細菌核心基因組多位點序列分型(cgMLST)與溯源評價
2021-05-28 02:41:26朱麗萍張文成顏世敢陳蕾蕾崔生輝
畜牧與獸醫 2021年6期
朱麗萍,張文成,顏世敢*,陳蕾蕾,崔生輝
(1. 齊魯工業大學生物工程學院/山東省微生物工程重點實驗室,山東 濟南 250353;2. 山東省農業科學院農產品研究所,山東 濟南 250100;3. 中國食品藥品檢定研究院,北京 100050)
食品安全關系人民健康和國計民生,是全球關注的熱點問題。食源性疾病是引發食品安全事件的主要因素。全球每年約15億人患食源性疾病,其中約70%是因食品被微生物污染所致。我國46.4%的食品安全事件是由食源性致病菌引起。沙門菌、致病性大腸桿菌、李氏桿菌等是最重要的食源性致病菌。其中沙門菌引起的食物中毒在微生物性食物中毒中占比高達70%~80%,每年造成全球約1.15億人感染和37萬人死亡[1]。加強對沙門菌等食源性致病菌的監控和防控,意義重大且迫在眉睫。
細菌分型是細菌溯源、流行病學調查、食品安全監管的重要手段,對食品安全、公共衛生具有決定性意義。
1 細菌溯源分型技術概述
細菌溯源分型技術包括表型分型技術和基因分型技術兩類。表型分型技術有血清分型、噬菌體分型等;基因分型技術有脈沖場凝膠電泳(pulsed field gel electrophoresis,PFGE)、多位點序列分型(multilocus sequence typing,MLST)、核糖體多位點序列分型(ribosome multilocus sequence typing,rMLST)、全基因組單核苷酸多態性(whole genome single nucleotide polymorphism,wgSNP)、全基因組多位點序列分型(whole genome multilocus sequence typing,wgMLST)、核心基因組多位點序列分型(core genome multilocus sequence typing,cgMLST)等。目前常用的細菌溯源分型技術以血清學分型、PFGE、MLST為主。血清學分型依靠肉眼觀察血清型試驗是否出現凝集而判斷細菌的抗原型,試驗誤差大,分辨率低,再加上細菌的血清型眾多,如沙門菌有2 610種血清型[2],血清學分型的工作量大、耗時長,分型效果不理想。PFGE是根據基因組酶切片段的電泳條帶圖譜進行聚類分析,分辨率及重復性較好,但無法辨別酶切位點之外的基因序列變異,且分型結果受人為因素影響大[3-4]。MLST是基于7~9個管家基因的序列多態性建立的分型技術,重復性、可比性好,但分辨率仍不能滿足精準溯源的需求,無法反映基因組其他幾千個基因的差異[5]。
隨著基因組測序技術的普及和測序成本的降低,基于全基因組序列的分型技術迅速發展成為細菌溯源的主流技術[6]。全基因組分型技術以wgMLST、cgMLST、wgSNP等為代表,分辨率高,重復性好,能夠實現精準溯源[7]。但wgMLST、wgSNP分析消耗巨大的計算資源,一般實驗室難以實現準確分型[8],而且wgSNP對測序的準確性要求極高,必須確保SNP位點的準確性和一致性。cgMLST與wgMLST、wgSNP相比,分辨率相當,僅需要較少的計算能力,可操作性和應用性更強。
