基于深度監督的跨模態圖文檢索方法研究
2021-06-24 03:32:10徐慧銘
黑龍江大學自然科學學報 2021年2期
焦 隆, 徐慧銘, 程 海
(黑龍江大學 電子工程學院, 哈爾濱 150080)
0 引 言
隨著互聯網文本、視頻和圖片等不同類型媒體數據的快速增長,跨模態檢索在現實應用中變得越來越重要。跨模態檢索旨在實現不同數據模式之間的靈活檢索,它將一種類型的數據作為查詢,來檢索另一種類型的相關數據[1]。跨模態搜索結果有助于用戶獲取有關目標事件或主題的全面信息。跨模態學習方法可分為二值表示學習和實值表示學習兩類[2]。文獻[3]利用二值表示方法提高計算效率,并將異構數據映射到一個共同的漢明空間中,跨模態檢索速度更快。由于表示學習被編碼為二進制碼,檢索精度通常會因信息丟失而略有下降。實值表示學習方法包括無監督方法、成對方法和有監督方法。文獻[4]使用無監督方法,利用多媒體文檔中共存的信息來學習不同類型的共同表示。文獻[5]使用成對的方法,利用更多相似的圖像文本對來學習公共表示,比較來自不同模態的樣本。文獻[6]使用有監督方法,利用標簽信息來區別不同類別的信息。盡管這些方法已經使用了分類信息,但分類信息僅用于學習每種模態中或多模態之間的區別特征,并沒有充分利用語義信息。文獻[7]使用典型相關分析CCA方法,通過最大化兩組異構數據之間的成對相關性來學習公共空間。然而,多媒體數據之間的關聯過于復雜,無法通過應用線性投影來完全建模。文獻[8]提出了一種基于深度卷積神經網絡和神經語言模型的多模態深度神經網絡,分別學習圖像模態和文本模態的映射函數。利用樣本的標簽分類信息來學習圖像和文本的模態內語義特征,隨著多媒體數據的不斷增長,采用一般深度學習的特征表示,由于維數過大而面臨儲存空間與檢索效率的挑戰,導致無法適應大規模多媒體數據檢索任務。
