基于SRAM的通用存算一體架構平臺在物聯網中的應用
2021-06-24 09:41:00曾劍敏虞志益解光軍
電子與信息學報 2021年6期
關鍵詞:指令
曾劍敏 張 章* 虞志益 解光軍
①(合肥工業大學電子科學與應用物理學院 合肥 230601)
②(中山大學微電子科學與技術學院 珠海 519082)
1 引言
隨著移動互聯網、云計算、物聯網和人工智能等技術的快速發展,我們正全面步入大數據時代。大數據最重要的特征之一,也是大數據時代社會所面臨最大的一個挑戰:有海量的數據需要處理[1]。因為在大數據時代,包括社交媒體、生物醫療、氣象、交通和航空航天等在內的多種領域均會產生海量的數據。例如當前國際射電天文界最重要的大型望遠鏡項目之一——平方千米陣(Square Kilometer Array, SKA)[2],每年可以產生300 PB容量的數據[3];一架波音噴氣式客機飛行一小時就能產生約21 TB容量的數據[4]。社會所產生的數據是呈指數式爆炸增長的[5],據全球知名數據公司IDC (International Data Corporation)發布的《數據時代2025》白皮書報告顯示,到2025年,全球每年產生的數據將從2018年的33 ZB增長到175 ZB,相當于全球每天產生491 EB的數據[6]。
大數據的出現與繁榮發展使得數據處理的重心逐漸從以計算為中心轉移到以數據為中心[7],即數據處理任務或應用從計算密集型轉移為數據密集型。而由于存儲墻[8]和帶寬墻[9]等原因,當前采用馮諾依曼架構設計的計算機系統在數據密集型計算中表現出的性能瓶頸和低能效等缺點日益凸顯。因此,為了解決這些問題,新的計算機架構,特別是超越馮諾依曼(beyond von Neumann)架構,亟待提出。
近年來,存算一體(In-Memory Computing,IMC)架構引起了研究人員的廣泛關注,并被認為是一種有望成為突破馮諾依曼瓶頸的新計算機架構范式。存算一體的核心思想是使得計算單元和存儲單元盡量靠近,甚至融合為一體[10]。近期前沿文獻中實現IMC架構的方式有多種,例如基于新興的3D堆疊封裝[11—13]或者憶阻器等非易失存儲器件[14—16]來實現。然而,由于3D堆疊以及非易失存儲等新興技術并不十分成熟,基于這些技術設計的IMC架構短時間很難得到廣泛應用。因此,許多文獻[17—24]逐漸基于技術成熟的SRAM來探索和設計IMC架構,并證明基于SRAM的IMC架構在實現數據密集型應用時能夠帶來顯著的性能和能效提升。例如,文獻[20]為本文作者所設計的一種基于SRAM實現的通用IMC架構平臺——DM-IMCA。為彌補現有文獻中幾乎所有基于SRAM來實現的IMC架構均面向如神經網絡等專用目的而設計的缺憾,DM-IMCA能夠在其內部SRAM中進行大部分的邏輯運算和算術運算,因此具有廣泛的通用性,并且具有較高的潛力和價值。
為了充分挖掘DM-IMCA的應用潛力和價值,本文探索了該平臺在物聯網領域中的應用。詳細來說,本文選取了包括物聯網中信息安全、深度神經網絡以及圖像處理在內的若干輕量型數據密集型應用,對相關算法進行分析或者拆分,并把算法的關鍵部分映射到DM-IMCA的SRAM中進行計算,以達到加速應用計算或者降低功耗的目的。
2 基于SRAM的存內邏輯計算原理

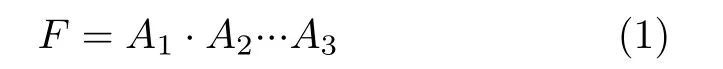
和
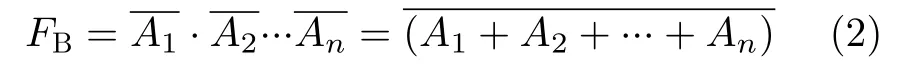
即可以利用SRAM位線的“線與”特性來實現多輸入與門和或非門。
3 DM-IMCA:基于SRAM的通用IMC架構平臺
3.1 DM-IMCA簡介
DM-IMCA[20]是一個基于SRAM的通用IMC架構平臺,其硬件架構如圖2所示。DM-IMCA主要由1個6級流水精簡指令集處理器核、1個指令存儲器、1個存內計算協處理器——IMC-CP,以及由若干SRAM模塊組成的數據存儲器組成。其中處理器核是基于一款開源、具有經典5級流水且兼容MIPS32架構的低功耗輕量處理器核OpenMIPS進行裁剪與改進而來的。