cgMLST已廣泛用于沙門菌[1,5,7-9]、耶爾森菌[5]、大腸桿菌[10-11]、李氏桿菌[12-15]、布氏桿菌[16-17]、金黃色葡萄球菌[18]、豬鏈球菌[19]、銅綠假單胞菌[20]、克雷伯菌[21]、結核桿菌[22-23]、雞支原體[24-26]、彎曲桿菌[27-28]等危害人、畜禽的致病菌基因組分型中。由于缺乏統一的分型標準,不同研究者采用的分型方案不同,導致分型結果缺乏可比性。目前為止,尚未見細菌全基因組溯源分型指南的報道。本文通過制定細菌的cgMLST指南,來規范cgMLST分型操作,使cgMLST分型結果具有可比性、重復性,便于分型結果的共享與比較。
2 細菌cgMLST分型與溯源的原理
cgMLST是基于細菌的核心基因組進行的多位點序列分型技術[29],分型精度高,重復性、可比性好,能客觀揭示細菌的遺傳進化關系,為細菌溯源、流行病學調查提供了科學依據[30]。
cgMLST是MLST的升級。MLST是建立在7~9個管家基因的基礎上的,無法反映其他大量基因的異同;而cgMLST是建立大量保守基因基礎上的,具有更高的分辨率,分型結果更客觀、更精準。而且用于cgMLST分型的核心基因中包含了用于MLST分型的所有管家基因,這樣便于將cgMLST結果與已有的MLST分型結果進行比較,檢驗cgMLST分型結果的可靠性。
cgMLST具有高分辨率,能將一種細菌分為多個亞型,通過聚類分析確定不同亞型間的遺傳進化關系,實現更深層次的溯源。cgMLST逐漸成為細菌分型、溯源、分子流行病學研究的重要手段,分型結果可用于不同實驗室間的共享和比較[31]。
2.1 核心基因組的特征
細菌的核心基因是指某種細菌的不同菌株共有的一批保守基因,它們負責該種菌的生物學基本特征及主要表型特征。核心基因具備以下特點:單拷貝基因,即在基因組中只出現一次;非質粒基因;基因內沒有無效的起始/終止密碼子;與其他基因不重疊(overlap);等位基因間不同源。
核心基因組是指根據分型需要人為地將某種細菌不同菌株共有的一定數量的核心基因組合在一起形成的基因群。基于細菌核心基因組序列多態性的分型技術就是cgMLST。
2.2 核心基因組的確定方案
細菌核心基因組的確定有兩種方案:根據菌株的基因組序列比對結果和分析目的,自行確定核心基因組中使用的核心基因的種類和數量多少。采用的核心基因不同,同一株菌獲得的cgMLST分型結果不同,對溯源分析的精度有一定影響;采用EnteroBase、PubMLST、SISTR等分型數據庫公開的核心基因名錄[9]。其中EnteroBase數據庫的數據量大、分辨率高、認可度最高[5]。
2.2.1 自行篩選核心基因組
選用已公開的同種細菌的完整基因組作為“種子”基因組(seed genome)。“種子”基因組需滿足以下條件:基因組完整,最好是采用Sanger法測序,且已完成基因注釋;基因組來自細菌的純培養物;代表株的基因組。
可利用Ridom Seqsphere+、Bionumerics、BPGA(細菌泛基因組分析工具)等生物信息學軟件從全基因組中篩選核心基因[32]。如 Ridom Seqsphere+分型軟件內嵌模塊自動把種子基因組內滿足條件的等位基因全部篩選出來作為核心基因組。
2.2.2 EnteroBase數據庫中公開的核心基因組
