基于深度學習網絡的大學生就業去向跟蹤模型
2021-06-27 03:26:16李春燕
電子設計工程 2021年12期
李春燕
(東北石油大學,黑龍江大慶 163318)
伴隨高等教育改革的逐漸深入,畢業生的就業競爭逐漸增大,高校大學生的就業形勢愈發嚴峻。大學生就業問題為中國教育領域中的重中之重,此問題對高等教育的延續、社會經濟發展與人才培養均存在不可忽視的作用[1]。為了全面優化大學生就業水平與就業質量,必須全面分析大學生就業狀況。大學生就業去向跟蹤能夠全方位掌握大學生就業趨向,分析大學生對自身的就業觀[2]。以往分析大學生就業狀況時,各大高校均以就業率來評價,但有研究結果顯示,就業率僅可以體現畢業生在畢業之際的就業狀況。高校畢業生在剛剛踏入工作崗位后,就業狀態將存在一定變動性,所以就業率并不能科學、合理地體現大學生就業狀況[3]。就業去向跟蹤,能夠在指定時間段內,持續跟蹤學生就業狀況,分析學生就業質量[4]。為此,該文構建基于深度學習網絡的大學生就業去向跟蹤模型,對大學生就業狀況分析存在現實意義。
1 大學生就業去向跟蹤模型的具體設計
1.1 基于粗糙集與BP神經網絡的就業數據分類方法
因為各大高校畢業生人群中存在尚未工作的學生,所以使用基于粗糙集與BP 神經網絡的就業數據分類方法,篩選大學生就業數據,獲取已就業大學生的就業數據。
1.1.1 分類模型的構建
1)就業數據預處理。將大學生就業原始數據集分為條件屬性集合與目標屬性集合,把每個就業數據屬性實施泛化,泛化是為了將大學生就業原始數據集中就業數據連續屬性的取值區間分成很多小區間,各個區間存在一種離散符號[5-6]。以此能夠獲取一種決策系統,合并決策系統里不存在差異的就業數據,獲取用來支持分類模型的決策系統(V,DVE)。
2)把粗糙集理論使用在就業數據特征選取問題中,在原始就業數據里獲取最能體現分類屬性的特征[7]。詳細方法是:
輸入:就業數據特征選擇的條件屬性集D、就業數據特征選擇的決策屬性集E、就業數據特征選擇的決策信息系統(V,DVE),V表示論域。
輸出:獲取判斷矩陣N、約簡集RRED(D,E)。
第一步:假定決策系統里就業數據屬性的數目是m,則RRED(D,E)=?,?表示大學生就業訓練數據集,m=|V|。
第二步:建立m×m的空屬性矩陣N。
第三步:構建判斷矩陣N。
第四步:輸出判斷矩陣N、約簡集RRED(D,E)。
3)構建模型節點。圍繞約簡集RRED(D,E)構建模型的初始節點,把就業數據屬性不存在差異的節點放在模型的同一層間,之后分別在各個節點里去除一種屬性,獲取后續節點。
4)分類模型。將各個節點使用BP 神經網絡模型實施訓練,訓練時,將第p層第j個節點設成獲取的分類模型是:

其中,bn表示就業數據屬性。
1.1.2 就業數據分類實現
將訓練數據集構建分類模型后,使用該模型對大學生就業數據實現分類[8-9]。分類流程如下:
1)將需要分類的就業數據集條件屬性和分層分類模型里的節點相匹配[10-11]。詳情見圖1。

圖1 分類節點衍生詳情
自左到右檢索獲取首個匹配節點。
2)使用此節點中已經訓練完畢的BP 神經網絡模型對就業數據集實施分類,篩選就業原始數據集中已就業與未就業的數據分類結果[12-13]。
1.2 基于馬爾科夫過程的大學生就業移動預測模型
獲取大學生就業原始數據集中已就業的就業數據后,通過基于馬爾科夫過程的大學生就業移動預測模型,完成大學生就業去向跟蹤[14]。
1.2.1 轉移矩陣
假定{Ym} 描述馬爾科夫鏈,大學生就業狀態空間設成描述大學生就業狀況第一次的概率分布。m描述轉移次數構成矩陣形式可能表示為:

1.2.2 穩態概率分布
大學生在就業崗位里并不存在固定性,將就業狀態設成V。針對隨機V而言,具有正整數n,若qMM()1 ≥0,則馬爾科夫鏈存在平穩分布狀態向量α:
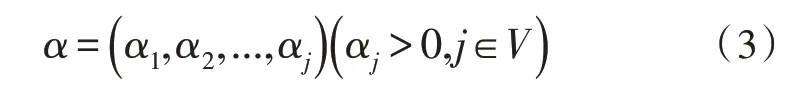
其屬于方程組(4)的唯一正解:

