一種嵌入鐵電晶體管內容尋址存儲器的高能效浮點運算結構
2021-06-24 09:40:30盧旭東龐展曦陳闖濤尹勛釗
電子與信息學報 2021年6期
張 力 高 迪 陳 爍 盧旭東 龐展曦陳闖濤 尹勛釗 卓 成*②
①(浙江大學信息與電子工程學院 杭州 310007)
②(浙江大學國際聯創中心 海寧 314400)
1 引言
隨著大數據時代的到來,計算系統中的數據搬移問題成為熱門話題,馮·諾依曼架構下的計算和存儲分離,成為制約系統能效的一大瓶頸[1]。將數據從動態隨機存取存儲器(Dynamic Random Access Memory, DRAM)、Flash之類的存儲器搬移出來造成的能耗和延遲,與數據在浮點運算單元(Floating Point Unit, FPU)中運算的能耗和延遲相比,要高出3個數量級以上,這就是所謂的“內存墻”問題[2]。考慮到數據密集型應用的日益增多,研究者在不斷地尋找各種方法來緩解甚至消除“內存墻”瓶頸。
在這些研究中,三元內容尋址存儲器(Ternary Content Addressable Memory, TCAM)受到了很大的關注,它的工作原理是將輸入與多個存儲單元的內容并行地進行比較,然后返回匹配到的數據地址[2]。TCAM作為一種特殊的內存計算形式,可以預先存儲使用較頻繁的數據和對應的計算結果,從而減少實際運算執行的次數,達到節約能耗的目的。由于其高并行性和在內存中進行計算的特性,它被認為是數據密集型應用的一種高效解決方案[1,2]。然而,仍然存在兩個關鍵的挑戰,阻礙了TCAM在實際應用中的進一步推廣[2,3]:(1)如何在普通的FPU中部署TCAM,在不產生額外成本的條件下,充分地利用TCAM的優勢?(2)如何解決傳統的基于互補金屬氧化物半導體(Complementary Metal Oxide Semiconductor, CMOS)靜態隨機存儲器(Static Random-Access Memory, SRAM)的TCAM不菲的能量和面積消耗?
為了解決CMOS SRAM的高消耗問題,研究者提出了使用新型的非易失性存儲器,如可變電阻型隨機存儲器(Resistive Random Access Memory,ReRAM)[3],來實現TCAM的方案。例如文獻[3—5]研究了各種ReRAM TCAM結構以及它們用于FPU計算的使用方案。雖然這些設計相比傳統CMOS SRAM提高了一定的內存密度,但它們仍然受限于器件的RON/ROFF,搜索和寫入功耗較高[3,6,7]。鐵電場效應晶體管(Ferroelectric Field Effect Transistor, FeFET)是另一個比較有前景的非易失性存儲器TCAM設計方向,它具有更低的能耗、延遲和面積[6—9]。文獻[6]提出了一種基于4T-2FeFET單元的TCAM,獲得了比之前其它非易失性存儲器和CMOS存儲器都高的能效。然而,由于使用了4個CMOS晶體管,該TCAM面積仍然較大。文獻[7]提出了一種2FeFET設計來提高密度,但只提供了功能驗證,沒有物理細節,導致得出了過于樂觀的結論。此外,之前的工作都沒有完全涵蓋上述TCAM在FPU中使用的兩個問題,因此需要一個全面的設計方案,通過FeFET TCAM實現高效節能的FPU計算。