EnteroBase數據庫中公開了沙門菌(Salmonella)、大腸桿菌/志賀菌(Escherichia/Shigella)、艱難梭菌(Clostridioides)、弧菌(Vibrio)、螺桿菌(Helicobacter)、耶爾森菌(Yersinia)、莫拉菌(Moraxella)共8種細菌的核心基因組,核心基因的名稱及功能見EnteroBase在線分析網站(http://enterobase.warwick.ac.uk/species/)。其中沙門菌的cgMLST分型方案中包含3 002個等位基因[33]。EnteroBase數據庫中用于cgMLST分型的核心基因的種類是固定的,用戶無法改變核心基因的種類和數量,也無法改變分型使用的算法。通過這種固定化的cgMLST分型方案,可以做到不同分析者采用EnteroBase數據庫對同一株菌進行cgMLST分型獲得的結果具有一致性。
2.3 cgMLST型的賦值規則
通過BLAST、Usearch等分析工具,檢索各分離株基因組序列中的基因位點,與分析模板中的核心基因組的序列進行比對,匹配度≥70%的基因序列被歸類為等位基因,經后續分析后將對其進行賦值;匹配度<70%的基因序列則不再進行后續分析,該等位基因的基因型標記為缺失(Missing)或賦值-1。
所有與模板基因組中的核心基因序列的匹配度≥70%的等位基因被分別賦值,每個等位基因被單獨賦予一個正整數,不同的數值代表不同的基因型,數值之間不存在關聯性,數值大小表示提交時間的先后順序。事先定義各等位基因使用的模板基因組的核心基因的基因型都為“1”,待分析的等位基因序列與模板基因組的核心基因進行BLAST比對,序列相同的等位基因則基因型賦值也為“1”,序列不同的等位基因則按照提交時間的先后順序賦予一個新的基因型數值。同一個數據庫內的等位基因編號與基因序列嚴格一一對應,后續用于分析的基因序列與已經賦值的基因型所對應的序列相同時,重復使用該基因型編號。不同的數據庫因為采用的核心基因組不同,所賦予的同株菌的基因型編號不同。
每株菌的等位基因型編號按照指定的順序排列形成該菌的等位基因譜。
cgMLST型的賦值:為了與MLST分型的ST型區分,cgMLST型簡寫為cgST。賦予種子基因組的cgST型為1。每株菌的等位基因譜與數據庫中已有的等位基因譜比對,如果相同則被賦予相同數值的cgST型;如果不同,則按照向數據庫提交時間的先后順序順位編號賦予一個新的正整數,作為該基因組的cgST基因型。每種cgST型對應唯一的等位基因譜。
2.4 基于cgMLST的細菌基因組溯源分析
cgMLST分型后往往要通過繪制遺傳進化樹,分析菌株間的遺傳距離和親緣關系,實現細菌溯源分析。
繪制進化樹可采用Ridom、Bionumerics或EnteroBase在線分析平臺。在完成cgMLST分型后直接繪制遺傳進化樹;也可以將進化樹數據導出為.nwk文件,利用進化樹修飾軟件(如Figtree、Meqsuite、Dendroscope)進一步修飾。
進化樹的種類有鄰居加入樹(Neighbor Join Tree,NJT)、最小生成樹(Minimum Spanning Tree,MST)、葡萄樹(GrapeTree)等[34]。不同類型的進化樹的形狀不同,但都可用于細菌溯源分析。繪制鄰居加入樹、葡萄樹采用的算法是N-J算法;繪制最小生成樹采用的算法有Kruskal算法或Prim算法。溯源分析時MST的呈現形式更直觀。
EnteroBase在線分析平臺還提供了基于cgMLST的HierCC層次聚類法,可以不用繪制進化樹僅依靠HierCC型數值大致判斷2株菌間的核心基因差異的個數。如果2個細菌的3 002個核心基因中存在2個等位基因差異,2株菌的cgMLST分型不同,即HierCC0聚類時為不同類,但HierCC2聚類時為同一類,且HierCC5、10….聚類時均為同一類。