圖1 SRAM列內邏輯運算示意圖

圖2 DM-IMCA硬件架構圖
數據存儲器由若干常規SRAM模塊與計算型SRAM——IMC-SRAM組成。IMC-SRAM是一款融合存儲和計算為一體的SRAM,其硬件架構如圖2(e)所示。IMC-SRAM是在如圖1所示的電路原理基礎之上,將傳統6管單元換成9管單元,以消除6管單元所帶來的讀寫互擾以及進行存內計算時的問題。此外,IMC-SRAM中還額外加入了少許邏輯門,用于實現除“與”和“或非”邏輯之外的其他運算。與已有文獻相比,IMC-SRAM可以支持更多類型的運算,例如加法、移位運算等。此外,IMC-SRAM支持存內向量計算。如圖2(e)所示,將向量操作數A和B沿字線方向對齊存儲,那么只需1次操作,便可對存儲陣列中某一行的A和B分量計算完,然后將計算結果回寫至同樣與A和B對齊存儲的向量C中。在IMC-SRAM進行存內計算時,數據存儲器中的常規SRAM仍然可以進行數據的讀寫操作。
IMC-CP是一個為存內計算設計的輕量協處理器,主要作用是對處理器核傳送過來的IMC指令進行譯碼,然后根據譯碼后的信息對IMC-SRAM進行模式配置及控制存內計算操作,包括計算并配置操作數地址以及管理IMC-SRAM中的存內計算過程。IMC-CP中還包括幾個重要的可配置的狀態寄存器:
(1)R0:用來保存下一次存內計算的矢量長度信息;
(2)R1-R3:用來保存IMC-CP對IMC指令譯碼后得到的源操作數和目的操作數的列地址;
(3)Rm:用來保存系統當前工作模式;
(4)Rn:用來保存系統中用以存內計算的IMCSRAM模塊的數量信息;
(5)Rv:保存當前IMC計算指令中的剩余矢量長度信息;
(6)Roc:保存存內計算的操作碼信息。


在DM-IMCA中,運行著兩套指令:傳統MIPS32指令和IMC指令(IMC instruction)。前者通過完整的處理器核流水線來執行,后者在處理器核的指令預譯碼流水級之后,傳送至IMC-CP進行二級譯碼,再由IMC-SRAM進行執行。兩套指令長度一致,因此,并不需要設計兩組不同的指令存儲器,可以將傳統MIPS32指令和IMC指令混合存儲于同一個指令存儲器中。這樣做的好處是便于對系統進行程序設計,達到真正的傳統指令和IMC指令混合編程的目的。對于兩種指令的識別,將會交由處理器核的指令預譯碼流水級來進行處理。指令存儲器采用常規的SRAM(通過工藝廠商提供的存儲編譯工具Memory Compiler生成)來進行設計。
DM-IMCA支持雙工作模式:普通模式和IMC模式。當DM-IMCA工作于普通模式時,數據的運算由處理器核的流水線來完成,此時IMCSRAM與傳統SRAM一樣,其功能是進行數據的存取,此時DM-IMCA表現得與傳統馮諾依曼架構一樣;當DM-IMCA工作于IMC模式時,IMCSRAM可以進行存內計算,數據無需傳送至流水線進行處理,此時DM-IMCA表現出與傳統馮諾依曼架構不一樣的特性。因此,DM-IMCA是一種超越傳統馮諾依曼的混合架構。