本文提出了基于深度監督跨模態檢索方法,保持不同語義類別樣本之間的區別,同時消除跨模態差異。將樣本在標簽空間和公共表示空間中的判別損失最小化,以監督模型學習鑒別特征。此外,最小化了模態不變性損失,并使用權重共享策略來學習公共表示空間中的模態變化特征,在這種學習策略下,充分利用了分類信息和語義信息。利用新增的數據集對改進的模型進行調參優化,提高了圖文檢索的準確率,實驗證明所改進的算法在平均精度值上優于現有圖文檢索算法。
1 圖文檢索數據特點
1.1 跨模態檢索函數表示
雙模數據的跨模態檢索即圖像和文本的跨模態檢索。把圖像-文本對的實例集合映射為函數表達式:
(1)
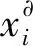
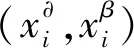
由于圖像特征向量和文本特征向量通常具有不同的統計特性,并且位于不同的表示空間中,所以它們不能在跨模態檢索中互相直接比較。利用交叉模態學習可以得到這兩種不同模態的函數,圖像模態的函數表示為:
(2)
文本模態的函數表示為:
(3)
式中:d為表示公共空間的維數;γα和γβ為兩個函數的可訓練參數,可以使不同數據模態的樣本直接進行比較。
在公共空間中,同一種類別樣本的相似度大于不同種類別樣本的相似度。因此,可以利用返回數據集中不同數據類型的相關樣本來查詢數據類型。將ω中實例的圖像、文本和標簽用矩陣表示,分別為U=[u1,u2,…,un]、V=[v1,v2,…,vn]和Y=[y1,y2,…,yn]。
1.2 VGGNet和Word2V-ec模型
卷積神經網絡(Convolutional neural network,CNN)是一種前饋神經網絡[9],本文跨模態圖文檢索網絡模型采用經典的卷積神經網絡VGGNet網絡結構來提取圖像和文本的特征[10]。小卷積核是VGGNet的重要特點,使用多個較小的卷積核代替一個卷積核較大的卷積層,一方面可以減少參數,另一方面相當于進行了更多的非線性映射,可以增加網絡的擬合能力。在訓練高級別的網絡時,可以先訓練低級別的網絡,用前者獲得的權重初始化高級別的網絡,可以加速網絡的收斂。
