有色噪聲分布式多通道語音增強算法研究
2021-06-07 06:19:40范忠奇王善斌
科技創新與應用 2021年14期
范忠奇,王善斌
(山東理工大學 計算機學院,山東 淄博255049)
多通道語音增強技術是近年來發展起來的一種多功能麥克風系統。多通道語音增強算法主要包括經典波束形成算法、多通道維納算法、多通道子空間算法、多通道最小失真算法以及多通道統計估計算法。這些多通道語音增強算法可以在增加麥克風數量的同時減少語音失真的背景噪聲,但不同情況其性能不同。多通道維納算法在平穩噪聲情況下獲得了良好的性能,但在非平穩噪聲情況下性能較差。多通道子空間算法比維納算法在非平穩噪聲情況具有更好的性能,多通道統計估計算法通過假設清潔語音信號和噪聲信號的傅里葉系數服從一定的概率分布,從而降低了背景噪聲。卡爾曼濾波被稱為一種有效的語音增強技術,不需要假設信號的平穩性,現有的用于語音增強的卡爾曼濾波算法都是通過提高卡爾曼濾波的AR參數的精度來實現的。本文提出了一種在有色噪聲環境下的時域分布式多通道語音增強濾波算法。該算法是基于卡爾曼濾波的時域多通道語音增強算法。仿真結果表明,該算法優于幾種傳統的多通道語音增強算法,實現了更高的降噪和低信號失真。
1 分布式多通道模型及其濾波算法
1.1 分布式多通道語音模型
分布式麥克風系統,它可以準確地及時去除M嘈雜的發言。分布式多通道麥克風模型可描述為:

其中M是通道的數量,yi(n)和vi(n)是噪聲并且是第n個樣本和通道i中的噪聲語音和背景噪聲,si(n)是真正的源信號,ci∈[0、1]是時間不變衰減因子。在特殊情況下,M=1和c1=1,分布式多通道模型成為一個眾所周知的單通道模型。我們的目標是從M嘈雜的信號觀測{yi(n)}Mi-1中估計語音信號s(n)。
1.2 分布式多通道語音卡爾曼濾波算法
本文提出了一種基于卡爾曼濾波算法的分布式多通道語音增強的時間域在有色噪聲的情況下,讓語音信號s(n)被建模為AR過程:

ai是AR語音模型參數,u(n)是方差的高斯白噪聲。用向量形式可表示為:

其中s(n)=[s(n-p+1),..s(n)]T,u=[0,..,0,u(n)]T,F是pxp矩陣定義為:

考慮到每個通道的語音信號都被有色噪聲所破壞。讓第i信道噪聲vi(n)被建模為AR過程:
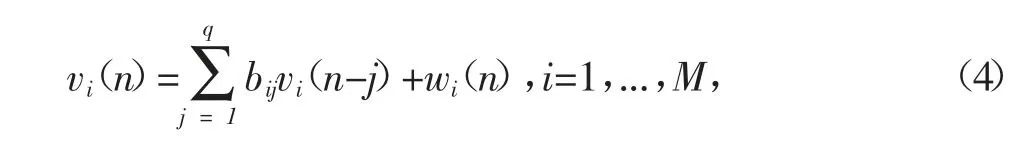
bij是AR噪聲模型參數和wi(n)均為零均值和方差為(n)的白高斯噪聲。式(4)可以寫成向量形式:

其中vi(n)=[vi(n-q+1),..,vi(n)]T,wi(n)=[0,.,0,wi(n)]T,Gi是qxq矩陣


其中:

