面向智能語言處理的漢語句法語義知識庫構建
2021-06-15 04:17:18史金生李靜文
哈爾濱師范大學·社會科學學報 2021年2期
史金生 李靜文


[摘?要]文章通過比較各種語義知識庫的特點,重點討論了基于生成詞庫和論元結構理論的句法語義知識體系研究及資源庫構建的內容、特色,并從句法-語義接口的透明性和自然性、名詞中心論建模方法的實用性、解決復雜語法問題的便捷性、情感評價色彩描述的突破性等四個方面分析了其價值,并提出了關于未來句法語義知識體系研究的幾點思考。
[關鍵詞]生成詞庫;論元結構;物性結構;句法語義知識庫;情感評價
[中圖分類號]H08?[文獻標志碼]A?[文章編號]2095-0292(2021)02-0001-09
[作者簡介] 史金生,首都師范大學文學院教授,博士研究生導師,國家語委科研基地中國語言智能研究中心副主任,中國語文現代化學會語義功能語法專委會理事長,研究方向:句法語義、漢語國際教育、語言知能;李靜文,首都師范大學文學院博士研究生,研究方向:句法語義。
一、引言
自然語言處理就是研究計算機處理自然語言的過程和方法,包括形式化、算法化、程序化、實用化等步驟,其中建立語言的形式化模型,使之能以一定的數學形式表示出來,是自然語言處理的核心。自然語言處理經歷了從知識驅動到數據驅動的不同發展階段:語言知識的獲取最早是基于語言學家的規則描寫,即根據語言學規則來編寫程序,然后發展到基于統計,即從大規模真實語料庫中獲取語言知識,近些年發展到基于神經網絡,通過深度學習,讓計算機自動獲取自然語言的特征。人工智能現在已經發展到第三代,已經來到了一個重要的拐點,其路徑是融合第一代知識驅動和第二代數據驅動,自然語言語義的精準理解因而成為人工智能皇冠上的明珠。
計算機要能實現準確的分析,就要具備相應的語義以及語法等知識,以及相應的常識知識和推理能力。建立句法、語義知識庫之類的語言知識資源,并且映射到知識圖譜之類通用的形式化的語義表示框架,可以幫助計算機理解自然語言的意義,并且在一定程度上進行常識性知識推理;相反,如果同相關的知識沒有牽扯,僅僅是統計方法、機器學習,計算機就不能達到對相關語言、概念的深刻理解。面向自然語言處理的知識庫可服務于自動分詞、詞性標注、句法分析、語義分析、機器翻譯、信息提取、情感分析、文本摘要和問答系統等多個領域。構建相應的句法語義知識庫成為當前自然語言處理的重要任務,而缺乏形態標記的漢語,建立相關的知識庫顯得更加迫切。
本文主要分析漢語句法語義知識庫構建的理論基礎、具體內容、特色優勢,并提出未來句法語義知識體系研究方面的幾點思考。
二、國內外基于不同理論框架的知識庫構建
現階段,語言知識庫主要包括現代漢語語法信息詞典、大規模現代漢語基本標注語料庫、平行語料庫、英漢和日漢對照雙語語料庫、多語言概念詞典、現代漢語短語結構規則庫等,此外,還有為上述語言知識庫服務的不同種類的工具軟件,這些最終構成了綜合型的語言知識庫。
如果要展示詞匯概念,并且描述概念和概念之間,以及概念和屬性間關系,就需要文本語義了,也就是需要重新構建語義知識庫。近年來,國內外比較流行的語義知識庫在設計方面各具特點,但都是依據一定的語言學理論構建起來的。