文本模態的公共表示學習采用了Word2V-ec模型,包含Skip-grams(SG)和Continuous bag of words(CBOW)兩種算法。通過訓練模型,保留模型中的一部分權重參數,來獲得詞向量。Skip-gram根據中心詞預測周圍的詞,模型如圖1所示。可以看出,SG模型預測的是p(wt-2|wt),p(wt-1|wt), …,p(wt+2|wt),由于圖中詞wt前后只取了各2個詞,所以窗口的總大小是2。假設詞ωt前后各取k個詞,即窗口的大小是k,那么SG模型預測的將是p(wt+p|wt)(-k≤p≤k,k≠0)。
CBOW根據周圍的詞預測中心的詞語,模型如圖2所示,CBOW與神經網絡語言模型不同的是去掉了最耗時的非線性隱藏層。模型預測的是p(wt|wt-2,wt-1,wt+1,wt+2),由于圖中目標詞wt前后只取了2個詞,所以窗口的總大小是2。假設目標詞wt前后各取k個詞,即窗口大小是k,那么模型預測將是p(wt,wt-(k-1),…,wt+1,…,wt+(k-1),wt+k)。
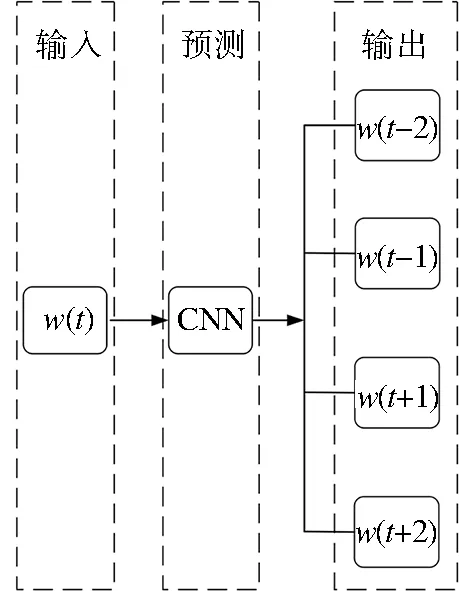
圖1 SG模型
2 設計與實現
2.1 跨模態圖文檢索的網絡結構
跨模態圖文檢索方法的總體框架如圖3所示,其中包括兩個子網絡:一個子網絡用于圖像模態,另一個子網絡用于文本模態,它們都是以端到端的方式進行訓練。圖像子網絡通過深度卷積神經網絡VGGNet生成4 096維特征向量作為圖像的原始高層語義表示,進行公共表示學習,得到每個圖像的公共表示。采用Word2V-ec模型將文本矩陣輸入到與文本CNN[11]配置相同的卷積層,生成文本的原始高層語義表示,可以進行公共學習表示。為了確保這兩個子網絡學習圖像和文本是共同的表示空間,強制兩個子網絡共享最后一層的權重。最后,假設空間中的公共表示是在理想分類的基礎上,將參數矩陣為p的線性分類器連接到這兩個子網絡中,利用標簽信息學習判別特征。因此,可以很好地學習交叉模態相關信息,提取判別特征。
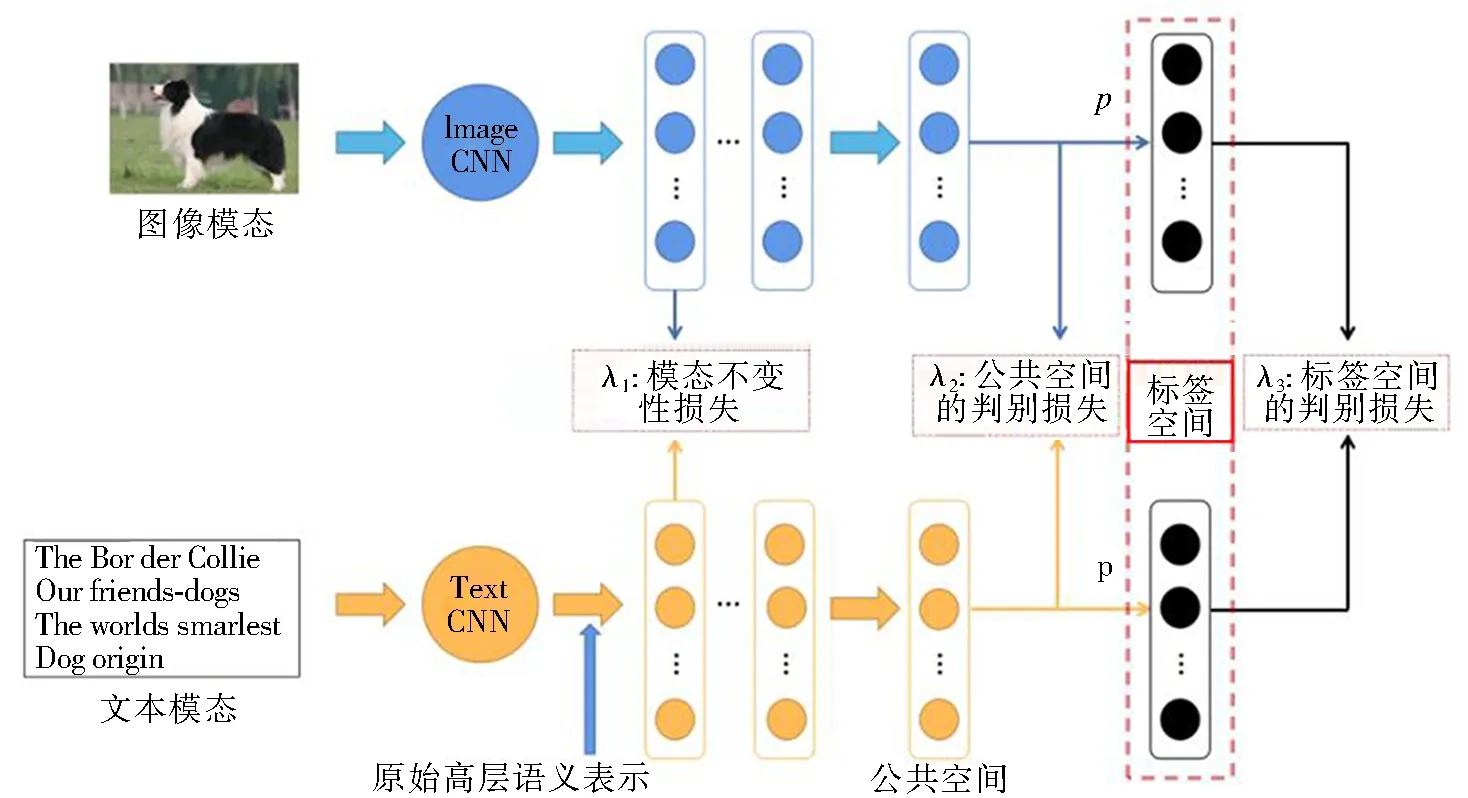
圖3 方法總體框架
