基于點對相似度的深度非松弛哈希算法
2021-06-20 10:11:02汪海龍肖創柏
自動化學報 2021年5期
關鍵詞:模型
汪海龍 禹 晶 肖創柏
近年來,隨著計算機軟件和硬件技術的發展,圖像、視頻等數據的維度和數量不斷增加,為了解決海量的高維數據的存儲和檢索問題,研究學者提出了將高維數據投影到低維二值空間的哈希學習方法.哈希學習方法是一種在保持圖像或視頻等高維數據間相似性的條件下,通過哈希函數或函數簇將高維空間的數據投影到低維漢明空間的二值編碼的機器學習方法.通過哈希學習方法對數據建立索引,提高圖像等高維數據的檢索效率,并節省存儲空間.現有的哈希方法大致可以分為兩類:數據獨立的方法和數據依賴的方法[1].
數據獨立的方法使用隨機投影來構造哈希函數.局部敏感哈希(Locality sensitive hashing,LSH)算法[2-4]于1998 年由Indyk 等提出,該算法在原始空間中使用隨機線性投影將距離近的數據投影到相似的二值編碼中.該算法的哈希函數簡單易實現,計算速度快,但準確率不高.核化局部敏感哈希(Kernelized locality-sensitive hashing,KLSH)算法[5]對LSH 算法提出了改進,KLSH 在核空間中隨機構造哈希函數,不需要考慮原始空間的數據分布,可以選擇任意核函數作為相似性度量函數.但由于核函數的引入,很大程度上增加了計算復雜度.數據獨立的方法雖然簡單易實現,但是由于這類方法不使用訓練數據訓練模型,所以需要很長的哈希碼才能達到較高的準確率.數據依賴的方法使用訓練數據來學習將高維數據投影為低維二值編碼的哈希函數.如同一般的機器學習方法,數據依賴的方法可以分為非監督型方法和監督型方法.
非監督型哈希學習方法是在數據沒有類別信息或不利用類別信息情況下,根據某種距離度量檢索最近鄰數據的方法.譜哈希(Spectral hashing,SH)算法[6]是一種典型的非監督哈希算法,其采用主成分分析(Principal component analysis,PCA)算法[7]獲取圖像數據的各個主成分方向,并計算所有的解析特征函數(Analytical eigenfunction),然后使用符號函數將這些解析特征函數的值量化為二值編碼.由于在實際情況中很難同時滿足譜哈希的兩個約束條件,即假設從多維均勻分布的空間中采樣數據以及不同維度上的哈希編碼之間相互獨立,因此譜哈希的使用受到一定限制.迭代量化哈希(Iterative quantization,ITQ)算法[8]將數據投影到中心為零(Zero-centered)的二值超立方體(Binary hypercube)的頂點,使得投影后的數據與原數據之間的量化誤差能夠最小化,并使用一種簡單有效的交替最小化(Alternating minimization)方法求解目標函數.與SH 算法相比,ITQ 算法不僅應用范圍更廣,而且經實驗驗證ITQ 算法的檢索效果更好.
監督型哈希學習方法是指將圖像或其他高維數據的類別標簽用于估計二值編碼模型的輸出,在迭代過程中不斷利用圖像的標簽信息計算實際輸出與預期輸出之間的誤差反饋給模型,不斷調整模型參數的方法.由于監督型哈希方法利用了數據的標簽信息,一般情況,監督型哈希方法的效果比非監督性哈希方法的效果好.2011 年,Norouzi 等提出了最小損失哈希(Minimal loss hashing,MLH)算法[9],這是一種典型的監督型哈希學習算法,該算法通過結構化支撐向量機(Structural support vector machine,Structural SVM)建立損失函數,由于損失函數不連續且非凸,難以直接求解,該算法通過構造并最小化損失函數的上界來求解損失函數.基于核的監督哈希(Kernel-based supervised hashing,KSH)算法[10]采用核的形式來構造哈希函數,使得其泛化可以處理非線性可分的問題,并且,不同于MLH 算法的是,KSH 算法不直接通過最小化哈希碼之間的漢明距離來學習哈希函數,而是通過最小化哈希碼的內積,使問題變得更簡單,更容易求解.2015 年,Shen 等[11]提出了監督型離散哈希(Supervised discrete hashing,SDH)算法,該算法使用Lagrange 乘子法將離散約束問題松弛為凸優化問題,在求解階段使用循環坐標下降法(Cyclic coordinate descent,DCC)求解目標函數,即每次迭代固定其他的哈希位,只將一個哈希位作為變量求解,SDH 算法在保持準確率的同時,提高了算法的效率.
上述傳統的哈希學習方法在提取圖像特征時采用手工設計特征,例如梯度方向直方圖(Histogram of oriented gradient,HOG)、尺度不變特征變換(Scale invariant feature transform,SIFT)等,不同場景的圖像使用相同的手工設計特征在一定程度上影響了哈希學習算法的性能,單一的特征導致檢索準確率不高.近年來,卷積神經網絡(Convolutional neural network,CNN)[12-13]在計算機視覺領域成為主要的特征學習工具,在圖像分類[14]、目標檢測[15-16]等方向得到廣泛應用.目前許多學者也嘗試將CNN 用于哈希學習方法中,陸續出現了一些深度哈希學習方法.
2014 年,Xia 等[17]提出了卷積神經網絡哈希(Convolutional neural network hashing,CNNH)算法,該算法利用深層框架來學習圖像的特征,然后以此特征學習哈希函數.這是一種兩階段哈希學習算法,第1 階段通過對相似度矩陣進行分解,預生成樣本的二值編碼;第2 階段將樣本數據輸入CNN,使用卷積層提取圖像特征,通過最小化網絡輸出值與第1 階段預編碼之間的誤差,獲得樣本的哈希碼.CNNH 相對于非深度哈希學習算法在準確率上有明顯的提高,然而也存在明顯的問題,第1 階段中相似度矩陣分解是一個非凸優化問題,分解過程中需要大量的松弛方法,導致準確率會受到很大的影響;第2 階段僅利用了CNN 自動提取圖像特征,沒有參與第1 階段的計算.基于監督型深度哈希的快速圖像檢索(Deep supervised hashing for fast image retrieval,DSH)算法[18]利用成對的圖像和圖像的標簽作為網絡的輸入進行訓練,并聯合使用對比損失函數(Contrastive loss)與哈希碼的?1范數正則項作為網絡的損失函數,以此約束哈希碼,使輸出在漢明空間的哈希碼更加多樣化,避免了兩階段哈希算法中第1 階段不能利用CNN 網絡,以及使用sigmoid 函數導致網絡收斂速度過慢的問題.2016年,Li 等[19]提出了基于標簽對的監督型深度哈希特征學習(Feature learning based deep supervised hashing with pairwise labels,DPSH)算法,該算法通過圖像的類別標簽構造圖像的標簽對矩陣,根據圖像的標簽對構建交叉熵損失函數,以此衡量深度卷積神經網絡訓練的損失,使用基于Lagrange 乘子法的松弛優化方法,對約束條件進行松弛,去掉符號函數的約束條件,解決離散約束問題.但是由于該算法使用Lagrange 乘子,某些哈希位會被過度松弛,導致相似點對之間的語義信息保留不完整.連續深度哈希學習(Deep learning to hash by continuation,HashNet)算法[20]也使用圖像的標簽對構建目標損失函數,該算法在目標函數構造過程中引入加權似然函數,有效地解決了相似點對數據不平衡問題,同時在網絡的輸出端使用尺度雙曲正切函數(Scaled tanh function)對網絡輸出進行閾值化,并在迭代過程中,不斷增大尺度系數,使其逼近符號函數的功能.從實驗結果來看,與傳統的哈希學習方法相比,監督型深度哈希學習方法在準確率方面明顯勝過傳統的方法.
本文提出了一種基于點對相似度的深度非松弛哈希(Deep non-relaxing hashing based on point pair similarity,DNRH)算法,該算法使用交叉熵保持相似點對之間的語義相似性,在卷積神經網絡的輸出端使用一種軟閾值函數閾值化網絡輸出得到準哈希碼,并使用?1范數約束輸出端的準哈希碼,使得準哈希碼的絕對值逼近1,避免了Lagrange 乘子的松弛求解對模型準確率的影響.本文利用卷積神經網絡提取圖像的特征表示并學習哈希函數生成哈希碼,這樣就避免了相似度矩陣分解的不準確對后續量化過程的影響.綜上所述,本文的主要貢獻歸納如下:
1)在損失函數中引入?1范數約束輸出端的準哈希碼,通過正則項約束準哈希碼,使其各哈希位的絕對值逼近1.
2)為了減小量化誤差,在CNN 的輸出端使用軟閾值函數,使輸出的準哈希碼非線性地接近-1或1.在模型外部使用符號函數sgn(·),將準哈希碼量化為二值哈希碼.
本文后續結構組織如下:第1 節介紹本文算法的背景,第2 節描述本文算法的模型、求解以及網絡結構,第3 節通過實驗驗證本文算法的性能,第4 節為全文結論.
1 背景
1.1 問題描述
在監督型哈希學習中,每一個數據樣本都有一個標簽,樣本的標簽矩陣為其中,yi∈{0,1}C,C 為樣本的總類別數.每一個樣本數據xi對應一個yi,當樣本xi屬于第c 類時,yi的第c 位為1,其他位均為0.通過樣本的標簽矩陣Y,可以定義樣本之間的相似度矩陣S ∈{0,1}n×n,對于任意兩個樣本xi與xj,若xi與xj屬于同一類別,則sij=1,否則,sij=0.
1.2 交叉熵損失函數
對于任意兩個長度相等的哈希碼bi和bj,將這兩個哈希碼的相似度φij用它們的內積定義為

