基于深度卷積神經(jīng)網(wǎng)絡的航拍目標檢測
2021-06-04 03:09:10趙玉瑩
微型電腦應用 2021年5期
趙玉瑩
(東北石油大學 計算機與信息技術學院, 大慶 163000)
0 引言
航拍圖像是指由無人機搭載高清攝像設備以俯拍的角度獲取地面的圖像信息。近些年,國家對于無人機的研究,已從簡單的飛行操作到實現(xiàn)偵查、勘探等功能。隨著人工智能技術的飛速發(fā)展,結合無人機等硬件設施已在交通監(jiān)管、農(nóng)林管理、智慧城市等領域得到廣泛應用。為了實現(xiàn)對地面信息的精準識別,航空影像的目標檢測技術已成為人們研究的重點。
在航拍圖像中存在背景龐雜,場景多樣,目標相對較小等情況[1],傳統(tǒng)的目標檢測方法無法滿足當前航拍圖像檢測的要求。自Hinton等人在2012年的ImageNet競賽中提出AlexNet網(wǎng)絡以來[2],依靠手工提取特征的傳統(tǒng)目標檢測方法已被基于卷積神經(jīng)網(wǎng)絡(CNN)的目標檢測方法所取締。目前基于CNN的目標檢測方法可歸納為兩種類型:一種是分兩個階段來完成目標檢測任務,該方法先將圖像中可能存在目標的區(qū)域都標記出來,即生成目標的候選框;然后采用基于CNN的模型將候選區(qū)域進行正確的分類。如R-CNN[3]、Faster R-CNN[4]、R-FCN[5]等都在公共數(shù)據(jù)集上實現(xiàn)了對目標的精準檢測和語義分割。但該類方法中會存在大量的候選框,使得對特征提取的計算量過大,導致檢測的速度過慢,無法滿足實時檢測的需求。針對這類方法存在的問題,研究學者們提出端到端的檢測方法。2016年,Redmon等人[6]提出了YOLO,其使用了回歸思想,將輸入的圖像分為大小一致的多個區(qū)域,直接在每個區(qū)域上預測相應的目標邊框與類別[7],相較于Faster R-CNN算法,檢測的速度提高許多,但是檢測的準確率略有遜色。同年,SSD方法結合了YOLO算法的回歸思想與Faster R-CNN中的多尺度特征提取方法[8],實現(xiàn)了檢測的精準性與實時性,然而對小目標的檢測結果依然不夠理想。航拍影像的獲取具有特殊性,存在目標尺度小、噪聲較多、背景龐雜等特性,因此無法將這些方法直接用于航拍目標檢測。