2.2 損失函數的設計
基于深度監督跨模態檢索的目標是學習數據的語義結構,即學習一個公共空間,其中來自同一語義類別的樣本應該是相似的,即使這些數據可能來自不同的形式。來自不同語義類別的樣本應該是不同的,為了了解多媒體數據的鑒別特征,提出在標簽空間和公共標識空間中最小化鑒別損失,通過最小化每一個圖像-文本對表示之間的距離,以減少交叉模式的差異。為了保持特征投影后不同類別樣本的區分性,假設公共表示是理想的分類,并使用線性分類器來預測投影在公共表示空間中的樣本語義標簽,在圖像模態網絡和文本模態網絡的頂部連接線性層。分類器利用訓練數據在公共空間中表示,為每個樣本生成一個c維向量的預測標簽。引入不同的損失函數來優化模型,標簽空間中的判別損失函數為:
(4)
公共空間中的判別損失函數為:
(5)
模態不變性損失函數為:
(6)
結合方程得出總損失函數為:
μ=μ1+Aμ2+Bμ3
(7)
式中:超參數A和B控制最后兩個分量對模型的影響;n是輸入實例的數目,函數采用隨機梯度下降算法進行優化[12]。
3 實驗測試與分析
3.1 數據集訓練
采用交叉模態數據集作為訓練數據集,Pascal sentence數據集包含1 000幅圖像,共20個圖像類別,每個圖像都對應有描述圖像內容的英文文本[13],如圖4所示。在此基礎上增加了5個不同類別的數據集,每個類別包含50幅圖像和對應的英文文本,新增后的數據集共有1 250幅圖像,25個圖像類別。將新增后的數據集按照4∶ 1的比例將數據集分為訓練集和測試集,其中1 000幅圖像用于跨模態圖文檢索網絡模型的訓練學習,250幅圖像用于測試檢索準確率試驗。

圖4 Pascal sentence數據集示意圖
在訓練模型時,用大小不同的隨機數對網絡的權值和閾值進行初始化。選用5種新增的圖文數據集進行訓練調參和優化模型,訓練過程中各參數的變化對訓練準確率的影響曲線如圖5和圖6所示。可以看出Batchsize對準確率的影響,迭代次數相同、在Batchsize=100時,準確率達到最大穩定值。