基于殘差神經網絡的煙絲類型識別方法的建立
2021-05-26 10:22:02周明珠劉德祥王宏強李曉輝
煙草科技 2021年5期
關鍵詞:模型
鐘 宇,周明珠,徐 燕,劉德祥,王宏強,董 浩*,3,4,禹 艦,李曉輝,楊 進,邢 軍
1.新疆維吾爾自治區煙草質量監督檢測站,烏魯木齊經濟技術開發區天柱山街55號 830026 2.國家煙草質量監督檢驗中心,鄭州高新技術產業開發區翠竹街6號 450001 3.中國科學院合肥物質科學研究院 安徽光學精密機械研究所 光電子技術研究中心,合肥市蜀山湖路350號 230031 4.中國科學技術大學,合肥市金寨路96號 230026
1 材料與方法
1.1材料
從一批未摻配煙絲中隨機取梗絲、葉絲、膨脹葉絲和再造煙葉絲各100根。
1.2圖像采集與處理
使用500萬像素工業相機和35 mm焦距工業鏡頭(德國Basler acA1920-40gm GigE相機和配套鏡頭),采集4種類型煙絲各100個樣本的圖像,單個圖像大小為2 592像素×1 944像素。
圖像處理、模型建立、數值計算代碼均采用python語言;殘差卷積神經網絡構建采用開源的tensorflow-gpu 1.13.2,keras2.1.5;圖 片 處 理 采 用opencv 4.3.0.36;數據集的組織、分割以及模型評價指標計算采用numpy 1.17.4,pandas 1.0.5,sklearn 0.23.1;圖像處理單元(Graphic Processing Unit,GPU)采用NVIDIA GeForce RTX2060。
1.3 模型構建
1.3.1 數據集構建
通過opencv將樣本縮放至256像素×256像素,以減小樣本內存。將處理后樣本的80%作為訓練集進行模型訓練,20%作為測試集用以驗證模型表現。訓練集和測試集的樣本分布見表1。

表1 訓練集和測試集樣本數量分布Tab.1 Sample quantity distribution of training set and test set (張)

圖1 梗絲樣本圖像Fig.1 Image of cut stem sample
為有效降低模型“過擬合”風險,采用水平/豎直方向平移、水平/豎直方向翻轉、隨機旋轉、隨機縮放、錯切變換等方式對數據集進行增強[15]。圖1為原數據集中梗絲的一個樣本圖像,圖2為梗絲圖像經不同方式變換后的增強圖像。經算法處理后,原數據集從400張增強至7 832張,增強后的訓練集和測試集樣本數量分布見表2。

圖2 梗絲樣本經數據增強后圖像Fig.2 Images of cut stem samples after image enhancement

表2 數據增強后訓練集和測試集樣本數量分布Tab.2 Sample quantity distribution of training set and test set after image enhancement (張)
1.3.2 分類模型構建
基于殘差神經網絡結構構建了煙絲類型分類模型,輸入層為224像素×224像素、3通道的張量。為防止模型“過擬合”,網絡中多處增加了批歸一化層[16],激活層均采用ReLU激活函數[17]。各模型層及輸入圖像張量在網絡前向傳播計算時,張量形狀變化情況見表3。其中,恒等映射模塊及卷積模塊結構見圖3。
1.1.1 患者入選標準 ①首發或復發急性心力衰竭/慢性心力衰竭急性發作期心功能NYHA分級:Ⅲ~Ⅳ級;②休克診斷根據《實用內科學》第十四版標準[1];同時符合以上2項。本研究經本院倫理委員會論證同意開展,所有入組患者均簽署知情同意書。
樣本經輸出層被計算為長度為4的張量,利用公式(1)計算該樣本屬于某分類的概率值。