圖3 存內向量計算自動化及自適應示意圖
3.2 IMC指令集
DM-IMCA包含一個專門為存內計算設計的指令集——IMC指令集。DM-IMCA中的處理器核經過改進,將其中不需要的部分指令去除,將騰出的指令空間用于IMC指令的編碼。IMC指令的高5位為識別碼,其中前3位(110)為1級識別碼,用于區分IMC指令和傳統MIPS32指令。1級識別碼在DMIMCA處理器核流水線中的預譯碼級被處理,并不會被傳送至協處理器IMC-CP中。因此,處理器核傳送給IMC-CP的指令實際上只有29位(IMC指令的低29位)。識別碼中的后兩位為2級識別碼,用于分區某條IMC指令的類型。各類指令的指令格式也分別在表1中列出。

表1 IMC指令集編碼格式
按照功能劃分,IMC指令可以分為兩大類:配置指令和計算指令,如表2所示。其中配置指令又可以分為存儲配置指令和地址配置指令。存儲配置指令的作用是對數據儲存器中用于存內計算的IMC-SRAM宏模塊數量進行配置。具體配置過程是將指令中rn字段所包含的信息寫入IMC-CP中的寄存器Rn中。地址配置指令用于配置存內計算的源操作數和目的操作數的行地址信息。地址配置指令中的r1和r2字段所包含的內容為存內計算源操作數的行地址信息,r3字段所包含的內容為存內計算目的操作數的行地址信息。地址配置指令的配置過程為分別將r1字段和r2字段內容寫入IMC-CP的寄存器R1和R2中,將r3字段內容寫入IMC-CP的寄存器R3中。計算指令的作用是控制IMC-SRAM的存內計算,包括存內計算的功能類型和向量長度。計算指令中的function字段包含了存內計算的操作碼(功能碼),用于IMC-SRAM選擇特定的存內計算功能,vl字段包含了相應存內計算操作的向量長度信息。

表2 IMC指令集
3.3 DM-IMCA的工作流程
首先,在進行存內計算操作之前(一般為系統啟動或者復位后),需要執行一條存儲配置指令memCfg來對IMC-CP中的寄存器Rm進行配置,以確定數據存儲器中參與存內計算的IMC-SRAM宏模塊數量。由于Rm在系統啟動或者復位后被置為1,因此如果不對寄存器Rm進行配置,而又需要多個IMC-SRAM模塊參與存內計算,存內計算將無法正確進行。
完成一個存內計算操作需要DM-IMCA連續執行兩條IMC指令。第1條為地址配置指令addrCfg,第2條則是一條計算指令。第1條指令執行所包含的內容為第2條指令將執行的存內計算操作的源操作數和目的操作數的行地址信息。第1條指令被IMCCP執行完后,IMC-CP中的寄存器R1-R3將會被寫入相應的操作數行地址信息,并且寄存器Rm被寫入“1”,表示IMC-CP被切換到IMC模式。在隨后的一個周期內,IMC-SRAM的行地址信息和工作模式將會被IMC-CP進行配置。第2條計算指令的作用則是讓IMC-SRAM開始啟動存內計算操作。計算指令被IMC-CP執行后,計算指令中所包含的存內計算操作碼和向量長度信息會被IMC-CP分別寫入寄存器Roc和Rv中,隨后IMC-SRAM中的存內計算流程正式開始。當IMC-SRAM完成存內計算后,將寄存器Rm清零,將IMC-CP切換至普通工作模式,并且通知IMC-SRAM和處理器核切換至同樣的工作模式。
下面以圖3中的存內向量加法為例來說明存內計算的指令執行過程。為簡化起見,將IMC-SRAM的起始地址設為0。對于圖3(a)中的實例,只有一個IMC-SRAM模塊參與存內計算,那么需要通過存儲配置指令將Rn設置為“1”(如果系統剛啟動或者復位,也可以不設置)。向量(數組)A, B和C的行地址分別為0, 3和6,存內加法計算的向量長度vl為20,那么完成C =A+B這個向量加法需要執行以下幾條指令:
(1) memCfg 1
(2) addrCfg 6, 3, 0
(3) maddu 20
與圖3(a)相比,圖3(b)中實例的區別在于調用了2個IMC-SRAM模塊參與存內計算。因此,完成同樣的存內計算,除了Rn的配置不同,其余均與圖3(a)中的實例一致。
4 DM-IMCA在物聯網信息安全中的應用
隨著物聯網應用的越來越廣泛,其安全性也變得更加重要。因此,非常有必要對所傳輸的數據進行加密來確保物聯網的信息安全。利用加密算法可以有效提高物聯網中設備通信時的數據安全。本節將以兩個輕量級加密算法為例,介紹DM-IMCA在信息安全中的應用。這兩個加密算法分別是一次性密碼(One-Time Pad, OTP)[25]算法和哈希算法[26](或稱為散列算法)。
4.1 基于DM-IMCA的OTP加密
在OTP加密技術中,信息發送方使用與信息長度一致的密鑰對信息進行加密,信息接收方在接收到加密信息后使用與加密時相同的密鑰進行解密。由于加解密使用了相同的密鑰,因此OTP屬于對稱加密類型。為保障加密的有效性和安全性,加解密使用的密鑰必須為一次性的,即一個密鑰只能使用一次。此外,加解密所使用的密鑰生成方式應該做到最大限度的隨機性。由于OTP技術的密鑰長度需要和被加密信息一致,因此其對大文件的加密效率較低,而比較適用于短信息加密。OTP加密的核心過程非常簡單,只需對信息內容和一次性密鑰做按位異或操作,運算結果便是加密后的內容,如表3所示。
DM-IMCA原生支持異或操作,因此OTP加密過程可直接通過使用IMC指令來實現。將表3中的數組K, P和C在IMC-SRAM中映射的行地址分別設置為32, 40和48,則其字節地址分別為0×400,0×500和0×600。通過DM-IMCA存內計算的方法來實現表3中算法的核心代碼如下:

表3 OTP算法
(1) addrCfg 48, 40, 32
(2) mxor N
此處N為各數組的字長信息。如果通過基準系統來實現同樣的OTP算法,其匯編代碼如下:
(1) li $t0, 0
(2) loop:
(3) lw $t4, 0x400($t0)
(4) lw $t5, 0x500($t0)
(5) xor $t6, $t4, $t5
(6) sw $t6, 0x600($t0)
(7) addiu $t0, $t0, 4
(8) blt $t0, Nb, loop
其中,代碼中的Nb=N/4,因為對于MIPS匯編來講,地址是以字節而不是字為單位計算的。通過上述OTP算法在不同系統中實現的匯編代碼對比,也可以看出,相比于傳統的馮諾依曼架構的基準系統,DM-IMCA的代碼要簡潔許多,可以節省大量指令存儲器空間。
為了測試與對比,本文搭建了一個測試平臺,如圖4所示。其中圖4(a)是一個作為對照組的基準系統(baseline system),主要由OpenMIPS、1塊大小為32 kbit (128行×256列)的傳統6管SRAM宏單元;圖4(b)是用于測試的DM-IMCA系統,主要由一個本文改進后的6級流水處理器核M-OpenMIPS、1個大小為32 kbit (128行×256列)的IMCSRAM模塊以及協處理器IMC-CP組成。基準系統及D M-I M C A 測試系統均采用由存儲編譯器(memory compiler)生成的6管SRAM模型作為指令存儲器。該平臺將用于本文所有應用的測試。
分別選擇長度為256 bit(N =8字)和1024 bit(N =32字)的密鑰,分別在DM-IMCA和基準系統中進行加密實驗。在加密前,明文數組P、密鑰數組K和密文數組C在IMC-SRAM中的存儲方式類似圖3的向量A, B和C。由于在實驗中,DM-IMCA只采用了一個IMC-SRAM宏模塊,因此N =8時,各數組分別需要占用IMC-SRAM一行的存儲空間,而N =32時,各數組占用的IMC-SRAM的存儲空間則為4行。分別統計通過DM-IMCA和基準系統進行OTP加密實驗所花費的時鐘周期數,如圖5所示。結果顯示,與基準系統相比,利用DMIMCA的存內運算來處理256 bit和1024 bit長度的OTP加密,分別可以獲得8.75和23.8倍的運算加速比。