為解決以上問題,本文提出一種基于深度殘差網(wǎng)絡多特征融合的目標檢測模型。本文的主要工作是采用基于端到端的SSD網(wǎng)絡框架,引入深度殘差網(wǎng)絡(ResNet)為基礎網(wǎng)絡增強網(wǎng)絡的學習能力,緩解由網(wǎng)絡加深產(chǎn)生的梯度消失現(xiàn)象,并采用特征金字塔(FPN)結構實現(xiàn)底層特征與高層語義信息的融合;提高對航拍影像中小目標檢測的精準性與魯棒性。
1 基于深度卷積神經(jīng)網(wǎng)絡的航拍目標檢測算法
1.1 深度殘差網(wǎng)絡
ResNet是2015年何凱明等人提出的用于圖像分類識別的一種深度卷積神經(jīng)網(wǎng)絡[9],其網(wǎng)絡的核心是通過對前后卷積層之間添加了“跳躍連接”機制,如圖1所示。
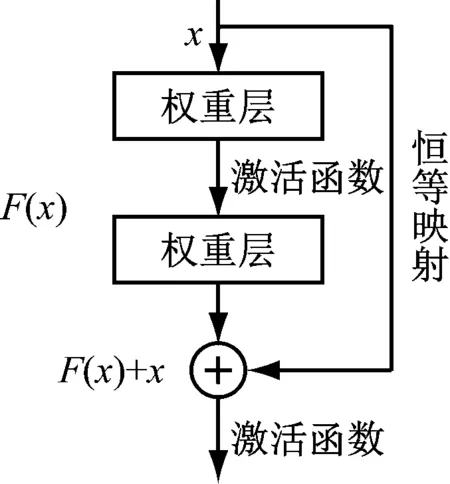
圖1 殘差塊結構圖
x為殘差塊的輸入;H(x)為模塊的輸出。定義另一個殘差映射函數(shù)F(x)=H(x)-x,那么原始的映射函數(shù)為H(x)=F(x)+x,可以看作是主路徑上的F(x)與跳躍連接中的x之和,這種結構實現(xiàn)了恒等映射的學習,在網(wǎng)絡訓練中促進梯度的反向傳播,還可以訓練更深的CNN。
將殘差塊的輸入設為xl,網(wǎng)絡的輸出設為xl+1,得到結構的計算過程為式(1)、式(2)。
yl=h(xl)+F(xl,Wl)
(1)
xl+1=f(yl)
(2)
式(2)中,f為激活函數(shù),本文采用ReLU函數(shù)。如果h(xl)=xl和f(yl)=yl是恒等映射,那么表達可為式(3)。
xl+1=xl+F(xl,Wl)
(3)
通過網(wǎng)絡的層數(shù)增加,不斷增加殘差塊,最后得到的遞歸式為式(4)。
