基于DCNN的火災探測與定位系統
2021-06-04 03:09:08張怡
微型電腦應用 2021年5期
張怡
(成都理工大學 工程技術學院, 四川 樂山 614000)
0 引言
火災是在很短的時間內對生命和財產造成重大損害的異常事件[1]。火災探測可分為兩大類:傳統火災報警和視覺傳感器輔助火災探測。傳統的火災報警系統基于需要近距離激活的傳感器。這些傳感器不太適合關鍵環境,在發生警報時需要人的參與來確認火災,包括探索火災位置。此外,這樣的系統通常不能提供關于火災的大小、位置和燃燒程度的信息。為了克服這些局限性,目前研究人員探索了許多基于視覺傳感器的方法[2-6],但這些系統仍然存在一些問題,例如觀察到的場景的復雜性、不規則的照明,以及低質量的幀;較高精度的算法其計算量也較大,而簡單的方法在精確度和誤報率方面存在較大誤差。因此,有必要在這些度量之間找到一個更好的折衷,以滿足一些實際應用場景的實際需求,所以在此提出了一個基于深度卷積神經網絡(DCNN)[7]的監控網絡中的早期火災探測系統(Fire Detection based on DCNN)。由于在系統中使用轉移學習策略訓練并微調AlexNet架構[8],使得系統尺寸較小。并且該系統可以智能地選擇對火災區域敏感的特征映射,從而更精確地分割火焰,達到精度的提升和誤報率減小。
1 系統構成和原理
為了實現高精度,多場景自動火災檢測,在此提出了FDC系統。本節主要對FDC系統進行介紹,給出了FDC系統框架圖,如圖1所示。
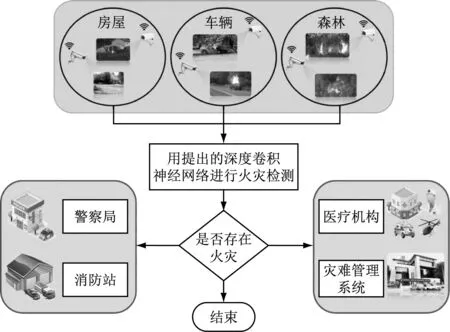
圖1 FDC系統框架圖
1.1 相關原理介紹
整個FDC系統框架主要是基于DCNN架構,典型的DCNN架構由三個處理層組成:卷積層,池化層和完全連接層[9]。這些層以層次結構排列,使得一層的輸出充當下一層的輸入。在訓練階段,調整和學習卷積核和完全連通層中所有神經元的權重。這些權重對輸入訓練數據的代表性特征進行建模,進而進行目標分類。