圖4 測試平臺
4.2 基于DM-IMCA的哈希函數實現
哈希算法的功能是將任意長度的信息映射到固定長度的序列中,這個序列稱為哈希值(Hash code)。通常哈希值的長度比信息小得多,且哈希算法的運算是不可逆的,因此常用于信息提煉,以保障信息的真實性。因此信息發送者可以將原始信息和相應的哈希值一起發送,信息接收者通過對接收到的信息進行同樣的哈希運算并將結果與接收到哈希值進行對比,來確認收到的信息是否為原始數據。這其實就是常用到的文件校驗功能。另一個哈希應用的實例是網站用戶登錄機制中的密碼找回。當用戶忘記自己注冊的某個網站的登錄密碼,申請找回密碼時,為了保護用戶的信息安全,網站管理方不是將登錄密碼明文發給用戶,而是將登錄密碼的哈希值發送給用戶,這樣就可以避免密碼遭到泄露。除此之外,哈希算法的應用還非常廣,例如數字簽名、協議鑒權等。隨著物聯網和區塊鏈的發展,哈希算法在該領域也有著許多應用[27]。
哈希算法實際上是一類算法,而不單指某個算法,常見的MD5和SHA, 以及HMAC等均屬于哈希算法的范疇。一般把產生哈希值的函數稱為哈希函數,按照哈希值的產生方式不同,哈希函數可以分為加法哈希、乘法哈希、位運算哈希等幾種經典的函數。這些基礎的哈希函數組合還可以構成更復雜的哈希函數。本節將選取加法哈希在DM-IMCA以及基準系統中進行實現。加法哈希的描述如表4所示,其中key和len分別表示輸入的字符串和字符串長度,prime是任意的質數。

圖5 測試OTP加密所花費的時間對比

表4 加法哈希算法
從表4可以看出,加法哈希函數運算的核心部分實質是一個加法樹,其規模隨著字符串長度的增加而越來越龐大。這樣的運算在基準系統中實現只能是以串行的方式逐個進行累加,顯然效率較低,耗時較長。在DM-IMCA中,可以將字符串數組映射于IMC-SRAM中,按存內計算的存儲要求排列,分批次進行運算。假設字符串長度len=128時,字符串數組key在IMC-SRAM中的起始地址為0×400(行地址為32)。先將數組key的元素對半分為兩個新的數組K1和 K2,并分別按如圖6所示的方式依次存儲于IMC-SRAM中(需要注意的是,由于當前IMC-SRAM不支持字符型數據的操作,因此需將char型數據轉換為unsinged int型)。K1和K2通過存內加法進行各元素相加,并將結果存于K1中,即
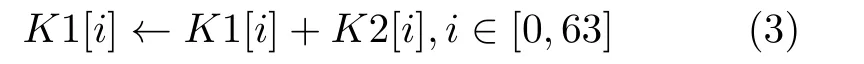
按式(3)完成第1階段運算后,接著用同樣的方法將數組K1對半分為兩部分,分別記為K3和K4,再通過存內計算執行如下操作:K3[i]←K3[i]+K4[i],i ∈[0,31]。以此類推,反復進行同樣的數組對半拆分操作及存內加法運算,直到無法使用存內運算進行加法操作,將剩下的元素取出至處理器核中進行相加。對于字符串長度len=128的實例,存內矢量加法運算的相關匯編代碼如下:
(1) addrCfg 32, 40, 32
K1[i]←K1[i]+K2[i],i ∈[0,63]
(2) maddu 64 //
(3) addrCfg 32, 36, 32
K3[i]←K3[i]+K4[i],i ∈[0,31]
(4) maddu 32 //

圖6 加法哈希函數運算中字符串在IMC-SRAM中的映射
(5) addrCfg 32, 34, 32
(6) maddu 16
(7) addrCfg 32,33, 32
(8) maddu 8
分別取長度len為256和512的字符串使用加法哈希算法在基準系統和DM-IMCA中進行試驗,并統計各自所消耗的時鐘周期數,其結果如圖7所示。結果顯示,與基準系統相比,使用DM-IMCA的存內運算功能進行長度為256和512位字符的加法哈希加密運算分別可以獲得約6.5倍和12.2倍的運算加速比。通過圖7還可以看出,隨著數日字符串長度翻倍,基準系統所需的加法哈希運算時間也幾乎翻倍,而使用DM-IMCA來運算增加的時間非常少。因此,字符串越長,使用DM-IMCA進行加法哈希運算越有優勢。
5 DM-IMCA在深度神經網絡中的應用

