一種基于自動特征學習的隕石坑區(qū)域檢測算法
2021-06-09 01:15:26陸婷婷張堯閻巖楊利民楊衛(wèi)東
北京航空航天大學學報 2021年5期
陸婷婷,張堯,閻巖,楊利民,楊衛(wèi)東
(1.中國運載火箭技術研究院 研究發(fā)展部,北京100176;2.河南工業(yè)大學 糧食信息處理與控制教育部重點實驗室,鄭州450001)
隨著各國新一輪深空探測活動的興起,如何通過自主手段進行著陸器自主導航成為深空探測任務的一個重點研究問題。由于星體表面的隕石坑具有幾何形態(tài)規(guī)則(邊緣呈圓形)、特征顯著、數(shù)量巨大等特點,已經(jīng)成為深空探測飛行器進行視覺導航所首選的導航路標,大量學者對基于隕石坑視覺導航算法進行了深入研究[1-5]。
如何從導航圖像中提取隕石坑區(qū)域是實現(xiàn)基于隕石坑視覺導航算法的首要步驟,這里的隕石坑區(qū)域是指導航圖像中包含且僅包含一個隕石坑的矩形區(qū)域。根據(jù)檢測原理的不同,當前的隕石坑區(qū)域檢測算法可以分為2類:基于隕石坑形態(tài)特征的檢測算法和基于監(jiān)督學習的檢測算法。
基于隕石坑形態(tài)特征的檢測算法主要利用隕石坑固有的形態(tài)特性實現(xiàn)隕石坑區(qū)域檢測。這一類隕石坑區(qū)域檢測算法的典型代表包括:基于閾值分割和形態(tài)學處理的檢測算法[6]、基于形態(tài)學的檢測算法[7]、基于模板匹配的檢測算法[8-9]、基于閾值分割和霍夫變換的檢測算法[10-11]、基于圖像邊緣信息和紋理分析的檢測算法[12]、基于張量投票的檢測算法[13]、基于Canny邊緣檢測算子和圖像光照方向的檢測算法[14-18]、基于邊緣信息和SIFT特征提取的檢測算法[19-20]等。實際上,以上這些典型算法僅適用于圖像背景簡單并且圖像拍攝視角不大的情況,但實際的隕石坑圖像中通常包括大量的溝壑、山谷等干擾地質特征,并且拍攝視角多變,因此,以上這些檢測算法無法適用于復雜的隕石坑圖像。
基于監(jiān)督學習的檢測算法將隕石坑區(qū)域檢測問題轉化為一個典型的二分類問題。這一類算法的研究主要集中在如何構建一個隕石坑區(qū)域分類器,典型算法包括:基于Boost及Boost的各種變種算法的分類方法[21-25]、基于貝葉斯分類器和遺傳算法的分類方法[26]、基于Fisher分類器的分類方法[27]等。與基于隕石坑形態(tài)特征的檢測算法相比,基于監(jiān)督學習的檢測算法具有更高的精度,這是因為監(jiān)督學習方法在進行最終識別之前,已經(jīng)利用訓練數(shù)據(jù)集學習到了強泛化能力。另外,以上算法在描述隕石坑區(qū)域特征時,均使用人工特征,無法隨著圖像環(huán)境的變化而自適應改變,當圖像環(huán)境發(fā)生變化時,這類算法的精度可能會發(fā)生惡化。除了以上算法外,最近還有研究學者提出利用卷積神經(jīng)網(wǎng)絡(Convolutional Neural Network,CNN)進行隕石坑區(qū)域檢測[28-30],但其所設計算法僅能適應導航圖像僅包含圓形隕石坑的情況,無法適應于含有橢圓形隕石坑的導航圖像。
為了更加精確地實現(xiàn)深空探測導航圖像的隕石坑區(qū)域檢測,本文提出一種基于自動特征學習的隕石坑區(qū)域檢測算法,該算法屬于監(jiān)督學習方法的一種,其在充分利用圖像隕石坑形態(tài)特征基礎上,通過利用已有數(shù)據(jù)集自動學習隕石坑區(qū)域特征的方式實現(xiàn)隕石坑區(qū)域高效檢測,并通過大量的仿真實驗驗證了所提隕石坑區(qū)域檢測算法的有效性,可滿足空間探測飛行器自主導航的需求。
1 隕石坑區(qū)域檢測算法總體框架
基于自動特征學習的隕石坑區(qū)域檢測算法總體框架如圖1所示,主要包括隕石坑候選區(qū)域檢測和隕石坑候選區(qū)域分類2個基本流程。

圖1 隕石坑區(qū)域檢測算法總體框架Fig.1 Overall framework of crater region detection algorithm
首先,根據(jù)圖像隕石坑的形態(tài)特征,從輸入導航圖像中提取隕石坑候選區(qū)域。一般情況下,圖像隕石坑由一對明顯的亮暗區(qū)域構成,面向太陽光照一側是亮區(qū)域、背向太陽光照的一側是暗區(qū)域,如圖2所示。那么,圖像隕石坑中的每一對滿足某種位置關系的亮暗區(qū)域便可能對應一個隕石坑區(qū)域,將利用該思想檢測隕石坑候選區(qū)域。與傳統(tǒng)的基于滑窗的檢測算法相比,本文候選區(qū)域檢測算法誤檢率低,可以有效減小隕石坑候選區(qū)域分類算法的計算負擔、提高計算效率,同時,不需要指定候選區(qū)域的具體尺寸,自適應程度高。

