融合上下文語義信息的漢越平行短語對抽取方法
2021-06-24 03:14:18高盛祥余正濤朱浩東文永華
云南民族大學學報(自然科學版) 2021年3期
楊 艦,高盛祥,余正濤,朱浩東,文永華
(1.昆明理工大學 信息工程與自動化學院,云南 昆明 650500; 2.昆明理工大學 云南省人工智能重點實驗室,云南 昆明 650500)
自然處理應用依賴于大規模的平行語料庫,而這種平行語料僅可用于少數幾種語言,比如英語、中文、少數歐洲語言等,對于大多數其他語言,并行數據實際上是稀缺的.可比語料作為一種豐富型資源,為數據稀疏性問題提供了一種可能的解決方案.雖然在2個可比較的文檔之間很少有句子級平行的情況,但是在可比較的語料庫中仍然存在潛在的大量并行短語,從可比語料中抽取平行短語對能緩解資源匱乏的語言數據稀疏性問題.
隨著互聯網的快速發展,網絡上存在大量的漢越可比語料資源,如維基百科的漢越對照頁面,雙語新聞網站等,這些新聞都是對同一事件進行描述,但并不是完全對齊的雙語文本.從這些雙語文本能很好的提取雙語知識,主要的提取任務有雙語詞典抽取,其主要是基于WordNet的語義相似性度量的使用,它可以消除翻譯后的上下文向量的歧義,然后通過種子字典構建2種語言之間的雙語詞典,這個方法的關鍵是種子字典,它在影響精度方面起著重要作用[1].如雙語短語對抽取,Zhang等使用SVM來從可比語料中抽取平行短語對,但是該方法需要人工設計短語特征,如:短語長度差、短語單詞數目等等,非常耗費人力和資源[2].近年來,隨著將詞使用分布式表示方法得到低維向量表示取得了較好的效果,越來越多的研究人員開始研究更大語言單元的分布式表示問題,尤其是短語[3],是由詞組成,但粒度又比句子小,如Mikolov等人將短語視為不可分的n-gram[4],Socher等提出了遞歸自編碼器來學習短語表示[5-8].然而上述的短語表示很少考慮融入上下文語義信息,使得短語表示脫離了句子語義本身,抽取出的短語準確率不高,因此本文提出融合上下文語義信息的漢越平行短語對抽取方法,主要利用注意力機制將句子編碼向量融入到短語向量中,本文為了學習雙語短語表示,引入半監督自編碼器,如下圖1所示,利用平行短語對作為約束條件,誘導性的學習雙語短語表示,在本文提出的方法中有效避免了構建SVM分類器模型需要使用的特征選擇過程,也引入了上下文語義信息和雙語短語對的約束條件來學習雙語短語向量表示.
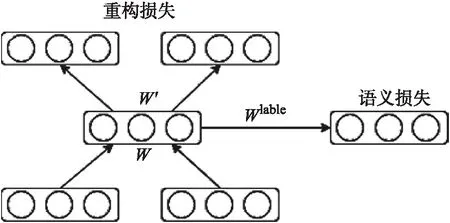
圖1 半監督自編碼器
文中的主要貢獻有以下2個方面:(1)融合上下文語義信息到短語表示中;(2)學習雙語短語向量表示的預訓練編碼器.
1 相關工作
可比語料作為豐富型的語料資源,為數據稀疏性問題提供了一種很好的解決方案,早期對可比語料庫的許多嘗試都集中在學習雙語單詞翻譯,這些嘗試的基本假設是基于單詞及其翻譯在相應的語言中以相似的上下文出現,因此可以使用共現統計來檢測它們;Munteanu等首次提出了從可比句子中檢測亞句片段[9].
