醫(yī)院檔案信息管理關鍵技術研究
2021-06-04 03:09:18李娣
微型電腦應用 2021年5期
李娣
(安陽市人民醫(yī)院, 河南 安陽 455000)
0 引言
隨著醫(yī)療行業(yè)的信息化發(fā)展,醫(yī)院檔案信息系統(tǒng)中儲存著越來越多的各類數(shù)據(jù)。采用數(shù)據(jù)挖掘對冗雜數(shù)據(jù)進行有效管理,并從中提取出有價值的信息,能夠幫助管理層進行決策,實現(xiàn)信息價值最大化[1]。醫(yī)院績效模型大多為profit×factor,即利潤與主觀系數(shù)之積[2]。單純用利潤作為績效考核的依據(jù)會打擊工作量大、工作難度高但利潤低科室醫(yī)務工作者的積極性,以工作量作為績效考核依據(jù)更具有客觀性與普適性[3]。在此基礎上,對具有利潤微薄、技術含量高、工作環(huán)境差等特殊情況的科室進行額外獎金補貼,能夠充分調(diào)動醫(yī)護工作者工作積極性。基于此,此次研究對醫(yī)院檔案信息進行數(shù)據(jù)挖掘,旨在從工作量和額外補貼兩方面入手,構建更合理的醫(yī)院績效管理模型。
1 醫(yī)院檔案信息數(shù)據(jù)挖掘績效管理
1.1 工作量績效線性回歸數(shù)據(jù)挖掘模型
此次研究中醫(yī)院檔案信息管理數(shù)據(jù)挖掘模型的設計考慮用工作量代替收入來構建績效模型,采用新模型得出的應付獎金總數(shù)需要與歷史水平相近。醫(yī)生工作量可以從HIS(Hospital Information System)系統(tǒng)的項目開單和病案管理系統(tǒng)中獲得。根據(jù)衛(wèi)健委最新規(guī)定,醫(yī)生績效評測不允許使用開單數(shù)量作為依據(jù)[4]。為合理評測醫(yī)生工作量,將績效分為醫(yī)療項目績效與治療患者數(shù)績效,前者占70%,后者占30%。RBRVS是綜合考慮醫(yī)療資源消耗與不同手術相對價值的醫(yī)生薪酬計算方式,這種計算方式在歐美地區(qū)得到了廣泛的應用[5]。此次研究采用RBRVS點數(shù)對工作量進行評估,利用不同執(zhí)行項目的RBRVS點數(shù)計算醫(yī)療項目績效。為便于績效模型的獎金控制,采用一元線性回歸建立不同科室的績效模型。以每個科室單一月度的項目點數(shù)作為自變量,將該科室該月度實發(fā)績效獎金的70%作為因變量,使用WEKA進行一元線性回歸方程擬合,獲得方程的斜率與截距。采取相同的方式對治療患者數(shù)績效進行線性回歸分析,合并兩項得到最終的績效模型方程。
為在既有績效管理系統(tǒng)中實現(xiàn)數(shù)據(jù)挖掘,使用WEKA智能分析環(huán)境進行內(nèi)部集成,通過在Java中導入WEKA,并進行接口調(diào)用。首先進行順序圖設計,在服務層獲取數(shù)據(jù)倉庫fact層中的項目點數(shù)、病案數(shù)據(jù)和歷史獎金表單,將上述表單轉化為List格式的數(shù)據(jù)庫訪問對象集合,如圖1所示。

圖1 線性回歸績效模型順序圖
業(yè)務邏輯層對服務層數(shù)據(jù)進行調(diào)用,并獲得項目點數(shù)、病案數(shù)據(jù)和歷史獎金三項數(shù)據(jù)庫訪問對象信息,然后利用服務層進行邏輯變化與組合對Arff文件進行生成。最后將Arff格式分發(fā)給線性回歸模型轉換類,將其轉換為線性回歸模型,并返回到業(yè)務邏輯層。然后對回歸模型進行類圖設計。類圖包含OrgSummaryDao、OrgSummaryService、IService等類包。
將員工編號設為維度表主鍵,其余事實信息保存為數(shù)值格式或日期格式。由于服務層獲取了Fact層的ResultSet,并將其改為了數(shù)據(jù)庫訪問對象,因此可以在服務層中提取出定義了QueryHelper的接口,用于對數(shù)據(jù)庫進行編輯操作。業(yè)務層需要的服務如表1所示。