圖2 圖像隕石坑的光照特征Fig.2 Optical characteristics of imaged crater
然后,對隕石坑候選區(qū)域進行分類,得到真實的隕石坑區(qū)域。該過程利用特征自動學習的方式提取所有隕石坑候選區(qū)域特征,并利用支持向量機(SVM)將這些候選區(qū)域分為2類:隕石坑區(qū)域和非隕石坑區(qū)域,從而實現(xiàn)隕石坑區(qū)域檢測。
下面分別對隕石坑候選區(qū)域提取和隕石坑候選區(qū)域分類2個核心環(huán)節(jié)的具體算法進行詳細設計和研究。
2 隕石坑候選區(qū)域提取
根據(jù)上述分析可知,圖像隕石坑具有明顯的亮暗區(qū)域,這些亮暗區(qū)域雖然不具有明確的幾何形態(tài),但卻屬于非常顯著和穩(wěn)定的區(qū)域特征,且具有射影不變性。針對以上特點,采用最大穩(wěn)定極值區(qū)域(Maximally Stable Extremal Regions,MSER)[31-32]算法實現(xiàn)圖像隕石坑候選區(qū)域提取。
通過分析原始MSER算法的基本特點可知,原始MSER算法僅能檢測到圖像隕石坑的穩(wěn)定區(qū)域,不能識別這些穩(wěn)定區(qū)域的亮暗關系,并且檢測到穩(wěn)定區(qū)域之間還具有明顯的嵌套包含關系,位于每組嵌套結構中部位置的穩(wěn)定區(qū)域通常是對隕石坑檢測意義不大的區(qū)域。因此,需要對原始MSER算法進行改進,得到適合于隕石坑亮暗區(qū)域檢測與匹配的穩(wěn)定區(qū)域檢測算法,稱這種改進后的MSER算法為Crater MSER。
基于Crater MSER算法的隕石坑候選區(qū)域檢測算法基本流程圖3所示。首先,從輸入的導航圖像中檢測最大穩(wěn)定極值區(qū)域;其次,從最大穩(wěn)定極值區(qū)域中提取出極大穩(wěn)定區(qū)域和極小穩(wěn)定區(qū)域,這些區(qū)域能夠有效代表隕石坑的亮暗特征;然后,分別對極大穩(wěn)定區(qū)域和極小穩(wěn)定區(qū)域進行面積濾波和形狀濾波,排除形狀特征異常的穩(wěn)定區(qū)域;最后,通過對濾波后的極大穩(wěn)定區(qū)域和極小穩(wěn)定區(qū)域的亮暗特征進行識別和匹配,實現(xiàn)隕石候選區(qū)域檢測。

圖3 Crater MSER算法的基本流程Fig.3 Basic flowchart of Crater MSER algorithm
2.1 最大穩(wěn)定極值區(qū)域的提取
為了獲取能夠表征隕石坑亮暗特征和形狀特征的穩(wěn)定區(qū)域,先利用原始的MSER算法[31-32]從輸入導航圖像中提取最大穩(wěn)定極值區(qū)域,其是輸入圖像中灰度變化最穩(wěn)定的區(qū)域,通常對應著圖像隕石坑的亮暗區(qū)域,這是由圖像隕石坑的灰度特性決定的。
根據(jù)MSER算法的基本思想[31-32]可知,基于原始MSER算法提取得到的最大穩(wěn)定極值區(qū)域之間存在著嵌套關系。圖4給出了一組最大穩(wěn)定極值區(qū)域提取的實例。對于給定的輸入圖像,基于原始MSER算法得到6個最大穩(wěn)定極值區(qū)域M1~M6,其中,M3~M6是亮區(qū)域,而M1和M2是暗區(qū)域,并且這些最大穩(wěn)定極值區(qū)域具有如下的嵌套關系:

式中:Mi∈Mj表示區(qū)域Mj完全包含Mi(i=1,2,3,4,5,6;j=1,2,3,4,5,6)。圖4中還繪制出了每個穩(wěn)定區(qū)域所對應的同矩橢圓,同一穩(wěn)定區(qū)域及其對應的同矩橢圓以相同的顏色顯示。

圖4 Crater MSER算法基本流程的真實實例Fig.4 Instances of basic procedure of Crater MSER algorithm
2.2 極大穩(wěn)定區(qū)域和極小穩(wěn)定區(qū)域提取
從所有的最大穩(wěn)定極值區(qū)域中提取出極大穩(wěn)定區(qū)域和極小穩(wěn)定區(qū)域,其中,極大穩(wěn)定區(qū)域是指不被任何其他穩(wěn)定區(qū)域所包含的穩(wěn)定區(qū)域,而極小穩(wěn)定區(qū)域是指不包含任何其他穩(wěn)定區(qū)域的穩(wěn)定區(qū)域。極大穩(wěn)定區(qū)域和極小穩(wěn)定區(qū)域之間存在著一一對應的關系,任何一個極小穩(wěn)定區(qū)域都被其所對應的極大穩(wěn)定區(qū)域所包含,并且這組相對應的極大和極小穩(wěn)定區(qū)域具有相同的亮暗信息。極大穩(wěn)定區(qū)域表征圖像隕石坑的形狀,其亮暗信息由所對應的極小穩(wěn)定區(qū)域決定,一對亮暗極大穩(wěn)定區(qū)域對應著一個隕石坑候選區(qū)域。
給定一組最大穩(wěn)定極值區(qū)域M={Mi}(1≤i≤NM,NM為M中的穩(wěn)定區(qū)域個數(shù)),可以利用式(2)所示的判別準則提取極大穩(wěn)定區(qū)域和極小穩(wěn)定區(qū)域:

式中:Imi(Mi)=1表示Mi為極小穩(wěn)定區(qū)域,Imi(Mi)=-1表示Mi為極大穩(wěn)定區(qū)域,而Imi(Mi)=0表示Mi既非極小穩(wěn)定區(qū)域也非極大穩(wěn)定區(qū)域。仍以圖4所示圖像為例,根據(jù)式(1)所示準則可以從輸入導航圖像的最大穩(wěn)定極值區(qū)域M1~M6中提取出所有的極大穩(wěn)定區(qū)域和極小穩(wěn)定區(qū)域,其中,M1和M3是極小穩(wěn)定區(qū)域,而M2和M6是極大穩(wěn)定區(qū)域,并且極大穩(wěn)定區(qū)域M2和M6分別包含極小穩(wěn)定區(qū)域M1和M3。
2.3 面積濾波及形狀濾波
2.2節(jié)所提取的極大穩(wěn)定區(qū)域和極小穩(wěn)定區(qū)域具有不同的形狀和尺寸,一些比較小的穩(wěn)定區(qū)域屬于噪聲區(qū)域,而一些具有極端形狀(如極度扁長)的區(qū)域也屬于非隕石坑區(qū)域,因此,應該對所有的極大和極小穩(wěn)定區(qū)域進行形狀濾波和面積濾波,選擇TA作為面積濾波的閾值、TS為形狀濾波閾值,面積濾波器濾除面積小于TA的所有穩(wěn)定區(qū)域,形狀濾波濾除所有滿足式(3)的穩(wěn)定區(qū)域:

式中:Ma和Mi分別為與該穩(wěn)定區(qū)域具有相同標準化二階中心矩的橢圓的長短軸,數(shù)值可以按照式(4)計算:
其中:σ11、σ12、σ22為該穩(wěn)定區(qū)域的標準化二階中心矩的3個組成元素,由式(5)計算得到:

式中:(xi,yi)為當前穩(wěn)定區(qū)域的第i個像素點;N為該穩(wěn)定區(qū)域包含像素點的個數(shù);[μxμy]T為該穩(wěn)定區(qū)域中心點坐標,由式(6)計算得到:

2.4 亮暗區(qū)域識別
進行面積濾波和形狀濾波之后,識別所有極小穩(wěn)定區(qū)域的亮暗信息,雖然基于閾值分割的技術常被用于解決該問題,但所設定的閾值依賴于圖像的質量和光照強度,魯棒性較差,將基于K均值聚類算法識別極小穩(wěn)定區(qū)域的亮暗信息,以所有極小穩(wěn)定區(qū)域的平均灰度值作為聚類的性能指標,將所有極小穩(wěn)定區(qū)域聚為2類(即K取2),并且具有較大平均灰度值那一類所對應的極小穩(wěn)定區(qū)域為亮區(qū)域,而具有較小灰度值的那一類所對應的極小穩(wěn)定區(qū)域為暗區(qū)域。K均值聚類是一種典型的非監(jiān)督分類學習算法,該算法所需要的輸入是K的取值及待分類的數(shù)據(jù)集。K均值聚類算法通過迭代進行簇分配和聚類中心移動2個步驟實現(xiàn)聚類,其中,簇分配的任務是依據(jù)所有樣本點距離當前簇中心的距離對所有樣本點進行分類,簇中心移動的任務是計算當前更新的簇的中心。對于極小穩(wěn)定區(qū)域平均灰度值的K均值聚類問題,其數(shù)據(jù)集具有圖5所示的形式,可以看出,所有的極小穩(wěn)定區(qū)域的灰度值可以被較為清晰地分為2類。

圖5 極小穩(wěn)定區(qū)域平均灰度值的一維K均值聚類示意圖Fig.5 Schematic diagram of one-dimensional K-means cluster of average gray values of minimal MSER regions
2.5 亮暗區(qū)域匹配
得到導航圖像中所有極小穩(wěn)定區(qū)域的亮暗信息后,便能夠識別出這些極小穩(wěn)定區(qū)域所對應的極大穩(wěn)定區(qū)域的亮暗信息,通過匹配已知亮暗信息的極大穩(wěn)定區(qū)域便可以實現(xiàn)隕石坑候選區(qū)域檢測,下面分析具體的匹配原理。
給定一對極大穩(wěn)定區(qū)域B和S,B為亮區(qū)域,S為暗區(qū)域,計算相互之間的投票分,以區(qū)域B對區(qū)域S的投票分為例。首先,計算區(qū)域B對區(qū)域S中某一個像素P的投票分:
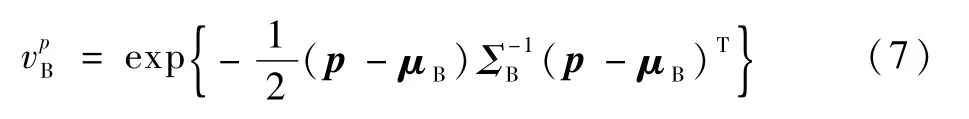
式中:p=[pxpy]T為像素P的位置坐標;μB=[μxμy]T可 以 利 用 式(6)計 算 得 到;ΣB=(σmn)2×2(m,n=1,2)為由式(5)計算得到的區(qū)域B的標準化二階中心矩。那么,區(qū)域B對區(qū)域S的投票分可由式(8)計算得到:

式中:NS為區(qū)域S中所有像素的個數(shù);Pk為區(qū)域S中的第k個像素;為區(qū)域B對像素Pk的投票分,可由式(7)計算得到。從而,如果區(qū)域B和區(qū)域S滿足以下3條準則,將會被合并。
準則1區(qū)域B和區(qū)域S之間的距離小于一個與區(qū)域B和區(qū)域S面積成比例的閾值,該閾值可以設置為2(AB+AS)/π,AB和AS分別為區(qū)域B和區(qū)域S的面積。
準則2太陽光光照方向lsun與區(qū)域S重心指向區(qū)域B重心的方向向量lSB之間的夾角為鈍角。
準則3區(qū)域B對區(qū)域S的投票分應該為區(qū)域B對所有滿足準則1和準則2的暗區(qū)域的投票分中的最大值,同樣地,區(qū)域S對區(qū)域B的投票分應該為區(qū)域S對所有滿足準則1和準則2的亮區(qū)域的投票分中的最大值。
基于以上匹配流程,可以獲得一系列匹配成功的極大穩(wěn)定區(qū)域對,沒有匹配成功的穩(wěn)定區(qū)域為非隕石坑區(qū)域,每對匹配成功的極大穩(wěn)定區(qū)域所對應的外接矩形框構成一個隕石坑候選區(qū)域。從圖4給出的實例可以看到,M2和M6為一對匹配成功的極大穩(wěn)定區(qū)域,包含M2和M6的圖像矩形區(qū)域即為要提取的隕石坑候選區(qū)域。
3 基于自動特征學習的隕石坑候選區(qū)域分類
3.1 隕石坑候選區(qū)域分類分析
利用隕石坑候選區(qū)域提取算法能夠從導航圖像中檢測出一系列隕石坑候選區(qū)域,其中有一部分候選區(qū)域是真正的隕石坑區(qū)域,而另外一部分候選區(qū)域是由于星體表面的溝壑、山丘等干擾地質特征造成的誤檢測隕石坑區(qū)域(非隕石坑區(qū)域)。因此,為了得到真正的隕石坑區(qū)域,需要將隕石坑候選區(qū)域分為2類:隕石坑區(qū)域和非隕石坑區(qū)域。
為了使用分類器對輸入圖像進行分類,必須從輸入圖像中提取出能夠代表該圖像的特征(紋理和邊緣等),從而簡化分類器的輸入,使其在數(shù)學上容易處理,同時提高分類精度。實際上,圖像的特征可以通過對它的每一個像素點及其鄰域內(nèi)的像素點與一個矩陣(稱為卷積核)進行卷積運算得到。當卷積核大小不同或者卷積核元素取值不同時,可以得到不同的圖像特征,通常情況下,這里的卷積運算是指以卷積核中的元素為權重、對其所覆蓋的圖像區(qū)域進行加權求和,以該加權和作為該卷積核所覆蓋區(qū)域中心像素點的特征取值。假設卷積核KE的尺寸為w×h,原始圖像為P,那么,輸出的新圖像P'在像素點(i,j)處的灰度值為

當卷積核KE取值不同時,輸出的特征圖像之間差別很大。這些手動設置的卷積核為相關圖像識別領域專家根據(jù)經(jīng)驗選取,所提取出的特征稱為人工特征,由于手動設置卷積核一經(jīng)選取就不再改變,人工特征無法隨著輸入圖像類型不同而自適應改變,對于情況多變的自然場景圖像適應性較差。
CNN是一個經(jīng)典的深度學習模型,其在圖像分類[33]、姿 態(tài) 估 計[34]、文 本 檢 測 識 別[35]等 諸 多領域取得了令人矚目的成績。CNN的一個重要特性是能夠利用給定的訓練數(shù)據(jù)集對物體特征進行自動學習,從而得到對物體特征最有效的表示。對于一般的分類問題而言[36-37],基于CNN自動學習得到的特征通常能夠獲得比傳統(tǒng)的人工特征(Haar-like特 征[38]、HOG特 征[39]、LBP特 征[40]等)更高的分類精度,并且CNN特征非常適合多變的自然場景圖像,能夠根據(jù)具體的應用場景自適應調(diào)整。
為此,將利用CNN實現(xiàn)隕石坑候選區(qū)域的特征提取。另外,由于線性SVM是一個經(jīng)典的分類器模型,并且大量的實際應用問題(步態(tài)檢測[41]、人臉檢測[42]、油罐檢測[43]等)已經(jīng)證明,相比于Logistic回歸和Softmax回歸,SVM具有更高的分類精度,將結合SVM分類器和CNN對隕石坑候選區(qū)域進行分類,最終實現(xiàn)隕石坑區(qū)域檢測。
3.2 隕石坑候選區(qū)域自動特征學習
所設計的用于隕石坑候選區(qū)域特征提取的CNN(簡稱為CraterCNN)結構如圖6所示,其包括5個卷積層(C1、C2、C3、C4、C5)和1個尺寸為1 000的全連接層FC6,輸出層是一個Softmax分類器,且輸出維度為2,輸入層是大小為227×227的RGB圖像。