本文提出一種新的2FeFET TCAM緊湊實現設計,并深入研究了其特性,從而解決上述能量和面積消耗問題;然后設計了一種嵌入了本TCAM的低功耗浮點運算結構。本方案的貢獻包括:(1)提出一個集成了FPU和TCAM的高能效浮點運算結構,并設計一個支持通用GPU應用并顯著降低能耗的執行流程;(2)設計一個超緊湊型2FeFET TCAM單元,以避免不必要的寄生效應和面積消耗,與16T CMOS TCAM單元[10]相比,最終實現了7.7倍的內存密度提升;(3)基于物理版圖和多電壓域Preisach模型[11],本文提出2FeFET TCAM的低能耗、低延遲設計指南。實驗結果表明,本文提出的計算結構用于數據密集型應用是非常有前景的,與常規FPU相比,可節省高達33%的能耗。
2 背景
鐵電材料氧化鉻(HfO2)的最新發展吸引了越來越多的人關注FeFET器件,以及使用FeFET設計CMOS兼容的非易失性應用[7—11]。FeFET晶體管的典型特征是在金屬-氧化物半導體場效應晶體管(Metal-Oxide-Semiconductor Field-Effect Transistor,MOSFET)的柵極上疊加一層鐵電層,如圖1(a)所示,由于鐵電材料的極化可以長時間保留,使Fe-FET具有磁滯現象。由于底層MOSFET的固有增益[11,12],FeFET的開關電流比(ION/IOFF)可以高達106。又由于其三端結構和與CMOS兼容,FeFET可用于設計具有獨立讀取路徑的緊湊型TCAM,從而顯著降低寫入能耗。

圖1 FeFET的器件結構和I-V特征曲線
FeFET通常涉及多電壓域切換,具有非飽和磁滯環、遲滯效應和極化開關動態特性,文獻[11]提出了一種經過實驗驗證的多電壓域Preisach模型,以精確描述如圖1(b)所示的FeFET的I-V特性。本文將采用Preisach模型來描述TCAM的各種現象。
3 計算結構
圖2展示了嵌入FeFET TCAM的浮點運算結構及其具體操作方案。為保證FeFET TCAM的高效集成并充分發揮其能耗優勢,本文設計了如圖2(a)所示的操作執行流程,該流程分為兩個階段:(1)計算樣本分析;(2) FPU計算和TCAM搜索。在計算樣本分析階段,首先要統計得到出現頻率最多的一組操作數,可以使用GEM5, GPGPU-Sim等微架構模擬器來進行仿真統計,統計時運行多個不同的測試腳本以確保較高的覆蓋率[13],這樣就得到了一個包含高頻操作數和相應輸出結果的統計列表。然后設定一個閾值來選擇哪些操作數和結果要存儲在FeFET TCAM中,這取決于TCAM容量和用戶的定義。最后將選好的操作數和結果存放在FeFET TCAM陣列中以供計算過程中的搜索使用。
圖2(b)和圖2(c)展示了嵌入了TCAM的高能效浮點運算結構及其工作流程,當系統開始執行浮點數運算操作時,輸入操作數被同時傳送給FPU電路和FeFET TCAM。如果在FeFET TCAM陣列中找到匹配的操作數,那么在FeFET TCAM中預先存儲的相應結果將被讀出,同時產生一個數據選擇器(MUltipleXer, MUX)的選擇信號和一個disable信號。disable信號被發送到FPU的門控時鐘,將FPU對該組操作數的計算中止掉。MUX選擇信號選擇FeFET TCAM的輸出作為有效輸出,屏蔽掉FPU的輸出。