目前,從可比語料庫中抽取平行短語對的方法主要有以下幾種方法:(1)SVM分類器,Zhang等提出將短語提取作為分類任務,首先在平行語料庫中通過GIZA++生成所有可能的短語對,將平行短語對設置為正例,然后把非平行的短語設置為負例;然后,人工設計短語對特征,如短語長度差、相同起始、相同結尾、短語中單詞數目等;最后,構建SVM分類器以判斷短語對是否平行[10-11].(2)模板方法,Santanu Pal等人通過定義模板方法抽取短語對來提升英語-孟加拉語機器翻譯的性能.首先,使用文本蘊含方法將雙語可比語料庫的兩側分為幾組;然后,使用概率雙語詞典的n-best列表在組之間建立了跨語言鏈接;最后,在每個對齊的組之間使用了基于模板的短語提取技術[12].Hewavitharana S等從可比句子對中,繞過非平行片段,只對齊平行片段,抽取雙語平行短語,融合到統計機器翻譯中,解決數據稀疏的問題[13];(3)短語樹對齊,Zhan等[14]提出了一種利用解析技術和詞對齊方法從漢英雙語語料庫中提取短語翻譯對的新方法.
在上述方法中,基本上是利用短語的特征來提出算法和分類器等,而實際上,上下文語義信息對于短語的定位、切割有很重要的支撐作用,同時,表示學習方法能夠有效的學習到短語本身的特征.因此,本文提出融合上下文語義信息的漢越平行短語對抽取方法,來從可比語料中抽取平行短語對,緩解漢越數據稀疏的問題.
2 融合上下文語義信息的漢越平行短語對抽取模型
考慮到上下文語義信息會對平行短語對抽取產生影響,本文提出的融合上下文語義信息的漢越平行句對抽取模型,主要基于兩部分組成:預訓練模型和分類器模型.對于預訓練模型,其主要目的是預訓練出編碼器,通過注意力機制將句子編碼信息融入到短語中,同時,利用平行短語對約束學習漢越雙語短語表示,如下圖2(A)所示.分類器模型則主要是由編碼器和全連接層組成,如下圖2(B)所示.