例如,美國普林斯頓大學WordNet知識庫,將語義上緊密聯系的相關詞匯聚合成同義詞集;美國科洛大學的VerbNet知識庫,以Levin的動詞分類作為理論基礎,描述不同類別動詞的論元結構;賓西法尼亞大學的Chinese PropBank知識庫,借鑒了PropBank的理論和描述框架;紐約大學的NomBank知識庫,借鑒了PropBank,Nomlex項目及支撐動詞有關研究;Chinese NomBank知識庫就是將英語命題庫以及英語NomBank常規架構,用到了中文名詞化謂詞標注當中;我國臺灣地區詞庫小組的Sinica TreeBank知識庫,運用了中心語主導原則和依存語法理論;上海師范大學與山西大學聯合構建的Chinese FrameNet,運用了框架語義學的理論;北京大學中文網庫是在配價語法基礎上提出了論元結構理論,并將這一理論運用于知識庫構建;清華大學、北京大學、魯東大學的事件描述塊句法語義標注庫,運用了格語法和配價語法理論。
以上語義知識詞庫為計算機實現自然語言的語義理解提供了可能性,但是也存在一些缺陷。比如,WordNet往往會將詞語之間的組合關系以及語句段落里面共現的關系忽視掉,VerbNet知識庫將動詞當作核心,這樣就不能夠妥善地處理和解決情景式事物指稱的問題,FrameNet無法準確地掌握相關詞匯概念在具體語句段落里面的最常見的共現關系;ConceptNet雖然被計算機賦予常識經驗,但缺少句子和語篇間的組合推斷。那么,如何解決像“網球問題”等事物間情景聯想的有關問題?計算機如何模仿人類進行常識推理和句法組合?一些語言學家作出了積極深入的探索。
三、基于生成詞庫和論元結構理論的漢語句法語義知識庫
最近,北京大學袁毓林教授團隊基于生成詞庫論和論元結構理論,對漢語實詞進行了句法語義知識挖掘構建,編寫了《現代漢語實詞語法語義功能信息詞典》(以下簡稱《實詞信息詞典》)。
1.主要內容
《實詞信息詞典》不僅充分地描寫了動詞和形容詞的論元角色及其句法配置,還描寫了名詞的物性角色及其句法配置,把漢語有關的句法、語義及相關的常識知識納入詞項的句法、語義描述中,從而在體詞和謂詞之間形成了具有鏈接性的語義網絡和句型體系。
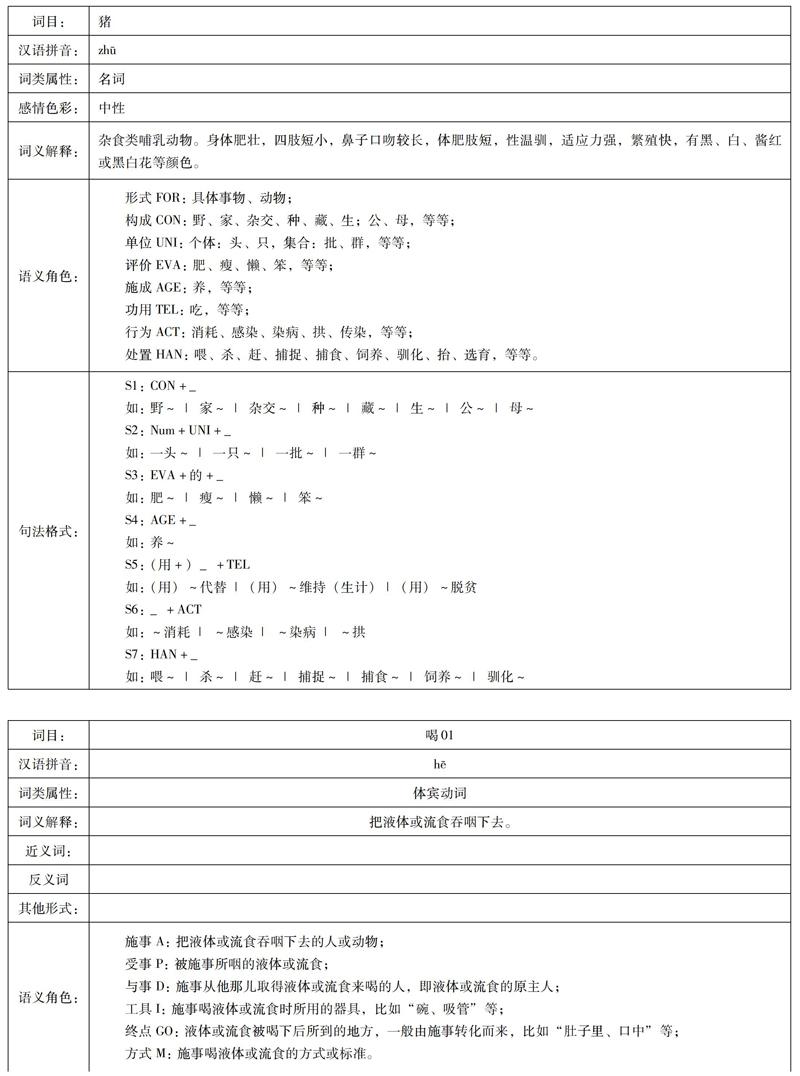
《實詞信息詞典》是一個綜合型的語義知識庫,可以服務于自然語言處理。詞典的主要內容有現代漢語常用實詞的語義角色、主要句型、經典例句等。同時,還有一個配套信息檢索系統,可以快速、準確地檢索到所需要的信息內容。該詞典由“漢語動詞句法語義功能信息詞典暨檢索系統”“漢語形容詞句法語義功能信息詞典暨檢索系統”“漢語名詞句法語義功能信息詞典暨檢索系統”這三個子系統構成。該詞典為實詞設計了一套前后一致、互相照應的語義表示框架,揭示它們之間語義角色關系;加入情感評價色彩的描寫,由此形成了相對完善的漢語語義知識體系。這一體系具有很大的優勢,基于該體系,可以形成相應的語義知識庫,其中具備了面向對象、可擴展的特點。特別重視語義角色,即詞語之間的搭配關系和選擇限制,并配有相關句型和習慣搭配。將語言知識納入到知識圖譜當中的方式,可以讓人們更加容易也更加深刻地理解AI的含義。
知識庫里面的每個實詞的構成都是有兩個部分,一個部分是語義角色,也被稱作物性角色,另一個部分則是句法格式。詞庫生成需要有四種不同的物性結構,語義知識庫則是在這四種不同的物性結構上進行了擴增,變成了10種不同的物性結構,分別是形式、構成、單位、評價、施成、材料、功用、行為、處置以及定位。這10種不同的物性結構一起組建成名詞物性結構框架。這項研究針對動詞、形容詞等,建立了論元結構描寫框架。在這個框架里面的內容主要有施事、經事、主事、與事、對象、工具、方法、原因、目標、時段、場合、起點、終點、途徑等,共計22種動詞語義角色。此外,還包括感事、與事、系事等合計9種形容詞語義角色。利用句法格式就能夠實現描寫名詞的物性結構與動詞、形容詞的論元結構的連接;并且還可以形成完整的句法語義接口知識,實現了在動態語境下意義浮現的解釋和說明。這一知識庫比其他語義知識庫更加注重組合性、語義劃分的精細化及語義結構,有利于計算機進行自動文本的常識性推理。
