探索基于文本特征識別的電子檔案自動歸類系統
2021-06-30 01:43:54德州職業技術學院田紹敏
電子世界 2021年11期
德州職業技術學院 田紹敏
本文根據傳統分類方法的不便之處,經有效思考,提出了一種新型電子檔案自動歸類系統,通過以文本特征作為識別對象,可有效完成分類工作。該系統具有語料庫模塊,能夠根據使用者日常搜索情況,分析其內在需求,實現對語料的挖掘,并完成相關操作。同時,借助排版模塊,通過使用其中內容映射運作方式,能夠對電子檔案進行具體歸檔。建立在多種方法基礎上,能夠根據文本特征詞,對電子檔案中存在的文本特征進行識別,確定其最終歸屬。
1 基于文本特征識別自動歸類系統分析
1.1 整體系統設計
本文系統整體系統設計如圖1所示。以實現實時性對海量信息自動歸類作為最終目的,本文系統借助文本特征識別技術,可有效縮短電子檔案內容分析時間,并以此作為依據,實現相應的歸類工作,能夠為使用者提供有效便利。
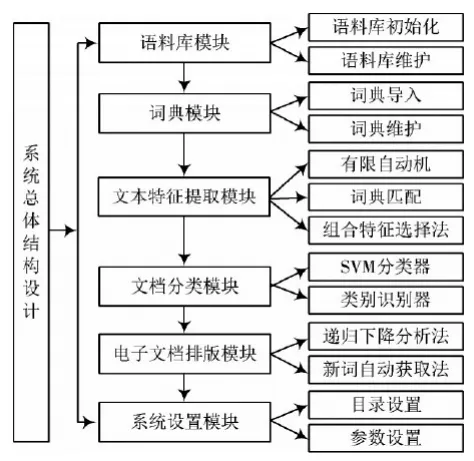
圖1 系統整體設計圖
在各系統模塊中,語料庫模塊主要負責對相關算法學習進行管理,并構建訓練檔案集。詞典模塊負責構建詞典,并在詞典中完成添加、清除詞條等操作。文本體征提取模塊在所有模塊中,具有核心地位,主要負責在合理切分詞條的基礎上,對詞頻進行統計,并以結果作為參考,制作文本特征項集。電子檔案分類模塊主要負責以上文項集作為依據,對檔案代表向量進行分類處理,并分析不同向量中存在的相似度,實現自動歸類。在電子檔案排版模塊,主要使用方法包括遞歸下降分析法、新詞自動獲取法,能夠在總體電子檔案中,自動對內容進行排版。系統設置模塊負責根據實際工作情況,合理調整系統各項參數。
1.2 語料庫模塊
在本文研究系統中,主要應用語料庫模塊設計為Ontology,建立在明確使用者需求基礎上,可有效實現對語料的深入挖掘,并進一步構建語料庫,為查詢、維護等相關操作提供便利,有利于促進文本特征提取模塊工作。對于自動運轉子模塊而言,主要分為兩部分,即后臺運行、對使用者挖掘、操作命令進行響應等。在挖掘命令方面,借助自動轉運子模塊功能,利用元搜索引擎,能夠在大數據中搜索相應的語料。同時,通過使用過濾子模塊,能夠將Web軟件利用檔案向量形式進行準確描述,以檔案向量進行參考,將本體向量與其進行對比,在分析相關性基礎上,能夠準確獲取相應的語料,并完成測試工作。在使用者抽象處理語料后,應將相關概念、Web頁面完整體現在本題庫、語料庫中,并根據運轉子模塊,得到最終挖掘結果,向使用者進行展示。在操作命令方面,經運轉子模塊有效處理后,本題庫操作模塊將會接收到具體命令,并在語料庫完成相關操作,將最終結果展示給使用者。
1.3 排版模塊
在電子檔案中,內容識別方法使用遞歸下降分析法,主題詞識別使用新詞自動獲取法,上述方法不僅在識別方面性能良好,還能夠起到對格式進行糾錯的作用,借助內容映射功能,能夠有效實現排版工作,排版效率顯著。對于固定檔案而言,排版子模塊能夠完成合理模板文件設計,具體需要參考格式固定情況,并以單一電子檔案設計作為參考。并進一步按照固定程序,實現在固定路徑內,對文件進行存儲。基于上述工作,使用者通過將所需要的歸檔資料輸入在相關區域內,經系統處理,可自動將資料進行規范。同時,針對文件類型不同,格式模板在標準方面也存在一定的差異,而應用格式模板子模塊,能夠有效對這一現象進行處理。針對格式校正模塊,可完成對檔案框架標題的修正,進一步實現對檔案內容的解析,并將其予以合理處理。針對排版子模塊,能夠精準識別不規范標題,并進行有效修正,能夠對文本中的各個段落進行重排,并將其按照相應的檔案格式完成生成。
1.4 軟件設計
(1)本特征識別算法。在電子檔案中,通過深入挖掘語料庫模塊,能夠有效獲取相應的語料,建立在明確文本特征識別算法基礎上,可將其有效應用在文本特征提取模塊中,提高文本特征識別水平,優化其精確度,能夠確保文本自動歸類工作完成。在本文系統中,通過以文本特征作為重點,落實相應的識別方法,并配套實施兩步特征選擇方法,在有機結合各類方法基礎上,進一步形成組合特征選擇法。
