博弈搜索樹算法的實現(xiàn)及其優(yōu)化
2021-06-23 07:53:06周子龍
科學(xué)技術(shù)創(chuàng)新 2021年18期
周子龍
(同濟(jì)大學(xué) 軟件學(xué)院,上海201804)
1 概述
在一般的搜索過程中,總是會有一個限定的、有限的搜索內(nèi)容集。一般的搜索算法也僅僅限于在該固定集中進(jìn)行查找操作,返回是否查找成功,即待查找的元素是否屬于該集合。而在許多情境中,該類搜索并不能滿足用戶的全部需要,有時候,我們并不是搜索某一特定的元素,而是給出集合中最符合用戶需求的元素。這些元素并不是絕對確定的,當(dāng)一定是在某一些特定要求下,根據(jù)某種評估,所能在有限的搜索集合中給出最有元素;同時,搜索的集合可能在需要執(zhí)行搜索的時候還未產(chǎn)生,需要一邊搜索一邊動態(tài)的產(chǎn)生新的元素。一般地,我們把符合上述描述的搜索稱為動態(tài)博弈搜索。相較于普通搜索,博弈搜索的搜索集合并不是可以立即確定的,它可能需要根據(jù)不同局中人的不同行為生成不同元素進(jìn)行不斷補(bǔ)充;以及,該過程也涉及到多個參與者,即上文提到的多個局中人,每一局中人均假設(shè)為理性博弈者,即其所作出的任何行為均是符合一定標(biāo)準(zhǔn)下利益最大化原則。綜上,動態(tài)博弈搜索樹是一種對動態(tài)決策的過程模擬,它在搜索的過程中同時產(chǎn)生許多新的可能的結(jié)果,依據(jù)利益最大化原則,為每一為局中人進(jìn)行操作,搜索出來的最優(yōu)行為即應(yīng)當(dāng)滿足如下要求:通過該最優(yōu)行為,當(dāng)所有局中人按照自己利益最大化原則進(jìn)行后續(xù)行為后,該行為為己方帶來最大收益。
在理想情況下,總是認(rèn)為考慮到的情況越多越好,但計算機(jī)的算力總是有限的,在現(xiàn)實生活中,局中人的思考能力以及思考時間也是有限的,故搜索不能無限制的進(jìn)行下去,只可能在有限的搜索深度下,得到當(dāng)前局面的最優(yōu)行為。此外,不可否認(rèn)的是,以往的經(jīng)驗也會影響到局中人的決策。局中人總是會依據(jù)一定的經(jīng)驗進(jìn)行判斷,而不是每遇到一個局面就從新開始進(jìn)行判斷。據(jù)此,在算法中,我們可以考慮加入歷史數(shù)據(jù)庫,在每一次搜索做出判斷時,先行搜索歷史數(shù)據(jù),一起到一定的啟發(fā)作用。至此,我們的目標(biāo)便已經(jīng)明確:在一定的規(guī)則下,為一個指定的局中人產(chǎn)生根據(jù)特定判斷下,特定行為局?jǐn)?shù)后,能夠?qū)υ摼种腥俗顑?yōu)利的行為。后文中,主要分析了如下的幾種搜索算法:極大極小值搜索算法、負(fù)極大值搜索算法、Alpha-Beta 剪枝算法、結(jié)合Hash 表的Alpha-Beta 剪枝算法等。
2 算法及其優(yōu)化
2.1 極大極小搜索算法
2.1.1 基本思想