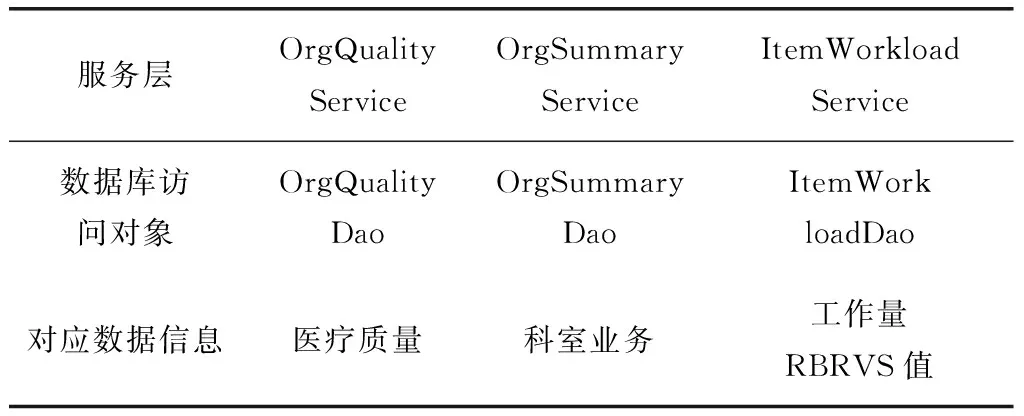
表1 業(yè)務邏輯層所需服務、對應的數(shù)據(jù)庫訪問對象和數(shù)據(jù)信息
其對應的數(shù)據(jù)信息分別為醫(yī)療質量、科室的業(yè)務和工作量RBRVS值。使用線性回歸模型轉換器進行Arff形式的模型構建,最后得出了slope與intercept屬性。將slope與intercept屬性匯總,得到每個科室的績效線性回歸方程。
1.2 科室扶持K-means聚類數(shù)據(jù)挖掘模型
對兩千多名中國醫(yī)生進行薪酬收入與工作量匹配度調(diào)查[6],結果如圖2所示。
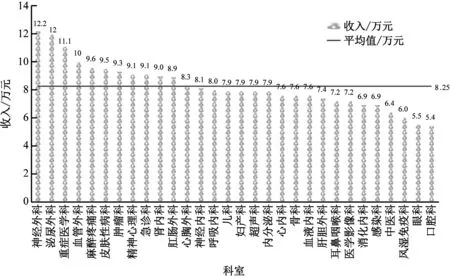
醫(yī)院各大科室中公認最累、壓力最大的部分科室中,急診科的薪資僅超過平均線0.85萬元,而兒科薪酬甚至沒有達到各科室的平均標準[7]。考慮到部分科室的工作環(huán)境較為苛刻,工作壓力較大,單純以工作量計算績效依然具有一定的片面性[8]。為深化醫(yī)院績效模式的改革,可以從學科價值、勞動強度、技術含量、精神壓力、職業(yè)傷害等多角度入手,建立科室扶持模型,對工作量績效模型進行進一步修正,以提升績效模型的合理性。為建立科室扶持模型,要先對不同
科室的工作內(nèi)容和工作環(huán)境等因素進行分析,將科室分為不同的扶持等級,并根據(jù)不同的扶持等級設定不同的獎金計算方法。
采用K-means算法對醫(yī)生與護士的科室進行主觀和客觀的評價,對不同科室與醫(yī)護類別進行分析。以護士評價為例,結合護士工作中各項因素,獲得包含10個參數(shù)的科室扶持屬性。其中噪音污染、職業(yè)風險、技術難度、生理勞累、職業(yè)傷害、職業(yè)暴露、硬件環(huán)境、心理勞累8項因素采取專家評分的方式進行評價。用藥收入、急診人數(shù)等數(shù)據(jù)信息從HIS系統(tǒng)中調(diào)取。將專家評分意見與所需的HIS系統(tǒng)數(shù)據(jù)進行合并,即可形成該科室護理人員的科室扶持屬性,對各科室的科室扶持屬性進行聚類分析,以獲得不同科室的扶持等級。基于WEKA的K-means聚類模型構建方法與一元回歸模型類似,由NurseClassifyBusiness生成Arff形式的WEKAK-means數(shù)據(jù),再將Arff文件傳遞給K-means模型轉換器,調(diào)用WEKA的API文件,使其轉換為K-means模型。
2 數(shù)據(jù)挖掘結果分析
2.1 工作量績效模型
選取某醫(yī)院2018年12月至2019年9月各科室各月項目績效、接待患者人數(shù)與對應實發(fā)績效獎金數(shù)據(jù),應用于WEKA一元線性回歸模型,分別建立各科室項目績效回歸方程與接待患者人數(shù)回歸方程,并合并為該科室的工作量績效模型回歸方程。某科室項目績效回歸分析圖,如圖3所示。

圖3 某科室項目點數(shù)績效回歸分析圖
從圖3中可以看出該科室的月項目點數(shù)與70%績效獎金大致呈線性分布,且各月數(shù)據(jù)散點均勻分布在擬合線兩側。由回歸擬合可以看出,該科室的項目績效方程為y=11.279x-13 670,其中y表示70%績效獎金/元,x表示當月該科室項目點數(shù)。R2為0.940 4,即該回歸分析擬合程度較高。
在如圖3所示項目點數(shù)回歸分析的基礎上繼續(xù)計算患者人數(shù)回歸方程,并推廣到醫(yī)院的12個主要科室,得到12條工作量績效一元線性回歸曲線,如圖4所示。

圖4 全院12個科室工作量績效一元線性回歸模型