內積越大,相似度越大,使用sigmoid 函數對相似度φij進行非線性閾值化,將其范圍規范化到區間(0,1),可得

基于哈希碼相似度的度量,Li 等[19]和Zhang等[21]利用交叉熵損失函數保持點對之間的相似度,圖像點對的哈希碼與相似度之間的似然p(sij|B)定義為
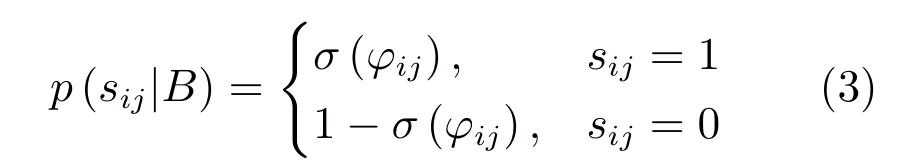
式中,sij表示樣本對之間的相似度,B 表示樣本數據對應的哈希碼.由該似然函數表明,當哈希碼bi與bj越相似,即σ(φij)越大,對應的似然函數p(sij|B)就越大;當哈希碼bi與bj越不相似,即1-σ(φij)越大,對應的似然函數p(sij|B)仍越大.極大似然估計可表示為
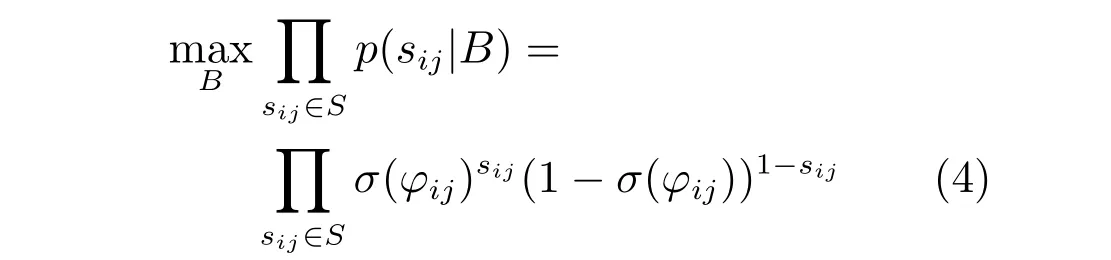
對式(4)中極大似然估計的目標函數取負對數即是交叉熵損失函數,可表示為

于是將極大似然估計轉換為最小化交叉熵損失函數,建立如下的約束最優化問題:

式中,W 表示全連接層的神經元參數,W 表示偏移量,θ 表示網絡卷積層的參數集合,bi表示二值哈希碼,bi中每一位量化到離散值-1 或1,φ(·)表示網絡提取的圖像特征,sgn(·)為符號函數,若x >0,則sgn(·)=1;否則sgn(·)=-1.
由于符號函數不連續,上述問題是一個離散的最優化問題,很難求解.為了求解上述問題,Li 等[19]使用基于Lagrange 乘子法的松弛優化方法,對約束條件進行松弛,簡化約束條件中符號函數的離散約束,使其成為凸優化問題,其目標函數為
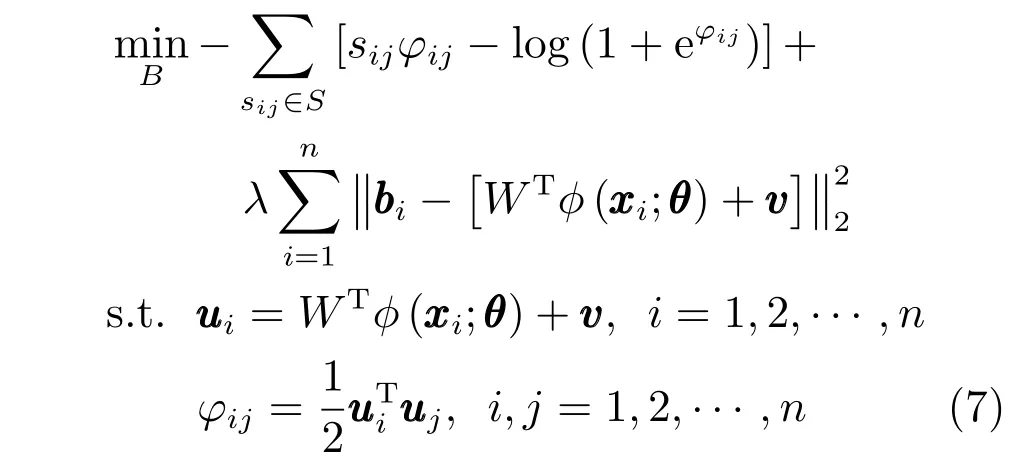
其中,ui表示網絡的直接輸出結果.該方法在每一次迭代過程中使用符號函數量化生成bi,這樣會出現大量不可忽略的損失,導致某些特征對應哈希位的約束變弱,使得計算結果不準確,這也是使用Lagrange 乘子法對約束條件松弛導致某些哈希碼過度松弛的問題.
2 深度非松弛哈希算法
2.1 模型的建立
本文利用深度卷積神經網絡訓練樣本數據,利用交叉熵保持樣本對之間的語義相似性,為了減少網絡輸出的準哈希碼的量化誤差,本文使用Liu等[18]提出的?1范數對網絡輸出的準哈希碼的分布進行約束
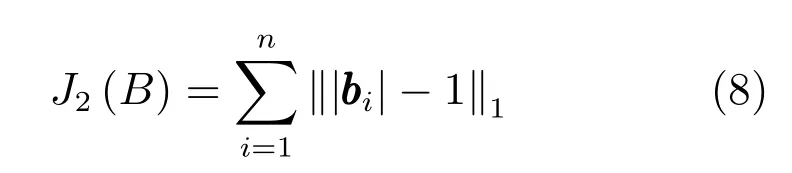
該正則項旨在使準哈希碼bi的各個哈希位逼近兩個離散值-1 或1,即bi中每一位的絕對值越接近1時,損失越小.
在迭代過程中直接使用網絡的輸出作為準哈希碼有很大概率過度偏離-1 或1,這樣將增大式(8)中J2(B)的損失值,盡管符號函數能夠很好地對其進行量化,然而符號函數不可導.相對于符號函數的離散編碼,雙曲正切函數能夠使準哈希碼的各哈希位非線性地接近-1 或1,且具有連續無限可導的良好性質,其形式為