其中源語言句子A和目標語言句子B代表漢越平行句對,源語言短語X和目標語言短語Y分別表示A,B句子中利用工具抽取到的漢語短語集合及越南語短語集合.圖2(A)左邊輸入為漢語句子和漢語短語,輸出的X1是帶有上下文語義信息的漢語短語,右半部分輸入為越南語句子和越南語短語,輸出的Y1是帶有上下文語義信息的越南語短語,這個過程為自編碼,其中損失稱為重構損失.為了使漢語、越南語訓練的短語向量相關聯,采取訓練雙語詞向量的方法訓練雙語短語向量,讓漢、越短語向量在空間中靠近,目的是把學習到的漢、越短語編碼器用作分類器.如圖2(B)中所示,把編碼器學習到的參數用到分類器中再進行微調以得到效果最優的分類器,其中源語言句子C和目標語言句子D代表可比句子,源語言短語M和目標語言短語N代表C,D句子中的漢、越短語.
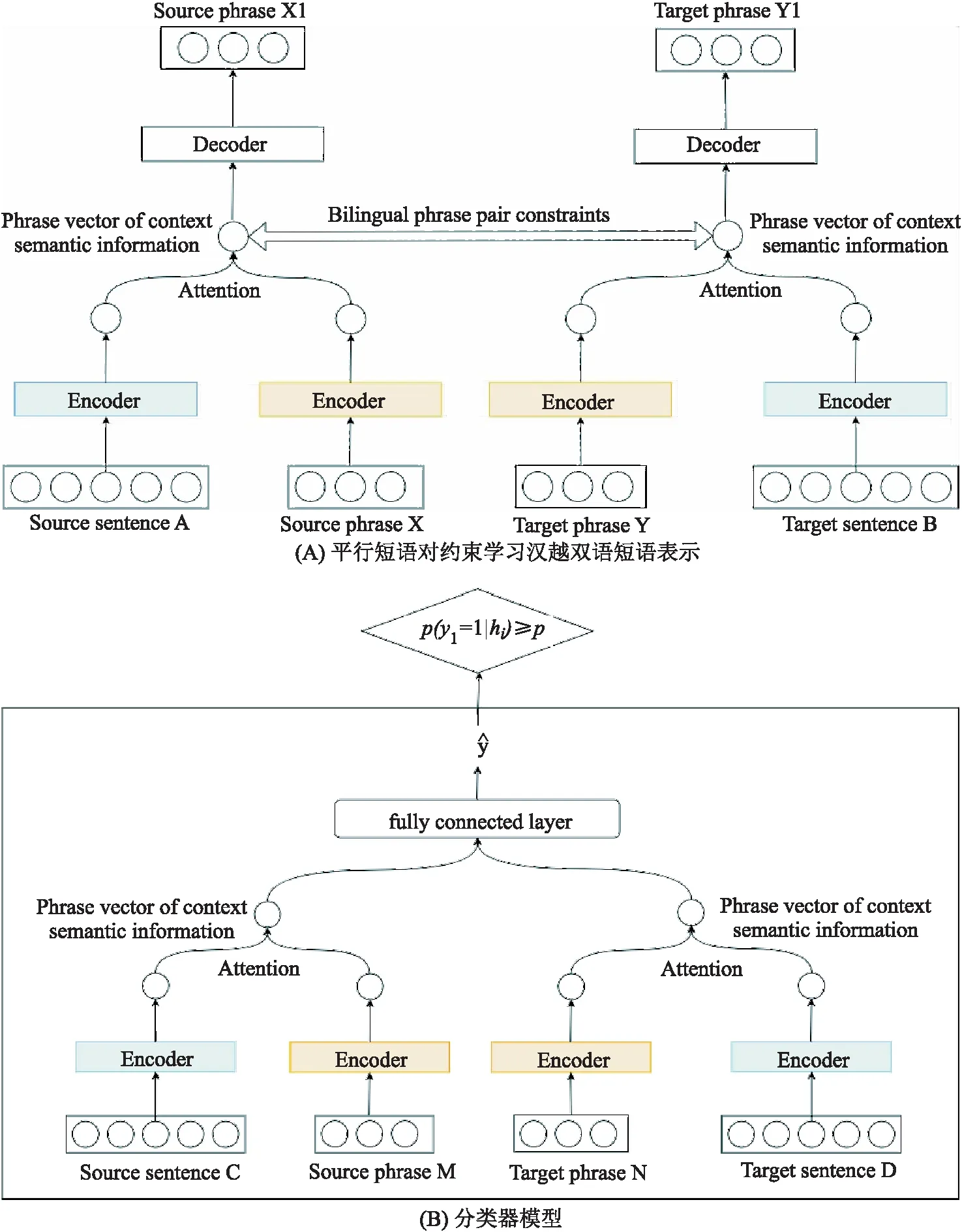
圖2 模型架構
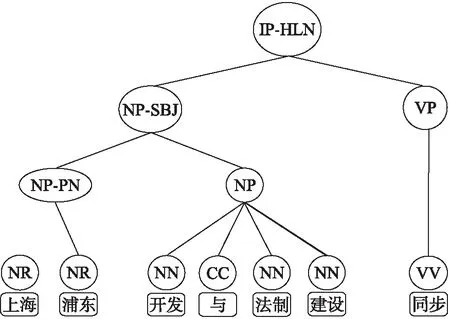
圖3 漢語短語結構樹
2.1 漢、越單語短語抽取
在本小節中,將從漢越可比語料中抽取漢語、越南語的短語集合,以便模型從中抽取出平行短語對,對于漢語和越南語的短語抽取,先利用偽平行句對抽取模型方式從可比語料中得到可比句子,將可比句子轉化為短語結構樹的形式[15-16],然后根據短語結構樹中的結點來獲取短語.漢、越單語短語抽取方法一致,以中文為例,如下圖3所示.
具體描述如下:
1) 利用斯坦福工具可以將句子轉化為Tree結構.
2) 對Tree結構進行遍歷,對于本文來說,只需將葉子節點以及相應的父結點取出來,如NP-PN,NP等.
3) 對于每個父結點可認為是句子中的一個短語,再利用短語中包含的單詞個數進行二次篩選.
4) 最后得到了漢語短語集合和越南語短語集合.
