jù)集上的量化跟蹤效果進行對比, 結(jié)果列于表2. 目標跟蹤準確率及標簽切換總數(shù)的性能分析如圖5所示.

表2 不同算法在MOT16數(shù)據(jù)集上的量化跟蹤結(jié)果

圖5 不同算法的跟蹤性能(標記點為MOTA和ID_SW)
由表2可見: 本文算法的MOTA=55.1%, 比排在第二位的MLT算法(MOTA=52.8%)高2.3%; 本文算法的MT=24.6%為5種算法中的最大值, 比排在第二位的MLT算法(MT=21.2%)高3.4%; 且本文算法在數(shù)據(jù)集MOT16中的誤檢數(shù)目和漏檢數(shù)目最少, 為2 992個和78 187個. 上述結(jié)果證明了本文算法有良好的跟蹤準確度且可有效解決目標被遮擋問題的軌跡丟失問題及標簽切換問題. 由圖5可見, 本文算法與MLT算法在跟蹤準確度和遮擋后的標簽切換問題中均取得了較好效果.

圖6 不同算法在跟蹤目標被遮擋情形下的跟蹤效果
為直觀顯示本文算法在處理目標遮擋問題時的優(yōu)勢, 在MOT16-01視頻序列上用本文算法與MLT,MOTDT,HCC,CppSORT算法進行對比實驗, 部分截圖結(jié)果如圖6所示, 其中: 第一行為第413幀圖像目標遮擋發(fā)生前; 第二行為第425幀圖像目標遮擋正在發(fā)生; 第三行為第435幀圖像目標遮擋已結(jié)束. 對比5種算法對同一幀圖像的跟蹤效果可知, 本文算法與MLT算法在如圖6所示的圖像中, 遮擋前后不僅可準確地跟蹤到行人目標, 且未發(fā)生標簽切換; 而MOTDT算法在第435幀圖像出現(xiàn)了漏檢行人目標的問題且存在跟蹤到的目標出現(xiàn)了標簽切換問題; HCC算法雖然在如圖6所示的3幀圖像中都框選到了行人目標, 但存在遮擋前后行人目標標簽切換問題; CppSORT算法在3幀圖像中均出現(xiàn)了漏檢情況, 跟蹤精確度較低. 實驗結(jié)果表明, 本文算法與MLT算法在具有遮擋問題的跟蹤實驗中均可很好地恢復被遮擋目標的標簽, 完成持續(xù)的跟蹤操作.
為進一步對比本文算法與MLT算法的優(yōu)劣, 對比分析兩種算法在MOT16-03數(shù)據(jù)集上的跟蹤結(jié)果, 部分截圖結(jié)果如圖7所示. 對比兩種算法在第670幀、 第1 016幀、 第1 165幀圖像目標的跟蹤結(jié)果可知, 當行人目標存在部分遮擋問題、 姿態(tài)問題和光線問題時, 本文算法的效果更好; 而MLT算法易出現(xiàn)漏檢現(xiàn)象. 實驗結(jié)果表明, 本文算法對不同姿態(tài)的、 存在部分遮擋的、 存在光線問題的目標跟蹤均有較好的效果.

圖7 本文算法與MLT算法目標跟蹤效果對比
綜上所述, 本文使用Mask R-CNN作為檢測器, 實現(xiàn)了基于檢測的多目標跟蹤. 當檢測結(jié)果輸入跟蹤器后, 通過Kalman濾波器預測下一幀圖像的目標位置, 得到先驗概率; 在已知檢測結(jié)果與預測結(jié)果的同時, 計算兩種結(jié)果的交并比及顏色直方圖, 通過加權(quán)和的形式生成關(guān)聯(lián)矩陣, 然后利用匈牙利算法完成匹配; 最后利用迭代完成對整個視頻序列的處理. 針對待跟蹤視頻序列中的遮擋問題引入了異常軌跡修正機制, 即根據(jù)跟蹤框的高寬及中心位置的對比, 修正異常跟-蹤軌跡. 實驗結(jié)果表明, 本文算法在MOT16數(shù)據(jù)集上的跟蹤準確率達55.1%且減少了標簽轉(zhuǎn)換總數(shù). 但由于本文算法基于Mask R-CNN實現(xiàn), 算法的速度還有待進一步提高.
猜你喜歡
中國設(shè)備工程(2022年12期)2022-07-11 04:33:00
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
中學生數(shù)理化·七年級數(shù)學人教版(2019年9期)2019-11-25 07:34:36
中學生數(shù)理化·七年級數(shù)學人教版(2019年9期)2019-11-25 07:34:34
中學生數(shù)理化·七年級數(shù)學人教版(2019年12期)2019-05-21 02:53:50
中學生數(shù)理化·七年級數(shù)學人教版(2019年12期)2019-05-21 02:53:48