在系統中使用類似于SqueezeNet[10]的模型來檢測火災和非火災圖像。該模型由2個規則卷積層、3個最大池化層、1個平均池化層和8個Fire模塊組成,輸入的是224×224×3像素的彩色圖像。在第一個卷積層,將64個3×3大小的濾波器應用于輸入圖像,生成64個特征映射。這64個特征映射的最大激活由第一個最大池化層選擇,其步長為2個像素,使用3×3像素的鄰域。這樣可以將特征圖的大小縮小兩倍,從而保留最有用的信息,同時丟棄不太重要的細節。接下來,使用兩個128個過濾器的Fire模塊,然后是另一個256個過濾器的Fire模塊。每個Fire模塊還包括兩個進一步的卷積、壓縮和膨脹。由于每個模塊由多個濾波器分辨率組成,并且在Caffe框架中沒有對此類卷積層的本地支持[11],因此引入了一個擴展層,每個Fire模塊中有兩個獨立的卷積層。第一層卷積包含1×1個濾波器,第二層包含3×3個濾波器。這兩個層的輸出在通道維度中連接。在3個Fire模塊之后,還有另一個最大池化層,其操作方式與第一個最大池化層相同。在512個濾波器的最后一個Fire模塊(Fire9)之后,修改卷積層,將類數減少到兩個[M=2(fire和normal)]。該層的輸出被傳遞到平均池化層,該層的結果直接輸入到Softmax分類器中,以計算兩個目標類的概率。
在FDC系統中還采用一種轉換學習策略,以進一步提高學習的準確性。采用這種策略,使用了一個預訓練的SqueezeNet模型,并根據分類問題對其進行了微調,由于學習速度較慢。所以刪除了最后一個完全連接層,以提高效率。
2 用于火災探測和定位的DCNN
本節介紹了使用所提出的DCNN進行火災探測和定位的過程。在系統中用不同的參數設置訓練不同的模型,經過微調過程,得到了一個在不同條件下,在室內和室外場景下,能夠遠距離、小范圍探測火災的最優模型。
使用DCNN的另一個動機因素是為了避免預處理和特征標注。在FDC系統中,圖像通過DCNN發送,它給輸入的圖像分配一個“fire”或“normal”標簽。這個標簽是根據網絡計算的概率分數來分配的。以較高的概率得分作為輸入圖像的最終類別標簽。一組樣本圖像及其預測的類標簽和概率分數,如圖2所示。
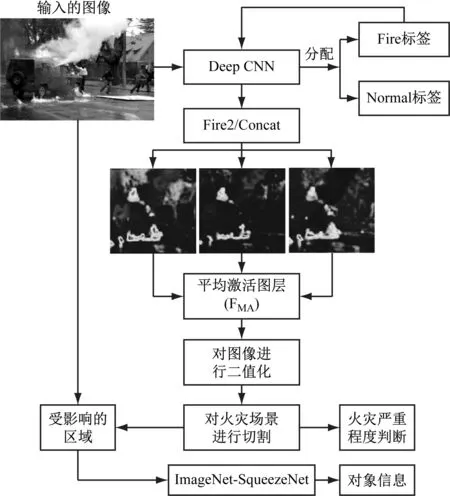
圖2 使用DCNN進行火災定位
為了在樣本圖像中定位火災,使用圖2中給出的框架。首先,從DCNN得到了一個預測。在非火災的情況下,不執行進一步的操作;在發生火災的情況下,對其定位進行進一步的處理,如算法1和算法2所示。