根據(jù)理性博弈人的基本假設(shè),為了簡化搜索邏輯,我們可以做出這樣的簡化:己方局中人在進(jìn)行判斷時,總是為自己選擇利益最大的行為,在模擬其它局中人判斷時,總是選擇使得己方局中人利益最小的行為。此時,整個的博弈過程為:輪到己方局中人行為時,進(jìn)行搜索,在當(dāng)前局面下所有可能的行為中選擇對己方局中人利益最大的一種行為。但在實際情況中,一次考慮總是遠(yuǎn)遠(yuǎn)不夠,在前文也提到了搜索深度的概念,故我們應(yīng)當(dāng)認(rèn)為,也應(yīng)該為其它局中人進(jìn)行模擬行為,并以此為己方局中人優(yōu)化決策。按照如上假設(shè)及搜索的基本思想,便是極大極小搜索,其基本思想如下:在每一次迭代中,為每一個局面生產(chǎn)所有可能的子局面,通過極大極小的原則,為不同的局中人選擇行為,在向上回溯的過程中,通過子局面的評估,給出父局面的評價。繼續(xù)向上回溯, 依次類推, 一直到當(dāng)前局面, 最終相對的最優(yōu)行為也就搜索出來了。如圖1 中:第一階段輪到藍(lán)方行為,藍(lán)方將選擇所有局面評估中對藍(lán)方最有利的一種(57),之后藍(lán)方將模擬紅方行為,并選擇對藍(lán)方評估最小的行為(19)。
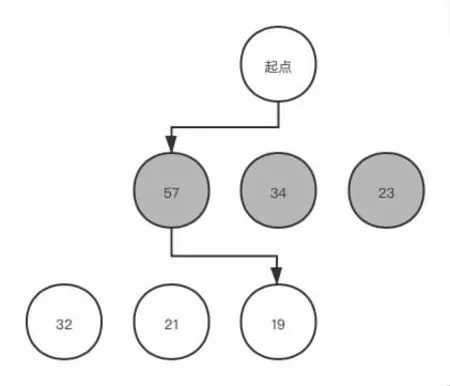
圖1
對這種極大極小過程的模擬,即是極大極小搜索算法。根據(jù)這種思想,Shannon 最先于1950 年提出該算法,從而奠定了整個博弈搜索的理論基礎(chǔ)。但在整個極大極小的過程,我們需要為不同的局中人執(zhí)行不同的操作,為己方取極大值,為另一方取極小值,為了消除這兩方面的差別,Kunth(1975)提出的負(fù)極大值算法通過將父節(jié)點的評估值設(shè)定為所有子節(jié)點的負(fù)數(shù)的極大值,從而達(dá)到為雙方取相同的操作,使得算法更加簡潔,但由于其原理于極大極小搜索算法完全等效,故本文不再給出其具體實現(xiàn)。
2.1.2 性能分析
在某一深度D 下,所有可能的行為數(shù)N 對于任何局中人來說應(yīng)當(dāng)認(rèn)為是相近的。每一次生成所有走法涉及到N 次操作,對于每一次評估操作,不妨設(shè)其時間復(fù)雜度為o(E),執(zhí)行和撤銷所有行為可以認(rèn)為其時間復(fù)雜度為o(ND),則該算法具體的時間復(fù)雜度為o(END)。
在每一局面中,均為所有可能的行為生成了相應(yīng)行為棧進(jìn)行存貯,棧的大小大致于所有可能的行為數(shù)相當(dāng),則空間復(fù)雜度應(yīng)為o(ND)。不難看出,該算法的執(zhí)行時間復(fù)雜度以及空間復(fù)雜度均隨著搜索深度指數(shù)增長,在具體的博弈過程中是亟待優(yōu)化的。
2.2 Alpha-Beta 搜索算法
2.2.1 基本思想
針對極大極小搜索算法巨大的時間空間消耗,進(jìn)一步分析其搜索過程,不難發(fā)現(xiàn)有許多搜索是無用的。其中存在著兩種明顯的冗余計算。第一種是極大值冗余現(xiàn)象。考慮這樣一種情況:假定在某一次搜索中父節(jié)點A 的評估值為子節(jié)點B、C 中的較大者。現(xiàn)子節(jié)點B 已經(jīng)全部搜索完畢,程序開始搜索子節(jié)點C。根據(jù)極大極小原理,子節(jié)點C 的評估值應(yīng)為其全部子節(jié)點中的最小值,在搜索C 的子節(jié)點C1 時,已經(jīng)得到C1 的評估值小于B 節(jié)點的評估值,那么,對于C 節(jié)點余下的子節(jié)點便失去了搜索的必要。這是因為C 節(jié)點是選擇其子節(jié)點最小值,并最小值不會大于C1 的值,故C 節(jié)點的值不會大于C1,又因C1 小于B,因而得出B 必定大于C,所以C 節(jié)點的估值在此時便可以判定不會影響父節(jié)點A 的評估。故而C 節(jié)點接下來的搜索便是多余的。