2.多層聯動推導特征
《實詞信息詞典》是在調查大規模真實文本語料的基礎上,通過對名詞、動詞和形容詞等實詞的物性結構和論元結構的精心設計和合理描述,把事物和跟事物相關的事件的有關世界知識及其語言表達形式表示出來,再輔之以指針鏈接和知識圖譜(knowledge graph)等數據表示技術和拉近—推遠(zoom-in and zoom-out)等便捷的呈現手段,有效地把相關的名詞、動詞和形容詞的語義關聯起來,形成了以名詞(實體)為檢索核心的、面向對象(object orientation)的語義知識庫。
比如“豬—喝—湯”的語義角色關系及句法配置的構建:
名詞“豬”的行為角色是動詞“喝”,這是從名詞出發看名詞和動詞的語義關聯;反過來,從動詞出發看動詞和名詞的語義關聯,動詞“喝”的施事角色是名詞“豬”,同時受事角色是名詞“湯”。而“湯”作為“豬”施成的條件與句子保持了句法結構的關聯。“湯”功用語義角色促發了與動詞“喝”進行關聯。因此我們看到“豬—喝—湯”構成了一個知識網絡,在知識網絡中每一個節點都因語義角色的關系而相互關聯,最終形成句法結構。通過對動詞的論元結構和名詞的物性結構的刻畫,為計算機理解名詞—動詞之間的語義關系,提供了一種有效的知識表示。
我們再看一下名詞與其他詞的關聯問題,《實詞信息詞典》解決了“饅頭問題”,圍繞名詞進行物性角色的構建也符合沈家煊(2019)“大名詞”觀的思路,如:
圍繞名詞“饅頭”可以組構成多種事件,如構成中可以與其他名詞形成偏正和聯合結構“雜糧饅頭”“主食饅頭”,處置語義角色在句法中表現為動詞的賓語,如“吃—饅頭”“買—饅頭”,作賓語也可以是施成角色,如“蒸饅頭”,“饅頭”的動作行為角色也可以賦予“饅頭”話題的身份,如“饅頭霉變”。“饅頭”的評價角色,使得饅頭可以作為被修飾的成分,如“熱氣騰騰的饅頭”“硬邦邦的饅頭”“松軟可口的饅頭”等。可見,圍繞“名詞”可以關聯動詞“吃”“蒸”等,也可以關聯名詞“主食”“雜糧”等,甚至還可以關聯形容詞“松軟可口”“硬邦邦”等。以名詞為中心輻射構成了知識圖譜。
另外,計算機在處理情感評價系統的時候存在輸出的困難,如何識別句子的隱藏特征成為需要解決的問題。我們在考察《實詞信息詞典》的形容詞部分找到了相關的證據。
比如:
我們可以看到“好”是對主事和范圍的評價,比如“這把傘的質量好”,也可以用于比較結構“這把傘的質量比那把傘的質量好”,但是我們發現,事件結構也可以用“好”進行主觀評價,比如“豬喝湯好”,“好”評價了前面的“豬喝湯”這一事件結構。如果借用化學上原子化合和配價的說法,那么形容詞就是語句組合的核心,像主體、方面等伴隨成分就是配價成分。不同的形容詞有不同的配價功能,支配不同數量和不同性質的配價成分,構成不同形式的短語和句子。袁毓林、曹宏(2019)“形容詞信息詞典”就是從這樣一種“情境語義學”( situation semantics) 和“配價語法”( valence grammar) 的角度,通過對大規模真實文本語料的調查和分析,全面、準確、簡明地描寫形容詞在情境意義和搭配用法上的關鍵性特點,使讀者“觀其伴,會其意; 明其價,知其用”,即讓讀者在查閱到一個形容詞條目以后,可以了解該形容詞通常與哪些伴隨成分一起出現,從而從搭配關系上理解該形容詞的意義、明白其配價組合方面的特點,并掌握其基本的常用句式,進而根據這些句式,模仿相關實例,理解相關的其他句子。