圖7 測試加法哈希算法進行加密所耗費的時間對比
近些年來,隨著集成電路工藝的發展,計算機的算力獲得了巨大提升。此外,在信息化時代,社會所產生的數據呈爆炸式增長。這些因素極大地促進了人工智能技術的快速發展,從而使人工智能得到了極廣泛的應用,包括熱門的計算機視覺、語音識別,以及自然語言處理[28]。在眾多的人工智能模型中,卷積神經網絡(Convolutional Neural Networks, CNNs)的發展尤其成功,例如著名的LeNet-5[29], VGGNet[30]和ResNet[31],均屬于CNN。然而,CNN對存儲和計算資源有著巨大的需求,例如VGG-16網絡需要存儲138 MB的參數,為了對一幅大小為224×224的圖像進行分類,需要進行高達15.5 G次的浮點精度MAC(Multiply-Accumulate)運算;ResNet-50也仍然需要存儲25.5 MB的參數,對同樣大小的圖片進行分類,需要高達3.9 G次的浮點精度MAC運算。對于面積和功耗等資源緊張型的場景,如嵌入式設備或移動終端,以及物聯網中的許多邊緣設備,這樣的原生網絡實在過于龐大,不便于部署。慶幸的是,Courbariaux等人通過研究證明可以同時將權值和神經元激活(neuron activations)二值化,即同時減小到1 bit精度,同時不會遭受明顯的分類精度損失[32,33]。例如,可以采用如式(4)所示的算法進行二值化。



表5 二值乘法真值表
將神經網絡的權值和激活二值化可以極大地壓縮參數所需的存儲空間,節省硬件計算資源。此外,功耗也相應得到大幅度降低[32]。

式(6)中的xor運算可以通過DM-IMCA中高度并行的mxor指令來實現存內計算,操作類似前述的OTP加密運算;此外,popcount操作也可以通過移位和加法等多類存內運算組合來完成。為了充分利用IMC-SRAM存儲空間,首先將向量a和W 的元素以字為單位合并后存儲于整形數組中。圖8所示的是當向量長度L=256時,激活a和權值W 的存儲映射實例。 a和W 分別映射到數組A和B中,并在IMC-SRAM中按行對其排列。其次,利用存內運算來完成XOR操作。隨后分別通過移位、數據位屏蔽以及加法來完成popcount操作。表6描述了popcount(xnor())操作在IMC-SRAM中的存內運算映射,其中第(3)行描述的是XOR操作,第(4)~(11)行描述的popcount操作。第(4), (5),(6)和(8)行描述的運算分別可以通過DM-IMCA中的mxor, mand, maddu和msr指令來實現并行運算。表6中算法中涉及的數組M, C和D在IMCSRAM中的存儲映射如圖8所示。若輸入數組A和B的長度較大,第(12)~(14)行操作還可以使用存內加法進一步進行加速,類似前面所介紹的對哈希算法中的加法樹運算。

表6 存內矢量XOR運算和popcount操作算法
設數組A, B, M, C和D在IMC-SRAM中的行地址分別為32, 40, 48, 56和64,當L=256時,在DM-IMCA中實現表6中算法中的第(4)~(11)行運算的匯編代碼如下:


圖8 二值神經網絡中激活和權重在IMC-SRAM中的映射

而在基準系統中實現相同的功能,各步的運算都只能使用串行操作,因此運算效率將會比在DMIMCA中實現更低。
在實際的二值神經網絡中,通常存在多維度的卷積操作,從而使參與MAC運算的兩個向量長度均比較長。因此,對應的二值卷積計算中a和W的向量長度也較長。本節將通過實驗模擬較長的二值卷積計算,從而觀察DM-IMCA存內運算對其的加速效果。分別取向量a和W的長度L=512,L=1024和L=2048,分別在基準系統和DM-IMCA系統中實現,最后統計各自所消耗的時鐘周期數,結果如圖9所示。經計算可知,相比于基準系統,采用DM-IMCA實現長度L=512, L=1024和L=2048二值卷積運算,分別可以獲得7.7倍、12.4倍和17.8倍的運算加速比。

