基于菌群優(yōu)化算法優(yōu)化生產(chǎn)車間傳感網(wǎng)能耗
2021-07-07 02:43:08王海林張春光唐超塵
濟南大學學報(自然科學版) 2021年4期
關(guān)鍵詞:優(yōu)化
王海林,張春光,唐超塵,劉 鑫
(1.廣州商學院 信息技術(shù)與工程學院,廣東 廣州 510555;2.北京科技大學 計算機與通信工程學院,北京 100083;3.西安電子科技大學 通信工程學院,陜西 西安 710071;4.桂林理工大學 信息科學與工程學院,廣西 桂林 541004)
隨著物聯(lián)網(wǎng)技術(shù)和傳感網(wǎng)技術(shù)的發(fā)展,智能化的生產(chǎn)車間得到了充分應用[1],將企業(yè)生產(chǎn)車間的生產(chǎn)環(huán)節(jié)、環(huán)境、工具和人員等進行數(shù)字化管理與監(jiān)控,為車間的生產(chǎn)管理提供了有效保障。通過前端行使數(shù)據(jù)采集功能的傳感器獲取生產(chǎn)各步驟的數(shù)據(jù),然后通過傳感器網(wǎng)絡將采集數(shù)據(jù)進行不斷轉(zhuǎn)發(fā)與路由,搜集至網(wǎng)關(guān)節(jié)點,最后通過網(wǎng)關(guān)節(jié)點發(fā)送至應用層網(wǎng)絡,在應用層實現(xiàn)數(shù)據(jù)的分析、監(jiān)控與可視化管理等。
前端的數(shù)據(jù)采集和后端的數(shù)據(jù)分析實現(xiàn)方法比較常見,其中前端可以根據(jù)生產(chǎn)過程的需要布置傳感器節(jié)點[2],后端只要獲得有效數(shù)據(jù)就可以進行純上層應用開發(fā)。相比之下,中端的傳感網(wǎng)數(shù)據(jù)的傳輸部分最為關(guān)鍵,如果僅采用自組網(wǎng)的網(wǎng)絡方式,就會造成資源浪費或者因傳輸能耗不均衡而導致網(wǎng)絡不穩(wěn)定[3],甚至不能傳輸數(shù)據(jù)。
本文中研究如何采用智能算法對傳感器網(wǎng)絡能耗進行分析,采用基于菌群優(yōu)化的徑向基函數(shù)(RBF)神經(jīng)網(wǎng)絡算法(簡稱本文算法)對傳感網(wǎng)數(shù)據(jù)進行融合,去除冗余感知數(shù)據(jù)并降低數(shù)據(jù)維度。首先分析傳感網(wǎng)節(jié)點的分簇及數(shù)據(jù)傳輸方式,然后建立基于徑向基函數(shù)神經(jīng)網(wǎng)絡的生產(chǎn)車間傳感網(wǎng)數(shù)據(jù)融合模型,引入菌群算法,利用菌群算法的趨化、復制和遷徙操作對神經(jīng)網(wǎng)絡的權(quán)重進行優(yōu)化,獲得穩(wěn)定的RBF神經(jīng)網(wǎng)絡結(jié)構(gòu),以便能夠降低能耗,提高傳感網(wǎng)的使用強度,改善生產(chǎn)車間傳感網(wǎng)絡傳輸?shù)姆€(wěn)定性。
1 傳感網(wǎng)能耗優(yōu)化
傳感網(wǎng)絡的應用環(huán)境不同于一般網(wǎng)絡,在能源提供方面,大部分節(jié)點采用的是電池供電方式,當電池耗盡時,傳感節(jié)點將停止工作,與所連傳感網(wǎng)絡“脫網(wǎng)”。為了避免頻繁地更換電池,且考慮到生產(chǎn)車間一般需要的傳感器節(jié)點數(shù)目多、分布面積較廣等現(xiàn)狀,必須控制生產(chǎn)車間的傳感網(wǎng)能耗[4],提高傳感網(wǎng)能源利用率。目前,關(guān)于傳感網(wǎng)的能耗優(yōu)化主要從以下2個方面考慮:一是傳感數(shù)據(jù)融合,通過將多個傳感器采集的數(shù)據(jù)進行有效融合,對原始數(shù)據(jù)及特征進行訓練,去冗余優(yōu)化后獲取特征更強的數(shù)據(jù),這種數(shù)據(jù)量的優(yōu)化能夠降低傳感網(wǎng)能耗;二是通過智能算法優(yōu)化傳感網(wǎng)節(jié)點的簇首及路徑,合理選擇簇首節(jié)點及路徑[5],控制擁塞,均衡處理網(wǎng)絡能耗。
目前主流的傳感網(wǎng)數(shù)據(jù)傳輸協(xié)議為低能耗自適應聚類分層協(xié)議算法(LEACH)結(jié)構(gòu),將傳感節(jié)點分為簇首和普通節(jié)點[6],節(jié)點分布如圖1所示。根據(jù)應用環(huán)境特點、場地分布以及需要獲取的傳感數(shù)據(jù)精度等,可以將需要分析的傳感節(jié)點進行分簇,降低整個傳感網(wǎng)絡的復雜度。傳感節(jié)點的傳輸方式主要是通過路由和轉(zhuǎn)發(fā)完成,工作方式如圖2所示。