另外,如果FeFET TCAM中沒有匹配的操作數,FPU將正常執行,并將其結果作為輸出提供給MUX。由于FeFET TCAM搜索流程的緊湊性,TCAM的搜索比FPU計算快得多,因為常見FPU的計算通常有幾個周期的延遲(例如Radeon hd7000系列顯卡中的FPU計算需要6個周期),所以當搜索TCAM操作數匹配時,是可以很快中止FPU計算、從而節省不必要的多階段運算以及相應的能耗。由于不匹配通常發生在不常見的數據樣本中,所以發生的概率較低,因此該設計總體上可以顯著地降低能耗和計算時間。此外,由于FPU計算和TCAM搜索是并行執行的,這樣的結構不需要對FPU進行額外的修改,從而使FeFET TCAM更易于集成。下一節將討論FeFET TCAM設計的細節、運作及設計指南,來支撐本節的結構設計。
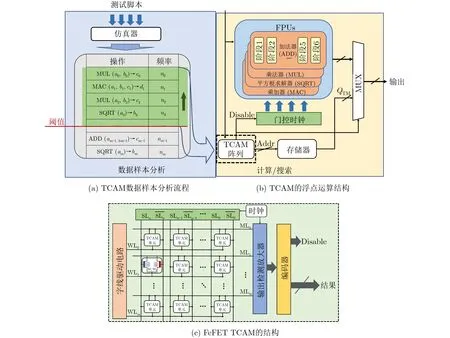
圖2 嵌入FeFET TCAM的浮點運算結構及其操作方案
4 2FeFET TCAM設計
基于Preisach模型[11]和圖1所展示的開關特性,4 T-2 FeFET結構[6]可以進一步優化成2 Fe-FET結構。因為FeFET可以看作一個單晶體管邏輯門,即將FeFET的柵電壓當作輸入A, FeFET的存儲的值當作輸入B,只有當柵電壓和儲值都是邏輯“1”時,漏極電流ID才為開啟電流ION,其他情況下為閉合電流IOFF。換句話說,FeFET可以被用作一個與門,輸出電流ID的兩個狀態分別對應邏輯“1”和“0”。
圖3(a)為2FeFET TCAM的單元電路結構,2個FeFET平行放置,漏極連接到匹配線(Match Line, ML),源極連接到源線(Source Line, ScL),兩個柵極分別連接到位線(Bit Line, BL)和選擇線(Selection Line, SL)。然后將多個2FeFET TCAM單元緊湊地放置在一起,形成一個TCAM陣列。為了減少寄生效應,圖3(b)展示了一個2×2 TCAM緊湊型陣列布局,寬度為46λ,高度為26λ。λ是該工藝下晶體管特征尺寸的1/2。其中SL和(或者BL和)共用同一根線,這根線可以是一根直線,不需要額外跨層走線,從而減少了單元中的寄生效應。與CMOS和ReRAM中的對應元件相比,如果根據無生產線芯片設計工藝渠道組織(Metal Oxide Semiconductor Implementation Service, MOSIS)的設計規則,使用45 nm工藝,2FeFET TCAM單元僅為16T CMOS TCAM[3]面積(1.12 μm2)的13%和2T2R ReRAM TCAM[10]面積(0.41 μm2)的35%。與4T-2FeFET TCAM[6]相比,該方案只消耗22%的面積。如此小的尺寸(7.7x內存密度提升)是實現低能耗快速搜索的關鍵。

圖3 2FeFET TCAM單元電路和陣列版圖結構
5 操作和設計原則
針對圖3所示的TCAM陣列版圖,圖4進一步闡述了2FeFET TCAM單元寫入狀態的操作流程,它可以寫入“1”、“0”和“無效”3種狀態。該操作需要兩個步驟來完成寫入,以寫入邏輯“1”為例:(1)在ScL為“0”時,寫入信號Vwr施加在BL和 SL上,從而使M1的柵極為4 V的高電壓,該FeFET中鐵電層極性就被翻轉,S管就被寫入一個“1”的狀態;(2)將Vwr施加到ScL,兩個FeFET的柵電壓保持不變,M2的VGS此時為—4 V,就給寫入了狀態“0”。這兩個FeFET的狀態聯合起來就表示了這個存儲單元為邏輯“1”。以此類推,翻轉Vwr的電平即可給這個單元寫入“0”。當寫入兩個“0”狀態到這兩個FeFET中時,該單元就表示“無效”。這就是TCAM單元的存儲實現邏輯。