cgMLST分型后,對于等位(核心)基因差異數≤10的2株菌,判定其具有高度同源性;等位(核心)基因差異數在10~30個時,需要結合流行病學調查與菌株背景信息判斷菌株間的同源性。
3 細菌cgMLST分型使用的數據和生物信息學軟件
3.1 細菌cgMLST分型采用的基因組數據類型
細菌cgMLST分型是建立在基因組高通量測序序列的基礎上進行的。細菌基因組DNA在二代測序儀上測序,得到原始數據(Raw Data),過濾掉低質量的reads,獲得有效數據(Clean Data)。使用組裝、拼接、優化、質控軟件對Clean Data進行組裝、拼接、優化和補洞,過濾掉500 bp以下的片段,最終得到基因組序列(Sequence)。
Raw Data、Clean Data、Sequence都可用于細菌cgMLST分型。但不同的基因組分型軟件采用的基因數據類型有差別。
下載的細菌基因組序列:可以從基因組數據庫(如GenBank)中下載已發布的細菌基因組序列,用作cgMLST分型的基因組數據。
3.2 細菌cgMLST分型需要的生物信息學軟件
3.2.1 Bionumerics(Version 7.6,Applied-Maths, Belgium)
適用數據類型:二代測序Clean Data、拼接的基因組序列及基因組數據庫中的基因組序列文件。Bionumerics的wgMLST分型方案不能自行創立。沙門菌的全基因組分型是基于21 065個等位基因[13]。Bionumerics的wgMLST分型數據庫是Applied-Maths公司自己創建的云數據庫,使用者無法改變分型方案,不同分析者獲得的分型結果一致。
優點:本地軟件加在線數據庫分析,對計算資源配置要求高,Bionumerics軟件的分析功能強大,主要用于細菌wgMLST分析,向下兼容MLST、cgMLST分型,提供多達42種常見微生物的全基因組分型模板。
缺點:軟件使用費較高。
3.2.2 Ridom Seqsphere+(Version 5.1.0,Ridom GmbH,Germany)
適用數據類型:二代測序Clean Data、拼接的基因組序列及基因組數據庫中的基因組序列文件。cgMLST分型方案采用的核心基因組是EnteroBase提供的cgMLST分型方案或通過基因組比對自行創立分型方案。通過本地化軟件分析,結合軟件分型命名數據庫cgMLST.org,實現cgMLST分型。
優點:本地化分析,能夠對分型結果進行多種進化樹繪制,操作較簡單,用戶可自行創立分型方案進行個性化分析。
缺點:軟件使用費高,占用大量的本地計算資源,對計算機硬件要求高。
3.2.3 EnteroBase免費在線分析平臺(http://enterobase.warwick.ac.uk/)
該分析平臺免費注冊使用,但目前僅能進行沙門菌(Salmonella)、大腸桿菌/志賀菌(Escherichia/Shigella)、艱難梭菌(Clostridioides)、弧菌(Vibrio)、螺桿菌(Helicobacter)、耶爾森菌(Yersinia)、莫拉菌(Moraxella)等8種腸桿菌的cgMLST分型和溯源。其中Salmonella分型數據庫包含262 196株菌,有MLST和cgMLST分析模塊;Escherichia/Shigella分型數據庫包含147 636株菌,有MLST和cgMLST分析模塊;Clostridioides分型數據庫包含18 371株菌,有MLST、cgMLST、rMLST分析模塊;Vibrio分型數據庫包含11 364株菌,有rMLST分析模塊;Helicobacter分型數據庫包含5 477株菌,有rMLST分析模塊;Yersinia分型數據庫包含4 915株菌,有MLST和cgMLST分析模塊;Moraxella分型數據庫包含2 564株菌,有MLST和rMLST分析模塊(以上數據截至2020-07-16)。