(2)預選取。針對特征預選取,主要使用方法為有限自動機選擇法,通過在檔案中,對文本內容進行提取,可明確相應的特征詞,并根據原電子檔案,將文本內容進行有效轉化,去除文本中原本存在的特征詞,使其處于無特征詞狀態。可設置特征集,并將特征詞作為其中一部分,在整個電子檔案語料庫模塊中,設置待處理原始語料集為X={X1......Xn},設置最終文本特征集為Y={y1......ym},在完成模式抽取的同時,進一步生成相應的有限自動機,并對結果進行識別處理,可在整個X中,對全部文本特征詞進行識別,進一步形成Y,經有效手段,對y中涉及到的所有字符串進行統計,將詞頻設置為xfj,將閾值設置為w,借助有效計算公式,可得出在w為3的情況下,將文本特征進行提取,能夠達到最高精度。在Y中,如果xfj低于w,將會得到字符串yj,在這種情況下,針對原電子檔案文本,可對文本特征詞進行有效復原,使其轉變為正常狀態。同時,在原電子檔案文本中,通過進行字典匹配,并借助有效識別法,能夠有效改變檔案文本集,使其轉變為無特殊詞狀態。
(3)組合特征選擇法。在X集中,對檔案所有文本進行分詞處理,借助組合特征選擇法,將部分詞進行有效選取,通過使用相關公式對剩余詞進行計算,獲取相應的CHI值,并以CHI值降序形式,對提取剩下的詞進行排列,按照從上到下的原則,將選取的部分詞,添加在Y集中。
建立在合理使用上述方法基礎上,通過整合Y集,并根據部分詞特征,可有效生成最終本文特征集。
(4)自動歸類流程。以上文內容作為依據,通過獲取相應的文本特征集,并合理使用SAV分類器、類別識別器,利用文檔分類模塊功能,自動歸類相關電子檔案。
建立在兩次歸類基礎上,能夠實現對電子檔案的綜合評定,確定其最終類別歸屬。借助SVM分類器,完成首次歸類,主要圍繞電子檔案,對其是否存在敏感電子檔案情況進行判斷,如果判定為是,則可以直接將該檔案按照敏感檔案進行歸類,如果判定為否,則需要對檔案予以二次歸類,在第二次歸類中,主要選擇類別識別器,以文本特征識別結果作為參考,進行分類,并最終實現歸類處理,通過兩次分類,確保電子檔案歸類合理性,并進一步保障所有檔案均能夠實現準確的自動分類。
2 實驗分析
為有效驗證上文系統準確性,本文在某圖書館中,集中抽取訓練集、測試集電子檔案共1000份,其中,前者500份,行封閉性歸類測試,設為A組,后者500份,行開放性歸類測試,設為B組。測試方向為查全率、精度。研究結果表明,A組查全率平均為97.70%,精度為96.30%。B組查全率平均為96.70%,精度為95.42%。兩組并不存在明顯差距,說明應用本文系統,能夠精確識別電子檔案,并且具有較高的普遍性,在有效性方面優勢顯著。
取相同實驗環境,將本文系統設為A組,將層級類別信息歸類系統設為B組,將權重自動優化歸類系統作為C組,三組均接受自動歸類實驗,并集中在不同信噪比環境下,對比三組平均中斷概率,分析不同系統穩定性情況。實驗結果表明,A組平均中斷概率為0.16%,B組為0.42%,C組為0.58%,A組相對較低。并且以平均信噪比在20db以下作為背景,三組在平均中斷概率方面并不存在明顯差異,并且在信噪比升高情況下,三組平均中斷概率隨之升高,但是A組整體上升情況低于B組、C組,說明應用本文系統,在穩定性方面優勢明顯。
對特征數進行調整,按照上文分組方式,對比三組準確率、召回率,具體實驗結果顯示:A組召回率、準確率均高于B組、C組。究其原因,在本文系統中,通過準確識別文本信息,完成自動分類,能夠避免受到以往特征詞丟失情況影響,并且借助組合特征選擇法,本文研究系統降噪效果顯著,穩定性良好。
結論:建立在有效電子檔案自動歸檔基礎上,可有效提取到海量信息。本文研究自動歸類系統主要根據文本特征,并進一步配套兩步特征選擇方法,實現對文本特征的有效識別,通過合理使用SVM分類器,加強對類別識別器的使用,能夠對文檔進行兩次歸類,最終完成相應的歸類。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
家庭影院技術(2017年9期)2017-09-26 03:41:45
小學教學參考(2015年20期)2016-01-15 08:44:38