在調整學習率參數時,Learning_rate為0.1、0.01和0.00 1時都出現了因學習率過大導致無法正常收斂的問題。由圖6可知,在Learning_rate=0.000 1時,準確率更高,收斂性最好。在參數選擇時,Batchsize為100,學習率為0.000 1時,在訓練過程中會達到最優權重。經過多次的調參訓練,模型的主要參數設置如表1所示,參數的設置是由多次訓練保存最優模型時確定的。

表1 主要參數設置
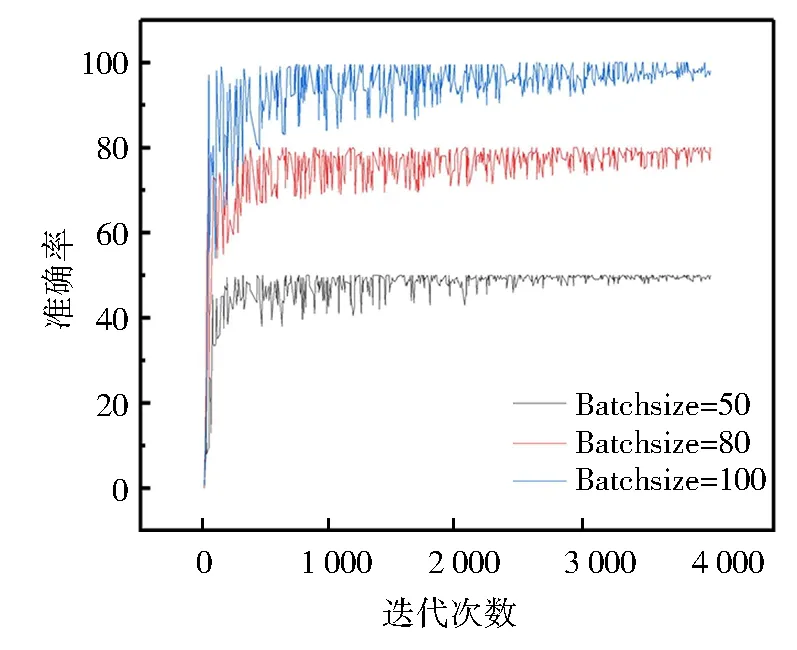
圖5 不同訓練批次的訓練準確率
將整個Pascal sentence數據集放到模型中訓練,自動提取學習特征,訓練的準確率如圖7所示,損失率如圖8所示。可以看出,隨著迭代次數的增加,準確率增加,最后達到穩定狀態。損失率恰恰相反。隨著訓練的次數不斷增加,準確率最高為98.2%,實驗證明本文的跨模態圖文檢索模型檢測效果很好。
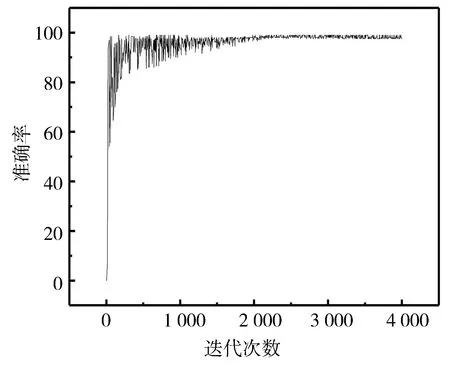
圖7 Pascal sentence數據集的訓練準確率
3.2 損失函數實驗
通過實驗測試所研究的損失函數對算法性能的影響,損失函數主要由三部分組成,分別是公共空間中的模態不變性損失μ1、公共空間中的判別損失μ2和最小化標簽空間中的判別損失μ3。為了綜合評估本算法相關的性能,執行了兩個模式檢索任務:圖像檢索文本和文本檢索圖像。平均精度值MAP綜合考慮了排序信息和精度,是跨模態檢索研究中廣泛使用的性能評價標準[14]。本文采用平均精度值MAP作為評價指標,對所改進的損失函數進行消融實驗,分別測試了沒有模態不變性損失函數μ1的模型1、沒有公共空間中判別損失函數μ2的模型2和沒有標簽空間中判別損失函數μ3的模型3,并與完整模型在Pascal sentence數據集上平均精度值(MAP)對比,最高分數以黑色字體顯示,如表2所示。可以看出,完整的目標函數在數據集上表現的最好。通過數據分析發現,在目標函數中同時考慮識別損失和模態不變性損失是一種有價值的多模態學習策略。