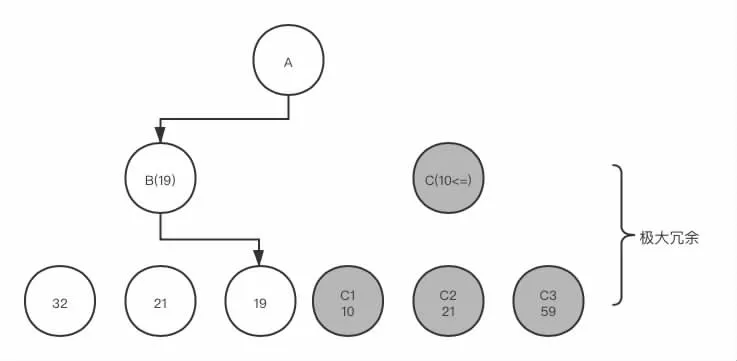
圖2
類似的,第二種情況便是極小值冗余現(xiàn)象。現(xiàn)在考慮相反的情況:當(dāng)父節(jié)點A 要取子節(jié)點中最小值,此時子節(jié)點B 已經(jīng)搜索完畢得到估值,程序開始繼續(xù)搜索子節(jié)點C,而C 節(jié)點應(yīng)為其子節(jié)點中的最大值,這時,倘若C 的某一個子節(jié)點C1 的估值大于B 節(jié)點,類似的,可以得出C 節(jié)點的余下子節(jié)點的估值便對父節(jié)點A 的評估沒有任何貢獻(xiàn)。
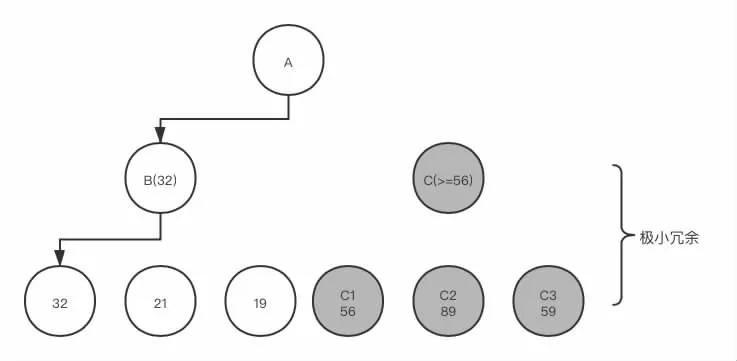
圖3
我們稱第一種冗余為極大冗余,對應(yīng)的,當(dāng)發(fā)現(xiàn)產(chǎn)生這種情況時便對這些多余的搜索分支進(jìn)行修剪,稱為Alpha 剪枝。對第二種優(yōu)化稱為Beta 剪枝。將這兩種優(yōu)化方案運(yùn)用到極大極小搜索算法中便構(gòu)成了Alpha-Beta 搜索算法。其具體的實現(xiàn)為:在每一次搜索過程中,記錄搜索極大值的節(jié)點的當(dāng)前最優(yōu)值為α,搜索極小值的節(jié)點的當(dāng)前最值為β。在每一次搜索開始時,將α,β 分別設(shè)置為機(jī)器最小值和機(jī)器最大值。這樣,在搜索的過程中間便能使得α,β 構(gòu)成一個窗口,從而跳過沒有落在這個窗口的子節(jié)點的搜索分支,達(dá)到減少搜索次數(shù)的優(yōu)化目的。
其總的行為流程圖如下:
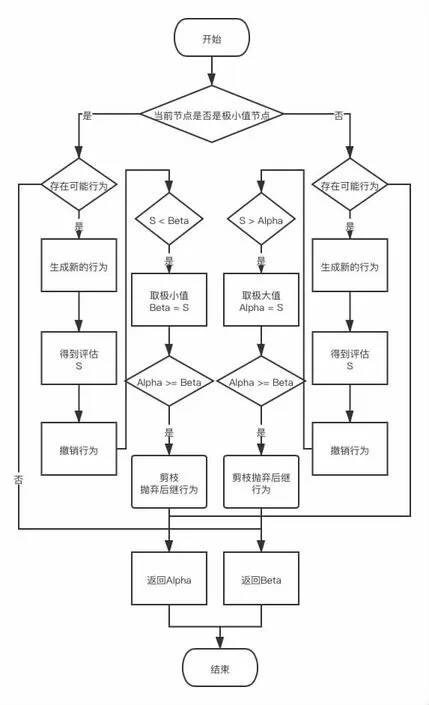
圖4
2.2.2 Alpha-Beta 性能分析
根據(jù)Kunth 等人的證明,在子節(jié)點排列最理想的情況下,即搜索到的第一個子節(jié)點估值就不落在[α,β] 窗口內(nèi)內(nèi),使用Aplha-Beta 搜索D 層生成的節(jié)點數(shù)目N 為
ND= 2bD/2-1 ( D 為偶數(shù))
ND= b(D+1)/2+b(D-1)/2-1 ( D 為奇數(shù))
這樣,時間復(fù)雜度降到了約極大極小搜索算法1/2 倍,為o(END/2)。
2.3 對上述搜索策略的優(yōu)化