圖6 CraterCNN網(wǎng)絡結構及基于SVM的隕石坑候選區(qū)域分類Fig.6 Structure of CraterCNN network and crater candidate region classification based on SVM
在對CraterCNN進行訓練時,采用遷移學習的思路實現(xiàn),即先利用預訓練的AlexNet模型[44]對CraterCNN的卷積層C1~C5的權值參數(shù)進行初始化設置,并通過隨機初始化方式設置CraterCNN的FC6的參數(shù)取值,再利用隕石坑數(shù)據(jù)集對CraterCNN網(wǎng)絡進行訓練微調(diào)。這種做法可以有效地利用AlexNet在ImageNet數(shù)據(jù)集上學習到的知識對隕石坑候選區(qū)域進行分類,防止了由于訓練集過小而可能造成過擬合的問題,同時也充分利用了隕石坑數(shù)據(jù)集自身的特征。
實際上,CraterCNN的第1個全連接層FC6輸出的就是網(wǎng)絡從輸入圖像中提取出的1 000維特征。
3.3 隕石坑候選區(qū)域分類
利用CraterCNN對隕石坑候選區(qū)域進行特征提取,得到1 000維特征向量后,便可以將這1 000維特征送入線性SVM分類器,從而實現(xiàn)對輸入隕石坑候選區(qū)域的分類。線性SVM的基本思想是:基于訓練數(shù)據(jù)集在樣本空間中找到一個能將不同類別樣本分割開來的超平面,并且這個劃分超平面具有最大的間隔。假設給定的隕石坑候選區(qū)域訓練數(shù)據(jù)集為D={(xtrain_1,ytrain_1),…,(xtrain_N,ytrain_N)},ytrain_i∈{0,1}(i=1,2,…,N),xtrain_i為第i個候選區(qū)域的d維特征向量,ytrain_i為xtrain_i的類別標簽,0表示非隕石坑區(qū)域,而1表示隕石坑區(qū)域。那么,劃分超平面可表示為gTx+b=1,其中,d維向量g為該劃分超平面的法向量,b為該劃分超平面的位移,b表示了劃分超平面與原點的距離,并且定義訓練數(shù)據(jù)集中距離超平面最近的2個非同類樣本之間的距離為間隔。那么,具有最大間隔的劃分超平面應該是如下優(yōu)化問題的最優(yōu)解:

實際上,以上的劃分超平面要求訓練數(shù)據(jù)集中所有樣本都能夠被正確分類,但這樣容易導致SVM分類器出現(xiàn)過擬合的情況,因此,一種魯棒性較強的SVM分類器應該一定程度上允許其在訓練數(shù)據(jù)集上出現(xiàn)一些錯分,從而可以通過引入非負松弛變量ξi的方式來實現(xiàn)這個目的。此時,允許在訓練數(shù)據(jù)集上出現(xiàn)一定程度錯分的SVM通常被稱為軟間隔SVM,其是如下優(yōu)化問題的解:
式中:常數(shù)pe衡量了容許SVM分類器在訓練數(shù)據(jù)集上出現(xiàn)錯分的程度,pe取值越大,表示要求SVM在訓練數(shù)據(jù)集上出現(xiàn)錯分的程度越低,而非負松弛變量ξi表示了樣本xtrain_i不滿足正確分類約束的程度。采用式(11)所示的軟間隔SVM實現(xiàn)對隕石坑候選區(qū)域的最終分類。
4 仿真實驗
通過仿真實驗手段對所提出的基于自動特征學習的隕石坑區(qū)域檢測算法的有效性和精度進行驗證,整個實驗過程在具有Windows10操作系統(tǒng)的臺式計算機上完成。首先,利用火星表面和月球表面真實隕石坑圖像對所提出的隕石坑候選區(qū)域提取算法進行驗證;其次,利用通用隕石坑數(shù)據(jù)庫對所提出的基于自動特征學習的隕石坑候選區(qū)域分類算法進行驗證;最后,分別利用仿真隕石坑圖像和真實隕石坑圖像對所提出的隕石坑區(qū)域檢測算法進行驗證。
4.1 隕石坑候選區(qū)域提取仿真實驗
分別利用火星表面和月球表面真實圖像測試所提出的隕石坑候選區(qū)域提取算法的性能,具體的實驗結果如圖7所示。
圖7中,前3行為火星表面圖像的隕石坑候選區(qū)域提取實驗結果,后2行為月球表面圖像的隕石坑候選區(qū)域提取實驗結果,第1列為輸入圖像,第2列為識別出的極大穩(wěn)定區(qū)域(紅色區(qū)域為暗極大穩(wěn)定區(qū)域,綠色區(qū)域為亮極大穩(wěn)定區(qū)域),第3列為隕石坑候選區(qū)域提取結果,其中,紅色矩形框為檢測到的隕石坑候選區(qū)域。可知,所提出的隕石坑候選區(qū)域提取算法可以較為精確地提取出輸入圖像中的隕石坑區(qū)域,但由于溝壑、山丘等地質特征的影響,也存在誤檢測的情況。例如,圖7中的前3行所對應的輸入隕石坑圖像中都存在溝壑,因此,相應的候選區(qū)域檢測結果中都出現(xiàn)了一個誤檢測區(qū)域,這個誤檢測區(qū)域需要利用后續(xù)的隕石坑候選區(qū)域分類算法進行篩選。

圖7 隕石坑候選區(qū)域提取實驗結果Fig.7 Experimental results of crater candidate region extraction
4.2 隕石坑候選區(qū)域分類仿真實驗
4.2.1 數(shù)據(jù)集選擇和性能指標設計
由美國麻省大學波士頓分校KDLab實驗室構造的隕石坑數(shù)據(jù)集h0905_0000[45]是當前隕石坑區(qū)域檢測研究最通用的訓練與測試數(shù)據(jù)集,許多檢測算法都在該數(shù)據(jù)集上進行了測試,因此,本節(jié)實驗將使用該數(shù)據(jù)集測試所提出的基于自動特征學習的隕石坑區(qū)域分類算法。
h0905_0000數(shù)據(jù)集是根據(jù)火星快車號攜帶的高分辨率立體相機拍攝到的火星Xanthe Terra區(qū)域全景圖h0905_0000制作而成。h0905_0000數(shù)據(jù)集包括3組數(shù)據(jù),如表1所示。這3組數(shù)據(jù)分別由全景圖h0905_0000的西部區(qū)域、中部區(qū)域、東部區(qū)域構建而成,每組數(shù)據(jù)都由正樣本和負樣本2類構成,正樣本為隕石坑區(qū)域(標簽為1),負樣本為非隕石坑區(qū)域(標簽為0),整個數(shù)據(jù)集共包括2 022個正樣本和2 888個負樣本。