Cao 等[20]使用尺度雙曲正切函數tanh(βx)閾值化網絡輸出值為準哈希碼,其中β 為尺度系數,控制函數值逼近1 或-1 的速度.類似地,在雙曲正切函數的基礎上,本文使用如下形式的函數:
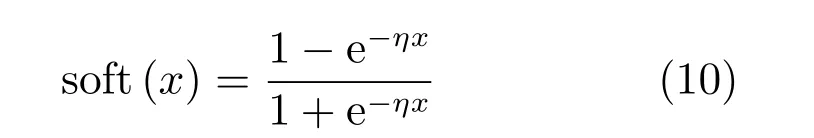
式中,η 控制閾值函數的斜率,本文中稱其為軟閾值函數.
與HashNet 算法[20]不同的是,HashNet 算法在訓練的過程中,逐漸增大閾值函數的尺度系數,隨著迭代次數的增加,閾值函數不斷逼近并最終收斂至符號函數,而本文的算法中軟閾值系數η 為模型參數,通過實驗獲取最優參數后,在每次迭代中,η保持不變,這樣將簡化模型并使模型快速收斂.本文在網絡輸出端使用式(10)的軟閾值函數,離散約束問題就轉化為可導損失函數對模型參數求導的問題.在迭代過程中,軟閾值函數將網絡輸出的結果平滑地非線性映射到(-1,1)之間,并且將大部分哈希位閾值化到-1和1 兩個值附近.圖1 給出一維空間soft(x)函數的曲線,隨著η 的增大,軟閾值函數soft(x)的函數值更加迅速地集中靠近離散值-1 或1.

圖1 soft(x)的函數曲線Fig.1 The function curve of the soft(x)
結合式(5)的交叉熵損失函數和式(8)的正則項,并在卷積網絡輸出端使用式(10)的軟閾值函數soft(x),本文建立如下目標函數:
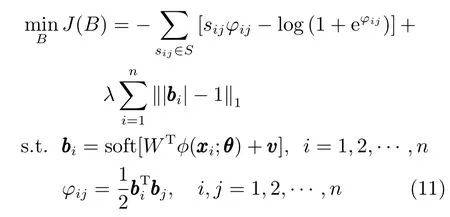
式中,n 表示樣本數,sij∈{0,1}表示樣本i和樣本j 是否相似,λ 表示正則項系數,soft(·)表示軟閾值函數,對向量逐元素運算,η 表示軟閾值函數的控制參數,bi表示前向網絡輸出的準哈希碼,φij表示兩個哈希碼之間的相似度.目標函數中,第1 項為語義保真項,第2 項為準哈希碼的正則項.在本文的網絡模型輸出端使用soft(·),輸出結果bi將迅速逼近-1和1 這兩個值,使得?1范數正則項損失減小,同時加快網絡收斂的速度.網絡經過訓練后,在網絡模型外部使用符號函數將準哈希碼量化為二值哈希碼.
2.2 參數學習
參數變量W和W 通過神經網絡的反向傳播(Back propagation,BP)求解,在每一次迭代中,通過隨機梯度下降算法(Stochastic gradient descent,SGD)更新W和W.目標函數用兩項之和表示為J=J1+λJ2,其中,
1)對準哈希碼bi求偏導
第1 項J1對bi求偏導,可得:

第2 項J2對bi求偏導,可得:

結合式(12)和式(13)可得損失函數J 對bi的偏導數為

2)對參數W 求偏導
設zzzi=WTφ(xi;θ)+W,損失函數J 對W 求偏導,根據鏈式求導法則可推導出:


其中,diag{·}表示主對角線上為向量元素的對角矩陣,soft′(x)=(2ηe-ηx)/(1+e-ηx)2,對向量逐元素運算.
因此,可得損失函數J 對W 的偏導數為
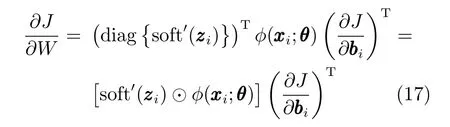
其中,⊙為哈達瑪積(Hadamard product).
3)對偏移量W 求偏導
損失函數J 對W 求偏導,根據鏈式求導法則可得:
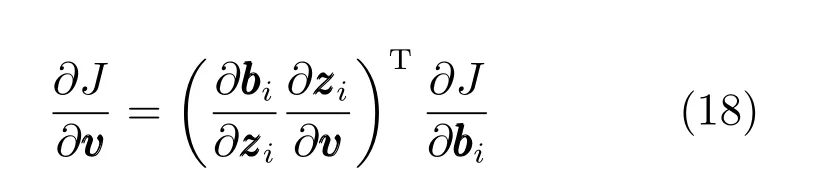

其中,Il∈Rl×l為單位矩陣.
因此,可得損失函數J 對W 的偏導數:

由以上求解過程可知,損失函數可導,即反向傳播的過程偏導數存在,網絡模型經過一定迭代能夠收斂.
2.3 網絡結構與參數
本文采用AlexNet 網絡模型作為深度哈希學習的基礎模型,AlexNet 模型一共分為8 層,5 個卷積層和3 個全連接層[12].在每一個卷積層中使用線性整流函數(Rectified linear unit,ReLU)作為激勵函數以及局部響應歸一化(Local response normalization,LRN)處理數據,然后經過下采樣(Pooling),自動提取圖像的特征表示,再經過全連接層輸出結果.本文使用的AlexNet 網絡模型及參數如圖2 所示,第1,3,5,6,7 層為卷積層.卷積層均使用保留邊界的滑動方式,第1和第3 層使用的卷積核的尺寸分別為11×11和5×5,其他3 個卷積核的尺寸為3×3,第1 層的滑動步長水平垂直方向均為2,其他4 個卷積層的滑動步長水平垂直方向均為1.第2,4,8 層為下采樣層,使用非保留邊界的滑動方式,窗口尺寸為3×3,滑動步長水平和垂直方向均為2,后三層為全連接層,輸出端使用軟閾值函數閾值化輸出為準哈希碼.

圖2 本文算法使用的網絡模型Fig.2 The network model of our algorithm
2.4 算法流程
算法1 給出了本文算法的偽代碼,輸入數據為一定格式的圖像,通過CNN 的卷積層和池化層提取圖像的特征表示,將圖像的特征表示輸入CNN 全連接層后使用軟閾值函數得到圖像的準哈希碼.根據目標函數,使用反向傳播算法更新參數W和W,通過指定次數的迭代訓練完成模型,最后,在訓練完成的模型外部使用符號函數,對圖像的準哈希碼量化輸出二值哈希碼.
算法1.深度非松弛哈希學習算法(DNRH)

