基于K-means聚類算法的學生表現數據分析及預測建模研究
2021-06-04 03:15:32呂丁
微型電腦應用 2021年5期
關鍵詞:學生
呂丁
(陜西警官職業學院 治安系, 陜西 西安 710021)
0 引言
本文通過對不同校園管理系統數據進行預處理,去除重復、缺失的臟數據,并基于傳統K-means算法建立學生表現行為的預測模型,對學生表現行為分類,通過針對不同類型學生特征,實現對學生校園表現的針對性管理。
1 K-means的數據預處理
1.1 數據挖掘
數據挖掘在以海量數據分析的基礎上,提取滿足不同業務目標數據信息的過程,并將信息反饋給用戶。為獲得滿足用戶需求的潛在有效信息,就要求對表層信息進行充分挖掘,去除冗余數據,并將關鍵數據能可視化的展示到用戶面前。預測和描述作為數據挖掘的兩個目標,預測指的是利用數據庫中某些信息字段和變量預測隱含的有用信息,描述指將數據描述成可理解模式[1-3]。
本文采用ETL工具來獲得校園一卡通系統、學生管理系統、圖書館系統和教務系統的數據信息,在對各數據管理系統的基礎上,選擇“學號、貧困生等級、獎學金等級、德育成績、體育成績、智育成績、競賽等級”7個屬性作為特征評價指標[4-6]。
1.2 數據的清理
數據的清理主要包括格式的標準化、異常數據和重復數據的清除和錯誤數據糾正。通過查詢某一高校成績管理系統,就能獲得近40余萬條信息,整個數據量極為龐大,因此有必要對一部分重復數據進行清除,并從其他系統中獲取其他維度的數據來補充整個數據庫。如成績系統中包括了學生各科目成績信息,而學生的獎學金、競賽信息均處于空缺,同時部分學生的某些成績表存在很多空缺數據,這主要是由于學生缺考、補考或一些未知原因造成。對于該類噪聲數據,從學生狀態重查出信息,將學生成績信息予以刪除操作。
針對學生成績信息,按照學期準則進行聚類,即對各科成績進行泛化處理,用高級層次值代替,獲得各科成績的泛化績點,如式(1)。
(1)
式中,i為科目數;Si和Xi分別為第i科得分和學分;J為績點數。Xi學分劃分為優秀、良好、及格、不及格,相應的得分轉化分別為90分、80分、60分和0分。
對困難級別的數據變化,將學生困難程度劃分為特別困難生、一般困難生、非困難生,對應的級別表示分別為2、1、0。
在學生競賽方面,學校教務管理系統采用文字形式描述,本文根據分析調查,采用以數字方式來表征競賽級別,如表1所示。
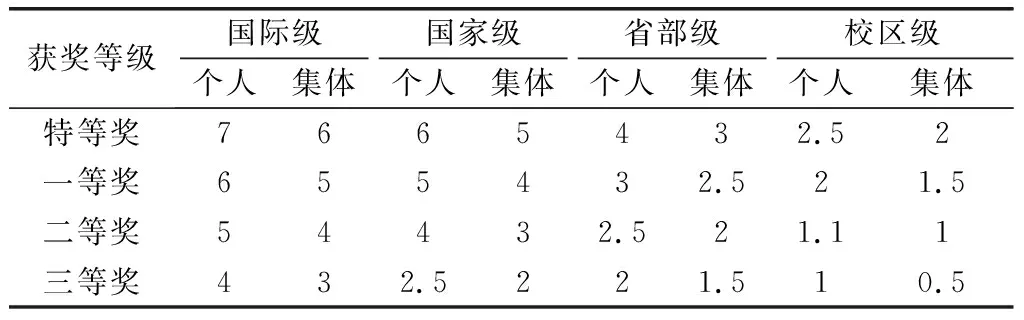
表1 學科競賽等級分值轉換
通過對競賽等級進行數值轉換,形成一個累積的加分制度。
獎學金在學生數據庫中同樣采用文字表達方式,由于系統中對應每個獎學金等級建立了對應的金額,基于此,本文對學生獎學金力度屬性,將獎學金金額轉化為相應的力度屬性,如式(2)。
(2)
式中,i為獎學金數量;Xi為獲得獎學金金額;V為獎學金力度。
在學生管理系統中,德育成績和體育成績均是以數據形式存儲的,滿分分別為20分和5分。
2 優化的K-Means聚類算法
K-Means作為經典的聚類算法,主要是通過迭代過程實現數據集類別的不同劃分,該算法具有簡單異性可擴展性強的優點[7-8]。K-Means算法首先從樣本集S中任意選擇K個樣本作為初始聚類中心。然后根據規則算法進行數據對象間距離,通過獲得的數據對象分組情況迭代計算直至中心無變化,得到K各聚類結果。算法的具體實現流程如下。
(1) 在K-Mean聚類算法中,設定算法輸入樣本集中包括n個數據對象和K個聚類個數;
(2) 根據聚類樣本聚類,計算得到各樣本與中心間距離,然后根據獲得的最小計算距離重新劃分對象。設兩個p維數據點xi=(xi1,xi2,…,xip)和xj=(xj1,xj2,…,xjp)間的歐氏距離,如式(3)。
(3)
確定所有樣本的平均距離為式(4)。
(4)
(3) 重新計算獲得每個樣本的均值后,返回步驟(2),直到目標函數值不變或小于指定閾值。確定目標函數的平方誤差準則函數,為式(5)。
(5)
式中,ci為相同類別數據的質心點,定義ci計算公式為式(6)。
(6)
式中,|Ci|是類Ci數據對象數量;ci表示第i個簇中心。
(4) 結束,獲得K個聚類。
對于K-means算法,算法簡單,效率高。但算法聚類數K時和中心點的選取都缺乏明確標準定義,大部分都是隨機給定的,這樣容易對算法結果造成較大影響。基于此本文提出一種解決初始值K的選擇方法。在K值選擇中,根據實際情況限定聚類的范圍,即假設聚類數K范圍為(m,n),則進行n-m次K-means傳統算法,并從多次聚類中選擇最優聚類數作為最佳聚類樹,設聚類各部各節點距離中心的歐氏距離為式(7)。
(7)
在初始點選取中,要求中心點互相距離最大化,初始中心周邊點必須密集。對于中心點互相距離為式(8)。
(8)
d作為所有中心點距離和的均值,能較好地表現聚類中心相互距離整體情況。對于聚類中各元素點的密度,計算方法,如式(9)。
(9)
式中,pi點xi周圍點密集程度,值越大,密度越大,則周圍點越多。其中zi為樣本點間距離,因此采用pi能較好地反應出i點周圍密集程度,確定zi的計算,如式(10)。
(10)
通過優化的K-means算法的具體流程如圖1所示。