圖1 低能耗自適應聚類分層協(xié)議算法(LEACH)節(jié)點分布
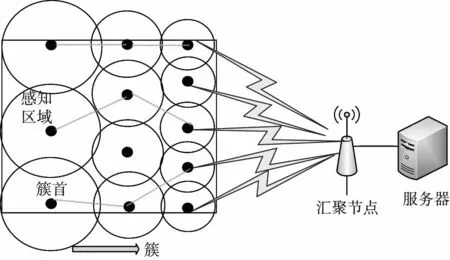
圖2 數(shù)據(jù)傳輸基本流程
在所有傳感節(jié)點傳輸?shù)絽R聚節(jié)點之前,經(jīng)過有效數(shù)據(jù)融合,減少數(shù)據(jù)量,有效地提高了傳感節(jié)點能量使用效率。
2 菌群優(yōu)化的RBF神經(jīng)網(wǎng)絡
2.1 RBF神經(jīng)網(wǎng)絡
設輸入樣本為Xi=(x1,x2,…,xn),i=1,2,…,m,其中m、n分別為樣本總量和單個樣本的特征總數(shù)。一般而言,輸入層神經(jīng)元個數(shù)和特征總數(shù)相等,經(jīng)過樣本特征篩選凈化后,輸入層神經(jīng)元數(shù)量一般小于特征總數(shù)[7]。第k個樣本經(jīng)過模型運算得到的輸出為Yk=(y1,y2,…,yN),N為輸出層神經(jīng)元個數(shù)。
首先,輸入樣本經(jīng)過權(quán)重到達隱藏層第1層的S1j[8]為
(1)
式中:Sij為隱藏層第1層第j個神經(jīng)元的輸出;W1ij為隱藏層第1層第j個神經(jīng)元與輸入層第i個節(jié)點的連接權(quán)重;θ1j為隱藏層第1層的第j個神經(jīng)元的偏置向量;p為隱藏層第1層神經(jīng)元總數(shù)。
S1j經(jīng)過特征轉(zhuǎn)換函數(shù)[9]后可得
(2)

經(jīng)過所有隱藏層的輸出結(jié)果[10]為
(3)
式中:Lt為t時刻的隱藏層輸出值;Vj t為t時刻的第j個神經(jīng)元的權(quán)重。
以此類推,經(jīng)過Gaussian函數(shù)求解得到整個模型的輸出結(jié)果。
2.2 菌群算法
設菌群個體總數(shù)為S,個體的優(yōu)化維度為ρ,通過不斷的趨化(次數(shù)為j)、復制(次數(shù)為k)和遷移(次數(shù)為l)操作,獲得適應度值大的優(yōu)良個體[11]。主要參數(shù)如下:da為引力深度;ωa為引力寬度;ωr為斥力高度;hr為斥力寬度;Pe為遷移驅(qū)散概率;Nc為總趨化次數(shù);C(i)為趨化更新步長;Nr為總復制次數(shù);Ne為總遷徙次數(shù)。
設第i個個體θ(i)(j,k,l)的趨化位置更新方法[12]為
θ(i)(j+1,k,l)=θ(i)(j,k,l)+C(i)。
(4)
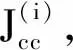
(5)
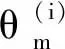