3 實驗結果與分析
3.1 在CIFAR-10和NUS-WIDE 上的實驗
將本文提出的算法與各種流行的哈希學習算法進行比較,其中包括2 個非監督哈希學習算法SH[6]和ITQ[8],4 個監督型非深度哈希學習算法MLH[9]、KSH[10]、SDH[11]和BRE[22],以及6 個監督型深度哈希學習算法CNNH[17]、FP-CNNH[23]、NINH[24]、DHN[25]、DSH[18]和DPSH[19].在6 個非深度哈希學習算法中從圖像中提取512 維的GIST 特征向量作為哈希函數的輸入.本文的DNRH 算法和其他6個深度哈希學習算法CNNH、DHN、FP-CNNH、NINH、DSH、DPSH 根據圖像的尺寸使用AlexNet網絡卷積層自動提取一定維度的圖像特征作為哈希函數的輸入,生成哈希碼.
為了將本文提出的DNRH 算法與上述哈希學習算法的性能比較,實驗中,本文選取CIFAR-10[26]和NUS-WIDE[27]兩個公開的數據集.在這兩個數據集上訓練模型并進行測試.CIFAR-10 由60 000幅32×32 像素的RGB 彩色圖像構成,共包含飛機、汽車、鳥、貓、鹿、狗、青蛙、馬、船和卡車10 個類別[26].其中50 000 幅作為訓練數據,10 000 幅作為測試數據.NUS-WIDE 數據集是由新加坡國立大學媒體搜索實驗室創建的網絡圖像數據集,共有5 018個標簽,81 個類別,將近270 000 幅來源于網絡的圖像.與CIFAR-10 不同的是,NUS-WIDE 數據集中某一幅圖像可能賦予一個或者多個標簽,在本文實驗中,主要抽取動物、建筑、植物、夕陽、人、天空、云、水、草、窗戶、湖、樹、汽車、沙灘、鳥、狗、馬、雪、花、海洋、馬路21 個常用的類別[27]用于實驗,每個類別中至少包括5 000 幅圖像.
在實驗階段,在CIFAR-10 數據集中,本文隨機從每一個類別中抽取500 幅圖像作為訓練數據,100 幅圖像作為測試數據,一共5 000 幅圖像組成訓練集,1 000 幅圖像組成測試集.在NUS-WIDE數據集中,隨機從每一個類別選出500 幅圖像作為訓練數據,100 幅圖像作為測試數據.一共10 500幅圖像組成訓練集,2 100 幅圖像組成測試集.在NUS-WIDE 數據集上直接使用AlexNet 網絡模型,將每幅圖像調整為224 × 224 像素的尺寸以適應AlexNet 網絡模型的輸入.為了驗證算法的魯棒性,本文在CIFAR-10和NUS-WIDE 兩個數據集上?1范數正則項系數λ 均設置為0.05,軟閾值函數控制參數η 均設置為12.
為了避免實驗誤差以及隨機性,在評價哈希學習算法的有效性上,本文采用平均準確率(Mean average precision,MAP)[28]作為檢索圖像的評價指標.選取一定長度的哈希碼后,在測試集中,選取一部分圖像作為待檢索的樣本,依次計算待檢索的圖像與數據集中其他圖像的漢明距離,根據漢明距離將圖像排序并計算排序列表中與待檢索圖像類別相同的圖像數量與檢索圖像總數之間的比值,作為準確率.
表1 比較了CIFAR-10 數據集上本文的DNRH算法與現有的哈希學習算法的MAP.從表1 可以觀察到,在4 種長度的哈希碼上,本文的DNRH 算法的平均準確率均明顯高于其他所有算法.通過比較CNNH、DHN、FP-CNNH、NINH、DPSH、DSH和DNRH 等7 個深度哈希算法以及其他6 個非深度哈希算法的MAP 可知,深度哈希算法高于非深度哈希算法的平均準確率,這表明使用CNN 模型的深度哈希學習算法自動提取圖像特征表示比傳統手工提取圖像特征表示具有更好的性能.對于12 bit的哈希碼,所有算法的檢索準確率相對偏低,隨著哈希碼長度的增加,所有算法檢索準確率都逐漸提高,哈希碼長度為48 bit 時,所有算法的檢索準確率達到了最高.相比于48 bit 以下的哈希碼,使用48 bit的哈希碼可以存儲更多的圖像特征,在檢索時,可以利用更多的圖像特征,取得更高的準確率.