2.2 融合上下文語義信息的預訓練模型
本文的預訓練模型主要利用上下文信息和雙語短語對作為約束訓練出漢、越編碼器.模型的實現主要是基于半監督自編碼.從上圖2(A)可看出,本文通過平行句對以及其包含的短語對作為訓練語料,在編碼層通過LSTM模型獲取短語和句子特征,經過注意力機制把獲取到的特征融入到短語表示中,使其帶有一定的上下文語義信息.對于給定長度為m個詞組成的句子x={x1,x2,…,xm},LSTM編碼得到的隱含向量ht在時間步為t時刻的更新公式如下所示:
ht=f(xt,ht-1),
(1)
其中,xt表示第t個詞,ht-1表示t-1時刻的隱含向量,通過逐詞編碼,生成句子語義向量h,同理,可以得到短語編碼向量.為了獲取最終包含上下文語義信息的短語向量表示c,通過注意力機制將句子編碼向量h和短語每個時刻的隱狀態hj=(h1,h2,…,hn)進行結合,如下公式所示:
(2)
(3)
et,j=a(st-1,hj),
(4)
其中,et,j表示的是句子編碼向量和短語中的對應關系,at,j則代表所占權重大小.a是匹配函數,其目的是計算該時刻兩個隱層狀態的匹配程度.其具體實現有多種方法,本文中采用點乘法.在解碼層同樣使用LSTM進行解碼,引入注意力機制后t時刻詞的產生概率公式如下所示:
st=f(st-1,yt-1,ct),
(5)
(6)

定義重構損失為Erec,其中s是源短語的向量列表,s′是目標短語的向量列表,si表示短語中的每一個詞,如下公式所示:
(7)
因此,漢越雙語短語對可以用(s,t)表示,θ為參數,分別學習到的向量特征代表源語言及目標語言短語對的約束程度:
Erec(s,t;θ)=Erec(s;θ)+Erec(t;θ).
(8)
為了學習到雙語短語表示,本文將平行短語對作為約束條件,目的是使得源語言的短語語義表示和目標語言的短語語義表示距離最小化,由于兩種語言的詞嵌入是分別單獨學習的并且位于不同的向量空間中,因此假設兩個語義嵌入空間之間存在轉換矩陣w,則雙語短語語義損失為Esem(s,t;θ),如下式所示:
Esem(s,t;θ)=Esem(s|t;θ)+Esem(t|s;θ).
(9)
用ps表示源短語s的向量特征,對語義損失作以下變換,首先將轉換矩陣w*pt,添加偏置項b,激活函數使用f=tanh激活函數,最后,我們計算它們的歐幾里得距離為:
(10)
Esem(s|t;θ) 可以使用相同的方式計算.
由于公式9只計算了語義的正向誤差,所以為了增強語義錯誤使用了正反兩個例子,即相應的最大語義邊際誤差變為
(11)
2.3 融合上下文語義信息的漢越短語對分類器
本文的短語對分類器模型主要是通過少量語料,對預訓練好的編碼器進行微調,對含有上下文語義信息的漢越短語向量輸入到全連接層中進行Softmax分類,用來判斷任意的漢、越短語是否為平行短語對,首先對短語對進行點乘和相減得到包含下文語義信息的短語向量表示c,然后分別與權重矩陣Wa及Wb點乘使之處于同一向量空間,加上偏置項b后使用激活函數tanh得到隱狀態hi,最后計算出短語對的概率p,σ代表sigmoid激活函數,公式如下所示:
(12)
(13)
(14)
p(yi)=σ(Wchi+c).
(15)
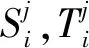
E(s,t;θ)=αErec(s,t;θ)+(1-α)Esem(s,t;θ).
(16)
超參數α代表了重構損失和語義損失的占比程度,模型在訓練集中要達到的最終目是:
(17)
本文的分類器的損失函數應為:
(18)
3 實驗與分析

表1 語料統計表

表2 實驗語料

表3 實驗設置
3.1 實驗數據
為驗證本文提出融合上下文語義信息的漢越平行短語對抽取方法的效果,本文的實驗數據規模如下表1所示,主要包含漢越平行語料和漢越可比語料.對于漢越平行語料,主要是利用GIZA++和一致性短語算法,獲取的平行短語對作為正例,非平行短語對作為負例.對于漢越可比語料,先得到可比語料中的可比句子,然后利用短語樹,得到句子中的短語集合.
本文模型的實驗設置如下表3所示.
實驗中采用了基于SVM的分類器[2]模型、自編碼器Auto Encoder訓練的分類器模型和融合短語對的半監督自編碼器Semi-AutoEncoder模型與本文模型在漢越短語對抽取效果上進行比較.其中SVM的參數設置及分類特征選擇引用Munteanu[9]的方法.Auto Encoder選擇tensorflow1.14版本,使用gpu,latent_size設置為128,batch_size設置為512,test_batch_size設置為256,training_epochs設置為50,神經網絡層數3層.Semi-AutoEncoder其參數training_epoches設置為100,drop_out設置為0.5,word_ebd_dims設置為300,dev_batch_size設置為50.