適用數據類型:二代測序Clean Data,或高質量的完整基因組序列(自己拼接的基因組序列和下載的基因組序列)。cgMLST V2+分型方案的特點:在線分析平臺,權威性高,使用廣。
優點:分析全部通過在線服務器實現,占用的計算機資源較低,對計算機配置要求不高。固定化的分型程序能夠保證分型參數一致,最大程度保證分型結果的可比性。用戶只需上載基因數據便可得到分型結果。在基因組質量要求,EnteroBase僅接受由平臺自身通道生成的組裝基因組且符合重疊群大小N50≥20 kb,基因組大小≥4 Mb并且至少含有97%的核心基因。在數據方面,EnteroBase具有大量的可參比結果,能夠調用更多的菌株進行遺傳進化分析、聚類分析。
缺點:不能進行個性化設置,可操作程度低。上載數據只能是測序的Raw Data,不接受拼接后的基因組序列。
4 cgMLST分型的技術路線
cgMLST分型技術路線見圖1。
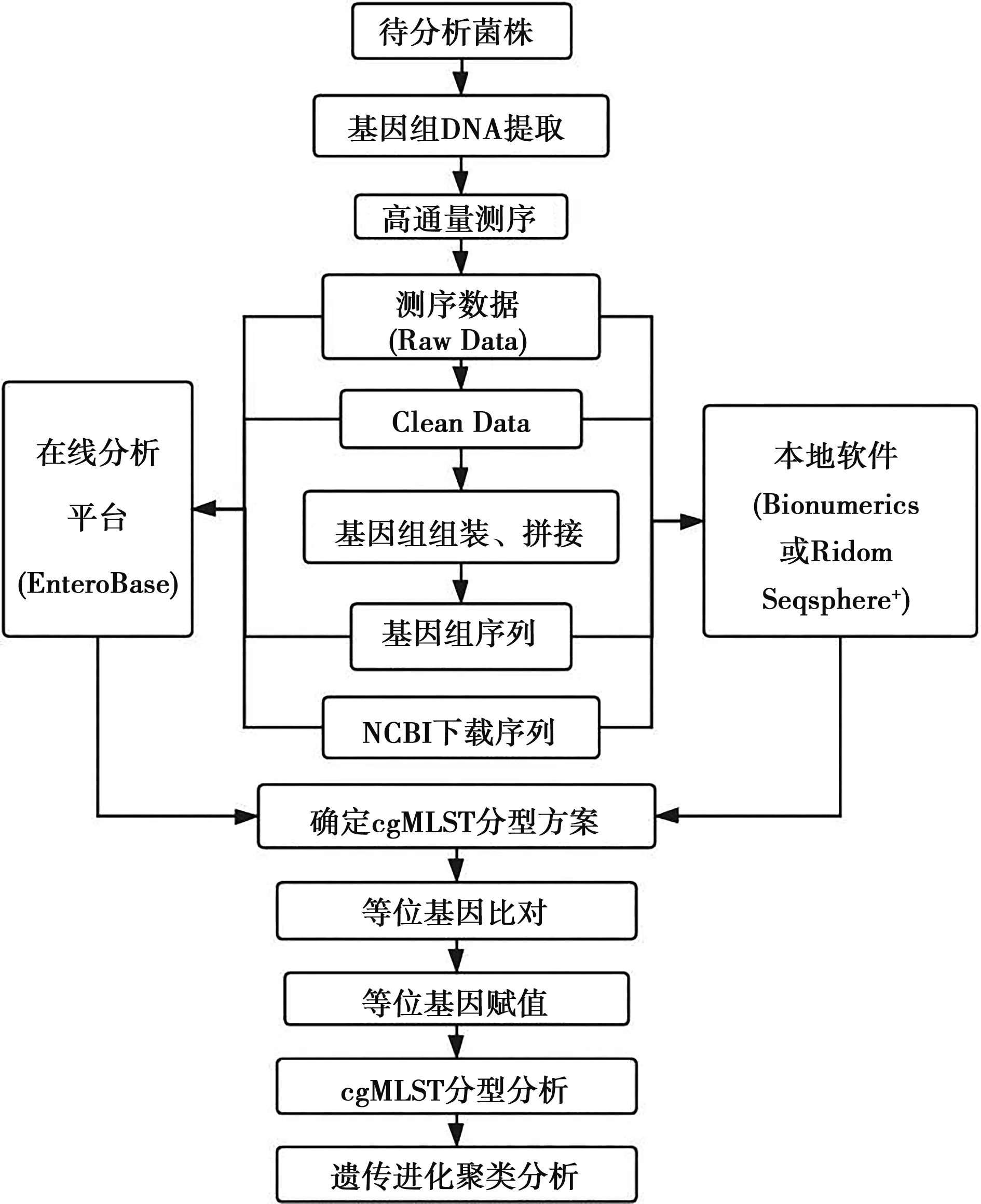
圖1 細菌cgMLST分型技術路線
5 細菌cgMLST分型、溯源分析步驟
5.1 采用公開的cgMLST分型方案
5.1.1 使用Ridom Seqsphere軟件自帶的cgMLST分型方案
創建分析項目。打開Ridom Seqsphere軟件,先登錄服務器(https://www.ridom.de/seqsphere/)上的Ridom SeqSphere+,再啟動客戶端的Ridom SeqSphere+。點擊菜單欄“File”,選擇 “New” 里面的“Create Project”,進入分析項目的編輯界面,給待分析的項目命名及選擇物種信息。本文以沙門菌為例,選擇Salmonellaenterica。然后點擊Download & Add,進入分型方案選擇界面,從分型方案中單獨勾選cgMLST或同時勾選MLST。Ridom SeqSphere+的沙門菌的cgMLST分型方案與EnteroBase中的沙門菌cgMLST v2方案完全相同。每個用于分析的基因組包含的等位基因與該等位基因參照序列進行BLAST,比對分析后保留同源性≥80%的結果,并給該等位基因進行基因型編號;若同源性<80%則該等位基因不會被編號,等位基因的基因型以及菌株的最終基因型命名來源于cgMLST.org數據庫。點擊“OK”完成項目創建。
細菌基因組的cgMLST分析。點擊主界面的菜單欄 “Flie” 中的“Process Assembled Genome Data”,調出已創建的分析項目。添加基因組文件。添加本地基因組通過“Add from File”實現。軟件也支持從NCBI在線獲取基因組,但在線利用NCBI基因組進行分型分析耗時遠大于本地基因組,所以建議先將基因組文件下載到本地磁盤再進行分析。選擇待分析的基因組后,點擊“OK”按鈕,進行分析。若同時選擇MLST與cgMLST兩個模塊,能同時獲得兩種分型結果。