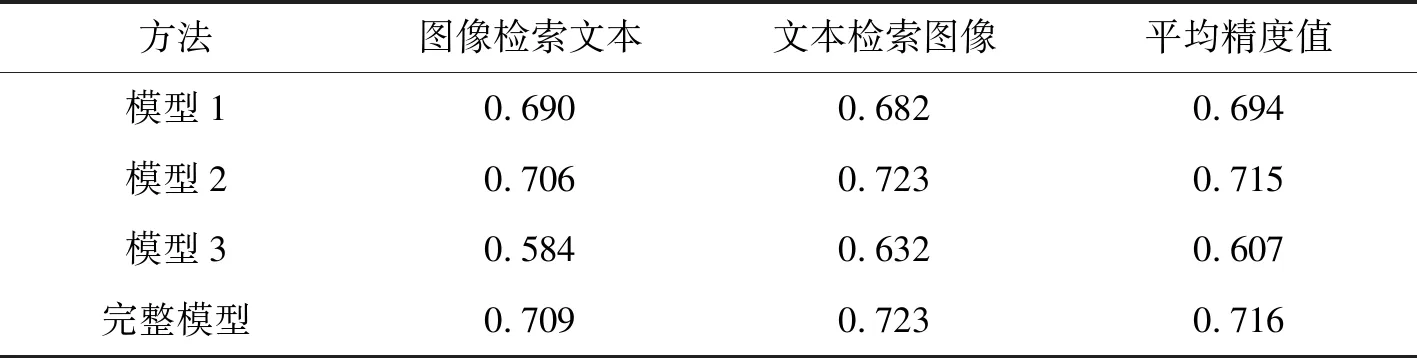
表2 不同模型的MAP值
3.3 對比實驗及測試結果
在新增后的Pascal sentence數據集上,使用平均精度值(MAP)對3種現有的圖文檢索算法進行性能評估。本算法與傳統的圖文檢索算法CCA[7]、基于深度學習的圖文檢索算法DCCA[15]和ACMR[1]等不同類型的圖文檢索算法進行對比,結果如表3所示。可以看出,基于深度學習的DCCA和ACMR算法在數據集中測試的平均精度值遠高于傳統算法CCA。實驗表明,改進的算法比DCCA和ACMR的平均精度值分別提升了5.6%和6.2%,改進后算法的性能優于傳統算法和現有基于深度學習的算法。
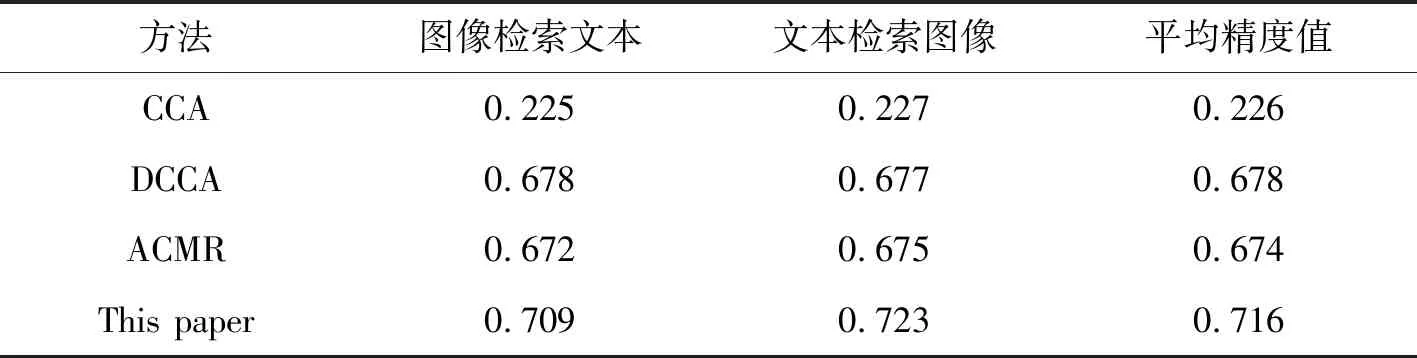
表3 不同方法的MAP值
測試方法是在Pascal sentence數據集中的測試集上隨機進行的。由圖像檢索文本,檢測結果是返回與圖像內容匹配度最高的3個英文文本,如表4所示。由文本檢索圖像,檢測結果是返回與文本內容匹配度最高的3個圖像,如表5所示。可以看出,本文改進算法的識別分類是有效的,能夠準確地返回圖文內容相互匹配的結果。

表4 圖像檢索文本結果

表5 文本檢索圖像結果
4 結 論
針對基于深度監督的跨模態檢索網絡結構設計與優化作了深入研究。對于跨模態檢索,所學習的公共表示既可以是有區別性的,也可以是模態不變的。通過在公共表示空間和標簽空間最小化判別損失和模態不變性損失來實現這個目標。利用卷積神經網絡對新增的數據集進行訓練學習,對算法進行多次調整參數,得到最優網絡模型。通過數據集進行驗證測試,實現了圖文檢索內容的相互匹配,對比現有其他圖文檢索的模型,本方法的平均精度值更高,性能更好。所改進的模型不僅可以應用于圖像和文本兩種模態的跨模態檢索,可以涉及到更多的模態,如音頻和視頻等,也可以應用到智慧醫療和腦科學等領域。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