e1=[0,...,0,1]是1×p向量,e2=[0,0,…1]是1×q向量。
使用以下遞歸方程可以獲得標準卡爾曼濾波估計:
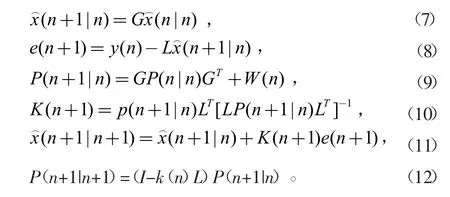
在上述卡爾曼濾波估計的基礎上,提出了一種分布式多通道語音增強的卡爾曼濾波算法,由L和N分別表示幀長度和幀數的算法,I(p+qM)×(p+qM)是(p+qM)×(p+qM)統一矩陣和e2=[0,0,1,0,.,0]是一個1×(p+qM)向量與qth元素是1和其他元素是0。通過該算法獲取增強后的語音信號s^(n)。
2 實驗仿真結果比較
2.1 實驗方法
在實驗環境中,房間是長10m,寬8m,高6m,聲源位于(2、4、1.6)處。10個全方位麥克風的均勻線性分布麥克風陣列,相鄰麥克風之間的間距約為30cm。第i麥克風位于(2.2,4+0.3x(i-1),1.6)。測試話語和噪聲信號來自NOIZEUS語料庫,所有信號的采樣都是8kHz。隨機從NOIZEUS數據庫中選擇20個不同的語音句子。這些句子連接在一起是一個清晰的信號。然后,將這些干凈的語音加到噪聲中,輸入信噪比分別為5dB。在這里使用雜噪音。在MATLAB環境下進行了仿真。
2.2 實驗結果與比較
實驗中采用分段信噪比(SSNR)的改善評估降噪效果。SSNR定義為:
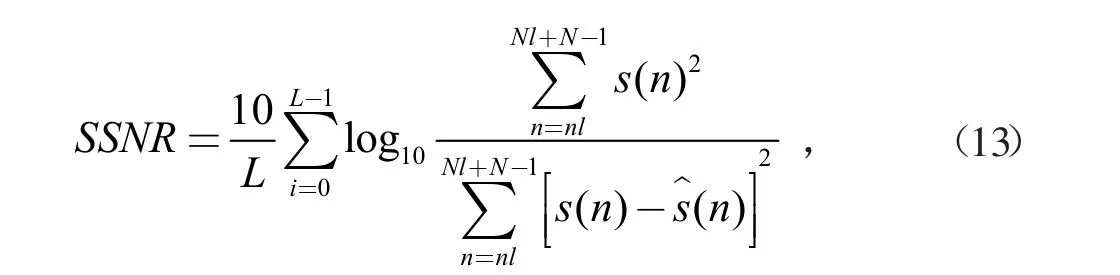
其中s(n)是原始語音信號,s^(n)是增強信號,N是原始語音信號的長度,Nl是l段語音長度。更大的SSNR值意味著更好的性能。
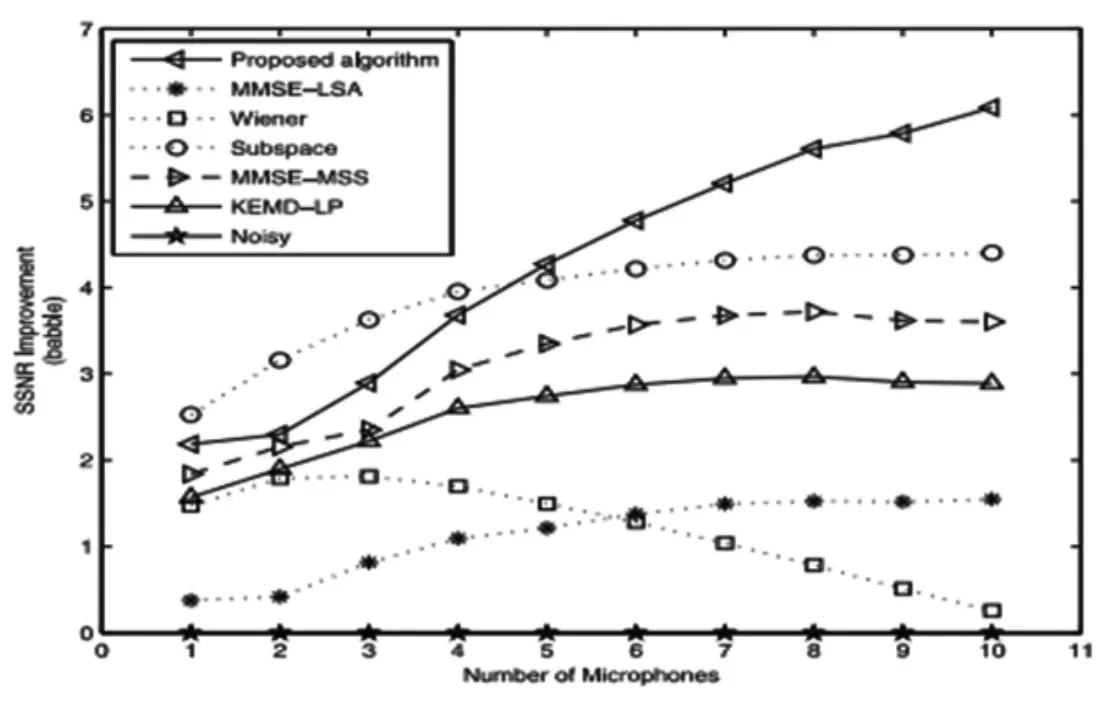
圖1 在信噪比為5dB的雜音噪聲中,6種算法與麥克風數量對SSNR的改善效果
在實驗中,本文將所提出的算法與其他5種算法進行了比較。當麥克風數M=1,2,…,10時,輸入信噪比為5dB。設p=6,q=6。圖1描述了在輸入信噪比是5db,以及在雜噪聲的情況下當MMSE-LSA、MMSE-MSS、Wiener、子空間和KEMD-LP作為麥克風的數目M從1到10時,該算法的SSNR變化。首先看到,該算法在SSNR改善優于其他5種算法,特別是在增加麥克風數量方面。這表明,在麥克風數量大的情況下,該算法具有最大的降噪能力。通過增加麥克風的數量,可以大大提高算法的性能。圖2顯示了當輸入信噪比值為5dB和M=4時,純凈信號、受有色噪聲污染的噪聲信號和6種增強信號的波形。結果表明,該算法產生的增強信號的波形比其他5種算法更接近于原語音信號。

圖2 在M=4、輸入信噪比為5dB的雜音噪聲情況下,6種算法處理后的純凈信號、噪聲信號和6種算法處理后的增強信號的波形
3 結論
本文提出了一種基于卡爾曼濾波的有色噪聲分布式多通道語音增強算法。仿真結果表明,與傳統的分布式多信道語音增強算法相比,該算法具有更高的降噪效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年11期)2018-08-04 03:25:42
北京航空航天大學學報(2017年9期)2017-12-18 07:12:25
光學精密工程(2016年6期)2016-11-07 09:07:19
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
電源技術(2016年9期)2016-02-27 09:05:39