分型結果的呈現與聚類分析。輸入的基因組數據經cgMLST分析后,軟件會自動彈出分析結果預覽表。關閉預覽表后,可在主界面點擊“Tools”中的“Comparison Table”查看cgMLST分型結果。分析后的數據存儲在每個項目下,可再次添加基因組分析數據,若同時選擇MLST與cgMLST分析,會在表格下方出現MLST與cgMLST兩個選擇項目,選擇其中之一便可獲得該分析的全部結果。點擊表格下方的Create Comparison Table便可進入分型結果。
分型結果以表格形式呈現。分型表從左到右各列分別為Missing Values in Distance Columns(缺失基因或因比對結果<80%造成該基因分型失敗的個數)、Perc Good Targets(核心基因中被成功分型的等位基因的百分比,但只有等位基因攜帶率≥90%的樣本才能用于新基因型的提交)、ST(MLST型,相同的ST型被標記成同一種顏色)、Complex Type(cgMLST型)。
點擊分型結果界面上方菜單欄中的進化樹分析按鈕進行進化樹的聚類分析,實現細菌的溯源分析結果可視化查看。
新產生的Complex Type的提交。cgMLST分析后,可能在Complex Type列中產生“?”特征值,這說明該基因組的Complex Type不存在數據庫中,是一個新發現的細菌基因組,需要提交至數據庫中獲取一個新的Complex Type編號(即cgST型)。提交時,選中要提交的樣本,點擊右鍵,選擇“Open Sample”,會在主界面形成一個上傳表,完善上傳表中的基因背景信息,包括分離人姓名、細菌分離時間、宿主來源等信息,填寫完畢,點擊上傳按鈕上傳新產生的cgST型。
5.1.2 使用EnteroBase在線分析平臺進行cgMLST分析
EnteroBase分析的數據對象是Clean Data,或高質量的完整基因組序列。
登錄EnteroBase在線分析平臺的網站(http://enterobase.warwick.ac.uk/),注冊個人賬戶。
選擇與待分析物種相對應的物種首頁,進入Database Home。EnteroBase數據庫中用于分析的物種模塊有Salmonella、Escherichia/Shigella、Clostridioides、Vibrio、Helicobacter、Yersinia、Moraxella。
點擊右側Upload Reads進行基因組數據上載,填寫相關信息,其中紅色框為必填項,然后進行上載基因組數據。首次加載頁面時,將顯示一個空白行,在其中輸入與上傳菌株相關的數據。單擊各單元格,可以通過直接鍵入或從下拉框中選擇來輸入數據,通過右鍵單擊表格并選擇“插入行” 來添加額外的行。
單擊Read Files單元,出現一個對話框用于添加基因組文件。上載Illumina測序平臺的原始數據文件(.fq.gz)。填寫所有必填項后,“提交數據(Submit Data)”按鈕將變為活動狀態,點擊進行上載。
查看基因組組裝結果:返回物種首頁,點擊My Strains,進入個人數據界面。默認會進入基因組組裝結果展示界面,沒有標紅的行即為組裝成功,可進行后續分析。基因組組裝結果的各項參數以表格形式展示,點擊Status列的下載圖標可下載組裝基因組的序列文件。
cgMLST分型結果展示:通過點擊右上角選擇欄中的cgMLST V2 +HierCC V1查看cgMLST分型結果。cgMLST的基因型包括ST(cgST型)和不同HC數值(如HC0、HC2、HC5…HC2850)下的ST型。不同HC數值下的ST型之間不具有可比性。