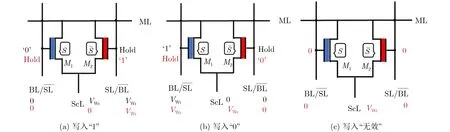
圖4 FeFET TCAM單元的寫入方法
搜索操作流程如圖5(a)所示,與寫入相似,也需要兩個階段:(1)預充電階段,ML預充到高電平;(2)輸入數據階段,根據輸入數據將Vsearch設置為圖5中TCAM的SL和的狀態,即邏輯‘1’設置為1 V,邏輯‘0’設置為0 V。如果存儲的數據匹配了,這個單元的2個FeFET都會被關閉,ML停留在高電位。否則,其中1個或兩個FeFET將被打開,ML線被拉低。圖5(b)給出了搜索過程中匹配和失配兩種情況的SPICE仿真波形。
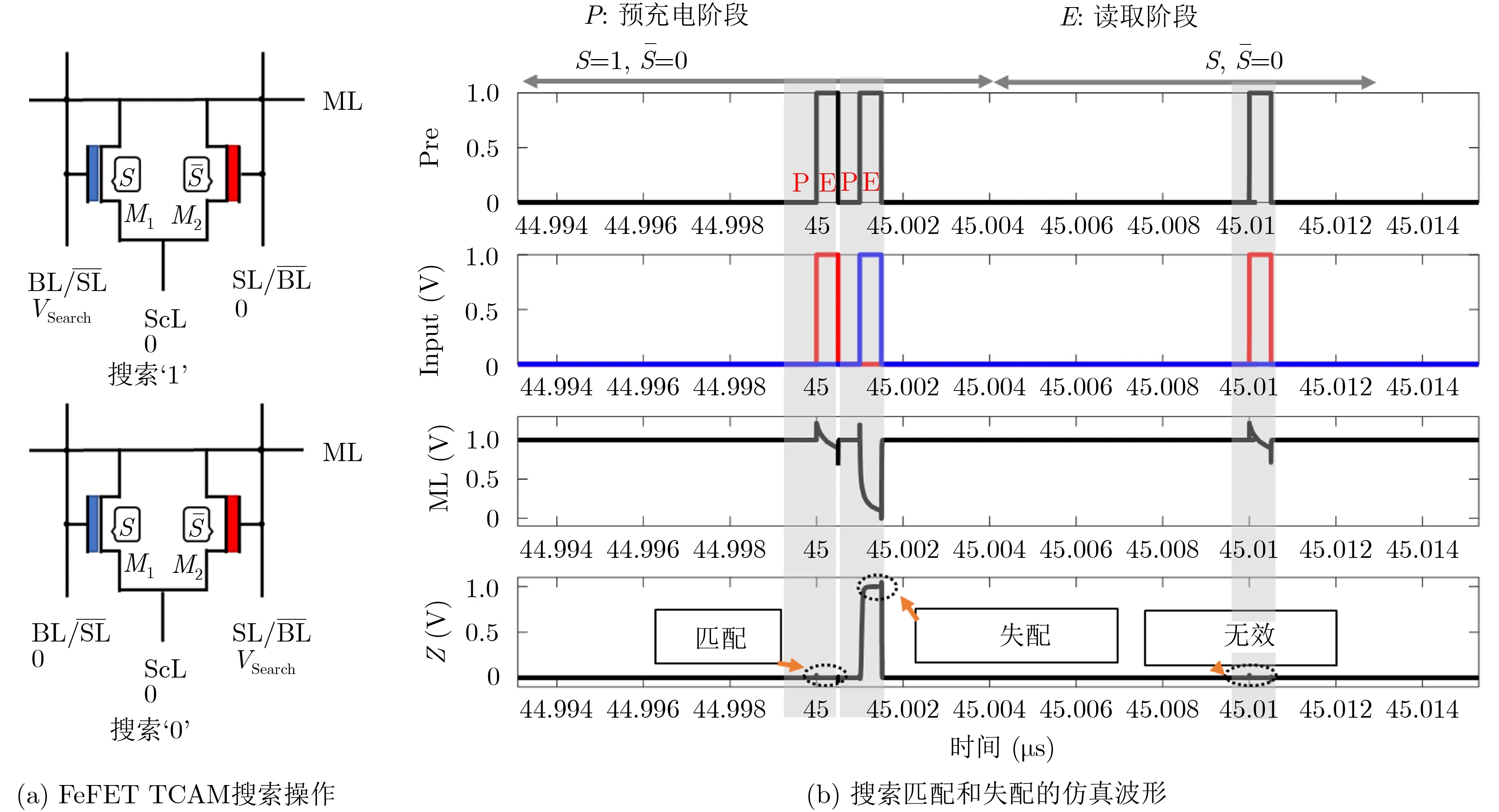
圖5 FeFET TCAM的搜索操作流程與仿真波形
注意,上面的仿真電路不僅包含到2FeFET TCAM陣列,而且還包含了寫入/搜索緩沖區、字線驅動電路、輸出檢測放大器(Sense Amplifier,SA)、時鐘和編碼器等電路結構。為了進一步縮小陣列的時延和功耗,本文有以下設計準則:(1)寫入時,將ML保持在低電平,以減少漏電流;(2)在陣列中,ML和ScL位置平行,BL和SL相互垂直。這樣的走線不僅使寫入和搜索緩沖區的連接更簡單,而且還使它們到SA和編碼器的走線為一條直線,從而使FPU到MUX的走線有更大的空間;(3)對于陣列中未選中的行,可以將對應的ScL設置為Vwr/2,從而避免不必要的寫入干擾。
6 驗證實驗與測試結果
本節將從兩個層面論證該設計結構的優點:(1)不同類型、不同尺寸的TCAM陣列的能耗分析;(2)多種GPU腳本測試的實際性能表現。
本文使用Spectre仿真器分別對2FeFET TCAM, 16T CMOS[3], 2 T2R ReRAM TCAM[8]和4T 2FeFET[6]實現的64×64 TCAM陣列進行了仿真分析,得到了表1所示的性能對比。FeFET TCAM采用45 nm工藝,按如圖3所示的版圖排列,TCAM單元和SA中的晶體管都為最小工藝尺寸。為了便于比較,16T CMOS TCAM也采用相同的45 nm PTM模型和最小晶體管尺寸。對于2T2R ReRAM,本文采用與文獻[3]中相同的參數,設置/復位電壓分別為1.8 V/1.2 V, HRS/LRS為2000/20 kΩ。

表1 不同TCAM實現方式的性能對比
可以看到,由于圖3所示超高密度的電路結構,該2FeFET TCAM與其它TCAM相比有著顯著的能耗優勢。ReRAM TCAM由于較高的Ron/Roff,需要有較大尺寸的晶體管來提供寫入操作的大電流,因此寫入能耗較大(~3225x)。CMOS TCAM由于晶體管數量較多,在面積和能耗方面均處于劣勢。2FeFET TCAM緊湊的物理實現不僅使能耗方面受益,而且還可以降低延遲,它的速度是其他TCAM的1.03~3倍。本文進一步比較了尺寸1~64的不同大小TCAM陣列的能耗,結果如圖6所示,可以看出,本文的2FeFET TCAM能耗優勢是會隨著陣列尺寸的增加而增大的。