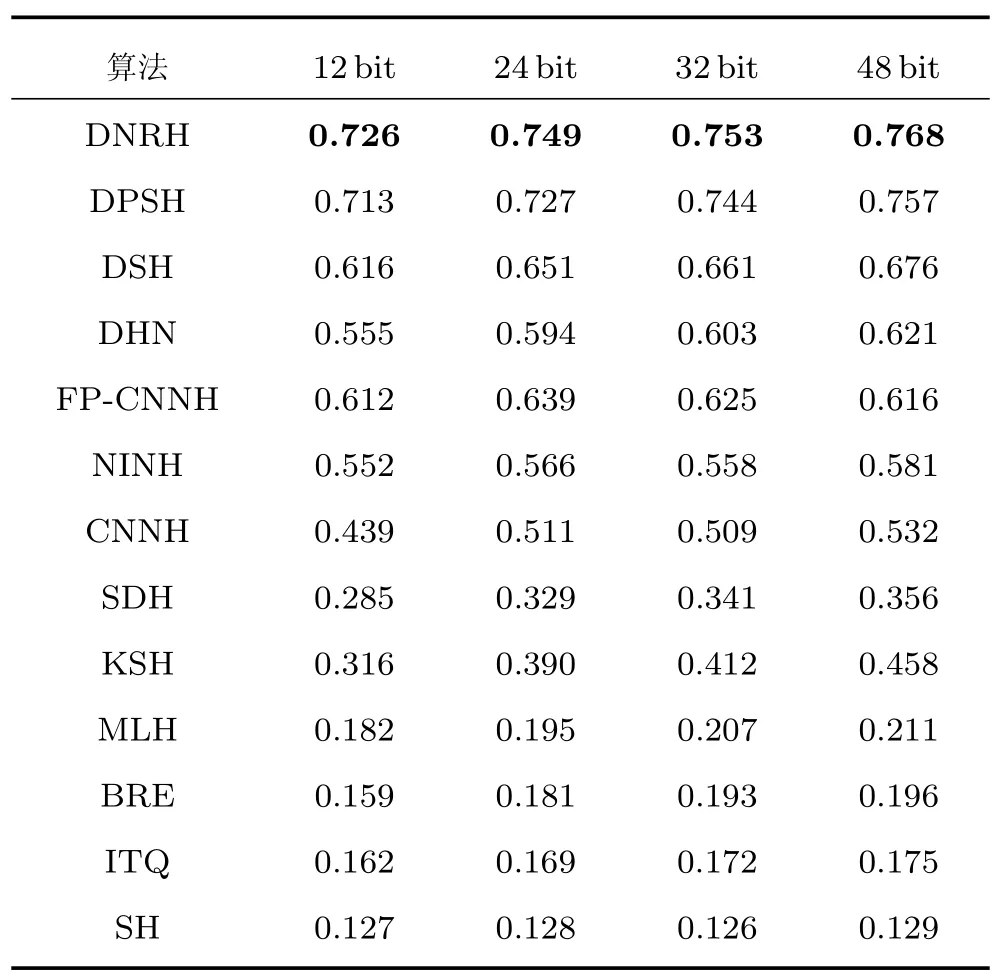
表1 各種算法在CIFAR-10 上的MAPTable 1 The MAP of different algorithms on CIFAR-10
NUS-WIDE 數據集的圖像相對于CIFAR-10數據集的圖像具有更高的像素,更完整的圖像細節,更貼近實際應用中的圖像.在NUS-WIDE 數據集中,一幅圖像可能包含多個標簽,在檢索過程中,只要檢索到的圖像與待檢索圖像包含有相同的標簽,就判定為正確檢索.表2 比較了在NUS-WIDE數據集上本文的DNRH 算法與現有的哈希學習算法在不同長度哈希碼上的平均準確率.由于NUSWIDE 數據集的圖像數量很大,在該數據集上,本文用每個測試樣本檢索返回的前5 000 個樣本計算MAP.在相同長度的哈希碼上,本文DNRH 算法在12 bit、24 bit、32 bit、48 bit 上的平均準確率分別為0.769、0.792、0.804、0.814,均高于其他的哈希學習算法,證明了本文的算法的普適性.其中,對于DPSH 算法,本文仍然使用在CIFAR-10 數據集上實驗的Lagrange 乘子η=10,并在各種算法使用相同的訓練集和測試集的設置下,在NUS-WIDE數據集上重新運行作者提供的代碼,計算其平均準確率.隨著哈希碼長度的增加,幾乎所有算法的平均檢索準確率都有一定程度的提高,尤其SDH 算法,48 bit 的哈希碼對應的平均準確率相對于12 bit 的哈希碼的平均準確率提高了近7%,表明更多的哈希位能夠表示更多的圖像特征,提高檢索準確率.
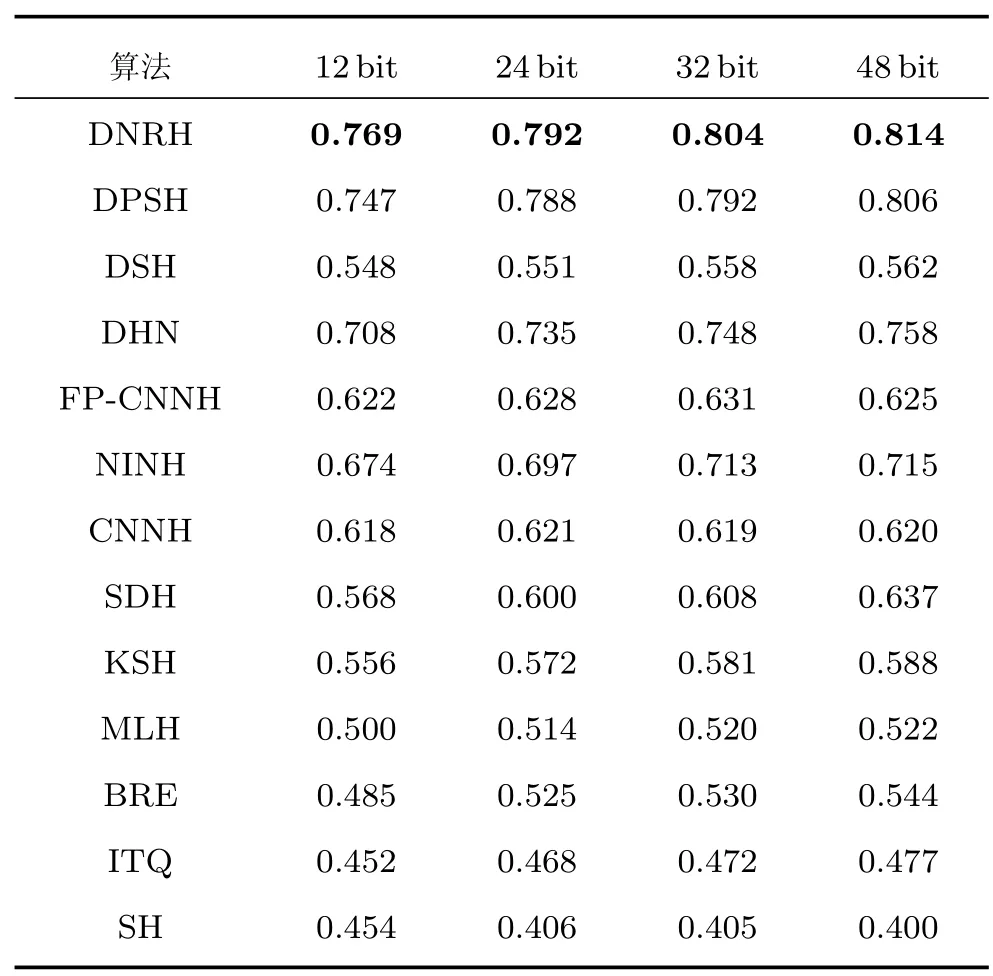
表2 各種算法在NUS-WIDE 上的MAPTable 2 The MAP of different algorithms on NUS-WIDE
3.2 ?1 范數和軟閾值函數的約束效果
在本文提出的DNRH 算法中,軟閾值函數的作用是在模型的前向計算中直接閾值化網絡輸出端的結果,而?1范數作為目標函數的正則項在模型的反向傳播中約束準哈希碼,使準哈希碼各個位的絕對值逼近1,這兩個模塊的作用均為約束準哈希碼.為了驗證聯合使用?1范數和軟閾值函數的約束性能,本文在CIFAR-10 數據集上分別對?1范數正則項獨立約束、軟閾值函數獨立約束以及?1范數和軟閾值函數聯合約束進行了實驗.
表3 列出了在4 種長度的哈希碼上,不同模型對應的平均準確率,其中,“交叉熵+軟閾值”表示使用式(5)的損失函數,并在網絡的輸出端使用軟閾值函數的模型,“交叉熵+?1范數”表示使用式(11)的損失函數,并略去約束條件,即在網絡的輸出端不使用軟閾值函數的模型,“交叉熵+?1范數+軟閾值”表示本文的DNRH 算法模型,即聯合使用?1范數和軟閾值函數.觀察表3 可知,“交叉熵+?1范數”和“交叉熵+軟閾值”這兩個模型的平均準確率明顯低于DPSH 算法,表明單獨使用?1范數和軟閾值函數的效果并不如以Lagrange 乘子松弛求解的DPSH 算法.而聯合使用?1范數和軟閾值函數(交叉熵+?1范數+軟閾值)在4 種長度哈希碼長度上,其MAP 相比于單獨使用其中一個模塊均提高了近10%,并且高于DPSH 算法.因此可得出結論,聯合使用?1范數和軟閾值函數能夠更好地約束哈希碼,提升算法性能.