(4)
式中,L表示任意深的殘差塊。
而對于梯度的反向傳播,設損失函數(shù)為θ,那么可以得到式(5)。
(5)

1.2 特征融合
雖然深度殘差網(wǎng)絡加深了網(wǎng)絡對目標特征的學習,但是對底層特征圖的利用不充分,致使小目標的檢測結果不夠理想。本文將FPN的思想添加到檢測模型的網(wǎng)絡結構中,把低層特征的邊緣信息和高層特征的豐富語義信息通過橫向連接和top-down網(wǎng)絡融合起來,實現(xiàn)對各個尺度卷積層的特征信息的充分利用,提升航拍圖像中多尺度目標的檢測精度。
對ResNet網(wǎng)絡的conv2,conv3,conv4和conv5層中最后經(jīng)過激活函數(shù)的輸出用{C2,C3,C4,C5}表示,然后在C5上添加1×1的卷積生成特征圖P5,再將P5與經(jīng)過1×1卷積處理后的C4合并生成P4,同理依次生成P3,P2,最后對{P2,P3,P4}的特征圖附加3×3卷積生成最終的特征圖,如圖2所示。
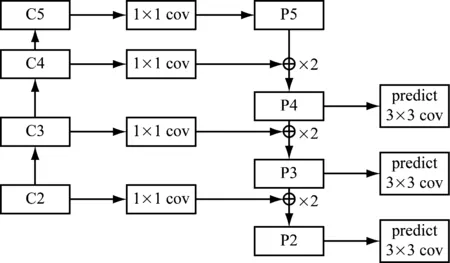
圖2 特征融合網(wǎng)絡結構
采用特征圖金字塔網(wǎng)絡結構將淺層特征與深層特征進行融合,有效地解決了網(wǎng)絡較深時淺層小目標易丟失、無法獲取豐富的語義信息的問題。
1.3 本文目標檢測模型
本文提出的檢測模型的網(wǎng)絡結構,如圖3所示。
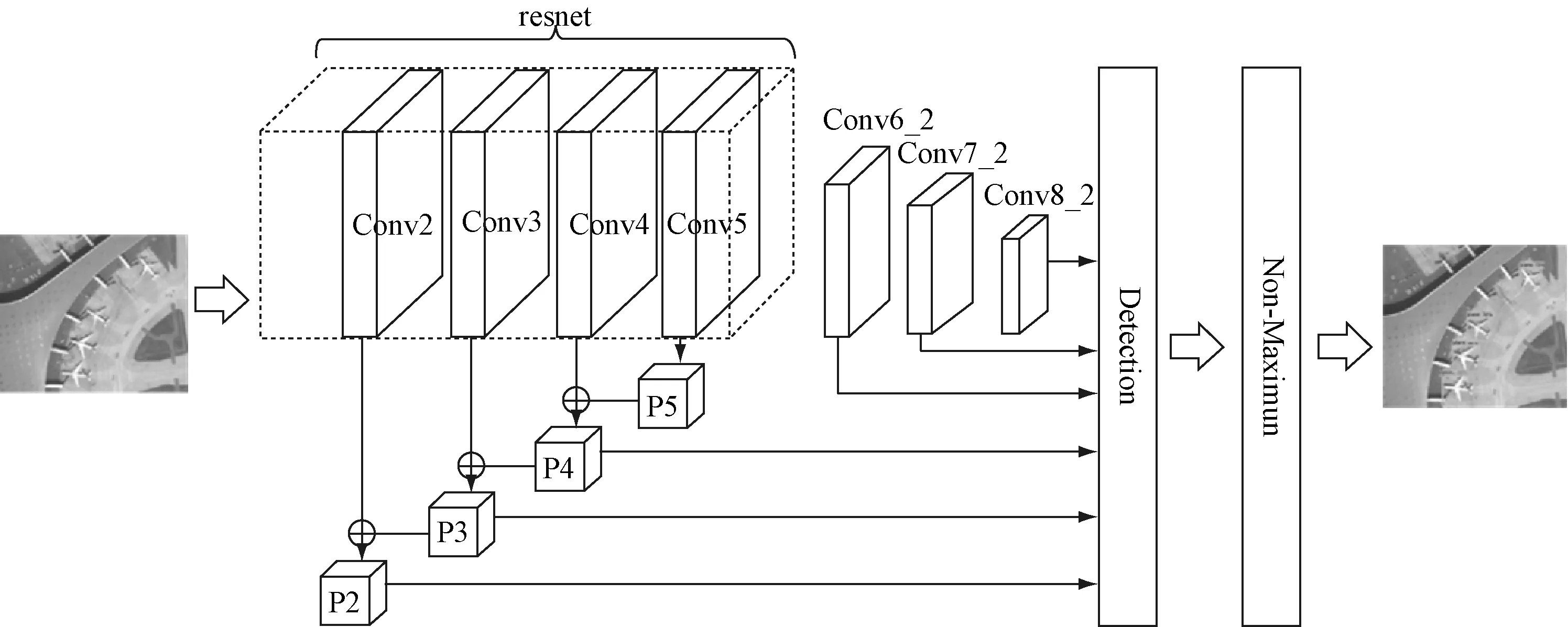
圖3 本文檢測模型的網(wǎng)絡結構圖
將原始的ResNet網(wǎng)絡去掉最后的全連接層和Softmax層后的網(wǎng)絡層作為本文檢測模型的基礎網(wǎng)絡,并將conv2,conv3,conv4特征融合后生成的特征圖與新增卷積層中conv6_2,conv7_2,conv8_2的特征圖一同進行預測。
對于每個特征層上的默認框本文采取不同的寬高比,由此提取多尺度的目標特征。每個默認框大小計算式為式(6)。
(6)