形容詞在修辭上生動優美、意蘊豐富,但是它的意義又顯得空靈朦朧,使用起來不太好把握火候。那么,怎樣才能比較切實地了解形容詞的意義、掌握形容詞復雜多變的用法呢?其實,了解一個詞和了解一個人有相似之處。通常,我們看一個人跟什么人來往,就可以知道他大概是一個什么樣的人。同樣,要了解一個詞的意義和用法,最好的辦法莫過于觀察它跟什么樣的詞語搭配。
另外,如“很+NP”類評價構式中的NP的語義角色關聯還需要繼續考慮,這就與詞典中“藝術”不能受到“很”“不”等副詞修飾相沖突,那么計算機如何識別“整體大于部分之和”的構式性問題還需要進一步思考。如:
四、句法語義知識庫構建的意義和價值
Halvorsen(1988)特別提出計算語言學其實是模擬了人類社會的語言接受和處理的能力。這種能力其實就是典型的人工智能方法,其最大優勢是實現了計算機同人類之間的轉化。即將人類思維成功轉化為相應的模型,使得人類的整個認知過程通過所建立的計算機模型進行實現。他曾經試圖使用計算范式去模擬人類學習、獲取、儲存、使用知識的全部流程。
通過運用語言知識資源,讓機器更加準確地理解語義,并進行一些常規的推理和推斷,這正是眾多計算機專家、語言學家們普遍關注和想要探究明白的問題。如何解決自然語言處理中的語義表示和理解技術,逐漸提上日程。總體而言,基于認知的《實詞信息詞典》,創建了具有鏈接性的語義網絡,把語義知識加入知識圖譜,利用計算機信息技術和語言知識資源建構了基于情感計算和常識計算的語義知識庫,解決了像“網球問題”“他是老狐貍”等需要人類常識經驗參與的語義知識問題,具有語言知識與常識推理互動溝通的創新性和信息技術開發的前沿性。
1.實現了句法-語義的自然對接
為計算機研究語言,主要以自然語言為對象,并對其具體的結構、意義規律進行不斷的深入挖掘,從中得到相應的規則,包括語法以及句法等。同時這些規則具有一定的特點,即相對容易實現形式化、算法化。基于上述理念建立的相應的理論模型,主要作用就是更好地組織各種規則。《實詞信息詞典》里面實詞語義結構的構成有兩大部分,一個部分是語義角色,也叫作物性角色,另外一個構成部分就是句法格式。語義角色可以表述事物語義特點;后面句法格式則是表示實詞和語義角色句法結合的特征。語義結構網絡在與常識性知識建立聚合聯系的同時,也關注句法結構、語境浮現和篇章鏈接的組合性關系和配置模式。這個知識庫構建了一個新的動作指針鏈接,最終就成為一個“謂詞—論元”式的語義關系圖式。基于生成詞庫理論,整合了VerbNet、FrameNet、ConceptNet等知識庫的優點,形成了動詞、形容詞論元結構知識庫和名詞物性結構知識庫互動的模式。
2.突出了名詞中心論建模方法的實用性
基于生成詞庫和論元結構形成的句法語義知識庫具備一定的優點,具體來講就是對相關詞語所反映的知識進行突出表現,不但包括常識知識,而且有百科知識,特別是名詞的描寫,是在“物性角色”基礎上,實現對相關的百科知識、語義結構進行詳細的描述,從而解決了對“圍棋是什么?”等相關問題的解釋。更重要的是,該語義資源還可以和計算機視覺技術相結合,讓計算機進行常識推理。例如,可以實現“如何選用某種工具(鏟子)來完成鏟土之類工作?”等等相關的判斷和推理。
從另一方面來說,該知識庫通過描寫事物間的關系,構建了名詞的框架結構;又基于論元結構建立了動詞和形容詞框架結構,并從句法角度刻畫了名詞與動詞和形容詞論元結構的選擇限制和搭配關系,演化為語義關聯、互動推導,而且都是以名詞作為核心,包括動詞、形容詞以及名詞,構建了屬性、動作和事物間的語義網絡。比如,名詞“網球”的施成角色是動詞“制作”等,這是從名詞的角度來對名詞、動詞之間的語義關聯進行分析;同理,從動詞的角度,網球這一名詞實際上就是動詞“打”等的受事角色。因此,這種以名詞為中心的語言建模和概念建模具有較強的實用性。