表1 h0905_0000隕石坑數(shù)據(jù)集分組Table 1 Groups of h0905_0000 crater dataset
由于全景圖h0905_0000所對應的火星表面區(qū)域的固有地質特征,中部區(qū)域地形較西部區(qū)域和東部區(qū)域復雜,中部區(qū)域所對應的數(shù)據(jù)集的識別難度最大。另外,數(shù)據(jù)集中的樣本尺寸范圍從5×5變化到100×100,但均為單通道的灰度圖像,在利用CraterCNN對這些數(shù)據(jù)集進行分類識別時,需要將其統(tǒng)一轉換成尺寸為227×227×3的RGB圖像。圖8給出了該數(shù)據(jù)集中的一些正負樣本示例。

圖8 h0905_0000隕石坑數(shù)據(jù)集中的正負樣本示例Fig.8 Positive and negative examples in h0905_0000 crater dataset
為了比較不同算法的精度,利用查準率P、查全率R和F1來評估算法的泛化能力,它們是分類問題中最常用的性能度量,其具體定義和計算方法與文獻[1,46]一致。
4.2.2 基于交叉校驗數(shù)據(jù)集的SVM分類器懲罰因子選擇
根據(jù)3.3節(jié)所述,在對CraterCNN提取到的特征進行分類時,使用了具有懲罰因子pe的軟間隔SVM分類器,pe表征了SVM分類器對訓練數(shù)據(jù)集出錯的容忍程度,對最終的分類器性能影響很大,本組實驗將利用交叉校驗數(shù)據(jù)集對SVM分類器的懲罰因子pe進行選擇。
首先,在整個h0905_0000數(shù)據(jù)集的東部區(qū)域、中部區(qū)域和西部區(qū)域分別抽取20%的樣本,其中正負樣本比例相等(均為10%),將這些來自3個區(qū)域的樣本構成的數(shù)據(jù)集作為交叉校驗數(shù)據(jù)集。其次,利用文獻[21]所介紹的Haar-like特征提取算子提取這些樣本的Haar-like特征,將這些人工特征作為SVM分類器的輸入對相應的樣本進行分類。這里之所以利用Haar-like特征進行軟間隔SVM分類器的懲罰因子pe的選擇,是因為已有的隕石坑檢測算法[21]已經(jīng)證實,Haar-like特征是目前比較適合應用于隕石坑檢測問題的特征,并且這種特征提取簡單、實現(xiàn)方便。
在對某一個懲罰因子進行測試時,將整個交叉校驗數(shù)據(jù)集均等地分為5份,每一次分別選擇其中的4份作為訓練數(shù)據(jù)集、另外1份作為測試數(shù)據(jù)集,如此循環(huán)進行5次操作,可以得到當前的懲罰因子對應的5個F1度量值,以這5個F1度量值的均值衡量相應懲罰因子所對應的SVM分類器的分類精度,實驗結果如表2所示。可以看到,當懲罰因子pe取值為0.000 1時,SVM分類器在交叉校驗數(shù)據(jù)集上的F1取值最高,因此,對于隕石坑候選區(qū)域分類問題而言,SVM分類器的懲罰因子應該設置為0.000 1。

表2 基于交叉校驗數(shù)據(jù)集的軟間隔線性SVM分類器懲罰因子選擇實驗結果Table 2 Experimental results for choosing the penalty factor of linear SVM classifier with soft interval based on cross check dataset
4.2.3 隕石坑候選區(qū)域分類算法測試
本組實驗利用h0905_0000隕石坑數(shù)據(jù)集測試所提出的基于自動特征學習的隕石坑區(qū)域分類算法(下文將該算法簡稱為CraterCNN+SVM)。由于h0905_0000隕石坑數(shù)據(jù)集的3個子集所包含的樣本個數(shù)都較少(見表1),為了充分高效利用有限數(shù)據(jù)集驗證算法性能,本組實驗將采用與選取SVM分類器的懲罰因子實驗相同的策略,對于h0905_0000隕石坑數(shù)據(jù)集的每一個子集,將其均等地分為10份(即10-Fold),如圖9所示,依次以其中的9份作為訓練集對分類器進行訓練,并以另外1份作為測試集計算分類器的查準率P、查全率R和F1,如此循環(huán),那么h0905_0000數(shù)據(jù)集的每一個子集都將得到10組查準率P、查全率R和F1,以這些度量指標的均值作為分類器在該組數(shù)據(jù)集上的最終度量指標,這樣做的目的是為了削弱不同分組情況引起的訓練數(shù)據(jù)集和測試數(shù)據(jù)集難度不同而對分類結果造成的影響。