P=Amin+rand(Amax-Amin),
(6)
式中:Amin和Amax分別為邊界最小值和最大值;rand(·)為在(0,1)范圍內(nèi)隨機取值的函數(shù)。
2.3 菌群優(yōu)化的RBF神經(jīng)網(wǎng)絡
RBF神經(jīng)網(wǎng)絡的優(yōu)化主要有以下2種途徑:一是通過算法不斷優(yōu)化RBF神經(jīng)網(wǎng)絡的各層權(quán)重,通過權(quán)重優(yōu)化,使RBF神經(jīng)網(wǎng)絡的輸出結(jié)果與實際結(jié)果更接近;二是通過算法不斷調(diào)整RBF神經(jīng)網(wǎng)絡的節(jié)點數(shù)以及節(jié)點分布,使得RBF神經(jīng)網(wǎng)絡的輸出結(jié)果與實際結(jié)果更接近。在實際操作中,也可以將這2種途徑混合使用,從而能夠得到全局最優(yōu)解。
本文中采用菌群算法對RBF神經(jīng)網(wǎng)絡權(quán)重進行優(yōu)化,根據(jù)初始權(quán)重及隨機預設節(jié)點生成的網(wǎng)絡模型結(jié)構(gòu),把該網(wǎng)絡結(jié)果進行數(shù)學表示及編碼,數(shù)學表示為矩陣的形式,將多個權(quán)重矩陣作為菌群算法的輸入集合,選擇誤差函數(shù)較小的網(wǎng)絡結(jié)構(gòu)模型進行算法優(yōu)化。
菌群混合優(yōu)化得到的最優(yōu)個體的過程,實際就是求解RBF神經(jīng)網(wǎng)絡權(quán)重最優(yōu)解的過程,獲得了權(quán)重最優(yōu)解就能夠確定RBF神經(jīng)網(wǎng)絡的生產(chǎn)車間傳感網(wǎng)能耗降低模型[14]。菌群算法訓練的最優(yōu)結(jié)果為最優(yōu)RBF神經(jīng)網(wǎng)絡結(jié)構(gòu)模型。經(jīng)過混合菌群優(yōu)化的RBF神經(jīng)網(wǎng)絡降低生產(chǎn)車間傳感網(wǎng)能耗的大致流程如下:
1)采集傳感網(wǎng)能耗樣本,然后進行初始化及向量化;
2)建立基于RBF神經(jīng)網(wǎng)絡的傳感網(wǎng)能耗降低模型,由S個節(jié)點組成;
3)隨機產(chǎn)生RBF神經(jīng)網(wǎng)絡權(quán)重;
5)根據(jù)菌群算法進行迭代和遷移過程,并判斷是否滿足截止條件,滿足則跳轉(zhuǎn)下一步,否則繼續(xù)迭代操作;

7)得到優(yōu)化后的RBF神經(jīng)網(wǎng)絡結(jié)構(gòu)模型,可有效降低各個傳感網(wǎng)節(jié)點的能耗。
具體流程如圖3所示。
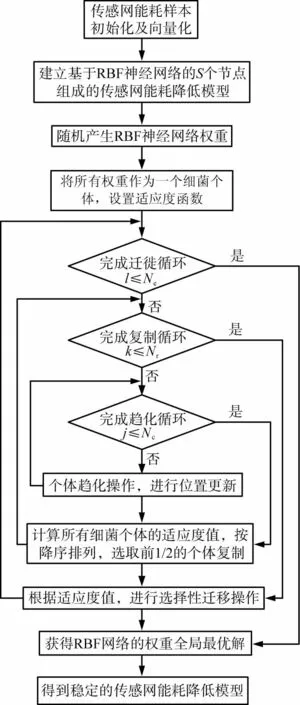
l—個體遷移次數(shù);k—個體復制次數(shù);j—個體趨化次數(shù);Nr—總復制次數(shù);Nc—總趨化次數(shù);Ne—總遷徙次數(shù)。圖3 菌群優(yōu)化徑向基函數(shù)(RBF)神經(jīng)網(wǎng)絡的傳感網(wǎng)能耗降低流程
3 實例仿真
為了驗證菌群優(yōu)化RBF神經(jīng)網(wǎng)絡在生產(chǎn)車間傳感網(wǎng)能耗降低的性能,采用MATLAB軟件和NS2軟件進行仿真,將常用的傳感網(wǎng)能耗優(yōu)化方法,如能量感知非均勻分簇(EAUC)、LEACH和自組織特征映射數(shù)據(jù)算法(SOFMDA),與本文算法進行能耗性能對比[15-16]。仿真環(huán)境主要參數(shù)見表1。在仿真過程中,RBF神經(jīng)網(wǎng)絡的輸入和輸出傳感節(jié)點個數(shù)分別為1 012和15,隱藏層神經(jīng)元個數(shù)為20。