圖1 改進的K-means算法流
3 學生校園表現聚類分析
3.1 樣本數據處理
通過對K-means算法改進,根據上節對數據預處理的基礎上,選擇“貧困生等級、獎學金等級、德育成績、體育成績、智育成績、競賽等級”數據作為六維評價輸入變量,設定最大迭代次數為10,經過預處理后的數據格式如圖2所示。

圖2 整理的學生數據表
上述數據是基于不同量綱獲得的整合數據,因此,需要對這些不同維度數據進行量綱統一,具體的計算為式(11)。
(11)
其中,xij為個體元素值。通過量綱統一后的待測數據能更真實的反映學生活動的數據聚類情況。
3.2 算法的核心代碼優化
定義算法所用到的數據的類屬性,如圖3所示。

圖3 初始化函數運行代碼
其中,K為聚類數;logo為分類標識;center為數據舊中心;centernew為新中心;train為輸入數據樣本;dimension為數據維度。對算法數據進行初始化操作,每進行一次優化算法則執行一次初始化函數。圖3為函數的運行代碼。其中表示擁有30組測試數據,一組6個維度,并確定初始化數據中心和K值的大小[6]。
算法在Windows 8PRO操作系統運行,數據庫采用SQLsever 2 000,navicat,給出改良后的K-means算法的部分核心代碼,如圖4所示。

圖4 改進K-means算法的核心代碼
3.3 優化分析結果
通過聚類分析,獲得選取學生的分類信息和各方面的平均值結果,如表2所示。

表2 學生類別平均分析值
優化K-means算法將學生分為4個類別。其中第一類學生成績中等,家庭較困難,并沒有享受過獎學金或競賽獎勵;第二類學生成績下游,家庭一般,未享受獎學金和競賽獎勵;第三類學生成績良好,競賽成績優秀,享受獎學金較高,家庭一般;第四類學生成績優秀、獲得過獎學金和競賽獎勵,家庭困難。
學生管理系統中幾位學生的分類情況,如圖5所示。

圖5 學生表現情況分析表
由圖5可知,根據選擇的類別屬性,系統將每一位學生根據自己的學號得到了其在德育、體育、競賽、智育、獎學金、貧困情況方面的分類級別。根據聚類算法后的學生分類結果,可以讓高校輔導人員對學生的具體情況進行有針對性的管理,符合當前高校學生“德、智、體、美、勞”的綜合發展需求。
4 總結
本文選擇學生校園表現進行研究,通過對學生生活、學習、活動等行為特征數據分析挖掘,采聚類算法建立學生生活表現類別模型,實現對學生生活表現數據,將學生進行分類。文中以校園一卡通系統、教務管理系統、學生管理系統數據為基礎,針對數據系統中“臟數據”進行預處理,通過數據清洗、集成和變換數據存儲格式,得到滿足K-mrans算法的維度輸入數據。針對傳統K-mrans算法聚類數K、中心點的選取容易造成算法結果偏差,根據實際情況限定聚類的范圍,得到最佳聚類K值和中心點,并添加量綱矩陣系數對學生表現進行聚類,最后通過在學生管理系統中寫入算法核心代碼建立學生表現模型,分析出不同類型學生行為特征,并指導學生日常管理工作。
猜你喜歡
作文大王·笑話大王(2021年4期)2021-04-26 19:00:35
英語文摘(2020年9期)2020-11-26 08:10:12
甘肅教育(2020年6期)2020-09-11 07:45:16
甘肅教育(2020年22期)2020-04-13 08:10:54
甘肅教育(2020年20期)2020-04-13 08:04:42
當代陜西(2019年5期)2019-11-17 04:27:32
電影(2018年9期)2018-11-14 06:57:21
作文世界(小學版)(2018年4期)2018-10-16 17:13:34
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
快樂作文·低年級(2016年6期)2016-06-24 18:58:40