式中m表示特征圖的數(shù)量;Sk表示默認框的大小相對于整張圖片的比例;Smin和Smax表示比例的最小值和最大值,分別設為0.2和0.9,可計算得出每個默認框的尺寸,其寬高設置為式(7)。
(7)
式中,ar為長寬比,取值為ar∈{1,2,3,1/2,1/3},由此對每個特征圖設計5個不同尺寸的默認框用以提取目標。
生成特征圖后根據(jù)目標函數(shù)進行分類與定位,因此目標函數(shù)分成類別損失與位置損失兩部分,類別損失是計算生成的默認框與目標類別之間的誤差,為式(8)。
(8)
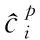
位置損失是計算預測框相對于真實物體邊界框的誤差,使用Smooth L1 loss進行計算,為式(9)。
(9)
式中,l代表預測框與默認框之間的變換關系;g代表真實物體邊界框與默認框之間的變換關系。最后的目標損失函數(shù)為置信損失Lconf(x,c)和位置損失Lloc(x,l,g)兩部分的加權和,其計算式為式(10)。
(10)
式中,N表示與真實物體邊界框對應的預測框的個數(shù);α表示用來決定類別損失和位置損失所占權重的參數(shù),一般取值為1[11]。最后使用非最大值抑制NMS過濾掉重疊度較大的預測框,最終剩余的預測框即為檢測結果。
2 實驗與結果分析
2.1 數(shù)據(jù)集制作與分析
本文實驗使用的圖像數(shù)據(jù)集是提取了DOTA[12]、UCAS_AOD、RSOD-Dataset等航拍數(shù)據(jù)集以及自己制作的航拍飛機檢測數(shù)據(jù)集,并通過鏡像、旋轉、添加噪聲、拼接等方式進行數(shù)據(jù)增廣,如圖4所示。
最終制作了6 525張航拍飛機圖像數(shù)據(jù)集,并對每張圖像中飛機標注的面積占整張圖像的比例進行了統(tǒng)計,如圖5所示。

圖4 數(shù)據(jù)增廣示例

圖5 目標面積占圖像面積的比例統(tǒng)計