若處于平穩分布狀況的鏈是Y,穩態的就業質量等級(就業狀態優劣)期望值FY與方差EY依次是:
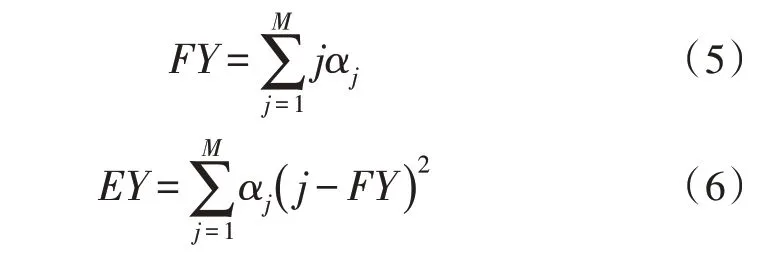
式中,j表示就業等級(就業崗位等級)。
分析穩態過程里的就業崗位屬性,能夠獲取大學生的就業結構、就業程度以及就業差異[15-16]。
1.2.3 轉移步數跟蹤
當就業去向轉移矩陣Q已經獲取后,m步轉移概率矩陣是:

在第一次就業便存在m步轉移,第m步時就業狀態概率分布是:
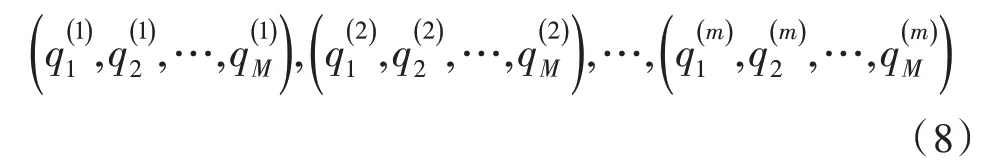
設定置信度是β,則就業各個階段的期望值是:

就業各個階段的期望值與平穩分布α=(α1,α2,…,αj)的期望值之比是:
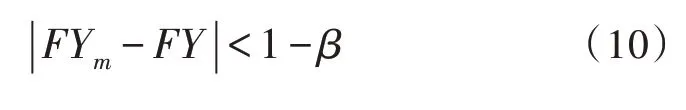
其中,m描述大學生第一次就業實現穩態時的轉移步數最小值。
1.2.4 就業崗位級別跟蹤
若大學生就業目標是一級就業(一級就業即為優秀崗位),將大學生在第一次就業中實現就業目標的期望時間設成k(M),那么時間模型是:

在前后兩次就業跟蹤中,就業目標降級出現的狀況很少,就業等級變小的比例能夠看成0。若i>j,就業崗位轉移矩陣是:

第一次就業的大學生實現就業目標的期望時間模型是:


2 實驗分析
使用該文模型對北京市“對外經濟貿易大學”2017 屆某本科生在2018-2019 年就業去向實施跟蹤。該學生學習的專業為經濟與金融,該文模型對其就業去向跟蹤結果見表1。
隨機在表1 中提取幾個月份的就業去向跟蹤結果和實際就業狀況實施校對,測試上述分析結果的真實性,結果見表2。根據表2 顯示,該文模型對北京市“對外經濟貿易大學”2017 屆某本科生2018-2019 年的就業去向跟蹤結果有效,與實際就業狀況完全匹配。

表1 就業去向跟蹤結果

表2 跟蹤結果真實性
為了測試該文模型的應用性能,對不同專業的大學生就業去向實施跟蹤,跟蹤對象在校學習專業依次是經濟與金融、物流管理、工商管理、海關管理、電子商務、行政管理、國際政治。分析該文模型、支持向量機模型對7 種專業大學生2018-2019 年的就業去向跟蹤結果的召回率,結果見圖2。分析圖2 召回率的測試結果可知,兩種模型對7 種專業大學生2018-2019 年就業去向的跟蹤結果存在差異,該文模型跟蹤結果的召回率大于支持向量機模型。由此可見,該文模型的跟蹤性能最佳。

圖2 兩種模型召回率對比結果
測試兩種模型在跟蹤該校7 種專業大學生2 年內就業去向時,對大學生就業去向的時間、崗位數據的漏查率與誤查率進行了對比,結果見圖3、圖4。分析圖3、圖4可知,該文模型對大學生就業去向的時間、崗位數據的漏查率與誤查率較低,在差異專業的大學生就業數據中,該文模型對就業去向的時間、崗位數據漏查率與誤查率均低于2%,而支持向量機模型對大學生就業去向的時間、崗位數據的漏查率與誤查率始終高于2%,則該文模型更適用于大學生就業去向跟蹤問題。

圖3 兩種模型漏查率對比結果

圖4 兩種模型誤查率對比結果
3 結束語
大學生就業狀況跟蹤,對各大高校辦學質量存在十分重要的影響。實時跟蹤大學生就業狀況,分析畢業生在工作崗位遇到的問題后,可在高校教育內容中進行拓展,對應屆大學生的就業能力培養存在一定意義。該文構建的大學生就業去向跟蹤模型,運用了深度學習理論對數據分類、趨勢預測的優勢,能夠實現大學生就業去向高精度跟蹤。經測試,該文模型的跟蹤結果的召回率優于支持向量機模型,且漏查率與誤查率較低,跟蹤性能佳。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
下一代英才(酷炫少年)(2019年3期)2019-03-25 02:34:18
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
黃河之聲(2017年14期)2017-10-11 09:03:59
光學精密工程(2016年6期)2016-11-07 09:07:19