3.解釋了一些復雜的語法現象
構建有足夠精細度的句法語義知識庫,有利于為計算機處理復雜的語法現象提供資源和解釋。例如,漢語里有“名詞+的+名詞”歧義的問題,像“魯迅的書”就可以理解為“魯迅擁有的書”以及“魯迅寫的書”兩種意思。針對自然語言處理,可以給計算機一個指令規則,即當NP1表示人或機構、NP2表示物品時,其中NP1和NP2之間隱含獲得義,但是“魯迅的書”卻沒辦法用規則來說明,而利用語義知識圖譜恰好能夠消解這種隱含動詞的歧義現象。在《實詞信息詞典》中檢索“魯迅”的百科知識,查到其身份是作家,再調用“作家”的物性角色,查到其功能角色是“寫”,從而消解了歧義。其次,可以通過物性角色去給有價名詞構建模型。比如“小明對小紅的意見”中“意見”作為二價名詞,可以在“物性角色”中的“構成”中,展現其降級“施事”和降級“受事”,解決有價名詞的句法語義問題。再如,有些結構是動詞中心論無法解決的問題,如“自行車騎起來很輕松。”如果我們轉換視角,用名詞中心論就更容易解釋,如把“騎”看成是名詞“自行車”的功用角色,后面的形容詞是名詞的直接評價角色,或者把“形容詞”看成名詞直接是從功用角色承繼下來的評價角色( [騎自行車]輕松)。另外,針對無根話題,如“大象,鼻子長”,通過在《實用信息詞典》中檢索“大象”,其構成角色為“鼻子”,這樣就找到了與前面的無根話題的聯系。最后,像“他打籃球打得好”轉變為“他的籃球打得好”的限制條件可以用語義知識圖譜解釋為,形容詞“好”是修飾“他打籃球”整個事件的,事件內“打”是后面賓語“籃球”的施成角色。可見,把名詞的物性角色與動詞、形容詞的論元角色整合起來,能夠為解決復雜的語法現象提供方便。
4.突破了情感評價色彩描述的難題
人類日常語言中的感情色彩表達常常是通過褒貶詞實現的,反過來說詞語的情感色彩表達了人類對相關事物的情感評價。《實詞信息詞典》對于漢語的實詞采用五級標度的方式表示其感情色彩。具體就是褒義(+2)、積極(+1)、中性(0)、消極(-1)、貶義(-2)。五級標度的方式避免了對情感色彩區分顆粒度過大或者過小的毛病,且有一定的階梯性。除此之外,還加入了副詞的考慮,如“很”“非常”等詞在與情感色彩詞搭配時,感情色彩將增強和減弱的情況。
另外,語義知識庫還結合通俗的“七情”分類和心理實驗,將情緒詞分為快樂、喜好、悲哀、驚恐、憤怒、厭惡等六類,讓計算機處理自然語言時具有了情感分析能力。所以,這種帶有情感評價色彩的描述,在自然語言處理當中是有很大的突破意義的。
五、結語
當前,語義計算已經從詞匯經句法轉向篇章,出現繁榮發展的趨勢。要準確地進行語義關系標注,不僅要描述論元結構,還要更加完整地把握命題結構甚至命題之外的時體、情態、篇章特征。如何標注清楚事件論元關系?如何在“謂詞—論元”結構中整合“時體—情態”結構?特別是“事件”已成知識圖譜新制高點的當下,怎樣讓靜態性語義知識庫和動態性事件框架更好地融合起來?這些問題都是需要更深入地探討的內容。
從語言本體而言,加強語言理論研究,逐步完善語義描述體系和詞典構架,使語義資源建設能夠更好地為知識圖譜和語義計算服務。要深入地聯合人格心理研究實驗,探索人格評價詞語所具有的情感傾向,并將這種傾向展開進一步細化。要重視語義角色的精細化等級,從數量和分類方面,尋找適合的語義角色顆粒度。總之,要想把語義資源與計算機技術推向深入,使得多層神經網絡的深度學習技術突出重圍,幫助計算機真正“智能”起來,“弄懂”人類語言,還需要更進一步的探索。