式中:pi,j—樣本i預測為某分類(j)的概率;Zi,j—樣本i對應的神經網絡輸出張量。
得到概率值后,再利用公式(2)計算該迭代次的損失值。

式中:yi,j—樣本i的真實標簽值,長度為4的張量,j處為1,其余處為0;pi,j—樣本i預測為某分類(j)的概率;m—樣本數。
模型在優化算法的作用下,逐次迭代更新神經網絡權值以降低損失值,直至達到指定迭代次數后停止訓練。
2 結果與分析
2.1 加載權值對模型的影響
在樣本量或訓練資源較少的情況下,訓練出較優的網絡權值需要較多的迭代次數。基于此,遷移學習領域的研究工作近年來取得較大進展[18-20],通過遷移已有的知識來解決目標領域中僅有少量有標簽樣本數據甚至無標簽樣本數據的學習問題。其過程是將已完成訓練的模型權值全部或部分載入到當前模型中,再根據實際問題全部或部分訓練模型的權值,可以有效提高模型的訓練效率。何凱明等[14]在ImageNet數據集上使用殘差神經網絡訓練網絡權值,實現了top-1分類準確率75.3%,top-5分類準確率92.2%,并發布了Resnet50的神經網絡權值。基于本文方法所構建的模型中,特征提取模塊遷移了Resnet50權值,全連接層模塊各層權值的初始值由隨機初始化的方式進行賦值,在模型訓練時,只更新全連接層模塊的權值,特征提取模塊各層權值不更新。對于是否加載遷移的權值,模型在訓練集和測試集上的表現見圖4。可見,加載權值的模型訓練時損失值下降較快,下降曲線較為平滑。在相同迭代次數下,訓練完成時損失值較低,在測試集上的表現相同。加載權值的模型訓練集和測試集的準確率差異不大,且均比不加載權值的模型高,說明模型的泛化能力和準確率均較高。

表3 殘差神經網絡結構Tab.3 Structure of residual neural network

圖3 殘差神經網絡中恒等映射及卷積模塊結構圖Fig.3 Structure of identity mapping module and convolution module in residual neural network

圖4 加載權值對模型的影響Fig.4 Influence of weight loading on model
2.2 優化算法和學習率對模型的影響
優化算法是通過改善訓練方式使損失值最小化。在訓練神經網絡權值時,梯度下降是一種最常用的算法,利用公式(3)對神經網絡的權值進行更新。
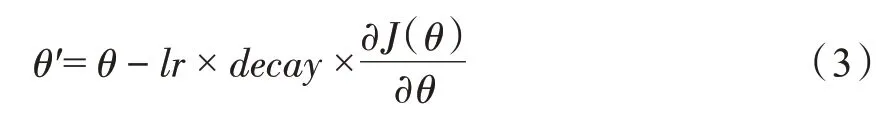
式中:J(θ)—損失函數;θ′—待更新的權值;θ—當前權值;lr—學習率(learning rate);decay—學習率衰減因子,隨著迭代次數增加,動態修改學習率。
Ashia C.Wilson等[21]探討了不同優化算法在CIFAR-10數據集訓練集及測試集上的不同表現。通過對比自適應估計(Adaptive Moment Estimation,Adam)算法及隨機梯度下降(Stochastic Gradient Descent,SGD)算法在不同學習率下的訓練及測試過程可以發現,隨著迭代次數增加,模型會逐步接近較優值,此時較大的學習率不利于模型收斂。因此,在模型訓練過程中,在學習率中加入一個衰減因子,能夠使學習率隨著迭代次數的增加而逐步減小。
學習率對模型表現有顯著影響[22]。不同算法對學習率的適應能力不同,但都表現出相同的規律。當學習率較大時,模型訓練速度快,損失值較快達到最低值且準確率較快上升至最高值,但模型在測試集上表現出較強的波動性,這是因為模型權值在較優值附近“振蕩”,無法收斂,隨迭代次數增加,在衰減因子的作用下學習率逐步降低并最終完成模型訓練;當學習率較小時,模型損失值下降和準確率上升均較為緩慢,在有限次迭代后,模型能力較低,未被完全訓練好。因此,較大和較小的學習率均存在不足,通過對學習率進行網格篩選,確定Adam算法較優學習率為2×10-5(0.000 02),SGD算法較優學習率為2×10-4(0.000 2)。
利用公式(4)~公式(7)計算準確率、召回率、f1分數、加權平均值4項指標,并以此評估模型表現。模型經過200次迭代后,在訓練集上,Adam和SGD算法在較優學習率下的表現見表4。可見,SGD算法的準確率、召回率、f1分數的加權平均值均為99.92%,略高于Adam算法(99.76%),但差異并不顯著。