通過Alpha-Beta 剪枝過后,我們極大的優(yōu)化了搜索次數(shù),但從Kunth 等人的假設(shè)也不難看出,真正優(yōu)化程度于節(jié)點的排列序列高度相關(guān)。由于Alpha-Beta 剪枝對中體的子節(jié)點排序,即當(dāng)前局面的下一步的行為高度相關(guān),那么,如果能夠粗略的對當(dāng)前局面產(chǎn)生的所有可能的行為有一個判斷,以便能更快地縮小[α,β]的范圍,從而產(chǎn)生更多的剪枝。這就涉及到了關(guān)于行為排序的思想。其次,在之前的多次索索中,難免會出現(xiàn)許多重復(fù)估值的現(xiàn)象,即可能通過不同的行為順序達(dá)到同一局面,這也會造成時間上的浪費(fèi),故可在搜索是建立歷史數(shù)據(jù)庫,以期之后遇到重復(fù)局面時能夠減小評估開銷,從而降低時間復(fù)雜度。這便是結(jié)合歷史經(jīng)驗進(jìn)行判斷的思想。
2.3.1 行為排序
為了進(jìn)行行為排序,我們需要對當(dāng)前局面進(jìn)行大致判斷,將當(dāng)前局面看似最無意義的行為放在搜索的后面,將可能產(chǎn)生最優(yōu)解的行為放在前面進(jìn)行搜索。這便十分依賴于博弈者所面臨的具體博弈的條件,下面僅僅以中國象棋為例,簡要闡明該思想。岳金朋(2008)在討論針對中國象棋的優(yōu)化中提出了一種靜態(tài)評價的啟發(fā),他將行為分為了吃子行為和非吃子行為。在吃子行為中,通過簡單的對被吃子是否有其它棋子保護(hù),而導(dǎo)致吃子后我方棋子可能被吃來對每一吃子行為進(jìn)行排序。簡而言之,他將被吃子的分?jǐn)?shù)減去我方行為完后可能被吃子的分?jǐn)?shù)作為判斷依據(jù)進(jìn)行排序。對與非吃子行為,岳金朋提出可以首先生成車的行為,最后生成帥的行為,在生成車的行為中,先考慮向前走的行為,后考慮向后走的行為,也可以起到一定的排序選擇作用。
2.3.2 歷史啟發(fā)
由于歷史啟發(fā)策略需要用到歷史數(shù)據(jù)庫,對每一個歷史局面進(jìn)行保存。Zobrist(1970)提出了一種根據(jù)目前局面的所應(yīng)方法,經(jīng)過驗證,該方法在搜索局面時十分高效。Zobrist 的具體方法是,對于每一個局面而言,其唯一的標(biāo)示就是當(dāng)前所有狀態(tài)的異或值。同時,Zobrist 提出,在所有的博弈搜索算法中,層次更深的搜索往往意味著更加穩(wěn)健的評估,故對于每一個歷史局面的保存應(yīng)該考慮到該局面的搜索深度。進(jìn)而結(jié)合上文提到的行為排序的思想,我們也應(yīng)當(dāng)考慮某一局面能夠引發(fā)的剪枝數(shù)量,一般而言,如果在同一層次的搜索中,如果能夠?qū)⒛軌蛞l(fā)剪枝數(shù)量更多的行為先行搜索,也可以極大的優(yōu)化算法的時間復(fù)雜度,因此,我們也應(yīng)該保存某一行為所能引發(fā)的剪枝數(shù)量。在Zobrist 的局面表示方法下,我們以此生成Hash 表進(jìn)行存儲每一個局面的具體信息。具體的Hash 表的實現(xiàn)原理于此不過多贅述,參見參考文獻(xiàn)[6]。具體而言,假設(shè)現(xiàn)在要對某一局面進(jìn)行d 層搜索,當(dāng)前窗口是[α,β],而通過上述方法發(fā)現(xiàn)歷史中該局面已經(jīng)存在,評價為v,類型為t,經(jīng)過了d’層搜索。如果t 為精確型估值,即在歷史中的搜索該局面沒有因為剪枝而放棄搜索,便可以直接返回v 而代替索索。如果t 為模糊型,則判定是否高過邊界,從而判斷是否可以直接引發(fā)剪枝。
2.4 淺層搜索優(yōu)化策略