[參?考?文?獻]
[1]Chomsky & G. A. Miller.Introduction to the formal analysis of natural languages[M].Wiley, New York,1963.
[2]Chomsky.?Formal properties of grammar[M].Wiley, New York,1963.
[3]Daniel Jurafsky & James H. Martin. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics and Speech Recognition [M].Upper Saddle River, New Jersey, Prentice Hall, 2000. 中文譯本:馮志偉, 孫樂翻譯.自然語言處理綜論[M].北京:電子工業出版社,2005.
[4]Grishman, Ralph .Computational Linguistics:An Introduction[M]. Cambridge University Press,1986.
[5]Halvorsen, Per-Kristian .Computer applications oflinguistic theory, in F. J. Newmeyer (ed.) Linguistics: The Cambridge Survey, Vol. II, Linguistic Theory: Extentions and Implications[M]. Cambridge University Press,1988.
[6]Manaris.?Natural language processing in the view of man-machine interchange[J].Advances in Computer, Volume,1999(47).
[7]白碩.語言學知識的計算機輔助發現[M].北京:科學出版社,1995.
[8]馮志偉.計算語言學對理論語言學的挑戰[J].語言文字應用,1992(1).
[9]馮志偉.自然語言的計算機處理[M].上海:上海外語教育出版社,1996.
[10]沈家煊.超越主謂結構[M].北京:商務印書館,2019.
[11]袁毓林.信息抽取的語義知識資源建設[J].中文信息學報,2002(5):8-14.
[12]袁毓林.語義資源建設的最新趨勢和長遠目標——通過影射對比、走向統一聯合、實現自動推理[J].中文信息學報,2008(3):3-15.
[13]袁毓林.面向信息檢索系統的語義資源規劃[J].語言科學,2008(1):1-11.
[14]袁毓林.漢語配價語法研究[M].北京:商務印書館,2010.
[15]袁毓林.基于生成詞庫論和論元結構理論的語義知識體系研究[J].中文信息學報,2013(6):23-30.
[16]袁毓林.漢語名詞物性結構的描寫體系和運用案例[J].當代語言學,2014(1):31-48.
[17]袁毓林,李強.怎樣用物性結構知識解決“網球問題”[J].中文信息學報,2014(5).
[18]袁毓林.怎樣利用語言知識資源進行語義理解和常識推理[J].中文信息學報,2018(12).
[19]袁毓林,曹宏.“漢語形容詞句法語義功能信息詞典暨檢索系統”知識內容說明書[J].辭書研究,2019(2).
[責任編輯?薄?剛]