式中:Pi—某分類的準確率,%;TPi—某分類預測正確的樣品數量,張;Ki—預測為某分類的樣品數量,張。


表4 模型在訓練集上的表現Tab.4 Performance of model on training set
式中:Ri—某分類的召回率,%;TPi—某分類預測正確的樣品數量,張;Ni—某分類的總樣品數量,張。

式中:f1i—某分類的f1分數,%;Pi—某分類的準確率,%;Ri—某分類的召回率,%。

式中:avg_weight—某指標基于樣品數的加權平均值;f—某指標;Ni—某分類的總樣品數量,張。
2.3 模型評估
模型在測試集、原數據集測試集上的表現與卷積神經網絡[9]的表現對比見表5和表6。測試集任一類型煙絲殘差神經網絡分類準確率最低為96.72%,高于卷積神經網絡(58.02%)。其中,葉絲的準確率略低,葉絲、膨脹葉絲的召回率較低,說明葉絲和膨脹葉絲相互誤認的概率較大,加權平均準確率為98.05%,高于卷積神經網絡(60.20%);原數據集測試集任一類型煙絲的分類準確率最低均達到94.74%,高于卷積神經網絡(80.95%),加權平均準確率為97.62%,高于卷積神經網絡(84.95%)。此外,測試集模型f1分數加權平均值為98.04%,訓練集為99.76%,兩者差異不大,說明模型的泛化能力較強。

表5 模型在測試集上的表現Tab.5 Performance of model on test set

表6 模型在原數據集測試集上的表現Tab.6 Performance of model on test set of original data
模型在測試集上的測試結果(表5)表明,識別錯誤和未被識別的樣本數約占2%,主要有兩種情況:一是模型未能區分出膨脹葉絲和葉絲,這是由于在宏觀尺度上,兩者的特征差異不明顯,尤其是少部分葉絲膨脹后沒有顯著變化,從而難以區分;二是部分樣本圖像來源于同一原始樣本數據或圖像增強,模型對其中一個原始圖像如果不能正確判斷,則其增強后的圖像也會出現誤判。因此,要提高模型識別準確率,一方面是增加訓練的樣本類型和數量,另一方面是提高圖像的質量,在訓練集中引入不同方式的增強圖像。
3 結論
為實現煙絲類型的準確識別,利用各類煙絲圖像特征差異,以殘差神經網絡為基礎建立了識別模型,并對模型的識別準確率、召回率、優化算法等進行了研究,結果表明:①基于殘差神經網絡的煙絲類型識別方法具有較高的準確率和召回率,模型測試集準確率和召回率均高于96%,可以有效識別煙絲類型。②模型的訓練集與測試集表現差異較小,模型具有較強的泛化能力。③預訓練權值、優化算法及學習率等超參數對于模型具有較大影響,通過加載預訓練權值可提升模型訓練速度;優化算法對模型表現影響較小,但不同算法的學習率不同,學習率應處于相對適中水平,較高學習率會增加模型收斂難度,較低學習率會降低模型訓練效率。④基于殘差神經網絡的煙絲類型識別方法相比基于卷積神經網絡的識別方法具有更高的識別率、泛化能力及魯棒性。未來將進一步研究煙絲在線收集以及在工業圖像采集條件下的數據集構建和提高模型識別準確率等問題,實現煙絲類型的實時分析。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