3.2 評測指標
為了驗證方法的有效性,本文采用準確率(Precision)、召回率(Recall)、F值(F-Measure)作為評測指標.計算公式如下:
(18)
(19)
(20)
3.3 實驗結果與分析
實驗1漢越短語對抽取實驗對比
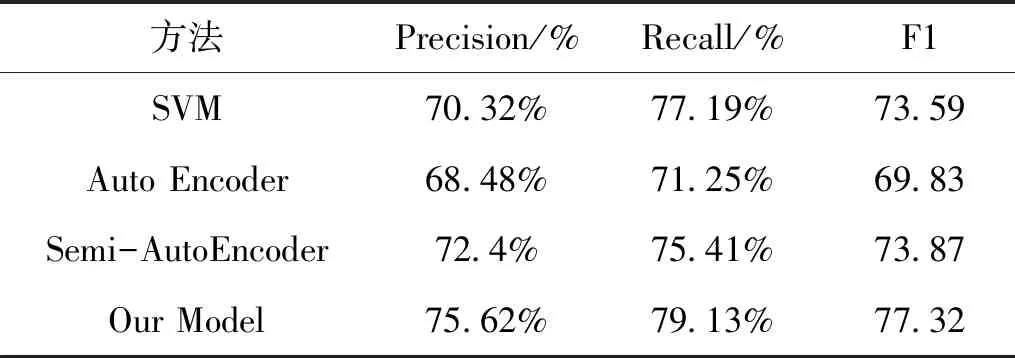
表4 漢越短語對抽取實驗對比
從表4實驗結果可以看出,對比SVM和AutoEncoder模型可知,將漢、越短語向量分別訓練效果不是很好,而當添加了短語對作為Semi-AutoEncoder約束,其準確度超過了基于SVM的分類器,同時,也可以看出本文提出融合上下文語義信息的漢越平行句對抽取模型,其準確率達到了75.62%,召回率為79.13%,相比于其他模型來說,都有所提升.說明融入了上下文語義信息的句子對分類器模型準確地更高更好.

實驗2短語對融入Moses系統前后Blue值對比
同時,為了檢測本文從可比語料中抽取的平行短語對能否提升翻譯性能,本文搭建了Moses翻譯系統,在數據清洗時將長語句與空語句刪除,詞對齊使用GIZA++訓練,語言模型訓練使用IRSTLM,最后對pharse-table和reordering-table進行優化加快速度,首先用漢越平行語料訓練得到基線的Blue值,然后將本文抽取的平行短語對添加到訓練數據中觀察Blue值的提升.性能評估使用BLEU值,實驗結果如表5所示:

表5 融合短語對的機器翻譯
從表5可以看出,當增加從可比語料中抽取的平行句對為200 k時,其BLEU增加了0.48,短語對增加為500 k時,BLUE值增加為0.93.從中我們可以看出,抽取的平行短語對能夠有效提高機器翻譯的性能.而隨著增加更多的平行短語對,性能會更優.因此,從可比語料中抽取知識是一種能夠有效解決數據稀缺型問題.
實驗3融入短語對后的譯文示例
表6給出的是基線系統與本文提出的加入抽取短語對后的翻譯對比示例.
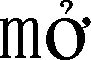

4 結語
本文為了解決稀缺型數據稀缺的問題,利用可比語料作為豐富型資源的特點,提出融合上下文語義信息的平行短語對抽取方法,從可比語料中抽取平行短語對,該方法主要考慮句子能為短語提供上下文信息以及平行短語對作為半監督的約束條件,可以預訓練出編碼器,通過預訓練的編碼器很容易訓練出漢越雙語平行短語對分類器,實驗結果表明,本文方法相比傳統的手工設計特征的基于SVM分類器方法性能有所提升,同時將本文方法用于抽取平行短語對應用于Moses系統中,也提高了翻譯性能.在接下來的工作中,探索將抽取的平行短語對融入到端到端的神經機器翻譯.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
核科學與工程(2015年4期)2015-09-26 11:59:03
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
外語學刊(2011年1期)2011-01-22 03:38:33