本實驗的數(shù)據(jù)集中共計有29 914個飛機目標,其中占整張圖像面積小于5%的就有25 283個,說明該數(shù)據(jù)集中多數(shù)為小目標。
2.2 實驗環(huán)境與訓練
實驗環(huán)境及具體配置參數(shù),如表1所示。
在模型訓練的過程中,學習率初始設為0.03,采用隨機下降法進行優(yōu)化,處理批次為4,共迭代了3萬次,前15 000次中學習率為0.03,然后將學習率下調至0.000 1再訓練15 000次,最后模型在20 000次左右整體損失函數(shù)得到收斂的最佳效果,如圖6所示。
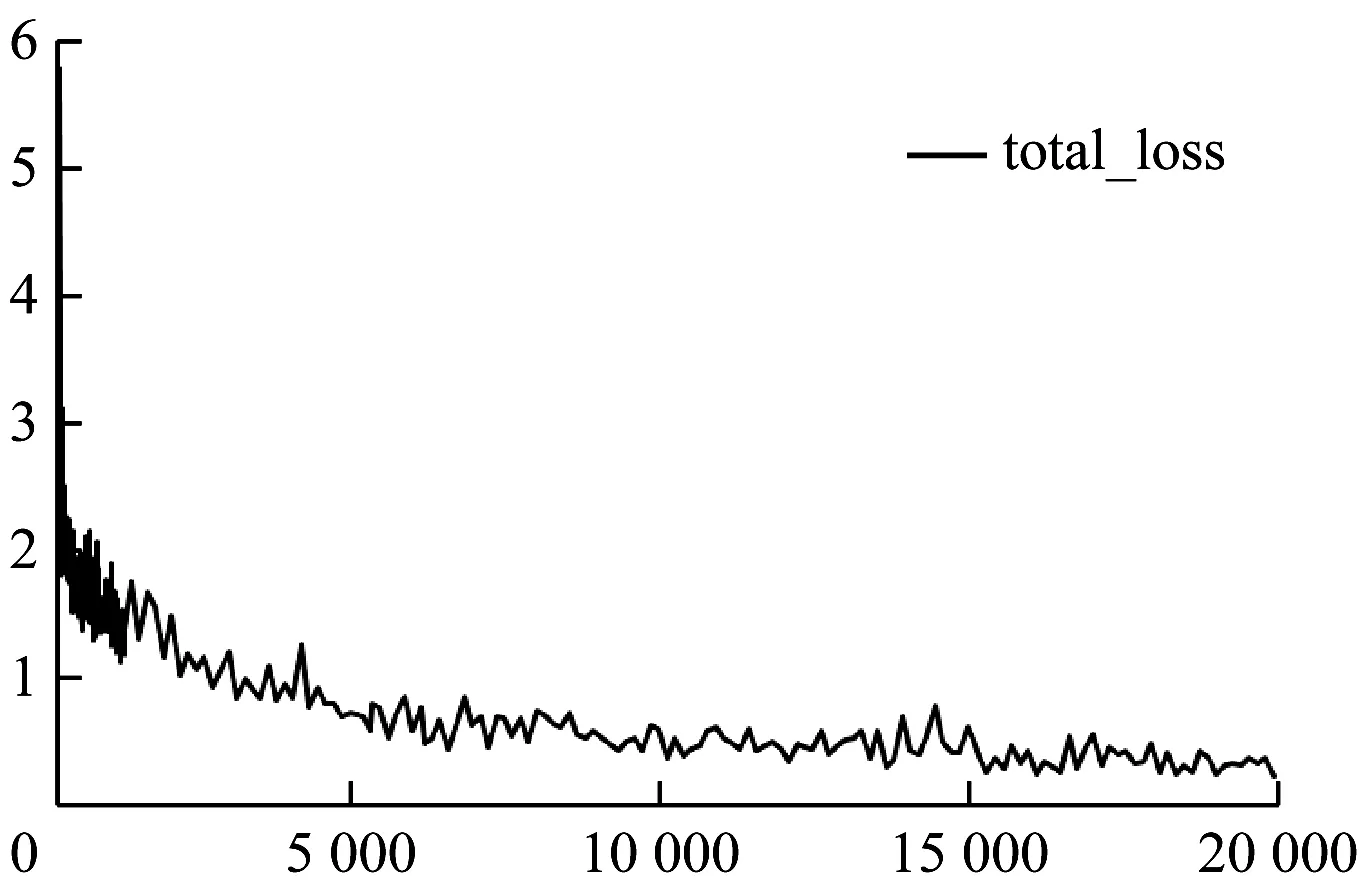
圖6 總體損失函數(shù)
2.3 實驗結果與對比
本實驗僅對飛機一類目標進行檢測,因此對模型檢測的結果使用平均準確率(mAP)與每秒處理圖像數(shù)量(FPS)作為評價標準,對基于VGG16網(wǎng)絡、ResNet50網(wǎng)絡的SSD算法和本文算法進行實驗對比,檢測結果如表2所示。

表2 三種檢測模型實驗結果對比
本文算法較基于VGG16的SSD算法對小目標檢測的準確率提升了6.7%。
不同算法對航拍視角下飛機檢測的結果如圖7所示。
由檢測結果圖可以看出,無論是在復雜背景還是密集區(qū)域中,本文算法都能較原始SSD算法檢測的效果更好。

(a) SSD算法
3 總結
本文針對傳統(tǒng)算法對航拍圖像中小目標檢測效果不理想的問題,通過引入深度殘差網(wǎng)絡加深網(wǎng)絡學習提升網(wǎng)絡訓練能力,并有效降低網(wǎng)絡冗余。同時本文針對基礎網(wǎng)絡中對底層邊緣信息利用不充分的問題,結合FPN網(wǎng)絡結構實現(xiàn)淺層特征圖與深層特征圖融合,充分利用多尺度卷積層的特征信息,增強了模型對小目標檢測的魯棒性。實驗結果表明,本文的航拍目標檢測算法可以愈加精確的檢測出圖像中的飛機目標,驗證了本算法的有效性。
猜你喜歡
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