與Shell 對插入排序算法的優(yōu)化類似,Krof(1985)也提出了對Alpha-Beta 搜索算法的一種可能的優(yōu)化方案。Krof 的基本思想是,在生成走法時,先進(jìn)行較為初級的淺層搜索,在上文中對Alpha-Beta 搜索算法的性能分析中我們不難看出,搜索復(fù)雜度伴隨著搜索層次成指數(shù)級增加。對于一個D 層的搜索而言,(D-2)層的搜索的復(fù)雜度完全與其不在一個數(shù)量級上。倘若在搜索生成走法前,先通過一個d 層的淺層搜索來對所有行為進(jìn)行排序,那么,那些在淺層搜索中的較優(yōu)行為就將在深層搜索中較前被嘗試,從而得到更高的剪枝效率。
2.5 本文提出的優(yōu)化方案——偽搜索策略
上述的諸多改進(jìn)全部是基于既定時間內(nèi)盡可能搜索多的深度,以深度提高程序的智能程度。然而,上述改進(jìn)全部是基于搜索前的改進(jìn),這可以極大的減少搜索量級,以換取更多的搜索時間。不過,本文在實際中發(fā)現(xiàn),在同一搜索量集中,不同搜索次數(shù)并不會很大的影響搜索時間,如共執(zhí)行N 次搜索和執(zhí)行2N 次搜索時間開銷并不大。但后者無疑進(jìn)行了更多次的搜索,在表現(xiàn)上理應(yīng)更加高效。因此,倘若在所有搜索結(jié)束,再進(jìn)行一些淺層的判斷,對程序的表現(xiàn)無疑是有益處的。設(shè)初始量級為N,每層生成M 個行為,共搜索D 層,則有:N=MD。若對第D 層行為進(jìn)行復(fù)雜度為P 的淺層判斷,則總共的量級N'應(yīng)有:
N'=N+M×P
其中:M×P<<N
故對總的程序無顯著影響,而判斷次數(shù)更高,可以獲得更好的表現(xiàn)。
3 測試
至此,我們完成了對整個博弈搜索過程的優(yōu)化。由于本文并不針對任何一種博弈過程,只是提出針對博弈搜索過程的算法及其優(yōu)化,無法進(jìn)行具體的性能分析,下文將以中國象棋為例,討論優(yōu)化的具體效果。在基于挑夾棋游戲規(guī)則進(jìn)行以類似本文2.2 的Alpha-Beta 搜索和通過2.3.1 行為排序進(jìn)行優(yōu)化后的算法進(jìn)行比較,得到如下結(jié)果:
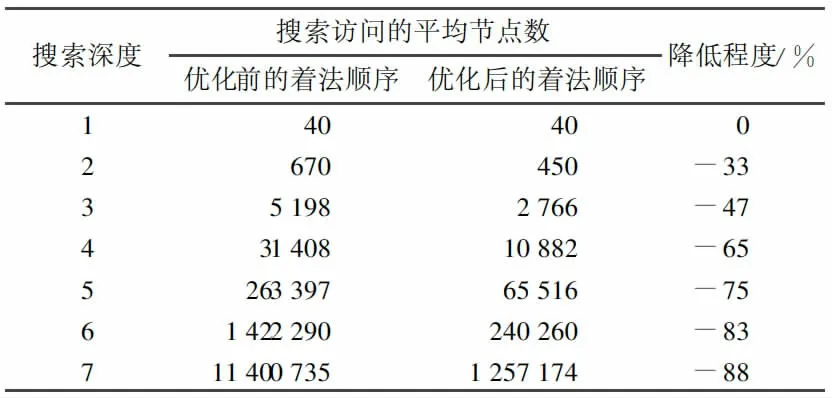
表1
通過2.4 淺層搜索優(yōu)化,與普通的Alpha-Beta 搜索進(jìn)行比較,得到如下結(jié)果:
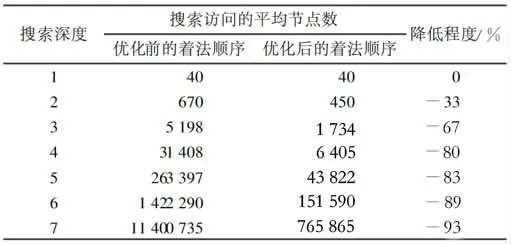
表2
猜你喜歡
兒童時代·幸福寶寶(2022年12期)2022-12-09 11:24:14
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2022年11期)2022-02-14 07:14:12
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年12期)2021-03-08 01:28:50
科普童話·學(xué)霸日記(2020年1期)2020-05-08 16:45:11
小天使·一年級語數(shù)英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