圖9 10-Fold訓練測試數(shù)據(jù)集示意圖Fig.9 Schematic diagram of 10-Fold training and testing dataset
對CraterCNN+SVM算法進行驗證。利用文獻[21]方法作為對比方法,該方法是目前在h0905_0000隕石坑數(shù)據(jù)集上獲得最高檢測精度的方法,其利用Haar-like人工特征和AdaBoost分類器實現(xiàn)對隕石坑候選區(qū)域的分類(下文將該對比方法簡稱為Haar-like+AdaBoost)。為了比較SVM分類器的性能,實驗還將利用Haar-like特征和SVM分類器組合算法實現(xiàn)對隕石坑候選區(qū)域的分類(下文將該對比方法簡稱為Haar-like+SVM),同時,還將利用所提出的CraterCNN提取隕石坑候選區(qū)域特征,并分別以Softmax分類器和AdaBoost分類器對CraterCNN網(wǎng)絡提取出的特征進行分類,將這2種對比方法簡稱為CraterCNN+Softmax和CraterCNN+AdaBoost。
所提出的CraterCNN+SVM和4種對比方法(Haar-like+AdaBoost、Haar-like+SVM、CraterCNN+Softmax、CraterCNN+AdaBoost)在h0905_0000數(shù)據(jù)集3個子集所對應的10-Fold數(shù)據(jù)集上的查全率R、查準率P和F1的取值如表3所示。可以看到,在3個子集上,CraterCNN+SVM均獲得了最高的F1度量取值,同時,除了中部區(qū)域的查全率P外,CraterCNN+SVM均獲得了最高的查全率P和最高的查準率R,由于中部區(qū)域的隕石坑識別難度最大,特征的非線性程度高,線性SVM的查全率較AdaBoost低一些。通過觀察CraterCNN+Softmax、CraterCNN+SVM、CraterCNN+AdaBoost在3個10-Fold數(shù)據(jù)集上的F1取值可以看到,CraterCNN+SVM的F1取值最高。同時,對于Haar-like特征而言,SVM分類器的精度要低于AdaBoost分類器的精度,這是因為隕石坑區(qū)域的Haar-like特征的線性可分性較差,所以,線性SVM分類器的性能要稍差于非線性的AdaBoost分類器。另外,由4.2.1節(jié)所述,中部區(qū)域的隕石坑識別難度最高,因此,各算法在3個區(qū)域的F1度量取值最低。

表3 Crater CNN+SVM與其他隕石坑候選區(qū)域分類算法對比實驗結果Table 3 Contrast experimental results of Crater CNN+SVM algorithm and other crater candidate regions classification algorithms
表4分別給出了CraterCNN特征和Haar-like特征在3組10-Fold測試集上的平均提取時間,以及CraterCNN+SVM和CraterCNN+AdaBoost在這3組數(shù)據(jù)集上的平均訓練時間和平均測試時間。可以看到,在3個數(shù)據(jù)集上,CraterCNN特征提取時間要明顯低于Haar-like特征,同時,Crater-CNN+SVM的平均訓練時間和平均測試時間都要低于CraterCNN+AdaBoost。

表4 不同特征提取及不同分類算法的訓練和測試在10-Fold數(shù)據(jù)集上的平均時間Table 4 Mean time of different feature extraction algor ithms and different classification algorithms on 10-Fold training dataset and testing dataset
為了更加形象化地對比CraterCNN提取的特征與Haar-like特征,利用高維特征可視化算法t-SNE分別對h0905_0000數(shù)據(jù)集的3個子集的所有樣本的CraterCNN特征和Haar-like特征進行顯示,結果如圖10所示。其中,圖10(a)~(c)分別是利用CraterCNN對3個數(shù)據(jù)集的所有樣本提取出的特征的二維可視化結果,而圖10(d)~(f)分別為這3個數(shù)據(jù)集中的所有樣本的Haar-like特征的二維可視化結果。可知,CraterCNN提取出的特征在3個數(shù)據(jù)集上的可分性都要優(yōu)于Haarlike特征,從而再次證明基于CNN的自動學習特征性能遠優(yōu)于人工特征。

圖10 基于t-SNE算法的CraterCNN特征和Haar-like特征可視化結果Fig.10 Visualized results of CraterCNN features and Haar-like features based on t-SNE algorithm
4.3 基于仿真隕石坑圖像的隕石坑區(qū)域檢測實驗
4.3.1 仿真隕石坑圖像數(shù)據(jù)集
為了有效驗證隕石坑區(qū)域檢測算法,采用仿真方法構建隕石坑圖像數(shù)據(jù)集。首先,利用基于三維解析模型的隕石坑仿真圖像生成算法[47]產(chǎn)生10幅隕石坑仿真圖像,并分別對每一幅圖像進行2次隨機射影變換,得到30幅隕石坑仿真圖像,這些仿真圖像充分模擬了著陸器在著陸過程中可能出現(xiàn)的各種位姿情況。其次,從這些仿真圖像中手動選取164個正樣本和164個負樣本。然后,分別對這些樣本進行水平和垂直方向的翻轉,得到656個正樣本和656個負樣本。最后,為了使這些隕石坑樣本更加接近真實圖像,分別對其進行高斯模糊和運動模糊處理,并添加高斯白噪聲,最終得到1 312個正樣本和1 312個負樣本作為仿真隕石坑圖像數(shù)據(jù)集。圖11給出了該數(shù)據(jù)集中的一些典型樣本示例。