圖9 測試二進制卷積運算所花費的時鐘周期數對比
6 DM-IMCA在圖像處理中的應用
除了在信息安全和卷積神經網絡領域,DMIMCA在其他領域也存在著潛在的應用價值,例如傳統的圖像處理和視頻處理領域。本節將簡單介紹DM-IMCA在圖像灰度化處理中的應用,以期能夠對DM-IMCA在其他方面的應用起到啟發作用。
在計算機圖形學中,每幅圖像使用一個2維數組表示,數組中的每個元素均表示一個像素點(Pixel)。根據像素點表示的不同,圖像可以分為多種類型:真彩色圖像、索引圖像、二值圖像和灰度圖[34]。其中二值圖像的每個像素點僅在“0”和“1”中取值,因此圖像只有白和黑兩種顏色。灰度圖像是每個像素只有一個采樣顏色的圖像,每個像素點在[0, 255]范圍內取值,0~255中間的每個值都代表了一個級別的灰度。因此灰度圖像體現的是一幅圖像中各區域的顏色深淺。真彩色圖像也稱為RGB圖像,每個像素點由紅(R)、綠(G)和藍(B)3個分量來按不同灰度疊加構成,每個分量取值均在[0, 255]范圍內。真彩色圖像能夠更真實地表達現實世界,因此在日常生活中我們通常使用彩色圖像來記錄事物。然而在很多場景中,灰度圖像依然有著非常廣泛的應用。例如黑白印刷由于比彩色印刷更廉價,依然受到大眾歡迎。在打印中通常需要將彩色圖像轉為灰度圖像,并對圖像的灰度進行增強以提高打印品質。另外,在圖像的邊緣檢測、特征提取、圖像分割及圖像分類等圖像處理過程中也經常使用灰度圖像,因為相比于彩色圖像,灰度圖像數據量小,便于存儲和提高運算效率。因此使用這些算法進行圖像處理之前,經常需要預先將彩色圖像轉換為灰度圖像。

因此,通過位寬量化及精度縮減,可以將圖像灰度化公式變換成只包含加法和移位運算。例如式(11)中的2×Gm×n可以通過DM-IMCA的一次加法(m a d d)或者移位(m s r l)實現,式(1 2)中的5×Gm×n可以通過DM-IMCA的兩次存內1 bit移位及一次加法實現。對于一個像素點來說,若使用式(11)來將RGB值轉換為灰度值,需要通過4次存內運算來完成。一般圖像由比較大的像素點陣(如16×16, 64×64或256×256)組成,圖像灰度化運算量比較大。但由于DM-IMCA支持自動化及自適應的存內向量計算,仍然可以對圖像灰度化運算提供可觀的加速比。對一幅像素為28×28的RGB圖像進行灰度化,實驗結果表明,對于相同的量化后算法,相比于基準系統,在DM-IMCA中實現可以獲得約10倍的運算加速比。
7 結束語
本文介紹了基于SRAM進行存內邏輯計算的原理,以及基于SRAM的通用存算一體架構平臺DMIMCA。隨后,本文選取了OTP加密、哈希算法、二值深度神經網絡以及圖像灰度處理等幾個輕量級物聯網應用,對其進行算法分析及拆分,將數據密集計算部分算法映射到一款通用型存算一體架構平臺DM-IMCA的計算型SRAM中,以達到對應用進行加速和提高能效的目的。這些實例表明DMIMCA在物聯網領域具有較高的應用價值,且為后續的應用提供了思路與方法。
猜你喜歡
科普童話·神秘大偵探(2023年1期)2023-05-30 12:48:10
測控技術(2018年5期)2018-12-09 09:04:26
電子測試(2018年18期)2018-11-14 02:30:34
電信科學(2016年10期)2016-11-23 05:11:56
時代農機(2015年3期)2015-11-14 01:14:29
科技傳播(2015年20期)2015-03-25 08:20:30
信息安全研究(2015年3期)2015-02-28 20:18:12
西安航空學院學報(2014年5期)2014-07-13 01:27:52
家電科技(2014年5期)2014-04-16 03:11:28
汽車零部件(2014年2期)2014-03-11 17:46:27