表1 仿真環(huán)境參數(shù)
3.1 不同算法的傳感網(wǎng)能耗優(yōu)化
3.1.1 傳感網(wǎng)存活節(jié)點數(shù)
不同算法的傳感網(wǎng)存活節(jié)點數(shù)如圖4所示。從圖中可看出,隨著訓練輪次的增加,訓練時間增加,而存活節(jié)點數(shù)減少,EAUC、LEACH和SOFMDA算法在運行時間為400 s時開始出現(xiàn)傳感網(wǎng)節(jié)點電池耗盡的情況,而本文算法在運行時間為520 s左右開始有節(jié)點“脫網(wǎng)”。在運行時間為400~800 s時,經(jīng)過EAUC、LEACH和SOFMDA算法優(yōu)化的傳感網(wǎng)節(jié)點數(shù)量減少速度快,其中EAUC算法的性能最差。在運行1 100 s時,EAUC、LEACH和SOFMDA算法的在網(wǎng)節(jié)點數(shù)為0,而運行1 400 s時,本文算法的在網(wǎng)節(jié)點數(shù)才開始趨0。
3.1.2 網(wǎng)絡節(jié)點平均能耗
初始設置共有1 012個網(wǎng)絡節(jié)點,每個節(jié)點初始能量為1 J,因此全網(wǎng)所有節(jié)點共有能量1 012 J。通過不斷地分簇和路由傳輸,對4種算法在不同運行輪數(shù)的能耗進行仿真,結(jié)果如表2所示。

表2 不同算法的節(jié)點能耗比較
由表中數(shù)據(jù)可以看出,隨著運行輪次不斷增加,生產(chǎn)車間的傳感網(wǎng)能耗不斷增大。當運行輪次為200~800時,4種算法的能耗均增加較快;而當運行輪次達到1 100時,EAUC、LEACH和SOFMDA算法的能耗趨于穩(wěn)定值,約為999 J,此時網(wǎng)絡中的節(jié)點能量大部分均已消耗。由于本文算法的網(wǎng)絡存活節(jié)點數(shù)減少緩慢,因此能量消耗持續(xù)的時間較長。在運行輪次達到1 500時,4種算法優(yōu)化的傳感網(wǎng)所有節(jié)點均停止工作,能耗總量達到1 012 J。
3.1.3 數(shù)據(jù)包接收結(jié)果
對匯聚節(jié)點接收的數(shù)據(jù)包進行仿真。從普通節(jié)點開始定時、定量上行發(fā)包,統(tǒng)計在網(wǎng)絡所有節(jié)點能耗耗費完之前匯聚節(jié)點接收的數(shù)據(jù)量,結(jié)果如圖5所示。由圖可以看出,所有節(jié)點能量消耗完畢后,本文中提出的算法的傳感網(wǎng)匯聚節(jié)點收到的數(shù)據(jù)包個數(shù)最多約為5.5×104,EAUC算法的最差,約為4.5×104。在運行時間為200~1 000 s的快速增長期內(nèi),相比其他3種算法,本文算法匯聚節(jié)點收到的數(shù)據(jù)包優(yōu)勢明顯,獲得更好的數(shù)據(jù)通信效果。

EAUC—能量感知非均勻分簇;LEACH—低能耗自適應聚類分層協(xié)議算法;SOFMDA—自組織特征映射數(shù)據(jù)算法;本文算法—基于菌群優(yōu)化的徑向基函數(shù)神經(jīng)網(wǎng)絡算法。圖4 不同算法的傳感網(wǎng)存活節(jié)點數(shù)量
3.2 菌群優(yōu)化性能
為了進一步驗證改進的菌群算法對傳感網(wǎng)能耗降低的影響,對菌群優(yōu)化RBF神經(jīng)網(wǎng)絡的能耗進行優(yōu)化。