表3 ?1 范數和軟閾值函數約束在CIFAR-10 上的MAPTable 3 The MAP of ?1-norm and soft threshold function constraint on CIFAR-10
3.3 參數影響的分析
3.3.1 正則項系數λ 對準哈希碼分布的影響
為了檢驗?1范數正則項對全連接層輸出的準哈希碼的約束能力,本文在CIFAR-10 數據集上對輸出的準哈希碼的分布情況進行了統計.統計準哈希碼中每一位的絕對值相對于1 的距離分別在區間[0,0.1),[0.1,0.2),[0.2,0.3),[0.3,0.4)的概率,如圖3 所示,不同顏色表示不同的分布區間,橫軸表示正則項系數λ,縱軸表示哈希位落在不同區間的概率.
從圖3 中準哈希碼各哈希位的分布情況可以看出,隨著λ 的增大,準哈希碼各哈希位的絕對值更集中靠近1,尤其在不使用?1范數(λ=0)約束的情況下,準哈希碼的哈希位在0~0.4 之間分布相對均勻,這樣在最后的量化過程中損失會增加,導致結果不準確.在目標函數中,語義保真項用于保持點對之間的相似性,?1范數正則項用于約束準哈希碼的分布,正則項系數λ 過大將過分增大?1范數正則項的比重,從而減小語義保真項的作用,影響分類效果.由此可以看出,適當的?1范數正則項對準哈希碼的分布有很好的約束作用.
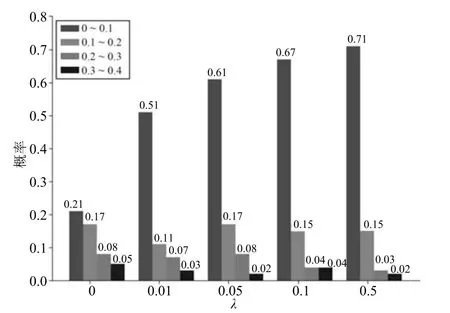
圖3 不同正則項系數λ 下準哈希碼的分布Fig.3 The distribution of hash code with different regularization coefficient λ
3.3.2 正則項系數λ 對準確率的影響
正則項系數λ 的取值,不僅影響模型輸出的準哈希碼各哈希位的分布,而且影響本文的DNRH 算法訓練模型的準確率.表4 給出了哈希碼的長度取48 時,在CIFAR-10和NUS-WIDE 數據集上λ 取不同值時的平均準確率.