圖11 隕石坑仿真圖像構成的隕石坑區(qū)域數(shù)據(jù)集正負樣本示例Fig.11 Positive and negative examples in crater region dataset composed of simulated crater images
4.3.2 隕石坑區(qū)域檢測算法測試
實驗利用基于仿真隕石坑訓練數(shù)據(jù)集得到的CNNCrater+SVM對隕石坑仿真圖像進行隕石坑區(qū)域檢測,并以4.3.1節(jié)實驗中提到的Haar-like+SVM算法作為對比方法,檢測結果如圖12所示。圖12的第1列給出了基于三維解析模型的隕石坑仿真圖像生成算法產(chǎn)生的4幅仿真圖像,利用所提出的隕石坑候選區(qū)域提取算法從輸入的隕石坑圖像中提取疑似隕石坑區(qū)域,算法得到的隕石坑亮暗區(qū)域和候選區(qū)域結果如圖12第2列和第3列所示,可以看到,所提出的隕石坑候選區(qū)域提取算法能夠較為精確地從輸入的隕石坑圖像中提取出隕石坑候選區(qū)域。圖12第4列和第5列分別為利用CraterCNN+SVM算法和Haar-like+SVM算法得到的隕石坑區(qū)域檢測結果,這2種算法從每幅隕石坑仿真圖像中正確檢測到的隕石坑區(qū)域個數(shù)如表5所示。可以看到,所提出的基于特征自動學習的隕石坑區(qū)域檢測方法能夠正確提取出所有的隕石坑區(qū)域,而Haar-like+SVM算法由于使用了人工特征,自適應性較差,對于圖12所列出的4幅隕石坑仿真圖像,該算法都分別出現(xiàn)了不同程度的錯誤檢測。

圖12 基于解析數(shù)據(jù)的隕石坑仿真圖像隕石坑區(qū)域檢測結果圖例Fig.12 Examples of crater region detection experimental results of crater simulation image based on analytical data
另外,表5還給出了所提出的候選區(qū)域提取算法、候選區(qū)域分類算法以及Haar-like+SVM算法處理圖12第1列所示的4幅隕石坑仿真圖像的時間。可以看到,基于自動特征學習的隕石坑區(qū)域檢測算法的大部分時間主要消耗在候選區(qū)域提取上。

表5 基于解析數(shù)據(jù)的隕石坑仿真圖像隕石坑候選區(qū)域檢測結果統(tǒng)計Table 5 Candidate crater region detection experimental results of crater simulation image based on analytical data
4.4 基于真實隕石坑圖像的隕石坑區(qū)域檢測實驗
利用真實隕石坑圖像對基于自動特征學習的隕石坑區(qū)域檢測算法(仍然簡稱為CraterCNN+SVM)進行驗證,所使用的測試圖像來自于美國麻省大學波士頓分校KDLab實驗室在構造隕石坑數(shù)據(jù)集h0905_0000時所采用的火星表面真實隕石坑圖像[45]。由于4.2節(jié)中的實驗已經(jīng)針對數(shù)據(jù)集h0905_0000完成了隕石坑區(qū)域分類器CraterCNN+SVM的訓練,本組實驗將直接利用訓練好的分類器,并結合所提出的隕石坑候選區(qū)域提取算法,完成對真實隕石坑圖像的隕石坑區(qū)域檢測。與4.3節(jié)相同,本組實驗仍然選擇Haarlike+SVM方法作為對比方法,檢測結果如圖13所示。
圖13第1列給出了來自KDLab實驗室的4幅火星表面真實隕石坑圖像。利用所提出的隕石坑候選區(qū)域提取算法從輸入的隕石坑圖像中提取疑似隕石坑區(qū)域,結果如圖13第2列所示。可以看到,所提算法能夠較為精確地從輸入圖像中提取出隕石坑候選區(qū)域。CraterCNN+SVM和Haar-like+SVM所提取到的隕石坑區(qū)域檢測結果如圖13第3列和第4列所示,這2種方法從每幅隕石坑仿真圖像中正確檢測到的隕石坑區(qū)域個數(shù)如表6所示。可以看到,CraterCNN+SVM能夠正確提取出所有的隕石坑區(qū)域,而Haar-like+SVM由于使用了人工特征,精度和自適應性較差,對于圖13所列出的4幅隕石坑仿真圖像,Haar-like+SVM都分別出現(xiàn)了不同程度的錯誤檢測結果。

圖13 基于真實隕石坑圖像隕石坑區(qū)域檢測結果圖例Fig.13 Examples of crater region detection experimental results based on real crater simulation image

表6 基于真實隕石坑圖像的隕石坑候選區(qū)域檢測結果統(tǒng)計Table 6 Candidate crater region detection experimental results based on real crater image
5 結 論
針對基于隕石坑視覺導航對隕石坑區(qū)域檢測的需求,提出一種高精度的基于自動特征學習的隕石坑區(qū)域檢測算法。
1)算法可以實現(xiàn)從導航圖像中提取隕石坑區(qū)域,為基于隕石坑的視覺導航方式提供必要的導航路標輸入。
2)算法有效地利用了圖像隕石坑的形態(tài)特點,利用改進后的MSER算法實現(xiàn)了隕石坑候選區(qū)域檢測,有效克服了傳統(tǒng)的滑窗檢測算法計算負擔大、效率低的問題,極大降低了誤檢率。
3)算法利用自動特征學習的方法實現(xiàn)隕石坑候選區(qū)域的分類,實現(xiàn)隕石坑區(qū)域檢測,檢測精度明顯高于傳統(tǒng)的基于人工特征的隕石坑區(qū)域檢測算法,在通用火星表面隕石坑數(shù)據(jù)集上,獲得了0.916 4的F1度量值,遠高于其他隕石坑區(qū)域檢測算法。
基于自動特征學習的隕石坑區(qū)域檢測算法可以為基于隕石坑視覺導航提供隕石坑區(qū)域信息,然而,要實現(xiàn)高精度的基于隕石坑視覺導航,還需要對隕石坑區(qū)域中的隕石坑環(huán)形邊緣提取算法進行研究,這將是下一步研究工作的重點。
猜你喜歡
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