EAUC—能量感知非均勻分簇;LEACH—低能耗自適應聚類分層協(xié)議算法;SOFMDA—自組織特征映射數(shù)據(jù)算法;本文算法—基于菌群優(yōu)化的徑向基函數(shù)神經(jīng)網(wǎng)絡算法。圖5 不同算法的匯聚節(jié)點接收的數(shù)據(jù)包數(shù)量
結(jié)合表1,菌群算法的主要參數(shù)設置值為S=100,Nc=100,Nr=10,Ne=5,Pe=0.2,C(i)=0.1,da=hr=0.01,ωa=ωr=10。
3.2.1 菌群優(yōu)化算法性能提升
RBF神經(jīng)網(wǎng)絡算法和本文算法的存活節(jié)點數(shù)如圖6所示。通過對比可以看出,經(jīng)過菌群優(yōu)化的RBF神經(jīng)網(wǎng)絡能減慢傳感網(wǎng)節(jié)點數(shù)的“脫網(wǎng)”速度,而且網(wǎng)絡節(jié)點數(shù)減少的速度更平緩。

RBF—徑向基函數(shù);本文算法—基于菌群優(yōu)化的徑向基函數(shù)神經(jīng)網(wǎng)絡算法。圖6 菌群優(yōu)化對傳感網(wǎng)存活節(jié)點數(shù)的影響
3.2.2 不同趨化步長的降耗性能
為了進一步分析菌群優(yōu)化算法對傳感網(wǎng)能耗降低的優(yōu)化性能,選擇運行輪次數(shù)為800,對趨化步長差異化設置,驗證趨化步長對傳感網(wǎng)的影響,仿真結(jié)果如表3所示。對比發(fā)現(xiàn),趨化步長為0.12時,存活節(jié)點數(shù)和匯聚節(jié)點接收的數(shù)據(jù)包數(shù)均取得了最優(yōu)值,對傳感網(wǎng)能耗優(yōu)化更明顯。
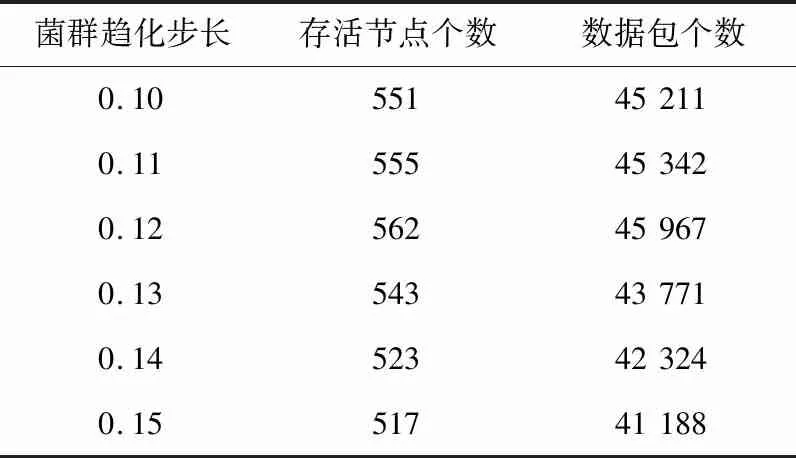
表3 菌群趨化步長對傳感網(wǎng)能耗影響
4 結(jié)語
本文中采用菌群優(yōu)化RBF神經(jīng)網(wǎng)絡進行生產(chǎn)車間傳感網(wǎng)能耗優(yōu)化,實驗證明,該方法能夠有效延緩傳感網(wǎng)節(jié)點“脫網(wǎng)”速度,在有限能量內(nèi)有效匯聚節(jié)點,從而接收到更多的數(shù)據(jù)。后續(xù)研究將進一步差異化調(diào)整菌群算法參數(shù),不斷降低傳感網(wǎng)能耗,提高生產(chǎn)車間數(shù)字化管理水平。
猜你喜歡
房地產(chǎn)導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發(fā)展導向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導向(2021年7期)2021-07-16 07:07:52
中學生數(shù)理化(高中版.高二數(shù)學)(2021年12期)2021-04-26 07:43:48
中學生數(shù)理化(高中版.高考數(shù)學)(2021年12期)2021-03-08 01:28:50
今日農(nóng)業(yè)(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(shù)(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