當相關系數(shù)取值介于0.5到1時,認為該科室工作量績效模型合理。這12個科室中線性回歸模型相關系數(shù)最低的是骨科,其相關系數(shù)為0.51。相關系數(shù)最高的是神經(jīng)外科,其相關系數(shù)達到了0.84。因此可以認為這些科室的工作量績效一元線性回歸模型較為合理。
運用全院所有科室綜合數(shù)據(jù),將醫(yī)院作為一個整體進行工作量績效一元線性回歸分析。最終獲得的回歸方程為y=4.83x+490 703.88,其中y表示績效獎金/元,x表示當月全院工作量。全院工作量一元線性回歸方程相關系數(shù)為0.88,可以看出醫(yī)院整體工作量與績效大致呈線性關系,采用一元回歸分析進行工作量績效擬合適用性較高。
2.2 科室扶持模型
使用K-means模型對護士環(huán)境進行扶持等級聚類分析,使用同簇距離來對聚類結果進行評價。通過對seed值的調(diào)整,發(fā)現(xiàn)seed值取139時能夠得到最短的同簇距離,此時同簇距離為82.582。使用WEKA中seed取139的K-means聚類算法,通過對工作強度、技術難度、硬件條件、工作環(huán)境、工作壓力等指標進行聚類,得出聚類結果如表2所示。

表2 K-means聚類結果
表2顯示的類簇中包含的一系列科室具有相似的工作強度、技術難度、硬件條件、工作環(huán)境與工作壓力。神經(jīng)外科、心外科和新生兒監(jiān)護中心是各大醫(yī)院壓力最大的科室,其中神經(jīng)外科與新生兒監(jiān)護中心工作強度與工作壓力極大。呼吸內(nèi)科、放療科和感染性疾病科工作強度也較高,且這些科室的職業(yè)暴露和職業(yè)傷害情況也較為嚴重。類簇5中科室的工作強度弱于類簇1和類簇4,且其工作環(huán)境相較于類簇1和類簇4的科室更加優(yōu)越。在實際扶持等級績效獎金的制定中,應優(yōu)先考慮類簇1和類簇4所包含的科室,而類簇5的科室應給予相對更少的獎金。
3 總結
醫(yī)院規(guī)模的擴張加劇了醫(yī)院檔案信息管理的難度,運用計算機技術手段對醫(yī)院檔案信息進行現(xiàn)代化管理能夠大幅提升醫(yī)院檔案信息管理效率。為探究醫(yī)院檔案信息管理技術,此次研究以WEKA工具的調(diào)用為基礎,基于醫(yī)院歷史績效設計了新的績效模型。運用一元回歸分析構建了包含項目工作量點數(shù)和接待患者數(shù)的工作量績效模型,并運用K-means算法構建了科室扶持聚類模型。獲得的全院整體工作量績效回歸模型相關系數(shù)達到了0.88,各科室分別的相關系數(shù)分布在0.51至0.84間,證明了工作量模型擬合效果較好。科室扶持聚類模型依照不同的工作環(huán)境將科室分為6組,其中工作壓力較大的科室為一組,工作環(huán)境較優(yōu)越的科室為一組,面臨職業(yè)風險的科室為一組,分組情況與實際情況較為吻合。因此可以認為數(shù)據(jù)挖掘技術在醫(yī)院檔案信息管理中具有較強的實際應用價值。此次研究中工作量績效回歸模型的項目點數(shù)部分采用的評測方式是基于美國醫(yī)生工作情況設計的RBRVS點數(shù),與國內(nèi)情況可能存在一定程度上的差異。在今后的工作中,可以通過對RBRVS點數(shù)的修正以改進工作量績效回歸模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
兒童繪本(2018年10期)2018-07-04 16:39:12
電力與能源(2017年6期)2017-05-14 06:19:37
光學精密工程(2016年6期)2016-11-07 09:07:19
小朋友·快樂手工(2016年5期)2016-05-14 17:18:34
信息通信技術(2015年6期)2015-12-26 01:16:46
中國衛(wèi)生(2015年8期)2015-11-12 13:15:20