表4 λ 的不同取值對應的MAPTable 4 The MAP on different λ
從表4 可以看出,在兩個數據集上λ 的取值對MAP 的影響分布相同.當λ=0.05 時,測試集上的檢索效果最好,λ 取值過小或過大都會對檢索的MAP 造成影響.分析其原因可知,λ 值過小,目標函數對準哈希碼分布的約束變弱,模型輸出的準哈希碼的部分哈希位將過度偏離-1 或1,造成最終量化為哈希碼時損失增大;λ 的取值過大將造成目標函數中語義保真項的比重減小,由于該約束項的作用是保持圖像之間的相似語義,減小該約束項的比重會造成相同類別之間的距離增大或者不同類別之間的距離減小,即圖像之間的相似性約束變弱,使得檢索效果變差.
3.3.3 軟閾值函數控制參數η 對準哈希碼分布的影響
為了驗證軟閾值函數對準哈希碼的閾值化效果,本文在NUS-WIDE 數據集上進行實驗,統計軟閾值函數控制參數η 取不同值時,模型輸出的準哈希碼的分布情況.同樣統計準哈希碼中每一位的絕對值相對于1 的距離分別在區間[0,0.1),[0.1,0.2),[0.2,0.3),[0.3,0.4)的概率,如圖4 所示,橫軸表示軟閾值函數控制參數η 的取值,縱軸表示哈希位落在不同區間的概率.

圖4 參數η 取不同值時準哈希碼的分布Fig.4 The distribution of hash code with different η
由圖4 可以看出,η 的取值越大,準哈希碼的各哈希位的越逼近1 或-1,尤其在η=20 時,準哈希碼誤差在0.1 以內的比例達到了90%,但是η 的取值過大也會帶來嚴重的問題,當η=20 時,在模型的訓練過程中,損失函數始終振蕩難以收斂,這是因為當η 取值過大時,軟閾值函數趨于不可導.為了在模型訓練中使損失平穩收斂,并且使準哈希碼絕對值逼近1,經過多次實驗,本文中η 的取值為12.
4 結論
本文提出了一種基于點對相似度的深度非松弛哈希學習算法,該算法通過CNN 自動提取圖像特征,在目標函數中使用交叉熵保持相似點對之間的語義相似性,在CNN 輸出端使用可導的軟閾值函數代替傳統方法中的符號函數,使準哈希碼非線性地接近-1 或1.并在損失函數中引入?1范數約束輸出的準哈希碼,使得準哈希碼逼近二值編碼.最終在訓練好的模型外部使用符號函數,將準哈希碼量化為二值哈希碼.在公開數據集(CIFAR-10、NUSWIDE)上的實驗驗證了本文提出的DNRH 算法優于其他哈希學習算法,取得了令人滿意的效果.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