算法1 Feature Map Selection輸入:訓練樣本(TS)、真實值(GT)和提出的CNN模型(CNN-M)輸出:對火敏感的特征圖1. 通過CNN-M前向傳播TS2. 從CNN-M的L層中選擇特征圖TS3. 將GT和FN調整為256×256像素4. 計算FN的平均激活圖FMAi5. 對每個特征圖Fi進行二值化:F(x,y)bin(i)=1, F(x,y)i>FMA(i)0, Otherwise 6. 計算GT和每個特征圖Fbin(i)之間的漢明距離HDi:HDi=|Fbin(i)-GT|,這就產生了TS×FN漢明距離7. 計算所有生成的漢明距離之和,并使用閾值T短列最小漢明距離8. 根據列出的漢明距離選擇適當的特征圖
算法1的流程圖,如圖3所示。

圖3 算法1的流程圖

算法2:火災定位算法輸入:視頻序列的圖像I和提出的深層CNN模型(CNN-M)輸出:分段火災的二進制圖像Ilocalize1. 從視頻序列中選擇一個幀并通過CNN-M向前傳播2. if predicted label = non-fire thencontinueelsea) 從CNN-M的“Fire2/Concat”層提取特征映射8、26和32(F8,F26,F32)b) 計算F8,F26和F32的平均激活圖(FMA)c) 通過閾值T對FMA應用二值化:FLocalize=1, FMA>T0, Otherwise d) 從FMA中分割火災區域endif
在使用算法1分析了提出的CNN不同層的所有特征映射后,由于“Fire2/Concat”層的特征映射8、26和32對火災區域敏感,適合火災定位。因此,融合了這3個特征映射并應用二值化來分割火焰,給出了一組帶有分割區域的火災圖像樣本,如圖4所示。
對火災進行分割的目的為:(1) 確定被觀察場景的嚴重程度/燃燒程度;(2) 從輸入的火災圖像中找到影響區域(ZOI)。根據分割后的火焰像素數可以確定燃燒程度。ZOI可以通過從原始輸入圖像中減去分割的火焰區域來計算。生成的ZOI圖像隨后從最初的SqueezeNet模型傳遞過來,該模型從1 000個對象中預測其標簽。對象信息可用于確定場景中的情況。這些信息,連同火災的嚴重程度,可以報告給消防隊,以便采取適當的行動。
3 實驗與評估
3.1 實驗環境
本文實驗主要是基于一臺英特爾i7處理器上的臺式機,其內存為64 GB,操作系統為Ubuntu,顯卡為英偉達GeForce GTX TITAN X,使用python 3.0進行實現。實驗中數據集為公開數據集[12],在該數據集中包含在不同環境中捕獲的31個視頻。在這些視頻中,包括火災的視頻有14個,而普通視頻有17個。總共使用了68 457張圖像。其中20%和80%的數據分別用于訓練和測試。

3.2 實驗結果
3.2.1 性能對比
在這里選擇了六個現有方法與FDC系統進行對比。結果如表1所示。

表1 各種火災探測方法的比較
文獻[15]和[16]在漏報方面表現最好。然而這兩個方法在誤報和準確性上表現不是很理想。對于誤報來說,文獻[17]表現最好,但其漏報率為14.09%,是所有檢測方法中最差的。為了獲得較高的準確率和較低的誤報率,在此研究了使用深度特征進行火災探測。首先使用了不帶微調的AlexNet架構,其準確率為89.96%,誤報率從11.67%降低到9.12%。在baseline AlexNet體系結構中,核的權重是隨機初始化的,并且在訓練過程中考慮到錯誤率和準確度而進行修改。在這里還應用了轉移學習的策略,通過這種策略,從預訓練的AlexNet模型初始化權重,結果準確率提高了4.33%,漏報和誤報分別減少了8.5%和0.15%。
3.2.2 實際定位結果對比
在這里將從火災定位和對所觀察到的場景的理解來評估本文方法的性能。計算漏報率和誤報率率來評價火災定位的性能。用來定位火災的特征圖比真實圖像小,因此調整了大小以匹配真實圖像的大小。然后,計算了探測地圖和地面真實圖像中重疊火力像素的數目,并將其作為誤報。同樣,還確定了探測圖中不重疊的火災像素的數量,并將其解釋為漏報。
將FDC的結果與一些現有方法進行對比,其結果如圖5所示。
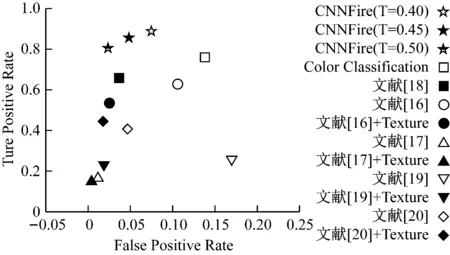
圖5 本文方法與其他方法對比結果
根據算法2中二值化過程的閾值T,在此報告了3種不同的CNNFire結果。從圖5可以看出,FDC系統在漏報率和誤報率之間保持了較好的平衡,使其更適合于監控系統中的火災定位。
4 總結
火災是最危險的異常事件,如不及早控制,可能造成巨大的災害,給人類、生態和經濟造成損失。受DCNN巨大潛力的啟發,在此提出了一種基于DCNN的輕量級閉路電視監控網火災探測系統FDC。該法既能定位火源,又能識別監控對象。此外,FDC系統分別使用微調和SqueezeNet架構來平衡火災探測的準確性和模型的大小。通過公開數據集,驗證了該系統在實際中部署的可行性。考慮到CNN模型對火災探測和定位的合理精度、規模和誤報率,該系統有助于災害管理團隊及時控制火災,避免巨大損失。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
家庭影院技術(2017年9期)2017-09-26 03:41:45