Grapetree進化樹繪制:點擊GrapeTree圖標,選擇進化樹算法(如N-J算法),彈出窗口完成Grapetree的繪制。可通過左側的相關設定修飾進化樹,最后導出分析結果,可以導出Newick Tree文件格式或者SVG圖片格式。
5.2 自行創立分型方案
該方案適用于大多數細菌cgMLST分型,尤其是那些沒有分型數據庫的細菌的cgMLST分型。以利用Ridom軟件為例,介紹如何自行創立分型方案進行沙門菌cgMLST分型。
登錄軟件:選擇工具欄中的Tools下的cgMLST Target Definer,選擇Seed Genome(可從NCBI上選擇種子基因組序列)。選擇添加或不添加“查詢”基因組(Query Genomes)。添加質粒序列信息(該步驟可以使得與添加的質粒序列中的基因匹配度≥90%且長度>100 bp的基因不在核心基因列表中)。分析參數一般選擇默認,創立分析模板。
打開創立的分析模板:導入待分析的基因組數據(組裝的基因組序列或NCBI中的基因組文件),然后進行cgMLST分析。分析完成后,從任務欄創建分析表,補全菌株相關信息,勾選cgMLST分析項目,查看以圖表形式展示的分型結果。
6 cgMLST分型與溯源分析的注意事項
種子基因組(或模板基因組):種子基因組的選擇對cgMLST分型結果影響大。自行創立分型方案時選用的種子基因組(或模板基因組)要具有代表性、廣泛性、完整性,盡量選用基因數據庫中收錄的完整基因組,不使用自行組裝的分離株的組裝基因組。
cgMLST分型方案中的核心基因組在不同菌株中要廣泛分布且具有完整性。如沙門菌3 002位點分型方案滿足在3 144個有代表性的沙門菌基因組中,每個等位基因至少存在于98%的基因組中,編碼框架至少在每個基因組中的完整性≥94%。
分型參數的設置:可以使用軟件的默認值,以保證獲得的分型結果具有一致性。在同一數據庫下,不同使用者按照相同的步驟、相同的參數,不同分析人員對同一基因組序列分析獲得的分型結果基本一致,具有可比性。
物種匹配與否:提交的基因組序列要與選用模板基因組屬于同一物種。
組裝基因組的質量評價:衡量基因組組裝質量的參數有Coverage、N50、Length、Contig Number、Low Quality等。通常要求基因測序覆蓋倍數>100。選擇合適的基因組重疊群參數,如二代測序的沙門菌組裝基因組的重疊群大小需滿足N50≥20 kb。原則上組裝的基因組大小要大于已知該物種的最小基因組(如沙門菌基因組需>4.0 Mb,不排除基因組較小的特殊性)。
用于基因組測序的細菌必須為克隆株,不存在其他分離株的污染。提取的基因組DNA中也不存在其他物種DNA的污染。
7 小結
細菌溯源分型對食品安全監管、流行病學調查具有重要意義。目前常用的血清學分型、PFGE、MLST等細菌溯源分型方法存在分型精度低、工作量大、耗時長等缺陷,不能滿足細菌精準溯源的需求。以wgMLST、cgMLST、wgSNP等為代表的全基因組分型技術具有分辨率高、重復性好的優點,能夠實現細菌的精準溯源,逐漸成為細菌分型和溯源的主流技術。其中,cgMLST需要較少的計算能力,在細菌分型、菌株演變和暴發溯源等研究中將更具應用價值和發展潛力。
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
山東工業技術(2016年15期)2016-12-01 05:31:22
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