圖6 不同工藝的TCAM在各種陣列尺寸下做搜索操作的能耗
最后,本文設計實驗研究了嵌入TCAM的運算結構的能耗性能表現。使用Multi2sim仿真工具搭建測試平臺,這是一款開源CPU-GPU多核計算機架構模擬器,允許用戶自定義運算器功能和系統結構。首先將TCAM編寫成Multi2sim支持模塊代碼,定義其功能、接口以及能耗性能參數。然后修改仿真器庫中的AMD Radeon HD 7970 GPU模型,加入TCAM模塊,與GPU自帶的FPU一起組成圖2所示的運算結構。切換TCAM尺寸定義和能耗參數,即可模擬不同尺寸、不同類型的TCAM。執行測試腳本,可統計各種運算操作的次數,計算出整個計算過程的能耗。本文采用Caltech 101數據集[14]中的多個數據密集型測試腳本來比較不同設計方案的能耗。在數據準備階段,使用GEM5 +GPGPU-Sim仿真流程運行/分析測試腳本,隨機選取了數據集中90%的數據用于分析,找出了最常見的一組操作數樣本[13],然后將選擇的數據存儲在相應的TCAM陣列中。然后使用剩下的10%的數據用于實際測試。經過Multi2sim仿真器模擬GPU運行測試腳本,得到了圖7所示的結果。這幾組結果為3種不同類型TCAM+FPU結構、在不同測試腳本和不同陣列尺寸下的總能耗,結果數據使用文獻[15]中的常規FPU能耗為基準進行歸一化,圖中紅字分別為1行、32行、64行時的TCAM所存數據的命中率。如圖7所示,采用本文2FeFET TCAM結構在各種情況下的能耗都低于其他兩種。值得注意的是,圖7的能耗變化還呈現出一種2次曲線的趨勢:對于較小的TCAM陣列,能耗隨著TCAM數量的增大而減小;到達一個特定的尺寸后,陣列會能耗達到最低;之后,能耗隨著陣列大小的增大而增大。這是因為當陣列尺寸較小時,增大陣列可以存儲更多的數據樣本,實現更高的搜索命中率,從而減少FPU的執行次數。當數組大小超過高頻樣本的數量后,增大的數組大小對減少FPU執行的貢獻不大,反而更大的數組在緩沖、寫入和搜索方面消耗的能量更多。平均而言,在32行陣列的情況下,采用2FeFET TCAM的FPU結構在6種測試腳本下平均可以節省33%的能耗,而基于CMOS和基于ReRAM的對應結構的平均能耗節約分別為22%和13%。

圖7 多個腳本測試不同TCAM實現的浮點運算結構的能耗
7 結論
本文介紹了一種嵌入新型FeFET TCAM的高效能浮點計算結構,本結構中的TCAM僅用2個Fe-FET實現,從而獲得了非常高的集成密度。然后使用該FeFET TCAM設計了TCAM+FPU的計算結構,通過預存儲高頻計算數據來減少FPU的執行次數,從而節省計算能耗。實驗表明,在不同的測試腳本下,本文提出的結構平均可以節省33%的能耗。
猜你喜歡
哲學評論(2021年2期)2021-08-22 01:53:34
現代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
藝術啟蒙(2018年7期)2018-08-23 09:14:18
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
現代企業(2015年9期)2015-02-28 18:56:50
